AI大模型探索之路-应用篇13:企业AI大模型选型指南
CSDN 2024-06-18 09:01:07 阅读 53
目录
前言
一、概述
二、有哪些主流模型?
三、模型参数怎么选?
四、参数有什么作用?
五、CPU和GPU怎么选?
六、GPU和显卡有什么关系?
七、GPU主流厂商有哪些?
1、NVIDIA芯片怎么选?
2、CUDA是什么?
3、AMD芯片怎么选?
4、NVIDIA和AMD两者有什么区别?
八、GPU显存怎么选?
1、模型参数?
2、量化处理?
九、什么是预训练和微调?
总结
前言
在打造企业AI大模型的路上,我们常常会遇到一系列的选型和概念挑战。例如,如何选择合适的模型,如何挑选GPU,以及什么是微调和监督微调等。本文旨在深入剖析这些常见问题,为大家提供一个全面的概览,帮助大家更好地理解和利用这些强大的工具。
一、概述
文章中我们将带着问题去了解打造企业AI大模型中的关键实践,包括模型选择、参数理解、硬件选择(CPU与GPU),以及训练技术(预训练和微调)。我们将探讨如何在众多开源模型和商业解决方案中做出选择,并基于业务需求调整模型参数和训练方法。通过阅读本文获得构建和部署高效AI大模型的知识和工具,为以后在此领域的旅程提供坚实的基础。

二、有哪些主流模型?
对于企业如果自己从零研发自己的大模型;它对算力、数据的要求非常高,研发投入非常大,
比如以OpenAI的GPT-3模型为例来估算。假设:
模型训练需要1,000个NVIDIA A100 GPU。每个GPU的价格为$10,000(这是A100 GPU的大致市场价格)。GPU租用费用为$8/小时(这是一个大致的市场价格)。模型训练时间为2个月(60天)。每天24小时不间断训练。
计算:
GPU购买成本 = 1,000 × 10,000=10,000,000
GPU租用成本 = 1,000 × 8/小时×24小时/天×60天= 11,520,000
因此对大多数企业而言,更多的是从目前以及开源或者闭源的大模型上进行选择;
由于篇幅有限,下面仅列了部分主流模型:
| 企业名称
| 模型名称
| 开源情况
|
| OpenAI
| GPT-3、GPT-3.5、GPT-4
| 不开源
|
|
|
|
|
|
| PaLM、PaLM 2
| 不开源
|
|
| Gemma 7B、Gemma 2B - It、CodeGemma-7B、CodeGemma-7B-IT、CodeGemma-2B、RecurrentGemma-2B
| 开源
|
| Meta
| OPT、LLaMA 7B、LLaMA 13B、LLaMA 33B、LLaMA 65B、LLaMA 65B
| 开源不可商用
|
| Meta
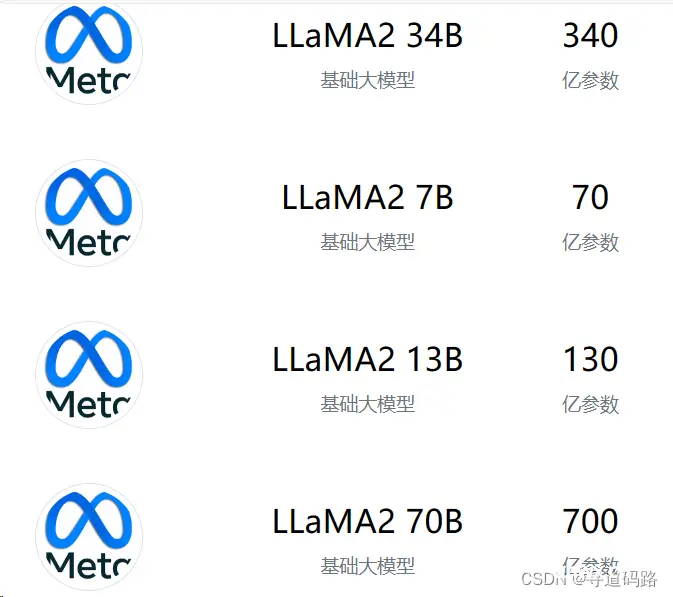
| LLaMA2 70B、LLaMA2 34B、LLaMA2 13B、LLaMA2 7B
| 开源
|
| 微软
| Phi-1、Phi-1.5
| 开源不可商用
|
|
| Phi-2
| 开源
|
| 智谱
| ChatGLM-6B、ChatGLM2-6B、ChatGLM3-6B-Base
| 开源
|
| 智谱
| ChatGLM2 12B、GLM-130B、GLM4
| 不开源
|
| 百川
| Baichuan 7B、Baichuan 13B - Base、Baichuan 13B - Chat、Baichuan2-7B-Base、Baichuan2-13B-Base
| 开源
|
| 阿里巴巴
| Qwen-7B、Qwen-1.8B、Qwen1.5-MoE-A2.7B、Qwen1.5-32B
| 开源
|
| 华为
| 盘古
| 不开源
|
| 百度
| 文心
| 不开源
|
三、模型参数怎么选?
在大模型名称后面通常都带有一个字母B,"7b"、"13b"、"70b"等,它通常指的是大型神经网络模型的参数数量。其中的 "b" 代表 "billion",也就是十亿。表示模型中的参数量,例如:"7b" 指的是 70 亿个参数;"13b"指的是 130 亿个参数。
四、参数有什么作用?
大模型的参数是衡量模型能力的一个指标,一般XXB越大,通常模型就更厉害;因为更多的参数通常意味着模型可以捕捉到更复杂的数据模式,从而有潜力执行更多种类的任务和提供更准确的预测或判断;
但是实际选择时我们要从多方面考虑:
成本资源:训练和部署大型模型需要更大的计算资源和存储空间,同时也需要更长的训练时间。调试与维护:小型模型通常更容易调试和维护,而大型模型可能因为复杂性增加而难以管理实时性要求:在模型的推理时间方面,大型模型可能因为其复杂性而导致较慢的预测速度。数据特性:某些模型可能比较适合处理特定类型的数据如图像、文本、时间序列等行业需求:不同行业可能有特定的需求和限制,例如在金融行业中,模型的解释性和合规性尤为重要;而在医疗行业,模型的准确性和可靠性至关重要
五、CPU和GPU怎么选?
1. 各自特点:
CPU是计算机的大脑,负责硬件资源调配、执行通用运算,像是一个资深数学家,擅长处理复杂的任务。
GPU是图形和并行计算的专家;适合图形渲染和科学计算;像是一个专门进行数值计算的团队,其中每个成员都负责执行简单的操作,但整个团队合起来可以同时处理大量的相似计算。
2. 使用场景:
CPU:适用于日常的办公、软件运行、系统管理等需要复杂决策和逻辑处理的场景。
GPU:适用于视频编辑、游戏、三维建模以及机器学习等需要大规模数据并行处理的场景。
3. 配置选择
CPU在深度学习中至关重要,需提供足够的数据处理能力以支持模型训练。例如,增加NVIDIA V100 GPU数量未能成比例提高DGX2服务器的吞吐量,表明CPU可能成为性能瓶颈。理想情况下,CPU核心数应随GPU数量线性增加,每块GPU建议分配4~8个CPU核心以满足数据读取需求,但更多核心并不总是带来显著提升。
六、GPU和显卡有什么关系?

GPU并不是一块普通的显卡。确切地说,GPU是显卡中的核心组件,专门负责图像处理任务。作为显卡的关键芯片,GPU承担了大部分图形计算工作,从而减轻了中央处理单元(CPU)的负担。
在3D图形处理领域,GPU展现出其核心技术的威力,包括但不限于硬件T&L(Transform and Lighting,即几何转换和光照处理)、立方环境材质映射、顶点混合技术、纹理压缩以及凹凸映射贴图等。这些技术的运用,使得GPU能够高效地执行复杂的图形渲染任务,极大地提升了视觉效果的真实性和细腻度。
其中,硬件T&L技术是GPU的代表性特征之一,它允许GPU在不依赖CPU的情况下,独立完成物体在3D空间中的变换和光照计算,显著提高了图形处理的效率和质量
七、GPU主流厂商有哪些?
全球知名的GPU芯片生产厂商主要有NVIDIA、AMD ,和Intel等。另外也有一些国产GPU公司,景嘉微、寒武纪、海光信息等公司。目前市场上还是以NVIDIA、AMD 为主;通常所说的A卡指的是使用AMD芯片的显卡,而N卡则是使用NVIDIA芯片的显卡。
1、NVIDIA芯片怎么选?

1)Tesla系列:Tesla系列芯片是英伟达针对高性能计算和并行计算而设计的GPU芯片,其特点是高度可编程性和高性能。Tesla系列芯片的应用领域包括科学计算、石油勘探、气象预报、深度学习等领域。例如,Tesla V100是一款拥有640个张量核心的GPU芯片,能够实现高性能的深度学习计算。
2)Quadro系列:Quadro系列芯片是英伟达为计算机图形学和可视化而设计的GPU芯片,其特点是高度的图形性能和精度。Quadro系列芯片的应用领域包括建筑设计、影视制作、游戏开发等领域。例如,Quadro RTX 6000是一款拥有4864个CUDA核心的GPU芯片,能够实现高精度、高逼真的图形渲染。
3)GeForce系列:GeForce系列芯片是英伟达面向游戏玩家和计算机爱好者而设计的GPU芯片,其特点是出色的图形性能和较低的价格。GeForce系列芯片的应用领域包括游戏开发、虚拟现实、数字内容制作等领域。例如,GeForce RTX 2080 Ti是一款拥有4352个CUDA核心的GPU芯片,能够实现高速的游戏渲染和虚拟现实应用。
4)Titan系列:Titan系列芯片是英伟达面向专业用户和高端游戏玩家而设计的GPU芯片,其特点是超高的图形性能和精度。Titan系列芯片的应用领域包括游戏开发、计算机辅助设计、数字内容制作等领域。例如,Titan RTX是一款拥有4608个CUDA核心的GPU芯片,能够实现高精度、高逼真的图形渲染。
2、CUDA是什么?
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和编程模型。该平台利用GPU(图形处理器)的强大计算能力,使其更适用于高性能计算和数据并行计算任务。是一种专门为NVIDIA的图形处理单元(GPU)设计的软件框架(也兼容其他AMD、Intel等厂商的芯片)
1、性能提升:利用GPU的并行处理能力,显著提高计算速度。
2、编程灵活:提供C语言的扩展,降低开发难度。
3、工具丰富:提供编译器、调试器和优化工具,支持开发过程。
4、库资源丰富:提供丰富的库函数,方便开发者使用。
5、广泛应用:适用于多种领域,如图形渲染、科学模拟和深度学习等。
6、统一架构:提供统一的内存管理和设备控制接口,简化代码结构。
3、AMD芯片怎么选?

1.RadeonVega系列:最新的系列,采用了先进的HBM2高速内存技术,能够为游戏玩家提供更加流畅的游戏体验,支持实时运行多项任务。
2.RadeonRX500系列:此系列包括了RX580、RX570等型号,性能强劲,能够满足广大游戏爱好者的需求,同时还支持虚拟现实(VR)和高清视频播放等功能。
3.RadeonRX400系列:此系列包括了RX480、RX470等,它们采用了全新的Polaris架构,能够提供更高效的性能和更低的功耗。
4、NVIDIA和AMD两者有什么区别?
NVIDIA:
1)图形处理能力:英伟达GPU以其卓越的图形渲染和计算能力著称,特别适合处理高负荷的图形应用。
2)视觉效果:英伟达GPU支持高清晰度、高质量纹理、光线追踪等先进特性,提供生动视觉体验。
3)机器学习能力:英伟达GPU擅长处理大数据集,其高度可并行的架构能够快速处理数百万个数据点。
AMD:
1)性能优异:在性能方面表现出色,可提供顶级游戏图像质量和流畅运行体验。
2)价格亲民:相较于竞争对手,AMD独显的价格更为实惠,既能提供高性能,又不会使您的钱包肆虐。
3)兼容性强:可以与许多不同类型的计算机硬件兼容,从笔记本到台式电脑,再到高端工作站。
4)能耗低:通常比其他同类产品消耗更少的能源,并且通常都提供了强大的节能选项。
八、GPU显存怎么选?
1、模型参数?
1) 显存的大小通常根据参数的精度来估算,不同的参数精度,需要的存储空间不一样;
2) 常见的参数精度有:双精度(FP64)、单精度(FP32)、半精度(FP16)
3) 如果一个模型有70亿(7B)个参数,精度为FP32(float32),32位占4个字节(1字节= 8位)
那么它大约需要的存储空间可以按照以下方式估算:

再将字节转为GB,所以:

因此一个有70亿参数的模型(精度为FP32),需要26G左右显存;如果1024换为1000,简单粗暴计算(7*4=28)大约需要28GB的存左右储空间来保存所有参数,13B则需要52G左右的显存;
注意:这是简单换算,不考虑其他方面的影响;对于模型训练,GPU的选择不仅取决于模型的大小,还取决于训练数据集的大小和期望的训练速度;训练通常需要的GPU显存是推理的10倍以上。
2、量化处理?
量化处理(一种模型压缩技术):简单理解可以将模型的从高精度的浮点数,转化为低精度的8位整数(int8)或者4位整数(int4),比如将32FP转为为int8后,存储空间缩减了四分之三(原来需要4个字节存储,现在只需1个字节);
比如:ChatGLM3-6B 默认情况, 以 FP16 精度加载,需要14G左右显存,量化后需要的显存更小。
| 量化等级
| 最低 GPU 显存(推理)
| 最低 GPU 显存(高效参数微调)
|
| FP16(无量化)
| 13 GB
| 14 GB
|
| INT8
| 8 GB
| 9 GB
|
| INT4
| 6 GB
| 7 GB
|
注意:量化技术可以降低模型的计算和存储成本,同时降低精度会导致信息丢失、模型的预测准确性有所下降。
九、什么是预训练和微调?
1、预训练(Pre-training)
预训练是语言模型学习的初始阶段;在预训练期间,模型会接触到大量未标记的文本数据,例如书籍、文章和网站。在大量未标记文本数据上训练语言模型。比如说在包含数百万本书、文章和网站的数据集上预训练像GPT-3这样的语言模型。预训练目标是捕获文本语料库中存在的底层模式、结构和语义知识。(basemodel)
2、微调(Fine-Tuning)
微调是在特定任务或领域上进一步训练大型语言模型(LLM)的过程。这可以通过使用预训练的LLM作为起点,然后在特定任务或领域的标记数据集上训练它来完成。微调可以通过调整模型的权重来更好地拟合数据,从而提高LLM在特定任务或领域上的性能。
3、监督微调(SupervisedFine-Tuning)
人工介入,给出高质量的文本问答例子。经过问答式训练的Model叫做SFTmodel,就可以正常回答人的问题了。(SFTmodel)
4、基于人类反馈的强化学习(ReinforcementLearningfromHumanFeedback)
人工先介入,通过对同一个Prompt生成答案的排序来训练一个RewardModel。再用RewardModel去反馈给SFTModel,通过评价生成结果的好坏,让模型更倾向于生成人们喜好的结果。RLHF是一种更复杂、更耗时的方法来微调LLM,但它比SFT更有效。(RLHFmodel)
总结
探索AI大模型的路上,我们不仅仅是在追逐技术的顶峰,更是在为具体的业务场景寻找最佳的匹配方案。面对层出不穷的技术细节和背景知识,我们通过不断学习、梳理和实践,逐步揭开其神秘的面纱。掌握了这些关键常识,我们就能够更精准地搭建起通向未来的桥梁,无论是在模型选择、硬件配置还是训练技巧上,都将游刃有余。最终希望这些解读不仅仅停留在理论探讨上,更能在实际的开发和应用中发光发热,引领大家在AI的星辰大海中乘风破浪。
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。
专栏:AIGC-AI大模型探索之路
上一篇: 【全栈小5】挥手告别2023,如期而至的2024,给大家分享我的一些小感受,2023也是AI百花齐放的一年
下一篇: 探索Semantic Kernel内置插件:深入了解ConversationSummaryPlugin的应用
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。