AI多模态教程:Qwen-VL多模态大模型实践指南
AIGCmagic社区 2024-08-07 15:01:05 阅读 91

一、模型介绍
Qwen-VL,由阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM),代表了人工智能领域的一个重大突破。该模型具有处理和关联图像、文本、检测框等多种类型数据的能力,其输出形式同样多样,包括文本和检测框。这种多功能性使得Qwen-VL在众多应用场景中展现出巨大的潜力。
Qwen-VL的核心能力在于其强大的视觉理解和语言生成能力。通过深度学习技术,该模型能够识别和理解图像中的内容,包括物体、场景和活动。同时,它还能生成描述性的文本,对图像中的信息进行解释和总结。这种跨模态的理解和生成能力,使得Qwen-VL在图像描述、视觉问答、图像编辑等任务中表现出色。
此外,Qwen-VL还具备检测框作为输入和输出的能力。这意味着它不仅能识别图像中的物体,还能精确定位它们的位置。在输出方面,Qwen-VL可以生成包含物体位置信息的检测框,这对于需要进行物体识别和定位的应用场景尤为重要。
Qwen-VL-Chat = 大语言模型(Qwen-7B) + 视觉图片特征编码器(Openclip ViT-bigG) + 位置感知视觉语言适配器(可训练Adapter)+ 1.5B的图文数据 + 多轮训练 + 对齐机制(Chat)
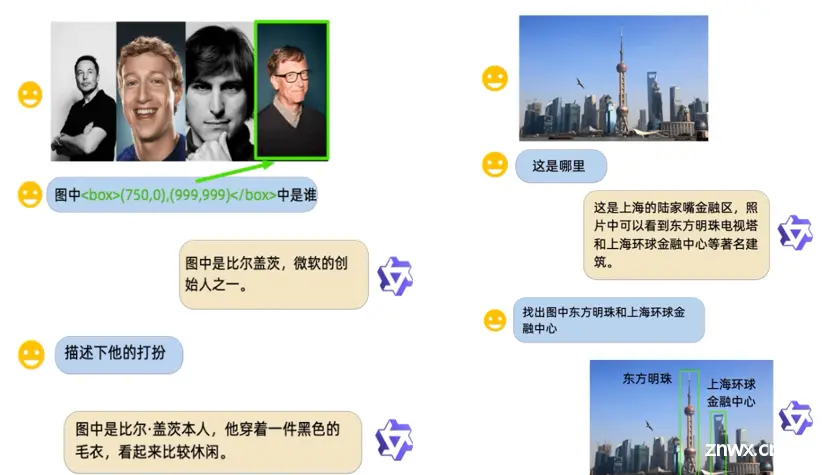
Qwen-VL 系列模型的特点包括:
多语言对话模型:天然支持英文、中文等多语言对话,端到端支持图片里中英双语的长文本识别;多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;开放域目标定位:通过中文开放域语言表达进行检测框标注;细粒度识别和理解:448分辨率可以提升细粒度的文字识别、文档问答和检测框标注。
二、硬件配置
微调训练,作为一种机器学习技术,通常用于调整和优化预训练模型,以适应特定任务或数据集。在微调训练过程中,显存占用和速度是两个关键的性能指标,它们直接影响到训练的效率和可行性。
显存占用主要受批量大小(Batch Size, BS)和序列长度(Sequence Length)的影响。批量大小决定了每次训练中处理的数据量,而序列长度则影响了模型处理每个数据点时的复杂度。当批量大小为1时,意味着每次训练只处理一个数据点,这在显存有限的情况下是一种常见的选择,因为它可以显著降低显存需求。
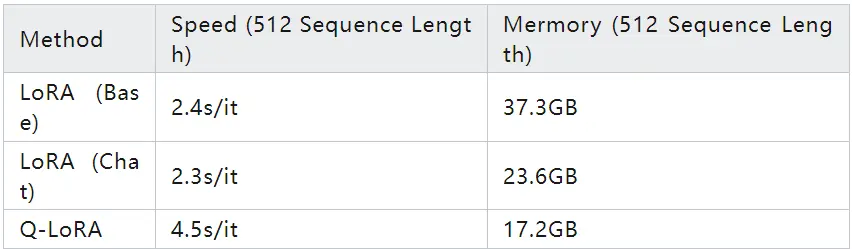
推理阶段的显存占用及速度如下:

在使用不同的显卡进行深度学习模型训练或推理时,选择合适的数值精度是一个重要的优化策略。不同的数值精度不仅影响模型的性能和准确性,还会直接影响显存的使用效率。
对于A100、H100、RTX3060、RTX3070等高性能显卡,建议启用bf16(Brain Floating Point)精度。bf16是一种16位浮点格式,它在保持较高精度的同时,相比传统的32位浮点数(fp32)可以显著节省显存。bf16精度特别适合用于深度学习模型,因为它在保持大部分精度的同时,减少了模型的大小,从而降低了显存占用。这对于训练大型模型或处理大量数据尤为重要。
而对于V100、P100、T4等较旧的显卡,由于它们可能不支持bf16精度,建议启用fp16(16位浮点)精度。fp16精度同样可以显著减少显存使用,虽然它的数值范围比bf16小,但在许多情况下仍然可以保持模型的性能。
当使用CPU进行推理时,由于CPU的内存管理方式与GPU不同,通常需要更多的内存来存储和处理数据。因此,建议至少有32GB的内存来确保推理过程的顺利进行。相比之下,使用GPU进行推理时,由于GPU的显存管理更为高效,通常需要约24GB的显存即可满足需求。
三、环境安装
Python虚拟环境:
<code>https://repo.anaconda.com/archive/Anaconda3-2019.03-Linux-x86_64.sh // 从官网下载安装脚本
$ bash Anaconda3-2019.03-Linux-x86_64.sh // 阅读协议确认安装,安装完成后再输入yes以便不需
$ conda create -n qwen_vl python=3.10 // 安装虚拟环境, python 3.10及以上版本
$ conda activate qwen_vl // 激活虚拟环境
$ conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia // pytorch 2.0及以上版本, 建议使用CUDA 11.4及以上
依赖包:
git clone https://github.com/QwenLM/Qwen-VL.git
cd Qwen-VL/
pip3 install -r requirements.txt
pip3 install -r requirements_openai_api.txt
pip3 install -r requirements_web_demo.txt
pip3 install deepspeed
pip3 install peft
pip3 install optimum
pip3 install auto-gptq
pip3 install modelscope -U
建议先从 ModelScope 下载模型及代码至本地,再从本地加载模型:
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# 其中版本v1.1.0支持INT4、INT8的在线量化,其余版本不支持
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.0.0'
# 下载模型到指定目录
local_dir = "/root/autodl-tmp/Qwen-VL-Chat"
snapshot_download(repo_id=model_id, revision=revision, local_dir=local_dir)
四、快速使用
Qwen-VL-chat :
① 代码调用方式
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
# 请注意:根据显存选择配置,分词器默认行为已更改为默认关闭特殊token攻击防护。
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True, fp16=Flase).eval()
# 第一轮对话
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': '这是什么?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
# 第二轮对话
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
print(response)
# <ref>击掌</ref><box>(536,509),(588,602)</box>
② WebUI调用方式
# 启动命令,局域网访问
python web_demo_mm.py --server-name 0.0.0.0

五、自定义数据集微调
提供finetune.py脚本和shell脚本的目的是为了简化用户在自有数据上微调预训练模型的过程,同时支持DeepSpeed和FSDP(Fully Sharded Data Parallel)两种优化技术,以提高训练效率和可扩展性。
finetune.py脚本的功能和特点:
微调功能:finetune.py脚本允许用户在自己的数据集上对预训练模型进行微调。微调是一种常见的做法,通过在特定任务上调整预训练模型的参数,可以提高模型在该任务上的性能。易于接入下游任务:脚本设计为模块化,使得用户可以轻松地将微调后的模型集成到各种下游任务中,如文本分类、情感分析、问答系统等。支持DeepSpeed和FSDP:DeepSpeed和FSDP是两种先进的优化技术,用于加速大型模型的训练。DeepSpeed提供了一系列优化策略,如模型并行、管道并行和ZeRO优化器等。FSDP则是一种数据并行策略,通过完全分片来减少每个GPU上的显存占用。这些技术的支持使得finetune.py脚本能够处理更大的模型和数据集。
(1) 自定义数据集准备:
需要将所有样本数据放到一个列表中并存入JSON文件中。每个样本对应一个字典,包含id和conversation,其中后者为一个列表。示例如下所示:
<code>[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是Qwen-VL,一个支持视觉输入的大模型。"
}
]
},
{
"id": "identity_1",
"conversations": [
{
"from": "user",
"value": "Picture 1: <img>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>\n图中的狗是什么品种?"
},
{
"from": "assistant",
"value": "图中是一只拉布拉多犬。"
},
{
"from": "user",
"value": "框出图中的格子衬衫"
},
{
"from": "assistant",
"value": "<ref>格子衬衫</ref><box>(588,499),(725,789)</box>"
}
]
},
{
"id": "identity_2",
"conversations": [
{
"from": "user",
"value": "Picture 1: <img>assets/mm_tutorial/Chongqing.jpeg</img>\nPicture 2: <img>assets/mm_tutorial/Beijing.jpeg</img>\n图中都是哪"
},
{
"from": "assistant",
"value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"
}
]
}
]
格式解释:
为针对多样的VL任务,增加了一下的特殊tokens: <img> </img> <ref> </ref> <box> </box>.对于带图像输入的内容可表示为 Picture id: <img>img_path</img>\n{your prompt},其中id表示对话中的第几张图片。"img_path"可以是本地的图片或网络地址。对话中的检测框可以表示为<box>(x1,y1),(x2,y2)</box>,其中 (x1, y1) 和(x2, y2)分别对应左上角和右下角的坐标,并且被归一化到[0, 1000)的范围内. 检测框对应的文本描述也可以通过<ref>text_caption</ref>表示。准备好数据后,你可以使用我们提供的shell脚本实现微调。注意,你需要在脚本中指定你的数据的路径。
(2) 模型微调方式
Qwen-VL支持以下微调方式:全参数微调、LoRA、Q-LoRA
① 全参数微调
默认下全参数微调在训练过程中更新LLM所有参数。实验中,在微调阶段不更新ViT的参数会取得更好的表现。全参数微调,不支持单卡训练,且需确认机器是否支持bf16。运行下面脚本开始训练:
# 分布式训练。由于显存限制将导致单卡训练失败,我们不提供单卡训练脚本。
sh finetune/finetune_ds.sh
② LoRA微调
与全参数微调不同,LoRA (论文) 只更新adapter层的参数而无需更新原有语言模型的参数。这种方法允许用户用更低的显存开销来训练模型,也意味着更小的计算开销。
使用官方项目里提供的微调脚本进行LoRA微调测试,模型采用HuggingFace下载的那个全精度模型,数据采用上面的示例数据,建议模型路径使用绝对路径,如果你想节省显存占用,可以考虑使用chat模型进行LoRA微调,显存占用将大幅度降低。
# 单卡训练
sh finetune/finetune_lora_single_gpu.sh
# 分布式训练
sh finetune/finetune_lora_ds.sh
#!/bin/bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
DIR=`pwd`
MODEL="/root/autodl-tmp/Qwen-VL-Chat"code>
DATA="/root/autodl-tmp/data.json"code>
export CUDA_VISIBLE_DEVICES=0
python3 finetune.py \
--model_name_or_path $MODEL \
--data_path $DATA \
--bf16 True \
--fix_vit True \
--output_dir output_qwen \
--num_train_epochs 5 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 10 \
--learning_rate 1e-5 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 600 \
--lazy_preprocess True \
--gradient_checkpointing \
--use_lora
注意事项:
需要修改脚本中的MODEL、DATA参数,将其换成实际的模型和数据地址需要修改脚本里的model_max_length参数,默认是2048,这需要27.3GB的显存
③ Q-LoRA微调
如果你依然遇到显存不足的问题,可以考虑使用Q-LoRA (论文)。该方法使用4比特量化模型以及paged attention等技术实现更小的显存开销,仅支持fp16。运行Q-LoRA你只需运行如下脚本:
# 单卡训练
sh finetune/finetune_qlora_single_gpu.sh
# 分布式训练
sh finetune/finetune_qlora_ds.sh
建议使用官方提供的Int4量化模型进行训练,即Qwen-VL-Chat-Int4。不要使用非量化模型!与全参数微调以及LoRA不同,Q-LoRA仅支持fp16。
(3) 模型合并
与全参数微调不同,LoRA和Q-LoRA的训练只需存储adapter部分的参数。因此需要先合并并存储模型(LoRA支持合并,Q-LoRA不支持),再用常规方式读取你的新模型:
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
path_to_adapter, # path to the output directory
device_map="auto",code>
trust_remote_code=True
).eval()
merged_model = model.merge_and_unload()
# max_shard_size and safe serialization are not necessary.
# They respectively work for sharding checkpoint and save the model to safetensors
merged_model.save_pretrained(new_model_directory, max_shard_size="2048MB", safe_serialization=True)code>
推荐阅读:
《AIGCmagic星球》,五大AIGC方向正式上线!让我们在AIGC时代携手同行!限量活动
《三年面试五年模拟》版本更新白皮书,迎接AIGC时代
AIGC |「多模态模型」系列之OneChart:端到端图表理解信息提取模型
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之LLM主干(1):ChatGLM系列
AI多模态模型架构之LLM主干(2):Qwen系列
AI多模态教程:从0到1搭建VisualGLM图文大模型案例
智谱推出创新AI模型GLM-4-9B:国家队开源生态的新里程碑
技术交流:
加入「AIGCmagic社区」群聊,一起交流讨论,涉及 「AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶」等多个不同方向,可私信或添加微信号:【lzz9527288】,备注不同方向邀请入群!!

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。