斯坦福提出首个开源视觉语言动作大模型OpenVLA
Flying Youth 2024-08-24 09:01:02 阅读 79
OpenVLA:开源视觉语言动作大模型
摘要模型结构训练数据训练设施实验总结和局限性
项目主页
代码链接
论文链接
模型链接
摘要

现有的VLA(Vision-Language-Action )模型具有这些局限性:
1)大多封闭且开放;
2)未能探索高效地为新任务微调VLA的方法,而这是VLAs被采用的关键组成部分。
为此本工作开发了OpenVLA,一个基于97万条Open X-Embodiment机器人任务的7B参数开源VLA模型,它为通用机器人操作策略设定了新的技术前沿,它支持直接控制多台机器人,并且可以通过参数高效微调快速适应新的机器人配置。OpenVLA建立在Llama2语言模型和ViT视觉编码器上,融合了来自 DINOv2和SigLIP的预训练权重。由于添加了更多数据和新模型组件,OpenVLA在通用物体操作任务上的表现十分出色,在29个任务和多种机器人形态上,其绝对任务成功率比封闭模型RT-2-X(55B)高出16.5%,同时参数数量减少了7倍。
模型结构
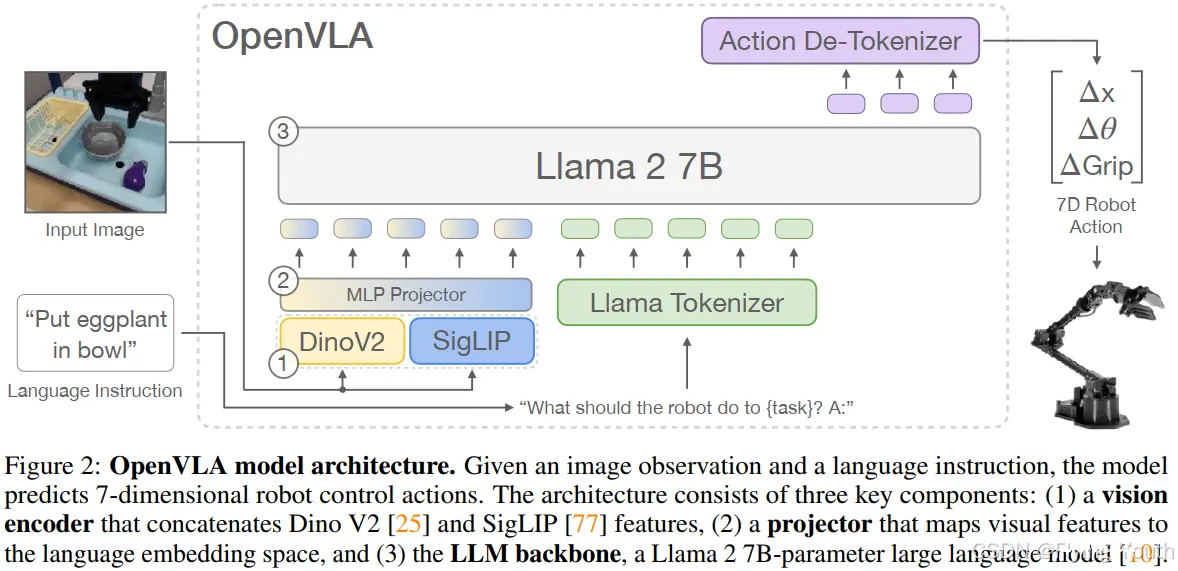
给定一张图像观测和语言指令,OpenVLA可以预测7维的机器人控制动作。该结构包含3个关键的组件:(1)一个联结了Dino V2和SigLIP特征的视觉编码器,(2)一个将视觉特征映射到语言embedding空间的投射层,(3)一个7B参数量的LLM backbone:Llama2。整个模型基于Prismatic-7B VLM,仅修改了输出部分,针对机械臂action使用归一化分为了256bin,动作token来自语言token后身下的token和使用频率很低的token(类似RT2)。
训练数据
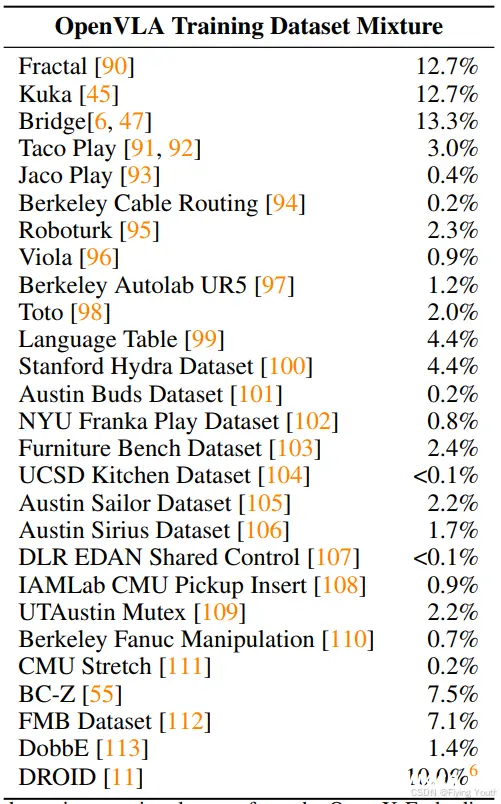
构建OpenVLA训练集的目标是捕捉各种机器人、场景和任务的多样性,使其可以直接控制各种机器人,并允许高效地微调以适配新的机器人。我们利用Open X-Embodiment 数据集作为基础来构建我们的训练集,截至撰写本文时,OpenX数据集包含70多个独立的机器人数据集,超过200万个机器人轨迹,为便于使用该数据集进行训练,我们对原始数据集进行了数据清洗,目标是确保:
(1)所有训练数据集中具有一致的输入和输出空间;为解决该问题,我们仅将训练数据集限制为至少包含一个第三人称摄像头和单臂末端执行器控制的操作数据集;
(2)在最终的训练混合数据中具有均衡的机器人配置、任务和场景;为此,我们利用Octo里的方法对所有通过第一轮筛选的数据集的混合数据权重进行不同比例配置。
此外我们还尝试将一些额外的数据集加入到训练集中,这些数据集是在Octo发布后添加到OpenX数据集中的,包括约10%的DROID数据集。在实践中,我们发现DROID上的动作标记准确率在整个训练过程中都保持较低的水平,这表明在未来可能需要更高的混合权重或模型来适应其多样性。为了不影响最终模型的质量,在训练的最后1/3阶段我们将DROID从中移除。
训练设施
OpenVLA模型在64个A100 GPU集群上训练了14天,(总共21,500个A100小时),batch_size设为2048。推理时OpenVLA在bfloat16精度(即未进行量化)下需要15GB的GPU内存,在NVIDIA RTX 4090 GPU上运行时约为6Hz(不包括编译、投机解码或其他推理加速技巧)。我们还可以通过量化进一步减少OpenVLA在推理过程中的内存占用,同时在实际的机器人任务中不会影响性能。同时我们实现了一个远程VLA推理服务器,允许实时远程向机器人传输动作预测,从而无需拥有强大的本地计算设备来控制机器人。我们将此远程推理解决方案作为开源代码的一部分进行发布。
实验
实验目标是测试OpenVLA是否能够作为一种强大的多机器人控制policy,并且能很好地微调适配新的机器人:
在评估多个机器人和各种类型的泛化能力时,OpenVLA与之前的通用机器人策略相比如何?OpenVLA可以在新的机器人设配置和任务上进行有效的微调吗?它与当前最先进的数据驱动的高效模仿学习方法相比如何?我们可以使用参数高效微调和量化来降低OpenVLA模型的训练和推理计算需求,使其更易于使用吗?性能-计算消耗的权衡是什么?
实验一:直接在多个实验平台上进行评估
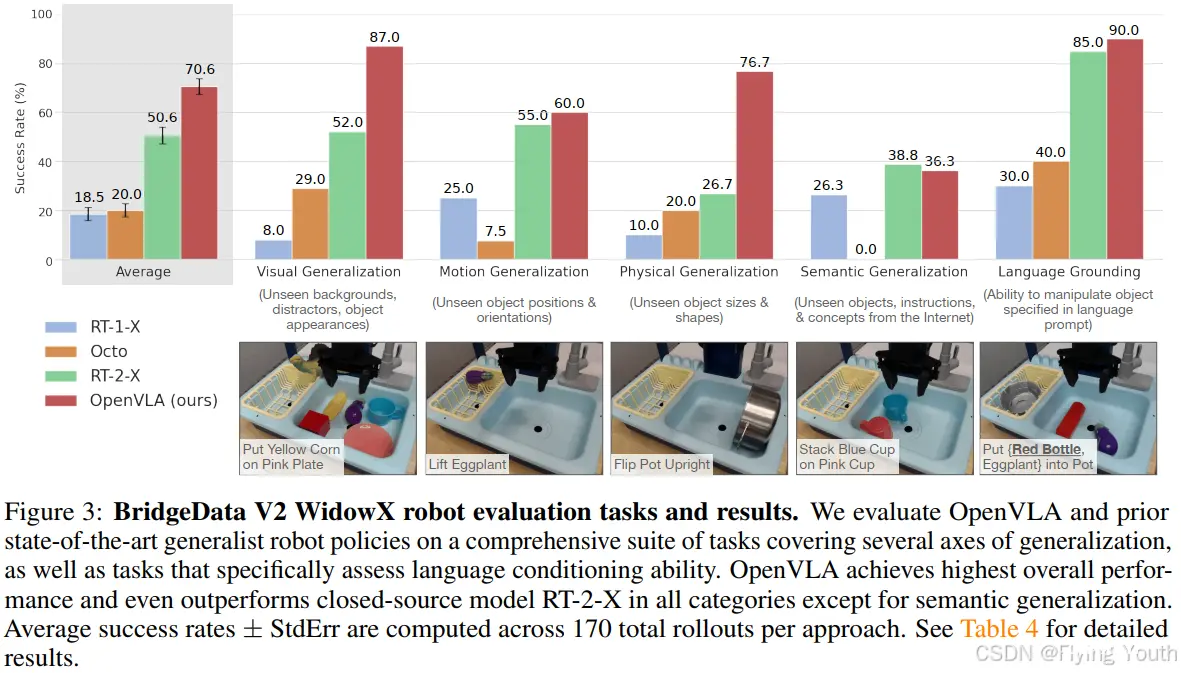
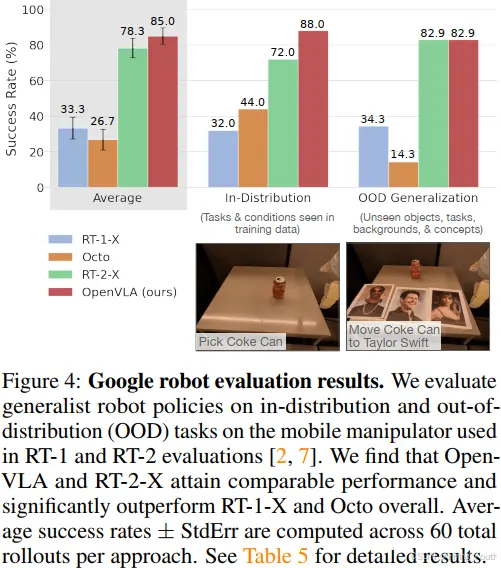
RT-1-X和Octo都表现不佳,经常无法操纵正确的物体,尤其是在有干扰物的情况下,有时还会导致机器人胡乱挥动手臂。请注意,我们的评估测试了比先前工作中的评估更大的泛化程度,以挑战互联网数据预训练的VLA模型。因此,没有互联网预训练的模型的性能预期较低。RT-2-X明显优于RT-1-X和Octo,证明了大规模网络数据的预训练VLMs对机器人技术的益处。
值得注意的是,OpenVLA在谷歌机器人评测中的表现与RT2-X相当,但在BridgeData V2评测中的表现显著优于RT-2-X,尽管其参数量仅为RT-2-X的十分之一(7B vs. 55B参数)。从质量上看,我们发现RT-2-X和OpenVLA都比其他测试模型表现出更稳健的行为,例如在有干扰物的情况下接近正确的物体,正确地使机器人的末端执行器与目标物体的朝向对齐,甚至从错误中恢复,例如不安全地抓取物体(有关更详细的示例,请参见https://openvla.github.io)。RT-2-X在语义泛化任务中表现出更高的性能,如图3所示,这是预期的,因为它使用了更大规模的互联网预训练数据,并与机器人动作数据和互联网预训练数据共同进行微调,以更好地保留预训练知识,而不是仅在机器人数据上进行微调,如OpenVLA。然而,OpenVLA在其他所有任务类别中在BridgeData V2和谷歌机器人评测中的表现与RT-2-X相当或更好。性能差异可归因于多种因素的结合:我们为OpenVLA创建了一个更大的训练数据集,包含97万条轨迹(而RT-2-X为35万条);我们对训练数据集进行了更仔细的清洗,例如从Bridge数据集中过滤掉了所有零动作;OpenVLA还使用了一种融合的视觉编码器,将预训练的语义和空间特征结合在一起。
实验二:在新的机器人上进行微调适配
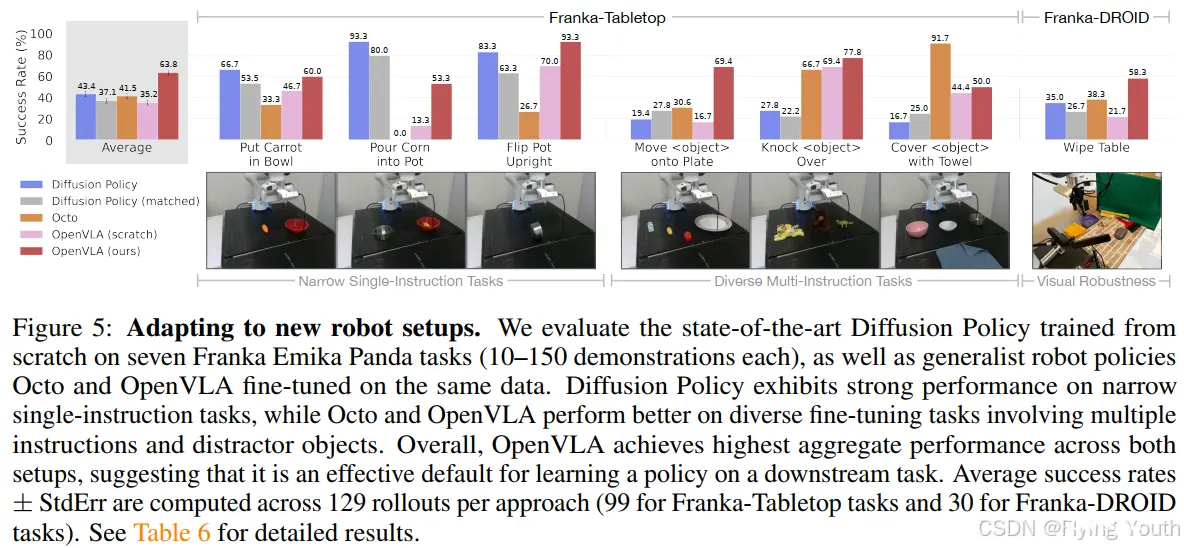
总的来说,我们发现OpenVLA实现了最高的平均性能。值得注意的是,大多数先前的工作只有在狭窄的单指令或多样化的多指令任务中才能获得较强的性能,导致成功率差异很大。OpenVLA是唯一在所有测试任务中的成功率能达到至少50%的方法,这表明它可能是一个强大的模仿学习选型,特别是涉及语言引导的多任务。对于狭窄但高度灵巧的任务,Diffusion Policy仍然显示出更平滑和更精确的轨迹; 扩散策略中的动作分块和时间平滑有望帮助OpenVLA达到相同水平的灵活性,并且可能是未来工作的一个有希望的方向。
实验三: 参数高效的微调
微调的方式有:
full finetuning(全参微调): 优化所有参数;last layer only(仅最后一层微调):仅微调OpenVLA transformer backbone 最后一层和token embedding矩阵;frozen vision(冻结视觉):固定视觉编码器,微调其他所有参数;sandwich微调:微调视觉编码器、token embedding矩阵和最后一层;LoRA微调:使用low-rank自适应的方法微调所有线性层
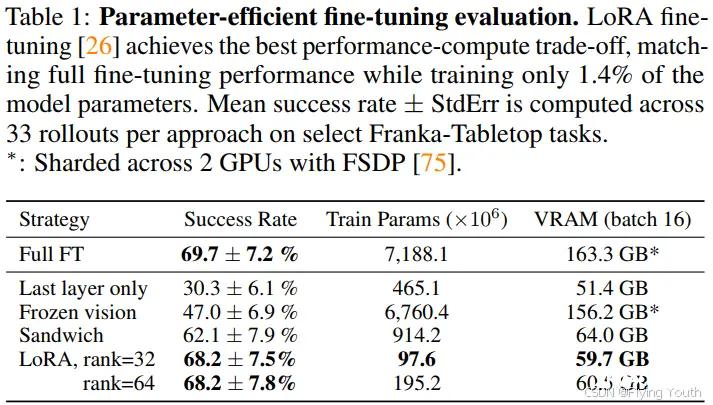
只有对网络进行最后一层微调或冻结视觉编码器时将导致性能不佳,进一步适应对目标场景的视觉特征是至关重要的。相比之下,Sandwich微调实现了更好的性能,因为它微调视觉编码器,同时它消耗了更少的GPU内存,因为它不会对整个LLM主干进行微调。最后,LoRA微调实现了两者之间的最佳权衡性能和训练记忆消耗,优于Sandwich微调并达到完全微调的性能,同时只微调了1.4%的参数。我们发现LoRA Rank对策略性能的影响可以忽略不计,因此建议使用r = 32的默认Rank。使用LoRA微调,我们可以在单个A100 GPU上在10-15小时内对新任务的进行微调,与完全微调相比,计算减少了8倍。
总结和局限性
总结:
1, OpenVLA是一个先进的、开源的视觉-语言-动作(Visual Language Action)模型;
2, 它现成能够实现跨身体机器人控制,同时可以通过参数高效微调技术轻松适应新的机器人;
3, 满足实时控制;
4, 指标达到业内SOTA。
局限性:
1,目前仅支持单张图像观测。将OpenVLA扩展到支持多图像和本体感知输入以及观测历史是未来工作的重要方向。探索使用在交织的图像和文本数据上预训练的VLM(视觉语言模型)可能有助于实现这种灵活输入的VLA微调。
2,提高OpenVLA的推理效率对于实现ALOHA(每秒50hz的高频控制)等配置的VLA控制至关重要[88]。这也将利于测试更灵巧的双手操作任务的VLA。探索使用动作分块或替代的推理时优化技术可能是一个可行的解决方案。
3,尽管OpenVLA在测试任务上的成功率通常低于90%,但它仍优于之前的通用Policy,有提升空间。
4,由于计算能力的限制,许多VLA设计问题尚未得到充分研究:基模型VLM的大小对VLA性能有何影响?在机器人动作预测数据和大规模互联网的视觉语言数据上进行协同训练是否可以显著提高VLA性能?最适合VLA模型的视觉特征是什么?
个人评价:非常Nice,赶紧在自己的机器人上复现
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。