LLM并行训练4-megascale论文学习
cnblogs 2024-06-30 08:13:00 阅读 88
字节megascale论文学习笔记
算法优化
并行注意力机制
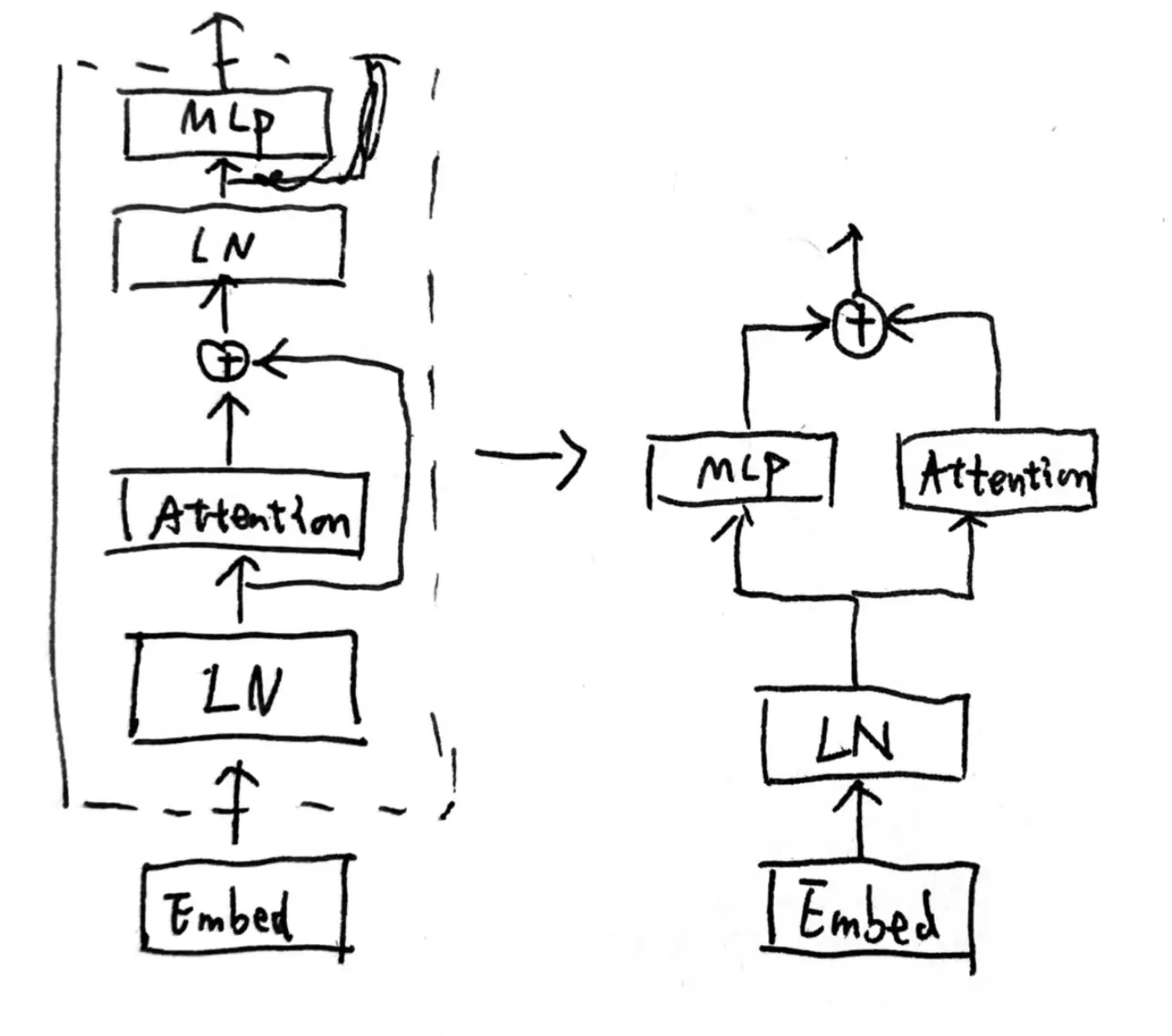
\[串行版本: y = x + MLP(LayerNorm(x + Attention(LayerNorm(x))))
\]
\[并行版本: y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x))))
\]
乍一看确实不是等价的, attention那块的后置mlp去哪了..这个其实没有理论证明, Palm论文里提到把mlp融合到attention里实验62B模型上性能没有下降. 主要对应的是下图网络结构的并行化改造.
滑动窗口Attention
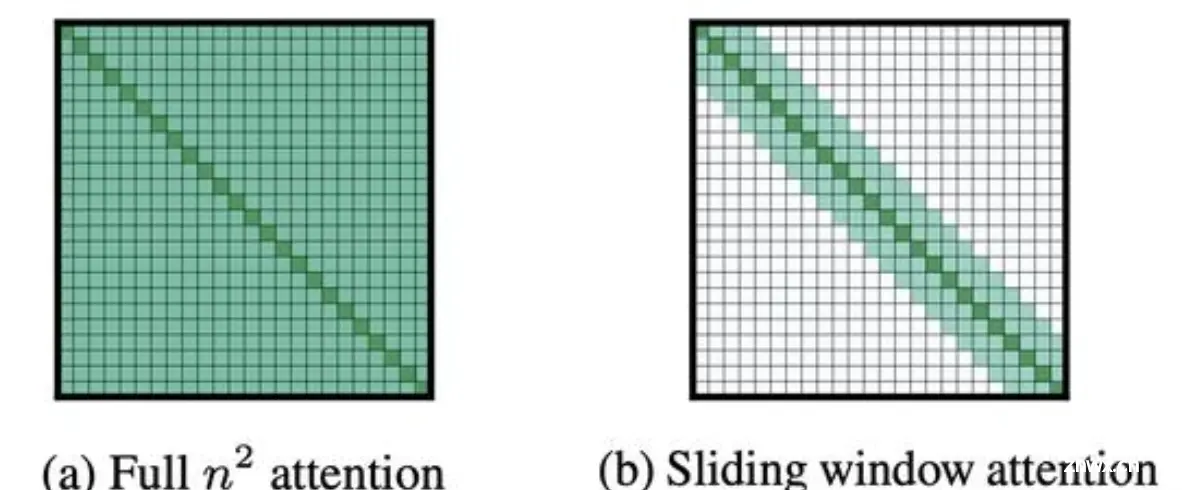
通过堆叠不同大小的窗口来捕获句子中的信息,所需要的计算量会比直接计算整个输入文本长度的计算量要小很多
滑动窗口attention的原理参考这个文章的解释:因为模型都是多层叠加的,所以层级越高,attend的视野域就越广。如果w=3,那么第一层只能注意3个位置,但到第二层能注意到第一层输出的三个位置,换算到第一层的输入,就是5个位置。所以随着层级越高,理论上每个位置注意到的区域就越大,所能存储的信息就越接近全局attention时的状态
AdamW优化(LAMB):
adamW对比adam是把权重衰减项从梯度的计算中拿出来直接加在了最后的权重更新步骤上, 为了把权重衰减和梯度计算解耦(如果加到梯度计算里会影响到动量的滑动平均), 从而提升优化效果.

这里做的优化是新增了一个 \(\phi\)截断函数, 主要目的是为了防止batch_size太大的时候导致优化过程中动量出现极端值影响bp. 这个方法论文里说可以把batch_size增大4倍从而加速训练.
\[W_t\leftarrow W_{t-1}-\alpha \cdot\phi(\frac{||W_{t-1}||}{||r_t+\lambda W_{t-1}||})(r_t+\lambda W_{t-1})
\]
3D并行优化
张量并行优化
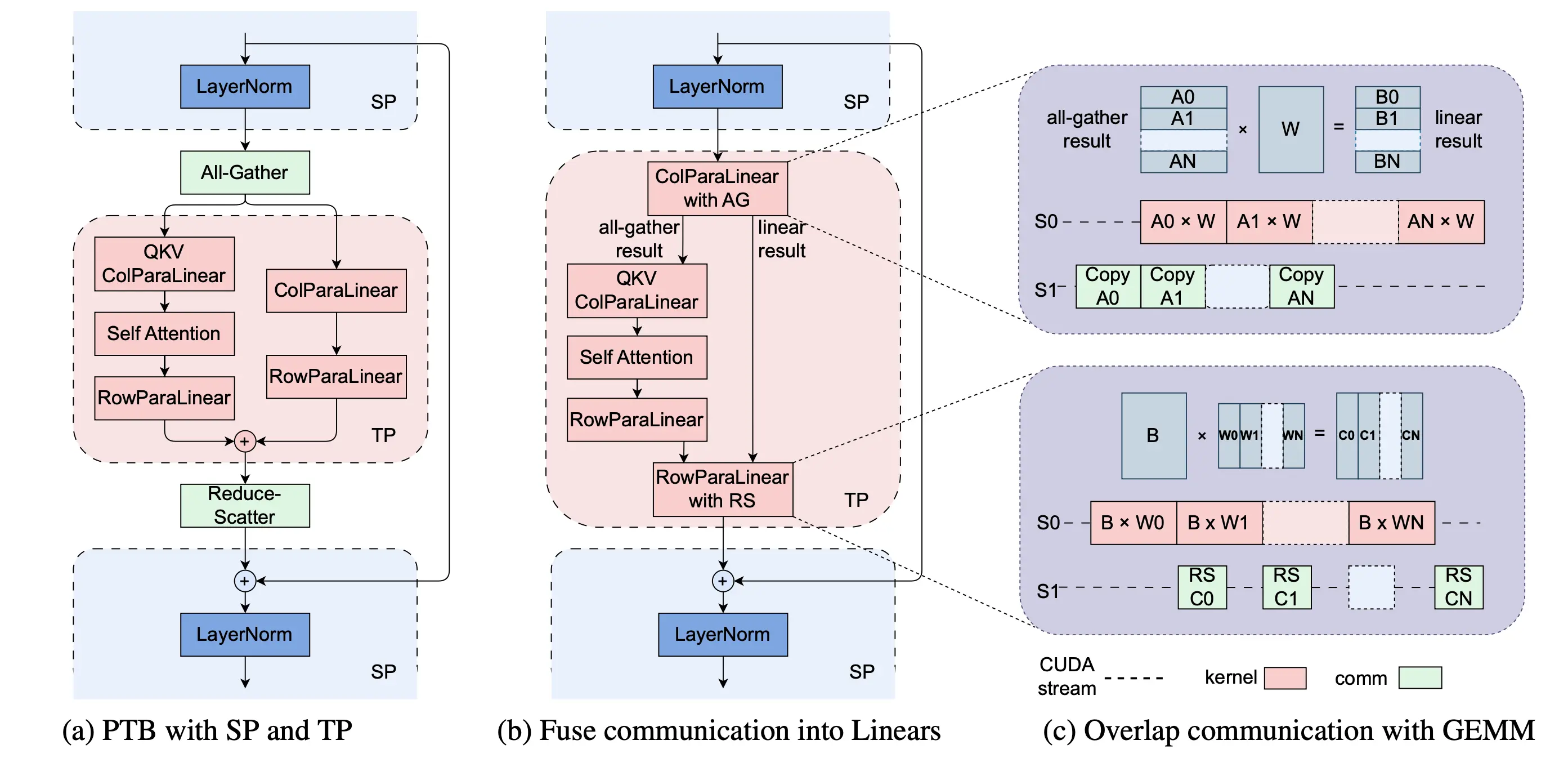
序列并行(SP)主要有2个目的: 平摊LayerNorm和Dropout的计算开销, 而且Activation占用显存也很多, 能够平摊显存消耗.
[!NOTE]
这里有个疑问: LayerNorm不是要算全局均值和方差么..这个拆分后是只算该设备内部的均值还是说需要进行额外的allReduce?
AllGather优化
序列并行(SP)后, 在进行张量并行(TP)前需要在fp的时候需要先通过gather把之前层的切片从其他节点copy汇聚过来. 如果等gather完成再跑mlp和attention就会让gpu在通信这段时间空置等待, 这里可以优化成每通信完成一个切片后, 进行这个切片的MLP列切分计算, 同时直接把gather结果送给attention并行计算, 最后再把切片计算结果concat到一起. 比如在copy完A0后, A0的前向计算就和A1的通信并行起来了, 这样就能尽量的隐藏通信
另外对矩阵做切片后再进行矩阵乘法, 计算效率要也比2个超大的矩阵乘法要高.
Reduce-Scatter优化
这块是需要把汇聚计算完成的tensor在重新进行切分发送到序列并行的节点里, 这里是把MLP的第二次行切分和attention结果加和给merge到了一起, 完成一个切片的计算后就发送出去, 同步进行下一个切片的计算使计算和通信异步进行.
流水线优化
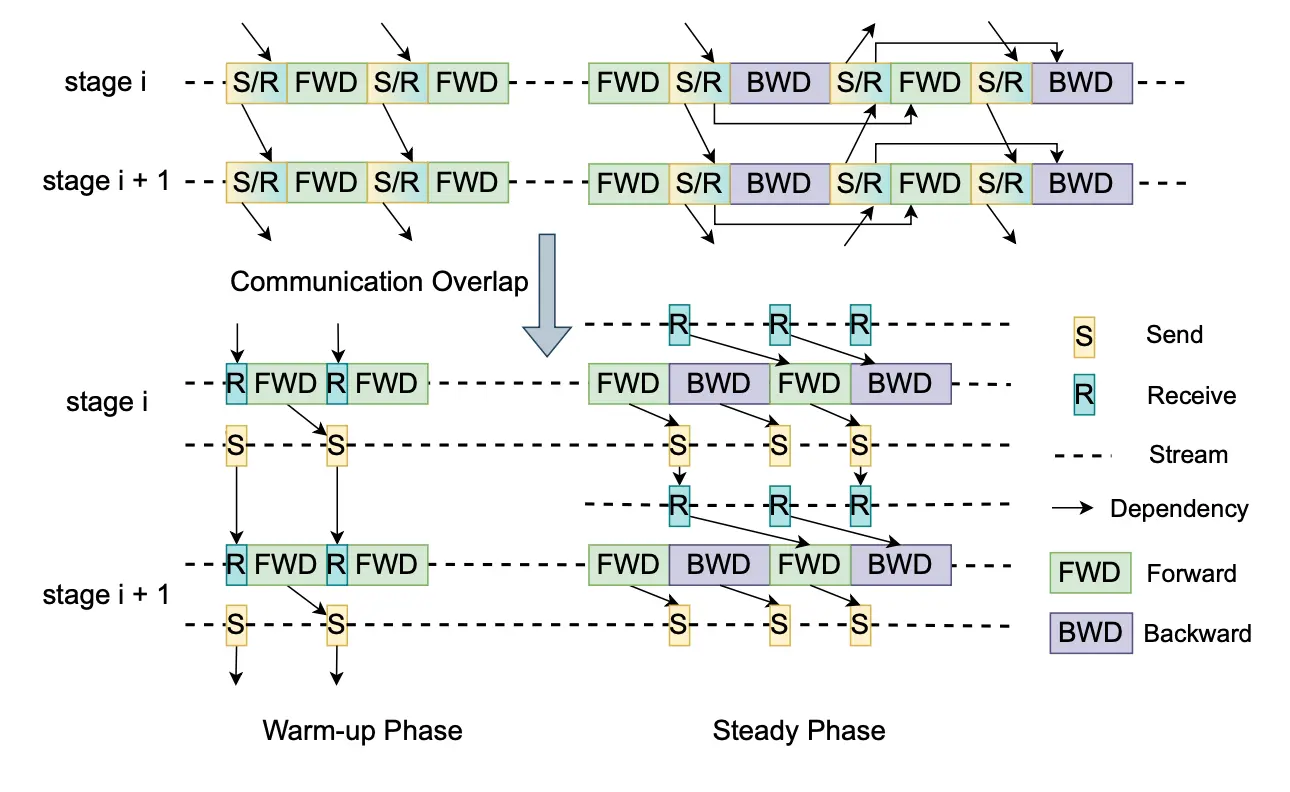
回顾一下交错式1F1B, 每个节点fp前需要等recv之前layer的结果, 在当前层fp完后, 通过allGather send出去计算完成的数据, 在bp的时候需要通过Reduce-scatter发送出去计算完的grad.
在warm-up/cool-down过程里, 都是必须等通信完成才能进行计算的. 为了缩短等待时间megascale把allGather的recv/send拆分开, recv优先级高于send, recv后就能直接开始计算, 不需要等send的长尾. 从而缩短等待时间.
在稳定状态的时候应该和megatron一样, 通信都会和计算异步. 实际情况里通信一般都会被隐藏掉(这里我没看懂为啥上面画的对比图是个纯串行的流程)
数据加载优化
这章的主要思想工作中经常用到就不细看了, 主要有2部分:
- 在bp完同步梯度的时候, 所有前向相关的数据就没用了, 就可以直接释放回池预加载下一轮fp需要的embed
- 避免单机内多张卡重复读相同的冗余数据(这里可能指的是embed集合么?), 先在内存里去好重再copy到显存
网络通信优化
TODO待补充..网络这块基本都忘完了.
集群容错
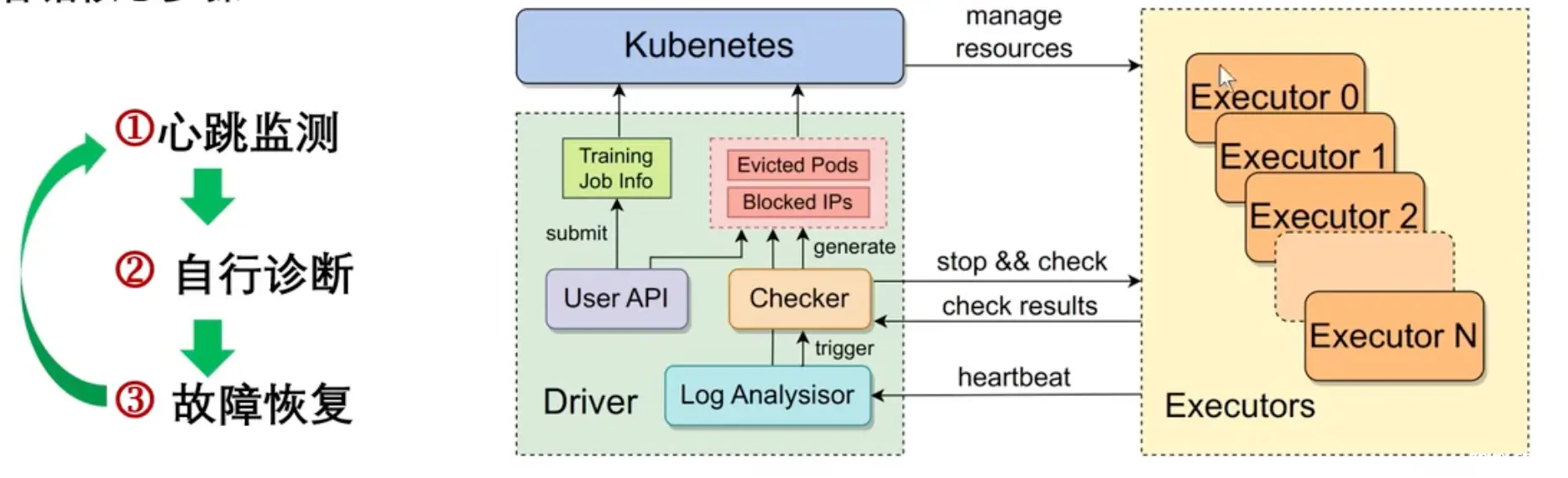
错误检测
主要思想和flux-cpu有很多相似点, 主要有以下几个点
- 每个worker定期上报心跳给中心节点, 确保当前状态正常
- 状态异常时的自动化诊断(NCCL allToAll, allReduce. 同主机RDMA网卡间的连接和带宽, 网卡到GPU/MEM的连接和带宽), 完成诊断后上报给中心节点.
- 中心节点向k8s申请失败节点的拉黑和重分配替换
状态恢复
- checkpoint保存: 这个看着实现方法和async_patch是一样的, 先把参数copy到内存, 模型继续训练. 同步再起一个异步线程用来把内存里的参数写到hdfs. 这样就可以把非常耗时的hdfs写入给隐藏掉.
- checkpoint读取: 主要优化手段是在同一数据并行组里的卡, 只选一个GPU对应的训练线程读hdfs后写内存, 然后通过broadcast给这个数据并行组里的其他卡. 可以降低hdfs的读取压力.
LLM的状态恢复感觉还挺复杂的, 如果有一个节点挂了在重分配后是所有节点全部回滚到上一个checkpoint还是有更快的方法..pipeline并行应该是在根据节点rank在启动的时候就分好了层, 节点重入后要替换原来的rank_id.
状态监控
基于cuda_event的timeline可视化, 算是老熟人了. 这里的难点感觉在于超多卡的实时日志收集, 根据DP来画出卡和卡的数据流依赖关系
参考:
megascale: https://arxiv.org/abs/2402.15627
Palm(并行attention): https://public.agent-matrix.com/publish/shared/Paper/Palm.pdf
滑动窗口注意力解释: https://zhuanlan.zhihu.com/p/223430086
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。