一文搞懂LLM大模型!LLM从入门到精通万字长文(2024.7月最新)
哥兜兜有糖 2024-08-18 08:31:06 阅读 83
LLM从入门到精通精品文章

目录
一、LLM基本概念
二、LLM发展历程
三、LLM大模型的分类
四、LLM主流大模型类别
五、LLM大模型建立的流程
六、Fine-Tuning
七、Prompt-Tuning
八、超大规模参数模型Prompt-Tuning方法
8.1上下文学习 In-Context Learning
8.2.指令学习 Instruction- Tuning
8.3 思维链Chain-of-Thought
九、Prefix-Tuning
十、LoRA

一、LLM基本概念
大模型LLM(Large Language Model)是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。
LLM的使用场景非常广泛。首先,LLM可以用于文本生成,可以生成连贯的段落、文章、对话等,可以应用于自动写作、机器翻译等任务中。其次,LLM可以用于问答系统,可以回答复杂的问题,甚至进行对话式问答。再者,LLM可以用于语义理解和推理,可以进行情感分析、命名实体识别、文本分类等任务。此外,LLM还可以用于智能助理、机器人交互、自动摘要、信息提取等应用领域。总的来说,LLM在自然语言处理和人工智能领域都有很大的潜力,可以提供更加智能和自然的人机交互体验。
二、LLM发展历程
截止目前,语言模型发展走过了三个阶段:
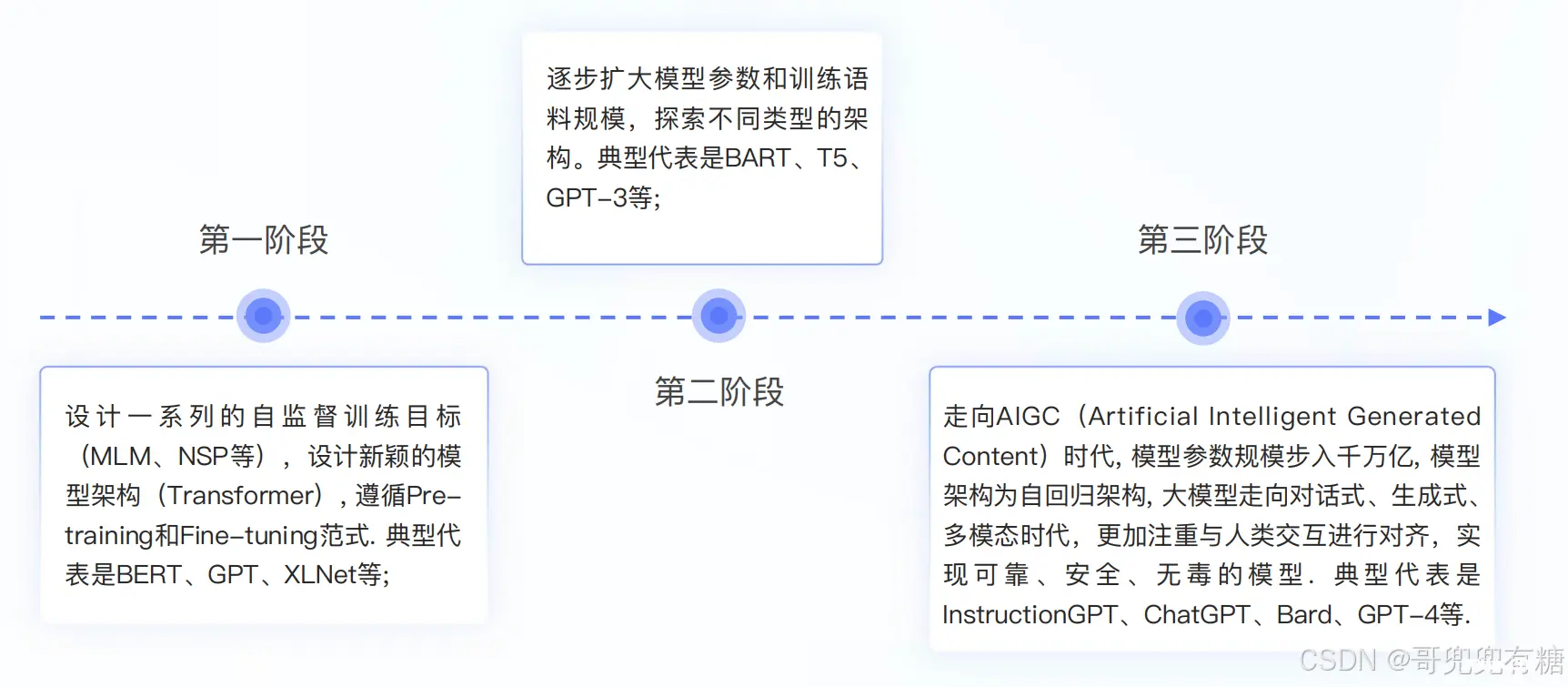
三、LLM大模型的分类
按照输入数据类型的不同,LLM大模型主要可以分为以下三大类:
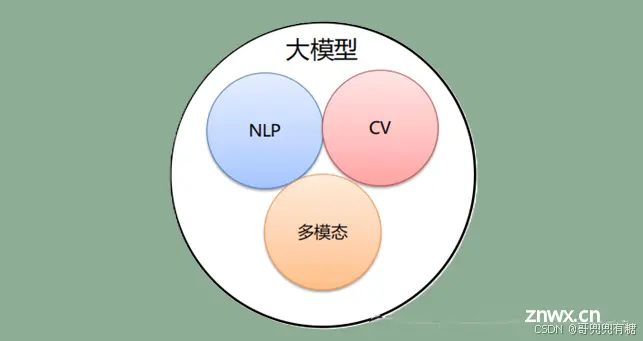
语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT系列(OpenAI)、Bard(Google)、文心一言(百度)。
视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。例如:VIT系列(Google)、文心UFO、华为盘古CV、INTERN(商汤)。
多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了NLP和CV的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB多模向量数据库(九章云极DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
四、LLM主流大模型类别
随着ChatGPT迅速火爆,引发了大模型的时代变革,国内外各大公司也快速跟进生成式AI市场,近百款大模型发布及应用。开源语言大模型种类有以下4个:

1 ChatGLM-6B模型简介:
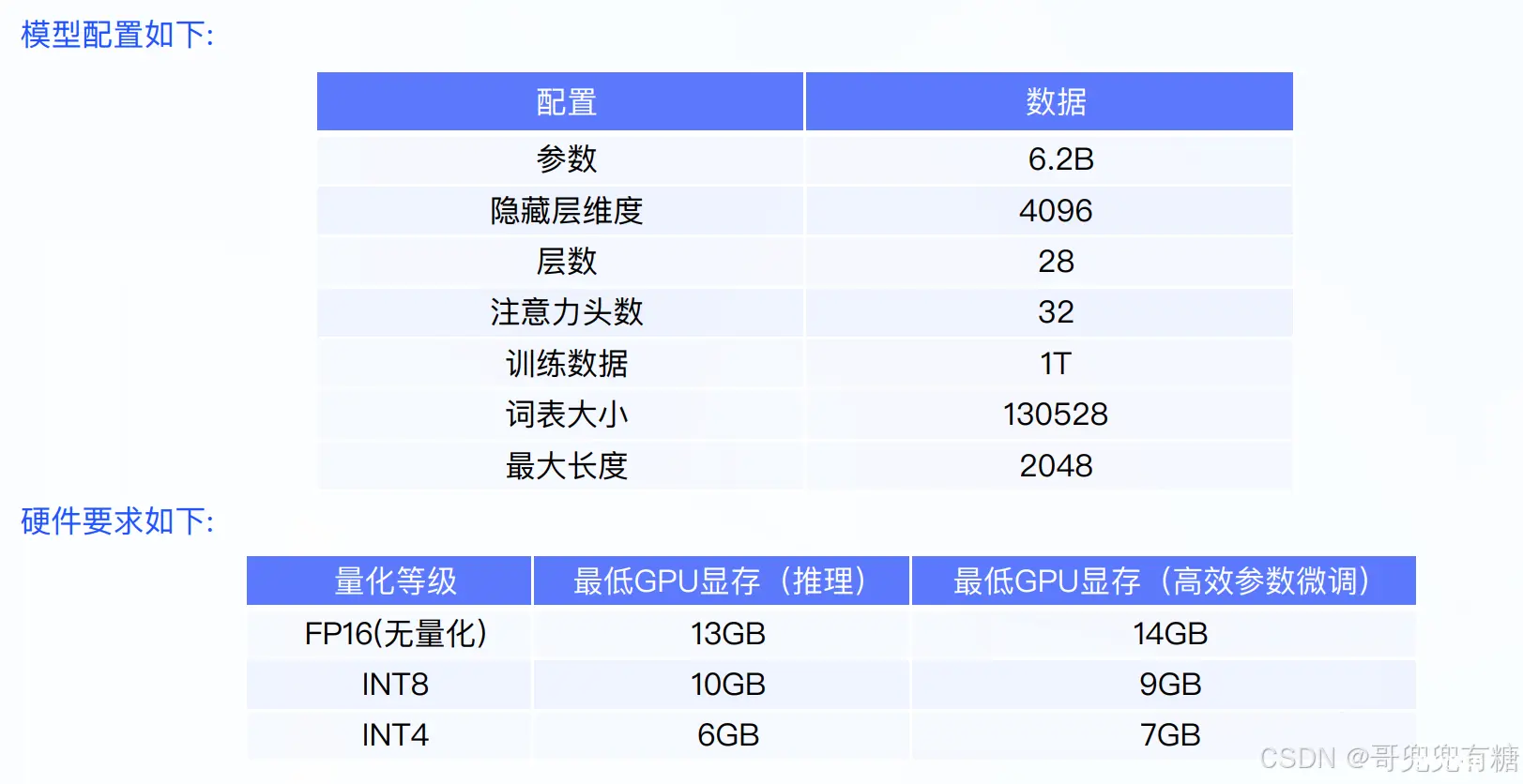
ChatGLM-6B 是清华大学提出的一个开源、支持中英双语的对话语言模型,基于General LanguageModel (GLM) 架构,具有 62 亿参数.该模型使用了和 ChatGPT 相似的技术,经过约 1T 标识符的中英双语训练(中英文比例为1:1),辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答(目前中文支持最好).
GLM是一种基于自回归空白填充目标的通用预训练框架. GLM 将 NLU 任务转化为包含任务描述的完形填空问题,可以通过自回归生成的方式来回答.
原理:在输入文本中随机挖去一些连续的文本片段,然后训练模型按照任意顺序重建这些片段.
完形填空问题是指在输入文本中用一个特殊的符号(如[MASK])替换掉一个或多个词,然后训练模型预测被替换掉的词.
优点:较低的部署门槛: INT4 精度下,只 需6GB显存,使得 ChatGLM-6B 可 以部署在消费级显卡上进行推理. 更长的序列长度: 相比 GLM-10B (序列长度1024),ChatGLM2-6B 序列长度达32K,支持更长对话和应 用。 人类类意图对齐训练。
缺点:模型容量小,相对较弱的模型记忆和语言能力。 多轮对话能力较弱。
模型配置(6B)与硬件要求:
2 LLaMA模型简介:
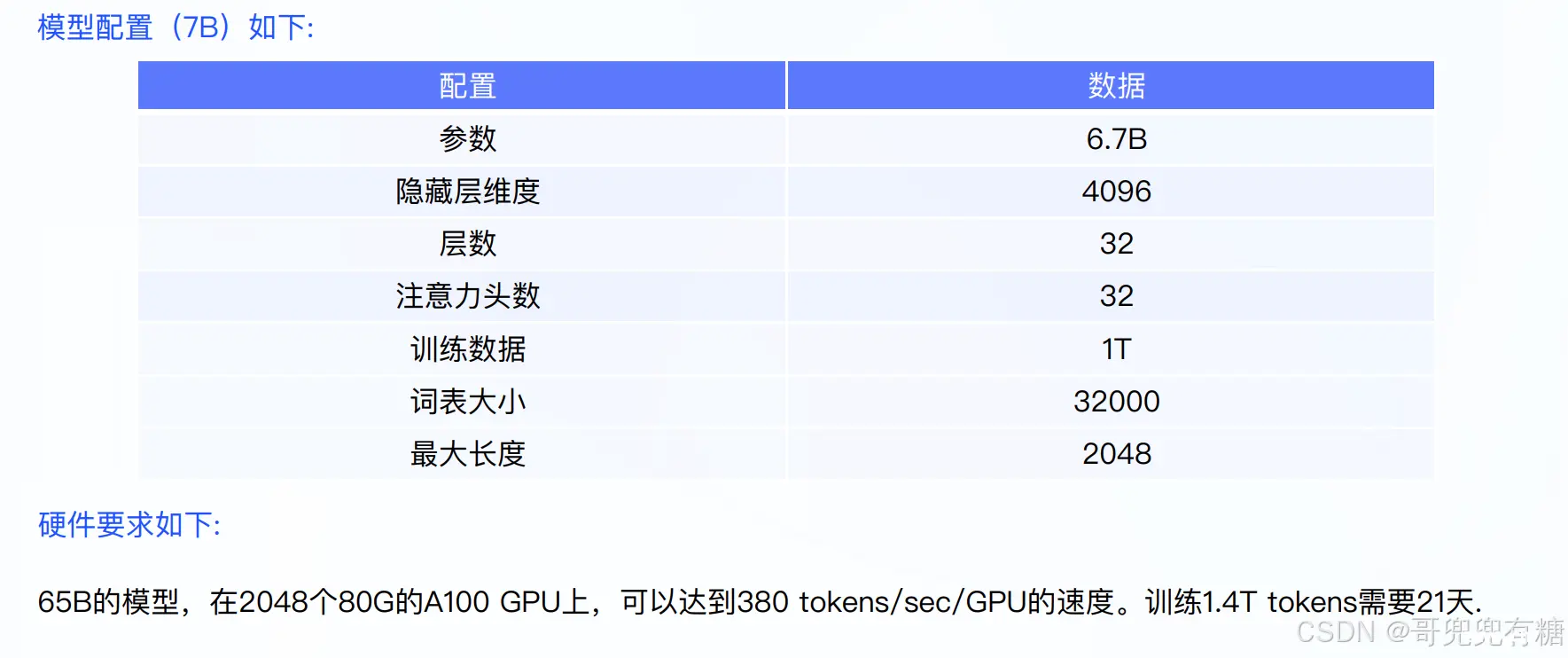
LLaMA(Large Language Model Meta AI),由 Meta AI 于2023年发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本. LLaMA训练数据是以英语为主的拉丁语系,另外还包含了来自 GitHub 的代码数据。训练数据以英文为主,不包含中韩日文,所有训练数据都是开源的。其中LLaMA-65B 和 LLaMA-33B 是在 1.4万亿 (1.4T) 个token上训练的,而最小的模型 LLaMA-7B 和LLaMA-13B 是在 1万亿 (1T) 个 token 上训练的.
LLaMA 的训练目标是语言模型,即根据已有的上文去预测下一个词
优点 : 具有 130 亿参数的 LLaMA 模型 「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿). 可以在单块 V100 GPU 上运行; 而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla70B 和 PaLM-540B.
缺点:会产生偏见性、有毒或者虚假的内容. 在中文上效果差,训练语料不包含中文或者一个汉字切分为多个token,编码效率低,模型学习难度大.
模型配置(7B)与硬件要求:
3 BLOOM模型简介
BLOOM系列模型是由 Hugging Face公司训练的大语言模型. 训练数据包含了英语、中文、法语、西班牙语、葡萄牙语等共 46 种语言,另外还包含 13 种编程语言. 1.5TB 经过去重和清洗的文本,其中中文语料占比为16.2%. 按照模型参数量,BLOOM 模型有 560M、1.1B、1.7B、3B、7.1B 和 176B 这几个不同参数规模的模型.
BLOOM 的训练目标是语言模型,即根据已有的上文去预测下一个词
优点:具有良好的多语言适 应性,能够在多种语 言间进行切换,且无 需重新训练.
缺点:会产生偏见性、有毒或者虚假的内容.
模型配置(176B)与硬件要求
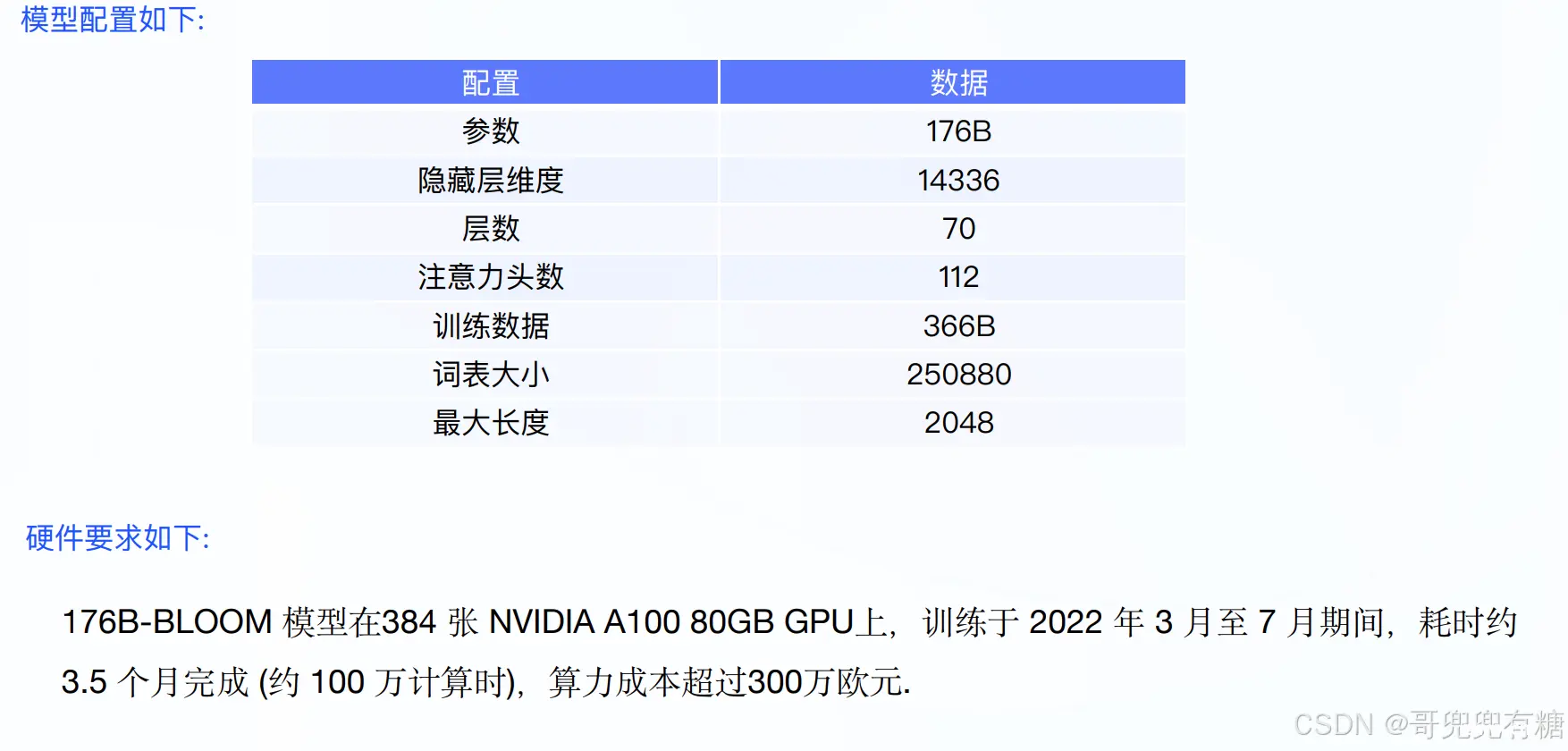
4 Baichuan-7B模型
Baichuan-7B由百川智能于2023年6月发布的一个开放且可商用的大型预训练语言模型,其支持中英双语,是在约 1.2万亿 (1.2T) 个 token上训练的70亿参数模型.
Baichuan-7B 的训练目标也是语言模型,即根据已有的上文去预测下一个词。
模型配置(7B)与模型特点:

五、LLM大模型建立的流程
LLM(Large Language Model)大模型训练的流程一般涉及以下几个阶段:
1. 数据收集和预处理:首先需要收集大量的训练数据,这些数据可以是从互联网上收集的文本数据,也可以是从现有的数据集中获取的。收集的数据需要进行预处理,包括去除噪声、标记化、分词等操作。
2. 构建模型架构:选择适合的模型架构来搭建LLM模型,常见的架构包括Transformer、BERT等。
3. 模型预训练:大模型首先在大量的无标签数据上进行训练,预训练的最终目的是让模型学习到语言的统计规律和一般知识。在这个过程中模型能够学习到词语的语义、句子的语法结构、以及文本的一般知识和上下文信息。需要注意的是,预训练本质上是一个无监督学习过程;得到预训练模型(Pretrained Model), 也被称为基座模型(Base Model),模型具备通用的预测能力。如GLM-130B模 型、OpenAI的A、B、C、D四大模型,都是基座模型;
4. 微调:在微调阶段,LLM使用特定的数据集进行训练,以适应特定的任务或应用。这个阶段通常使用迁移学习的方法,将预训练的模型作为基础,在特定任务上进行微调。
5. 模型评估:训练完成后,需要对训练得到的模型进行评估。评估的方式可以是计算模型在验证集或测试集上的准确率、召回率等指标。同时,也可以对生成的文本进行人工评估,判断模型生成的文本是否符合预期。
6. 模型部署和优化:训练完成后,需要将模型进行部署,可以通过将模型封装成API接口的形式提供给用户使用。同时,也可以进行模型的优化,如模型压缩、量化等,以提高模型的效率和性能。
需要注意的是,LLM大模型训练的过程通常需要大量的计算资源和时间,并且在训练过程中需要进行大规模的参数更新,因此需要有高效的训练算法和计算平台来支持。
六、Fine-Tuning
首先解释一下什么是Prompt?
prompt顾名思义就是“提示”的意思,应该有人玩过你画我猜这个游戏吧,对方根据一个词语画一幅画,我们来猜他画的是什么,因为有太多灵魂画手了,画风清奇,或者你们没有心有灵犀,根本就不好猜啊!这时候屏幕上会出现一些提示词比如3个字,水果,那岂不是好猜一点了嘛。
Fine-Tuning属于一种迁移学习方式,在自然语言处理(NLP)中,Fine-Tuning是用于将预训练的语言模型适应于特定任务或领域。Fine-Tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它.
Fine-Tuning的目的是把模型适配到特定的任务上!
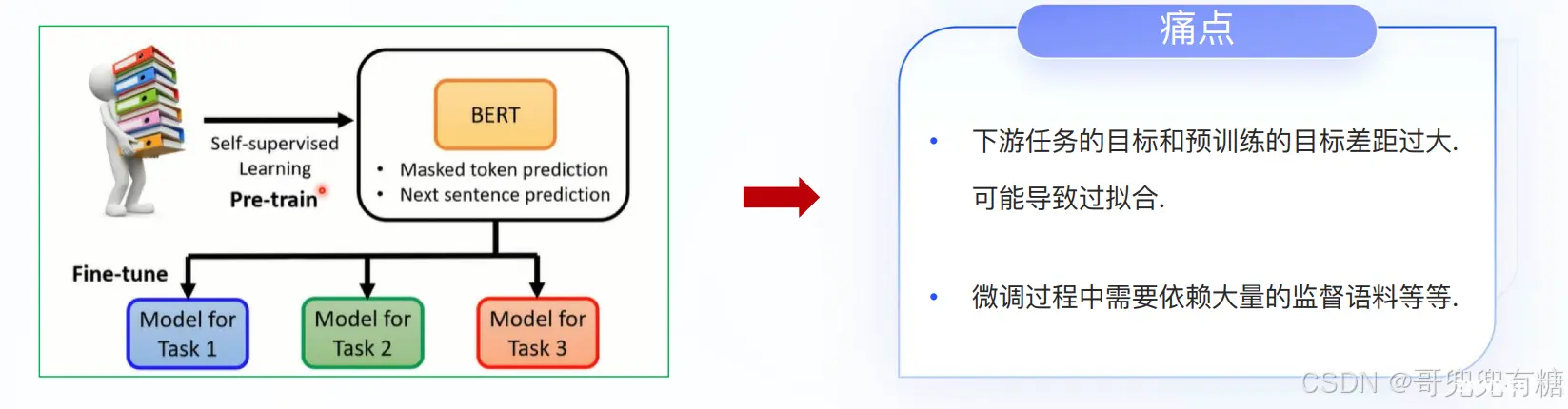
解决方法:Prompt-Tuning, 通过添加模板的方法来避免引入额外的参数,从而让模型可以在小样本(few-shot)或者零样本(zero-shot)场景下达到理想的效果 。
七、Prompt-Tuning
Prompt-Tuning方法是一种用于改进语言模型的训练方法,是由谷歌提出的一种轻量级的优化方法。在语言模型中,Prompt是一个前缀文本,用于指导生成的文本内容。Prompt-Tuning方法通过对Prompt进行优化,使其能够更好地引导模型生成符合预期的文本。
基于Fine-Tuning的方法是让预训练模型去迁就下游任务,而基于Prompt-Tuning的方法可以让下游任务去迁就预训练模型, 其目的是将Fine-tuning的下游任务目标转换为Pre-training的任务.
传统的语言模型训练方法通常使用大量的无标签文本来预训练模型,然后使用有标签数据进行微调。然而,这种方法存在一些问题,例如模型生成的文本可能缺乏准确性和一致性。Prompt-Tuning方法通过添加或调整Prompt,可以更精确地指导模型生成特定类型的文本。具体来说,Prompt-Tuning方法有以下几个步骤:
1. 创建Prompt:根据任务需求,设计一个能够引导生成文本的Prompt。Prompt可以是一个简单的问题、一句话的描述、或者一段指令等。
2. 选择优化策略:根据不同的优化目标,选择适当的优化策略。常见的策略包括Prompt Engineering、Prompt Language Modeling、Prompt Optimization等。
3. 优化Prompt:根据选择的优化策略,在训练数据中对Prompt进行优化。这可以包括通过梯度下降方法调整Prompt的权重,或者通过生成和筛选多个Prompt进行优选。
4. 微调模型:使用优化后的Prompt和有标签数据对模型进行微调,以便模型能够更好地生成符合Prompt要求的文本。
通过使用Prompt-Tuning方法,可以提高语言模型生成文本的准确性和一致性,并且能够更好地指导模型生成特定类型的文本,适用于各种任务,例如机器翻译、对话系统、摘要生成等。
八、超大规模参数模型Prompt-Tuning方法
近两年来,随着Prompt-Tuning技术的发展,对于超过10亿参数量的模型来说,Prompt-Tuning所带来的增益远远高于标准的Fine-tuning. 如GPT-3模型, 只需要设计合适的模板或指令即可以实现免参数训练的零样本学习.
根本原因:模型参数量足够大,训练过程中使用了 足够多的语料,同时设计的 预训练任务足够有效.
该方法在参数规模非常大的模型微调时效果很好,当参数规模达到 100亿时和全量微调效果一致。
面向超大规模的模型的Prompt-Tuning方法有三种:
1.上下文学习 In-Context Learning :直接挑选少量的训练样本作为该任务的提示.。
2.指令学习 Instruction- Tuning :构建任务指令集,促使模型根据任务指令做出反馈。
3.思维链Chain-of-Thought :给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。

8.1上下文学习 In-Context Learning
In-Context learning(ICL)最早在GPT3中提出, 旨在从训练集中挑选少量的标注样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应的结果,有以下三种学习方式。

8.2.指令学习 Instruction- Tuning
其实Prompt-Tuning本质上是对下游任务的指令,简单的来说:就是告诉模型需要做什么任务,输出什么内容. 上文我们提及到的离散或连续的模板,本质上就是一种对任务的提示.
因此, 在对大规模模型进行微调时, 可以为各种类型的任务定义更明显的指令, 并进行训练,来提高模型对不同任务的泛化能力.
举个例子:
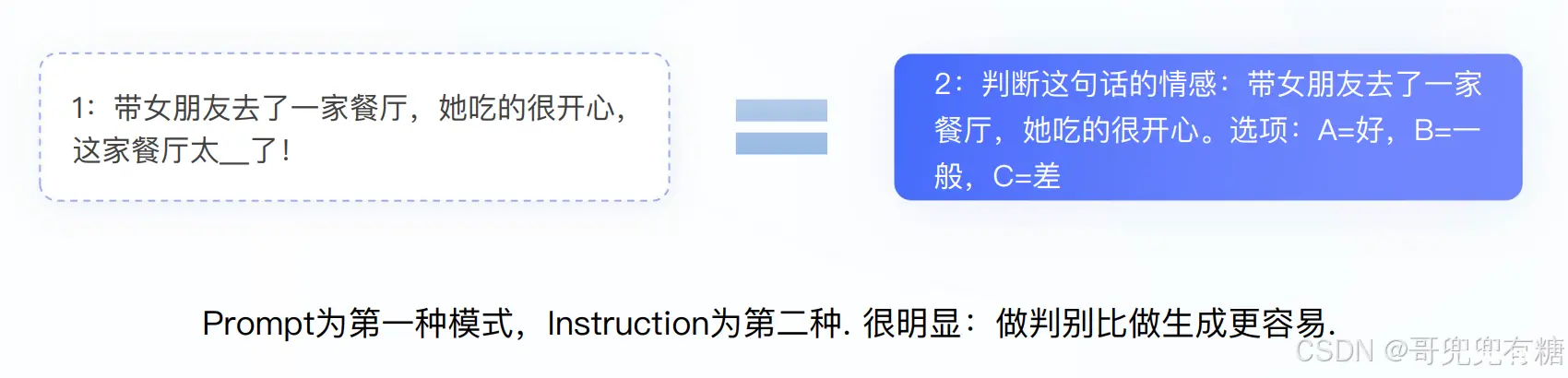
指令学习和Prompt的区别是什么?
指令学习激发语言模型的理解能力;指令学习激发语言模型的补全能力.
8.3 思维链Chain-of-Thought
思维链方法的核心思想是将思考的过程及其相关的观念和想法串联起来,形成一个连续的思维链条。这种链条可以由线性或非线性的思维过程构成,从而帮助模型不断延伸和扩展思考。相比于之前传统的上下文学习(即通过x1,y1,x2 ,y2 ,....xtest作为输入来让大模型补全输出ytest),思维链多了中间的推导提示.
九、Prefix-Tuning
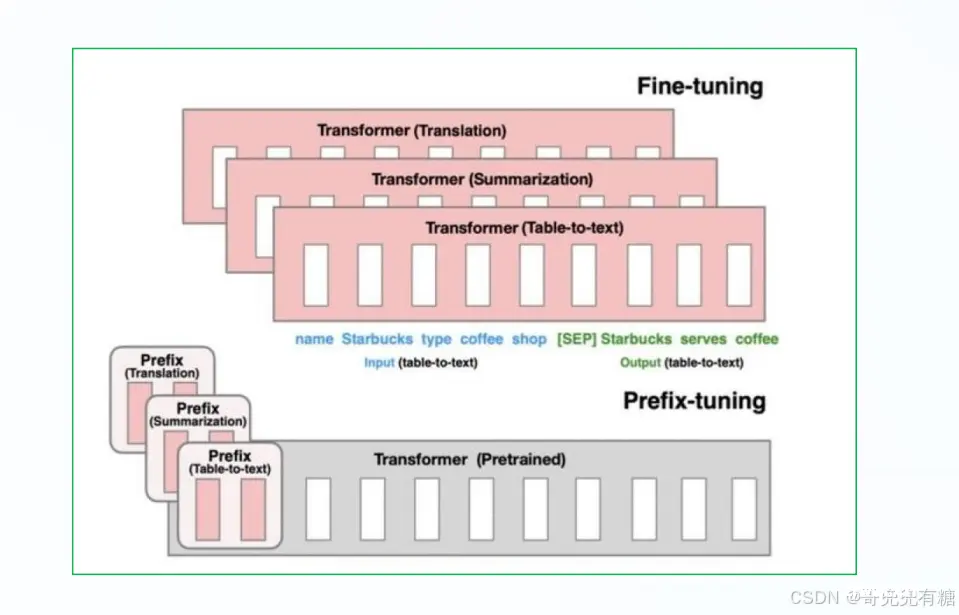
2021年斯坦福大学论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》中提出了PrefixTuning 方法,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定.
原理简述:在原始模型基础上,增加一个可被训练的Embedding 层,用于给提示词增加前缀进行信息过滤,从而让模型更好的理解提示词意图, 并在训练过程中不断优化这些参数;
优点:Prefix Tuning既能够在模型结构上增加一些新的灵活性,又能够在模型使用上提供一种自动的、能够改进模型表现的提示机制;
十、LoRA
低秩适应(Low-Rank Adaptation,LoRA)是一种参数高效的微调技术,LoRA是最早由微软研究院发布的一项微调技术; 其核心思想是对大型模型的权重矩阵进行隐式的低秩转换,也就是:通过一个较低维度的表示来近似表示一个高维矩阵或数据集。
LoRA 原理:
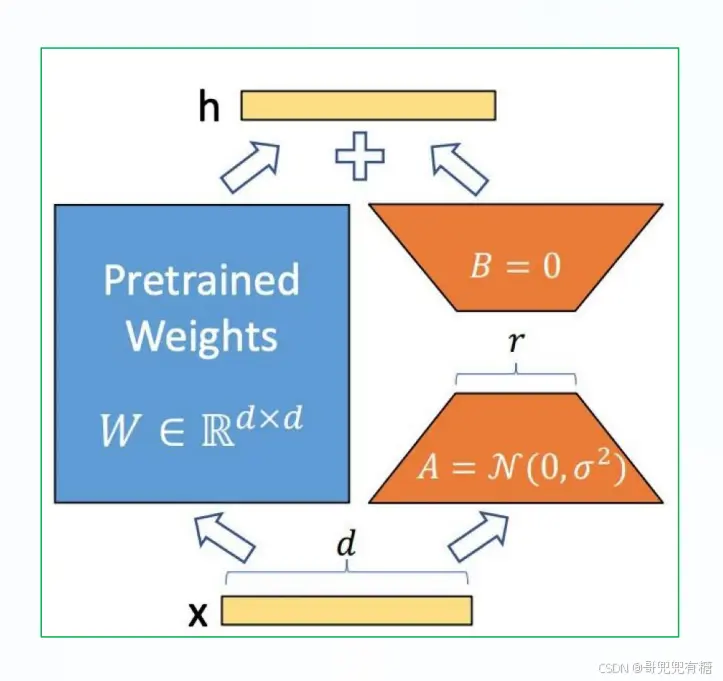
LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的Linear层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。
简而言之:基于大模型的内在低秩特性,LoRA通过在模型的权重矩阵中添加一个低秩矩阵来实现微调。这个低秩矩阵可以看作是对原始权重矩阵的一个小的调整,它不会显著改变模型的参数规模,但可以有效地捕捉到特定任务的特征。
点个收藏,持续更新中。。。
上一篇: LangGraph Studio:首款智能体(agent)IDE
下一篇: 【香橙派】Orange pi AIpro开发板评测,看小白如何从0到1快速入门,以及亲测手写数字识别模型训练与推理
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。