2024年最佳AI大模型-LLM排名(非常详细)零基础入门到精通,收藏这一篇就够了
Python_chichi 2024-08-10 10:31:02 阅读 74
2024年的技术趋势包括生成式AI和大型语言模型(LLMs)用于AI聊天机器人。OpenAI的GPT-4模型是最佳的大型语言模型,具有复杂推理理解、高级编码能力等特点。其他优秀的模型包括Google的PaLM 2和Anthropic的Claude v1。此外,开源模型如Falcon、LLaMA和Guanaco也展现出强大的性能。
几个关键的发展焦点:
OpenAI的GPT-4模型
GPT-4是当前最先进的大型语言模型之一,由OpenAI开发。它具有复杂的推理理解能力和高级编码功能,使其在自然语言处理任务中表现卓越,包括但不限于文本生成、摘要、翻译和对话系统。
Google的PaLM 2
Google的Pathways Language Model (PaLM) 2代表了其语言模型的最新进展,展示了在多任务学习和多模态任务中的强大能力。PaLM 2通过改进的训练技术和算法优化,提高了模型的效率和灵活性。
Anthropic的Claude v1
由Anthropic开发的Claude v1是另一个高性能的大型语言模型,它在保持响应质量的同时,优化了对话管理和情境适应能力,特别是在长对话中表现出良好的连贯性和一致性。
开源模型:Falcon、LLaMA和Guanaco
开源社区也不断推出具有竞争力的模型,如Falcon、LLaMA和Guanaco,这些模型在Hugging Face等平台上广受欢迎。它们提供了一个低成本且灵活的选择,使得研究人员和开发者可以在不受商业许可限制的情况下,探索和实验AI的各种可能性。
Cohere和GPT4All
Cohere:一家AI初创公司,提供多种基于最新研究的模型,支持企业和开发者在自然语言处理任务中实现更精准的结果。
GPT4All:这是一个开源项目,旨在使用户能够在本地计算机上方便地运行大型语言模型,减少对云计算资源的依赖,增强数据隐私和安全性。
在 OpenAI 发布 ChatGPT 之后,打造最佳LLM产品的竞赛已经增长了数倍。大公司、小型创业公司和开源社区正在努力开发最先进的大型语言模型。到目前为止,已经发布了数百多个LLMs,但哪些是最有能力的?
1. GPT-4
OpenAI 的 GPT-4 模型是 2024 年最好的 AI 大型语言模型 (LLM)。GPT-4 模型于 2023 年 3 月发布,展示了具有复杂推理理解、高级编码能力、熟练参加多项学术考试、表现出人类水平表现的技能等的巨大能力
事实上,它是第一个可以同时接受文本和图像作为输入的多模态模型。尽管 ChatGPT 尚未添加多模态功能,但一些用户已经可以通过由 GPT-4 模型提供支持的 Bing Chat 进行访问。
除此之外,GPT-4 是为数不多的LLMs解决幻觉并将事实性提高一英里的产品之一。与 ChatGPT-3.5 相比,GPT-4 模型在多个类别的事实评估中得分接近 80%。OpenAI 还不遗余力地使用人类反馈强化学习 (RLHF) 和领域专家的对抗性测试,使 GPT-4 模型更符合人类价值观。
GPT-4 模型已经过 1+ 万亿个参数的训练,支持最大上下文长度为 32,768 个令牌。到目前为止,我们还没有太多关于 GPT-4 内部架构的信息,但最近 The Tiny Corp 的 George Hotz 透露,GPT-4 是一个混合模型,有 8 个不同的模型,每个模型有 2200 亿个参数。基本上,如前所述,它不是一个大的密集模型。
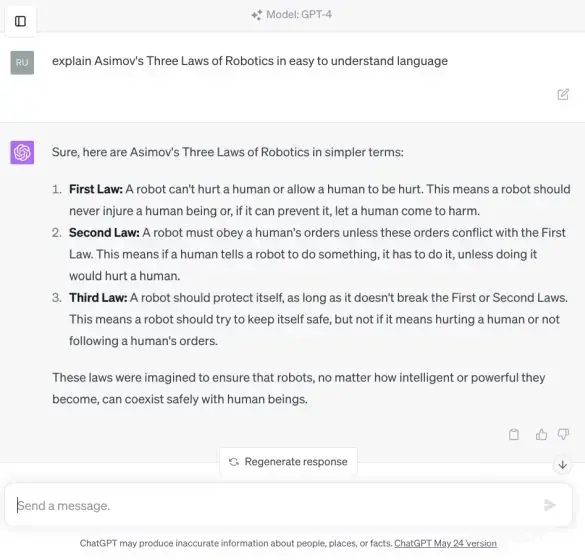
最后,您可以使用 ChatGPT 插件并使用 GPT-4 模型通过 Bing 浏览网页。唯一的缺点是响应速度慢,推理时间要长得多,这迫使开发人员使用较旧的 GPT-3.5 模型。总的来说,OpenAI GPT-4 模型是迄今为止你能在 2024 年使用的最好的LLM模型,如果你打算将它用于严肃的工作,我强烈建议订阅 ChatGPT Plus。它的价格为 20 美元,但如果您不想付费,您可以从第三方门户免费使用 ChatGPT 4。
2. GPT-3.5
继 GPT 4 之后,OpenAI 凭借 GPT-3.5 再次位居第二。它是一种LLM类似于 GPT-4 的通用产品,但缺乏特定领域的专业知识。首先谈谈优点,这是一个非常快速的模型,可以在几秒钟内生成完整的响应。
无论您是使用 ChatGPT 撰写论文还是提出使用 ChatGPT 赚钱的商业计划等创意任务,GPT-3.5 模型都做得非常出色。此外,该公司最近为 GPT-16-turbo 模型发布了更大的 3.5K 上下文长度。别忘了,它也是免费使用的,没有每小时或每天的限制。
也就是说,它最大的缺点是 GPT-3.5 会产生很多幻觉并经常喷出虚假信息。因此,对于严肃的研究工作,我不建议使用它。尽管如此,对于基本的编码问题、翻译、理解科学概念和创造性任务,GPT-3.5 是一个足够好的模型。
在 HumanEval 基准测试中,GPT-3.5 模型得分为 48.1%,而 GPT-4 得分为 67%,这是所有通用大型语言模型中最高的。请记住,GPT-3.5 已经接受了 1750 亿个参数的训练,而 GPT-4 的训练超过了 1 万亿个参数。
3. PaLM 2 (Bison-001)
接下来,我们有来自谷歌的 PaLM 2 AI 模型,它被评为 2024 年最佳大型语言模型之一。谷歌在 PaLM 2 模型上专注于 20+ 种语言的常识推理、形式逻辑、数学和高级编码。据说最大的 PaLM 2 模型已经接受了 5400 亿个参数的训练,最大上下文长度为 4096 个令牌。
谷歌宣布了四款基于 PaLM 2 的不同尺寸型号(Gecko、Otter、Bison 和 Unicorn)。其中,Bison 目前可用,它在 MT-Bench 测试中获得了 6.40 分,而 GPT-4 获得了高达 8.99 分的分数。
也就是说,在 WinoGrande、StrategyQA、XCOPA 和其他测试等推理评估中,PaLM 2 做得非常出色,优于 GPT-4。它也是一个多语言模型,可以理解来自不同语言的习语、谜语和细微的文本。这是其他人LLMs难以解决的问题。
PaLM 2 的另一个优点是它的响应速度非常快,可以同时提供三种响应。您可以按照我们的文章在 Google 的 Vertex AI 平台上测试 PaLM 2 (Bison-001) 模型。对于消费者,您可以使用在 PaLM 2 上运行的 Google Bard。
4. Claude v1
如果您不知道,Claude 是由 Anthropic 开发的强大LLM产品,它得到了 Google 的支持。它由前 OpenAI 员工共同创立,其方法是构建有用、诚实和无害的 AI 助手。在多项基准测试中,Anthropic的Claude v1和Claude Instant模型显示出巨大的前景。事实上,Claude v1 在 MMLU 和 MT-Bench 测试中的表现优于 PaLM 2。
它接近 GPT-4,在 MT-Bench 测试中得分为 7.94,而 GPT-4 得分为 8.99。在 MMLU 基准测试中,Claude v1 获得 75.6 分,GPT-4 获得 86.4 分。Anthropic 也成为第一家提供 100k 代币作为其 Claude-instant-100k 模型中最大上下文窗口的公司。您基本上可以在一个窗口中加载近 75,000 个单词。这绝对是疯狂的,对吧?如果您有兴趣,可以立即查看我们关于如何使用 Anthropic Claude 的教程。
5. Cohere
Cohere 是一家 AI 初创公司,由曾在 Google Brain 团队工作的前 Google 员工创立。它的联合创始人之一 Aidan Gomez 是介绍 Transformer 架构的“注意力就是你所需要的一切”论文的一部分。与其他 AI 公司不同,Cohere 专为企业服务,为企业解决生成式 AI 用例。Cohere 有许多从小到大的模型——只有 6B 参数到使用 52B 参数训练的大型模型。
最近的 Cohere Command 模型因其准确性和鲁棒性而广受赞誉。根据 Standford HELM 的说法,Cohere Command 模型的准确性得分在同行中最高。除此之外,Spotify、Jasper、HyperWrite 等公司都在使用 Cohere 的模型来提供 AI 体验。
在定价方面,Cohere 对生成 100 万个代币收取 15 美元的费用,而 OpenAI 的 turbo 模型对相同数量的代币收取 4 美元的费用。尽管如此,就准确性而言,它比其他LLMs的要好。因此,如果您经营一家企业并正在寻找最好的LLM产品来融入您的产品,您可以看看 Cohere 的模型。
6. Falcon
Falcon 是这个榜单上的第一个开源大型语言模型,它的排名已经超过了迄今为止发布的所有开源模型,包括 LLaMA、StableLM、MPT 等。它由阿联酋技术创新研究所 (TII) 开发。Falcon 最好的一点是它已经开源了 Apache 2.0 许可证,这意味着您可以将该模型用于商业目的。也没有版税或限制。
到目前为止,TII已经发布了两个Falcon模型,它们在40B和7B参数上进行了训练。开发人员建议这些是原始模型,但如果你想用它们来聊天,你应该选择Falcon-40B-Instruct模型,该模型针对大多数用例进行了微调。
猎鹰模型主要使用英语、德语、西班牙语和法语进行训练,但它也可以在意大利语、葡萄牙语、波兰语、荷兰语、罗马尼亚语、捷克语和瑞典语中工作。因此,如果您对开源 AI 模型感兴趣,请先看看 Falcon。
7. LLaMA 7
自从 LLaMA 模型在网上泄露以来,Meta 就全力以赴开源。它正式发布了各种尺寸的 LLaMA 模型,从 70 亿个参数到 650 亿个参数。根据 Meta 的说法,其 LLaMA-13B 模型的表现优于 OpenAI 的 GPT-3 模型,后者已经接受了 1750 亿个参数的训练。许多开发人员正在使用 LLaMA 来微调和创建一些最好的开源模型。话虽如此,请记住,LLaMA 仅用于研究,不能与 TII 的 Falcon 模型不同用于商业用途。
谈到 LLaMA 65B 型号,它在大多数用例中都表现出惊人的功能。它在 Hugging Face 的公开LLM排行榜中名列前 10 名。Meta 表示,它没有使用任何专有材料来训练该模型。相反,该公司使用了来自 CommonCrawl、C4、GitHub、ArXiv、Wikipedia、StackExchange 等的公开数据。
简而言之,在 Meta 发布 LLaMA 模型后,开源社区看到了快速创新,并提出了新技术来制作更小、更高效的模型。
8. Guanaco-65B
在几个LLaMA衍生的模型中,Guanaco-65B被证明是最好的开源LLM,仅次于Falcon模型。在 MMLU 测试中,它的得分为 52.7,而 Falcon 模型得分为 54.1。同样,在 TruthfulQA 评估中,Guanaco 的得分为 51.3,Falcon 的得分为 52.5。Guanaco 有四种口味:7B、13B、33B 和 65B 型号。Tim Dettmers和其他研究人员在OASST1数据集上对所有模型进行了微调。
至于 Guanaco 是如何微调的,研究人员提出了一种名为 QLoRA 的新技术,该技术可以有效地减少内存使用量,同时保持完整的 16 位任务性能。在 Vicuna 基准测试中,Guanaco-65B 模型的表现甚至优于 ChatGPT(GPT-3.5 模型),参数大小要小得多。
最好的部分是,65B 型号在短短 24 小时内就已经在具有 48GB VRAM 的单个 GPU 上进行了训练。这表明开源模型在降低成本和保持质量方面取得了多大的进展。综上所述,如果您想尝试离线,本地LLM,您绝对可以尝试Guanaco模型。
9. Vicuna 33B
Vicuna 是 LMSYS 开发的另一个强大的开源。LLM与许多其他开源模型一样,它源自 LLaMA。它已经使用监督指令进行了微调,训练数据是从 sharegpt.com 收集的,这是一个用户分享他们令人难以置信的 ChatGPT 对话的门户。它是一个自回归的大型语言模型,在 330 亿个参数上进行训练。
在 LMSYS 自己的 MT-Bench 测试中,它获得了 7.12 分,而最佳专有模型 GPT-4 获得了 8.99 分。在 MMLU 测试中,它也获得了 59.2 分,GPT-4 获得了 86.4 分。尽管是一个小得多的模型,但骆马的性能非常出色。您可以通过单击以下链接查看演示并与聊天机器人进行交互。
10. MPT-30B
MPT-30B 是另一个与 LLaMA 衍生模型竞争的开源LLM模型。它由 Mosaic ML 开发,并对来自不同来源的大量数据进行了微调。它使用来自 ShareGPT-Vicuna、Camel-AI、GPTeacher、Guanaco、Baize 和其他来源的数据集。这个开源模型最好的部分是它的上下文长度为 8K 令牌。
此外,它的表现优于 OpenAI 的 GPT-3 模型,并在 LMSYS 的 MT-Bench 测试中获得 6.39 分。如果您正在寻找在本地运行的小型LLM产品,MPT-30B 型号是一个不错的选择。
11. 30B-Lazarus
30B-Lazarus模型是由CalderaAI开发的,它使用LLaMA作为其基础模型。开发人员使用了来自多个模型的 LoRA 调整数据集,包括 Manticore、SuperCOT-LoRA、SuperHOT、GPT-4 Alpaca-LoRA 等。因此,该模型在许多LLM基准测试中的表现要好得多。它在 HellaSwag 中获得 81.7 分,在 MMLU 中获得 45.2 分,仅次于 Falcon 和 Guanaco。如果您的用例主要是文本生成而不是对话式聊天,那么 30B Lazarus 模型可能是一个不错的选择。
12. WizardLM
WizardLM 是我们的下一个开源大型语言模型,它旨在遵循复杂的指令。一组人工智能研究人员提出了一种 Evol-instruct 方法,将初始指令集重写为更复杂的指令。生成的指令数据用于微调 LLaMA 模型。
由于这种方法,WizardLM 模型在基准测试中的表现要好得多,用户更喜欢 WizardLM 的输出而不是 ChatGPT 响应。在 MT-Bench 测试中,WizardLM 在 MMLU 测试中得分为 6.35 分和 52.3 分。总的来说,对于13B参数,WizardLM做得很好,为较小的模型打开了大门。
GPT4ALL 是由 Nomic AI 运营的一个项目。我推荐它不仅因为它的内部型号,而且在没有任何专用 GPU 或互联网连接的情况下在您的计算机上本地LLMs运行。它开发了一种运行良好的 13B Snoozy 模型。我已经在我的计算机上多次测试了它,鉴于我有一台入门级 PC,它生成的响应非常快。我也在 GPT4All 上使用了 PrivateGPT,它确实从自定义数据集中回答了。
除此之外,它还包含来自不同组织的 12 个开源模型。它们中的大多数都基于 7B 和 13B 参数构建,重量约为 3 GB 到 8 GB。最棒的是,你会得到一个GUI安装程序,你可以选择一个模型,并立即开始使用它。无需摆弄终端。简而言之,如果您想以用户友好的方式在计算机上运行本地LLM,GPT4All 是最好的方法。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。