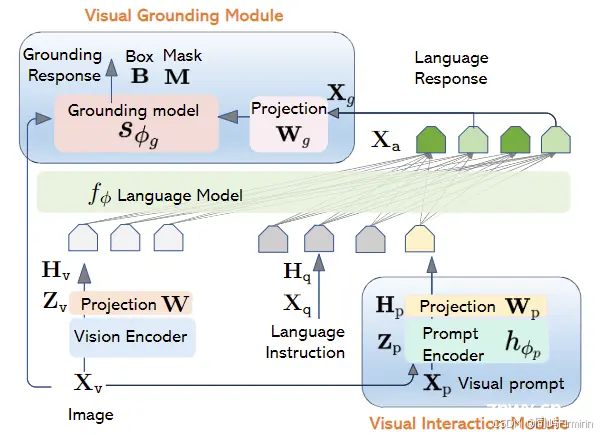
模型输入图像和用户指令,输出带有边界框的图像描述,每个边界框对应一个短语。_groundingbenchmarks...
浏览 95 次 标签: 【多模态大模型paper阅读笔记-6】Grounding多模态 LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models