
本文介绍了GNUparallel的Linux安装及主要使用方法,为实现CPU并行处理任务做准备。GNUParallel是一个shell工具,为了在一台或多台计算机上并行的执行计算任务,一个计算任务可以是一条s...
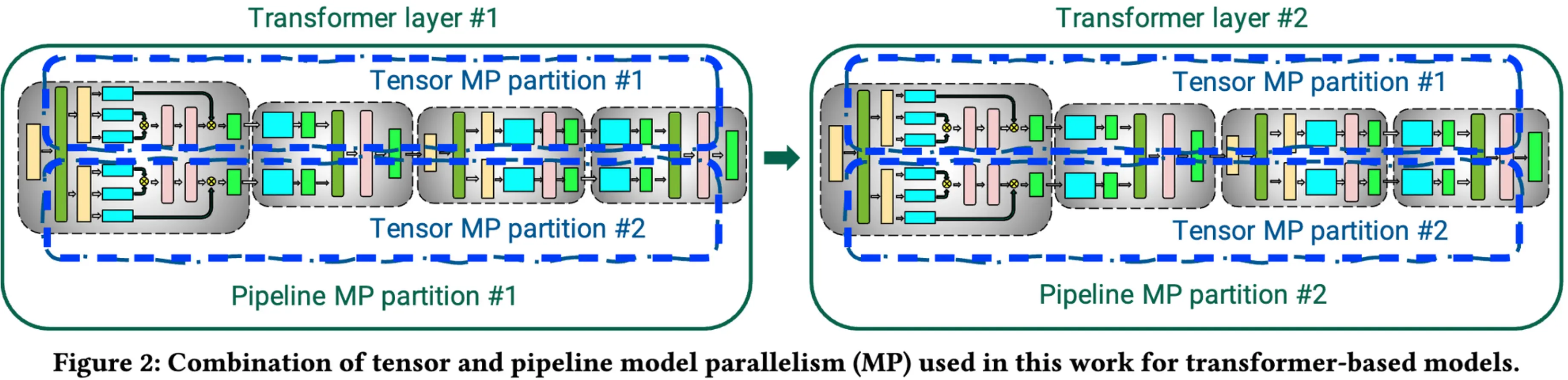
概述根据前面的系列文章,对预训练大模型里用到的主要并行加速技术做了一系列拆分.但是在实际的训练里往往是多种并行混合训练.我们要怎么配置这些并行策略才能让训练框架尽可能的减少通信瓶颈,提升GPU计算利用率呢?这里的变量太多了,以最简单的3D并行为例...
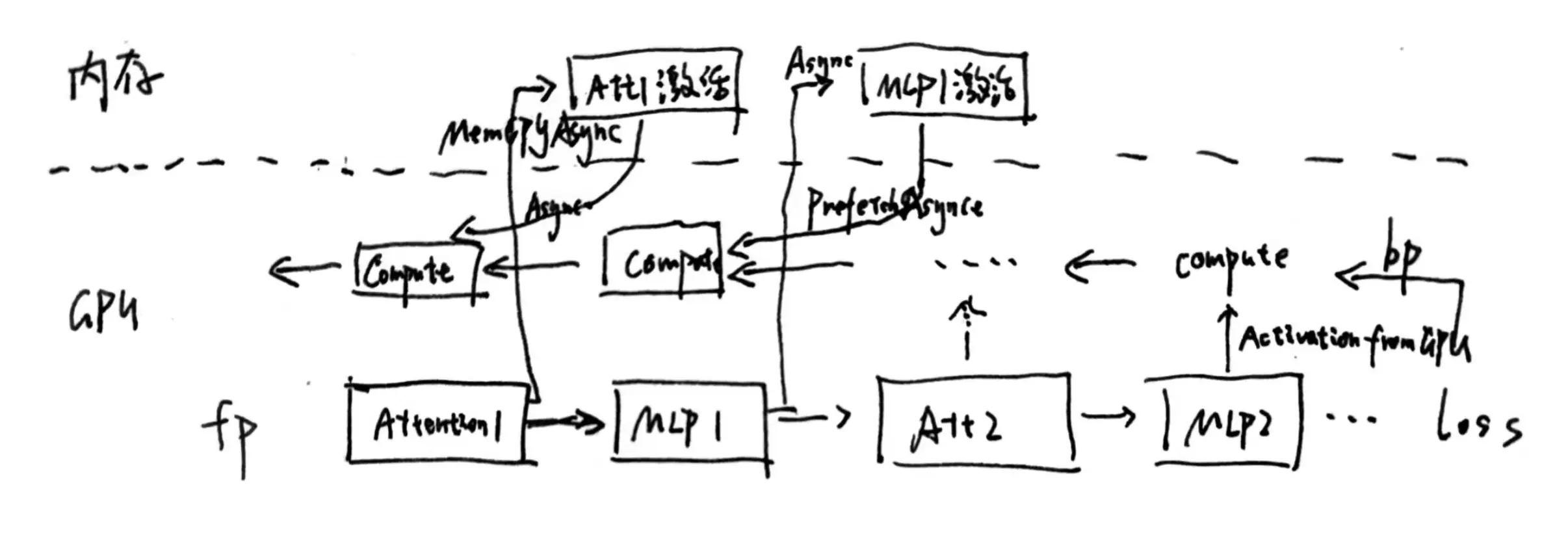
LLM训练activation优化相关技术,包括激活重计算/序列并行/zero-R/zero-offload等...
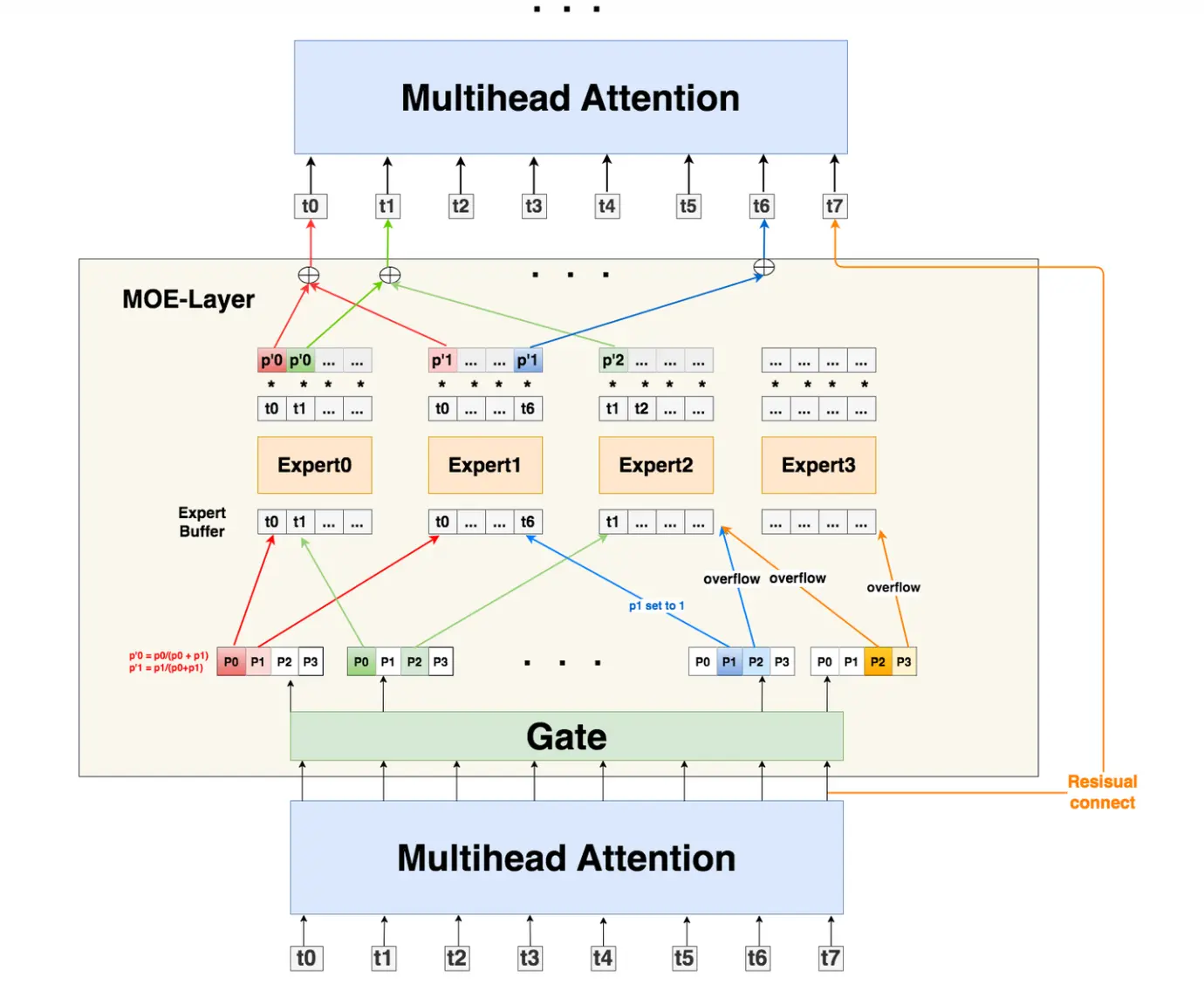
前置知识MOE(MixerOfExpert)moe的主要原理是替换attention层后的MLP层,通过将不同类型的token按照门控单元计算出的概率分配给最大概率处理的专家网络处理,对比单一MLP更适合处理复杂多样化的数据集.主要思想和集成学习感觉...

简单理解:前端先将文件切割多份,在进行上传,由后端进行切片合并操作。秒传断点续传并行。_前端分割文件...

*《数字化运维:IT运维架构的数字化转型》**以传统运维管理体系(PPTR)为基座,在融合数字化转型、ITIL4、DevOps、SRE以及敏捷精益思想的基础上,首先提出了数字化运维管理体系OPDM(Operat...
大侠幸会,在下全网同名「算法金」0基础转AI上岸,多个算法赛Top「日更万日,让更多人享受智能乐趣」今日215/10000为模型找到最好的超参数是机器学习实践中最困难的部分之一1.超参数调优的基本概念机器学习模型中的参数通常分为两类...

并行流是Java中StreamAPI的一部分,用于在多核处理器上并行执行流操作。在Java8及更高版本中引入的StreamAPI提供了一种新的处理集合的方式,使得开发者能够更轻松地进行数据处理和操作。在使用...

GE(GraphEngine)图引擎采用多流并行算法,在满足计算图任务内部依赖关系的前提下,支持高效并发执行计算任务,从而大大提高硬件资源利用率和AI计算效率。...
算法优化并行注意力机制\[串行版本:y=x+MLP(LayerNorm(x+Attention(LayerNorm(x))))\]\[并行版本:y=x+MLP(LayerNorm(x))+...