AI大模型落地应用场景:LLM训练性能基准测试
大飞攻城狮 2024-08-28 16:01:03 阅读 93
随着 ChatGPT 的现象级走红,引领了AI大模型时代的变革,从而导致 AI 算力日益紧缺。与此同时,中美贸易战以及美国对华进行AI芯片相关的制裁导致 AI 算力的国产化适配势在必行。之前也分享过一些国产 AI 芯片、使用国产 AI 框架 Mindformers 基于昇腾910训练大模型,使用 MindIE 进行大模型服务化等。
训练性能的定义
训练性能在本文指机器(GPU、NPU或其他平台)在指定模型和输入数据的背景下,完成一次端到端训练所需要花费的时间,考虑到不同模型的训练数据量和训练轮次(epoch)差异,此处定义的性能是在完成一个batch训练所需花费的时间。而端到端通常是指完成一个AI模型单步训练的过程。也就是说,本文所讨论的性能的衡量和性能的优化,都是站在模型角度上。
对于一个batch而言,训练所花费的时间主要由以下部分构成:
单batch总时间 = 数据加载时间 + 模型前反向时间 + 优化器时间 + 模型后处理时间 + 通信时间 + 调度时间
数据加载时间:指的是模型在加载自身所需要的数据(如图片、视频和文本等)的时间,包括将数据从硬件存储设备读取到CPU(Central Processing Unit)中、CPU中数据的预处理(编解码等操作)、CPU数据放到Device(GPU/NPU…)上的时间。特别地,对于一些需要切分在若干张卡上的模型,数据加载还包括从数据加载卡广播到其他卡上的时间。模型前反向时间:指深度学习模型的前向过程和反向过程,即Forward和Backward过程,包含前向的数据计算和反向的数据微分求导。优化器时间:通常指的是模型参数更新时间。模型后处理时间:一般指的是优化器更新后的时间,包括数据的后处理或者一些必要的同步操作,通常取决于模型特有操作。通信时间:概念比较宽泛,一般将单节点内卡与卡和多节点间的通信行为归为通信时间,由于一些AI框架(如:PyTorch)的特殊机制或者优化,通信和计算通常可以并行起来(即通信计算重叠),因此我们一般考虑的是未被计算掩盖的通信时间。调度时间:指的是模型从CPU的指令到调用NPU侧的核(Kernel)所需要的时间。
训练性能指标
在模型训练过程中,通常关注的性能指标如下:
| 指标名称 | 单位 | 指标含义 |
|---|---|---|
| 吞吐率 | samples/s、tokens/s | 单位时间(例如1s)内处理的Token数/训练样本数 |
| 单步时间 | s | 执行一个step所花费的时间 |
| 线性度、加速比 | values | 单卡训练扩展到多卡,单机拓展到集群的效率度量指标 |
| 内存占用 | 百分比 | - |
| 带宽占比 | 百分比 | - |
| 训练效率 | tokens/day | - |
| 浮点运算 | TFLOPS | 每秒浮点运算次数,是计算设备的计算性能指标 |
| 模型算力利用率(Model FLOPs Utilization, MFU) | 百分比 | 模型一次前反向计算消耗的矩阵算力与机器算力的比值 |
| 硬件算力利用率(Hardware FLOPs Utilization, HFU) | 百分比 | 考虑重计算后,模型一次前反向计算消耗的矩阵算力与机器算力的比值 |
在计算性能指标时,通常的优先级排序为:吞吐率 > 单步迭代时间 > 线性度 > 内存占用 > 带宽占用 > 训练效率 > 浮点计算次数每秒 > 算力利用率。
FLOPS 与 FLOPs的不同之处
概念不同:FLOPS 表示每秒浮点运算次数,是计算设备的计算性能指标;而 FLOPs 表示模型中的浮点运算操作总数,是模型计算复杂度的指标。应用不同:FLOPS 用于评估计算设备的处理能力和性能;FLOPs 用于衡量模型的计算复杂度和计算量。单位不同:FLOPS 的单位是每秒浮点运算次数(如 TFLOPS、GFLOPS);FLOPs 的单位是浮点运算操作总数(如 MFLOPs、GFLOPs)。
吞吐量
与涉及单个样本数据处理的延迟(Latency)不同,为了实现最大吞吐率(Throughput),我们希望在集群训练的过程中有效并行处理尽可能多的样本数据。这种有效的并行性依赖于数据、模型和设备规模。因此,为了正确测量最大吞吐率,可以执行以下两个步骤:
估计允许最大并行度的最佳训练样本数据批量大小,即Batch Size;在AI训练集群中,给定这个最佳Batch Size,测量神经网络模型在一个step每1秒钟内可以处理的训练样本数据。
要找到最佳Batch Size值,一个好的经验法则是达到AI加速卡(GPU/NPU…)对给定数据类型的内存限制,即Batch Size接近占满内存。这取决于硬件类型、神经网络的参数大小以及输入数据的大小等。
要找到这个最大的Batch Size,最快方法是执行二分搜索。当时间不重要时,简单的顺序搜索就足够了。不过在大模型训练的过程中,Batch Size的值会影响到重计算、Pipeline并行、Tensor并行等不同并行模式的配比,还有micro Batch Size的数据配比。因此,默认Batch Size为16的倍数比较合理。
线性度
线性度,又名加速比(speed up),指单机拓展到集群的效率度量指标。
单机内部线性度=单机多卡总吞吐量单卡吞吐量∗卡数单机内部线性度 = \frac{单机多卡总吞吐量}{单卡吞吐量*卡数}单机内部线性度=单卡吞吐量∗卡数单机多卡总吞吐量
单机多卡总吞吐率,在NLP大语言模型中以tokens/s为基本单位,在CV大模型中以samples/s为基本单位。
集群线性度=多机多卡总吞吐量单卡吞吐量∗卡数∗集群机器数据集群线性度 = \frac{多机多卡总吞吐量}{单卡吞吐量 * 卡数 * 集群机器数据}集群线性度=单卡吞吐量∗卡数∗集群机器数据多机多卡总吞吐量
即:
集群线性度≈多机多卡总吞吐量单机总吞吐量∗集群机器数据集群线性度 \approx \frac{多机多卡总吞吐量}{单机总吞吐量 * 集群机器数据}集群线性度≈单机总吞吐量∗集群机器数据多机多卡总吞吐量
线性度的取值范围为0~1,数值越接近于1,其性能指标越好。
如果多卡或多机的加速比接近高线性度(即线性度接近于1),说明在扩展时通信不是瓶颈,则可以通过改变或者增加通信带宽提升性能,对于整体AI大模型训练的性能提升在通信上问题就会比较小。
当线性度不高(例如:小于0.8,具体视服务器集群的规模而定)时,排除数据IO和CPU的本身因素影响后,可以判断此时分布式通信存在瓶颈。
算力利用率
算力利用率指负载在集群上每秒消耗的实际算力占集群标称算力的比例。
标称算力是指硬件或设备在正常工作状态下的理论计算能力,通常以单位时间内能够完成的浮点运算次数(FLOPS)或整数运算次数(IOPS)来衡量。
模型算力利用率(Model FLOPs Utilization, MFU) 是指模型一次前反向计算消耗的矩阵算力与机器算力的比值硬件算力利用率(Hardware FLOPs Utilization, HFU) 是指考虑重计算后,模型一次前反向计算消耗的矩阵算力与机器算力的比值
MFU
对一个典型的GPT类大模型,其主要的浮点算力都由Transformer层和logit层中的矩阵乘(GEMMs)贡献。比如千亿盘古大模型,99%以上的浮点算力都由fp16的矩阵乘贡献。通常只考虑矩阵运算(Matrix Multiplications,GEMMs)。
对于一个GPT类Transformer大模型,
transformer 模型的层数为 l隐藏层维度为 h注意力头数为 a词表大小为 V批次大小为 b序列长度为 sGPU单卡的峰值算力 F训练使用GPU的卡数 N训练一次迭代时间 T
因此,每次迭代的浮点预算数为
model FLOPs per iteration = 72blsh2(1+s6h+V12hl)72blsh^2(1 + \frac{s}{6h} + \frac{V}{12hl})72blsh2(1+6hs+12hlV)
MLP 中将tensor维度从h提升到4h 再降低到h,浮点计算数为 16bsh216bsh^216bsh2
第一个线性层,矩阵乘法的输入和输出形状为 [𝑏,𝑠,ℎ]×[ℎ,4ℎ]→[𝑏,𝑠,4ℎ] 。计算量为 8𝑏𝑠h28𝑏𝑠ℎ^28bsh2 。第二个线性层,矩阵乘法的输入和输出形状为 [𝑏,𝑠,4ℎ]×[4ℎ,ℎ]→[𝑏,𝑠,ℎ] 。计算量为 8𝑏𝑠h28𝑏𝑠ℎ^28bsh2。 Q,K,V的变化([𝑏,𝑠,ℎ]×[ℎ,ℎ]→[𝑏,𝑠,ℎ]),浮点计算数为 6bsh26bsh^26bsh2Attention矩阵运算,浮点计算数为 2bs2h+2bs2h2bs^2h + 2bs^2h2bs2h+2bs2hAttention后到线性层的运算([𝑏,𝑠,ℎ]×[ℎ,ℎ]→[𝑏,𝑠,ℎ]),浮点计算数为2bsh22bsh^22bsh2logits运算([b,s,h]x[h,V]->[b,s,V]),浮点计算数为2bshV2bshV2bshV
整个语言模型的每个step的前向传播 FLOPs: l(24bsh2+4bs2h)+2bshVl(24bsh2+4bs2h)+2bshVl(24bsh2+4bs2h)+2bshV
考虑反向计算,反向传播的计算量大约是前向传播的2倍;因此,每个step总FLOPs = 3(l(24bsh2+4bs2h)+2bshV)3(l(24bsh2+4bs2h)+2bshV)3(l(24bsh2+4bs2h)+2bshV) = 72blsh2+12bls2h+6bshV72blsh^2 + 12bls^2h + 6bshV72blsh2+12bls2h+6bshV = 72bslh2(1+s6h+V12lh) 72bslh^2(1+ \frac{s}{6h} + \frac{V}{12lh})72bslh2(1+6hs+12lhV)
第一项来自 QKVO 和 FFN 中的矩阵乘法第二项来自 attention 矩阵的计算,当s << 6h 时,可以忽略第三项来自 LM head,当V << 12lh ,可以忽略
对于 LLaMa-13B 来说,
6h = 6 * 5120 = 30720
通常序列长度 s 为 2048,所以 Attention 矩阵的计算其实占比很小(1/15),可以忽略。
12lh = 12 * 50 * 5120 = 3072000
词表大小为 32000。所以 LM head 占比也很小(0.01),也可以忽略。
MFU 计算公式:
MFU=model FLOPs per iteration(GPU单卡算力∗卡数∗一次迭代时间)MFU = \frac {model \ FLOPs \ per \ iteration} {(GPU单卡算力 * 卡数 * 一次迭代时间)}MFU=(GPU单卡算力∗卡数∗一次迭代时间)model FLOPs per iteration
即
MFU=72bslh2(1+s6h+V12lh)F∗N∗TMFU= \frac {72bslh^2(1+ \frac{s}{6h} + \frac{V}{12lh})}{F * N * T}MFU=F∗N∗T72bslh2(1+6hs+12lhV)
在模型固定的情况下,减少卡数和一次迭代时间,可以增大MFU。所以减少训练时间就是提高MFU。
HFU
使用了激活重新计算,在反向传播之前需要进行额外的前向传播,HFU的计算公式:
HFU=4l(24bsh2+4bs2h)+3∗2bshVHFU = 4l(24bsh2+4bs2h)+3 * 2bshVHFU=4l(24bsh2+4bs2h)+3∗2bshV = 96blsh2+16bls2h+6bshV96blsh^2 + 16bls^2h + 6bshV96blsh2+16bls2h+6bshV
这里由于存在不同的重计算策略,计算方式会有一些差异。
通信性能指标
针对同一通信算子在不同卡之间通信时间的波动的分析,其主要目的在于需要识别一些可能存在的通信算子内部瓶颈单元。在分析过程中,主要采用以下几个指标:
算子的执行时间以及内部等待耗时的变化和比例
该指标可以用来初步识别是否存在慢卡瓶颈,对每块卡上的wait_ratio,通过比较wait_ratio与wait_ratio_threshold(当前设置为0.2)的关系,识别是否存在慢节点。
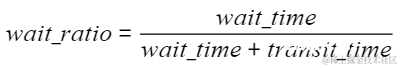
通信带宽分析
当通信算子内部不存在慢节点时,进行通信带宽分析。
主要有如下步骤:
对比该通信算子在各卡上的数据传输耗时 ,得到通信带宽最慢的rank;计算该rank上的sdma_bw和rdma_bw,并结合sdma_transit_time和rdma_transit_time给出对应平均带宽:SDMABandwidth=sdma_bwsdma_transit_time,RDMABandwidth=rdma_bwrdma_transit_timeSDMA_{Bandwidth} = \frac {sdma\_bw}{sdma\_transit\_time} , RDMA_{Bandwidth} = \frac {rdma\_bw}{rdma\_transit\_time}SDMABandwidth=sdma_transit_timesdma_bw,RDMABandwidth=rdma_transit_timerdma_bw
SDMA(System DMA, 系统直接内存访问),一种异步数据传输技术,可以在不占用CPU资源的情况下,实现数据在内存和外设之间的高速传输。RDMA(Remote DMA, 远程直接数据存取),就是为了解决网络传输中服务器端数据处理的延迟而产生的。 同时,我们会设置一个经验带宽,一般设置为最大带宽的0.8,如图所示。
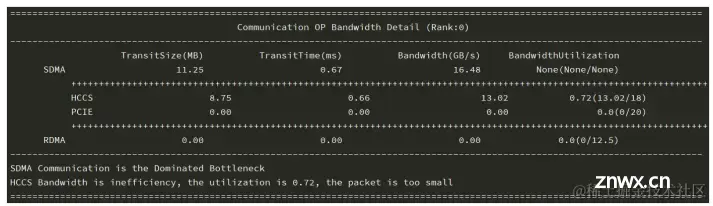
只有SDMA通信:
SDMA平均带宽接近经验带宽,表示该通信算子瓶颈是SDMA带宽;SDMA平均带宽小于经验带宽,表示该通信算子瓶颈是SDMA通信效率低。 只有RDMA通信:
RDMA平均带宽接近经验带宽,表示该通信算子瓶颈是RDMA带宽;RDMA平均带宽小于经验带宽,表示该通信算子瓶颈是RDMA通信效率低。 SDMA通信和RDMA通信:
SDMA耗时最长,表示当前通信算子主要瓶颈在于SDMA通信,瓶颈是SDMA带宽或SDMA通信效率低;RDMA耗时最长,表示当前通信算子主要瓶颈在于RDMA通信,瓶颈是RDMA带宽或RDMA通信效率低。
流水线并行效率指标
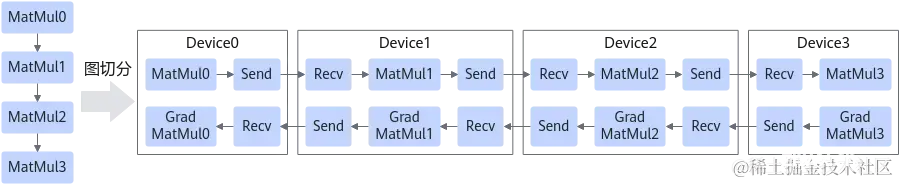
流水线并行是将神经网络中的算子切分成多个阶段(Stage),再把阶段映射到不同的设备上,使得不同设备去计算神经网络的不同部分。
流水线并行适用于模型是线性的图结构,如图所示,将4层MatMul的网络切分成4个阶段,分布到4台设备上。正向计算时,每台机器在算完本台机器上的MatMul之后将结果通过通信算子发送(Send)给下一台机器,同时,下一台机器通过通信算子接收(Receive)上一台机器的MatMul结果,同时开始计算本台机器上的MatMul;反向计算时,最后一台机器的梯度算完之后,将结果发送给上一台机器,同时,上一台机器接收最后一台机器的梯度结果,并开始计算本台机器的反向。
简单地将模型切分到多设备上并不会带来性能的提升,因为模型的线性结构,同一时刻只有一台设备在工作,而其它设备在等待,造成了资源的浪费(流水线空泡bubble)。为了提升效率,流水线并行进一步将小批次(MiniBatch)切分成更细粒度的微批次(MicroBatch),在微批次中采用流水线式的执行序,从而达到提升效率的目的,如图所示。将小批次切分成4个微批次,4个微批次在4个组上执行形成流水线。微批次的梯度汇聚后用来更新参数,其中每台设备只存有并更新对应组的参数。其中白色序号代表微批次的索引。
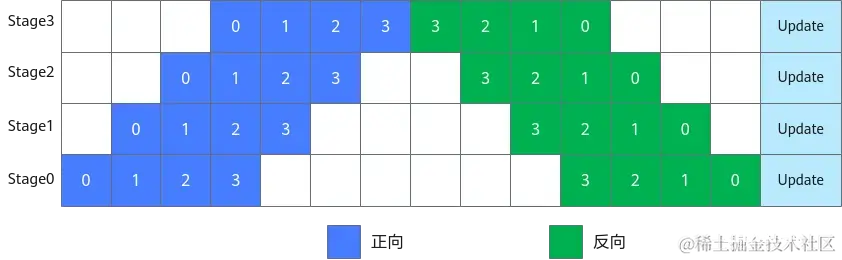
1F1B (1 forward 1 backward,一次前向,一次反向)的流水线并行实现中对执行序进行了调整,来达到更优的内存管理。如图所示,在编号为0的MicroBatch的正向执行完后立即执行其反向,这样做使得编号为0的MicroBatch的中间结果的内存得以更早地释放,进而确保内存使用的峰值更低。

假设MicroBatch Num是m,pipeline stage是p,流水线并行的效率是:
PipelineUtilization=mp+m−1Pipeline_{Utilization} = \frac {m}{p+m-1}PipelineUtilization=p+m−1m
分布式训练并行策略及优化技术
目前,对于LLM而言,传统的单机单卡已经无法满足其训练要求,因此,需要采用多机多卡进行分布式并行训练来扩展模型参数规模,同时使用一些训练优化技术去降低显存、通信、计算等,从而提升训练性能。
分布式训练并行技术:
数据并行张量并行流水线并行MOE并行(稀疏化)
混合精度训练:
FP16 / BF16:降低训练显存的消耗,还能将训练速度提升2-4倍。FP8:NVIDIA H系列GPU开始支持FP8,兼有FP16的稳定性和INT8的速度,Nvidia Transformer Engine 兼容 FP8 框架,主要利用这种精度进行 GEMM(通用矩阵乘法)计算,同时以 FP16 或 FP32 高精度保持主权重和梯度。 MS-AMP训练框架 (使用FP8进行训练),与广泛采用的 BF16 混合精度方法相比,内存占用减少 27% 至 42%,权重梯度通信开销显著降低 63% 至 65%。运行速度比广泛采用的 BF16 框架(例如 Megatron-LM)快了 64%,比 Nvidia Transformer Engine 的速度快了 17%。
重计算(Recomputation)/梯度检查点(gradient checkpointing):一种在神经网络训练过程中使动态计算只存储最小层数的技术。一种用计算换显存的方法。通过减少保存的激活值来压缩模型占用空间,在计算梯度时必须重新计算没有存储的激活值。
梯度累积:它将多个Batch训练数据的梯度进行累积,在达到指定累积次数后,使用累积梯度统一更新一次模型参数,以达到一个较大Batch Size的模型训练效果。累积梯度等于多个Batch训练数据的梯度的平均值。
FlashAttention v1 and v2 :通过分块计算和kernel融合,减少了HBM访问次数,实现了计算加速,同时减少了显存占用。 参考:Megatron-deepspeed , 训练推理都可以使用。
MQA / GQA: 一定程度的Key value的共享,从而可以使模型体积减小,减少了数据的读取。
卸载(Offload)技术:一种用通信换显存的方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。如:ZeRO-Offload、ZeRO-Infinity等。
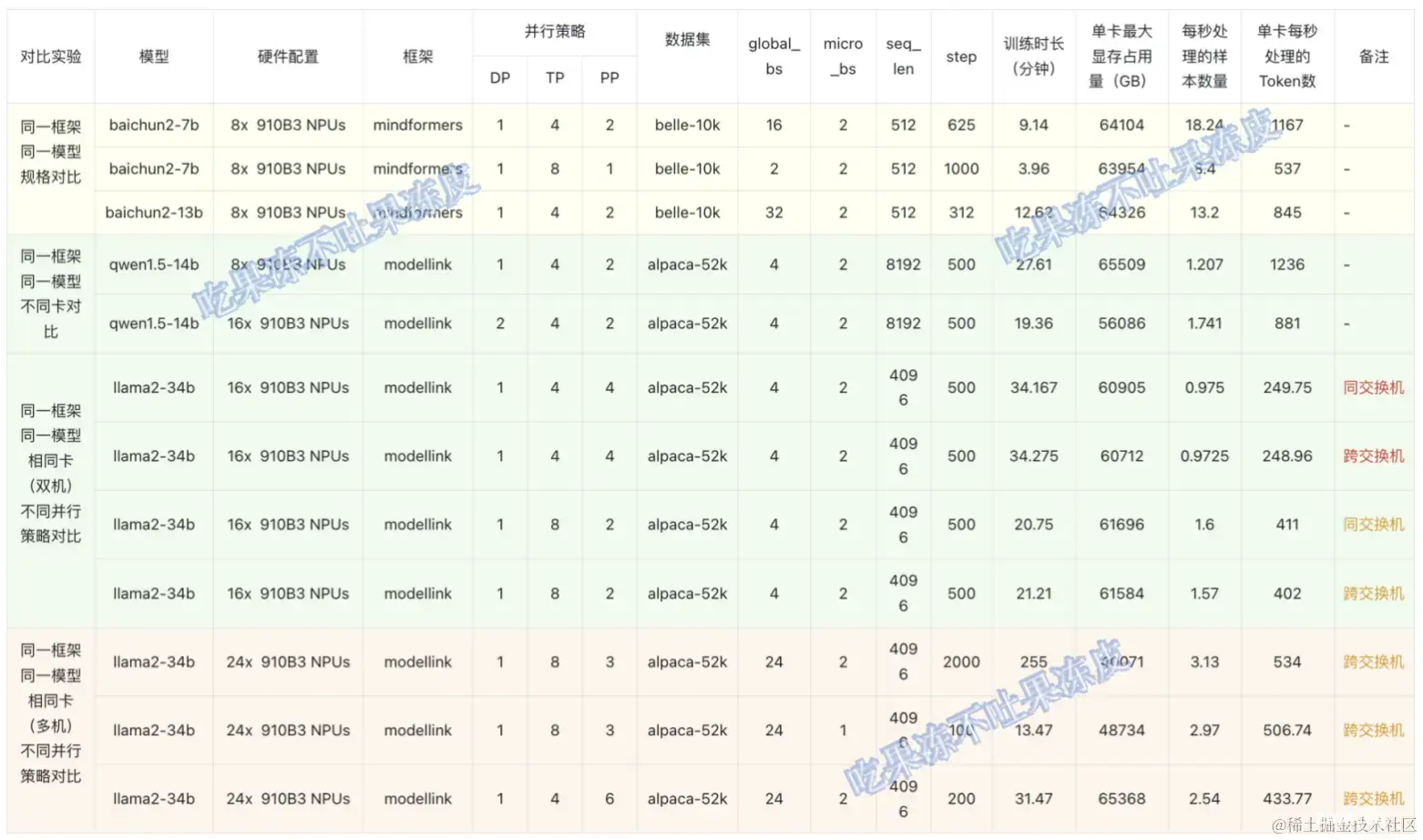
基于昇腾910B3进行 LLM 训练性能测试
性能测试说明:
AI框架:ModelLink、MindFormers模型:baichuan2-7b/13b、qwen1.5-7b/14b、llama2-34b分布式并行策略:DP/TP/PP训练优化技术:FlashAttn、GQA、混合精度等指标:吞吐量、显存(仅为当前分布式策略下的吞吐量,并不是最大吞吐量)训练数据集:alpaca-52k、belle-random-10k服务器配置:3 台 910B3 x 8 (其中,某两台在同一个交换机,另外一台在另一个交换机)
下面在910B3上对不同训练框架、不同模型参数规格、不同卡进行了几组对比实验,比如:同一框架同一模型不同参数规模对比,同一框架同一模型不同卡对比,同一框架同一模型不同并行策略对比、不同框架同一模型对比等。
声明:本文LLM训练性能测试数据仅供参考,同时,每种框架里面的训练优化技术没有严格对齐(当然能够提供一组默认的最佳的训练参数是AI框架性能和易用性的隐性衡量标准);因此,具体性能实测为准。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。