用大模型解决视觉任务:《VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks》
AI菜鸟 2024-07-23 12:35:02 阅读 86
NIPS2023文章《VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks》简要技术介绍
本文写于2024年4月9日。
本文是关于NIPS2023论文VisionLLM的简要介绍。VisionLLM是一个多模态的大语言模型框架,可以借助大语言模型的力量,实现自定义的传统视觉任务,例如检测、分割、图像标题等。框架最大的特点就是灵活性和适应性,通过语言指令让模型做不限定的视觉任务。本文按照论文顺序和主要内容做介绍。
有关本专栏的更多内容,请参考大语言模型文献调研专栏目录
文章目录
1. 基础信息1. 资源1.2 论文的动机
2. 前人工作2.1 大语言模型2.2 视觉生成式模型2.3 指令微调
3. VisionLLM3.1 联合语言指令3.2 语言引导的图像分词器3.3 基于大语言模型的开放式任务解码器
4. 实验4.1 部署4.2 任务级别定制4.3 目标级输出格式定制4.4 消融实验
1. 基础信息
1. 资源
论文题目:VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
论文链接:https://proceedings.neurips.cc/paper_files/paper/2023/file/c1f7b1ed763e9c75e4db74b49b76db5f-Paper-Conference.pdf
论文代码:https://github.com/OpenGVLab/VisionLLM
论文引用(BibTex):
@article{wang2024visionllm,
title={Visionllm: Large language model is also an open-ended decoder for vision-centric tasks},
author={Wang, Wenhai and Chen, Zhe and Chen, Xiaokang and Wu, Jiannan and Zhu, Xizhou and Zeng, Gang and Luo, Ping and Lu, Tong and Zhou, Jie and Qiao, Yu and others},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
1.2 论文的动机
大型语言模型(LLMs)显著推动了人工通用智能(AGI)的进展,展现出令人瞩目的zero-shot能力,可供用户处理定制任务,这样的特性在各种应用中具有巨大潜力。然而,在计算机视觉领域,尽管存在许多强大的视觉基础模型(VFMs),任务的形式仍然是提前定义好的,并不能像LLMs那样解决开放式任务。
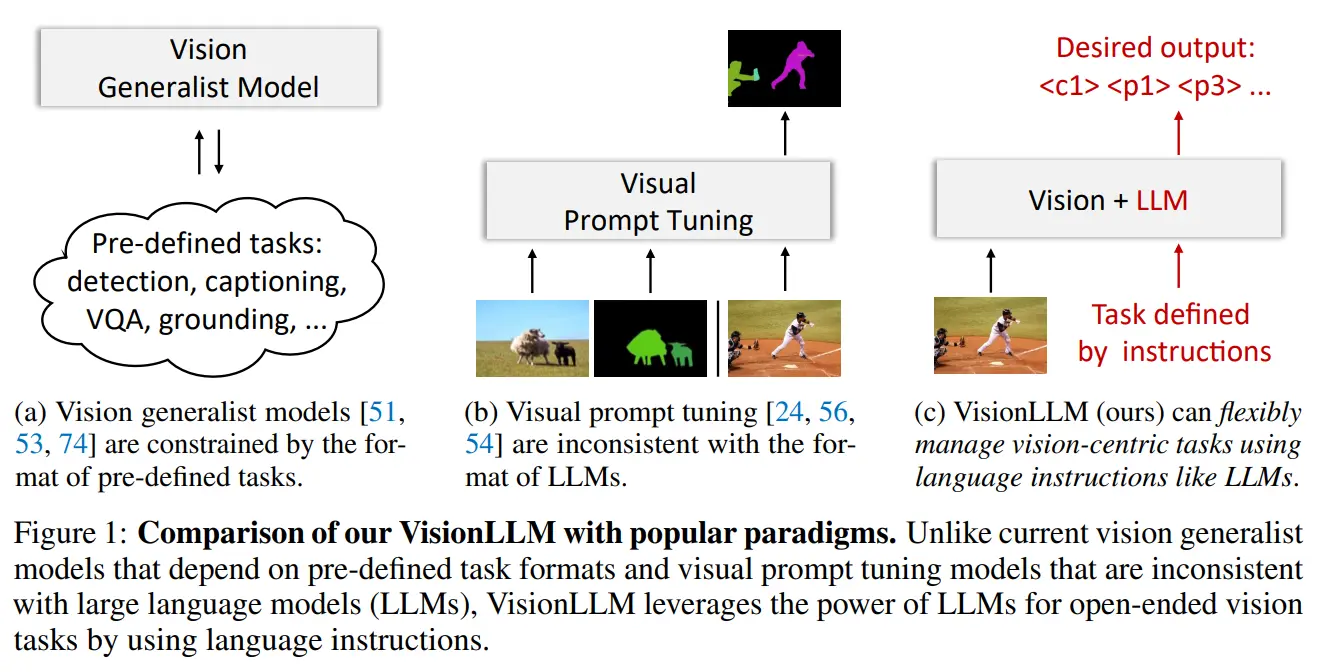
视觉提示微调(Visual Instruction Tuning)已经成为一种灵活勾勒纯视觉任务的方式,例如利用视觉掩码进行目标检测、实例分割和姿态估计。然而,视觉提示的格式与语言指令差异很大,这使得直接将LLMs的推理能力和世界知识应用于视觉任务变得具有挑战性。因此,迫切需要一个统一的通用框架,可以无缝地整合LLMs的优势和视觉中心任务的特定要求。
基于此,作者提出VisionLLM,这是一个基于LLM的解决视觉中心任务的框架。VisionLLM将图像视为一种外语,将视觉中心任务与语言任务对齐,这种对齐允许使用语言指令灵活定义和管理任,基于LLMs的解码器然后根据这些指令预测开放式任务的结果。实验证明了通过语言指令实现各种级别的任务定制的VisionLLM的能力,从细粒度的对象级别到粗粒度的任务级别定制,都取得了良好的结果。
2. 前人工作
2.1 大语言模型
LLM在语言生成、上下文学习、世界知识和推理方面表现出色,GPT系列是代表作,包括GPT-3、ChatGPT、GPT-4和InstructGPT,其他LLMs如OPT、LLaMA、MOSS和GLM也较为著名。
近期出现了基于API的应用程序,解决了以视觉为中心的任务,这些应用程序将视觉API与语言模型结合,以进行决策或规划。使用基于语言的指令描述视觉元素便利,但仍面临细节捕捉和复杂背景理解的限制, 这些限制影响了视觉和语言模型的有效连接。
因此, LLMs在各种NLP应用中表现出巨大潜力,但在视觉中心任务上的应用受到了挑战,主要是由于模态融合和任务形式的限制。
2.2 视觉生成式模型
机器学习领域长期追求通用模型,要求模型使用共享框架解决各种任务。例如:
受到序列到序列(seq2seq)模型在自然语言处理领域的成功启发,最近的进展如OFA、Flamingo和GIT提出将多样化任务建模为序列生成任务。Unified-IO、Pix2Seq v2和UniTab通过使用离散坐标标记来编码和解码空间信息以支持更多任务扩展了这一思想。Gato还将强化学习任务整合到seq2seq框架中。GPV通过将seq2seq模块与基于DETR的视觉编码器结合起来,开发了一个通用视觉系统。
然而,这些方法存在一些限制,如推理速度慢和由于非并行自回归解码过程而导致性能下降。Uni-Perceivers通过根据表示相似性为每个输入使用最大似然目标来统一不同任务,而不考虑它们的模态,从而支持在统一框架中同时支持生成和非生成任务。然而,这些通用模型仍然受到预定义任务的限制,无法像LLMs那样支持基于语言指令的灵活开放式任务定制。
2.3 指令微调
语言指令在LLMs中的应用:
GPT-3引入了语言指令的概念,为各种NLP任务提供了一种强大的表达方式。后续作品如InstructGPT、FLAN和OPT-IML通过探索指导调整方法,有效增强了LLMs的零-shot和少-shot能力。这种范式也被应用于计算机视觉领域,用于定义图像到文本任务。
LLM+视觉提示模型:
Flamingo是一项具有里程碑意义的工作,将视觉和语言输入作为提示,在各种视觉语言任务中取得了显著的少-shot结果。BLIP-2将视觉编码器与LLMs连接起来,建立了强大的多模态模型。MiniGPT-4和LLaVA通过在合成多模态指令遵循数据上微调BLIP-2风格模型,发挥了LLMs的潜力。对于图像修复任务,Bar等人提出了首个利用图像上的离散标记进行修复的视觉提示框架。
当前任务的局限性:
Painter和SegGPT使用遮罩图像建模进行上下文学习,虽然在分割任务中表现良好,但在实际视觉任务中的适用性仍有挑战。视觉提示模型的定义与LLMs中的语言指令不一致,难以充分利用LLMs的推理、解析能力和世界知识。
VisionLLM旨在将以视觉为中心的任务与语言任务对齐,使用语言指令统一灵活地定义所有任务,并通过共享的LLM-based任务解码器来解决它们。
3. VisionLLM
VisionLLM旨在提供一个统一的通用框架,能够无缝地将大型语言模型(LLMs)的优势与以视觉为中心的任务的特定需求相结合。VisionLLM的整体架构包括三个关键设计,这三个设计共同实现了一个灵活而开放式的框架,通过语言指令可以处理不同级别的任务定制的各种以视觉为中心的任务:
统一的语言指令,为以视觉为中心的任务定义和定制提供一致的接口。语言引导的图像分词器,它根据给定的语言提示对视觉信息进行编码,使模型能够有效地理解和解析视觉内容。基于LLM的开放式任务解码器,利用编码的视觉信息和语言指令生成满意的预测或输出。
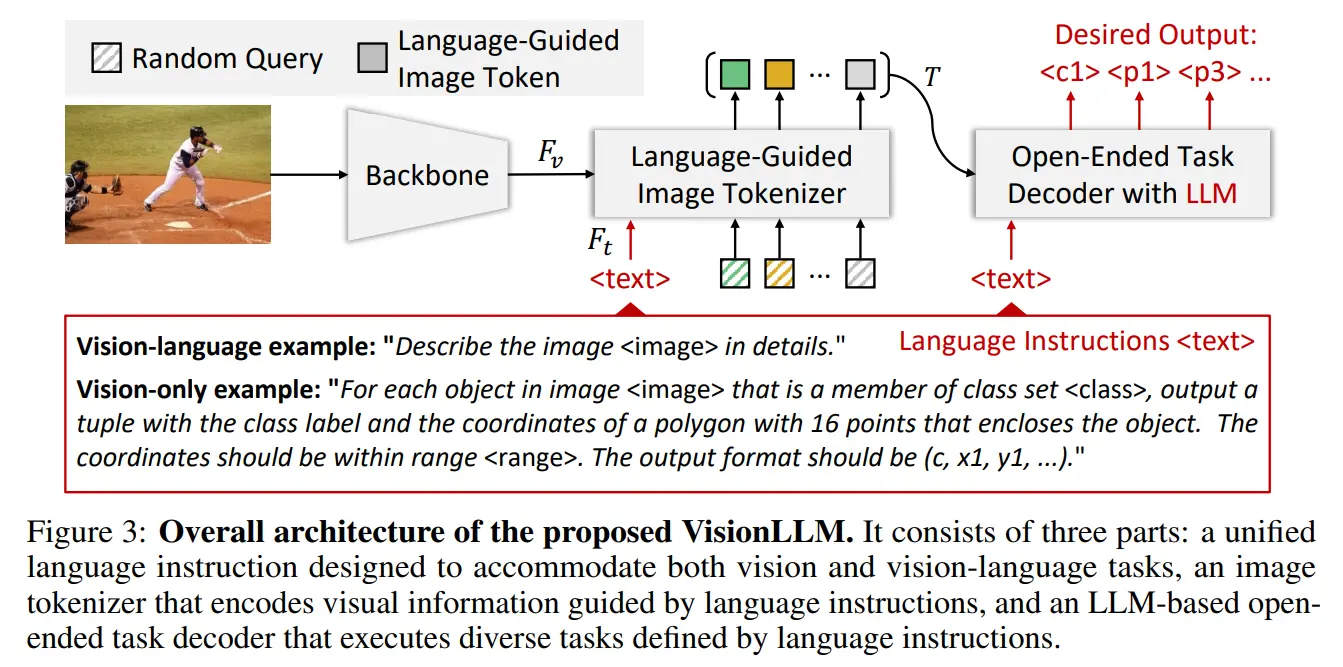
与以前依赖API的交互式系统不同,VisionLLM提供了一个更灵活、端到端的流程,使得VisionLLM能够有效地将视觉和语言结合起来,在开放式和可定制的以视觉为中心的任务中取得了显著的性能。
第一,给定描述当前任务的语言指令和输入图像,模型首先使用语言引导的图像分词器根据给定提示对图像标记进行编码。第二,将图像标记和语言指令输入到基于LLM的开放式任务解码器中。第三,它根据统一的语言指令对生成的输出进行评估,使模型能够产生特定于任务的结果。
3.1 联合语言指令
VisionLLM引入统一的语言指令来描述以视觉为中心的任务,实现对各种仅视觉和视觉-语言任务描述的统一,并允许灵活的任务定制。
对于视觉-语言任务(如图像字幕和视觉问答),采用直接且类似于NLP任务的方法。根据之前的方法,首先描述图像字幕任务为:“The image is . Please generate a caption for the image: ”,而视觉问答任务为:“The image is . Please generate an answer for the image according to the question: ”。这里,“”和“”分别是图像标记和问题的占位符。图像标记直接放置在占位符处 。
对于仅视觉任务:由于视觉和语言之间的模态和任务格式差异,为视觉任务设计有效的语言指令是一项具有挑战性的工作。因此,作者通过语言指令提供任务描述并指定所需的输出格式来描述视觉任务。
视觉任务语言化:任务描述传递了预期任务给语言模型。借鉴自 self-instruct 方法,设计了一组带占位符的种子指令,并利用LLMs生成大量相关的任务描述,在训练过程中随机选择其中一个。视觉标签语言化:对于传统的视觉感知任务(如目标检测和实例分割),作者提出了一个统一的输出格式,表示为元组 (C, P),其中 C 表示在类别集合中的类别索引,而 P = {xi , yi} N i=1 则表示定位对象的 N 个点。为了与单词标记的格式保持一致,类别索引 C 和点的坐标 xi , yi 都被转换成离散化的标记。具体来说,类别索引是从 0 开始的整数,而点的连续坐标被均匀地离散化为 [-, ] 范围内的整数。对于目标检测和视觉定位任务,点的数量 N 等于 2,表示对象边界框的左上角和右下角点。在实例分割的情况下,使用多个(N > 8)沿对象边界的点来表示一个实例掩码。其他感知任务,如姿态估计(关键点检测),也可以以这种方式被表述为语言指令。
以实例分割任务的语言指令为例:“在图像中对类别集合中的所有对象进行分割,生成格式为 (c, x1, y1, x2, y2, …, x8, y8) 的列表。这里,c 表示从 0 开始的类别标签索引,而 (x1, y1, x2, y2, …, x8, y8) 对应于对象边界点相对于中心点的偏移量。图像是”
3.2 语言引导的图像分词器
VisionLLM将图像视为一种外语,并将其转换为标记表示。与之前利用固定大小的块嵌入来表示图像的作品不同,引入了语言引导的图像分词器,灵活地编码与特定任务语言提示或指令对齐的视觉信息,这种设计不仅独立于输入分辨率表示图像,还提取了相对于语言提示具有信息量的视觉表示。具体步骤为:
对于给定高度和宽度的图像,首先将其馈送到图像主干(例如 ResNet)并提取四个不同尺度的视觉特征 。利用文本编码器(例如 BERT)从给定提示中提取语言特征。通过交叉注意力,将语言特征注入到每个尺度的视觉特征中,得到多尺度语言感知的视觉特征,实现跨模态特征的对齐。采用基于 transformer 的网络(如 Deformable DETR),使用 M个随机初始化的查询来捕获图像的高层信息。将基于多尺度语言感知的视觉特征构建 transformer-based 网络,以提取M个图像标记,每个标记由嵌入和位置表示,表示标记的语义和位置信息。
3.3 基于大语言模型的开放式任务解码器
作者在 Alpaca 上构建了解码器,这是从 LLaMA 调整而来的一种 LLM,用于处理带有语言指导的各种视觉相关任务。然而,Alpaca 在以视觉为中心的任务中存在一些固有的缺点,比如:
它的词汇表中只有少量数字标记(例如,0∼9),这限制了它通过数字定位对象的能力;它使用多个标记来表示类别名称,导致在对象分类中的效率低下;它是一个因果模型,对于视觉感知任务效率低下。
为了解决这些问题,作者通过专门设计的附加标记扩展了 LLN 的词汇表,以用于视觉为中心的任务。
位置坐标离散化:首先,添加了一组位置标记,表示为 {, …, , …, },其中 表示图像标记的位置
的 i ∈ [−512, 512] 离散化偏移量,相对于图像高度或宽度的相对值等于 i/512。这些标记成功地将对象定位任务从连续变量预测转换为更统一的离散区间分类。
类标签打码:其次,我们引入了语义无关的分类标记 {, , …, } 来替代类别名称标记,从而克服了使用多个标记表示类别的低效性。类别名称和分类标记之间的映射灵活地在语言指令的类别集合中提供,例如 {“person”:, “car”:, “black cat”:,…}。这一设计使得模型可以从提供的类别集合中选择适当的类别名称,促进了高效准确的对象分类。
结构化输出:此外,为了解决因果框架引起的低效问题,作者引入了以输出格式作为查询的解码。首先使用 LLM 从任务指令中解析结构化输出格式(例如,对于目标检测是“ ” ,对于图像字幕是“”),然后将结构化输出格式的标记作为查询输入到解码器中,根据查询生成所需的输出。这种简单的方法使得我们的模型不仅可以避免在视觉感知任务中低效的标记解码,还能保持视觉-语言任务的统一框架。
在目标检测任务的训练和推理阶段,向解码器输入了 100 组“ ”,生成了 100 个对象预测。那些具有较高置信度得分的预测将被保留,这符合目标检测任务的常见做法。通过这种方式,对象位置和分类的输出被形式化为一种外语,从而将这些以视觉为中心的任务统一成令牌分类的格式。因此,视觉-语言任务和仅视觉任务都可以像语言任务一样使用交叉熵损失进行监督。
此外,为了有效训练,作者采用了低秩适应(LoRA)方法,能够在不增加过多计算成本的情况下训练和微调模型。作者将 LoRA 排名设置为 64,并在注意层的 QKVO(查询、键、值和输出)上使用 LoRA。它还充当语言和视觉标记之间的桥梁,促进了两种模态之间的有效对齐,确保了更好的任务定制,并提高了整个系统的收敛性。
4. 实验
4.1 部署
作者实现了两个 VisionLLM 变体,分别采用 ResNet 和 InternImage-H 作为图像主干。采用 BERT-Large 作为文本编码器和 Deformable DETR (D-DETR) 来捕获高层信息的语言引导图像分词器。使用经过指令微调的 Alpaca-7B 模型作为 LLM,并结合 LoRA 进行参数高效微调。训练模型分为两个阶段:
第一阶段初始化 D-DETR 和 BERT 的预训练权重,训练视觉主干和语言引导图像分词器生成具有语言意识的视觉特征;第二阶段将图像分词器与 Alpaca-7B 相连接,引入多任务的统一监督。在第二阶段中,冻结视觉主干,同时冻结大部分 LLN 参数,除了少量 LoRA 参数。
4.2 任务级别定制
VisionLLM支持对任务进行粗粒度的定制,包括视觉感知任务和视觉语言任务。在四个标准的以视觉为中心的任务上评估了VisionLLM的任务级定制能力,包括目标检测、实例分割、视觉定位和图像字幕。作者将模型与特定任务方法以及最近提出的视觉通用模型进行了比较。值得注意的是,除非特别说明,模型结果来自一个共享参数的通用模型,仅通过更改语言指令来切换不同的任务。
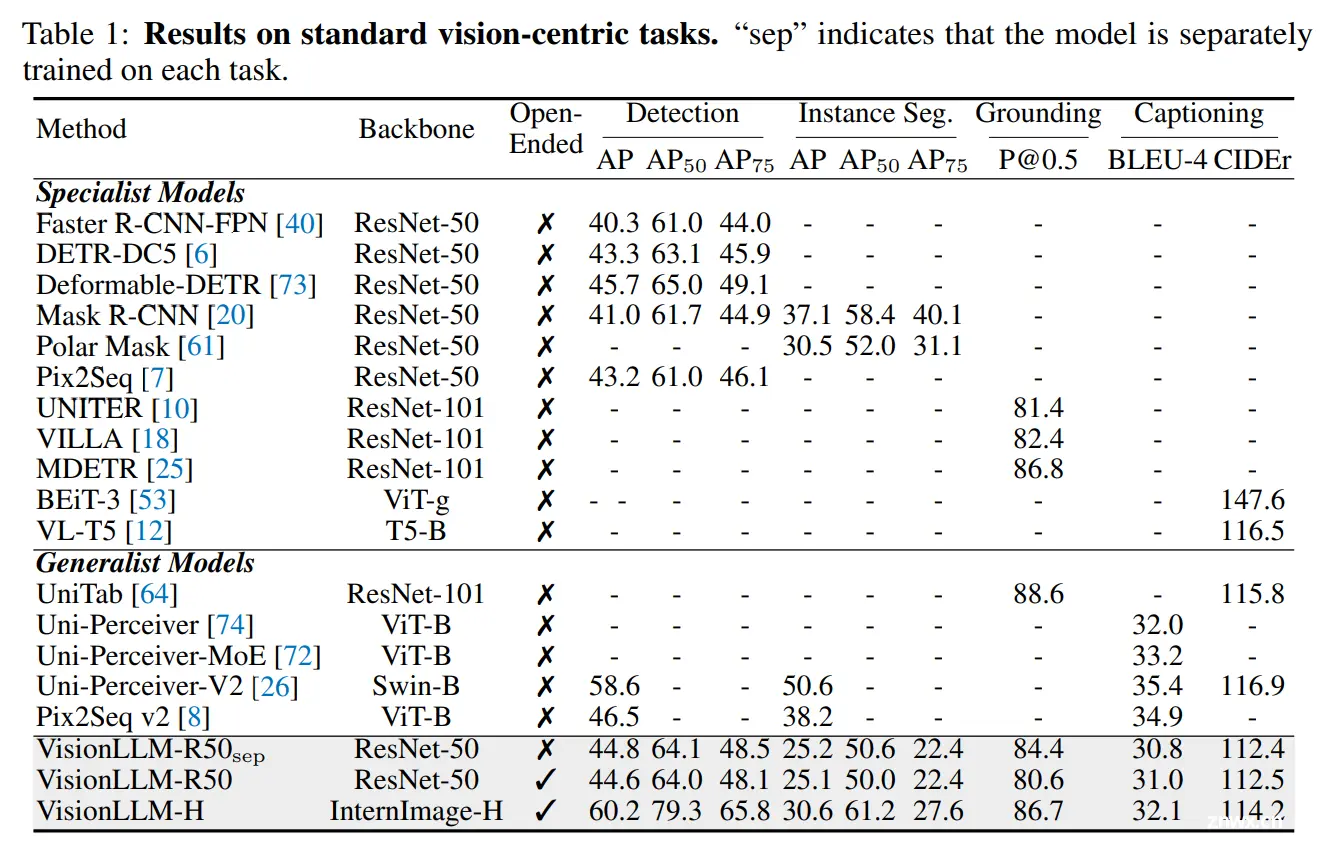
目标检测。目标检测是一个基础的计算机视觉任务,在图像中识别和定位感兴趣的对象。作者的方法在使用 ResNet-50 主干时达到了可比较或更高的结果,达到了 44.6 的 mAP。在相同的主干 ResNet-50 下,作者的方法比 Pix2Seq 高出 1.4 的 mAP,后者也将输出坐标离散化为整数。
此外,受益于输出格式作为查询的框架,可以在推理过程中并行解码多个预测,使方法更加高效。使用 InternImage-H 作为视觉主干,作者获得了 60.2% 的 mAP,接近当前最先进的专用检测模型,显示了作者通用模型的可扩展性。
视觉定位。视觉定位(Visual Grounding)将文本描述与图像中相应的区域或对象关联起来。训练视觉定位和目标检测可能会产生冲突,因为目标检测旨在检测所有对象,而视觉定位应仅定位所指对象并抑制其他对象。受益于统一的任务指令和LLM强大的指令理解能力,VisionLLM有效执行这两项任务,在视觉定位方面达到了 80.6 P@0.5 的结果。使用 InternImage-H 作为主干,在 RefCOCO 验证集上实现了 86.7 P@0.5。
实例分割。实例分割涉及识别和分割图像中的个体对象。作者沿着对象边界采用灵活数量的点(即 8∼24)来表示实例掩模。与特定于实例分割的主流模型相比,VisionLLM具有可比较的掩模 AP50(在 InternImage-H [51] 上为 61.2%),但相对较低的掩模 AP75。这种差距可能源于以下因素:
作者将输出坐标离散化为整数以统一任务,这会引入信息丢失;由于内存和计算约束,我们模型中的点数受限,这也导致性能下降;基于点的方法通常比直接掩模预测方法(如 Mask R-CNN [20])产生更低的结果。
图像说明文字生成。图像字幕生成任务中,作者报告了 BLEU-4 和 CIDEr 指标。值得注意的是,作者没有采用 CIDEr 优化。VisionLLM 达到了与先前方法类似的性能。使用 ResNet-50,我们获得了 BLEU-4 得分为 31.0,CIDEr 得分为 112.5。当使用 InternImage-H 作为主干时,VisionLLM获得了可比较的 BLEU-4 分数为 32.1 和 CIDEr 分数为 114.2。这些结果表明了 VisionLLM 在为图像生成描述性和上下文相关的字幕方面的有效性。
4.3 目标级输出格式定制
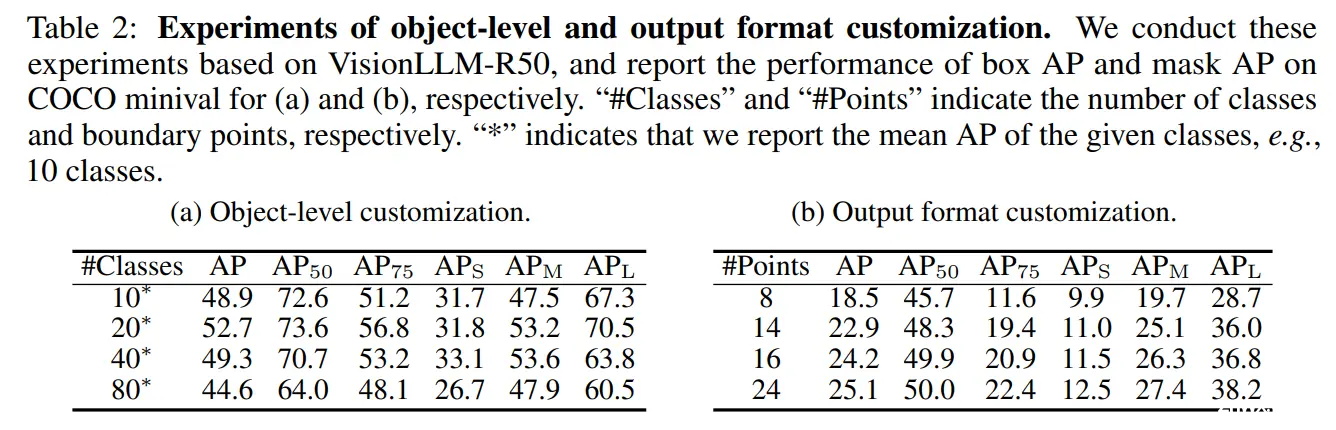
VisionLLM 不仅允许自定义任务描述,还可以使用语言指令调整目标对象和输出格式。在这里,我们在 COCO 数据集上评估了我们模型的细粒度定制能力。特别地,为了自定义目标对象,作者修改语言指令中的 <class>,将模型的识别目标从 10 类修改为 80 类。同样,为了自定义输出格式,作者修改语言指令中的点数,以改变任务的输出格式。VisionLLM在对象级别和输出格式变化方面都表现良好。
4.4 消融实验
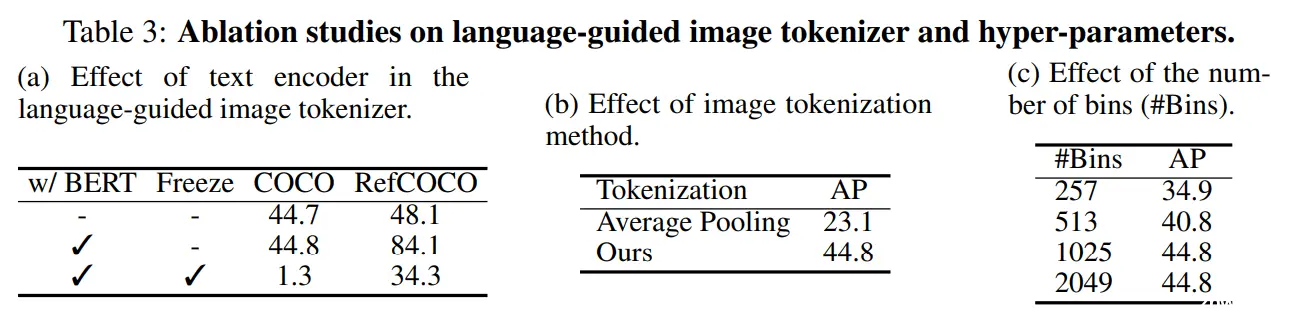
作者在这一部分分析了 VisionLLM 中关键组件和超参数对其性能的影响。使用 ResNet-50 主干,并在 COCO2017 上进行了带有随机类别和任务描述的目标检测任务的消融实验。
单任务 vs. 多任务。作者评估了语言指令的多任务学习对 VisionLLM 的影响。单任务训练的模型 VisionLLM-R50sep 在除了图像字幕生成外略优于联合训练的模型 VisionLLM-R50。这是由于多任务之间的冲突,这也影响了以前的通用模型,并反映了精度和泛化之间的权衡。文本编码器在语言引导图像分词器中的作用。作者研究了文本编码器(即 BERT)在我们的语言引导图像分词器中的作用,报告了目标检测和视觉定位的结果。前两行显示了对于目标检测来说BERT并不是必要的,但对于视觉定位来说至关重要。我们还研究了在训练过程中冻结文本编码器的效果。最后一行表明,冻结BERT会阻碍视觉和语言模态之间的对齐,从而降低两个任务的性能。图像分词方法。作者使用 D-DETR 编码器的特征图进行平均池化,以获得 M 个嵌入,这些嵌入用作图像的分词表示。结果表明了作者方法的明显优势。这是因为VisionLLM能够以更灵活的方式捕获各种大小的对象的信息。定位分词的数量。作者将定位分词的数量从 257(即 -128∼128)变到 2049(即 -1024∼1024),以研究其对视觉感知性能的影响。随着定位分词数量的增加,模型的性能持续提升,直到达到饱和点。值得注意的是,当数量从257增加到1025时,性能显著提升(+9.9 AP)。这些结果表明,更多的定位令牌使模型能够实现更精细的定位能力,从而提高了定位的准确性。
有关本专栏的更多内容,请参考大语言模型文献调研专栏目录
者自知才疏学浅,难免疏漏与谬误,若有高见,请不吝赐教,笔者将不胜感激!
softargmax
2024年4月9日
上一篇: 文档解析效果全维度测评标准
下一篇: Java 集合框架:Vector、Stack 的介绍、使用、原理与源码解析
本文标签
用大模型解决视觉任务:《VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks》
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。