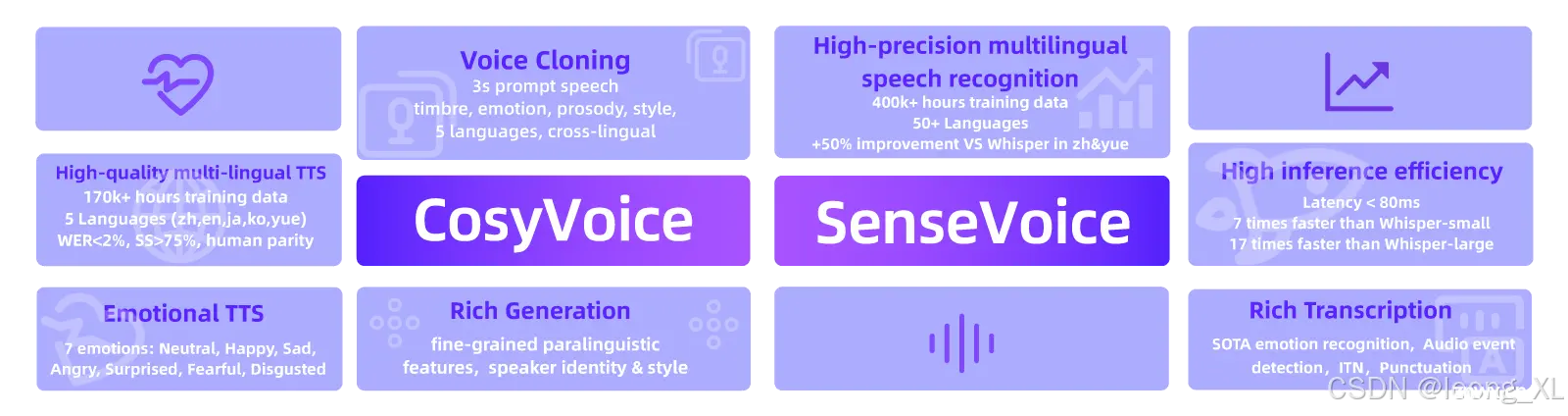
参考:https://fun-audio-llm.github.io/在线体验:https://modelscope.cn/studios/iic/CosyVoice-300M参考:https://github.com/FunAudioL...
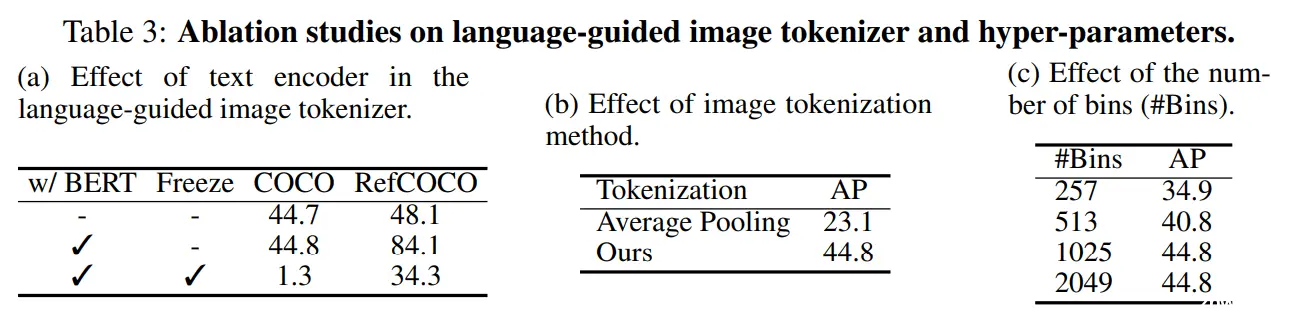
本文是关于NIPS2024论文VisionLLM的简要介绍。VisionLLM是一个多模态的大语言模型框架,可以借助大语言模型的力量,实现自定义的传统视觉任务,例如检测、分割、图像标题等。框架最大的特点就是灵活性...

超详细从0-1部署ChatGLM2-6B-INT4(6GB),双卡2070Super8GB*2,后续一步一步对大模型进行微调测试!...

为了完成我们的任务,我们将使用HuggingFaceEmbeddings类,这是一个本地管道包装器,用于与HuggingFaceHub上托管的GTE模型进行交互。它的工作原理如下:我们设置了一个名为queryi...
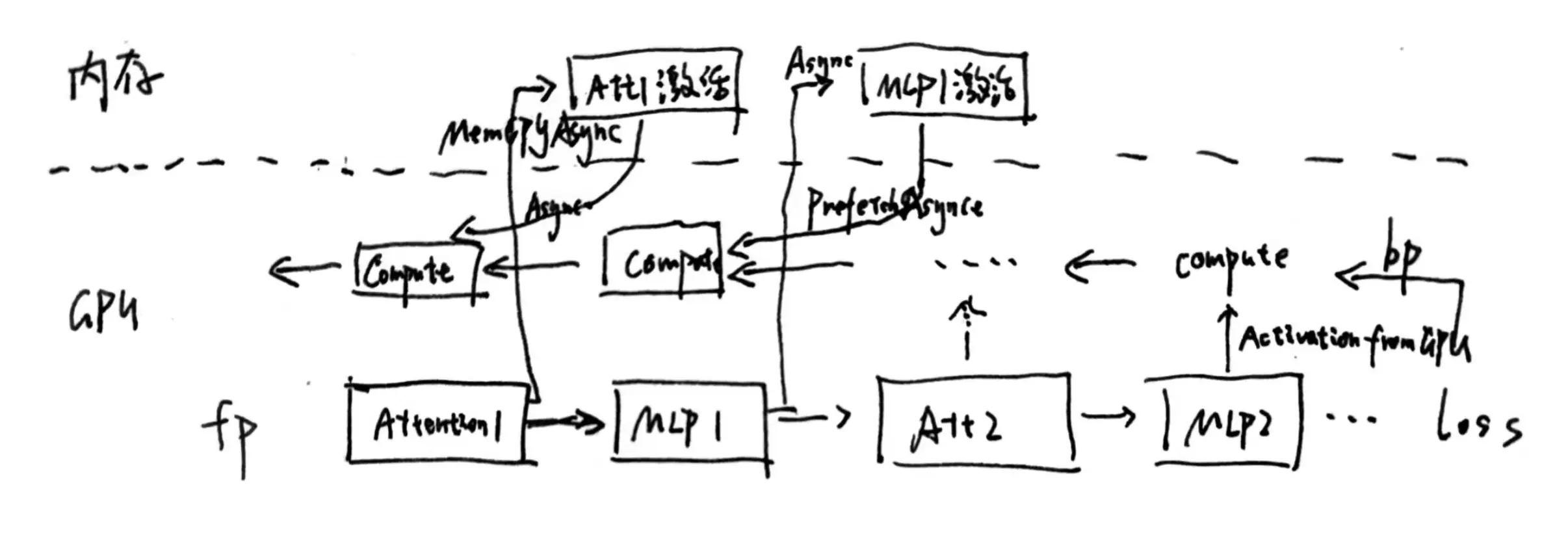
LLM训练activation优化相关技术,包括激活重计算/序列并行/zero-R/zero-offload等...

大家好,我是yma16,本期分享【香橙派AIpro评测】烧系统到部署到体验AI应用样例:香橙派AIpro烧系统到体验AI应用样例(新手福音)香橙派AIproOrangePiAIPro开发...

AnythingLLM、LocalGPT和PrivateGPT都是与大语言模型(LLM)相关的项目,它们允许用户在本地环境中与文档进行交互,但它们在实现方式和特点上存在一些差异。AnythingLLM使用Pinec...
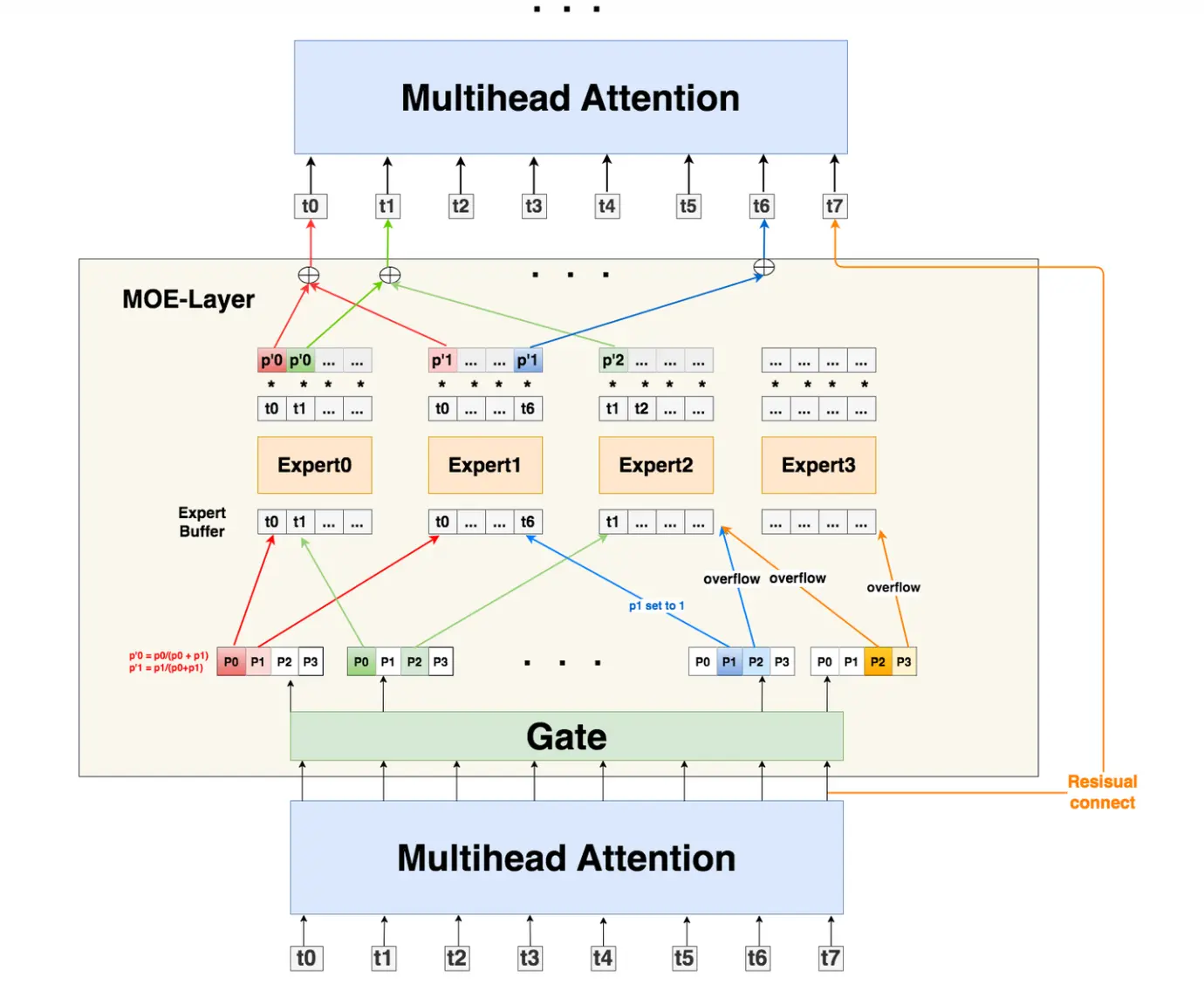
前置知识MOE(MixerOfExpert)moe的主要原理是替换attention层后的MLP层,通过将不同类型的token按照门控单元计算出的概率分配给最大概率处理的专家网络处理,对比单一MLP更适合处理复杂多样化的数据集.主要思想和集成学习感觉...

这篇文章的作者来自开源人工智能框架Ray的开发公司Anyscale。主要贡献者是Google前首席工程师WaleedKadous。他也曾担任UberCTO办公室工程战略负责人。其中一位华人合作者是Google前员工HuaiweiS...

而在Triton+vLLM的组合中,Triton不会做任何的调度处理,而是将请求全部打给vLLM,让vLLM根据PagedAttention和异步API自行处理请求,vLLM的调度策略更适配大语言模型decode...