【多模态大模型paper阅读笔记-6】Grounding多模态,LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models
同屿Firmirin 2024-08-24 10:31:02 阅读 95
论文名称:Visual Instruction Tuning
论文链接:https://arxiv.org/pdf/2304.08485
项目链接:https://llava-vl.github.io/llava-grounding/
keypoints
精读
1. background&motivation
尽管目前多模态模型可以支持grounding的能力,但是grounding能力和chat能力是分开的,当模型被问到grounding的能力时,它们chat的能力下降的比较明显。主要问题是:缺少一个grounded visual chat dataset(GVC)。本文构造了一个GVC数据集,同时提出了一个Grounding-Bench。
模型在主流bench上也颇具竞争力:RefCOCO/+/g and Flickr30K。
认识到对于多模态模型视觉grounding能力的重要性,现有的很多团队开始研究grounding和referring的能力。例如MiniGPT-v2、CogVLM-Grounding,目前的模型在处理grounding问题时,将其当作独特的任务,需要使用独特的提示词,只能生成比较短的caption(训练数据集Flickr30K导致的),这些模型很难同时兼顾grounding和chat。一些模型LaVA-PLUS / BuboGPT通过外接一个grounding model来获取grounding能力,但grounding model中的language encoder会影响模型整体的性能。
总之,以往的工作无法兼顾grounding和chat,而且只能提供bbox坐标框,无法实现像素级的grouning和refering。这是数据的缺乏和模型架构不够合理导致的。
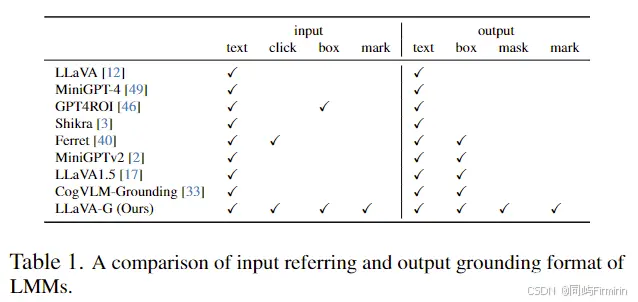
2. Contribution
引入了一个数据标注pipeline,将人工标注的数据(CoCo等)和GPYT-4的对话生成能力结合起来,能用于生成高质量Grounded Visual Chat (GVC) data,成功得到了包含150K实例的 GVC数据。一个端到端的模型LLaVAGrounding,主要是MLLM连接一个grounding model来获取grounding能力,支持对象级和像素级的grounding,支持多种视觉提示包括:mark, click, box, and scribble,上图是和其他工作的对比。一个Grounding-Bench,用于评估grounded chat,并能使用GPT4辅助评估。在这个Grounding-Bench上显著优于其他MLLM,在传统bench上也很有竞争力。
3. Grounded Visual Chat Data Creation
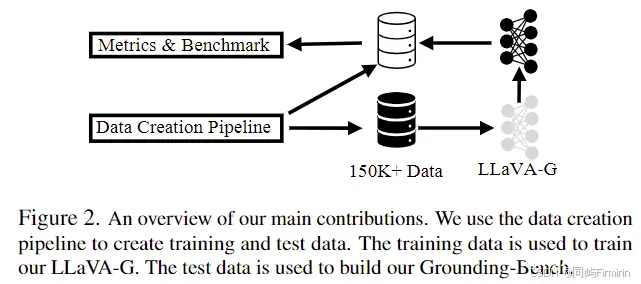
沿用了LLaVA instruction tuning data的格式,参考:
http://t.csdnimg.cn/u1qm4
对话使用仅语言的GPT-4生成,图像和grounding标注来自COCO。
GVC数据的生成流程如下:

图中,Context type1(对象和其坐标框bbox)和type2(图像的描述caption)会被输入给GPT4用于上下文学习,GPT4会在type2的句子中找到type1中存在的object,并在句子中标注出来。算是将两种数据做了一个融合,最后输出的数据格式如下:
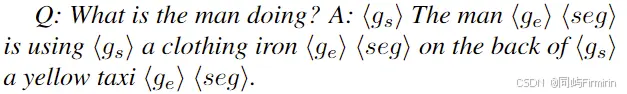
每个句子中的object短语会用 <gs><ge>标识出来,并跟一个特殊的token<seg>。用于LLaVA-G最后输入到外接的grounded model中,输出对应的框或遮罩。(注意区分什么是GPT4的,什么是LLaVA的)。
为了对用户提问中的对象做ground,提问中的object也会被标识出来,作为grounded model的输入,所以最终的GVC问答数据格式如下:
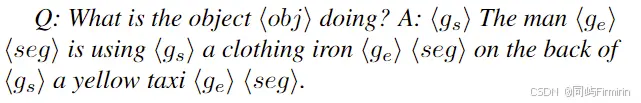
4. Network Architectures
就是一个LLaVA架构+prompt encoder+grounding model。
整个模型输入图像+用户标的点、框等等(visual prompt,SAM的做法),
输出自然语言回答+目标对应的Box/Mask等。
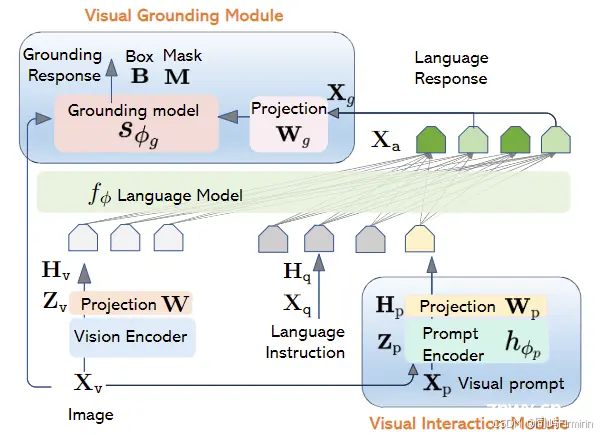
值得注意是,Xp(输入的视觉提示)和Xg(用于grounding的输出特征)是可选的。
4.1 Prompt encoder
用了预训练好的Semantic-SAM。
这个模块会从原图像和用户提供的visual prompt中提取视觉特征。
再用一个简单的线性投射层将视觉特征映射到和语言模型相同维度的embedding tokens。
值得注意的是输入的语言embedding中有特殊token <obj> 作为占位符,而Prompt encoder的输出会取代它。
4.2 Grounding model
LLM的输出除了自然语言回答外,还会额外输出一个特征Xg用于grounding,这些特征是于LLM输出中,<seg>标记的最后一层的特征。
特征Xg首先用一个可训练的矩阵投射到grounding space,再输入到一个预训练好的模型OpenSeeD中,用于输出最终的bbox和mask。
5. Training
三阶段的训练。
训练任务:
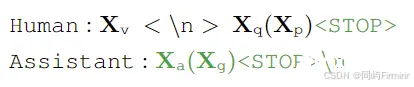
仅绿色部分参与计算自回归损失。
5.1 Stage 1: Pretraining for alignment.
专注于视觉编码器的特征对齐和grounding模型的粒度对齐。
使用的数据集如下:

蓝、绿、红分别用于一阶段、二阶段和三阶段。
Feature alignment for vision encoder.
LLaVA 585K and Flickr30K中包含图像-caption对,用来训练投射矩阵W。
对话数据:问题来自一堆预设问题的随机选取,回答就是数据集中该图像的captain。
预设问题如下:

Feature and granularity alignment for grounding model
为了加强grounding功能,用的是RefCOCO/+/g, COCO 2017train, Visual Genome, and Flickr30K Entities。用于对齐LLM的输出Xg和grounding model的词表。
对话构造有所不同:
对于RefCOCO/+/g and Visual Genome,问题从以下选取,答案仅仅是<seg>。

LLM最后一个隐藏层的特征被用于grounding,其中<seg>对应的部分Xg被矩阵Wg映射到grounding model的vocabulary space。
本阶段训练的参数包括:
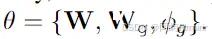
5.2 Stage 2: Instruction tuning for grounded visual chat
这一阶段使用数据为Grounded Visual Chat,不包含视觉提示。
同时为了训练没有grounding时的对话能力。使用数据为 LLAVA 158K 指令跟踪数据。在这个阶段,冻结 CLIP 视觉编码器,训练其他部分。
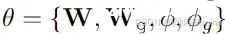
这一阶段的损失包括自回归损失和grounding损失。
语言自回归损失和LLaVA中的相同,包括answer tokens和stop tokens,
ground损失包括box、mask和匹配损失,其中box和mask损失仅用于训练ground模型,匹配损失还会传播到语言模型。
5.3 Stage 3: Extension to visual prompt.
这一阶段是为了训练模型对视觉提示的支持,仅训练visual prompt encoder和其投射矩阵Wp。训练数据中使用了GT的visual prompt作为输入来预测captions。
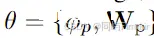
可选的:Set-of-Mark (SoM) prompts
与视觉提示不同,这种是直接在图像上把目标标记出来,例如在该图中直接在目标上标记数字编号:

训练数据就会变成这样:
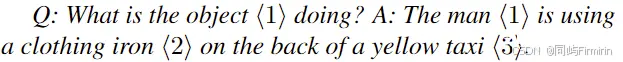
6. Grounding-Bench
本文构造的基准,用于衡量模型的grounded visual chat能力,要揣摩这里的意思,既不是单纯的对话能力,也不是ground能力。
使用MSCOCO val中的数据,使用本文之前提到的数据构造方法,得到1000张图+7000实体。
任务定义
模型输入图像和用户指令,输出带有边界框的图像描述,每个边界框对应一个短语。
评估分数

括两个主要方面:聊天分数和ground response分数。评估算法如下:
Evaluate Chat Scores: 去掉用于grounding的特殊标记和box,计算纯chat的语言分数。
Evaluate Grounded Response Scores:包括召回率R、精确率P和F1 score。流程如下:
选择和gt的iou不小于0.5的预测框;用预测框和模型输出的chat组成grounded response,如下图;用GPT-4计算与GT的语义匹配度TP,下图正确匹配4个refer和3个实体;计算得分P、R、F。

7 实验
7.1 实验设置
LLM:Vicuna7b v1.3
grounding model:the vision part of an OpenSeeD Tiny model pretrained on COCO and Object365
interactive encoder:Semantic-SAM Tiny model pretrained on COCO with three granularities
stage1:仅训练grounding model, prompt encoder, and projection layers,lr:1e-4
stage2:训练LLM和projection layers,lr:2e-5
训练grounding model,lr:1e-4
7.2 Grounding-Bench
在自建数据集GVC上实验。
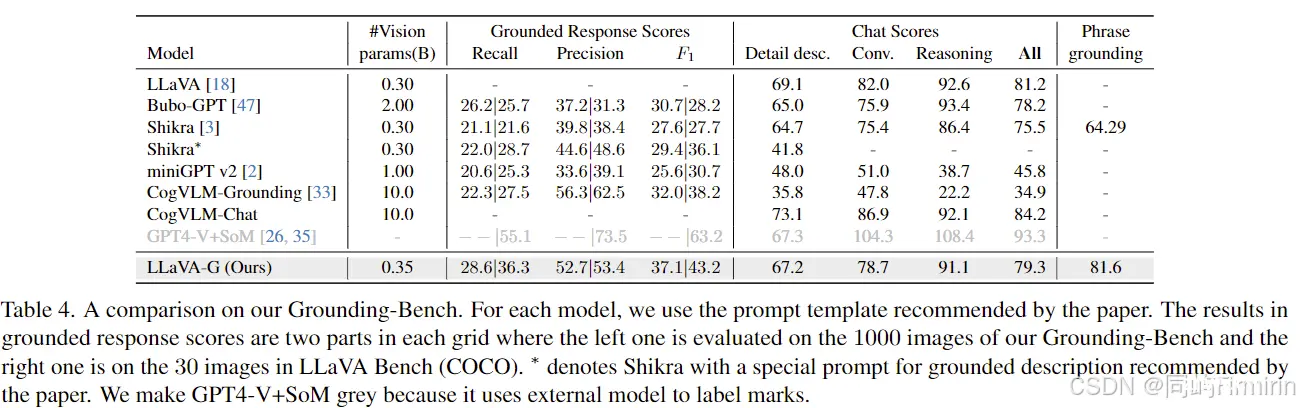
左边为Grounding-Bench中1000张图的评估结果,右边为LLaVA Bench 30张图的结果。所有LMM使用了各自的prompt以保证最佳性能。
7.3 Traditional Grounding Benchmarks
RefCOCO/+/g for Referring Expression Comprehension (REC,根据详细描述框选图中目标) and Referring Expression Segmentation (RES,根据详细描述像素级分割目标)。
Flickr30K Entities for Phrase Grounding。
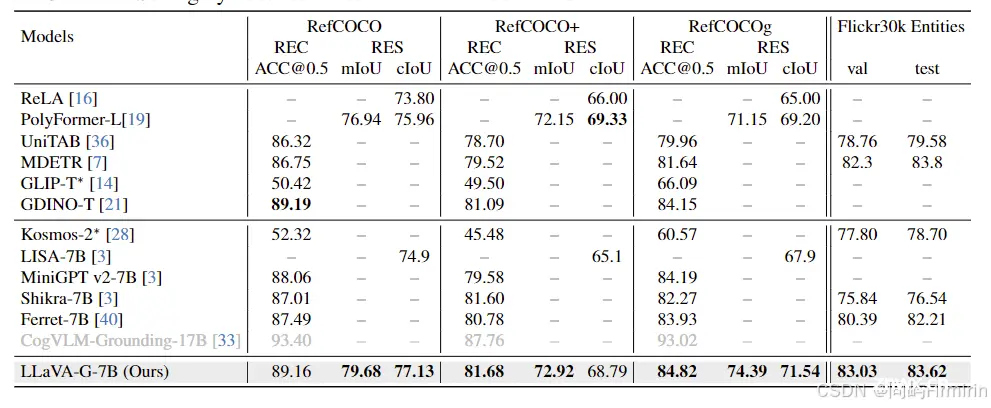
REC弱于CogVLM-Grounding-17B以外的LMM,作者说是因为他们采用了更大的visual encoder和连接器
7.4 Visual Prompts
验证模型支持多种visual prompts包括marks, clicks, and boxes。
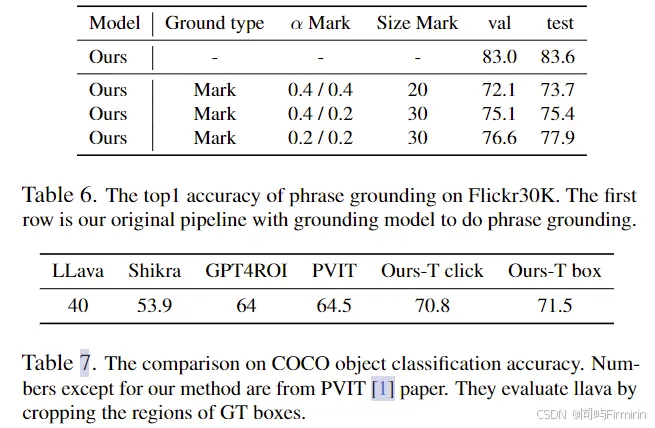
这里使用的mark都是真值 mark。
7.5 可视化



7.6 消融
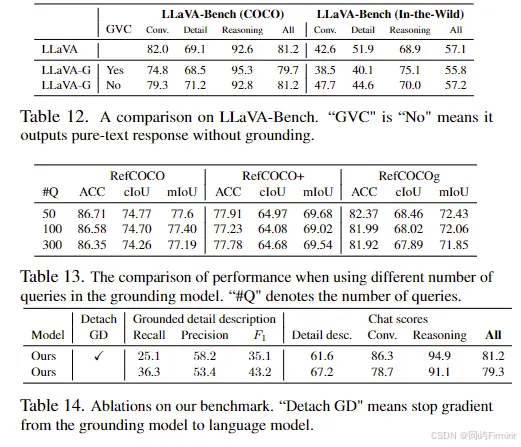
局限性:在语义范围方面存在局限性,未来的工作可以探索将数据集和数据标记方法扩展到开放词汇设置。
上一篇: 【香橙派AIpro开发板实测】OrangePi AIpro超级AI大脑 华为昇腾处理器 运行yolov8
本文标签
【多模态大模型paper阅读笔记-6】Grounding多模态 LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。