为企业知识库选模型?全球AI大模型知识库RAG场景基准测试排名
CSDN 2024-07-10 16:01:02 阅读 91
大语言模型常见基准测试
大家对于AI模型理解和推理能力的的基准测试一定非常熟悉了,比如MMLU(大规模多任务语言理解)、GPQA(研究生级别知识问答)、GSMSK(研究生数学知识考察)、MATH(复杂数学知识推理)、MGSM(多语言数学知识问答)、Code(代码生成能力考察)等。随着AI能力逐渐应用到企业业务中,AI模型也逐渐应用到企业知识库问答。
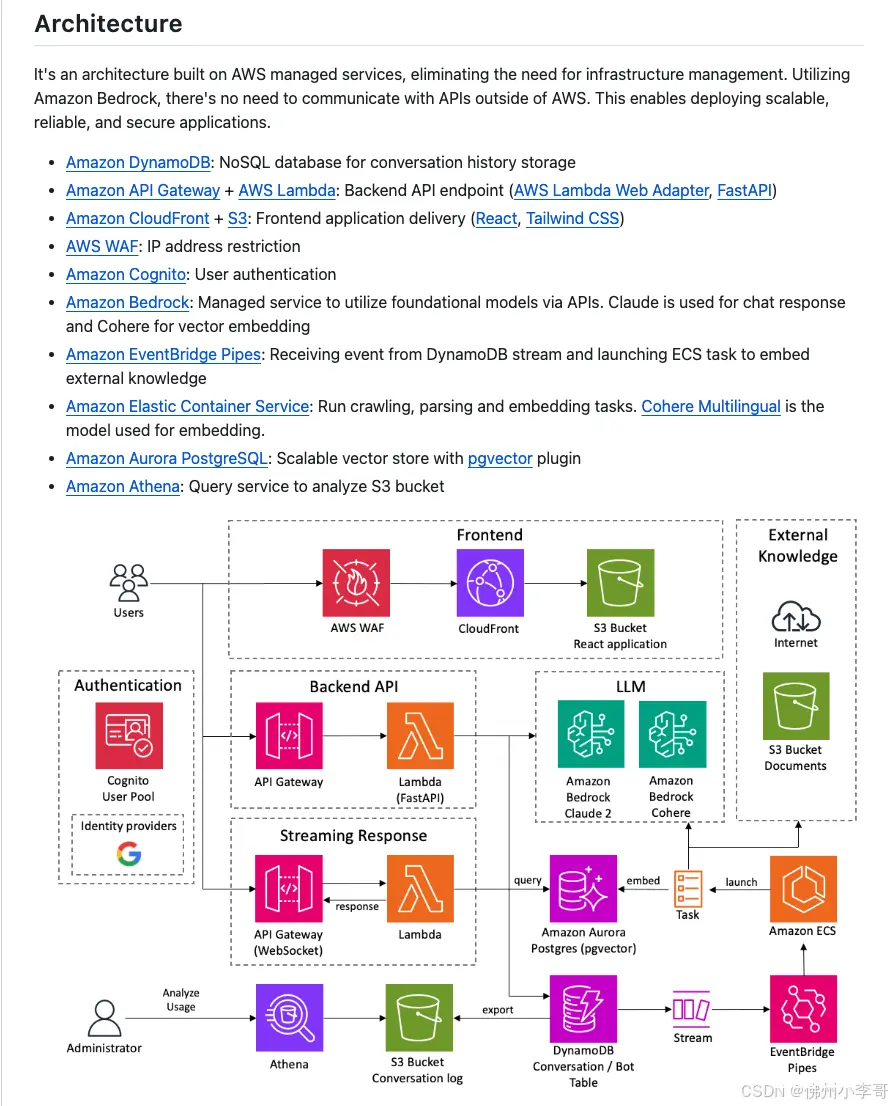
RAG测试集H2ogpte和国际热门AI模型表现
今天小李哥分享的是目前全球最热门模型在知识库RAG场景下的性能表现,本次才用的基准测试集为Github上的开源测试集:enterprise-h2ogpte。基准测试数据集包括PDFs和图片等文件。
测试的主要模型包括了Anthropic的Claude 3系列、Open AI的Chat GPT-4、Google的Gemini Pro以及Mistral AI Large模型等国际上最热门的模型。榜单里也加入了测试的准确度、成本和响应速度,为开发者和企业的LLM模型选择提供了参考。
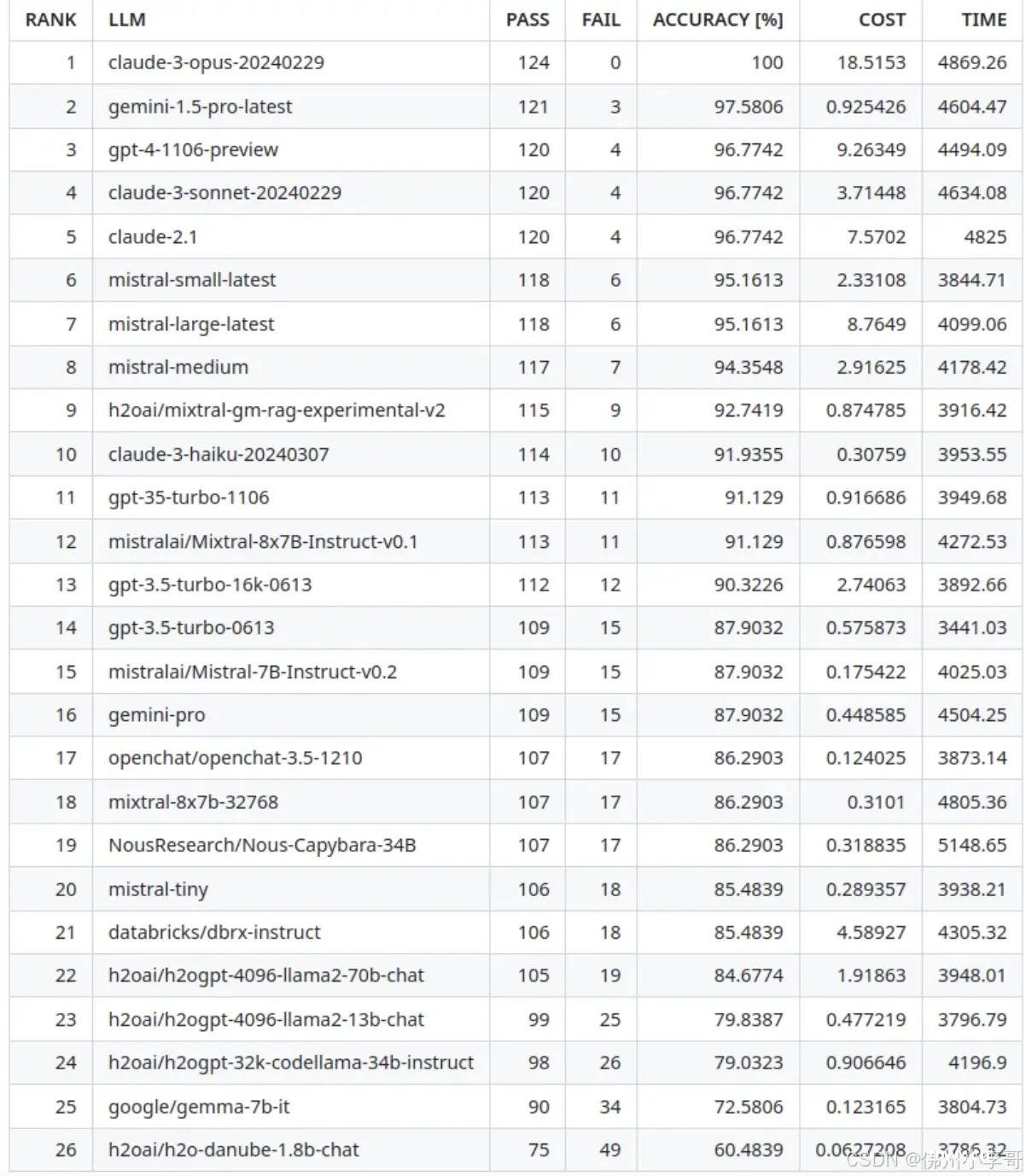
在最新的RAG基准测试中,Claude 3 模型展示了其强大的性能和稳定性,荣登榜首。此次基准测试评估了多款领先的语言模型,结果显示,Claude 3 模型在各项指标中表现优异,特别是在通过率和准确率方面。
同时ChatGPT-4、Meta Llama3和Gemini Pro 1.5紧随其后,性能表现上差距非常小(小于3%)。由于性能上相差不大,在模型选择上我们会根据成本和响应时间综合考虑。在文章后面,小李哥将会给大家介绍综合考虑的结果。
Top3测试结果展示
Claude 3-Opus-20240229
通过次数:124失败次数:0准确率:100%成本:18.515时间:4869
Gemini-1.5-pro-latest
通过次数:121失败次数:3准确率:97.5806%成本:0.925时间:4604.47
GPT-4-1106-Preview
通过次数:120失败次数:4准确率:96.7742%成本:9.263时间:4494.09
其他值得关注的模型
Claude-3-sonnet 以96.7742%的准确率和3.714的低成本并列第3。Mistral-large-latest 和 Mistral-small-latest 分别位居第6和第7,展示了Mistral系列模型的稳健性能,在RAG场景同样具备优势。GPT-3.5-Turbo-1106 和 GPT-3.5-Turbo-16k-0613 分别位列11和第13,继续保持了GPT-3系列的优良表现。
成本与性能的权衡
在成本和时间方面,各模型也表现出显著差异。例如,排名第一的Claude 3-Opus-20240229虽然准确率使其成为实际应用中的理想选择,但成本过于高昂,除了一些对准确度要求很高的场景之外(医疗、金融、法律等),综合来看并不适用于企业日常的AI场景。而Gemini-1.5-pro在保持高准确率的同时拥有极低的成本,准确率上与Claude 3 Opus也极为接近,最适用于企业日常中对预算有控制同时对性能要求较高的场景。同时Claude 3 Sonnet具有仅次于Gemini Pro 1.5的性价比,适用于在亚马逊云科技AWS上部署AI服务的企业(目前亚马逊云科技模型托管平台还不支持Gemini),更适用于亚马逊云科技生态的AI软件服务系统。
如何在亚马逊云科技上使用Claude 3大语言模型构建知识库
在亚马逊云科技上,有两种方式构建企业知识库。第一种为使用亚马逊云科技AWS的模型托管平台Amazon Bedrock自带的知识库功能。其中向量库、向量模型、大语言模型和问答UI都已经集成到现成功能里,帮助用户更高效、轻松地构建知识库。

获取知识库回复代码:
<code>def retrieveAndGenerate(query, kbId, numberOfResults, model_id, region_id):
model_arn = f'arn:aws:bedrock:{region_id}::foundation-model/{model_id}'
return bedrock_agent_runtime.retrieve_and_generate(
input={
'text': query
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': model_arn,
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': numberOfResults,
'overrideSearchType': "SEMANTIC", # optional'
}
}
},
'type': 'KNOWLEDGE_BASE'
},
)
response = retrieveAndGenerate("In what year did Amazon’s annual revenue increase from $245B to $434B?", \
"<knowledge base id>", numberOfResults, model_id, region_id)['output']['text']
完整的请求API语法和响应内容如下:
POST /retrieveAndGenerate HTTP/1.1
Content-type: application/json
{
"input": {
"text": "string"
},
"retrieveAndGenerateConfiguration": {
"externalSourcesConfiguration": {
"generationConfiguration": {
"additionalModelRequestFields": {
"string" : JSON value
},
"guardrailConfiguration": {
"guardrailId": "string",
"guardrailVersion": "string"
},
"inferenceConfig": {
"textInferenceConfig": {
"maxTokens": number,
"stopSequences": [ "string" ],
"temperature": number,
"topP": number
}
},
"promptTemplate": {
"textPromptTemplate": "string"
}
},
"modelArn": "string",
"sources": [
{
"byteContent": {
"contentType": "string",
"data": blob,
"identifier": "string"
},
"s3Location": {
"uri": "string"
},
"sourceType": "string"
}
]
},
"knowledgeBaseConfiguration": {
"generationConfiguration": {
"additionalModelRequestFields": {
"string" : JSON value
},
"guardrailConfiguration": {
"guardrailId": "string",
"guardrailVersion": "string"
},
"inferenceConfig": {
"textInferenceConfig": {
"maxTokens": number,
"stopSequences": [ "string" ],
"temperature": number,
"topP": number
}
},
"promptTemplate": {
"textPromptTemplate": "string"
}
},
"knowledgeBaseId": "string",
"modelArn": "string",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": { ... },
"numberOfResults": number,
"overrideSearchType": "string"
}
}
},
"type": "string"
},
"sessionConfiguration": {
"kmsKeyArn": "string"
},
"sessionId": "string"
}
HTTP/1.1 200
Content-type: application/json
{
"citations": [
{
"generatedResponsePart": {
"textResponsePart": {
"span": {
"end": number,
"start": number
},
"text": "string"
}
},
"retrievedReferences": [
{
"content": {
"text": "string"
},
"location": {
"s3Location": {
"uri": "string"
},
"type": "string"
},
"metadata": {
"string" : JSON value
}
}
]
}
],
"guardrailAction": "string",
"output": {
"text": "string"
},
"sessionId": "string"
}
知识库提示词样例:
"""You are a question answering agent. I will provide you with a set of search results and a user's question, your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.
Here are the search results in numbered order:
<context>
$search_results$
</context>
Here is the user's question:
<question>
$query$
</question>
$output_format_instructions$
Assistant:
"""
第二种方式则为使用亚马逊云科技AWS推出的Github开源工程项目bedrock-claude-chat。包括前端、后端、向量库、向量/LLM模型、用户登录/管理/授权功能都已经帮助大家实现。直接可以一键部署。

部署步骤:
Clone this repository
<code>git clone https://github.com/aws-samples/bedrock-claude-chat
Install npm packages
cd bedrock-claude-chat
cd cdk
npm ci
Install AWS CDK
npm i -g aws-cdk
Deploy this sample project
cdk deploy --require-approval never --all
部署成功则能看到如下结果:
✅ BedrockChatStack
✨ Deployment time: 78.57s
Outputs:
BedrockChatStack.AuthUserPoolClientIdXXXXX = xxxxxxx
BedrockChatStack.AuthUserPoolIdXXXXXX = ap-northeast-1_XXXX
BedrockChatStack.BackendApiBackendApiUrlXXXXX = https://xxxxx.execute-api.ap-northeast-1.amazonaws.com
BedrockChatStack.FrontendURL = https://xxxxx.cloudfront.net
总结
此次基准测试的结果清晰地展示了Claude 3模型在当前语言模型领域中的领先地位。无论是在准确率还是在性能成本的平衡方面,Claude 3模型都表现出色。对于需要高精度和高可靠性的应用场景,Claude 3无疑是最佳选择。
但是企业的模型选择更会考虑到成本的控制,和用户请求的响应时间和体验。在这种场景下,使用谷歌的Gemini Pro 1.5则为更优质的选择。如果想了解如何在谷歌云和亚马逊云科技上使用各类AI模型,欢迎大家关注小李哥获取未来更多国际前沿AI技术方案和动态。
随着语言模型的不断发展,期待在未来看到更多像Claude 3这样的优秀模型,为各类AI应用提供更强大、更高效的支持。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。