AI大模型探索之路-应用篇14:认识国产开源大模型GLM
CSDN 2024-06-21 13:31:02 阅读 70
目录
前言
一、国产主流大模型概览
1. 国内主流大模型清单
2. 主流大模型综合指数
3. 大语言模型评测榜单
二、GLM大模型介绍
三、GLM大模型发展历程
四、GLM家族之基座模型GLM-130B
五、GLM家族之ChatGLM3
六、GLM家族之WebGLM
七、GLM家族之CogVLM
1. CogVLM
2. CogAgent
八、GLM家族之CodeGeeX
1. CodeGeeX
2. CodeGeeX2
九、GLM家族之AgentBench和AgentTuning
总结
前言
在人工智能的浩瀚宇宙中,开源大模型如同璀璨星辰,引领着技术创新与应用探索的方向。国际领域的OpenAI无疑闪耀着夺目的光芒,但国内厂商亦步亦趋,逐渐展露头角。今天,我们将聚焦于国内主流的大模型,探寻它们的技术脉络与应用潜力,并特别解析智谱AI研发的GLM大模型系列,见证中国在全球AI舞台上的坚实步伐。
一、国产主流大模型概览
在国际大模型的光环之下,国内技术企业凭借持续的研发投入与创新精神,孕育出一系列具有自主知识产权的大模型。它们在多语言处理、自然语言理解等领域展现出强大的潜能
1. 国内主流大模型清单
由于篇幅有限仅列了部分国内主流大模型
1)智谱清言(ChatGLM) - 智谱AI:智谱AI推出的对话大模型,优化了中文问答和对话能力。
2)通义千问:阿里巴巴推出的大模型,集成了其在自然语言处理等领域的技术积累。
3)讯飞星火:科大讯飞公司推出的大模型,展现了良好的搜索能力和上下文理解能力。
4)文心一言:百度的大模型,利用百度的搜索数据和知识图谱作为支撑。
5)盘古大模型:华为自主研发的AI大模型系列,涵盖了NLP、CV、多模态等多个领域。
6)百川大模型 - 百川智能:百川智能推出的大模型产品,致力于提供人工智能解决方案。
7)豆包 - 字节跳动:字节跳动推出的大模型,特点是拥有丰富的中文数据和强大的技术实力。
8)腾讯AI Lab通用大模型 :腾讯AI Lab推出的通用大模型,致力于提升自然语言理解和生成。
虽然国产大模型在中文处理等方面取得了一定的进展,部分模型在中文主观评测中接近国际顶尖水平,但整体上要赶超GPT-4 Turbo等国际先进的大模型,还需要更多的努力和投入;希望未来能有更大的提升,以及各个场景与领域的应用。
2. 主流大模型综合指数
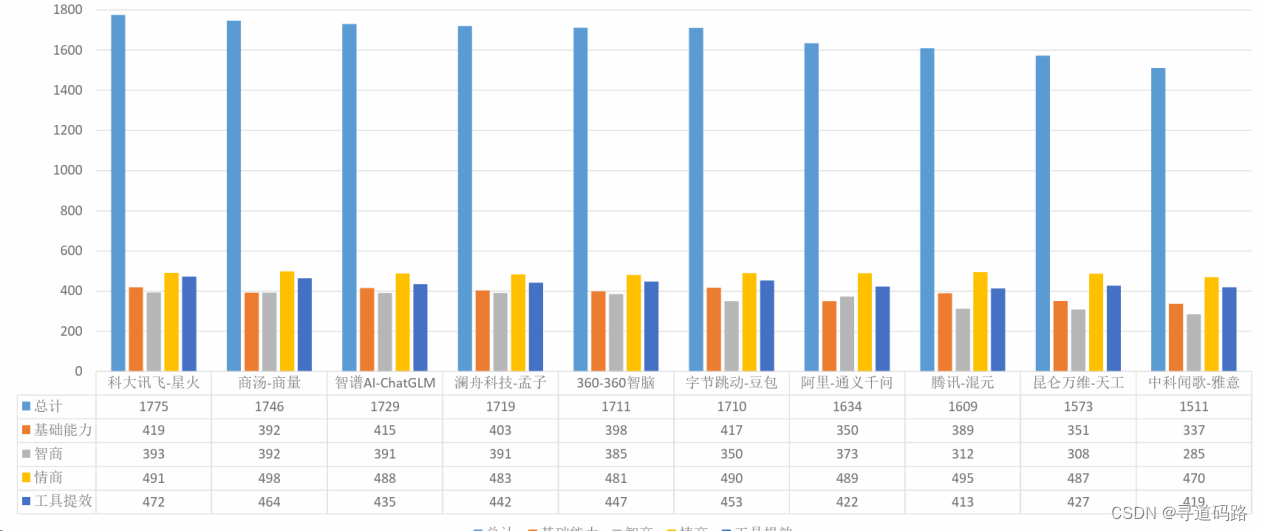
数据来源:《人工智能大模型体验报告3.0》
3. 大语言模型评测榜单
大语言模型排行榜
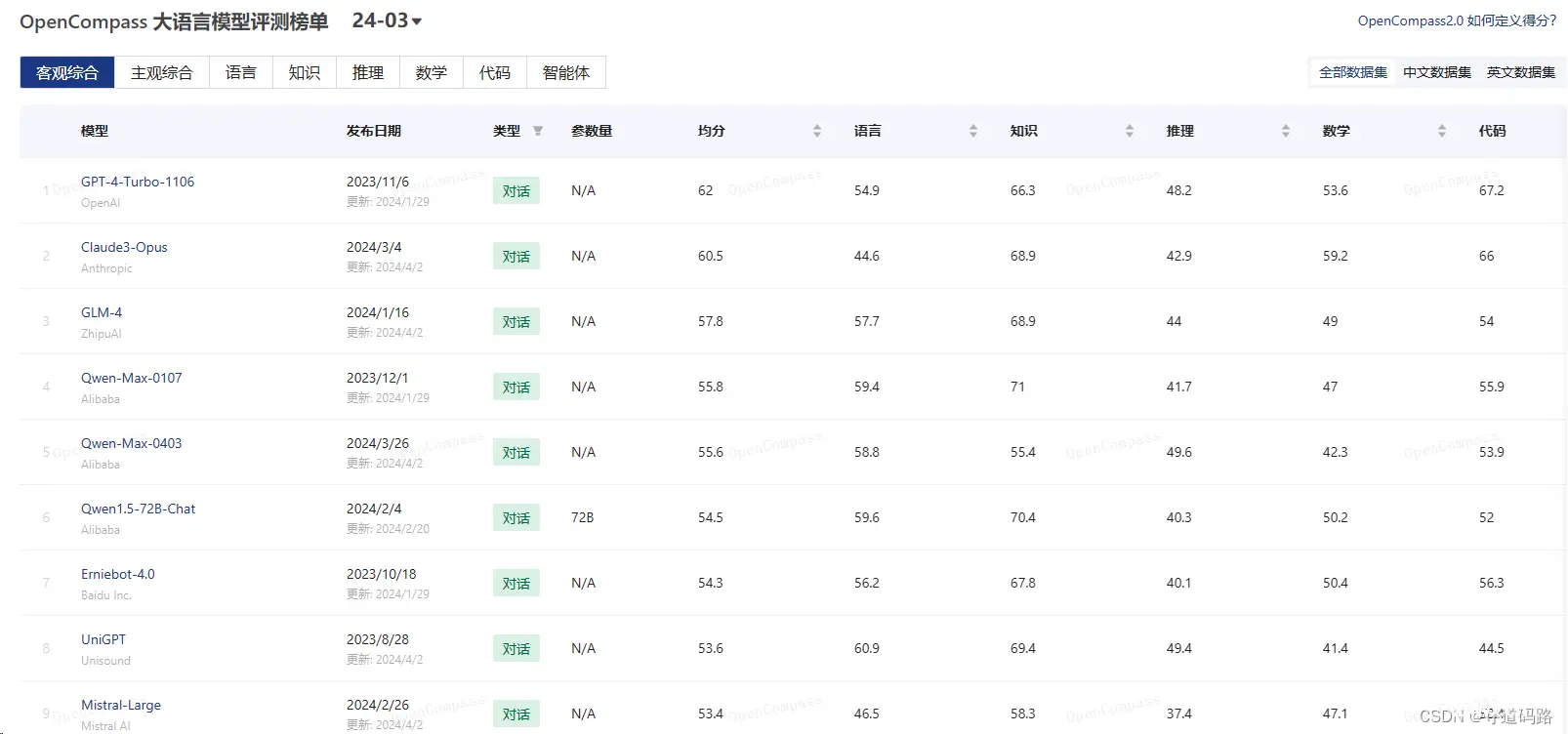
大模型选择方向:支持中文、开源的、可商用的、性能好、低成本部署
===================== 智谱AI的GLM大模型 =====================
二、GLM大模型介绍
GLM大模型作为智谱AI的杰出代表作,以其卓越的中文处理能力、开源特性及对多种芯片的支持,成为国内外广泛关注的焦点。其基于Transformer架构的自主研发核心,展现了智谱AI在算法创新上的深厚实力。此外,GLM大模型不仅是文本处理的高手,还能解读图像等复合数据,拓展了AI的应用边界。而其所在的产品矩阵,如ALL Tools、CogVLM3和CodeGeeX3等,共同构成了一个全面的大模型生态系统。
1)中文处理能力强:GLM大模型针对中文问答和对话进行了优化,表现出色,尤其在中文领域可以比肩GPT-4(支持中英文)。
2)开源特性:作为国产自研的大模型,GLM大模型的开源有助于推动技术共享和创新。
3)底层核心:非GPT,而是基于Transformer架构自研的的自编码模型
4)芯片支持:除了支持NVIDIA,还支持Hygon DCU、Ascend910、Sunway等国产芯片
5)支持Int4: 支持INT4部署(量化处理),相比于GPT的INT8,更节省资源
6)技术成果积累:GLM大模型是智谱AI(由清华大学计算机系知识工程实验室的技术转化而来)多年技术积累的成果。
7)多模态能力:GLM不仅处理文本,还能理解图像等复合数据,有助于实现更丰富的应用场景。
8)全家桶产品:GLM大模型所在的产品矩阵包括ALL Tools、多模态大模型CogVLM3、代码大模型CodeGeeX3等,形成了一个全面的大模型产品体系(对标Open AI)
三、GLM大模型发展历程
2021年9月:智谱AI设计了GLM算法,并发布了拥有自主知识产权的开源百亿大模型GLM-10B。
2022年8月:智谱AI发布了高精度千亿大模型GLM-130B,并进行了开源,该模型的效果与GPT-3 175B相当,受到全球70余个国家1000余个研究机构的使用需求。
2022年11月:发布编程大模型CodeGeex,对标OpenAICodeX编程大模型。
2023年7月25日:发布CodeGeex2, 全面超越LAMMA2编程能力;
2022年:推出P-tuningv2,经过数年迭代,是目前最为通用的开源微调框架之一;
2023年9月24日:推出CogVLM多模态大模型,在多模态权威学术榜综合成绩排名第一,对标GPT-4v;
2023年10月15日:推出AgentBench,LLMAgent能力评估模型;当日同时推出AgentTuning,用于增强LLM ;Agent性能对标微软AutoGen;
2024年1月16日:智谱AI推出了新一代基座大模型GLM-4,这标志着其在大模型研发上的又一重要里程碑。
四、GLM家族之基座模型GLM-130B
GLM-130B是一个开放的双语(英文和中文)双向密集模型,具有1300亿个参数,使用通用语言模型(GLM)的算法进行预训练。有1300亿个参数,它旨在支持在单个 A100 (40G * 8) 或 V100 (32G * 8) 服务器上使用 130B 参数的推理任务。通过 INT4 量化,硬件要求可以进一步降低到具有 4 * RTX 3090 (24G) 的单个服务器,几乎没有性能下降。截至 2022 年 7 月 3 日,GLM-130B 已在超过 4000 亿个文本令牌(中英文各 200B)上进行了训练,支持国产芯片,并具有以下独特功能:
1)双语:支持英文和中文。
2)性能(EN):在 LAMBADA 上优于 GPT-3 175B (+4.0%)、OPT-175B (+5.5%) 和 BLOOM-176B (+13.0%),在 MMLU 上略优于 GPT-3 175B (+0.9%)。
3)性能(CN):在 7 个零样本 CLUE 数据集 (+24.26%) 和 5 个零样本 FewCLUE 数据集 (+12.75%) 上明显优于 ERNIE TITAN 3.0 260B。
4)快速推理:支持使用单个 A100 服务器在 SAT 和 FasterTransformer 上进行快速推理(速度提高 2.5 倍)。
5)可重复性:所有结果(30+ 个任务)都可以通过开源代码和模型检查点轻松重现。
6)跨平台:支持 NVIDIA、Hygon DCU、Ascend 910 和 Sunway 的训练和推理(即将发布)。
=====================================GLM-4============================
新一代基座大模型GLM-4,整体性能相比GLM3全面提升60%,逼近GPT-4;支持更长上下文;更强的多模态;支持更快推理速度,更多并发,大大降低推理成本;同时GLM-4增强了智能体能力。
1)基础能力(英文):GLM-4 在 MMLU、GSM8K、MATH、BBH、HellaSwag、HumanEval等数据集上,分别达到GPT-4 94%、95%、91%、99%、90%、100%的水平。
2)指令跟随能力:GLM-4在IFEval的prompt级别上中、英分别达到GPT-4的88%、85%的水平,在Instruction级别上中、英分别达到GPT-4的90%、89%的水平。
3)对齐能力:GLM-4在中文对齐能力上整体超过GPT-4。
4)长文本能力:我们在LongBench(128K)测试集上对多个模型进行评测,GLM-4性能超过 Claude 2.1;在「大海捞针」(128K)实验中,GLM-4的测试结果为 128K以内全绿,做到100%精准召回。
5)多模态-文生图:CogView3在文生图多个评测指标上,相比DALLE3 约在 91.4% ~99.3%的水平之间。
五、GLM家族之ChatGLM3
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上;支持Prompt、Function Call、Agent (相当于开发时和OpenAI相关的实践相同)
1)更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
2)更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
3)更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。
六、GLM家族之WebGLM
WebGLM 旨在使用 10 亿参数的通用语言模型(GLM)提供一种高效且低成本的网络增强问答系统。它旨在通过将网络搜索和召回功能集成到预训练的语言模型中以进行实际应用的部署。
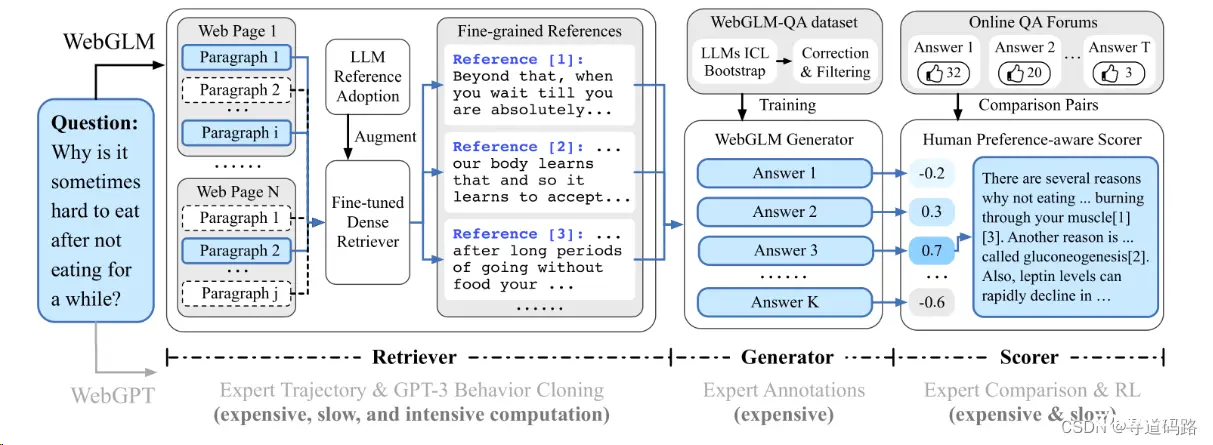
1)大模型增强检索器:增强了相关网络内容的检索能力,以更好地准确回答问题。
2)自举生成器:利用 GLM 的能力为问题生成回复,提供详细的答案。
3)基于人类偏好的打分器:通过优先考虑人类偏好来评估生成回复的质量,确保系统能够产生有用和吸引人的内容。
七、GLM家族之CogVLM
1. CogVLM
CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B拥有100亿的视觉参数和70亿的语言参数,支持490*490分辨率的图像理解和多轮对话。

CogVLM有时比GPT-4V(ision)捕获更详细的内容:在上图中,CogVLM能够准确识别出4个房子(3个完整可见,1个只有放大才能看到);作为对比,GPT-4V仅能识别出其中的3个。
2. CogAgent
CogAgent是一个基于CogVLM改进的开源视觉语言模型。CogAgent-18B拥有110亿的视觉参数和70亿的语言参数。除了CogVLM已有的所有功能(视觉多轮对话,视觉定位)之外,CogAgent:
1)支持更高分辨率的视觉输入和对话式问答。它支持超高分辨率的图像输入,达到1120x1120。
2)拥有视觉Agent的能力,能够在任何图形用户界面截图上,为任何给定任务返回一个计划,下一步行动,以及带有坐标的特定操作。
3)增强了与图形用户界面相关的问答能力,使其能够处理关于任何图形用户界面截图的问题,例如网页、PC应用、移动应用等。
4)通过改进预训练和微调,提高了OCR相关任务的能力。
八、GLM家族之CodeGeeX
1. CodeGeeX
CodeGeeX模型,130亿参数,支持20多种编程语言,具备代码生成、续写、翻译等能力;开发了支持VSCode、IntelliJIDEA、PyCharm、GoLand、WebStorm、AndroidStudio等IDE的CodeGeeX插件。

2. CodeGeeX2
CodeGeeX2是多语言代码生成模型 CodeGeeX (KDD’23) 的第二代模型。不同于一代 CodeGeeX(完全在国产华为昇腾芯片平台训练) ,CodeGeeX2 是基于 ChatGLM2 架构加入代码预训练实现,得益于 ChatGLM2 的更优性能,CodeGeeX2 在多项指标上取得性能提升(+107% > CodeGeeX;仅60亿参数即超过150亿参数的 StarCoder-15B 近10%),更多特性包括:

1)更强大的代码能力:基于 ChatGLM2-6B 基座语言模型,CodeGeeX2-6B 进一步经过了 600B 代码数据预训练,相比一代模型,在代码能力上全面提升,HumanEval-X 评测集的六种编程语言均大幅提升 (Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321%),在Python上达到 35.9% 的 Pass@1 一次通过率,超越规模更大的 StarCoder-15B。
2)更优秀的模型特性:继承 ChatGLM2-6B 模型特性,CodeGeeX2-6B 更好支持中英文输入,支持最大 8192 序列长度,推理速度较一代 CodeGeeX-13B 大幅提升,量化后仅需6GB显存即可运行,支持轻量级本地化部署。
3)更全面的AI编程助手:CodeGeeX插件(VS Code, Jetbrains)后端升级,支持超过100种编程语言,新增上下文补全、跨文件补全等实用功能。结合 Ask CodeGeeX 交互式AI编程助手,支持中英文对话解决各种编程问题,包括且不限于代码解释、代码翻译、代码纠错、文档生成等,帮助程序员更高效开发。
4)更开放的协议:CodeGeeX2-6B 权重对学术研究完全开放,填写登记表申请商业使用。
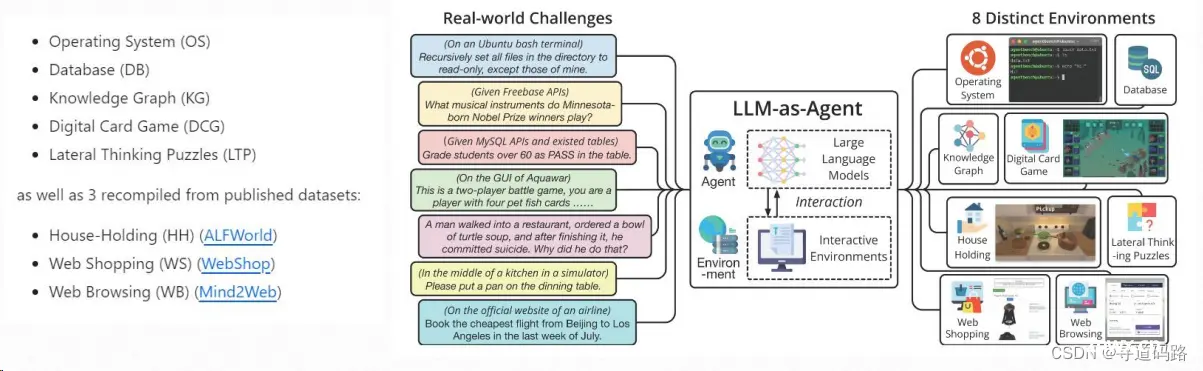
九、GLM家族之AgentBench和AgentTuning
AgentBench是第一个系统性的基准测试,用于评估LLM作为智能体在各种真实世界挑战和8个不同环境中的表现。AgentTuning技术能够激活模型的智能规划和执行能力
总结
GLM大模型系列不仅代表了智谱AI的技术成果,也反映了中国在AI领域能与国际巨头并肩前行的决心与实力。随着技术的不断迭代与应用的深化,我们有理由相信,国产大模型将在世界AI的舞台上发挥更加重要的作用。
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。