LLM并行训练7-混合并行总结
cnblogs 2024-07-30 08:13:00 阅读 88
LLM并行训练-总结: 如何调整混合并行策略和nvidia训练GPT3的分析
概述
根据前面的系列文章, 对预训练大模型里用到的主要并行加速技术做了一系列拆分. 但是在实际的训练里往往是多种并行混合训练. 我们要怎么配置这些并行策略才能让训练框架尽可能的减少通信瓶颈, 提升GPU计算利用率呢? 这里的变量太多了, 以最简单的3D并行为例:
- <li>硬件层面有: 单台机器的卡数/卡间带宽/网卡带宽, 机器间通信时的网络拓扑构建.
- 并行策略上有: 张量并行数/流水线并行数/数据并行数
- 训练超参有: batch_size / AttnHeads / seq_len / hidden_size
如果靠脑补来调整这些参数, 会存在一个非常巨大的搜索空间, 很难找到最优于计算效率的方法, 所以需要先通过理论分析确定各个参数的大致范围. 最后再通过有限次尝试找到较优的方案. 本章参考nvidia的调参实践GTC演讲, 结合GPT3训练例子对如何调整并行策略进行总结
并行方法适用场景分析
后文的标记备注:
- \((p, t, d)\) : 3D 并行维度. \(p\) 代表流水并行数, \(t\) 代表张量并行数, \(d\) 代表数据并行数
- \(n\): 总共的 GPU 数量. 要求 \(p\cdot t \cdot d = n\).
- \(B\): Global batch size.
- \(b\): Microbatch size.
- \(b^{'}\): 一个流水线要处理的 batch size 大小, 等于 \(B/d\).
- \(m = \frac{1}{b} \cdot \frac{B}{d}\): 一个 batch 在每个 pipeline 的 microbatch 的数量.
- \(s\): seq_len.
- \(h\): hidden_size = emb_size * attention_head_size
- \(a\): attention_head_size
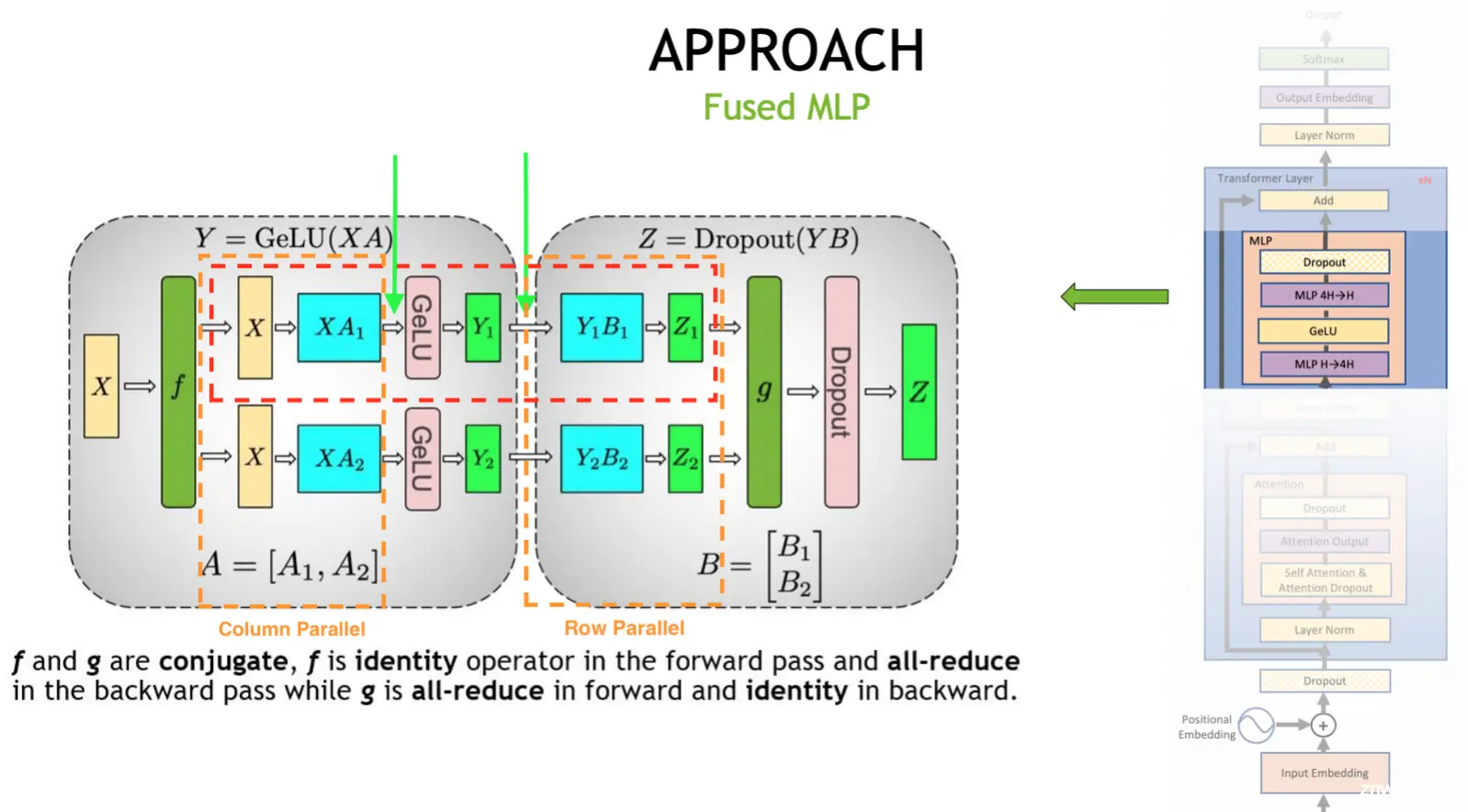
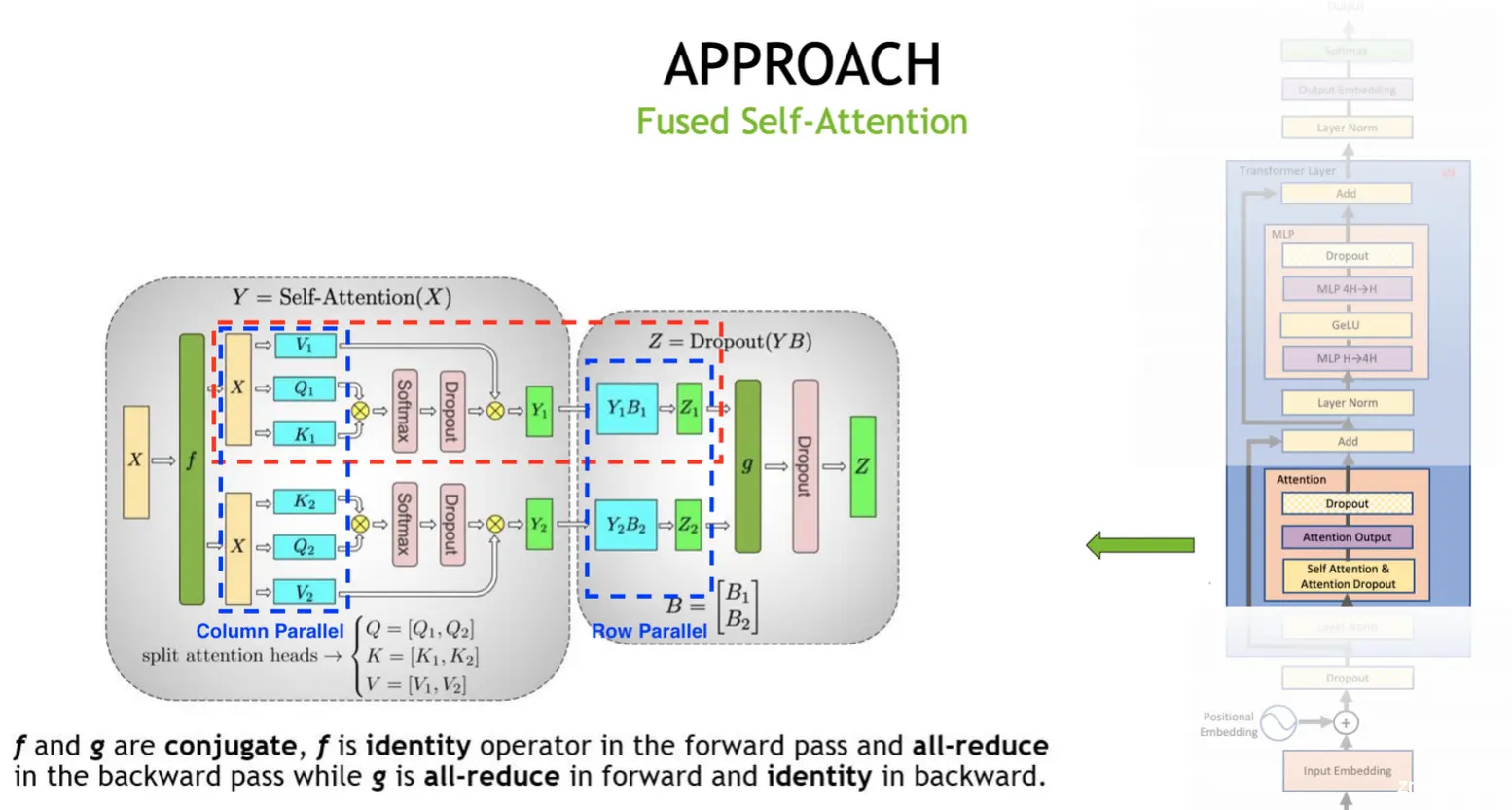
张量并行(TP)
TP开销
| 模式 | Normal | ColParallel | ratio |
|---|---|---|---|
| flops | (n次乘法 + n次加法)* n^2 = 2n^3 | 2n^3/t | 1/t |
| Bandwidth | (n^2)【n*n 矩阵的读或写】 * 2(fp16)) * 3(读 X、读A,写 Y) = 6n^2 | 2n^2 + 4n^2/t(A,Y切分) | (1+2/t)/3 |
| Intensity(flops/bandwidth) | n/3 | n/(2+p) | 3/(2+t) |
当并行度\(t\)增长的时候, 可以看到intensity也处于一个增长的趋势. 需要权衡通信和计算成本的平衡, 由于TP需要在结束时进行一次激活的AllReduce, 在多机通信上会导致较高的通信成本. 所以TP一般只考虑在单机卡间通信时使用. TP在LLM里主要有两个使用场景:
- MLP先列再行, 这块前后一般会和SP结合进行将AllReduce拆分为allGather和reduceScatter

- <li>attention处多头切分并行 每个头之间的计算各自独立, 所以可以进行切分计算.
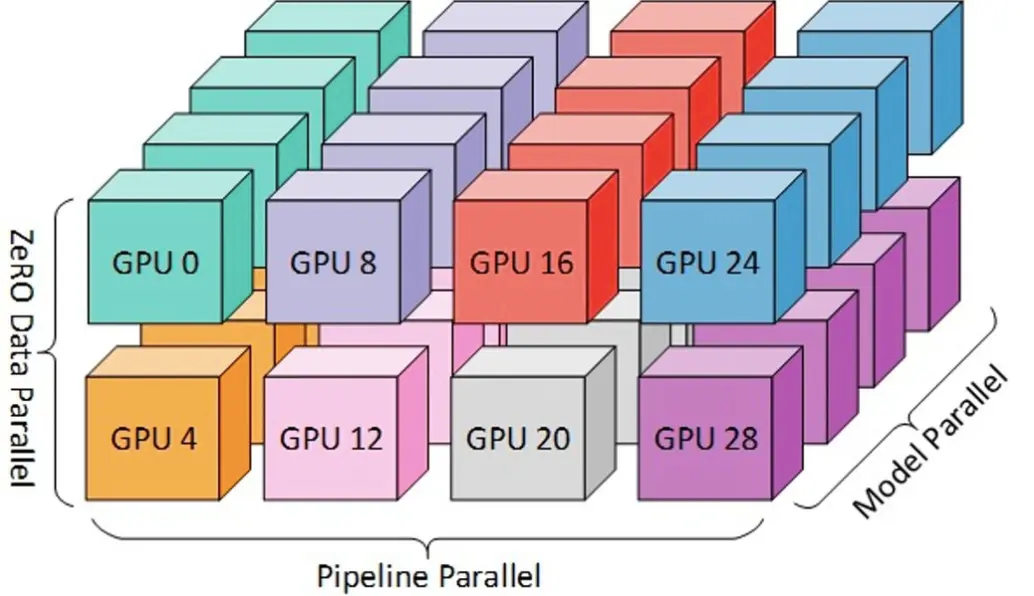
流水线并行(PP)
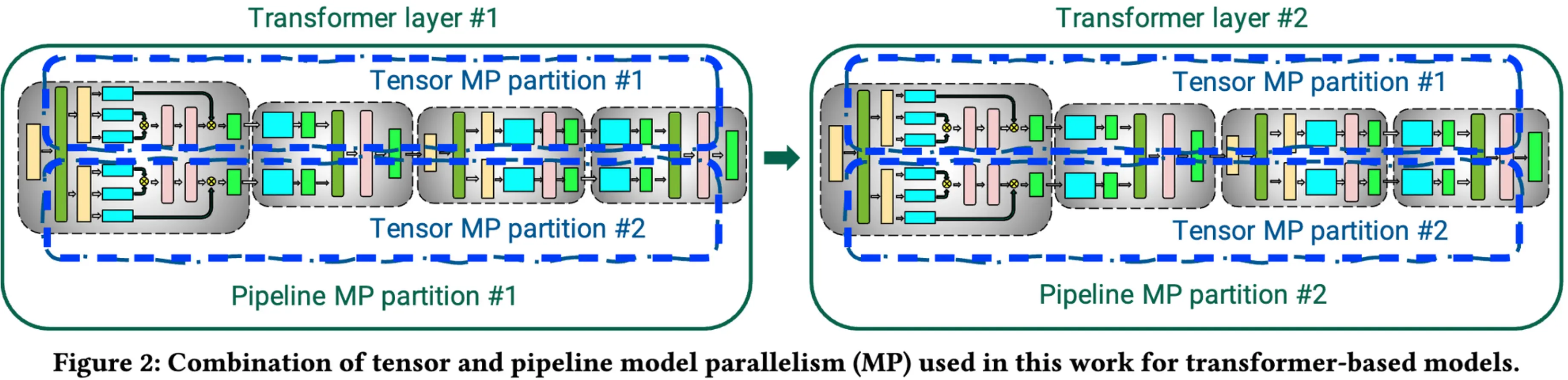
流水线主要是将一个batch的数据切分为多个mirco-batch, 在micro-batch之间做异步并行. 因为通信内容只包含切分stage的输出, 而且是点对点通信, 不需要多点集合通信. 通信数据量小, 因此比较适合在多台机器间通信的场景. LLM里一般把一个transformLayer作为一个stage, 在多个stage之间构建pipeline, 如下图:
混合并行
当网络结构确定后, 一般TP和PP就能估算到比较合理的区间, 最后根据显存容量的计算来估计DP需设置的值.
TP与PP的策略分析
数据并行度\(d=1\)时, \(p * t = n\), 会有以下计算公式:
- <li>
单机单次allReduce通信量: \(2bsh(\frac{t-1}{t})\), (layer激活为\(bsh\), allReduce通信量为数据量2倍)
流水线并行时单个micro-batch机器间通信量为: \(C_{inter} = 2bsh\) (fp/bp各一次)
流水线bubble_time: \(\frac{(p-1)}{m}=\frac{n/t-1}{m}\), 提高TP并行度时会减少气泡占比, 但会增大单机内部的通信量, tp内部一个microbatch需要4个allReduce(fp/bp各两个)
设一个pipeline内有\(l^{stage}\)个transformLayer, 则在1F1B非交错调度的情况下单个stage单机内部通信量为:
\[C_{inra} = l^{stage}\cdot4\cdot2bsh(\frac{t-1}{t}) = l^{stage}\cdot4\cdot2bsh(1-\frac{1}{t})
\]
所以机器间和机器内的通信量关系为:
\[C_{intra}= l^{stage}\cdot4\cdot(1-\frac{1}{t}) \cdot C_{inter}
\]
因为机器间通信速率远小(IB 200GB/s)于卡间通信(NVLink 600GB/s), 所以我们如果希望优化吞吐, 那么应该尽量降低机器间通信比率.
[!TIP]
也就是在不会导致TP产生机器间通信的前提下让t尽可能的大. 如果这样还放不下模型,再使用流水线并行来切分模型。
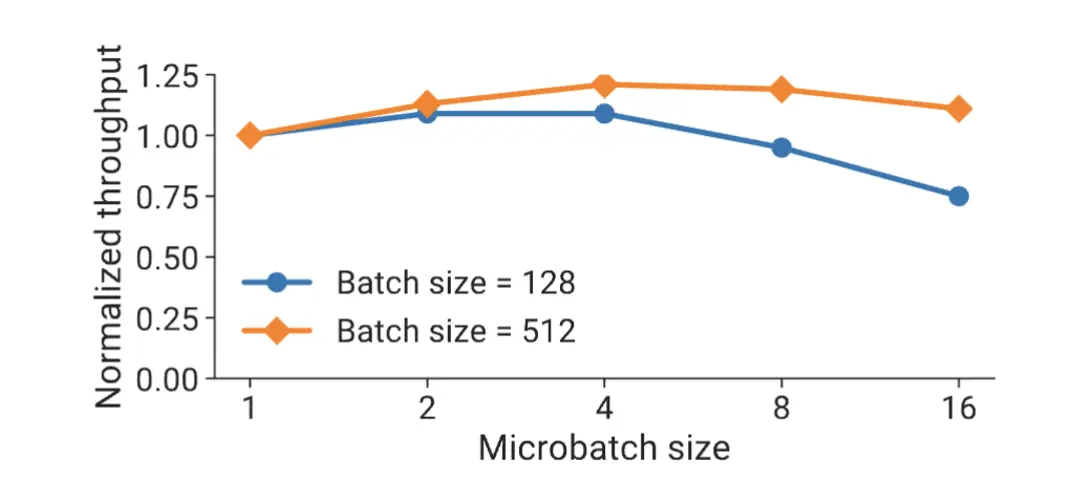
micro-batch设置
在固定其他参数的前提下. 只调整micro_batch数, 单个batch的执行时间: \((\frac{b^{'}}{b}+(p-1))\cdot(t_{f} + t_{b})\) , 如果增大b, 单个pipeline内数量减少但执行时间会变长, 计算耗时和b是非线性的关系. 而且调整micro-batch后, 通信耗时也会变化, 所以mirco-batch调整需要实验尝试才能找到最优解. megatron在论文中尝试gpt训练的mirco-batch设置4比较合适

DP的策略分析
便于分析设\(t=1, d * p = n\), 在这种情况下的流水线bubble占比为 \(\frac{p-1}{m} = \frac{n/d - 1}{B/b/d} = \frac{b(n - d)}{B}\)
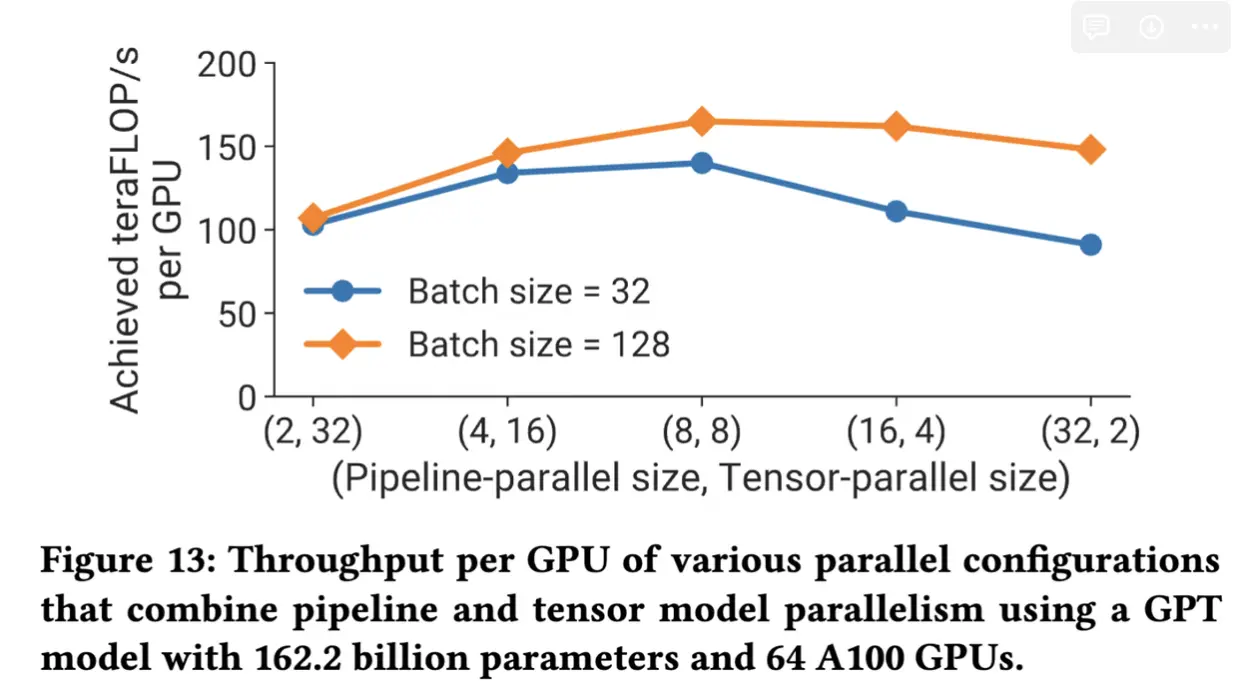
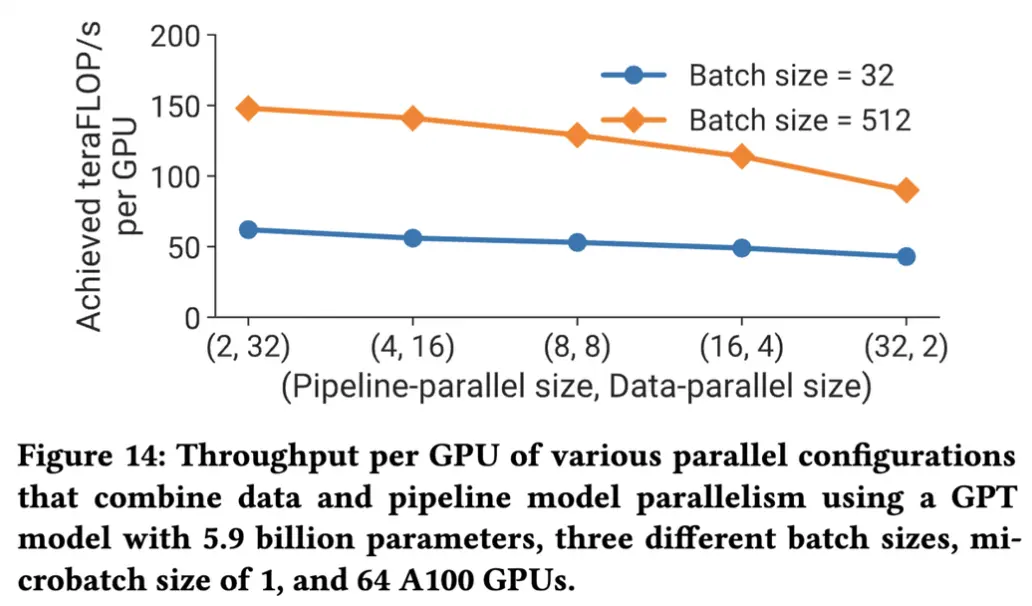
PP和DP关系: 对于d单调递减, 也从下图可以看到, 当流水线并行的数量越小, 数据并行度越大的时候训练速度越快. 所以我们可以在PP满足显存占用的情况下尽可能的提升DP并行度.
和Batch_size关系: bubble和B成反比, B越大吞吐越高. 但是过大的B和数据并行度会导致模型不收敛. 需要在不影响效果的前提下调整B
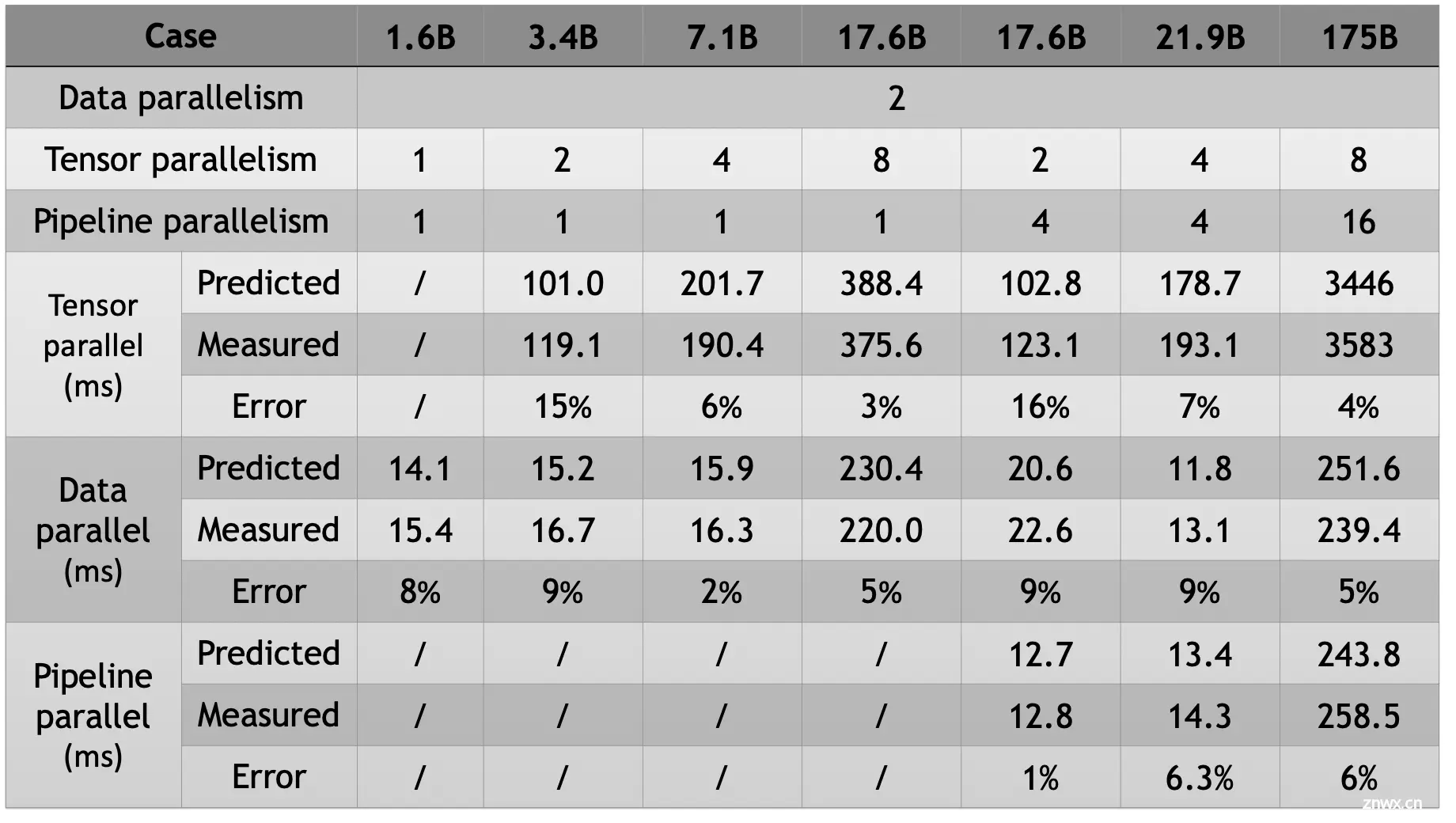
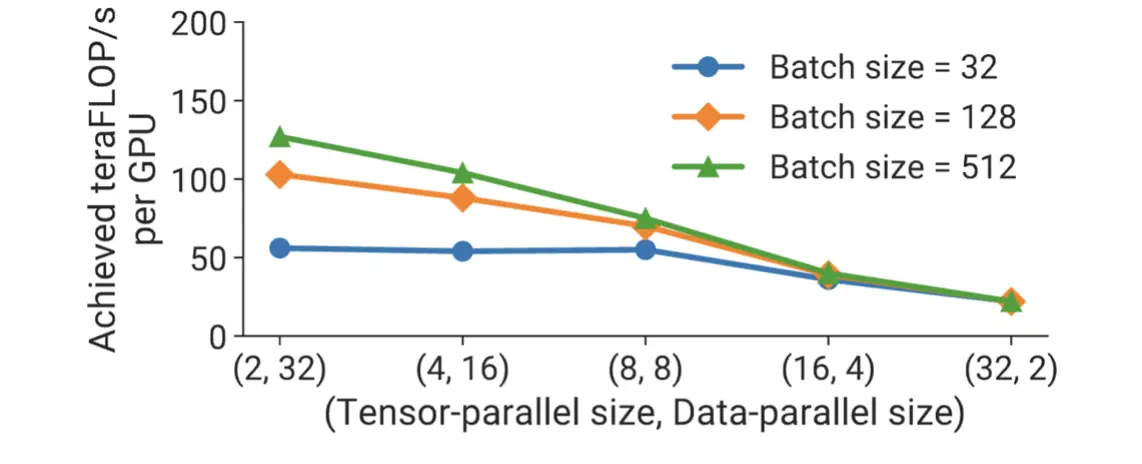
DP和TP关系: 在TP内每个batch 需要进行4次allReduce, 而DP只需要对梯度做一次allReduce, 另外在TP的时候如果W比较小也会影响矩阵乘法计算效率. 下图可以看到TP并行度越小, DP并行度越大吞吐越高. 调整策略是只要TP满足显存需求, 就尽可能的增大DP来提升吞吐.
[!TIP]
如果模型比较大,需要先组合模型并行和流水并行,\(M=t \cdot p\) 的组合用来满足模型和模型相关的数据的显存需求,但是要让 M 尽量小。之后使用数据并行来扩展训练规模(扩大数据并行度、扩大 Global batch size)
GPT-3例子分析
以如下的超参GPT-3训练为例:
显存分析
ModelMemory
单卡存储模型参数主要包含4个部分(由于流水线并行, 单卡一般只存储1-2个transformLayer): attention参数 / FC参数 / token_emb / Positional encoding
以\(N_p\)代表一份全量参数, 则单卡上包含的参数量如下:
\[\frac{N_p}{n} = h * \frac{h}{t}*3(QKV参数)+h*\frac{h}{t}(multihead拼接后经过的fc) + h*\frac{h}{t}*4*2(fc1+fc2参数) \\
+ \frac{v}{t} *h(token) + s*\frac{h}{t}(positional) \approx 1.73B\approx \frac{175B}{p*t} (单卡上单份DP参数量)
\]
在混合精度训练中, 总共的数据量包扩1份fp16的w和grad, 1份fp32的optimizer_state(\(w+grad+momentum+variance\))
\[N_{storage} = 2Bytes * N_p + 2Bytes * N_p + (4+4+4+4)Bytes*N_p = 20N_P = 27.4GB
\]
Activation
在nvidia分享里, 看着activation只存了过token前的emb激活和进fc前的激活, 剩下的全部都是bp时重计算的..因为也没使用SP, 这里每张卡的激活都存了TP并行数的冗余数据
\[M_{act}^{emb} = 2𝐵𝑦𝑡𝑒𝑠 * 𝑏 * 𝑠 * \frac{v}{t}
\]
\[M_{transformer}^{emb} = 2𝐵𝑦𝑡𝑒𝑠 * 𝑏 * 𝑠 * h * \frac{n}{p}
\]
Extra
包含在fp时所需分配的临时显存 & 通信需要的临时显存 & allocator导致的显存碎片
这块在上一章-激活优化里其实已经分析过, 这里忽略不表
\[\begin{gathered}
M_{\text {extra }}^{\text {embed }}=4 \text { Bytes } \times b \times s \times \frac{v}{t}=0.05 G B \\
M_{\text {extra }}^{\text {allreduce }}=(2+4) \text { Bytes } \times N_p \\
M_{\text {extra }}^{q k v}=2 \text { Bytes } \times\left(s \times \frac{h}{t} \times b \times 3+b \times s \times s \times \frac{a h}{t} \times 2\right) \\
M_{\text {extra }}^{m l p}=2 \text { Bytes } \times\left(b \times s \times \frac{4 h}{t}+b \times s \times \frac{4 h}{t}+b \times s \times \frac{h}{t}\right)
\end{gathered}
\]
显存峰值
显存使用可能出现峰值的地方有三个地方:
- <li>fp完成时, 这里主要变化量是存在大量的extra: \(M_1=M_{p a r a}+M_{o p t}+p \times M_{a c t}^{\text {transformer }}+M_{a c t}^{e m b e d}+M_{e x t r a}^{e m b e d}\) , 显存消耗32.2GB
- bp完成时, 这里因为把大量的act释放后重计算,相对消耗不多: \(M_2 =M_{p a r a}+M_{o p t}+p \times M_{a c t}^{t r a n s f o r m e r}+M_{g r a d}-M_{a c t}^{t r a n s f o r m e r} +M_{e x t r a}^{q k v}+M_{e x t r a}^{m l p}\), 显存消耗25.0GB
- 更新optimizer_state时, 这是由于很多临时显存用于梯度allReduce, 所以出现显存峰值: \(M_3= M_{p a r a}+M_{o p t}+p \times M_{a c t}^{\text {transformer }}+M_{g r a d}-M_{a c t}^{\text {transformer }} +M_{\text {extra }}^{\text {allreduce }}\), 显存消耗34.3GB
通信分析
BW: bus bandwidth(单次通信的数据长度)
TP: 每个mlp和attention 在fp /bp / bp时的fp重计算 三个阶段各需要一次allReduce
\[T_{tp} = \frac{2bsh}{BW} * \frac{2(t-1)}{t}[allReduce通信次数*单次通信长度]*(3+3)[mlp和attention\ allReduce次数] *\frac{n}{p}[layer数] * \frac{B}{bd}[minibatch数] \\
\]
DP: 在optimizer更新时需要对各个数据副本进行一次allReduce
\[T_{dp} = \frac{N_p}{BW} * \frac{2(d-1)}{d}
\]
PP(1F1B交错式): 在机器间通信的点对点方式和在机器内通信的allGather(TODO: 这里没太看懂)
\[T_{p p}=\underbrace{\left(2 \frac{B}{b d}+2(p-1)\right) \times \frac{\frac{\text { message size }}{t}}{B W_{\text {inter }}}}_{\text {P2P }}+\underbrace{\left(\frac{B}{b d}+(p-1)\right) \times \frac{\text { message size }}{B W_{\text {intra }}} \times \frac{t-1}{t}}_{\text {Allgather }}
\]
从实际实验上也能看到TP占了主要的通信成本.
总结
3d并行的调优经验:
- <li>如果模型比较大,需要先组合模型并行和流水并行,\(M=t \cdot p\) 的组合用来满足模型和模型相关的数据的显存需求,但是要让 M 尽量小。之后使用数据并行来扩展训练规模(扩大数据并行度、扩大 Global batch size)
- 在不会导致TP产生机器间通信的前提下让t尽可能的大. 如果这样还放不下模型,再使用流水线并行来切分模型。
参考
megatron-LM复杂度分析论文: https://arxiv.org/pdf/2104.04473
nvidia GTC演讲: https://developer.nvidia.com/gtc/2020/video/s21496
[nvidia GTC GPT-3调参分析](链接: https://pan.baidu.com/s/190TFeOI9SALaaH9CVMWH7Q?pwd=chux 提取码: chux)
megatron分析博客: https://www.cnblogs.com/rossiXYZ/p/15876714.html
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。