【AI 斯坦福 STORM】基于互联网搜索,帮你从零开始撰写文章
从零开始学AI 2024-06-21 10:31:04 阅读 50
今天介绍斯坦福出品的系统,STORM。
STORM是一个基于互联网搜索的LLM系统,可以从零开始撰写类似维基百科的文章。
技术栈:
dspy 一个用于算法优化LM提示和权重的框架You.com搜索API YOU APIs利用实时网络数据使LLMs和搜索体验更加真实和及时。
我们试用下。打开网站
登录
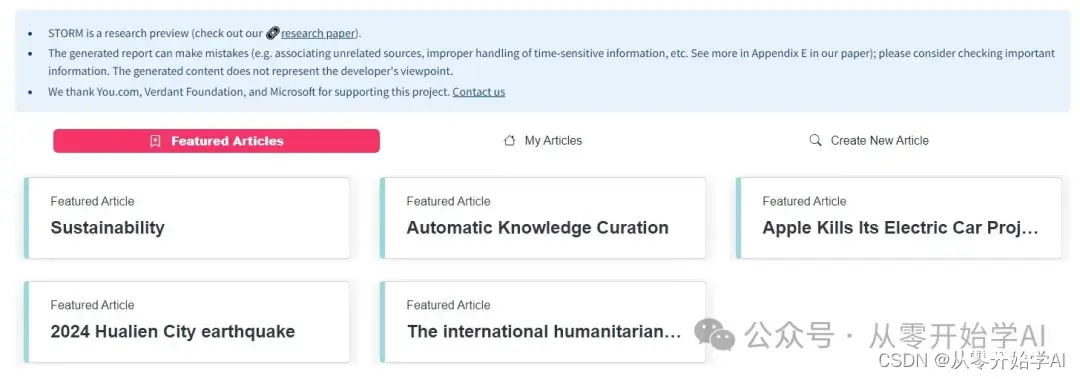
好像还不错,已经有几篇文章了。点击苹果取消电动车项目
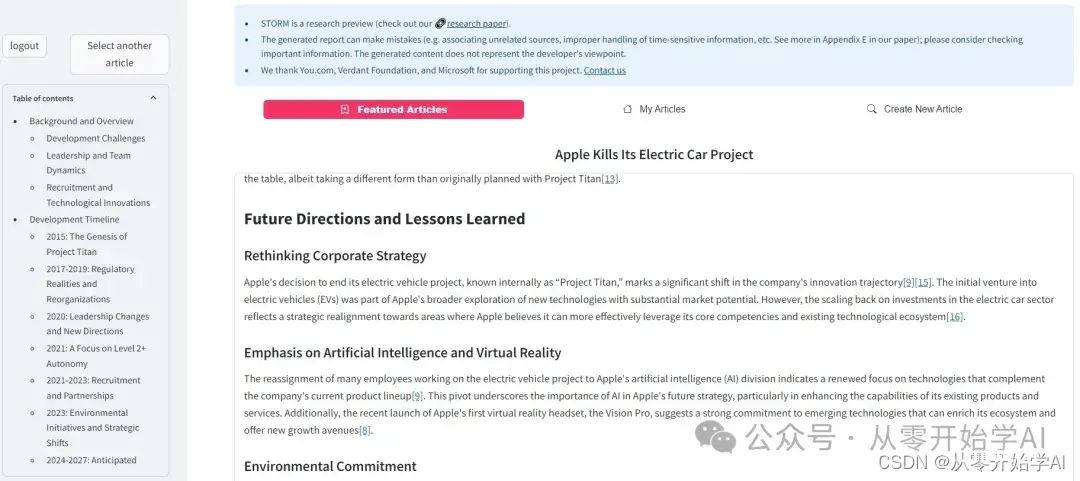
文章不长,看着还可以。我们考虑自己创建一篇试试
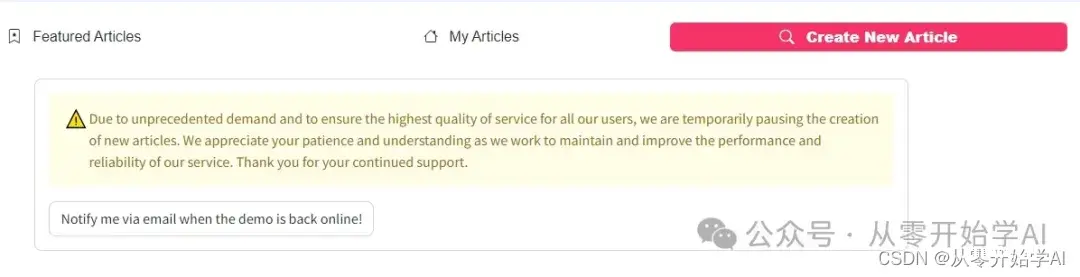
显示现在服务已关闭。。。
看官方的文档,我们还是能学到点不少东西:
分解步骤模拟角色对话调用一些现有的api,例如api.you.com
和之前文章介绍的吴恩达的四种设计模式,其实也非常匹配
ReflectionTool usePlanningMulti-agent collaboration
如有兴趣,请继续往下看官方readme
STORM: 通过检索和多角度提问合成主题概要
该存储库包含我们的NAACL 2024论文《使用大型语言模型协助从零开始撰写类似维基百科的文章》的代码,作者是Yijia Shao、Yucheng Jiang、Theodore A. Kanell、Peter Xu、Omar Khattab和Monica S. Lam。
概述 (立即尝试STORM!)

STORM是一个基于互联网搜索的LLM系统,可以从零开始撰写类似维基百科的文章。
虽然该系统无法生成出版就绪的文章,因为通常需要大量编辑,但经验丰富的维基百科编辑发现在他们的写作前阶段使用它非常有帮助。
请尝试我们的在线演示,看看STORM如何帮助您的知识探索之旅,并提供反馈帮助我们改进系统 🙏!
写作前的研究
STORM将生成带有引用的长篇文章分解为两个步骤:
写作前阶段:系统进行基于互联网的研究,收集参考资料并生成大纲。写作阶段:系统利用大纲和参考资料生成带有引用的完整文章。
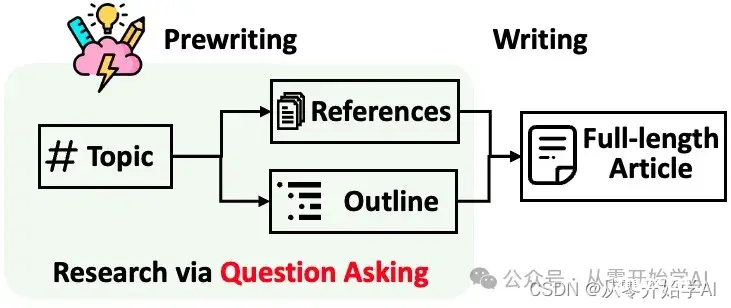
STORM确定自动化研究过程的核心是自动生成良好的问题。直接提示语言模型提问并不奏效。为了提高问题的深度和广度,STORM采用了两种策略:透视指导下的提问:给定输入主题,STORM通过调查类似主题的现有文章发现不同的视角,并用它们来控制提问过程。模拟对话:STORM模拟了一场基于互联网来源的维基百科作者与主题专家之间的对话,以使语言模型能够更新其对主题的理解并提出跟进问题。
基于两个阶段的分离,STORM以高度模块化的方式实现(参见src/engine.py),使用了dspy。
设置
我们将STORM视为自动化知识整理的一个示例。我们正在努力增强我们的代码库以增加其可扩展性。敬请关注!
下面,我们提供一个快速开始指南,以在本地运行STORM以重现我们的实验。
安装所需的包。
conda create -n storm python=3.11conda activate stormpip install -r requirements.txt 设置OpenAI API密钥和You.com搜索API密钥。在根目录下创建一个名为secrets.toml的文件,并添加以下内容:
# 设置OpenAI API密钥。OPENAI_API_KEY=<your_openai_api_key># 如果您使用OpenAI提供的API服务,请包括以下行:OPENAI_API_TYPE="openai"# 如果您使用Microsoft Azure提供的API服务,请包括以下行:OPENAI_API_TYPE="azure"AZURE_API_BASE=<your_azure_api_base_url>AZURE_API_VERSION=<your_azure_api_version># 设置You.com搜索API密钥。YDC_API_KEY=<your_youcom_api_key>
论文实验
我们实验中使用的FreshWiki数据集可以在FreshWiki中找到。
在src目录下运行以下命令。
写作前阶段
针对FreshWiki数据集的批量实验:
python -m scripts.run_prewriting --input-source file --input-path ../FreshWiki/topic_list.csv --engine gpt-4 --do-research --max-conv-turn 5 --max-perspective 5 --engine (choices=[gpt-4, gpt-35-turbo]):用于生成大纲的LLM引擎--do-research:如果为True,则模拟对话以研究主题;否则,加载结果。--max-conv-turn:每个信息寻求对话的最大问题数量--max-perspective:要考虑的最大透视数量,每个透视对应一个信息寻求对话。 STORM还使用一般对话收集有关主题的基本信息。因此,QA对的最大数量为max_turn * (max_perspective + 1)。 💡 减少max_turn或max_perspective可以加快过程速度并降低成本,但可能导致大纲不够全面。如果设置了--disable-perspective(禁用透视驱动的问题提问),则该参数将不会起作用。
要在单个主题上运行实验:
python -m scripts.run_prewriting --input-source console --engine gpt-4 --max-conv-turn 5 --max-perspective 5 --do-research 该脚本会要求您输入Topic和要排除的Ground truth url。如果您没有要排除的URL,请将该字段留空。
生成的大纲将保存在{output_dir}/{topic}/storm_gen_outline.txt中,收集的参考资料将保存在{output_dir}/{topic}/raw_search_results.json中。
写作阶段
针对FreshWiki数据集的批量实验:
python -m scripts.run_writing --input-source file --input-path ../FreshWiki/topic_list.csv --engine gpt-4 --do-polish-article --remove-duplicate --do-polish-article:如果为True,则通过添加摘要部分并在--remove-duplicate设置为True时删除重复内容来润色文章。
要在单个主题上运行实验:
python -m scripts.run_writing --input-source console --engine gpt-4 --do-polish-article --remove-duplicate 该脚本会要求您输入Topic。请输入与写作前阶段使用的主题相同的主题。
生成的文章将保存在{output_dir}/{topic}/storm_gen_article.txt中,与引用索引对应的参考资料将保存在{output_dir}/{topic}/url_to_info.json中。如果设置了--do-polish-article,则润色后的文章将保存在{output_dir}/{topic}/storm_gen_article_polished.txt中。
自定义STORM配置
我们在src/modules/utils.py的LLMConfigs中设置了默认的LLM配置。您可以使用set_conv_simulator_lm()、set_question_asker_lm()、set_outline_gen_lm()、set_article_gen_lm()、set_article_polish_lm()来覆盖默认配置。这些函数接受来自dspy.dsp.LM或dspy.dsp.HFModel的实例。
💡 良好的实践建议,
为conv_simulator_lm选择一个更便宜/更快的模型,用于在对话中拆分查询、合成答案。如果您需要进行实际的写作步骤,请为article_gen_lm选择一个更强大的模型。根据我们的实验,性能较差的模型在生成带有引用的文本方面表现不佳。
自动评估
在我们的论文中,我们将评估分为两个部分:大纲质量和完整文章质量。
大纲质量
我们引入了标题软回溯和标题实体回溯来评估大纲质量。这使得原型化写作前方法变得更加容易。
在./eval目录下运行以下命令,对FreshWiki数据集计算指标:
python eval_outline_quality.py --input-path ../FreshWiki/topic_list.csv --gt-dir ../FreshWiki --pred-dir ../results --pred-file-name storm_gen_outline.txt --result-output-path ../results/storm_outline_quality.csv
完整文章质量
eval/eval_article_quality.py 提供了评估完整文章质量的入口点,使用ROUGE、实体回溯和评分标准来评估。在eval目录下运行以下命令计算指标:
python eval_article_quality.py --input-path ../FreshWiki/topic_list.csv --gt-dir ../FreshWiki --pred-dir ../results --gt-dir ../FreshWiki --output-dir ../results/storm_article_eval_results --pred-file-name storm_gen_article_polished.txt
自行使用指标
基于相似度的指标(例如ROUGE、实体回溯和标题实体回溯)的实现在eval/metrics.py中。
对于评分标准,我们使用了这篇论文中介绍的prometheus-13b-v1.0。eval/evaluation_prometheus.py 提供了使用该指标的入口点。
贡献
如果您有任何问题或建议,请随时提出问题或提交请求。我们欢迎贡献以改进系统和代码库!
联系人:Yijia Shao 和 Yucheng Jiang
引用
如果您在工作中使用了这段代码或其中的一部分,请引用我们的论文:
@inproceedings{shao2024assisting, title={ {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models}}, author={Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam}, year={2024}, booktitle={Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)}}
官网本文 博客 - 从零开始学AI微信 - 从零开始学AICSDN - 从零开始学AI
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。