LLM-01 大模型 本地部署运行 ChatGLM2-6B-INT4(6GB) 简单上手 环境配置 单机单卡多卡 2070Super8GBx2 打怪升级!
武子康 2024-07-22 08:13:00 阅读 100
超详细从0-1部署ChatGLM2-6B-INT4(6GB),双卡 2070 Super 8GB * 2,后续一步一步对大模型进行微调测试!
搬迁说明
之前在 CSDN 上发文章,一直想着努力发一些好的文章出来!这篇文章在 2024-04-17 10:11:55 已在 CSDN 发布
写在前面
其他显卡环境也可以!但是最少要有8GB的显存,不然很容易爆。
如果有多显卡的话,单机多卡也是很好的方案!!!
背景介绍
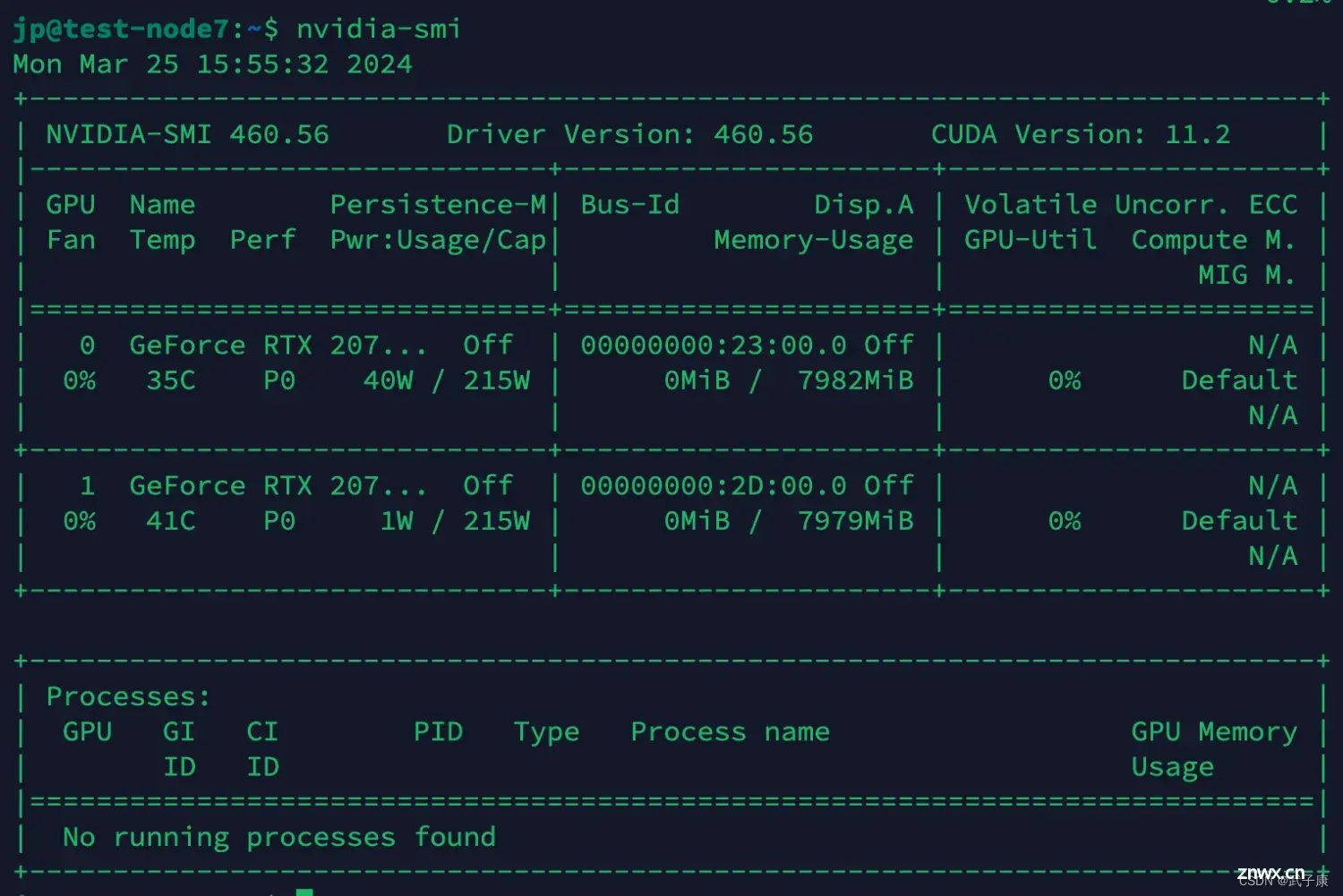
目前借到一台算法组的服务器,我们可以查看一下目前显卡的情况
<code>nvidia-smi
PS: (后续已经对CUDA等进行了升级,可看我的其他文章,有升级的详细过程)
项目地址
官方的地址:
<code># 需要克隆项目
https://github.com/THUDM/ChatGLM2-6B
# 模型下载(如果你没有科学,麻烦一点需要手动下载)
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b-int4&mode=list
# 模型下载(如果可以科学,官方下载的体验是比较舒适的)
https://huggingface.co/THUDM/chatglm2-6b-int4
我们需要对项目进行克隆,同时需要下载对应的模型,如果你有科学,可以忽略模型的下载,因为你启动项目的时候它会自己下载。
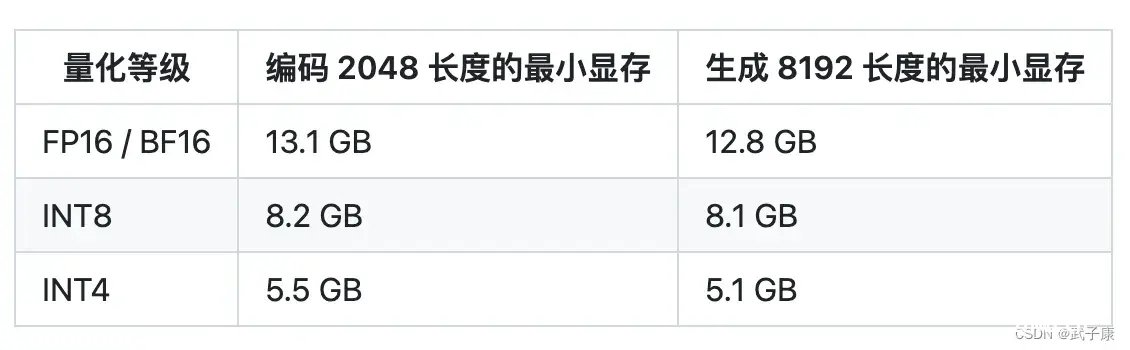
配置要求
根据官方的介绍,可以看到对应的显卡要求,根据我的情况(2070Super 8GB * 2),我这里选择下载了INT4的模型。
安装Pyenv
由于很多不同的项目队python版本的要求不同,同时对版本的要求也不同,所以你需要配置一个独立的环境。
这里你可以选择 <code>Conda,也可以选择pyenv,或者docker。我选的方案是:pyenv
# pyenv 官方地址
https://github.com/pyenv/pyenv
安装完成之后,记得配置一下环境变量:
<code>echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrccode>
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrccode>
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
如果你和我一样使用的是 ZSH 的话:
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrccode>
echo '[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrccode>
echo 'eval "$(pyenv init -)"' >> ~/.zshrc
测试Pyenv
# 查看当前系统中的Python情况
pyenv versions
使用Pyenv
# Python版本
pyenv local 3.10
# 独立环境
python -m venv env
# 切换环境
source env/bin/active
# cd 到项目目录
# 安装Python库 pip install - requirements.txt
你将看到类似的内容,我这里在 MacBook 上测试的:

安装依赖
<code># Python版本
pyenv local 3.10
# 独立环境
python -m venv env
# 切换环境
source env/bin/active
# cd 到项目目录
# 安装Python库 pip install - requirements.txt

<code>注意: 这是两个部分:(这是我服务器的配置,你也要搞清楚你的内容放置在哪里) 如下图:
- 项目文件夹 /home/jp/wzk/chatglm2-6b-int4/ChatGLM2-6B
- 模型文件夹 /home/jp/wzk/chatglm2-6b-int4/chatglm2-6b-int4
项目文件夹:

模型文件夹

启动项目
在项目的目录下,我们利用现成的直接启动:web_demo.py
<code># 先打开看一眼
vim web_demo.py
model_path 是你下载的模型文件夹(如果你不是手动下载的话,可以不改,这样的话会自动下载)

<code>PS: 此时需要到最后一行,修改对外暴露服务
# 代码修改为这样
demo.queue().launch(server_name="0.0.0.0", server_port=7861, share=False, inbrowser=True)code>
退出保存,我们启动服务:
python web_demo.py
使用项目
完成上述的操作,稍等后看到:
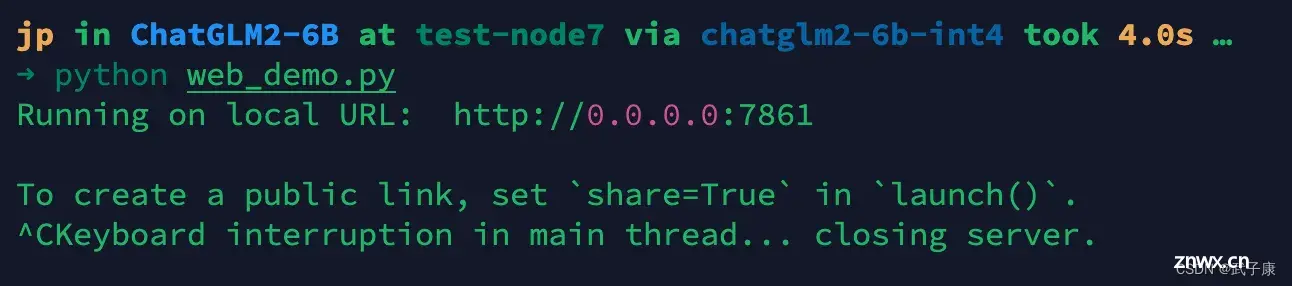
根据你的服务器IP和端口,访问即可:

多卡启动
由于单卡很容易爆 OOM,正好这里是 2 * 2070Super 8GB,我们简单的修改一下代码,就可以将模型分到两张显卡中。
官方给的方案是,通过accelerate库来启动。
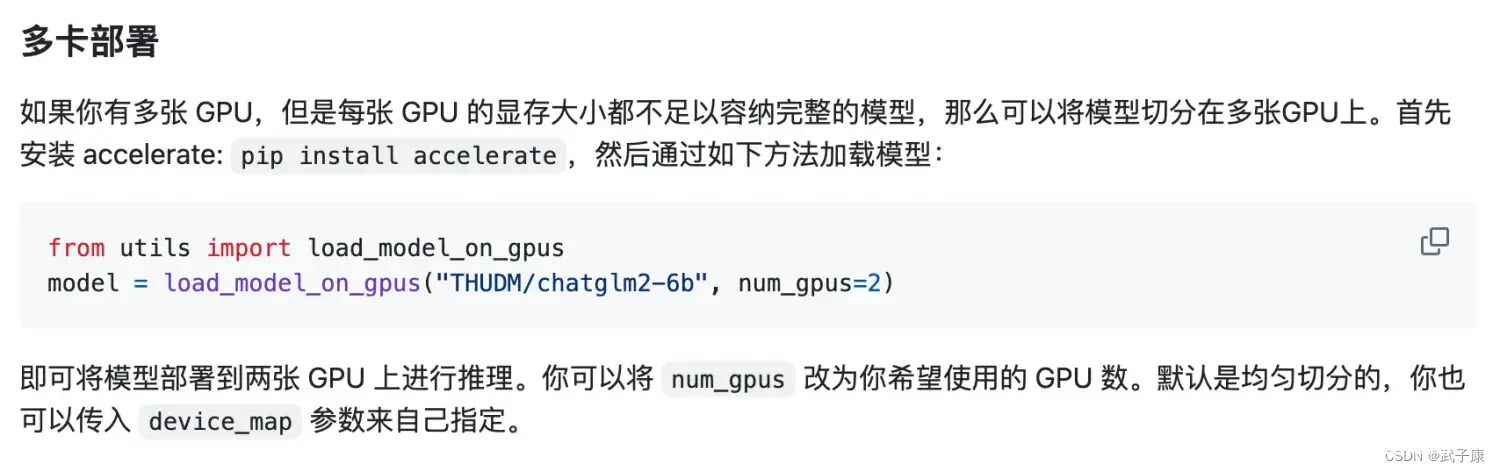
修改刚才的 web_demo.py,详细位置请看图:
<code># GPU 数量修改为2
model = load_model_on_gpus(model_path, num_gpus=2)

重新启动即可,就已经是多卡启动了!!!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。