Kubernetes超详细教程,一篇文章帮助你从零开始学习k8s,从入门到实战
CSDN 2024-10-03 17:37:01 阅读 57
k8s 概述
k8s github地址:https://github.com/kubernetes/kubernetes
官方文档:https://kubernetes.io/zh-cn/docs/home/
k8s,全程是 kubernetes,这个名字源于希腊语,意为"舵手"或"飞行员”
k8s 这个缩写是因为 k 和 s 之间有八个字符
Google 在2014年开源了 k8s 项目,k8s 是一个用于自动化部署、扩展和管理容器化应用程序的开源系统。同样类似的容器编排工具还有 docker swarm/mesos 等,但 k8s 应用最为广泛,社区更为活跃。
什么是 k8s
k8s 是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。它最初由 Google 开发,现由 Cloud Native Computing Foundation(CNCF)维护。k8s 的目标是简化应用程序的部署和管理,提供弹性、可扩展、高可用的服务。
k8s 基于容器技术,如 docker,作为应用程序的基本构建块。容器是一种轻量级的虚拟化技术,可以将应用程序及其依赖项打包到一个独立的、可移植的运行环境中。通过使用容器,开发者可以将应用程序与其运行环境隔离开来,并实现快速部署和跨平台运行。
k8s 提供了一套丰富的功能,用于管理容器化应用的生命周期。它的核心概念包括:
<code>Pod:Pod 是 k8s 管理的最小调度单位,它可以包含一个或多个容器,并共享网络和存储资源。Pod 提供了容器之间的通信和协作。Deployment:Deployment 定义了应用程序的期望状态,并负责创建和管理 Pod 的副本。它支持滚动更新、回滚和扩缩容等操作。Service:Service 定义了一组 Pod 的访问方式和网络策略,为 Pod 提供了稳定的网络端点。Service 可以通过负载均衡将请求分发到后端的 Pod上。Namespace:Namespace 提供了一种逻辑隔离的机制,用于将集群中的资源划分为多个虚拟集群。不同的 Namespace 可以拥有独立的资源配额、访问控制策略等。Volume:Volume 是用于持久化数据的抽象,它可以在 Pod 之间共享和持久化存储数据。k8s 支持多种类型的 Volume,如本地磁盘、网络存储等。
除了上述核心概念之外,k8s 还提供了许多其他功能,包括自动扩展、存储管理、配置管理、日志和监控等。它支持水平扩展和自动化恢复,可以根据应用程序的资源需求和约束条件自动调度和管理容器的运行。k8s 还提供了丰富的 API 和命令行工具,使得开发者和运维人员可以方便地管理和操作容器化应用。
k8s 的设计目标是高度可扩展和高可用的,可以在大规模的集群上运行和管理应用程序。它可以部署在各种云平台和裸机环境中,支持多种操作系统和容器运行时。k8s 已经成为容器编排领域的事实标准,被广泛应用于云原生应用的开发和运维中。
为什么要使用 k8s
当你的应用只是跑在一台机器,直接一个 docker + docker-compose 就够了,方便轻松;
当你的应用需要跑在3、4台机器上,你依旧可以每台机器单独配置运行环境 + 负载均衡;
当你应用访问数不断增加,机器逐渐增加到十几台、上百台、上千台时,每次加机器、软件更新、版本回滚,都会变得非常麻烦、痛不欲生
这时候,k8s 就可以一展身手了;
它是一个全新的基于容器技术的分布式架构领先方案,是谷歌十几年依赖大规模应用容器技术的经验积累和升华的一个重要成果。
运维、部署问题。集群拓展问题、容器编排管理问题
若是咱们的系统设计遵循了 k8s 的设计思想,那么传统系统架构中那些和业务没有多大关系的底层代码或功能模块,均可以马上从咱们的视线消失,咱们没必要再费心于负载均衡器和部署实施问题,没必要再考虑引用或本身开发一个复杂的服务治理框架,没必要再头疼于服务监控和故障处理模块的开发。使用 k8s 提供的解决方案,咱们节省了超过30%的开发成本,同时能够将精力更加集中于业务自己,并且因为 k8s 提供了强大的自动化机制,因此系统后期的运维难度和运维成本也大幅度下降。
k8s 是一个开放的开发平台。没有限定任何编程接口,因此不管是 Java、Go、C++ 还是用 python 编写的服务,均可以毫无困难地映射为 k8s 的Service,并经过标准的 TCP 通讯协议进行交互。此外,因为 k8s 平台对现有的编程语言、编程框架、中间价没有任何侵入性,所以现有的系统很容易改造升级并迁移到 k8s 平台上。
IT 行业历来都是一个由新技术驱动的行业。
新兴的容器化技术当前已经被不少公司所采用,其从单机走向集群已成为必然,而云计算的蓬勃发展正在加速这一进程。k8s 做为当前惟一被业界普遍承认和看好的容器分布式系统解决方案,能够预见,在将来几年内,会有大量的新系统选择它,无论这些系统是运行在企业本地服务器或者是被托管到公有云上。
项目部署的发展历程
谈起 k8s 的发展历史,首先回顾一下项目部署的发展历程,分布经历了物理机、虚拟机、容器化三个阶段的演变。
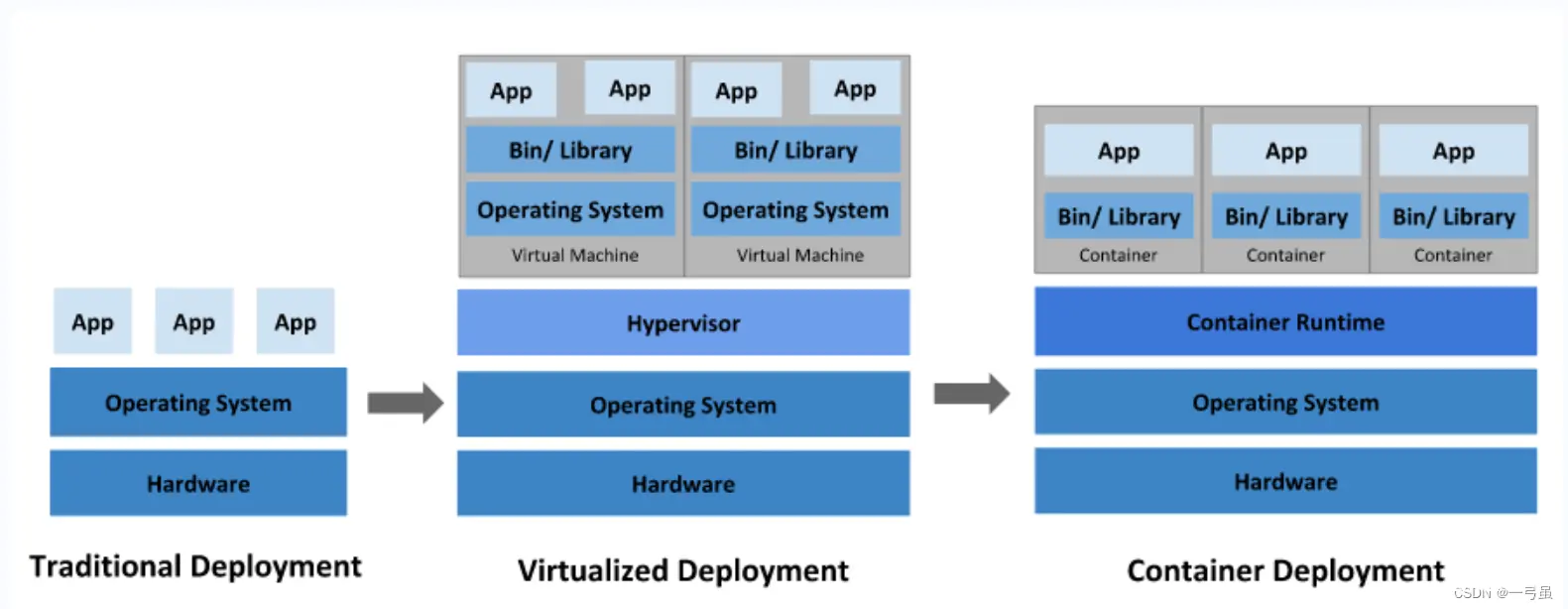
传统部署时代:
早期,应用程序直接在物理服务器上运行,无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况,结果可能导致其他应用程序的性能下降。一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展,并且维护许多物理服务器的成本很高。
虚拟化部署时代:
为了解决物理机存在的弊端,引入了虚拟化技术,支持在单个物理服务器的 CPU 上运行多个虚拟机(VM),每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。虚拟化技术允许应用程序在 VM 之间隔离,提供一定程度的安全,一个应用程序的信息不能被另一应用程序随意访问。虚拟化技术能够更好地利用物理服务器上的资源,由于可轻松地添加或更新应用程序而实现更好的可伸缩性,降低了硬件成本。
容器部署时代:
容器类似于 VM,但是具有被放宽的隔离属性,可以在应用程序之间共享操作系统,因此容器被认为是轻量级的隔离。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等,由于它们与基础架构分离,因此可以跨云和操作系统发行版本进行移植。
问题出现:一旦容器多了,如何进行管理
随着微服务、容器化等技术的发展,解决了资源利用率不高的问题,但是随之而来却是如何进行容器管理,过多的容器使得运维工作也成为了一种负担,因此容器编排对于大型依托于容器化部署的分布式系统至关重要。在容器编排方面,k8s 所扮演的角色如下图所示:

k8s 相当于在容器之上,对服务器资源以及容器调度等过程进行管理
k8s 的特点与功能
特点:
可移植:支持公有云,私有云,混合云,多重云;可扩展:模块化,插件化,可挂载,可组合;自动化:自动部署,自动重启,自动复制,自动伸缩/扩展。
功能:
自动装箱:基于容器对应用运行环境的资源配置要求自动部署应用容器。自我修复(自愈能力):当容器失败时,会对容器进行重启;当所部署的 Node 节点有问题时,会对容器进行重新部署和重新调度;当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务。水平扩展:通过简单的命令、用户UI 界面或基于 CPU 等资源使用情况,对应用容器进行规模扩大或规模剪裁。服务发现:用户不需使用额外的服务发现机制,就能够基于 k8s 自身能力实现服务发现和负载均衡。滚动更新:可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新。版本回退:可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退。密钥和配置管理:在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署。存储编排:自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要,存储系统可以来自于本地目录、网络存储(NFS、Gluster、Ceph、Cinder 等)公共云存储服务等
k8s 优点
k8s 作为一个容器编排平台,具有许多优点,使其成为云原生应用开发和运维的首选工具
自动化管理:k8s 可以自动化地部署、扩展和管理应用程序。它提供了丰富的功能,如自动调度、自动伸缩、自动恢复等,减轻了人工管理的负担,提高了应用程序的可靠性和稳定性。弹性扩展:k8s 支持水平扩展,可以根据应用程序的负载情况动态调整应用程序的副本数量。当负载增加时,k8s 可以自动添加新的副本来处理更多的请求,当负载减少时,k8s 可以自动缩减副本数量,以节省资源。高可用性:k8s 具有高可用性的设计,可以在集群中自动进行容器的调度和迁移,以实现故障转移和负载均衡。它可以检测到容器或节点的故障,并自动重新调度容器到可用节点上,从而确保应用程序的连续可用性。灵活的部署模型:k8s 可以部署各种类型的应用程序,包括微服务架构、传统的单体应用程序、批处理作业等。它提供了丰富的部署配置选项,可以根据应用程序的需求进行定制化配置,并支持多种部署策略,如滚动更新、蓝绿部署等。跨平台和云厂商无关性:k8s 可以在各种云平台和裸机环境中部署和运行,它与特定的操作系统和容器运行时无关。这意味着开发者可以在不同的环境中无缝迁移应用程序,而不必担心依赖于特定的硬件或软件。强大的生态系统:k8s 拥有庞大的社区和丰富的生态系统,提供了许多插件和工具,用于扩展和增强其功能。开发者可以从这些插件中选择适合自己需求的工具,以满足特定的开发和运维需求。可观测性和监控:k8s 提供了丰富的监控和日志功能,可以实时监控应用程序的状态和性能指标,帮助开发者快速诊断和解决问题。它还支持集成外部监控工具和日志分析系统,以进一步增强可观测性。
总的来说,k8s 具有自动化管理、弹性扩展、高可用性、灵活的部署模型、跨平台和云厂商无关性、强大的生态系统以及可观测性和监控等优点,使其成为容器编排领域的事实标准,被广泛应用于云原生应用的开发和运维中。
k8s 设计架构
k8s 集群 = 多个 master node + 多个 work node
k8s 中包含了很多新的概念,它通过整合资源,提供了一套便于应用部署的方案及实现,极大减少了系统运维的工作量。
官方架构设计图:
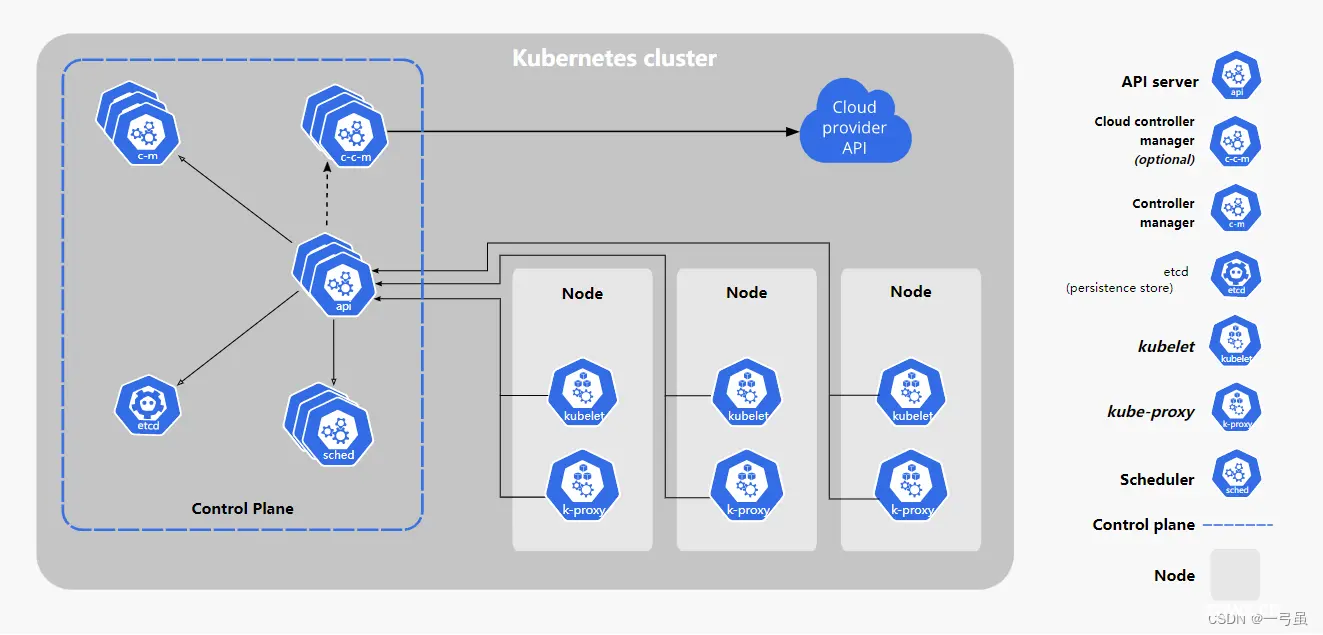
k8s 通常是集群化部署,一个 k8s 集群由一组被称作节点(Node)的机器组成,一个节点可以理解为一台服务器,这些节点上运行 k8s 所管理的容器化应用。集群具有至少一个控制节点(MasterNode)和若干工作节点(WorkNode),节点可以是物理机或者虚拟机。
控制节点包含了控制平面(Contro Plane),控制平面中的组件用来管理整个集群,工作节点用来托管对应的工作负载 Pod。
一般来说节点上都会包含 kubelet、kube-proxy 等组件以及容器运行时。
需要知道的一些概念:
控制平面:让我们从 k8s 集群的神经中枢(即控制平面)开始说起。在这里,我们可以找到用于控制集群的 k8s 组件以及一些有关集群状态和配置的数据。这些核心 k8s 组件负责处理重要的工作,以确保容器以足够的数量和所需的资源运行。 控制平面会一直与您的计算机保持联系。集群已被配置为以特定的方式运行,而控制平面要做的就是确保万无一失。kube-apiserver:如果需要与您的 k8s 集群进行交互,就要通过 API。k8s API 是 k8s 控制平面的前端,用于处理内部和外部请求。API 服务器会确定请求是否有效,如果有效,则对其进行处理。您可以通过 REST 调用、kubectl 命令行界面或其他命令行工具(例如 kubeadm)来访问 API。kube-scheduler:您的集群是否状况良好?如果需要新的容器,要将它们放在哪里?这些是 k8s 调度程序所要关注的问题。调度程序会考虑容器集的资源需求(例如 CPU 或内存)以及集群的运行状况。随后,它会将容器集安排到适当的计算节点。kube-controller-manager:控制器负责实际运行集群,而 k8s 控制器管理器则是将多个控制器功能合而为一。控制器用于查询调度程序,并确保有正确数量的容器集在运行。如果有容器集停止运行,另一个控制器会发现并做出响应。控制器会将服务连接至容器集,以便让请求前往正确的端点。还有一些控制器用于创建帐户和 API 访问令牌。etcd:配置数据以及有关集群状态的信息位于 etcd(一个键值存储数据库)中。etcd 采用分布式、容错设计,被视为集群的最终事实来源。容器集 Pod:容器集是 k8s 对象模型中最小、最简单的单元。它代表了应用的单个实例。每个容器集都由一个容器(或一系列紧密耦合的容器)以及若干控制容器运行方式的选件组成。容器集可以连接至持久存储,以运行有状态应用。容器运行时引擎:为了运行容器,每个计算节点都有一个容器运行时引擎。比如 docker,但 k8s 也支持其他符合开源容器运动(OCI)标准的运行时,例如 rkt 和 CRI-O。kubelet:每个计算节点中都包含一个 kubelet,这是一个与控制平面通信的微型应用。kubelet 可确保容器在容器集内运行。当控制平面需要在节点中执行某个操作时,kubelet 就会执行该操作。kube-proxy:每个计算节点中还包含 kube-proxy,这是一个用于优化 k8s 网络服务的网络代理。kube-proxy 负责处理集群内部或外部的网络通信。
k8s 使用场景
k8s 适用于各种使用场景,尤其适用于云原生应用的开发和运维。以下是一些常见的k8s 使用场景:
微服务架构:k8s 可以有效地管理和部署微服务架构。它可以将不同的微服务部署为独立的容器,通过 Service 和 Ingress 等机制实现微服务之间的通信和负载均衡。k8s 提供了弹性扩展和自动恢复的能力,可以根据负载情况动态调整微服务的副本数量,确保高可用性和性能。自动化部署和持续集成/持续交付(CI/CD):k8s 可以与 CI/CD 工具集成,实现自动化的部署和持续交付。开发者可以使用 k8s 的 Deployment 和Service 等资源对象定义应用程序的期望状态,并通过 CI/CD 工具自动构建、测试和发布应用程序到 k8s 集群中。弹性扩展和负载均衡:k8s 支持水平扩展,可以根据应用程序的负载情况动态调整副本数量。它可以根据负载自动添加或删除容器实例,并通过Service 和 Ingress 等机制实现负载均衡,确保请求能够平均分发到后端的容器上。多租户和多环境管理:k8s 提供了 Namespace 的概念,可以将集群中的资源划分为多个虚拟集群,实现多租户的管理。通过使用不同的Namespace,可以将不同的应用程序或不同的环境(如开发、测试、生产)隔离开来,提供更好的资源隔离和安全性。批处理和定时任务:k8s 可以用于批处理作业和定时任务的管理。通过使用 CronJob 等资源对象,可以定义和调度定时任务,例如数据处理、报表生成等。k8s 提供了任务的并行执行、故障恢复和任务状态监控等功能,适用于处理大规模的批处理工作负载。混合云和多云环境管理:k8s 具有跨平台和云厂商无关性的特性,可以在混合云和多云环境中部署和管理应用程序。它可以在不同的云平台上运行,如 AWS、Azure、Google Cloud 等,同时也可以在私有云和裸机环境中部署。这使得开发者可以在不同的环境中无缝迁移应用程序,并减少对特定云厂商的依赖。
总的来说,k8s 适用于微服务架构、自动化部署和 CI/CD、弹性扩展和负载均衡、多租户和多环境管理、批处理和定时任务,以及混合云和多云环境管理等多种使用场景。它提供了丰富的功能和灵活的配置选项,使开发者能够更方便地管理和运维容器化应用程序。
minikube 安装
minikube 是一个用于在本地计算机上运行单个节点的 k8s 集群的工具。它允许开发人员可以在自己的计算机上进行本地的 k8s 开发和测试。通过minikube,您可以模拟一个完整的 k8s 集群环境,包括节点、Pod、服务和存储等组件。它是一个轻量级、易于安装和使用的工具,适用于在本地进行 k8s 相关的开发、测试和学习。
徒手搭建过 k8s 的同学都晓得其中的煎熬,复杂的认证,配置环节相当折磨人,出错率相当高,而 minikube 就是为解决这个问题而衍生出来的工具,minikube 可以在单机环境下快速搭建可用的 k8s 集群,非常适合测试和本地开发,现有的大部分在线 k8s 实验环境也是基于 minikube 的。
可以在 minikube 上体验 kubernetes 的相关功能。
minikube 基于 go 语言开发,可以在单机环境下快速搭建可用的 k8s 集群,快速启动,消耗机器资源较少,可在你的笔记本电脑上的虚拟机内轻松创建单机版 k8s 集群,非常适合测试和本地开发。
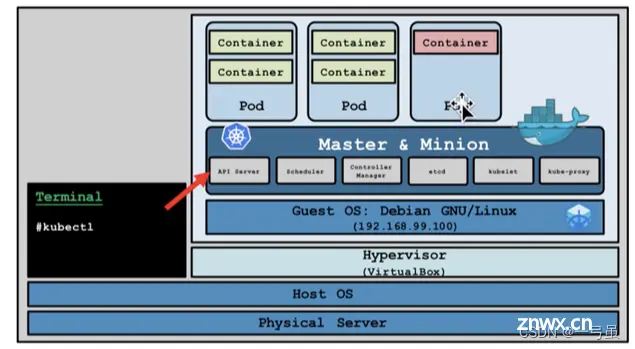
minikube 架构
下图是 minikube的架构,可以看出,master 节点与其它节点合为一体,而整体则通过宿主机上的 kubectl 进行管理,这样可以更加节省资源。
其支持大部分 k8s 的功能,列表如下:
<code>DNS
NodePorts
ConfigMaps and Secrets
Dashboards
Container Runtime: Docker, and rkt
Enabling CNI (Container Network Interface)
Ingress
…
minikube 支持 Windows、macOS、Linux 三种 OS系统,会根据平台不同,下载对应的虚拟机镜像,并在镜像内安装 K8S。
我们这里直接使用 Windows 安装体验。
minikube 安装
下载步骤:
安装 docker
下载地址:https://docs.docker.com/desktop/install/windows-install/
知道下载后的 Docker for Windows Installer 安装文件,完成安装。
安装好之后会重启
安装好后如图所示
安装 minikube
minikube 下载地址 https://minikube.sigs.k8s.io/docs/start/
1、点击这里下载安装程序<code>minikube-installer.exe,安装即可

2、配置环境变量
3、命令行测试,需要保证 docker 启动
minikube 常用命令
查看 minikube 版本
<code>minikube version
C:\Users\DELL>minikube version
W0323 17:19:55.916748 1800 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
minikube version: v1.32.0
commit: 8220a6eb95f0a4d75f7f2d7b14cef975f050512d
启动 minikube
minikube start
C:\Users\DELL>minikube start
W0323 17:24:17.006260 23440 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
* Microsoft Windows 11 Home China 10.0.22631.3296 Build 22631.3296 上的 minikube v1.32.0
* 根据现有的配置文件使用 docker 驱动程序
* 正在集群 minikube 中启动控制平面节点 minikube
* 正在拉取基础镜像 ...
> index.docker.io/kicbase/sta...: 453.90 MiB / 453.90 MiB 100.00% 2.61 Mi
! minikube was unable to download gcr.io/k8s-minikube/kicbase:v0.0.42, but successfully downloaded docker.io/kicbase/stable:v0.0.42 as a fallback image
* Creating docker container (CPUs=2, Memory=4000MB) ...
* 正在 Docker 24.0.7 中准备 Kubernetes v1.28.3…
- 正在生成证书和密钥...
- 正在启动控制平面...
- 配置 RBAC 规则 ...
* 配置 bridge CNI (Container Networking Interface) ...
* 正在验证 Kubernetes 组件...
- 正在使用镜像 gcr.io/k8s-minikube/storage-provisioner:v5
* 启用插件: storage-provisioner, default-storageclass
* 完成!kubectl 现在已配置,默认使用"minikube"集群和"default"命名空间
检查 minikube 集群状态
minikube status
C:\Users\DELL>minikube status
W0323 17:30:34.612462 4616 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
获取 minikube 集群的 ip 地址
minikube ip
C:\Users\DELL>minikube ip
W0323 17:31:38.368205 2484 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
192.168.49.2
通过 SSH 连接到正在运行的 minikube 集群
minikube ssh
C:\Users\DELL>minikube ssh
W0323 17:34:12.883919 24608 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
# 查看集群下所有的 docker 容器
docker@minikube:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1407610b3a2f 6e38f40d628d "/storage-provisioner" 6 minutes ago Up 6 minutes k8s_storage-provisioner_storage-provisioner_kube-system_d4ee5dfb-c7e0-441c-baa2-12474b5ad5c4_1
f6403b614117 ead0a4a53df8 "/coredns -conf /etc…" 7 minutes ago Up 7 minutes k8s_coredns_coredns-5dd5756b68-w9wgv_kube-system_0a9ad253-2304-447e-8ab3-2f06da88a721_0
606d3bac1dbb registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_coredns-5dd5756b68-w9wgv_kube-system_0a9ad253-2304-447e-8ab3-2f06da88a721_0
4cdfd56f9d60 bfc896cf80fb "/usr/local/bin/kube…" 7 minutes ago Up 7 minutes k8s_kube-proxy_kube-proxy-cdq9d_kube-system_2f2aca3c-4d8c-45c1-8efc-b7d0d4938025_0
821e8c045d0c registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_kube-proxy-cdq9d_kube-system_2f2aca3c-4d8c-45c1-8efc-b7d0d4938025_0
c7f05331626d registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_storage-provisioner_kube-system_d4ee5dfb-c7e0-441c-baa2-12474b5ad5c4_0
ae5966109c8a 6d1b4fd1b182 "kube-scheduler --au…" 7 minutes ago Up 7 minutes k8s_kube-scheduler_kube-scheduler-minikube_kube-system_75ac196d3709dde303d8a81c035c2c28_0
49f497991344 10baa1ca1706 "kube-controller-man…" 7 minutes ago Up 7 minutes k8s_kube-controller-manager_kube-controller-manager-minikube_kube-system_7da72fc2e2cfb27aacf6cffd1c72da00_0
51420b3b4a70 73deb9a3f702 "etcd --advertise-cl…" 7 minutes ago Up 7 minutes k8s_etcd_etcd-minikube_kube-system_9aac5b5c8815def09a2ef9e37b89da55_0
982fdca2d503 537434729123 "kube-apiserver --ad…" 7 minutes ago Up 7 minutes k8s_kube-apiserver_kube-apiserver-minikube_kube-system_55b4bbe24dac3803a7379f9ae169d6ba_0
7f2976f13746 registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_kube-scheduler-minikube_kube-system_75ac196d3709dde303d8a81c035c2c28_0
b2b10a4815fa registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_kube-controller-manager-minikube_kube-system_7da72fc2e2cfb27aacf6cffd1c72da00_0
eff72a86aa15 registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_kube-apiserver-minikube_kube-system_55b4bbe24dac3803a7379f9ae169d6ba_0
7236c52d6a38 registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_etcd-minikube_kube-system_9aac5b5c8815def09a2ef9e37b89da55_0
停止服务 minikube
minikube stop
启动 minikube 的仪表板(可视化界面),执行此命令后,将自动打开一个浏览器窗口,显示 minikube 集群的仪表板界面
minikube dashboard
C:\Users\DELL>minikube dashboard
W0323 17:40:48.423278 11632 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
* 正在开启 dashboard ...
- 正在使用镜像 docker.io/kubernetesui/dashboard:v2.7.0
- 正在使用镜像 docker.io/kubernetesui/metrics-scraper:v1.0.8
* 某些 dashboard 功能需要启用 metrics-server 插件。为了启用所有功能,请运行以下命令:
minikube addons enable metrics-server
* 正在验证 dashboard 运行情况 ...
* 正在启动代理...
* 正在验证 proxy 运行状况 ...
^C
C:\Users\DELL>minikube dashboard
W0323 17:41:42.866075 25216 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
* 正在验证 dashboard 运行情况 ...
* 正在启动代理...
* 正在验证 proxy 运行状况 ...
* 正在使用默认浏览器打开 http://127.0.0.1:59903/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ ...
停止 minikube 集群服务
<code>minikube stop
C:\Users\DELL>minikube stop
W0323 17:53:55.131539 25916 main.go:291] Unable to resolve the current Docker CLI context "default": context "default": context not found: open C:\Users\DELL\.docker\contexts\meta\37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f\meta.json: The system cannot find the path specified.
* 正在停止节点 "minikube" ...
* 正在通过 SSH 关闭“minikube”…
* 1 个节点已停止。
可以通过以下命令获取 minibuke 相关信息
# 获取所有节点
kubectl get node
C:\Users\DELL>kubectl get node
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane 17m v1.28.3
# 获取所有命名空间中的Pod列表
kubectl get pods -A
C:\Users\DELL>kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-5dd5756b68-w9wgv 1/1 Running 0 19m
kube-system etcd-minikube 1/1 Running 0 19m
kube-system kube-apiserver-minikube 1/1 Running 0 19m
kube-system kube-controller-manager-minikube 1/1 Running 0 19m
kube-system kube-proxy-cdq9d 1/1 Running 0 19m
kube-system kube-scheduler-minikube 1/1 Running 0 19m
kube-system storage-provisioner 1/1 Running 1 (18m ago) 19m
kubernetes-dashboard dashboard-metrics-scraper-7fd5cb4ddc-lxkt2 1/1 Running 0 7m45s
kubernetes-dashboard kubernetes-dashboard-8694d4445c-sl6cc 1/1 Running 0 7m45s
服务器裸机搭建 k8s 集群
环境准备
至少3个服务器(本次使用3台阿里云服务器),4核4G以上(按量付费),内网要能互相通信,也就是必须要在同一个网段下
本次实验的3个服务器私网 ip 如下:
192.168.0.1 (主机)
192.168.0.2
192.168.0.3
这3个服务器一台为 master node(初始化主节点)、两台 work node(工作节点)
3个服务器都要安装 docker
3个服务器同时执行命令:
在输入命令行位置右键发送键输入到所有会话
# 移除之前安装的 docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 安装 gcc 环境
sudo yum install -y gcc
sudo yum install -y gcc-c++
# 配置yum源
sudo yum install -y yum-utils
# 使用国内的镜像。
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 更新 yum 索引
sudo yum makecache fast
# 安装 docker
sudo yum install -y docker-ce docker-ce-cli containerd.io
# 配置阿里云镜像加速,在自己的阿里云镜像加速器查看
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://g8vxwvax.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
# 设置开机启动Docker
sudo systemctl enable docker
# 检查是否安装成功
docker -v
安装 k8s 前的系统环境准备,官方要求
<code># 节点之中不可以有重复的主机名,mac地址等,设置不同的hostname
# 3个服务器分别执行
hostnamectl set-hostname k8s-master
hostnamectl set-hostname k8s-node1
hostnamectl set-hostname k8s-node2
# 3台服务器全部执行
# 关闭防火墙
sudo systemctl stop firewalld
sudo systemctl disable firewalld
# 将 SElinux 设置为 permissive 模式,禁用
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcin$/SELINUX=permissive/' /etc/selinux/config
# 关闭swap分区
sudo swapoff -a
sudo sed -ri 's/.*swap.*/#&/' /etc/fstab
# 允许 iptables 检查桥接流量(所有节点)
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system
至此,我们的所有环境就配置好了,接下来就要搭建 k8s 集群了
安装集群三大件 kubelet、kubeadm、kubectl
你需要在每台机器上安装以下的软件包:
kubeadm:用来初始化集群的指令。kubelet:在集群中的每个节点上用来启动 Pod 和容器等。kubectl:用来与集群通信的命令行工具。
参考阿里巴巴开源镜像站 k8s 安装步骤:https://developer.aliyun.com/mirror/kubernetes
# 3台服务器全部执行
# 安装 kubeadm、kubelet 和 kubectl,配置yum文件,因为国内无法直接访问google,这里需要将官网中的google的源改为国内源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
setenforce 0
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet && systemctl start kubelet
# 查看版本信息
kubectl version
在 k8s v1.24 及更早版本中,我们使用 docker 作为容器引擎在 k8s 上使用时,依赖一个 dockershim 的内置 k8s 组件,k8s v1.24发行版中将dockershim 组件给移除了,取而代之的就是 cri-dockerd(当然还有其它容器接口),简单讲 CRI 就是容器运行时接口(Container Runtime Interface,CRI),也就是说 cri-dockerd 就是以 docker 作为容器引擎而提供的容器运行时接口,如果我们想要用 docker 作为 k8s 的容器运行引擎,我们需要先部署好 cri-dockerd,用 cri-dockerd 来与 kubelet 交互,然后再由 cri-dockerd 和 docker api 交互,使我们在 k8s 能够正常使用 docker 作为容器引擎。
<code># 下载
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.4/cri-dockerd-0.3.4.amd64.tgz
# 解压cri-docker
tar xvf cri-dockerd-*.amd64.tgz
cp -r cri-dockerd/ /usr/bin/
chmod +x /usr/bin/cri-dockerd/cri-dockerd
# 写入启动cri-docker配置文件
cat > /usr/lib/systemd/system/cri-docker.service <<EOF
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
# 写入cri-docker的socket配置文件
cat > /usr/lib/systemd/system/cri-docker.socket <<EOF
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
EOF
# 当你新增或修改了某个单位文件(如.service文件、.socket文件等),需要运行该命令来刷新systemd对该文件的配置。
systemctl daemon-reload
# 确保docker是启动的
# 启用并立即启动cri-docker.service单元。
systemctl enable --now cri-docker.service
# 显示docker.service单元的当前状态,包括运行状态、是否启用等信息。
systemctl status cri-docker.service
出现以下内容说明启动成功:
[root@k8s-master ~]# systemctl status cri-docker.service
● cri-docker.service - CRI Interface for Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/cri-docker.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2024-03-24 16:01:06 CST; 9s ago
Docs: https://docs.mirantis.com
Main PID: 3238 (cri-dockerd)
Tasks: 9
Memory: 14.5M
CGroup: /system.slice/cri-docker.service
└─3238 /usr/bin/cri-dockerd/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/googl...
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Start docker client with r...ut 0s"code>
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Hairpin mode is set to none"code>
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Loaded network plugin cni"code>
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Docker cri networking mana...n cni"code>
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Docker Info: &{ID:a848d1ba... [Nati
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Setting cgroupDriver cgroupfs"code>
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Docker cri received runtim...:,},}"code>
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Starting the GRPC backend ...face."code>
Mar 24 16:01:06 k8s-master cri-dockerd[3238]: time="2024-03-24T16:01:06+08:00" level=info msg="Start cri-dockerd grpc backend"code>
Mar 24 16:01:06 k8s-master systemd[1]: Started CRI Interface for Docker Application Container Engine.
Hint: Some lines were ellipsized, use -l to show in full.
总结:环境准备
机器环境安装了 k8s 的组件安装 cri 环境
安装并初始化 master 节点
# 所有机器添加master节点的域名映射,这里要改为自己当下master的ip
echo "192.168.0.1 cluster-master" >> /etc/hosts
# node节点ping测试映射是否成功
ping cluster-master
# 如果init失败,可以kubeadm重置
kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
####### 主节点初始化(只在master执行) #######
# 注意修改apiserver的地址为master节点的ip
## 注意service、pod的网络节点不能和master网络ip重叠
kubeadm init \
--apiserver-advertise-address=192.168.0.1 \
--control-plane-endpoint=cluster-master \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.28.2 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.169.0.0/16 \
--cri-socket unix:///var/run/cri-dockerd.sock
等待命令运行完毕即可,执行成功后可以看到
[root@k8s-master ~]# kubeadm init \
> --apiserver-advertise-address=192.168.0.1 \
> --control-plane-endpoint=cluster-master \
> --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
> --kubernetes-version v1.28.2 \
> --service-cidr=10.96.0.0/16 \
> --pod-network-cidr=192.169.0.0/16 \
> --cri-socket unix:///var/run/cri-dockerd.sock
[init] Using Kubernetes version: v1.28.2
......
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster-master:6443 --token 9jk1zp.v738zd885ew7m7lp \
--discovery-token-ca-cert-hash sha256:6a1cb9a74d02f28b06471114e28faa8de6cbc3501eb3a9a989123840c281e85a \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-master:6443 --token 9jk1zp.v738zd885ew7m7lp \
--discovery-token-ca-cert-hash sha256:6a1cb9a74d02f28b06471114e28faa8de6cbc3501eb3a9a989123840c281e85a
根据上面的提示信息,我们在 master 中执行以下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
初始化完成后,可以使用命令查看节点信息了
kubectl get nodes
# 发现是 NotReady 状态
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane 5m47s v1.28.2
work 节点加入集群
加入节点命令,此命令的参数是在初始化完成后给出的,每个人的都不一样,需要复制自己生成的。
是上面初始化 master 节点执行后信息的最后几行,查看自己生成的
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-master:6443 --token 9jk1zp.v738zd885ew7m7lp \
--discovery-token-ca-cert-hash sha256:6a1cb9a74d02f28b06471114e28faa8de6cbc3501eb3a9a989123840c281e85a
根据自己生成的信息执行以下命令:
kubeadm join cluster-master:6443 --token 9jk1zp.v738zd885ew7m7lp \
--discovery-token-ca-cert-hash sha256:6a1cb9a74d02f28b06471114e28faa8de6cbc3501eb3a9a989123840c281e85a \
--cri-socket unix:///var/run/cri-dockerd.sock
# 需要注意的是,如果由于当前版本不再默认支持docker,如果服务器使用的docker,需要在命令后面加入参数--cri-socket unix:///var/run/cri-dockerd.sock。
执行完成后,在 master 主机上查看节点信息
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane 11m v1.28.2
k8s-node1 NotReady <none> 13s v1.28.2
k8s-node2 NotReady <none> 7s v1.28.2
#另外token默认的有效期为24小时,过期之后就不能用了,需要重新创建token,操作如下
kubeadm token create --print-join-command
# 另外,短时间内生成多个token时,生成新token后建议删除前一个旧的。
# 查看命令
kubeadm token list
# 删除命令
kubeadm token delete tokenid
部署 calico
我们需要部署一个 pod 网络插件,安装 Pod 网络是 Pod 之间进行通信的必要条件,k8s 支持众多网络方案,这里选用 calico 方案。
文档:https://kubernetes.io/docs/concepts/cluster-administration/addons/
calico 历史版本地址:https://docs.tigera.io/archive#v3.1.7
# 下载calico.yml
curl https://docs.tigera.io/archive/v3.25/manifests/calico.yaml -O
我们 initmaster 上面配置的 --pod-network-cidr=192.169.0.0/16,这里面也要对应修改
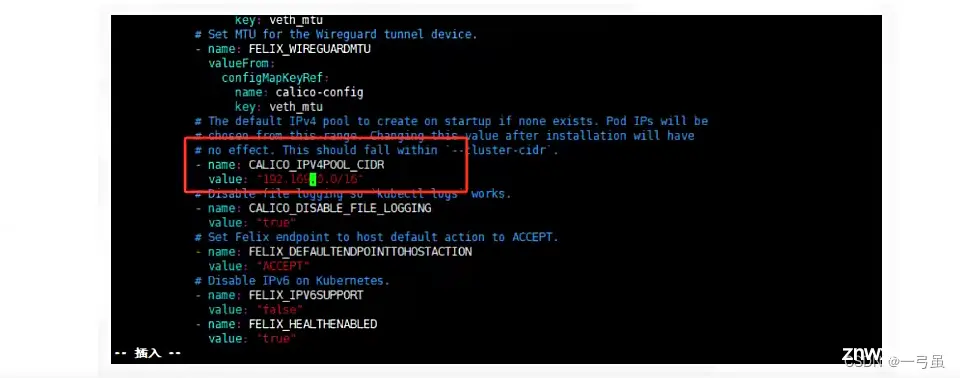
可能存在的问题:calico 默认会找 eth0 网卡,如果当前机器网卡不是这个名字,可能会无法启动,需要手动配置以下。
使用以下命令查找:
<code>ll /etc/sysconfig/network-scripts/

框起来的就是网卡名字,我这里是 eth0。如果是用虚拟机搭建的,网卡名字可能不同
如果网卡名字不是 eth0,需要编辑<code>calico.yaml配置文件加入如下内容 ,在 CLUSTER_TYPE 同级目录下
- name: IP_AUTODETECTION_METHOD
value: "interface=eth0"# 改成你自己的网卡名字
网卡名字为 eth0 的则不需要配置
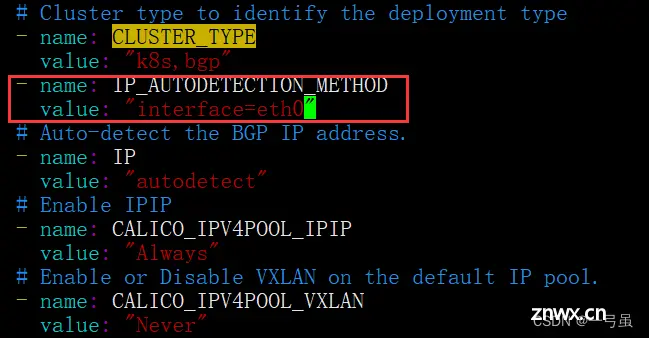
修改完配置后,我们应用一下,应用完毕之后需要等待一下。
<code>kubectl apply -f calico.yaml
[root@k8s-master ~]# kubectl apply -f calico.yaml
poddisruptionbudget.policy/calico-kube-controllers created
serviceaccount/calico-kube-controllers created
serviceaccount/calico-node created
configmap/calico-config created
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/caliconodestatuses.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipreservations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org created
clusterrole.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrole.rbac.authorization.k8s.io/calico-node created
clusterrolebinding.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrolebinding.rbac.authorization.k8s.io/calico-node created
daemonset.apps/calico-node created
deployment.apps/calico-kube-controllers created
等待一会以后,发现我们的节点状态变为了 Ready ,就OK了
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 40m v1.28.2
k8s-node1 Ready <none> 29m v1.28.2
k8s-node2 Ready <none> 29m v1.28.2
查看所有的 pod
kubectl get pod -A
[root@k8s-master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-658d97c59c-wzj97 1/1 Running 0 9m18s
kube-system calico-node-f76hr 1/1 Running 0 2m10s
kube-system calico-node-llncs 1/1 Running 0 2m
kube-system calico-node-lwqjh 1/1 Running 0 109s
kube-system coredns-6554b8b87f-pbmbq 1/1 Running 0 42m
kube-system coredns-6554b8b87f-pgrq2 1/1 Running 0 42m
kube-system etcd-k8s-master 1/1 Running 0 42m
kube-system kube-apiserver-k8s-master 1/1 Running 0 42m
kube-system kube-controller-manager-k8s-master 1/1 Running 0 42m
kube-system kube-proxy-58b62 1/1 Running 0 31m
kube-system kube-proxy-b6x29 1/1 Running 0 42m
kube-system kube-proxy-jxct4 1/1 Running 0 31m
kube-system kube-scheduler-k8s-master 1/1 Running 0 42m
测试 k8s 的自愈能力
我们将一个节点关机重启,reboot。
将 k8s-node2 关机:
[root@k8s-node2 ~]# poweroff
Connection closing...Socket close.
Connection closed by foreign host.
Disconnected from remote host(k8s-node2) at 17:02:36.
Type `help' to learn how to use Xshell prompt.
在 master 主机查看节点状态:
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 49m v1.28.2
k8s-node1 Ready <none> 37m v1.28.2
k8s-node2 NotReady <none> 37m v1.28.2
发现 k8s-node2 已经是 NotReady 了,这时我们启动 k8s-node2 这台主机
等待一会,重新在 master 主机查看节点状态
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 51m v1.28.2
k8s-node1 Ready <none> 40m v1.28.2
k8s-node2 Ready <none> 39m v1.28.2
发现 k8s-node2 又自动加入到集群了
k8s 的自愈能力非常强大,主要包括以下几个方面:
自动重启:k8s 监控容器的状态,一旦发现容器崩溃或异常退出,会自动重启容器,确保应用持续可用。
自动扩缩容:k8s 基于资源利用率和负载情况,可以自动扩展或缩减容器副本的数量,以满足应用程序的需求。通过水平扩展和自动负载均衡,k8s可以动态调整容器副本的数量,提高应用程序的可伸缩性和性能。
自动容错和故障迁移:k8s 提供了容器的健康检查机制,可以监控容器的状态,并在容器不健康或不可访问时自动将其从集群中删除,以避免影响其他容器的正常运行。同时,k8s 还支持故障迁移,将故障容器重新部署到其他可用的节点上,以确保应用程序的高可用性。
自动滚动升级:k8s 支持滚动升级应用程序,可以在不中断服务的情况下逐步更新容器版本。通过逐步替换容器副本,k8s 实现了应用程序的平滑升级,降低了升级过程中的风险。
自动恢复:k8s 可以监控节点的健康状态,一旦发现节点故障或不可访问,会自动将容器迁移到其他可用节点上,实现容器的自动恢复。
总的来说,k8s 具有自动管理和调度容器的能力,可以监控容器的状态、自动重启容器、自动扩缩容、自动容错和故障迁移、自动滚动升级等,提供了强大的自愈能力,确保应用程序的高可用性、可伸缩性和稳定性。
安装 k8s Dashboard 可视化界面
项目地址:https://github.com/kubernetes/dashboard
编辑文件recommended.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kubernetes-dashboard
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 31443
selector:
k8s-app: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-certs
namespace: kubernetes-dashboard
type: Opaque
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-csrf
namespace: kubernetes-dashboard
type: Opaque
data:
csrf: ""
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-key-holder
namespace: kubernetes-dashboard
type: Opaque
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
rules:
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs", "kubernetes-dashboard-csrf"]
verbs: ["get", "update", "delete"]
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["kubernetes-dashboard-settings"]
verbs: ["get", "update"]
- apiGroups: [""]
resources: ["services"]
resourceNames: ["heapster", "dashboard-metrics-scraper"]
verbs: ["proxy"]
- apiGroups: [""]
resources: ["services/proxy"]
resourceNames: ["heapster", "http:heapster:", "https:heapster:", "dashboard-metrics-scraper", "http:dashboard-metrics-scraper"]
verbs: ["get"]
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
rules:
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kubernetes-dashboard
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.0.0-rc7
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: { }
serviceAccountName: kubernetes-dashboard
nodeSelector:
"beta.kubernetes.io/os": linux
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
ports:
- port: 8000
targetPort: 8000
selector:
k8s-app: dashboard-metrics-scraper
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: dashboard-metrics-scraper
template:
metadata:
labels:
k8s-app: dashboard-metrics-scraper
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'runtime/default'
spec:
containers:
- name: dashboard-metrics-scraper
image: kubernetesui/metrics-scraper:v1.0.4
ports:
- containerPort: 8000
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 8000
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- mountPath: /tmp
name: tmp-volume
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
serviceAccountName: kubernetes-dashboard
nodeSelector:
"beta.kubernetes.io/os": linux
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
volumes:
- name: tmp-volume
emptyDir: { }
编辑完成后执行应用:
kubectl apply -f recommended.yaml
执行完成后,查看所有 pod
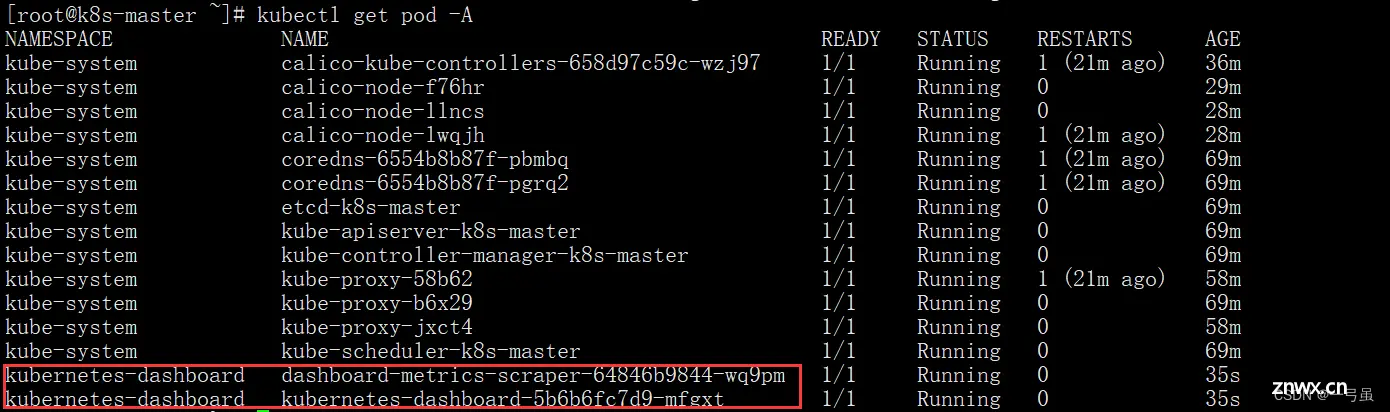
看到这两个成功启动即可
执行下面命令:
<code># 当前默认命名空间下的服务 -A 全部命名空间下的服务
kubectl get svc -A
[root@k8s-master ~]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 70m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 70m
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.12.26 <none> 8000/TCP 100s
kubernetes-dashboard kubernetes-dashboard NodePort 10.96.157.187 <none> 443:31443/TCP 100s
可以看到,访问端口是31443,协议是443,也就是 https
打开浏览器,访问集群任意节点(ip 为3个服务器任意一个即可)即可以进入控制面板。
这里测试我们使用 chrome 浏览器
由于浏览器 chrome 使用 https 不安全,在这个页面凭空输入:thisisunsafe,即可进入
由于登录需要 token,接下来我们创建一个 token
编辑文件<code>dash-token.yaml
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: admin
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: admin
namespace: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kubernetes-dashboard
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
执行应用这个文件,获取令牌:
kubectl apply -f dash-token.yaml
kubectl create token admin --namespace kubernetes-dashboard
[root@k8s-master ~]# kubectl apply -f dash-token.yaml
clusterrolebinding.rbac.authorization.k8s.io/admin created
serviceaccount/admin created
[root@k8s-master ~]# kubectl create token admin --namespace kubernetes-dashboard
eyJhbGciOiJSUzI1NiIsImtpZCI6IkV6MDJ6S1NSMDlvTmJKRGc4WWJ5RUk1aW5MOUxRMUFmNFk3M1BMWmVGWTQifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzExMjc2MzY5LCJpYXQiOjE3MTEyNzI3NjksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbiIsInVpZCI6ImY4NjNhZjk5LTczMWEtNDlkZi04ODhhLWU3MDBlMGNhZWQ2OSJ9fSwibmJmIjoxNzExMjcyNzY5LCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4ifQ.CwVQxLVq6fKRacovFHCQat20Xz-M1OjLCZnKM_ERHa87UchqD6aRYSoZG-oFvW2TVGLvRIwa3ViNNVMWtFMEUwy0Zzg_nM6SdqWc-fvvfWLabA_Deqi0gANlcCcUW6lLlm37iQ9nUrsfRK6LLFlow9J_wkOnB6ZmzSQcNltEbBk5SL4-Zf0goOdycLI79p8xFM26TVg5U-2eILCGBLnVAUMHpADBvkmaKSR3ix1VLFk2g6aPV89ySmt4dTwuXS--bEGW7EY1hF3-8Z_c93x9yP7p7sgdvzKYcwTmeE4ML8M3VGVoK_Nnv5-MBmyDFfDoRSaUdtJBcLiIEUXzkJuhBQ
拿到 token 去登录即可
可以在 dashboard 界面查看自己 k8s 集群的所有信息
k8s 核心概念及操作命令
namespace(简称 ns)
k8s 资源创建的两种方式:使用命令行创建、使用 yaml 文件创建
什么是 ns
在 k8s 中,ns 是一种用于对集群资源进行逻辑分组和隔离的机制。它允许将 k8s 集群划分为多个虚拟集群,一个 ns 可以看作是一个虚拟的集群,每个 ns 内的资源相互隔离,不同 ns 之间的资源不会冲突,它将物理集群划分为多个逻辑部分,不同的业务(web、数据库、消息中间件)可以部署在不同的命名空间,实现业务的隔离,并且可以对其进行资源配额,限制 cpu、内存等资源的使用,名称空间用来隔离资源,是一种标识机制,不会隔离网络。
ns 的主要作用如下:
逻辑分组:ns 可以将集群中的资源进行逻辑分组,使得不同的应用程序或团队可以在同一个集群中独立管理和操作自己的资源,避免资源的混淆和冲突。资源隔离:不同的 ns 之间的资源是相互隔离的,即使具有相同名称的资源也可以在不同的 ns 中存在。这样可以确保不同应用程序或团队之间的资源不会相互干扰,提高了安全性和稳定性。访问控制:ns 提供了基于 ns 的访问控制机制,可以通过角色和角色绑定来控制不同 ns 内的资源访问权限,实现细粒度的权限控制。资源配额:可以为每个 ns 设置资源配额,限制该 ns 内的资源使用量,避免某个应用程序或团队过度占用资源,导致其他应用程序受到影响。监控和日志:k8s 可以对不同 ns 中的资源进行监控和日志记录,方便对集群中不同 ns 的资源进行分析和故障排查。
通过使用 ns,k8s 提供了一种灵活的资源隔离和管理机制,可以将集群划分为多个虚拟集群,实现资源的逻辑分组和隔离,提高了集群的安全性、可管理性和可扩展性。
ns 适合用于隔离不同用户创建的资源,每一个添加到 k8s 集群的工作负载必须放在一个命名空间中,不指定 ns 默认都在 default 下面。
初始 ns
k8s 启动时会创建四个初始名字空间:
<code>default:k8s 包含这个名字空间,以便于你无需创建新的名字空间即可开始使用新集群。
kube-node-lease:该名字空间包含用于与各个节点关联的 Lease(租约)对象。 节点租约允许 kubelet 发送心跳, 由此控制面能够检测到节点故障。
kube-public:所有的客户端(包括未经身份验证的客户端)都可以读取该名字空间。 该名字空间主要预留为集群使用,以便某些资源需要在整个集群中可见可读。 该名字空间的公共属性只是一种约定而非要求。
kube-system:该名字空间用于 k8s 系统创建的对象。
ns 基本命令
获取所有的 ns
kubectl get ns
[root@k8s-master ~]# kubectl get ns
NAME STATUS AGE
default Active 3h18m
kube-node-lease Active 3h18m
kube-public Active 3h18m
kube-system Active 3h18m
kubernetes-dashboard Active 128m
创建 ns
kubectl create ns ns名称
[root@k8s-master ~]# kubectl create ns yigongsui
namespace/yigongsui created
[root@k8s-master ~]# kubectl get ns
NAME STATUS AGE
default Active 5h25m
kube-node-lease Active 5h25m
kube-public Active 5h25m
kube-system Active 5h25m
kubernetes-dashboard Active 4h16m
yigongsui Active 14s
删除 ns,假如这里面有服务资源,也会删除(慎用)
kubectl delete ns ns名称
[root@k8s-master ~]# kubectl delete ns yigongsui
namespace "yigongsui" deleted
[root@k8s-master ~]# kubectl get ns
NAME STATUS AGE
default Active 5h33m
kube-node-lease Active 5h33m
kube-public Active 5h33m
kube-system Active 5h33m
kubernetes-dashboard Active 4h24m
yaml 文件创建 ns
编辑文件my-ns.yaml,名字可以任取,必须是 yaml 文件
apiVersion: v1
kind: Namespace
metadata:
name: my-ns
创建命令有两种:
kubectl apply -f my-ns.yaml
kubectl create -f my-ns.yaml
区别:
apply:创建或更新,如果 ns 存在且发生了变化,会进行更新create:只能用于创建,如果 ns 存在,会报错
# 编辑 yaml 文件
[root@k8s-master k8s]# vim my-ns.yaml
# yaml 文件内容
[root@k8s-master k8s]# cat my-ns.yaml
apiVersion: v1
kind: Namespace
metadata:
name: my-ns
# yaml 文件创建 ns
[root@k8s-master k8s]# kubectl apply -f my-ns.yaml
namespace/my-ns created
[root@k8s-master k8s]# kubectl get ns
NAME STATUS AGE
default Active 5h39m
kube-node-lease Active 5h39m
kube-public Active 5h39m
kube-system Active 5h39m
kubernetes-dashboard Active 4h30m
my-ns Active 10s
[root@k8s-master k8s]# kubectl create -f my-ns.yaml
Error from server (AlreadyExists): error when creating "my-ns.yaml": namespaces "my-ns" already exists
yaml 资源配置清单,是声明式管理 k8s 资源
删除 yaml 文件指定的 ns
kubectl delete -f my-ns.yaml
[root@k8s-master k8s]# kubectl delete -f my-ns.yaml
namespace "my-ns" deleted
将 ns 的信息以 yaml 格式输出
kubectl get ns my-ns -o yaml
[root@k8s-master k8s]# kubectl get ns my-ns -o yaml
apiVersion: v1
kind: Namespace
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{ "apiVersion":"v1","kind":"Namespace","metadata":{ "annotations":{ },"name":"my-ns"}}
creationTimestamp: "2024-03-24T14:12:23Z"
labels:
kubernetes.io/metadata.name: my-ns
name: my-ns
resourceVersion: "33348"
uid: 36e5f296-7213-46b3-9a89-fb21354fe151
spec:
finalizers:
- kubernetes
status:
phase: Active
yaml 文件属性信息
apiVersion: api版本标签信息
kind:资源类型
metadata:资源元数据信息
spec: 属性
apiVersion: apps/v1 # 指定api版本标签
kind: Deployment # 定义资源的类型/角色,deployment为副本控制器,此处资源类型可以是Deployment、Job、Ingress、Service等
metadata: # 定义资源的元数据信息,比如资源的名称、namespace、标签等信息
name: nginx-deployment # 定义资源的名称,在同一个namespace空间中必须是唯一的
namespace: kube-public # 定义资源所在命名空间
labels: # 定义资源标签
app: nginx
name: test01
spec: # 定义资源需要的参数属性,诸如是否在容器失败时重新启动容器的属性
replicas: 3 # 副本数
selector: # 定义标签选择器
matchLabels: # 定义匹配标签
app: nginx # 需与.spec.template.metadata.labels 定义的标签保持一致
template: # 定义业务模板,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配
metadata:
labels: # 定义Pod副本将使用的标签,需与.spec.selector.matchLabels 定义的标签保持一致
app: nginx
spec:
containers: # 定义容器属性
- name: nignx # 定义一个容器名,一个 - name: 定义一个容器
image: nginx:1.21 # 定义容器使用的镜像以及版本
ports:
- name: http
containerPort: 80# 定义容器的对外的端口
- name: https
containerPort: 443
pod
什么是 pod
在 k8s 中,pod 是最小的可部署和可管理的计算单元。它是 k8s 中应用的最小单位,也是在 k8s 上运行容器化应用的资源对象,其他的资源对象都是用来支撑或者扩展 Pod 对象功能的,用于托管应用程序的运行实例。
pod 是一个逻辑主机,它由一个或多个容器组成,这些容器共享同一个网络命名空间、存储卷和其他依赖资源。这些容器通过共享相同的资源,可以更方便地进行通信、共享数据和协同工作。
一个 pod 可以包含一个或多个容器,这些容器一起运行在同一个主机上,并共享同一个 IP 地址和端口空间。它们可以通过 localhost 直接通信,无需进行网络通信。这使得容器之间的通信更加高效和简便。
pod 还提供了一些额外的功能,例如:
共享存储卷:pod 中的容器可以共享同一个存储卷,从而实现数据的共享和持久化。同一命名空间:pod 中的容器共享同一个网络命名空间,它们可以通过 localhost 直接通信。生命周期管理:pod 可以定义容器的启动顺序、重启策略和终止行为。资源调度:pod 可以作为 k8s 调度器的最小调度单位,用于将容器放置在集群中的不同节点上。
需要注意的是,pod 是临时性的,它可能会被创建、删除或重新创建。因此,pod 不具备持久性和可靠性。如果需要实现高可用性和容错性,可以使用 replicaSet、deployment 等 k8s 资源来管理和控制 pod 的副本。
总之,pod 是 k8s 中的基本概念,用于托管应用程序的运行实例。它由一个或多个容器组成,共享同一个网络命名空间和存储卷,提供了容器间通信、存储共享和生命周期管理等功能。

了解:
每一个 pod 都有一个特殊的被称为”根容器“的 pause容器。pause 容器对应的镜像属于 k8s 平台的一部分.
k8s 不会直接处理容器,而是 pod。
pod 是多进程设计,运用多个应用程序,也就是一个 pod 里面有多个容器,而一个容器里面运行一个应用程序。
pod 基本命令
创建一个 pod,默认在 default 下
<code># kubectl run pod名 --image=镜像名
kubectl run my-nginx --image=nginx
[root@k8s-master k8s]# kubectl run my-nginx --image=nginx
pod/my-nginx created
获取当前集群中的 pod 列表以及与每个 pod 相关的详细信息,默认是 default
kubectl get pod
参数:
-A:等价于--all-namespaces,获取所有 ns 下的 pod 信息-n:等价于--namespace=<namespace>,获取指定 ns 下的信息
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx 1/1 Running 0 88s
获取指定 pod 的详细信息
# kubectl describe pod pod名
kubectl describe pod my-nginx
[root@k8s-master k8s]# kubectl describe pod my-nginx
Name: my-nginx
Namespace: default
Priority: 0
Service Account: default
Node: k8s-node1/192.168.0.2
Start Time: Sun, 24 Mar 2024 23:02:15 +0800
Labels: run=my-nginx
Annotations: cni.projectcalico.org/containerID: c16d009c2f2fcde906fd693d565d13086c4c2b5ad268d92b0cab4eff4cef1059
cni.projectcalico.org/podIP: 192.169.36.67/32
cni.projectcalico.org/podIPs: 192.169.36.67/32
Status: Running
IP: 192.169.36.67
IPs:
IP: 192.169.36.67
Containers:
my-nginx:
Container ID: docker://97119d84370669ae58a833ec2dbd094ba8ed5891abf884b771366beb8875bd8b
Image: nginx
Image ID: docker-pullable://nginx@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31
Port: <none>
Host Port: <none>
State: Running
Started: Sun, 24 Mar 2024 23:02:26 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-lh4lf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-lh4lf:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 5m30s default-scheduler Successfully assigned default/my-nginx to k8s-node1
Normal Pulling 5m30s kubelet Pulling image "nginx"
Normal Pulled 5m20s kubelet Successfully pulled image "nginx" in 9.882s (9.882s including waiting)
Normal Created 5m19s kubelet Created container my-nginx
Normal Started 5m19s kubelet Started container my-nginx
查看 pod 的日志
# kubectl logs pod名
kubectl logs my-nginx
[root@k8s-master k8s]# kubectl logs my-nginx
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2024/03/24 15:02:26 [notice] 1#1: using the "epoll" event method
2024/03/24 15:02:26 [notice] 1#1: nginx/1.21.5
2024/03/24 15:02:26 [notice] 1#1: built by gcc 10.2.1 20210110 (Debian 10.2.1-6)
2024/03/24 15:02:26 [notice] 1#1: OS: Linux 3.10.0-1160.108.1.el7.x86_64
2024/03/24 15:02:26 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2024/03/24 15:02:26 [notice] 1#1: start worker processes
2024/03/24 15:02:26 [notice] 1#1: start worker process 31
2024/03/24 15:02:26 [notice] 1#1: start worker process 32
2024/03/24 15:02:26 [notice] 1#1: start worker process 33
2024/03/24 15:02:26 [notice] 1#1: start worker process 34
删除指定 pod
# kubectl delete pod pod名
kubectl delete pod my-nginx
[root@k8s-master k8s]# kubectl delete pod my-nginx
pod "my-nginx" deleted
[root@k8s-master k8s]# kubectl get pod
No resources found in default namespace.
yaml 文件创建 pod
编辑文件my-pod.yaml,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: nginx01
这是创建一个名为 my-nginx 的 pod,并在其中运行名为 nginx01 的容器(镜像为 nginx)。
编辑完成后执行以下命令:
kubectl apply -f my-pod.yaml
[root@k8s-master k8s]# vim my-pod.yaml
[root@k8s-master k8s]# cat my-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: nginx01
[root@k8s-master k8s]# kubectl apply -f my-pod.yaml
pod/my-nginx created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx 1/1 Running 0 2m
[root@k8s-master k8s]# kubectl describe pod my-nginx
Name: my-nginx
Namespace: default
Priority: 0
Service Account: default
Node: k8s-node1/192.168.0.2
Start Time: Sun, 24 Mar 2024 23:26:05 +0800
Labels: run=my-nginx
Annotations: cni.projectcalico.org/containerID: af662227a2724395f76f3459401c0a1293d6453f9501a3198ad276ff49f93223
cni.projectcalico.org/podIP: 192.169.36.68/32
cni.projectcalico.org/podIPs: 192.169.36.68/32
Status: Running
IP: 192.169.36.68
IPs:
IP: 192.169.36.68
Containers:
nginx01:
Container ID: docker://4ea31b6af6e594aa9c502133c9c5034ce15d6c96a1c5d1ccb86f7d2189b147d1
Image: nginx
Image ID: docker-pullable://nginx@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31
Port: <none>
Host Port: <none>
State: Running
Started: Sun, 24 Mar 2024 23:26:06 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-khgxd (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-khgxd:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m49s default-scheduler Successfully assigned default/my-nginx to k8s-node1
Normal Pulling 2m49s kubelet Pulling image "nginx"
Normal Pulled 2m48s kubelet Successfully pulled image "nginx" in 237ms (237ms including waiting)
Normal Created 2m48s kubelet Created container nginx01
Normal Started 2m48s kubelet Started container nginx01
访问 pod 中的应用
# 在 k8s 中每一个 pod 都会分配一个 ip
# 执行 kubectl get pod 命令使用-o wide参数展示 pod 更多的列
kubectl get pod -o wide
[root@k8s-master k8s]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-nginx 1/1 Running 0 12m 192.169.36.68 k8s-node1 <none> <none>
根据 ip 地址就可以访问 my-nginx 下的容器 nginx01 了
# 默认为http协议,也就是80端口,nginx默认端口就是80
curl 192.169.36.68 或 curl 192.169.36.68:80
[root@k8s-master k8s]# curl 192.169.36.68
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>code>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>code>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
以交互方式进入 pod 的内部
# kubectl exec -it pod名 /bin/bash
kubectl exec -it nginx01 /bin/bash
参数:
c:指定要进入哪个容器
[root@k8s-master k8s]# kubectl exec -it my-nginx -c nginx01 /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@my-nginx:/# cd /usr/share/nginx/html/
root@my-nginx:/usr/share/nginx/html# ls
50x.html index.html
root@my-nginx:/usr/share/nginx/html# echo "hello my-nginx" > index.html
root@my-nginx:/usr/share/nginx/html# exit
exit
[root@k8s-master k8s]# curl 192.169.36.68
hello my-nginx
pod 运行多个应用(容器)
编辑文件my-pod2.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
run: my-pod
spec:
containers:
- name: nginx1
image: nginx
- name: tomcat1
image: tomcat:8.5.92
[root@k8s-master k8s]# kubectl apply -f my-pod2.yaml
pod/my-pod created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx 1/1 Running 0 28m
my-pod 2/2 Running 0 2m41s
访问 pod 中的两个容器 nginx1 和 tomcat1
# 查看 pod 的ip
[root@k8s-master k8s]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-nginx 1/1 Running 0 29m 192.169.36.68 k8s-node1 <none> <none>
my-pod 2/2 Running 0 3m53s 192.169.36.69 k8s-node1 <none> <none>
# 访问 nginx1
[root@k8s-master k8s]# curl 192.169.36.69:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>code>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>code>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
# 访问 tomcat1
[root@k8s-master k8s]# curl 192.169.36.69:8080
<!doctype html><html lang="en"><head><title>HTTP Status 404 – Not Found</title><style type="text/css">body { font-family:Tahoma,Arial,sans-serif;} h1, h2, h3, b { color:white;background-color:#525D76;} h1 {font-size:22px;} h2 {font-size:16px;} h3 {font-size:14px;} p {font-size:12px;} a {color:black;} .line {height:1px;background-color:#525D76;border:none;}</style></head><body><h1>HTTP Status 404 – Not Found</h1><hr class="line" /><p><b>Type</b> Status Report</p><p><b>Description</b> The origin server did not find a current representation for the target resource or is not willing to disclose that one exists.</p><hr class="line" /><h3>Apache Tomcat/8.5.92</h3></body></html>code>
k8s 架构思想:没有什么是加一层解决不了的
pod创建底部流程
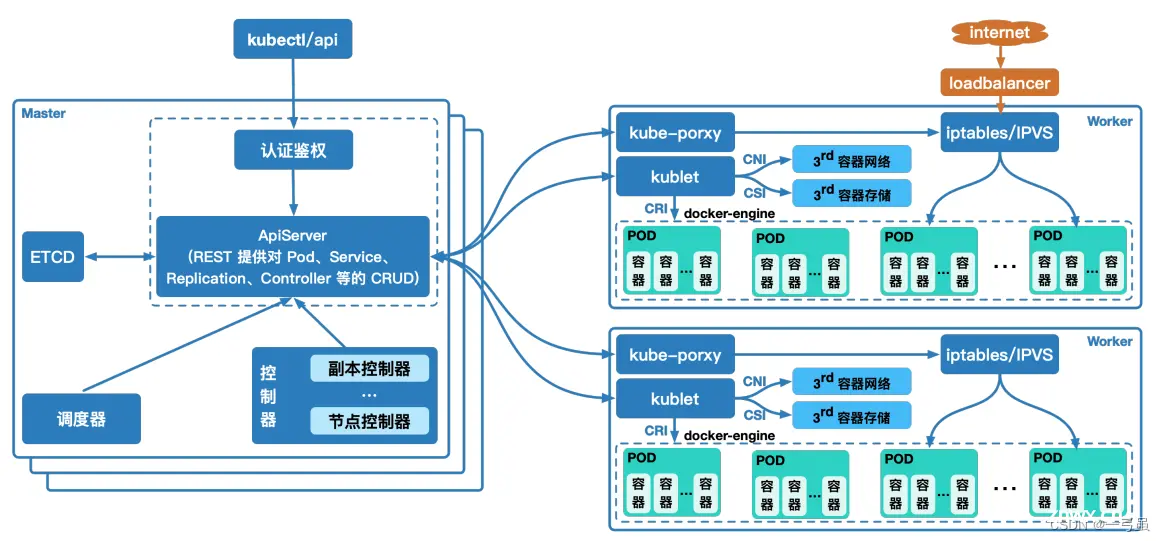
k8s 中包含了众多组件,通过 watch 的机制进行每个组件的协作,每个组件之间的设计实现了解耦其工作流程如下图所示:
以创建 pod 为例:
集群管理员或者开发人员通过 kubectl 或者客户端等构建 REST 请求,经由 apiserver 进行鉴权认证(使用 kubeconfig 文件),验证准入信息后将请求数据(metadata)写入 etcd 中;ControllerManager(控制器组件)通过 watch 机制发现创建 pod 的信息,并将整合信息通过 apiservre 写入 etcd 中,此时 pod 处于可调度状态Scheduler(调度器组件)基于 watch 机制获取可调度 pod 列表信息,通过调度算法(过滤或打分)为待调度 pod 选择最适合的节点,并将创建pod 信息写入 etcd 中,创建请求发送给节点上的 kubelet;kubelet 收到 pod 创建请求后,调用 CNI 接口为 pod 创建网络环境,调用 CRI 接口创建 pod 内部容器,调用 CSI 接口对 pod 进行存储卷的挂载;等待 pod 内部运行环境创建完成,基于探针或者健康检查监测业务运行容器启动状态,启动完成后 pod 处于 running 状态,pod 进入运行阶段。
deployment
为了更好地解决服务编排的问题,k8s 在 V1.2 版本开始,引入了 deployment 控制器,值得一提的是,这种控制器并不直接管理 pod,
而是通过管理 replicaset(副本集)来间接管理 pod,即:deployment 管理 replicaset,replicaset 管理 pod。
所以 deployment 比 replicaset 的功能更强大。
最小单位是 pod=>服务。
deployment 部署,操作我的 pod。
通过 deployment,使 pod 拥有多副本、自愈、扩缩容等能力。

什么是 deployment
在 k8s 中,deployment 是一种用于定义和管理 pod 的资源对象(并不直接管理 pod)。deployment 提供了一种声明式的方式来描述所需的应用程序副本数量、容器镜像和其他相关配置,以及在应用程序更新或扩缩容时的自动化管理。
deployment 的主要功能包括:
创建和管理 pod:deployment 使用 pod 模板定义了所需的容器镜像、环境变量、卷挂载等配置,并根据指定的副本数量自动创建和管理 pod 实例。滚动更新:deployment 支持滚动更新应用程序,即在不中断服务的情况下逐步替换旧的 pod 实例为新的 pod 实例。可以通过指定更新策略、最大不可用副本数等参数来控制滚动更新的行为。扩缩容:deployment 可以根据 CPU 使用率、内存使用率等指标自动扩缩容应用程序副本数量,以适应负载的变化。健康检查和自愈能力:deployment 可以定义容器的健康检查机制,如果某个 pod 实例失败或不健康,deployment 会自动重启或替换该实例,以保证应用程序的高可用性。版本控制和回滚:deployment 允许您在进行应用程序更新时记录应用程序的版本,并支持回滚到之前的版本,以便在出现问题时进行恢复。
通过使用 deployment,您可以轻松地管理和控制应用程序的生命周期,并实现应用程序的自动化部署、更新和扩缩容。
deployment 基本命令
首先清除所有 pod
<code>[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx 1/1 Running 0 50m
my-pod 2/2 Running 0 24m
# 参数 -n 指定 ns,不指定则删除所有 ns 下的同名 pod
[root@k8s-master k8s]# kubectl delete pod my-nginx my-pod -n default
pod "my-nginx" deleted
pod "my-pod" deleted
[root@k8s-master k8s]# kubectl get pod
No resources found in default namespace.
使用 deployment 创建一个 pod
# kubectl create deployment pod名 --image=镜像名
kubectl create deployment tomcat --image=tomcat:8.5.92
这里我们对比一下,使用 deployment 创建的 pod 与使用 run 命令创建的 pod 有什么区别
# deployment 创建
[root@k8s-master k8s]# kubectl create deployment tomcat --image=tomcat:8.5.92
deployment.apps/tomcat created
# run 创建
[root@k8s-master k8s]# kubectl run nginx --image=nginx
pod/nginx created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 9s
tomcat-d7f8f49fc-nt5xg 1/1 Running 0 22s
我们惊奇的发现,使用 deployment 创建的 pod,它的名字的后面加了一串随机生成的 string
接下来我们删除这两个 pod
[root@k8s-master k8s]# kubectl delete pod nginx
pod "nginx" deleted
[root@k8s-master k8s]# kubectl delete pod tomcat-d7f8f49fc-nt5xg
pod "tomcat-d7f8f49fc-nt5xg" deleted
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
tomcat-d7f8f49fc-f54r7 1/1 Running 0 4s
其中,名为 nginx 的 pod 是正常删除了,名为 tomcat-d7f8f49fc-nt5xg 的 pod 删除之后,又重新生成了一个新的 pod,名字还是 tomcat + 一串随机生成的 string,与之前不同
这是因为通过 deployment 部署的 pod,拥有极强的自愈能力,只要 deployment 还在,就会无限创建 pod
如果想要删除这个 pod,就要先删除 deployment
查看 ns 下的所有 deployment ,默认只查看 default 下的
kubectl get deploy
参数:
-A:查看所有 ns 下的 deployment-n:查看指定 ns 下的 deployment
[root@k8s-master k8s]# kubectl get deploy -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
default tomcat 1/1 1 1 14m
kube-system calico-kube-controllers 1/1 1 1 7h54m
kube-system coredns 2/2 2 2 8h
kubernetes-dashboard dashboard-metrics-scraper 1/1 1 1 7h18m
kubernetes-dashboard kubernetes-dashboard 1/1 1 1 7h18m
[root@k8s-master k8s]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
tomcat 1/1 1 1 15m
[root@k8s-master k8s]# kubectl get deploy -n default
NAME READY UP-TO-DATE AVAILABLE AGE
tomcat 1/1 1 1 15m
删除 deployment
kubectl delete deploy tomcat -n default
[root@k8s-master k8s]# kubectl delete deploy tomcat -n default
deployment.apps "tomcat" deleted
[root@k8s-master k8s]# kubectl get pod
No resources found in default namespace.
可以看到 pod 也被删除了
多副本能力
创建 deployment 时可以指定创建 pod 的个数,使用--replicas
# --replicas=3 副本数量
kubectl create deployment nginx-deploy --image=nginx --replicas=3
[root@k8s-master ~]# kubectl create deployment nginx-deploy --image=nginx --replicas=3
deployment.apps/nginx-deploy created
[root@k8s-master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 3/3 3 3 43s
# 启动了3个 pod
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-d845cc945-8xml2 1/1 Running 0 55s
nginx-deploy-d845cc945-bwjmm 1/1 Running 0 55s
nginx-deploy-d845cc945-rwbs5 1/1 Running 0 55s
# 每一个 pod 都对应了一个 ip,自动进行分布式部署
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deploy-d845cc945-8xml2 1/1 Running 0 94s 192.169.36.74 k8s-node1 <none> <none>
nginx-deploy-d845cc945-bwjmm 1/1 Running 0 94s 192.169.169.135 k8s-node2 <none> <none>
nginx-deploy-d845cc945-rwbs5 1/1 Running 0 94s 192.169.36.73 k8s-node1 <none> <none>
从这3个 pod 中我们可以发现,名字是由 deployment 名字(nginx-deploy)+ 一段固定的字符串(d845cc945)+ 随机生成的字符串(3个都不一样,第一个是 8xml2)构成,现在我们思考这一段固定的字符串是干什么的?
我们在介绍 deployment 时,一开始就说了 deployment 是管理 replicaset 的而不是管理 pod 的,这一段固定的字符串就是 deployment 与 replicaset 进行映射的标签
k8s 就是使用这个来保证我们的 deployment 可以映射到唯一的 replicaset。
有关 replicaset 的概念后面再详解,现在了解即可
# 查看 ns 下的所有副本集
# 可以看到,replicaset 的标签可以找到这个 deployment 部署的所有 pod,pod 里面也有对应的标签,pod-template-hash 是一致的
[root@k8s-master ~]# kubectl get replicaset --show-labels
NAME DESIRED CURRENT READY AGE LABELS
nginx-deploy-d845cc945 3 3 3 12m app=nginx-deploy,pod-template-hash=d845cc945
[root@k8s-master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deploy-d845cc945-8xml2 1/1 Running 0 13m app=nginx-deploy,pod-template-hash=d845cc945
nginx-deploy-d845cc945-bwjmm 1/1 Running 0 13m app=nginx-deploy,pod-template-hash=d845cc945
nginx-deploy-d845cc945-rwbs5 1/1 Running 0 13m app=nginx-deploy,pod-template-hash=d845cc945
使用 yaml 文件创建 deployment
编辑文件my-deploy.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
labels:
run: nginx-deploy
spec:
replicas: 3
selector:
matchLabels:
app: nginx-deploy
template:
metadata:
labels:
app: nginx-deploy
spec:
containers:
- image: nginx
name: nginx
创建一个名为 nginx-deploy 的deployment,replicaset 有3个 pod,每一个 pod 下有一个名为 nginx 的容器
# 先删除旧的 deployment
[root@k8s-master k8s]# kubectl delete deploy nginx-deploy
deployment.apps "nginx-deploy" deleted
[root@k8s-master k8s]# kubectl get deploy
No resources found in default namespace.
# 执行 yaml 文件,创建 deployment
[root@k8s-master k8s]# kubectl apply -f my-deploy.yaml
deployment.apps/nginx-deploy created
[root@k8s-master k8s]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 3/3 3 3 2m19s
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-d845cc945-7mtfk 1/1 Running 0 2m23s
nginx-deploy-d845cc945-jbbhz 1/1 Running 0 2m23s
nginx-deploy-d845cc945-ntx8m 1/1 Running 0 2m23s
[root@k8s-master k8s]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deploy-d845cc945-7mtfk 1/1 Running 0 2m34s 192.169.169.136 k8s-node2 <none> <none>
nginx-deploy-d845cc945-jbbhz 1/1 Running 0 2m34s 192.169.36.76 k8s-node1 <none> <none>
nginx-deploy-d845cc945-ntx8m 1/1 Running 0 2m34s 192.169.36.75 k8s-node1 <none> <none>
[root@k8s-master k8s]# curl 192.169.169.136:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>code>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>code>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
yaml 格式精进:
apiVersion: apps/v1 # 指定deployment的api版本
kind: Deployment # 指定创建资源的角色/类型
metadata: # 指定Deployment的元数据
name: nginx # 创建名为nginx的Deployment
labels: # 指定Deployment的标签(可自定义多个),这里的标签不需要与任何地方的标签匹配,根据实际场景随意自定义即可
app: demo
spec: # Deployment的资源规格
replicas: 2 # Deployment将创建2个Pod副本(默认为 1)
selector: # 匹配标签选择器,定义Deployment如何查找要管理的Pod,因此这里必须与Pod的template模板中定义的标签保持一致
matchLabels:
app: demo
template: # 指定Pod模板
metadata: # 指定Pod的元数据
labels: # 指定Pod的标签(可自定义多个)
app: demo
spec: # Pod的资源规格
containers: # 指定Pod运行的容器信息
- name: nginx # 指定Pod中运行的容器名
image: nginx:1.20.0 # 指定Pod中运行的容器镜像与版本(不指定镜像版本号则默认为latest)
ports:
- containerPort: 80 # 指定容器的端口(即Nginx默认端口)
k8s 对应的资源api标签信息,如果你写的 apiVersion 不存在,k8s无法运行
[root@k8s-master k8s]# kubectl api-versions
admissionregistration.k8s.io/v1
apiextensions.k8s.io/v1
apiregistration.k8s.io/v1
apps/v1
authentication.k8s.io/v1
authorization.k8s.io/v1
autoscaling/v1
autoscaling/v2
batch/v1
certificates.k8s.io/v1
coordination.k8s.io/v1
crd.projectcalico.org/v1
discovery.k8s.io/v1
events.k8s.io/v1
flowcontrol.apiserver.k8s.io/v1beta2
flowcontrol.apiserver.k8s.io/v1beta3
networking.k8s.io/v1
node.k8s.io/v1
policy/v1
rbac.authorization.k8s.io/v1
scheduling.k8s.io/v1
storage.k8s.io/v1
v1
deployment 扩缩容 scale
需求:系统运营过程中,流量越来越大,扛不住了,需要增加部署。或者流量减少,需要减少部署降低成本。
扩缩容命令:重新指定副本数
# kubectl scale deployment deployment名 --replicas=副本数
# 使用 -n 指定 ns,默认为 default
# 缩容就是指定的副本数比原来少
kubectl scale deploy nginx-deploy --replicas=5
[root@k8s-master k8s]# kubectl scale deploy nginx-deploy --replicas=5
deployment.apps/nginx-deploy scaled
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-d845cc945-45bn6 1/1 Running 0 36s
nginx-deploy-d845cc945-75d5h 1/1 Running 0 36s
nginx-deploy-d845cc945-7mtfk 1/1 Running 0 15m
nginx-deploy-d845cc945-cnkrk 1/1 Running 0 2m22s
nginx-deploy-d845cc945-lxhgr 1/1 Running 0 36s
deployment 实现故障转移,自愈
如果运行中,一个节点宕机了,k8s 会自动再其他节点自动重启拉起,保证副本数量可用。
挂掉一个节点,该节点上的服务就会异常
等待 5 分钟后,会自动在其他可用 work 节点进行创建并运行,之所以要等待5分钟,这是因为 k8s 的 Taint(污点)与 Toleration(容忍)机制所造成。
此服务中断时间 = 停机等待5分钟时间 + 重建时间 + 服务启动时间 + readiness 探针检测正常时间
假设:node2 活过来了,原来的 pod 还能重新回来吗?
答案是不能,服务数量严格安装 deployment 的副本数量,5个副本全部在 node1 节点上,即使 node2 活过来了,也不会重新构建
灰度发布 set image、滚动升级 set image、回滚 rollout [ history 历史 : undo:回滚 ]
首先我们对 pod 进行实时监控
kubectl get pod -w
[root@k8s-master k8s]# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
nginx-deploy-d845cc945-45bn6 1/1 Running 0 19m
nginx-deploy-d845cc945-75d5h 1/1 Running 0 19m
nginx-deploy-d845cc945-7mtfk 1/1 Running 0 34m
nginx-deploy-d845cc945-cnkrk 1/1 Running 0 21m
nginx-deploy-d845cc945-lxhgr 1/1 Running 0 19m
打开一个新的窗口,升级 deployment 的 nginx 镜像,查看监控窗口输出
# 升级镜像版本到 nginx:1.19.2
[root@k8s-master ~]# kubectl set image deploy nginx-deploy nginx=nginx:1.19.2 --record
Flag --record has been deprecated, --record will be removed in the future
deployment.apps/nginx-deploy image updated
监控窗口输出:
......
nginx-deploy-86b5d68f7b-g8v2n 0/1 Pending 0 0s
nginx-deploy-86b5d68f7b-fnj68 0/1 Pending 0 0s
nginx-deploy-86b5d68f7b-g8v2n 0/1 Pending 0 0s
nginx-deploy-86b5d68f7b-fnj68 0/1 Pending 0 0s
nginx-deploy-86b5d68f7b-g8v2n 0/1 ContainerCreating 0 0s
nginx-deploy-86b5d68f7b-fnj68 0/1 ContainerCreating 0 0s
nginx-deploy-86b5d68f7b-5mnsp 0/1 Pending 0 0s
nginx-deploy-86b5d68f7b-5mnsp 0/1 Pending 0 0s
nginx-deploy-86b5d68f7b-5mnsp 0/1 ContainerCreating 0 0s
nginx-deploy-d845cc945-75d5h 1/1 Terminating 0 22m
nginx-deploy-d845cc945-75d5h 0/1 Terminating 0 22m
nginx-deploy-86b5d68f7b-fnj68 0/1 ContainerCreating 0 1s
nginx-deploy-86b5d68f7b-g8v2n 0/1 ContainerCreating 0 1s
nginx-deploy-86b5d68f7b-5mnsp 0/1 ContainerCreating 0 1s
nginx-deploy-d845cc945-75d5h 0/1 Terminating 0 22m
nginx-deploy-d845cc945-75d5h 0/1 Terminating 0 22m
......
可以看到是属于滚动升级,deployment 始终保证有一个服务是正常运行的。
查看 deployment 的历史部署信息
kubectl rollout history deploy nginx-deploy
[root@k8s-master k8s]# kubectl rollout history deploy nginx-deploy
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image deploy nginx-deploy nginx=nginx:1.19.2 --record=true
查看指定版本的信息:
kubectl rollout history deploy nginx-deploy --revision=2
[root@k8s-master k8s]# kubectl rollout history deploy nginx-deploy --revision=2
deployment.apps/nginx-deploy with revision #2
Pod Template:
Labels:app=nginx-deploy
pod-template-hash=86b5d68f7b
Annotations:kubernetes.io/change-cause: kubectl set image deploy nginx-deploy nginx=nginx:1.19.2 --record=true
Containers:
nginx:
Image:nginx:1.19.2
Port:<none>
Host Port:<none>
Environment:<none>
Mounts:<none>
Volumes:<none>
rollout undo 回滚到指定版本
# 默认回滚到上个版本
kubectl rollout undo deploy nginx-deploy
参数:
--to-revision:指定回滚到哪个版本,默认值是0,回滚到上个版本
[root@k8s-master k8s]# kubectl rollout undo deploy nginx-deploy
deployment.apps/nginx-deploy rolled back
[root@k8s-master k8s]# kubectl rollout history deploy nginx-deploy
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
2 kubectl set image deploy nginx-deploy nginx=nginx:1.19.2 --record=true
3 <none>
[root@k8s-master k8s]# kubectl rollout undo deploy nginx-deploy --to-revision=2
deployment.apps/nginx-deploy rolled back
[root@k8s-master k8s]# kubectl rollout history deploy nginx-deploy
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
3 <none>
4 kubectl set image deploy nginx-deploy nginx=nginx:1.19.2 --record=true
总结:
负责工作负载:是一个部署

Deployment:无状态应用部署,微服务,提供一些副本功能
StatefulSet:有状态应用,redis、mysql、 提供稳定的存储和网络等等
DaemonSet:守护型应用部署,比如日志,每个机器都会运行一份。
Job/CronJob:定时任务部署,垃圾回收清理,日志保存,邮件,数据库备份, 可以在指定时间运行。
<code>apiVersion:
kind: Deployment / StatefulSet / DaemonSet / CronJob
metadata:
spec:
service
目前为止,我们部署的所有应用目前并不能通过浏览器访问
在前面讲解 pod 时知道,pod 的生命周期比较短,其生命周期可以用朝生夕死来形容,这就造成了提供服务的 pod 的 ip 地址频繁变化。而在访问服务时,我们期望提供服务的 ip 地址是稳定不变的。由上描述可知,pod 的特性和人们的期望就发生了严重的冲突。此冲突就引出了 service。
service:pod的服务发现和负载均衡
基本操作
首先清除所有 deployment
[root@k8s-master k8s]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 5/5 5 5 78m
[root@k8s-master k8s]# kubectl delete deploy nginx-deploy
deployment.apps "nginx-deploy" deleted
部署三个 nginx pod
[root@k8s-master k8s]# kubectl create deploy web-nginx --image=nginx --replicas=3
deployment.apps/web-nginx created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-nginx-5f989946d-2lbc4 1/1 Running 0 33s
web-nginx-5f989946d-hgxm8 1/1 Running 0 33s
web-nginx-5f989946d-m5cqq 1/1 Running 0 33s
全部启动之后进入容器内部,修改 html
# 分别进入3个 pod 下的 nginx 容器
kubectl exec -it web-nginx-5f989946d-2lbc4 /bin/bash
kubectl exec -it web-nginx-5f989946d-hgxm8 /bin/bash
kubectl exec -it web-nginx-5f989946d-m5cqq /bin/bash
# 进入到html文件所在目录
# 全部执行
cd /usr/share/nginx/html
# 分别执行
echo "web-nginx-111" > index.html
echo "web-nginx-222" > index.html
echo "web-nginx-333" > index.html
# 查看 ip
[root@k8s-master k8s]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-nginx-5f989946d-2lbc4 1/1 Running 0 11m 192.169.169.145 k8s-node2 <none> <none>
web-nginx-5f989946d-hgxm8 1/1 Running 0 11m 192.169.36.89 k8s-node1 <none> <none>
web-nginx-5f989946d-m5cqq 1/1 Running 0 11m 192.169.36.90 k8s-node1 <none> <none>
# 访问查看修改后的内容
[root@k8s-master k8s]# curl 192.169.169.145
web-nginx-111
[root@k8s-master k8s]# curl 192.169.36.89
web-nginx-222
[root@k8s-master k8s]# curl 192.169.36.90
web-nginx-333
创建一个 service
这里根据 deployment 使用命令kubectl expose创建 service
# kubectl expose deploy deployment名 --port=service暴露的端口 --target-port=pod内容器的端口
kubectl expose deploy web-nginx --port=8000 --target-port=80
[root@k8s-master k8s]# kubectl expose deploy web-nginx --port=8000 --target-port=80
service/web-nginx exposed
查看所有 service
# 默认只查看 default 下的所有 service
kubectl get svc
[root@k8s-master k8s]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23h
web-nginx ClusterIP 10.96.12.5 <none> 8000/TCP 56s
接下来我们使用 service 的 ip 来访问 nginx 服务
[root@k8s-master k8s]# curl 10.96.12.5:8000
web-nginx-333
[root@k8s-master k8s]# curl 10.96.12.5:8000
web-nginx-111
[root@k8s-master k8s]# curl 10.96.12.5:8000
web-nginx-222
[root@k8s-master k8s]# curl 10.96.12.5:8000
web-nginx-111
[root@k8s-master k8s]# curl 10.96.12.5:8000
web-nginx-333
[root@k8s-master k8s]# curl 10.96.12.5:8000
web-nginx-333
[root@k8s-master k8s]# curl 10.96.12.5:8000
web-nginx-222
可以看到,访问的 nginx 服务是随机的
还可以通过域名来访问,不过只能在容器内部,集群中无法通过域名访问
项目中的服务,在通过 service 调用的时候,可以直接在代码里面写域名访问
service 每次创建 ip 都会变化,但是在程序需要一个不变的地址,就通过域名来访问
service 的域名格式:service服务名.namespace空间.svc:端口
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-nginx-5f989946d-2lbc4 1/1 Running 0 57m
web-nginx-5f989946d-hgxm8 1/1 Running 0 57m
web-nginx-5f989946d-m5cqq 1/1 Running 0 57m
[root@k8s-master k8s]# kubectl exec -it web-nginx-5f989946d-2lbc4 /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-333
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-111
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-333
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-333
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-111
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-111
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-333
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-333
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-111
root@web-nginx-5f989946d-2lbc4:/# curl web-nginx.default.svc:8000
web-nginx-222
查看 service 的详细信息
kubectl describe svc web-nginx
[root@k8s-master k8s]# kubectl describe svc web-nginx
Name: web-nginx
Namespace: default
Labels: app=web-nginx
Annotations: <none>
Selector: app=web-nginx# 查询哪些 pod 的标签带了 app=web-nginx,映射逻辑
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.12.5# 对外访问的 ip 地址
IPs: 10.96.12.5
Port: <unset> 8000/TCP# 对外访问的端口
TargetPort: 80/TCP
Endpoints: 192.169.169.145:80,192.169.36.89:80,192.169.36.90:80
Session Affinity: None
Events: <none>
删除 service
kubectl delete svc web-nginx
[root@k8s-master k8s]# kubectl delete svc web-nginx
service "web-nginx" deleted
我们目前创建的 serivce 都只能在集群内部访问,无法在浏览器访问
在企业中我们希望 web 服务是对外暴露,用户可以访问的。
而 redis,mysql,mq 等,我们只希望在这些服务只能在内部使用,不对外暴露。
如果想要做到这点,我们在创建 service 需要查看一个参数--type
--type='':code>
Type for this service: ClusterIP, NodePort, LoadBalancer, or ExternalName. Default is 'ClusterIP'.
可以看到默认配置是 ClusterIP,也就是不对外暴露,只能在集群内部访问
我们可以使用配置 NodePort,NodePort 类型的 service 允许从集群外部通过节点的 ip 地址和分配的端口号访问 service
# 创建 service
[root@k8s-master k8s]# kubectl expose deploy web-nginx --port=8000 --target-port=80 --type=NodePort
service/web-nginx exposed
# 查看 default 下的所有 service
[root@k8s-master k8s]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23h
web-nginx NodePort 10.96.188.73 <none> 8000:32435/TCP 29s
可以看到 web-nginx 的 port 除了容器内部访问的 8000,还多了一个32435,这就是可以对外访问的端口,可以通过集群的任意节点访问这个 service
这样我们就可以打开浏览器,输入任意节点的ip地址:32435就可以访问 nginx 了,如果访问不了,需要设置阿里云安全组

service 的几种类型
ClusterIP:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP
NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 ip: NodePort 来访问该服务。
LoadBalancer:在 NodePort 的基础上,借助 Cloud Provider 创建一个外部负载均衡器,并将请求转发到 NodePort
ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的kube-dns 才支持。
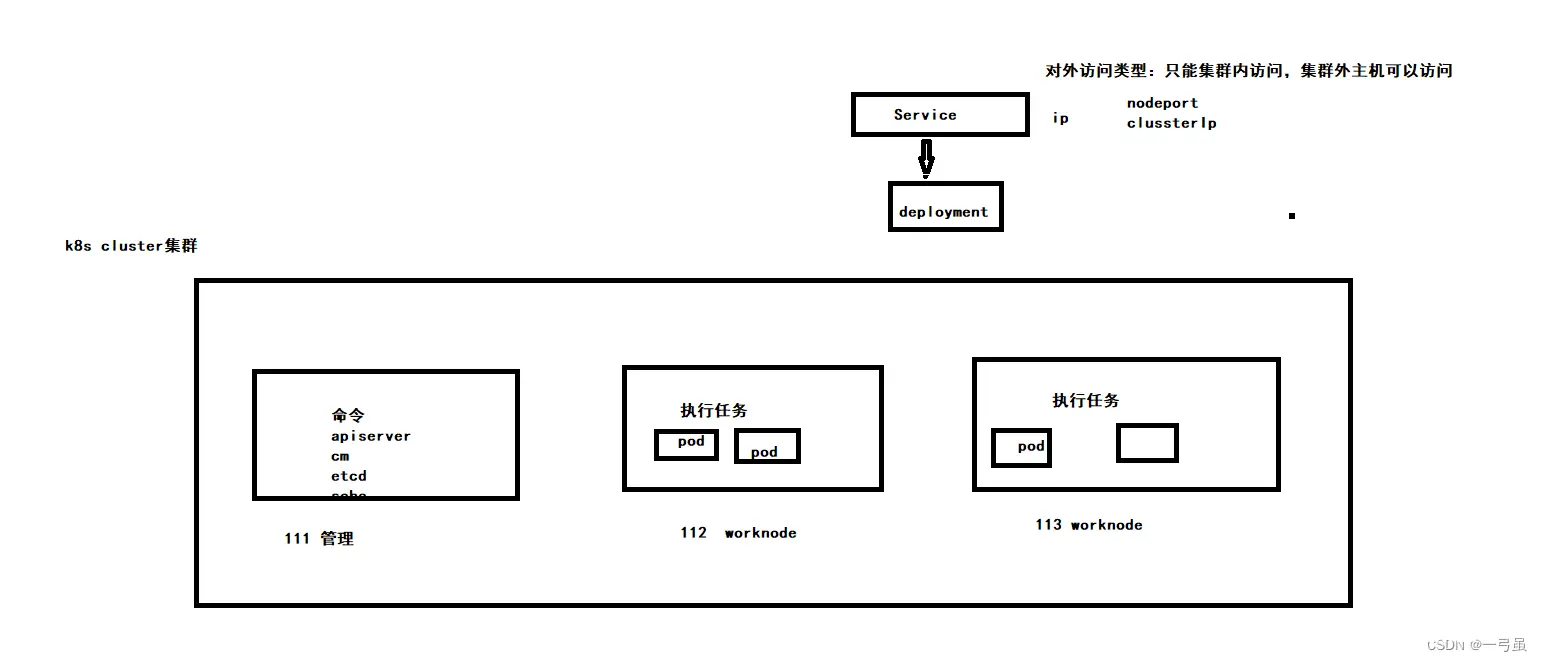
生成的 ip 探究
我们创建 service 的 ip 是 <code>10.96.188.73,细心的小伙伴可以发现
我们在初始化 master 节点时,执行了以下命令:
kubeadm init \
--apiserver-advertise-address=192.168.0.1 \
--control-plane-endpoint=cluster-master \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.28.2 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.169.0.0/16 \
--cri-socket unix:///var/run/cri-dockerd.sock
是在这里面我们指定了 service 的 ip 范围
k8s在内部有一套自己的网络管理系统,内部网络将我们所有的服务连接在一起
使用 yaml 文件创建 service
编辑文件my-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: web-nginx # 需要与deployment的标签匹配
ports:
- protocol: TCP
port: 8000
targetPort: 80
type: NodePort
[root@k8s-master k8s]# kubectl apply -f my-service.yaml
service/my-service created
[root@k8s-master k8s]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23h
my-service NodePort 10.96.78.150 <none> 8000:30812/TCP 2m37s
ingress
官方文档:https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress/
官网地址:https://kubernetes.github.io/ingress-nginx/,ingress 就是 nginx 做的。
安装文档:https://kubernetes.github.io/ingress-nginx/deploy/
什么是 ingress
ingress:service 的统一网关入口
K8s 的 pod 和 service 需要通过 NodePort 把服务暴露到外部, 但是随着微服务的增多。 端口会变得不好管理。 所以通常情况下我们会设计一个 ingress 来做路由的转发,方便统一管理。效果如图:
ingress 主要分为两部分
ingress controller 是流量的入口,是一个实体软件, 一般是 nginx 和 Haproxy 。ingress 描述具体的路由规则。
ingress作用:
基于 http-header 的路由
基于 path 的路由
单个 ingress 的 timeout
请求速率 limit
rewrite 规则
安装 ingress
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml
如果网站无法访问则无法下载,使用下面 yaml 文件
编辑文件ingress.yaml:
apiVersion: v1
kind: Namespace
metadata:
labels:
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
name: ingress-nginx
---
apiVersion: v1
automountServiceAccountToken: true
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx
namespace: ingress-nginx
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission
namespace: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx
namespace: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- apiGroups:
- ""
resources:
- configmaps
- pods
- secrets
- endpoints
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses/status
verbs:
- update
- apiGroups:
- networking.k8s.io
resources:
- ingressclasses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resourceNames:
- ingress-nginx-leader
resources:
- configmaps
verbs:
- get
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- create
- apiGroups:
- coordination.k8s.io
resourceNames:
- ingress-nginx-leader
resources:
- leases
verbs:
- get
- update
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- create
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission
namespace: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- secrets
verbs:
- get
- create
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
- namespaces
verbs:
- list
- watch
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- networking.k8s.io
resources:
- ingresses/status
verbs:
- update
- apiGroups:
- networking.k8s.io
resources:
- ingressclasses
verbs:
- get
- list
- watch
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission
rules:
- apiGroups:
- admissionregistration.k8s.io
resources:
- validatingwebhookconfigurations
verbs:
- get
- update
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx
namespace: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: ingress-nginx
subjects:
- kind: ServiceAccount
name: ingress-nginx
namespace: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission
namespace: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: ingress-nginx-admission
subjects:
- kind: ServiceAccount
name: ingress-nginx-admission
namespace: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: ingress-nginx
subjects:
- kind: ServiceAccount
name: ingress-nginx
namespace: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: ingress-nginx-admission
subjects:
- kind: ServiceAccount
name: ingress-nginx-admission
namespace: ingress-nginx
---
apiVersion: v1
data:
allow-snippet-annotations: "true"
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-controller
namespace: ingress-nginx
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
externalTrafficPolicy: Local
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- appProtocol: http
name: http
port: 80
protocol: TCP
targetPort: http
- appProtocol: https
name: https
port: 443
protocol: TCP
targetPort: https
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-controller-admission
namespace: ingress-nginx
spec:
ports:
- appProtocol: https
name: https-webhook
port: 443
targetPort: webhook
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
minReadySeconds: 0
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
spec:
containers:
- args:
- /nginx-ingress-controller
- --publish-service=$(POD_NAMESPACE)/ingress-nginx-controller
- --election-id=ingress-nginx-leader
- --controller-class=k8s.io/ingress-nginx
- --ingress-class=nginx
- --configmap=$(POD_NAMESPACE)/ingress-nginx-controller
- --validating-webhook=:8443
- --validating-webhook-certificate=/usr/local/certificates/cert
- --validating-webhook-key=/usr/local/certificates/key
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: LD_PRELOAD
value: /usr/local/lib/libmimalloc.so
image: cnych/ingress-nginx:v1.5.1
imagePullPolicy: IfNotPresent
lifecycle:
preStop:
exec:
command:
- /wait-shutdown
livenessProbe:
failureThreshold: 5
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
name: controller
ports:
- containerPort: 80
name: http
protocol: TCP
- containerPort: 443
name: https
protocol: TCP
- containerPort: 8443
name: webhook
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
requests:
cpu: 100m
memory: 90Mi
securityContext:
allowPrivilegeEscalation: true
capabilities:
add:
- NET_BIND_SERVICE
drop:
- ALL
runAsUser: 101
volumeMounts:
- mountPath: /usr/local/certificates/
name: webhook-cert
readOnly: true
dnsPolicy: ClusterFirst
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: ingress-nginx
terminationGracePeriodSeconds: 300
volumes:
- name: webhook-cert
secret:
secretName: ingress-nginx-admission
---
apiVersion: batch/v1
kind: Job
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission-create
namespace: ingress-nginx
spec:
template:
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission-create
spec:
containers:
- args:
- create
- --host=ingress-nginx-controller-admission,ingress-nginx-controller-admission.$(POD_NAMESPACE).svc
- --namespace=$(POD_NAMESPACE)
- --secret-name=ingress-nginx-admission
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: cnych/ingress-nginx-kube-webhook-certgen:v20220916-gd32f8c343
imagePullPolicy: IfNotPresent
name: create
securityContext:
allowPrivilegeEscalation: false
nodeSelector:
kubernetes.io/os: linux
restartPolicy: OnFailure
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 2000
serviceAccountName: ingress-nginx-admission
---
apiVersion: batch/v1
kind: Job
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission-patch
namespace: ingress-nginx
spec:
template:
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission-patch
spec:
containers:
- args:
- patch
- --webhook-name=ingress-nginx-admission
- --namespace=$(POD_NAMESPACE)
- --patch-mutating=false
- --secret-name=ingress-nginx-admission
- --patch-failure-policy=Fail
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: cnych/ingress-nginx-kube-webhook-certgen:v20220916-gd32f8c343
imagePullPolicy: IfNotPresent
name: patch
securityContext:
allowPrivilegeEscalation: false
nodeSelector:
kubernetes.io/os: linux
restartPolicy: OnFailure
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 2000
serviceAccountName: ingress-nginx-admission
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: nginx
spec:
controller: k8s.io/ingress-nginx
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
labels:
app.kubernetes.io/component: admission-webhook
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: ingress-nginx-admission
webhooks:
- admissionReviewVersions:
- v1
clientConfig:
service:
name: ingress-nginx-controller-admission
namespace: ingress-nginx
path: /networking/v1/ingresses
failurePolicy: Fail
matchPolicy: Equivalent
name: validate.nginx.ingress.kubernetes.io
rules:
- apiGroups:
- networking.k8s.io
apiVersions:
- v1
operations:
- CREATE
- UPDATE
resources:
- ingresses
sideEffects: None
执行 yaml 文件,下载 ingress
[root@k8s-master k8s]# vim ingress.yaml
[root@k8s-master k8s]# kubectl apply -f ingress.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
serviceaccount/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
configmap/ingress-nginx-controller created
service/ingress-nginx-controller created
service/ingress-nginx-controller-admission created
deployment.apps/ingress-nginx-controller created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
ingressclass.networking.k8s.io/nginx created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
可以看到 namespace 为 ingress-nginx,查看一下它的 pod、service 和 deployment
[root@k8s-master k8s]# kubectl get deploy -n ingress-nginx
NAME READY UP-TO-DATE AVAILABLE AGE
ingress-nginx-controller 1/1 1 1 2m25s
[root@k8s-master k8s]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.30.238 <pending> 80:32726/TCP,443:30681/TCP 2m31s
ingress-nginx-controller-admission ClusterIP 10.96.155.54 <none> 443/TCP 2m31s
[root@k8s-master k8s]# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-nlwsf 0/1 Completed 0 3m12s
ingress-nginx-admission-patch-2g25m 0/1 Completed 3 3m12s
ingress-nginx-controller-7598486d5d-7chkw 1/1 Running 0 3m12s
k8s 会动创建两个 nodeport 。一个80 (http),一个443 (https)
ingress-nginx-controller 对外暴露服务的
ingress-nginx-controller-admission,准入控制器,限制,请求不符合ingress对象,拒绝请求…
核心是 pod/ingress-nginx-controller
服务创建成功,首先在集群内访问:
[root@k8s-master k8s]# kubectl get pod -o wide -n ingress-nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-nginx-admission-create-nlwsf 0/1 Completed 0 8m10s 192.169.169.146 k8s-node2 <none> <none>
ingress-nginx-admission-patch-2g25m 0/1 Completed 3 8m10s 192.169.36.91 k8s-node1 <none> <none>
ingress-nginx-controller-7598486d5d-7chkw 1/1 Running 0 8m10s 192.169.36.92 k8s-node1 <none> <none>
[root@k8s-master k8s]# curl 192.169.36.92
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
集群内可以访问成功,接下来在浏览器访问:
[root@k8s-master k8s]# kubectl get svc -o wide -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
ingress-nginx-controller LoadBalancer 10.96.30.238 <pending> 80:32726/TCP,443:30681/TCP 9m14s app.kubernetes.io/component=controller,app.kubernetes.io/instance=ingress-nginx,app.kubernetes.io/name=ingress-nginx
ingress-nginx-controller-admission ClusterIP 10.96.155.54 <none> 443/TCP 9m14s app.kubernetes.io/component=controller,app.kubernetes.io/instance=ingress-nginx,app.kubernetes.io/name=ingress-nginx
这里面我们可以看到 ingress-nginx-controller 的类型是 LoadBalancer,也就是说只能从这个 pod 部署的节点可以访问
ingress-nginx-controller-7598486d5d-7chkw 1/1 Running 0 8m10s 192.169.36.92 k8s-node1 <none> <none>
上面我们看到,这个服务是部署在 node1 这个节点上,在浏览器输入下面两个任意一个即可
http://node1ip地址:32726
https://node1ip地址:30681

ingress 基本命令
首先删除 default 空间下的 svc 和 deployment
<code># 创建两个 deployment
[root@k8s-master k8s]# kubectl create deployment web-nginx --image=nginx --replicas=2
deployment.apps/web-nginx created
[root@k8s-master k8s]# kubectl create deployment web-tomcat --image=tomcat:8.5.92 --replicas=2
deployment.apps/web-tomcat created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-nginx-5f989946d-6krjl 1/1 Running 0 84s
web-nginx-5f989946d-dhstb 1/1 Running 0 84s
web-tomcat-758dc4ddf6-bgk2b 1/1 Running 0 65s
web-tomcat-758dc4ddf6-f2tjh 1/1 Running 0 65s
# 创建两个 service
[root@k8s-master k8s]# kubectl expose deploy web-nginx --port=8000 --target-port=80
service/web-nginx exposed
[root@k8s-master k8s]# kubectl expose deploy web-tomcat --port=8080 --target-port=8080
service/web-tomcat exposed
[root@k8s-master k8s]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-nginx-5f989946d-6krjl 1/1 Running 0 2m9s 192.169.36.93 k8s-node1 <none> <none>
web-nginx-5f989946d-dhstb 1/1 Running 0 2m9s 192.169.169.147 k8s-node2 <none> <none>
web-tomcat-758dc4ddf6-bgk2b 1/1 Running 0 110s 192.169.36.94 k8s-node1 <none> <none>
web-tomcat-758dc4ddf6-f2tjh 1/1 Running 0 110s 192.169.169.148 k8s-node2 <none> <none>
[root@k8s-master k8s]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 25h <none>
web-nginx ClusterIP 10.96.94.113 <none> 8000/TCP 27s app=web-nginx
web-tomcat ClusterIP 10.96.44.167 <none> 8080/TCP 19s app=web-tomcat
# 测试本地访问
[root@k8s-master k8s]# curl 10.96.94.113:8000
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>code>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>code>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@k8s-master k8s]# curl 10.96.44.167:8080
<!doctype html><html lang="en"><head><title>HTTP Status 404 – Not Found</title><style type="text/css">body { font-family:Tahoma,Arial,sans-serif;} h1, h2, h3, b { color:white;background-color:#525D76;} h1 {font-size:22px;} h2 {font-size:16px;} h3 {font-size:14px;} p {font-size:12px;} a {color:black;} .line {height:1px;background-color:#525D76;border:none;}</style></head><body><h1>HTTP Status 404 – Not Found</h1><hr class="line" /><p><b>Type</b> Status Report</p><p><b>Description</b> The origin server did not find a current representation for the target resource or is not willing to disclose that one exists.</p><hr class="line" /><h3>Apache Tomcat/8.5.92</h3></body></html>code>
内部可以访问了,我们要给内部服务做负载均衡 ingress了
使用 yaml 文件创建 ingress
编辑文件my-ingress.yaml:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "nginx.yigongsui.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: web-nginx
port:
number: 8000
- host: "tomcat.yigongsui.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: web-tomcat
port:
number: 8080
[root@k8s-master k8s]# kubectl apply -f my-ingress.yaml
ingress.networking.k8s.io/ingress-host-bar created
上面的 yaml 文件设置域名nginx.yigongsui.com映射到 web-nginx 的服务,端口是8000,域名tomcat.yigongsui.com映射到 web-tomcat 服务,端口是8080
获取 ingress,默认是 default 空间
kubectl get ingress
[root@k8s-master k8s]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-host-bar nginx nginx.yigongsui.com,tomcat.yigongsui.com 80 19s
负载均衡
由于我们要使用域名进行访问,在本机中我们可以通过在 hosts 文件中添加域名映射的方式来进行测试
在 hosts 文件中添加:
120.27.160.240 nginx.yigongsui.com
120.27.160.240 tomcat.yigongsui.com
ip 是 node1 节点的 ip,因为 ingress-nginx-controller 是部署在 node1 节点上
配置完成后,我们通过域名来访问 nginx 和 tomcat
# 访问 nginx,两者任选其一即可
http://nginx.yigongsui.com:32726
https://nginx.yigongsui.com:30681
# 访问 tomcat
http://tomcat.yigongsui.com:32726
https://tomcat.yigongsui.com:30681

ingress 实现限流
Annotations地址:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-host-bar
# 一些ingress的规则配置,都直接在这里写即可!
annotations:
nginx.ingress.kubernetes.io/limit-rps: "1"
spec:
ingressClassName: nginx
rules:
- host: "nginx.yigongsui.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: web-nginx
port:
number: 8000
- host: "tomcat.yigongsui.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: web-tomcat
port:
number: 8080
[root@k8s-master k8s]# kubectl apply -f my-ingress.yaml
ingress.networking.k8s.io/ingress-host-bar configured
配置完成后,重复刷新页面,会看到:

可以看到已经被限流了
具体的其他使用,学习 nginx 相关内容即可,然后查看 ingress 的替代命令!
annotations 配置,通用配置,https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/
rules:具体请求的规则,https://kubernetes.github.io/ingress-nginx/user-guide/ingress-path-matching/
案例:创建一个 mysql pod
编写 yaml 文件<code>my-mysql.yaml:
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
volumes:
- name: data-volume
hostPath:
path: /home/mysql/data
type: DirectoryOrCreate
这个文件中设置了数据卷挂载,容器内目录/var/lib/mysql挂载到宿主机上的/home/mysql/data上
[root@k8s-master k8s]# kubectl apply -f my-mysql.yaml
pod/mysql-pod created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-pod 1/1 Running 0 39s
web-nginx-5f989946d-6krjl 1/1 Running 0 140m
web-nginx-5f989946d-dhstb 1/1 Running 0 140m
web-tomcat-758dc4ddf6-bgk2b 1/1 Running 0 140m
web-tomcat-758dc4ddf6-f2tjh 1/1 Running 0 140m
pod 启动成功,我们进入容器内部
[root@k8s-master k8s]# kubectl exec -it mysql-pod /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@mysql-pod:/#
连接数据库,密码是123456,用户名是 root:
root@mysql-pod:/# mysql -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.36 MySQL Community Server (GPL)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
可以看到数据库能正常使用了
我们查看一下 mysql-pod 部署在哪个节点上
[root@k8s-master home]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-pod 1/1 Running 0 4m25s 192.169.169.149 k8s-node2 <none> <none>
web-nginx-5f989946d-6krjl 1/1 Running 0 144m 192.169.36.93 k8s-node1 <none> <none>
web-nginx-5f989946d-dhstb 1/1 Running 0 144m 192.169.169.147 k8s-node2 <none> <none>
web-tomcat-758dc4ddf6-bgk2b 1/1 Running 0 144m 192.169.36.94 k8s-node1 <none> <none>
web-tomcat-758dc4ddf6-f2tjh 1/1 Running 0 144m 192.169.169.148 k8s-node2 <none> <none>
可以看到部署在 node2 节点上,打开 node2 服务器,查看/home目录是不是多了个mysql目录
[root@k8s-node2 ~]# cd /home
[root@k8s-node2 home]# ll
total 4
drwxr-xr-x 3 root root 4096 Mar 25 19:39 mysql
可以看到确实多了mysql目录
我们这个 mysql 案例就算完成
思考
mysql使用过程中,数据持久化在 k8s 中如何保证唯一性?
我们案例的 mysql pod 是部署在 node1 节点,数据也在 node1 上,如果这个 mysql pod 重启后部署在了 node2 节点上,这样数据不就丢失了
这就需要我们用到 k8s 的存储卷技术了
我们 yaml 文件中的 hostPath 就是一种存储卷技术
hostPath 卷将主机节点上的文件或目录挂载到 pod 中,仅用于在单节点集群上进行开发和测试,不适用于多节点集群;例如,当 pod被重新创建时,可能会被调度到与原先不同的节点上,导致新的 pod 没有数据。
hostPath 的 type 值:
| DirectoryOrCreate | 目录不存在则自动创建。 |
|---|---|
| Directory | 挂载已存在目录。不存在会报错。 |
| FileOrCreate | 文件不存在则自动创建。不会自动创建文件的父目录,必须确保文件路径已经存在。 |
| File | 挂载已存在的文件。不存在会报错。 |
| Socket | 挂载 UNIX套接字。例如挂载/var/run/docker.sock进程 |
集群与单机的冲突,导致本地的数据挂载在k8s几乎无用,日志,单机项目!守护进程
如果清空,对应的数据就会清空
接下来,我们详细介绍一下存储卷技术
存储卷
什么是存储卷
在 k8s 中,存储卷(Volume)是一种抽象的概念,用于提供 pod 中容器的持久化存储。存储卷允许将数据存储在 pod 的生命周期之外,以便在容器重启、迁移或重新调度时保留数据。
存储卷可以连接到 pod 中的一个或多个容器,并提供持久化的存储空间。这些存储卷可以是来自 k8s 集群的本地存储、网络存储、云存储提供商或外部存储系统等。
存储卷可以用于各种用途,例如:
数据持久化:将数据存储在存储卷中,以便在容器重启后仍然可用。数据共享:将存储卷连接到多个容器,使它们可以共享相同的数据。数据备份和恢复:使用存储卷来备份和还原应用程序的数据。数据迁移和复制:将存储卷从一个 pod 迁移到另一个 pod,或者将存储卷复制到其他地方。
由于 pod 本身是具有生命周期的,所以 pod 内部运行的容器及相关的数据,在 pod 中是无法持久化存储的。我们知道,docker 支持配置容器使用存储卷,已实现数据在容器之外的存储空间中持久化存储。相应的,k8s 也支持类似的存储卷功能,此处存储卷与 pod 资源绑定。
简单来说,存储卷是定义在 pod 资源之上、可被其他内容所有容器挂载的共享目录,它关联至外部的存储设备之上的存储空间,从而独立于容器自身的文件系统,而数据是否具有持久化存储能力取决于存储卷自身是否支持持久存储机制,与 pod 无关。
k8s 支持的存储类型
k8s 支持非常丰富的存储卷类型,总体上来看,大致可以分为如下三种类型:
本地存储,例如 emptyDir、HostPath;
网络存储,nfs、cinder、cephfs、AzureFile;
特殊存储资源,例如 secret、ConfigMap
对于本地存储,emptyDir 的生命周期与 pod 资源相同,所以 pod 一旦删除,存储的数据同时被删除。HostPath(node1 node2)的生命周期与节点一致,当 pod 重新被调度到其他节点时,虽然原节点上的数据没有被删除,但是 pod 不再使用此前的数据。
网络存储系统是独立于 k8s 集群之外的存储资源,数据存储的持久性与 k8s 集群解耦合。k8s 在集群中设计了一种集群级别的资源 PersistentVolume:服务器资源(管理主动分配一些存储空间)(简称 PV)来关联网络存储,用户通过 PersistentVolumeClaim:用户就要申请使用资源(服务器就会自动匹配)(简称 PVC)来申请使用存储资源。
secret 和 ConfigMap 算是 k8s 集群中两种特殊类型的存储资源。secret 用于向 pod 传递敏感信息,例如密码、私钥、证书等。这些信息直接定义在镜像中容易导致泄露,用户可以讲这些信息集中存储在 secret 中,由 pod 进行挂载,从而实现敏感数据与系统解耦。
ConfigMap 资源用于向 pod 注入非敏感数据,用户将一些非敏感的配置数据存储在 ConfigMap 对象中,然后在 pod 中使用 ConfigMap 卷引用它即可,从而帮助实现容器配置文件集中化定义和管理。
emptyDir
emptyDir:初始内容为空的本地临时目录
它是一个临时卷(Ephemeral Volume)
与 pod 一起创建和删除,生命周期与 pod 相同
emptyDir 会创建一个初始状态为空的目录
通常使用本地临时存储来设置缓存、保存日志等
例如,将 redis 的存储目录设置为 emptyDir,编辑文件redis-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis-pod
spec:
containers:
- name: redis01
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: { }
[root@k8s-master k8s]# vim redis-pod.yaml
[root@k8s-master k8s]# kubectl apply -f redis-pod.yaml
pod/redis-pod created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
redis-pod 1/1 Running 0 2m27s
容器启动之后我们进入容器内部,添加数据
[root@k8s-master k8s]# kubectl exec -it redis-pod /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@redis-pod:/data# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set name yigongsui
OK
这样我们添加了一条数据,接下来我们退出并删除这个容器
127.0.0.1:6379> exit
root@redis-pod:/data# exit
exit
[root@k8s-master k8s]# kubectl delete -f redis-pod.yaml
pod "redis-pod" deleted
删除容器后,我们再重新启动这个容器,看看数据还在不在
[root@k8s-master k8s]# kubectl apply -f redis-pod.yaml
pod/redis-pod created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
redis-pod 1/1 Running 0 16s
[root@k8s-master k8s]# kubectl exec -it redis-pod /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@redis-pod:/data# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> get name
(nil)
发现数据不存在了,这就说明 emptyDir 的生命周期很短,与 pod 相同,只做临时存储使用
网络存储 nfs
nfs:全称是 Network File System,它最大的功能就是可以通过网络,让不同的机器、不同的操作系统可以共享彼此的文件。
安装 nfs
三台服务器都要安装 nfs
<code>yum install -y nfs-utils
接下来,在 master 主节点配置:
# 主节点配置
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
# 创建/nfs/data文件夹(主节点)
mkdir -p /nfs/data
# 启动rpc远程绑定(主节点)
systemctl enable rpcbind --now
# (开机)启动nfs服务(主节点)
systemctl enable nfs-server --now
# 配置生效(主节点)
exportfs -r
# 查看目录
exportfs
[root@k8s-master k8s]# echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
[root@k8s-master k8s]# mkdir -p /nfs/data
[root@k8s-master k8s]# systemctl enable rpcbind --now
[root@k8s-master k8s]# systemctl enable nfs-server --now
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
[root@k8s-master k8s]# exportfs -r
[root@k8s-master k8s]# exportfs
/nfs/data <world>
接下来在 node 节点下执行,
# 查看主节点机器有哪些目录可以同步挂载(node节点)
# showmount -e 主节点的内网ip,我的内网ip是192.168.0.1
showmount -e 192.168.0.1
[root@k8s-node1 home]# showmount -e 192.168.0.1
Export list for 192.168.0.1:
/nfs/data *
接下来在 node 节点执行以下命令挂载 nfs 服务器上的共享目录到本机路径
# mkdir -p 本机目录 (名字可以任取)
# mount -t nfs 192.168.0.1:/nfs/data 本机目录
# node1 执行
mkdir -p /nfs/node1
mount -t nfs 192.168.0.1:/nfs/data /nfs/node1
# node2 执行
mkdir -p /nfs/node2
mount -t nfs 192.168.0.1:/nfs/data /nfs/node2
测试看看三个节点是否共通
# master节点新增文件
[root@k8s-master k8s]# cd /nfs/data/
[root@k8s-master data]# echo "hello master" > master.txt
# node1节点新增文件
[root@k8s-node1 home]# cd /nfs/node1/
[root@k8s-node1 node1]# echo "hello node1" > node1.txt
# 查看三个节点内数据是否共通
[root@k8s-master data]# ls
master.txt node1.txt
[root@k8s-node1 node1]# ls
master.txt node1.txt
[root@k8s-node2 home]# ls /nfs/node2/
master.txt node1.txt
可以看到三个节点已经共通了
文件都共享,在 nfs 文件系统中,volumes 肯定也可以连通
测试:编辑文件nginx-nfs.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-nfs
name: nginx-nfs
spec:
replicas: 2
selector:
matchLabels:
app: nginx-nfs
template:
metadata:
labels:
app: nginx-nfs
spec:
containers:
- image: nginx01
name: nginx
volumeMounts:
- name: nginx-storage
mountPath: /usr/share/nginx/html
volumes:
- name: nginx-storage
nfs:
server: 192.168.0.1
path: /nfs/data/nginx-nfs
创建一个 deployment 部署,自行测试即可,在主节点的/nfs/data/nginx-nfs目录,新建 index.html,编辑内容,在容器里进行访问测试。
主节点的/nfs/data/nginx-nfs目录也和从节点的目录共通(node1 的目录就是/nfs/node1/nginx-nfs),也都可以进行测试
结论:无论容器怎么部署怎么删除,数据都可以持久化保存了
PV & PVC
持久卷(Persistent Volume):删除 pod 后,卷不会被删除
PV:持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置
PVC:持久卷申明(Persistent Volume Claim),申明需要使用的持久卷规格
k8s 支持的存储系统非常多,要求大家全都掌握,是不现实的。为了屏蔽底层存储实现细节,方便使用,引入了 PV 和 PVC 两种资源对象。
封装机制!数据中台
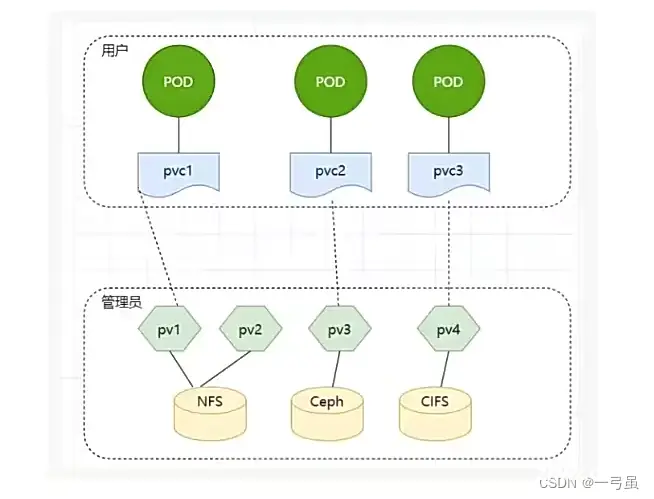
PV
Persistent Volume 是持久卷的意思,是对底层共享存储的一种抽象封装。一般情况 PV 由管理员创建和配置,它与底层具体的存储技术有关,通过插件完成与存储的对接。
PV 是存储资源的抽象,资源清单如下:
<code>apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
nfs: # 存储类型,与底层真正存储对应
capacity: # 存储能力,目前只支持存储空间的设置
storage: 2Gi
accessModes: # 访问模式
storageClassName: # 存储类别
persistentVolumeReclaimPolicy: # 回收策略
accessModes 用于描述用户应用对存储资源的访问权限,访问权限包括下面几种方式:
ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载ReadOnlyMany(ROX):只读权限,可以被多个节点挂载ReadWriteMany(RWX):读写权限,可以被多个节点挂载需要注意的是,底层不同的存储类型可能支持的访问模式不同
回收策略(persistentVolumeReclaimPolicy)
persistentVolumeReclaimPolicy 当 PV 不再被使用了之后,对其的处理方式。目前支持三种策略:
Retain (保留) 保留数据,需要管理员手工清理数据Recycle(回收) 清除 PV 中的数据,效果相当于执行 rm -rf /thevolume/*Delete (删除) 与 PV 相连的后端存储完成 volume 的删除操作,当然这常见于云服务商的存储服务
一个 PV 的生命周期中,可能会处于4种不同的阶段:
Available(可用):表示可用状态,还未被任何 PVC 绑定Bound(已绑定):表示 PV 已经被 PVC 绑定Released(已释放):表示 PVC 被删除,但是资源还未被集群重新声明Failed(失败):表示该 PV 的自动回收失败
PVC
Persistent Volume Claim 持久卷声明的意思,是用户对存储需求的一种声明。也就是向 k8s 系统发出的一种资源需求申请。
PVC 作为资源的申请,用来声明对存储空间、访问模式、存储类别需求信息。下面是资源清单文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
namespace: dev
spec:
accessModes: # 访问模式
selector: # 采用标签对PV选择
storageClassName: # 存储类别
resources: # 请求空间
requests:
storage: 5Gi
示例
创建一个 pv,创建一个 pvc,创建一个 pod 绑定 pvc 就可以了!
pv 做就是连接存储系统,规定一个大小的空间,权限配置
pvc 做的就是写一个声明,根据自己的使用者的要求(存储系统、大小、权限),来匹配 pv
pod 使用 pvc volumes 挂载的类型!
准备工作:在 nfs 主节点(master 节点)创建 PV 池
mkdir -p /nfs/data/01
mkdir -p /nfs/data/02
mkdir -p /nfs/data/03
创建 pv,编辑文件my-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01-10m
spec:
capacity:
storage: 10M
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/01
server: 192.168.0.1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02-1gi
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/02
server: 192.168.0.1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv03-3gi
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/03
server: 192.168.0.1
执行 yaml 文件
[root@k8s-master k8s]# kubectl apply -f my-pv.yaml
persistentvolume/pv01-10m created
persistentvolume/pv02-1gi created
persistentvolume/pv03-3gi created
查看所有 pv
kubectl get pv
[root@k8s-master k8s]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 50s
pv02-1gi 1Gi RWX Retain Available nfs 50s
pv03-3gi 3Gi RWX Retain Available nfs 50s
创建 pvc,编辑my-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 500Mi
storageClassName: nfs
执行 yaml 文件
[root@k8s-master k8s]# vim my-pvc.yaml
[root@k8s-master k8s]# kubectl apply -f my-pvc.yaml
persistentvolumeclaim/nginx-pvc created
再次查看所有 pv
[root@k8s-master k8s]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 7m54s
pv02-1gi 1Gi RWX Retain Bound default/nginx-pvc nfs 7m54s
pv03-3gi 3Gi RWX Retain Available nfs 7m54s
可以看到 pv02-1gi 的状态变成了 Bound,也就是说我们创建的这个 pvc 绑定到了 pv02-1gi
这是因为在 pvc 会根据我们 yaml 文件设置的存储类型以及需要的存储容量来选择绑定到最合适的 pv,我们在 pvc 中设置了存储类型为 nfs,所需的容量为 500M,所以绑定到了 pv02-1gi
删除这个 pvc,查看 pv 状态
[root@k8s-master k8s]# kubectl delete -f my-pvc.yaml
persistentvolumeclaim "nginx-pvc" deleted
[root@k8s-master k8s]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 12m
pv02-1gi 1Gi RWX Retain Released default/nginx-pvc nfs 12m
pv03-3gi 3Gi RWX Retain Available nfs 12m
可以看到,状态变为了 Released,也就是释放状态
根据 my-pvc.yaml 文件再创建一个 pvc,查看 pv 状态
[root@k8s-master k8s]# kubectl apply -f my-pvc.yaml
persistentvolumeclaim/nginx-pvc created
[root@k8s-master k8s]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 14m
pv02-1gi 1Gi RWX Retain Released default/nginx-pvc nfs 14m
pv03-3gi 3Gi RWX Retain Bound default/nginx-pvc nfs 14m
# 查看 pvc 绑定到了哪个 pv上
[root@k8s-master k8s]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nginx-pvc Bound pv03-3gi 3Gi RWX nfs 101s
可以看到 pvc 绑定到了 pv03-3gi 上,说明正处于 Released 状态的 pv 无法绑定任何 pvc
已经了解 pv 和 pvc 的绑定关系,接下来我们创建一个 pod 去绑定 pvc
清除所有的 deployment 和 pod
[root@k8s-master k8s]# kubectl get deploy
No resources found in default namespace.
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
redis-pod 1/1 Running 0 16h
[root@k8s-master k8s]# kubectl delete pod redis-pod
pod "redis-pod" deleted
编辑文件my-pvc-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-pod-pvc
name: nginx-pod-pvc
spec:
replicas: 2
selector:
matchLabels:
app: nginx-pod-pvc
template:
metadata:
labels:
app: nginx-pod-pvc
spec:
containers:
- image: nginx
name: nginx01
volumeMounts:
- name: nginx-volume
mountPath: /usr/share/nginx/html
volumes:
- name: nginx-volume
persistentVolumeClaim:
claimName: nginx-pvc
执行 yaml 文件,查看 deployment 和 pod
[root@k8s-master k8s]# kubectl apply -f my-pvc-pod.yaml
deployment.apps/nginx-pod-pvc created
[root@k8s-master k8s]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-pod-pvc 2/2 2 2 19s
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-pod-pvc-967fcb547-rj5ll 1/1 Running 0 30s
nginx-pod-pvc-967fcb547-wbbh7 1/1 Running 0 30s
查看 pod 的详细信息,里面有关于 pvc 信息
[root@k8s-master k8s]# kubectl describe pod nginx-pod-pvc-967fcb547-rj5ll
......
Volumes:
nginx-volume:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: nginx-pvc
ReadOnly: false
kube-api-access-5rlkl:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
......
因为 pvc 绑定在 pv03-3gi 这个 pv 上,这个 pv 的挂载目录是/nfs/data/03,所以我们去这个目录下编辑文件
[root@k8s-master k8s]# cd /nfs/data/03
[root@k8s-master 03]# echo "hello yigongsui" > index.html
进入 pod 容器内部,访问首页,查看结果
[root@k8s-master 03]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-pod-pvc-967fcb547-rj5ll 1/1 Running 0 11m
nginx-pod-pvc-967fcb547-wbbh7 1/1 Running 0 11m
[root@k8s-master 03]# kubectl exec -it nginx-pod-pvc-967fcb547-rj5ll /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-pod-pvc-967fcb547-rj5ll:/# curl localhost
hello yigongsui
可以看到里面的首页也变化了
这样我们的两个容器内目录就永久存储到我们的本地目录了,这样无论 pod 怎么重新部署删除,数据都不会丢失了
生命周期
PVC 和 PV 是一一对应的,PV 和 PVC 之间的相互作用遵循以下生命周期:
资源供应:管理员手动创建底层存储和 PV。资源绑定:用户创建 PVC,k8s 负责根据 PVC 的声明去寻找 PV,并绑定。
在用户定义好 PVC 之后,系统将根据 PVC 对存储资源的请求在已存在的 PV 中选择一个满足条件的。
一旦找到,就将该 PV 与用户定义的 PVC 进行绑定,用户的应用就可以使用这个 PVC 了,就可以在 pod 里面去使用如果找不到,PVC 则会无限期处于 Pending 状态,直到等到系统管理员创建了一个符合其要求的 PV,PV 一旦绑定到某个 PVC 上,就会被这个 PVC 独占,不能再与其他 PVC 进行绑定了,一一绑定。资源使用:用户可在 pod 中像 volume 一样使用 pvc。
pod 使用 volume 的定义,将 PVC 挂载到容器内的某个路径进行使用。
资源释放:用户删除 pvc 来释放 pv。
当存储资源使用完毕后,用户可以删除 PVC,与该 PVC 绑定的 PV 将会被标记为“已释放”,但还不能立刻与其他 PVC 进行绑定。通过之前 PVC 写入的数据可能还被留在存储设备上,只有在清除之后该 PV 才能再次使用。
这里我们查看 pv02-1gi 的绑定关系:
kubectl get pv pv02-1gi -o yaml
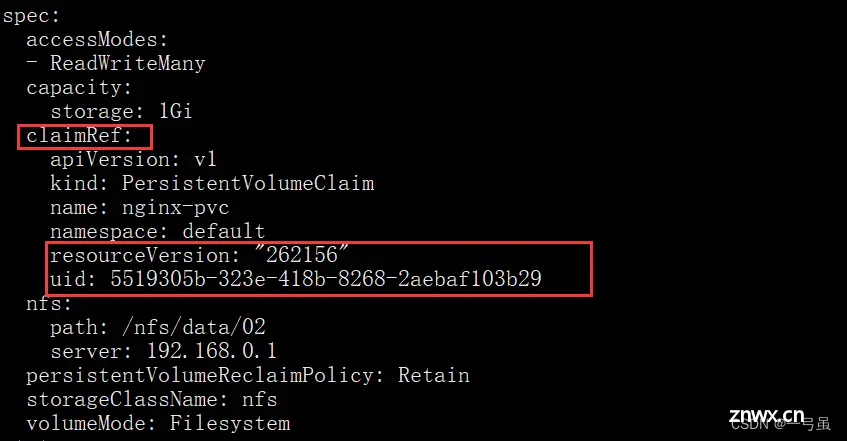
在这里唯一绑定了 pvc,需要清除才可以绑定其它 pvc
我们可以使用以下命令去动态修改 k8s 配置
<code>kubectl edit pv pv02-1gi
与 linux 的 vim 编辑器一致,点击i进入输入模式,删除这两行即可
查看 pv 状态
[root@k8s-master 03]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 135m
pv02-1gi 1Gi RWX Retain Available default/nginx-pvc nfs 135m
pv03-3gi 3Gi RWX Retain Bound default/nginx-pvc nfs 135m
可以看到 pv02-1gi 的状态已经变为 Available,就可以重新绑定 pvc 了
资源回收:k8s 根据 pv 设置的回收策略进行资源的回收。
对于 PV,管理员可以设定回收策略,用于设置与之绑定的 PVC 释放资源之后如何处理遗留数据的问题。只有 PV 的存储空间完成回收,才能供新的PVC绑定和使用。
问题:pv、pvc都是我们手动创建和绑定的,十分麻烦
有没有这样一种技术可以自动帮我们绑定,我们在 pod 创建的时候,自动帮我们创建 pv 和 pvc
答:有,StorageClass
StorageClass(存储类)
官方地址:https://kubernetes.io/zh-cn/docs/concepts/storage/storage-classes/#local
在 java 中,我们知道 class 是类的概念,相当于一个模板,通过类来创建对象
那么 StorageClass 其实就相当于是 pv 的模板,通过这个模版可以自动帮我们创建 pv 并通过 pvc 自动挂载上
接下来我们去理解 StorageClass
什么是 StorageClass
在 k8s 中,StorageClass 是用于定义和管理动态供应的持久化存储的对象。它是 PersistentVolume(PV)的动态供应机制的一部分。
StorageClass 定义了一组存储配置,包括存储提供者、存储类型、I/O 特性、复制策略等。它允许管理员为不同的存储需求创建多个 StorageClass,并为每个 StorageClass 指定不同的参数。
当创建 PersistentVolumeClaim(PVC)时,可以指定所需的 StorageClass。k8s 会根据 StorageClass 的定义和可用的存储资源,动态创建与 PVC 匹配的 PersistentVolume,并将其绑定到 PVC 上。
StorageClass 的优点是可以根据应用程序的需求自动创建和配置持久化存储,无需手动预先创建 PersistentVolume。这样可以简化存储管理的工作,提高存储资源的利用率。
另外,StorageClass 还支持动态卷的回收和回收策略的定义。当 PVC 被删除时,如果定义了回收策略,k8s 会自动回收对应的 PersistentVolume,释放存储资源。
总之,StorageClass 是 k8s 中用于动态供应和管理持久化存储的重要机制,可以根据需求自动创建、配置和回收存储资源,提高存储的灵活性和利用率。
静态供应与动态供应
我们这里的 PV 是我们提前开辟好的空间申明,是静态供应。
还有一种动态供应,根据 PVC 申请的空间,来实现 PV 的创建,从而进行绑定。
在动态资源供应模式下,通过 StorageClass 和 PVC 完成资源动态绑定(系统自动生成 PV),并供 pod 使用的存储管理机制。
在一个大规模的 k8s 集群里,可能有成千上万个 PVC,这就意味着运维人员必须实现创建出这个多个 PV,此外,随着项目的需要,会有新的 PVC 不断被提交,那么运维人员就需要不断的添加新的,满足要求的 PV,否则新的 pod 就会因为 PVC 绑定不到 PV 而导致创建失败。而且通过 PVC 请求到一定的存储空间也很有可能不足以满足应用对于存储设备的各种需求。
而且不同的应用程序对于存储性能的要求可能也不尽相同,比如读写速度、并发性能等,为了解决这一问题,k8s 又为我们引入了一个新的资源对象:StorageClass,通过 StorageClass 的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,用户根据 StorageClass 的描述就可以非常直观的知道各种存储资源的具体特性了,这样就可以根据应用的特性去申请合适的存储资源了。
而 StorageClass 对象的作用,其实就是创建 PV 的模板。
示例
获取指定 ns 下的 StorageClass 命令,默认是 default:
[root@k8s-master 03]# kubectl get sc
No resources found
接下来我们开始测试:
一个 k8s 中可以有多个 StorageClass,多个模版!
k3s 自带一个 local-path 存储类,我们这里也创建一个 local-path-storage.yaml 去创建存储类
apiVersion: v1
kind: Namespace
metadata:
name: local-path-storage
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: local-path-provisioner-service-account
namespace: local-path-storage
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: local-path-provisioner-role
rules:
- apiGroups: [ "" ]
resources: [ "nodes", "persistentvolumeclaims", "configmaps" ]
verbs: [ "get", "list", "watch" ]
- apiGroups: [ "" ]
resources: [ "endpoints", "persistentvolumes", "pods" ]
verbs: [ "*" ]
- apiGroups: [ "" ]
resources: [ "events" ]
verbs: [ "create", "patch" ]
- apiGroups: [ "storage.k8s.io" ]
resources: [ "storageclasses" ]
verbs: [ "get", "list", "watch" ]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: local-path-provisioner-bind
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: local-path-provisioner-role
subjects:
- kind: ServiceAccount
name: local-path-provisioner-service-account
namespace: local-path-storage
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: local-path-provisioner
namespace: local-path-storage
spec:
replicas: 1
selector:
matchLabels:
app: local-path-provisioner
template:
metadata:
labels:
app: local-path-provisioner
spec:
serviceAccountName: local-path-provisioner-service-account
containers:
- name: local-path-provisioner
image: rancher/local-path-provisioner:master-head
imagePullPolicy: IfNotPresent
command:
- local-path-provisioner
- --debug
- start
- --config
- /etc/config/config.json
volumeMounts:
- name: config-volume
mountPath: /etc/config/
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumes:
- name: config-volume
configMap:
name: local-path-config
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-path
provisioner: rancher.io/local-path
volumeBindingMode: WaitForFirstConsumer
reclaimPolicy: Delete
---
kind: ConfigMap
apiVersion: v1
metadata:
name: local-path-config
namespace: local-path-storage
data:
config.json: |-
{
"nodePathMap":[
{
"node":"DEFAULT_PATH_FOR_NON_LISTED_NODES",
"paths":["/opt/local-path-provisioner"]
}
]
}
setup: |-
#!/bin/sh
set -eu
mkdir -m 0777 -p "$VOL_DIR"
teardown: |-
#!/bin/sh
set -eu
rm -rf "$VOL_DIR"
helperPod.yaml: |-
apiVersion: v1
kind: Pod
metadata:
name: helper-pod
spec:
containers:
- name: helper-pod
image: busybox
imagePullPolicy: IfNotPresent
执行 yaml 文件
[root@k8s-master k8s]# vi local-path-storage.yaml
[root@k8s-master k8s]# kubectl apply -f local-path-storage.yaml
namespace/local-path-storage created
serviceaccount/local-path-provisioner-service-account created
clusterrole.rbac.authorization.k8s.io/local-path-provisioner-role created
clusterrolebinding.rbac.authorization.k8s.io/local-path-provisioner-bind created
deployment.apps/local-path-provisioner created
storageclass.storage.k8s.io/local-path created
configmap/local-path-config created
[root@k8s-master k8s]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
local-path rancher.io/local-path Delete WaitForFirstConsumer false 17s
把这个存储类设置为默认的存储类型,执行以下命令:
kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
[root@k8s-master k8s]# kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
storageclass.storage.k8s.io/local-path patched
[root@k8s-master k8s]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
local-path (default) rancher.io/local-path Delete WaitForFirstConsumer false 119s
每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件创建持久卷。 该字段必须指定。
在很多 k8s 系统中是自带的。
我们创建一个 pod 去测试是否会自动生成 pv 和 pvc,创建文件mysql-pod.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-path-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- image: mysql:5.7
name: mysql01
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: local-mysql-data
volumes:
- name: local-mysql-data
persistentVolumeClaim:
claimName: local-path-pvc
[root@k8s-master k8s]# vim mysql-pod.yaml
[root@k8s-master k8s]# kubectl apply -f mysql-pod.yaml
persistentvolumeclaim/local-path-pvc created
pod/mysql-pod created
查看 pv 和 pvc 是否自动创建了
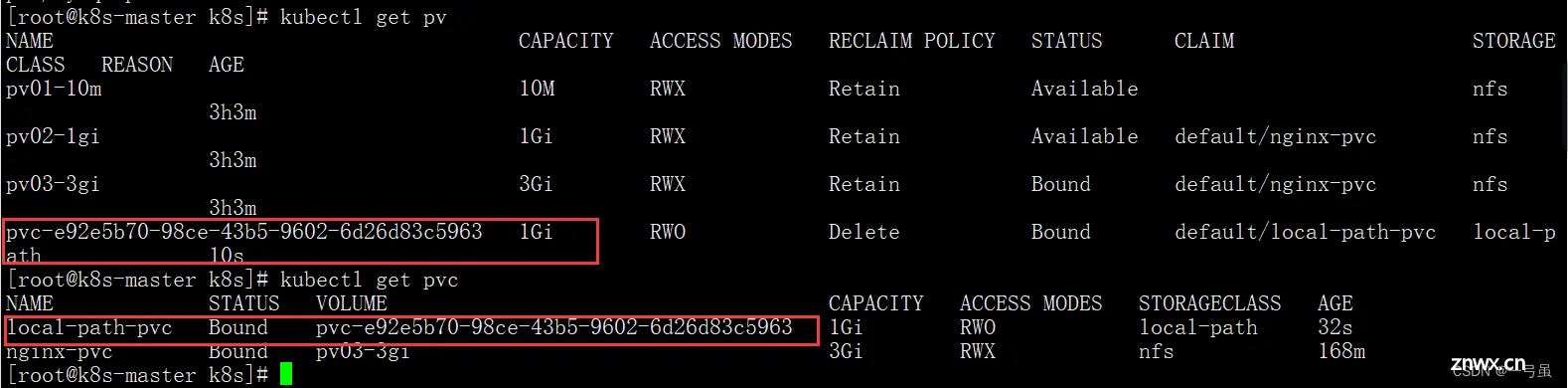
可以看到 pv 和 pvc 都自动创建了
创建 pod 时去申请 pvc,StorageClass 会动态创建 pvc 和 pv,pvc 申请多大存储 pv 就会创建多大空间
<code>local卷也存在自身的问题,当 pod 所在节点上的存储出现故障或者整个节点不可用时,pod 和卷都会失效,仍然会丢失数据,因此最安全的做法还是将数据存储到集群之外的存储或云存储上。同时配置,做一些灾备,保证数据不会丢失!
总结
本地存储:
缺点:
容易丢失pod 一没有可能就不见了pod 换了节点启动,数据也可能没了
存储卷:
nfs
系统就全部连接了,数据就不会再丢失方便使用 问题
一个系统中可能有很多的存储类型 nfs cifs hdfs oss,用户连接不方便,希望存在一个统一平台
pv
k8s 提供的同一存储类型对象
管理声明(文件类型、大小、使用方式,权限…回收策略)
pvc
用户拿着 pvc 就可以在 k8s 中自动找到 pv 绑定,从而实现数据持久化(k8s 的持久化存储策略)
storageClass
pv 每次手动创建十分麻烦,希望可以动态创建pvstorageClass 动态创建 pv 模版实现。
pvc 直接在 pod 中声明就好了! 不需要在手动创建 pv 了! 自动根据用户 pod 申请的 pvc 来根据 storageClass 自动创建 pv
至此,k8s 数据持久化搞定!
ConfigMap
configmap 是 k8s 中的资源对象,用于保存非机密性的配置的,数据可以用 kv 键值对的形式保存,也可通过文件的形式保存。
什么是 configmap
在 k8s 中,ConfigMap 是一种用于存储应用程序配置数据的对象。它允许将配置信息与应用程序分离,从而实现配置的解耦和管理的集中化。
ConfigMap 是以键值对的形式存储配置数据的,可以包含一个或多个键值对。这些配置数据可以包含环境变量、命令行参数、配置文件等。ConfigMap 的数据可以通过环境变量、命令行参数或挂载文件的方式注入到 Pod 中的容器中。
ConfigMap 可以通过 kubectl 命令行工具、YAML 文件或 API 进行创建和管理。可以在命名空间级别或集群级别创建 ConfigMap,并将其应用于特定的 Pod、Deployment、StatefulSet 等对象。
通过使用 ConfigMap,可以实现以下的优势:
解耦配置和应用程序:将配置信息从应用程序中分离,使得应用程序更加灵活和可配置。集中化管理配置:通过创建和管理 ConfigMap 对象,可以集中管理应用程序的配置,而不需要修改容器镜像或重新部署应用程序。容器化配置:ConfigMap 中的配置数据可以以环境变量、命令行参数或挂载文件的方式注入到容器中,方便应用程序的使用。动态更新配置:通过更新 ConfigMap 对象,可以实现对应用程序配置的动态更新,而不需要重新启动或重新部署应用程序。
总之,ConfigMap 是 k8s 中用于存储和管理应用程序配置数据的一种机制,通过将配置与应用程序分离,实现了配置的解耦和集中化管理,提高了应用程序的灵活性和可维护性。
configmap 作用
我们在部署服务的时候,每个服务都有自己的配置文件,
如果一台服务器上部署多个服务:nginx、tomcat、apache 等,那么这些配置都存在这个节点上
假如一台服务器不能满足线上高并发的要求,需要对服务器扩容,扩容之后的服务器还是需要部署多个服务:nginx、tomcat、apache,新增加的服务器上还是要管理这些服务的配置
如果有一个服务出现问题,需要修改配置文件,每台物理节点上的配置都需要修改,这种方式肯定满足不了线上大批量的配置变更要求
所以,k8s 中引入了 Configmap 资源对象,可以当成 volume 挂载到 pod 中,实现统一的配置管理。
configmap 特点
Configmap 是 k8s 中的资源, 相当于配置文件,可以有一个或者多个 ConfigmapConfigmap 可以做成 Volume,k8s pod 启动之后,通过 volume 形式映射到容器内部指定目录上;容器中应用程序按照原有方式读取容器特定目录上的配置文件;在容器看来,配置文件就像是打包在容器内部特定目录,整个过程对应用没有任何侵入。
configmap 使用
一个项目的所有配置文件都是用一个 configmap 来统一管理!这里我们使用 redis 进行测试
编辑一个简单的 redis 配置文件,my-redis.conf,内容如下
appendonly yes
根据 redis 配置文件创建一个 configmap
kubectl create cm redis-cm --from-file=my-redis.conf
[root@k8s-master k8s]# kubectl create cm redis-cm --from-file=my-redis.conf
configmap/redis-cm created
[root@k8s-master k8s]# kubectl get cm
NAME DATA AGE
kube-root-ca.crt 1 2d4h
redis-cm 1 11s
这个 configmap 就保存在 k8s 的 etcd 中,这个 redis 配置文件 my-redis.conf 就可有可无了
可以以 yaml 格式查看这个 configmap
kubectl get cm redis-cm -o yaml
[root@k8s-master k8s]# kubectl get cm redis-cm -o yaml
apiVersion: v1
data:
my-redis.conf: |
appendonly yes
kind: ConfigMap
metadata:
creationTimestamp: "2024-03-26T12:24:25Z"
name: redis-cm
namespace: default
resourceVersion: "298281"
uid: a472846b-e060-478a-8d37-f21300f975d8
创建一个 redis pod,编辑文件redis-cm.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis-cm
spec:
containers:
- name: redis01
image: redis
command:
- redis-server
- "/redis-master/redis.conf"
ports:
- containerPort: 6379
volumeMounts:
- mountPath: /data
name: redis-data
- mountPath: /redis-master
name: config
volumes:
- name: redis-data
emptyDir: { }
- name: config
configMap:
name: redis-cm
items:
- key: my-redis.conf
path: redis.conf
在 yaml 文件中,容器与 configmap 进行挂载的目录/redis-master是任意取的,自行设置即可
容器下 command 的第二个属性"/redis-master/redis.conf"是由容器与 configmap 挂载的目录加上最后一行的 path 构成,path 也是任意取名,是容器内生成的 redis 文件,内容是由上面的 key 映射到 configmap 里面对应的内容
根据 yaml 文件创建 pod
[root@k8s-master k8s]# vim redis-cm.yaml
[root@k8s-master k8s]# kubectl apply -f redis-cm.yaml
pod/redis-cm created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-pod 1/1 Running 0 3h37m
nginx-pod-pvc-967fcb547-rj5ll 1/1 Running 0 6h14m
nginx-pod-pvc-967fcb547-wbbh7 1/1 Running 0 6h14m
redis-cm 1/1 Running 0 59s
进入 pod 容器内部,查看/redis-master下的 redis.conf 文件
[root@k8s-master k8s]# kubectl exec -it redis-cm /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@redis-cm:/data# cd /redis-master/
root@redis-cm:/redis-master# ls
redis.conf
root@redis-cm:/redis-master# cat redis.conf
appendonly yes
可以看到/redis-master下的 redis.conf 文件已经和 configmap 绑定好了
在外部修改 configmap,查看容器内部的 redis.conf 会不会发生变化
[root@k8s-master k8s]# kubectl edit cm redis-cm
configmap/redis-cm edited
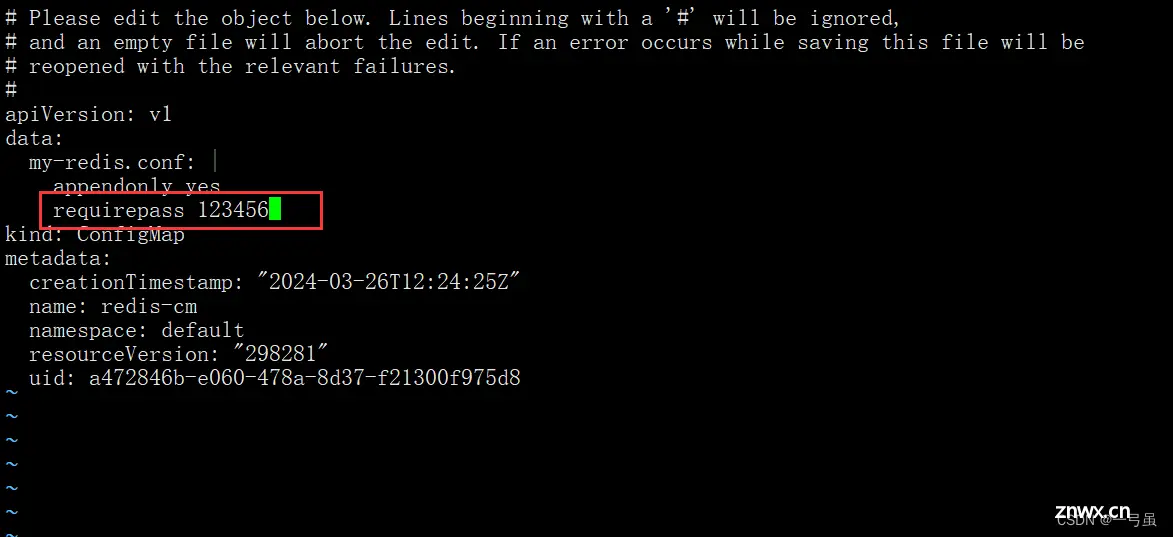
在上面新增一行<code>requirepass 123456,这是 redis 修改登录密码的属性
更改完成后等1-2分钟,进入容器查看redis.conf变化
[root@k8s-master k8s]# kubectl exec -it redis-cm /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@redis-cm:/data# cd /redis-master/
root@redis-cm:/redis-master# cat redis.conf
appendonly yes
requirepass 123456
我们在容器中尝试获取这两个属性
root@redis-cm:/redis-master# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get appendonly
1) "appendonly"
2) "yes"
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) ""
发现我们新增加的 requirepass 属性是获取不到的,这是容器的问题,因为当前 pod 没有热更新的能力
关于 configmap 命令
kubectl create cm xxxx --from-file=文件名
volumeMounts:
- name: xxx和voulmes的name对应
mountPath: 容器内加载配置文件的路径。
voulmes:
- name: xxx和容器内要挂载目录的对应
configMap:
name:
items:
key:
path:
实战:部署 mysql 服务
回顾加深 pv、pvc、configmap
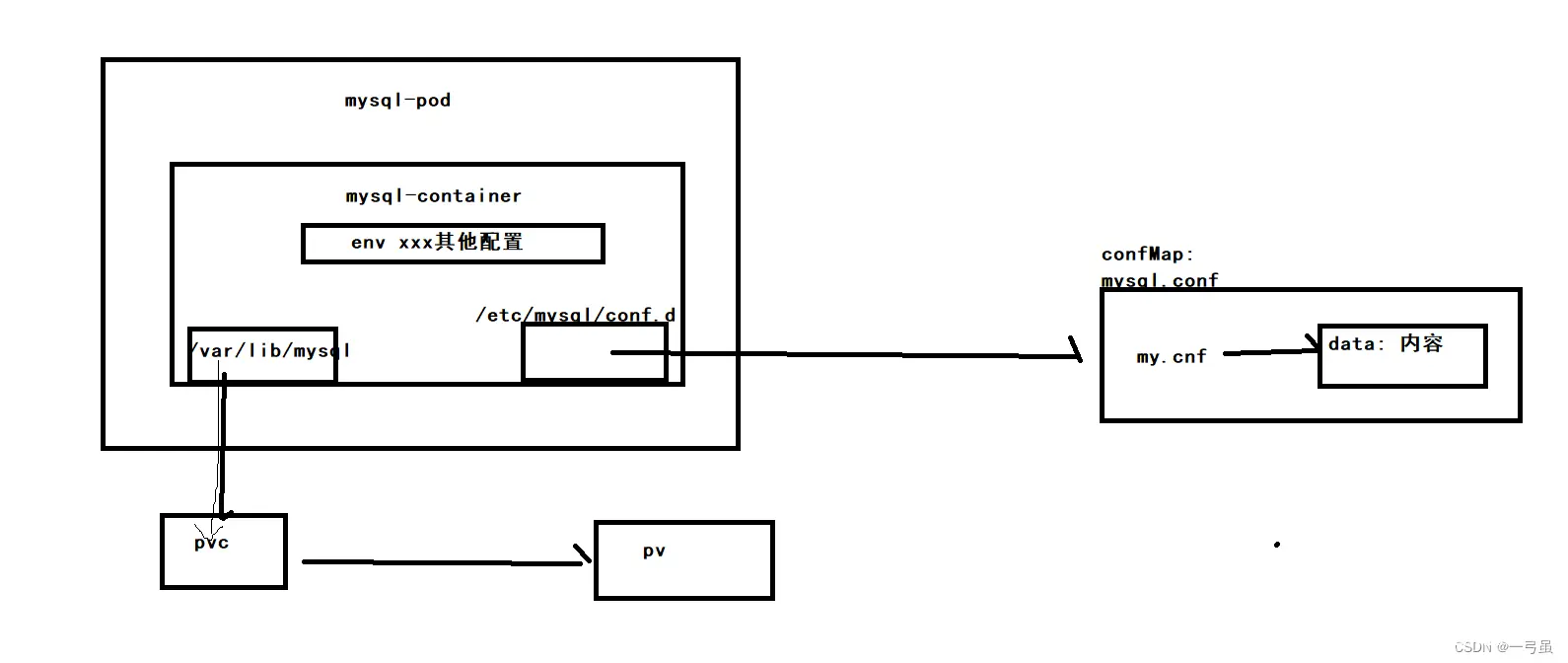
删除所有 deployment、pv、pvc、configmap、StorageClass创建一个 nsf 挂载目录给 mysql
<code>mkdir -p /nfs/data/mysql
创建 yaml 文件mysql-server.yaml
# 创建pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/mysql
server: 192.168.0.1
---
# 创建pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: nfs
---
# 创建 configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
mysql.cnf: |
[mysqld]
port=3306
character-set-server=utf8mb4
---
# 创建一个mysql服务
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
- mountPath: /etc/mysql/conf.d
name: conf-volume
volumes:
- name: conf-volume
configMap:
name: mysql-config
- name: data-volume
persistentVolumeClaim:
claimName: mysql-pvc
执行 yaml 文件
[root@k8s-master k8s]# vi mysql-server.yaml
[root@k8s-master k8s]# kubectl apply -f mysql-server.yaml
persistentvolume/mysql-pv created
persistentvolumeclaim/mysql-pvc created
configmap/mysql-config created
pod/mysql-pod created
启动成功后,查看 /nfs/data/mysql 下的文件
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-pod 1/1 Running 0 4s
[root@k8s-master k8s]# cd /nfs/data/mysql/
[root@k8s-master mysql]# ll
total 188476
-rw-r----- 1 polkitd input 56 Mar 26 22:01 auto.cnf
-rw------- 1 polkitd input 1680 Mar 26 22:01 ca-key.pem
-rw-r--r-- 1 polkitd input 1112 Mar 26 22:01 ca.pem
-rw-r--r-- 1 polkitd input 1112 Mar 26 22:01 client-cert.pem
-rw------- 1 polkitd input 1680 Mar 26 22:01 client-key.pem
-rw-r----- 1 polkitd input 1352 Mar 26 22:01 ib_buffer_pool
-rw-r----- 1 polkitd input 79691776 Mar 26 22:01 ibdata1
-rw-r----- 1 polkitd input 50331648 Mar 26 22:01 ib_logfile0
-rw-r----- 1 polkitd input 50331648 Mar 26 22:01 ib_logfile1
-rw-r----- 1 polkitd input 12582912 Mar 26 22:02 ibtmp1
drwxr-x--- 2 polkitd input 4096 Mar 26 22:01 mysql
drwxr-x--- 2 polkitd input 4096 Mar 26 22:01 performance_schema
-rw------- 1 polkitd input 1680 Mar 26 22:01 private_key.pem
-rw-r--r-- 1 polkitd input 452 Mar 26 22:01 public_key.pem
-rw-r--r-- 1 polkitd input 1112 Mar 26 22:01 server-cert.pem
-rw------- 1 polkitd input 1676 Mar 26 22:01 server-key.pem
drwxr-x--- 2 polkitd input 12288 Mar 26 22:01 sys
发现 nfs 挂载是没有问题的
进入容器内部,查看 configmap 挂载有没有问题
[root@k8s-master mysql]# kubectl exec -it mysql-pod /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@mysql-pod:/# cd /etc/mysql/conf.d/
root@mysql-pod:/etc/mysql/conf.d# ls
mysql.cnf
root@mysql-pod:/etc/mysql/conf.d# cat mysql.cnf
[mysqld]
port=3306
character-set-server=utf8mb4
configmap 挂载有没有问题
Secret
什么是 secret
在 k8s 中,Secret 是一种用于存储敏感数据的对象,如密码、API 密钥、证书等。Secret 的设计目的是为了安全地存储和传输敏感信息。
Secret 可以以多种形式存储敏感数据,包括 Base64 编码、字符串文本、docker 镜像等。Secret 的数据可以在 pod 中以环境变量、命令行参数或挂载文件的方式使用。
Secret 可以通过 kubectl 命令行工具、YAML 文件或 API 进行创建和管理。可以在命名空间级别或集群级别创建 Secret,并将其应用于特定的 Pod、Deployment、StatefulSet 等对象。
与 ConfigMap 类似,Secret 也是以键值对的形式存储数据的。但不同的是,Secret 的数据是加密的,并且在传输和存储过程中会进行加密和解密操作,以确保敏感信息的安全性。
通过使用 Secret,可以实现以下的优势:
安全存储敏感信息:Secret 可以加密存储敏感数据,确保敏感信息在传输和存储过程中的安全性。解耦敏感数据和应用程序:将敏感数据从应用程序中分离,使得应用程序更加灵活和可配置。集中化管理敏感数据:通过创建和管理 Secret 对象,可以集中管理应用程序的敏感数据,而不需要将其硬编码到应用程序中。
总之,Secret 是 k8s 中用于存储和管理敏感数据的一种机制,通过加密和解密操作,确保敏感信息的安全性,并将敏感数据与应用程序分离,提高了应用程序的灵活性和安全性。
secret 示例
我们这里使用 Base64 编码测试 secret
注意:Base64 只是一种编码,不含密钥的,并不安全。默认情况下,k8s Secret 未加密地存储在 API 服务器的底层数据存储(etcd)中。 任何拥有 API 访问权限的人都可以检索或修改 Secret,任何有权访问 etcd 的人也可以。 此外,任何有权限在命名空间中创建 Pod 的人都可以使用该访问权限读取该命名空间中的任何 Secret,只防君子,不防小人;
查看 “123456” 的 base64 编码
[root@k8s-master ~]# echo -n '123456' | base64
MTIzNDU2
[root@k8s-master ~]# echo 'MTIzNDU2' | base64 --decode
123456
编辑 yaml 文件mysql-server.yaml进行测试
# 创建pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/mysql
server: 192.168.0.1
---
# 创建pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: nfs
---
# 创建 configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
mysql.cnf: |
[mysqld]
port=3306
character-set-server=utf8mb4
---
# 创建一个mysql服务
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-password
key: PASSWORD
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
- mountPath: /etc/mysql/conf.d
name: conf-volume
volumes:
- name: conf-volume
configMap:
name: mysql-config
- name: data-volume
persistentVolumeClaim:
claimName: mysql-pvc
---
# 创建secret对象,在一些敏感位置使用
apiVersion: v1
kind: Secret
metadata:
name: mysql-password
data:
PASSWORD: MTIzNDU2
根据 yaml 文件创建 pod,测试密码 “123456” 能否登录
[root@k8s-master k8s]# kubectl apply -f mysql-server.yaml
persistentvolume/mysql-pv created
persistentvolumeclaim/mysql-pvc created
configmap/mysql-config created
pod/mysql-pod created
secret/mysql-password created
[root@k8s-master k8s]# kubectl exec -it mysql-pod /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@mysql-pod:/# mysql -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.36 MySQL Community Server (GPL)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
能够正常登录,测试成功
Statefulset
如果我们需要部署多个 MySQL 实例,就需要用到 StatefulSet。
StatefulSet 是用来管理有状态的应用。一般用于管理数据库、缓存等。
与 Deployment 类似, StatefulSet 用来管理 pod 集合的部署和扩缩。
Deployment 无序(mysql-xxxxxx-xxx mysql-xxxxxx-xxx mysql-xxxxxx- xxx)用来部署无状态应用。StatefulSet(mysql-xxxxxx-1 mysql-xxxxxx-2 mysql-xxxxxx-3)用来有状态应用。
StatefulSet 的核心功能就是通过某种方式记录这些状态,然后在 Pod 被重新创建时能够为新 Pod 恢复这些状态
StatefulSet 本质上是 Deployment 的一种变体,在 v1.9 版本中已成为 GA 版本,它为了解决有状态服务的问题,它所管理的 Pod 拥有固定的 Pod 名称,启停顺序,在 StatefulSet 中,Pod 名字称为网络标识(hostname),还必须要用到共享存储。
在 Deployment 中,与之对应的服务是 service,而在 StatefulSet 中与之对应的 headless service,headless service,即无头服务,与 service 的区别就是它没有 Cluster IP:,解析它的名称时将返回该 Headless Service 对应的全部 Pod 的 Endpoint 列表。
除此之外,StatefulSet 在 Headless Service 的基础上又为 StatefulSet 控制的每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为:
$(podname).(headless server name)
$(podname).(headless server name).namespace.svc.cluster.local
StatefulSet 为每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为: $(podname).(headless server name),也就意味着服务间是通过 Pod 域名来通信而非 Pod IP,因为当 Pod 所在 Node 发生故障时,Pod 会被飘移到其它 Node 上,Pod IP 会发生变化,但是 Pod 域名不会有变化。
StatefulSet 使用 Headless 服务来控制 Pod 的域名,这个域名的 FQDN 为:(service name).(namespace).svc.cluster.local,其中,“cluster.local” 指的是集群的域名。
什么是 statefulset
在 k8s 中,StatefulSet 是一种用于管理有状态应用的资源对象。与一般的 deployment 不同,StatefulSet 提供了一种有序部署和管理有状态应用的方式。
StatefulSet 主要用于部署需要持久化存储和唯一标识的应用,例如数据库或分布式存储系统。它为每个 Pod 实例分配一个唯一的标识符,并根据这个标识符进行有序的创建、更新和删除操作。
StatefulSet 在创建和删除 Pod 实例时,会按照一定的顺序进行操作,确保每个 Pod 实例的唯一标识符和网络标识符的稳定性。这使得有状态应用可以保持持久化存储的连接,并且具备可靠的网络标识符,以便于应用之间的通信。
StatefulSet 还提供了一些其他的功能,如有序的缩放、滚动更新、有状态服务的 DNS 解析等。它使用有状态服务的特性,提供了高可用性、可伸缩性和可靠性。
总之,StatefulSet 是 k8s 中用于管理有状态应用的一种资源对象,它为有状态应用提供了有序的部署、更新和删除操作,并保证每个 Pod 实例的唯一标识符和网络标识符的稳定性。
statefulset 优点
k8s 中的 StatefulSet 具有以下优点:
稳定的网络标识符:每个 StatefulSet 的 Pod 实例都具有稳定的网络标识符,这使得其他应用可以通过直接使用该标识符来访问和通信。这对于有状态应用非常重要,因为它们通常需要持久的网络标识符来保持连接。有序的创建和删除:StatefulSet 按照一定的顺序创建和删除 Pod 实例,这确保了应用在启动和关闭时的有序性。这对于有状态应用非常重要,因为它们通常需要按顺序启动和关闭,以避免数据丢失或损坏。持久化存储:StatefulSet 可以与持久化存储卷(如PersistentVolume)结合使用,以确保数据的持久性和可靠性。每个 Pod 实例都可以使用独立的存储卷,这对于有状态应用非常重要,因为它们通常需要在重新启动后保留数据。有序的缩放和滚动更新:StatefulSet 支持有序的缩放和滚动更新,可以根据需要增加或减少 Pod 实例的数量,并确保这些操作按顺序进行。这对于有状态应用非常重要,因为它们的缩放和更新通常需要遵循特定的顺序和规则。服务发现和 DNS 解析:StatefulSet 可以为每个 Pod 实例创建一个稳定的网络 DNS 名称,使得其他应用可以通过该名称来发现和访问它们。这对于有状态应用非常重要,因为它们通常需要通过名称进行服务发现和通信。
总的来说,StatefulSet 在 k8s 中为有状态应用提供了一种可靠、稳定和有序的部署、管理和操作方式,使得有状态应用可以更好地运行和维护。
statefulset 示例
编辑 yaml 文件nginx-sf.yaml
# headless service,即无头服务,nginx, ClusterIP: None
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
# StatefulSet, web, 3个副本pod nginx,自动创建3个pvc - 自动创建3个pv
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.20.1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
# 存储卷申请模版,指定了pvc名称,pvc的大小,申请的类型....
volumeClaimTemplates: # pvc template
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "local-path"
resources:
requests:
storage: 1Gi
注意:这文件中使用的 storageClassName 为 local-path,是在之前介绍存储类的时候的创建的,如果没有这个 local-path 是无法创建 pvc 的,如果没有,编写 yaml 文件创建 local-path
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-path
provisioner: rancher.io/local-path
volumeBindingMode: WaitForFirstConsumer
reclaimPolicy: Delete
执行 yaml 文件
[root@k8s-master k8s]# vi nginx-sf.yaml
[root@k8s-master k8s]# kubectl apply -f nginx-sf.yaml
service/nginx created
statefulset.apps/web created
查看 pod 和 pvc
[root@k8s-master k8s]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pvc-3050033b-638f-4d03-80d6-be6e270ac02a 1Gi RWO local-path 34m
www-web-1 Bound pvc-e22cd565-5f89-4b57-8be7-c4f648d52214 1Gi RWO local-path 9m15s
www-web-2 Bound pvc-e79aa081-176a-439f-875e-8119c021930e 1Gi RWO local-path 8m53s
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 81s
web-1 1/1 Running 0 57s
web-2 1/1 Running 0 48s
pod 和 pvc 创建完毕,名字也是按顺序起的,不是 deployment 那种随机字符串的格式进入容器内部,访问首页
[root@k8s-master k8s]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 3m16s 192.169.36.106 k8s-node1 <none> <none>
web-1 1/1 Running 0 2m52s 192.169.169.161 k8s-node2 <none> <none>
web-2 1/1 Running 0 2m43s 192.169.36.107 k8s-node1 <none> <none>
[root@k8s-master k8s]# kubectl exec -it web-0 /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@web-0:/# curl 192.169.36.106:80
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.20.1</center>
</body>
</html>
访问成功,我们创建的没有问题
为什么需要 headless service 无头服务?
在用 Deployment 时,每一个 Pod 名称是没有顺序的,是随机字符串,因此是 Pod 名称是无序的,但是在 statefulset 中要求必须是有序 ,每一个pod 不能被随意取代,pod 重建后 pod 名称还是一样的。而 pod IP 是变化的,所以是以 Pod 名称来识别。pod 名称是 pod 唯一性的标识符,必须持久稳定有效。这时候要用到无头服务,它可以给每个 Pod 一个唯一的名称 。
为什么需要 volumeClaimTemplate?
对于有状态的副本集都会用到持久存储,对于分布式系统来讲,它的最大特点是数据是不一样的,所以各个节点不能使用同一存储卷,每个节点有自已的专用存储,但是如果在 Deployment 中的 Pod template 里定义的存储卷,是所有副本集共用一个存储卷,数据是相同的,因为是基于模板来的 ,而 statefulset 中每个 Pod 都要自已的专有存储卷,所以 statefulset 的存储卷就不能再用 Pod 模板来创建了,于是 statefulSet 使用 volumeClaimTemplate,称为卷申请模板,它会为每个 Pod 生成不同的 pvc,并绑定 pv, 从而实现各 pod 有专用存储。这就是为什么要用volumeClaimTemplate 的原因。
稳定的存储:在 StatefulSet 中使用 VolumeClaimTemplate,为每个 Pod 创建持久卷声明(PVC)。 请注意,当 Pod 或者 StatefulSet 被删除时,持久卷声明和关联的持久卷不会被删除。
结论
使用 StatefulSet 创建 pod,按照顺序依次创建。 StatefulSet name 名 - 0/1/2/3/4 依次类推
无论如何删除 pod,再次启动,名称不会发生变化。
动态创建的 pvc 名字也不会发生变化。
在真实的项目中,redis,mysql 持久化存储的 pod 都是使用 StatefulSet 来部署的,创建有状态应用。
无论 pod ip 怎么变化,服务名不变,项目中就可以通过服务名来访问,域名只能在容器内部访问(对应项目启动的 pod)
测试:使用域名访问
root@web-0:/# curl web-1.nginx
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.20.1</center>
</body>
</html>
root@web-0:/# curl web-2.nginx.default.svc.cluster.local
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.20.1</center>
</body>
</html>
可以看到,完全可以通过域名来访问
总结
有状态应用 statefulset 无状态应用 deployment
Headless Service 给 deployment 的 pod 分了名字,然后 StatefulSet 将这种名字锁死。
StatefulSet 可以让 pod 的名字不变 + PVC,使得 pod 对应的 volume 不会变,也就是存储了存储状态。
Pod 标识:在具有 N 个副本的 StatefulSet中,每个 Pod 会被分配一个从 0 到 N-1 的整数序号,该序号在此 StatefulSet 上是唯一的。
部署扩缩容前提保证:
对于包含 N 个 副本的 ,当部署 Pod 时,它们是依次创建的,顺序为 0…N-1。当删除 Pod 时,它们是逆序终止的,顺序为 N-1…0。在将扩缩操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。
CronJob
什么是 CronJob
在 k8s 中,CronJob 是一种用于定期执行任务的资源对象。它基于 Cron 表达式,允许您在指定的时间间隔内自动运行容器化的任务。
CronJob 可以定义以下属性:
schedule:指定任务执行的时间表,使用标准的 Cron 表达式语法。例如,“0 * * * *” 表示每小时执行一次任务。jobTemplate:定义要执行的任务的模板,通常是一个 Pod 模板。这个模板包含了任务所需的容器镜像、命令、环境变量等配置。concurrencyPolicy:指定任务并发策略,默认为 Allow。Allow 表示允许并发执行任务,Forbid 表示禁止并发执行任务,新任务将会被跳过,Replace 表示如果任务正在执行,则会终止当前任务并启动新任务。successfulJobsHistoryLimit 和 failedJobsHistoryLimit:指定保留成功和失败任务历史记录的数量。
当 CronJob 被创建后,它将按照指定的时间表自动创建和调度 Job 对象。每个 Job 对象代表了一次任务的执行。k8s 将确保根据时间表创建和执行任务,并在任务完成后终止和清理相关的 Job 和 Pod。
CronJob 提供了一种简便的方式来周期性地运行容器化任务,例如定时备份、数据清理、定期报告等。它减少了手动执行任务的工作量,并提供了可靠的任务调度和执行机制。
CronJob 特点
在现代的云原生应用中,定时任务是一个非常重要的组成部分。k8s 提供了一种称为 CronJob 的机制,可以让我们方便地定义和管理定时任务。
CronJob 管理基于时间的 job,即:
在给定时间点只运行一次周期性地在给定时间点运行
一个 CronJob 对象类似于 crontab(cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job,格式可以参考 cron。
典型的用法如下所示:
在给定的时间点调度 Job 运行创建周期性运行的 Job,例如:数据库备份、发送邮件。
CronJob 表达式由五个字段组成,分别代表分钟、小时、日、月、周几。每个字段可以是以下任何值:
单个数字:例如5表示第5分钟或5月份。逗号分隔的数字列表:例如5,15,25表示第5、15和25分钟。连续的数字范围:例如10-15表示从第10分钟到第15分钟。星号(*):表示匹配该字段的所有值。例如在分钟字段上使用星号表示每分钟执行任务。斜杠(/):表示步长值。例如在分钟字段上使用"*/3"表示每隔3分钟执行一次任务。
CronJob 表达式示例:
每小时执行:0 * * * *每天晚上10点执行:0 22 * * *每周一早上6点执行:0 6 * * 1每2分钟运行一次任务 : */2 * * * *
示例
cronjob 类似于 Linux 的 crontab, cronjob 简写为 cj,查看 cronjob 任务。
查看所有 cronjob,默认是 default 空间下
kubectl get cj 或 kubectl get cronjob
[root@k8s-master k8s]# kubectl get cj
No resources found in default namespace.
[root@k8s-master k8s]# kubectl get cronjob
No resources found in default namespace.
CronJob 的基本属性:
CronJob Spec
.spec.schedule:调度,必需字段,指定任务运行周期,格式同 Cron
.spec.jobTemplate:Job 模板,必需字段,指定需要运行的任务,格式同 Job
.spec.startingDeadlineSeconds :启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:
Allow(默认):允许并发运行 JobForbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个Replace:取消当前正在运行的 Job,用一个新的来替换
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
.spec.suspend :挂起,该字段也是可选的。如果设置为 true,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为 false。
.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit :历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为 3 和 1。设置限制的值为 0,相关类型的 Job 完成后将不会被保留。
下面编写一个案例进行测试
编辑 yaml 文件my-cj.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *" # 每一分钟执行一次任务
# 描述自己的定时任务具体内容
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo yigongsui cronjob logs
restartPolicy: OnFailure
执行 yaml 文件,创建 cronjob
[root@k8s-master k8s]# vi my-cj.yaml
[root@k8s-master k8s]# kubectl apply -f my-cj.yaml
cronjob.batch/hello created
查看 cronjob 和 pod
[root@k8s-master k8s]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 29s 34s
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-28524538-hrckz 0/1 Completed 0 32s
过一分钟,再次查看 pod
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-28524538-hrckz 0/1 Completed 0 63s
hello-28524539-bhkbl 0/1 ContainerCreating 0 3s
发现又生成了一个 pod
查看日志:
[root@k8s-master k8s]# kubectl logs hello-28524539-bhkbl
Tue Mar 26 16:59:16 UTC 2024
yigongsui cronjob logs
日志正常输出
过了3分钟以上以后查看 pod 和 job
[root@k8s-master k8s]# kubectl get job
NAME COMPLETIONS DURATION AGE
hello-28524542 1/1 19s 2m26s
hello-28524543 1/1 18s 86s
hello-28524544 1/1 19s 26s
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-28524542-ncqvk 0/1 Completed 0 2m30s
hello-28524543-m8gdf 0/1 Completed 0 90s
hello-28524544-2vcqt 0/1 Completed 0 30s
可以看到只有3个 job 和 pod,这是新版本的特性,定时任务启动的 job 和 pod 只会保留3个
删除这个 cronjob,查看 job 和 pod
[root@k8s-master k8s]# kubectl delete -f my-cj.yaml
cronjob.batch "hello" deleted
[root@k8s-master k8s]# kubectl get job
No resources found in default namespace.
[root@k8s-master k8s]# kubectl get pod
No resources found in default namespace.
可以看到 job 和 pod 也全部删除了
DaemonSet
说明
是个 Pod 控制器能够确保 k8s 的所有节点都运行一个相同的 pod 副本,假设这个 pod 名称为 pa
当增加 node 节点时,这个节点会自动创建一个 pa副本当删除 node 节点时,pa 副本会自动删除 删除 daemonset 会删除它们创建的 pod
使用场景
需要在每一个 node 节点运行一个存储服务,例如 gluster,ceph需要在每一个 node 节点运行一个日志收集服务,例如 fluentd,logstash需要在每一个 node 节点运行一个监控服务,例如 Prometheus Node Exporter,zabbix agent 等
DaemonSet 概述
在 k8s 中,DaemonSet 是一种用于在集群中的每个节点上运行一个副本的资源对象。它确保每个节点上都运行一个 Pod 的副本,以便在整个集群中提供特定的服务或功能。
DaemonSet 具有以下特点:
每个节点一个副本:每个节点上都会自动创建一个 Pod 的副本,并且不会自动在新节点上创建副本。节点自动感知:当节点加入或离开集群时,DaemonSet 会自动调整 Pod 的数量,以保证每个节点上都有运行的副本。节点亲和性:可以使用节点选择器或亲和性规则来选择在特定节点上运行 DaemonSet 的 Pod。基于 Pod 模板:DaemonSet 使用 Pod 模板来定义要创建的 Pod 的配置,包括容器镜像、命令、环境变量等。
DaemonSet 在很多场景中都非常有用,例如:
日志收集:在每个节点上运行日志收集代理,将节点日志发送到集中的存储或分析系统。监控和度量:在每个节点上运行监控代理,收集节点和容器的度量指标。网络代理:在每个节点上运行网络代理,实现网络隔离、负载均衡等功能。
通过使用 DaemonSet,您可以确保在整个集群中的每个节点上都运行指定的 Pod,以提供特定的服务或功能,并确保集群中的每个节点都具有相同的配置。
我们的 k8s 集群默认有两个 DaemonSet
获取所有 ns 下的 DaemonSet
kubectl get ds -A
[root@k8s-master k8s]# kubectl get ds -A
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system calico-node 3 3 3 3 3 kubernetes.io/os=linux 2d8h
kube-system kube-proxy 3 3 3 3 3 kubernetes.io/os=linux 2d9h
示例
编辑 yaml 文件my-ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-nginx
namespace: kube-system
labels:
la-nginx: daemonset-nginx
spec:
selector:
matchLabels:
k2-nginx: daemonset-nginx
template:
metadata:
labels:
k2-nginx: daemonset-nginx
spec:
containers:
- name: daemonset-nginx
image: nginx
执行 yaml 文件,创建 daemonset
[root@k8s-master k8s]# vim my-ds.yaml
[root@k8s-master k8s]# kubectl apply -f my-ds.yaml
daemonset.apps/daemonset-nginx created
查看 ns 命名空间为 kube-system 下的所有 pod
kubectl get pod -n kube-system
可以看到,我们只启动了2个 pod,集群明明有3个节点,我们看看在哪2个节点启动了
<code>kubectl get pod -n kube-system -o wide
......
daemonset-nginx-5x8gr 1/1 Running 0 4m42s 192.169.169.169 k8s-node2 <none> <none>
daemonset-nginx-8s6dg 1/1 Running 0 4m42s 192.169.36.114 k8s-node1 <none> <none>
......
可以看到,只在 node1 和 node2 两个节点启动了,master 节点没有启动,这是为什么呢?
因为 master 天生就打了一个污点信息 NoSchedule,污点后面再讲
我们可以通过以下命令查看节点设置了哪些污点
# k8s-master 是节点的名字
kubectl describe node k8s-master
......
Taints: node-role.kubernetes.io/control-plane:NoSchedule
......
里面有这样一条信息,这就是 master 节点打上的污点,就是不让 pod 调度到该节点
查看其它节点的信息,发现为none
# 如果为空,Pod 可以自由地调度到这个节点上
Taints: <none>
说明:
有指定节点,那就在指定节点创建 pod,如指定了 nodeName,affinity,污点容忍度等…
未指定节点,将在所有节点上创建 Pod
Deployments 和 Daemonset 区别联系
相似性
都能创建Pod创建的 Pod 对应的进程都不希望被终止掉
使用 Deployments 的场景:无状态的 Sevice 使用 Deployments,微服务,需要实现对副本的数量进行扩缩容、平滑升级,就用 Deployments
使用 Daemonset 的场景:需要 Pod 副本总是运行在全部或特定主机上,并需要先于其他 Pod 启动,就用 daemonSet。
pod 深入理解
pod 容器生命周期
pod 的几种状态
可以使用命令kubectl get pod -w实时监控查看 pod 的状态
running:正常运行状态Pending:资源分配不对的时候会挂起,出现此状态Terminating:某个节点突然关机,上面的 pod 就会是这种状态ContainerCreating:容器创建的时候OOMKilled:当要求的内存超过限制的时候,k8s 会把这个容器 kill 后重启ErrImagePull:宿主机上不了网,镜像拉取失败
生命周期
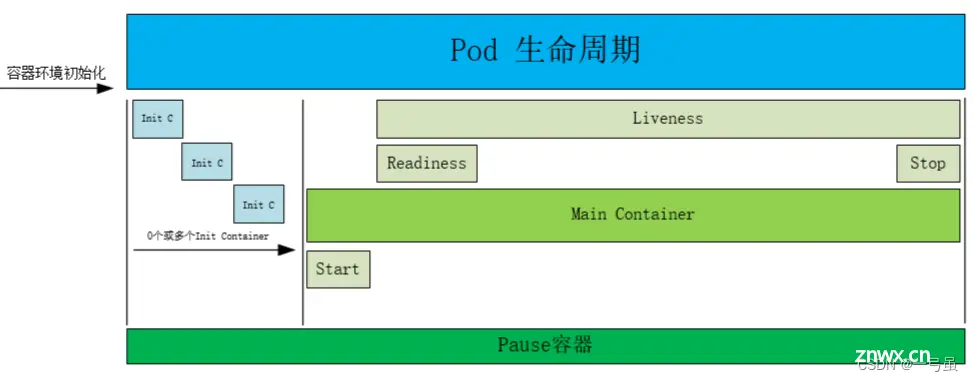
每个 Pod 里运行着一个特殊的被称之为 Pause 的容器,其他容器则为业务容器,这些业务容器共享 Pause 容器的网络栈和 Volume 挂载卷,因此他们之间通信和数据交换更为高效。在设计时可以充分利用这一特性,将一组密切相关的服务进程放入同一个 Pod 中;同一个 Pod 里的容器之间仅需通过localhost 就能互相通信。
Pause 容器,又叫 Infra 容器
比如说现在有一个 Pod,其中包含了一个容器 A 和一个容器 B Pod ip,它们两个就要共享 Network Namespace。在 k8s 里的解法是这样的:它会在每个 Pod 里,额外起一个 Infra container 小容器来共享整个 Pod 的 Network Namespace。
Infra container 是一个非常小的镜像,大概 700KB 左右,是一个 C 语言写的、永远处于 “暂停” 状态的容器。由于有了这样一个 Infra container 之后,其他所有容器都会通过 Join Namespace 的方式加入到 Infra container 的 Network Namespace 中。
所以说一个 Pod 里面的所有容器,它们看到的网络视图是完全一样的。即:它们看到的网络设备、IP 地址、Mac 地址等等,跟网络相关的信息,其实全是一份,这一份都来自于 Pod 第一次创建的这个 Infra container。这就是 Pod 解决网络共享的一个解法。
由于需要有一个相当于说中间的容器存在,所以整个 Pod 里面,必然是 Infra container 第一个启动。并且整个 Pod 的生命周期是等同于 Infra container 的生命周期的,与容器 A 和 B 是无关的。这也是为什么在 k8s 里面,它是允许去单独更新 Pod 里的某一个镜像的,即:做这个操作,整个 Pod 不会重建,也不会重启,这是非常重要的一个设计。
Pod hook(钩子)是由 k8s 管理的 kubelet 发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。可以同时为 Pod 中的所有容器都配置 hook。
init 容器
官网:https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/init-containers/
Init 容器是一种特殊容器,在 Pod 内的应用容器启动之前运行。Init 容器可以包括一些应用镜像中不存在的实用工具和安装脚本。
每个 pod 中可以包含多个容器, 应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
Init 容器与普通的容器非常像,除了如下两点:
它们总是运行到完成。每个都必须在下一个启动之前成功完成。
如果 Pod 的 Init 容器失败,kubelet 会不断地重启该 Init 容器直到该容器成功为止。 然而,如果 Pod 对应的 <code>restartPolicy 值为 “Never”,并且 Pod 的 Init 容器失败, 则 k8s 会将整个 Pod 状态设置为失败。
为 Pod 设置 Init 容器需要在 Pod 规约 中添加 initContainers 字段, 该字段以 Container 类型对象数组的形式组织,和应用的 containers 数组同级相邻。
Init 容器的状态在 status.initContainerStatuses 字段中以容器状态数组的格式返回 (类似 status.containerStatuses 字段)。
下面我们编写一个案例测试 init 容器
编写 yaml 文件my-init.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
根据文件创建 pod
[root@k8s-master k8s]# vim my-init.yaml
[root@k8s-master k8s]# kubectl apply -f my-init.yaml
pod/myapp-pod created
查看 pod
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 86s
可以看到我们的这个 pod 没有运行成功,这是因为 init 容器没有启动成功
Init 容器会等待至发现名称为 mydb 和 myservice 的服务。
接下来我们创建这两个服务,编写 yaml 文件init-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
启动两个服务,查看 pod 状态
[root@k8s-master k8s]# vim init-svc.yaml
[root@k8s-master k8s]# kubectl apply -f init-svc.yaml
service/myservice created
service/mydb created
[root@k8s-master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 5m13s
可以看到 pod 已经顺利启动了
总结
Init 容器与普通的容器非常像,区别是每个都必须在下一个容器启动之前成功完成。
如果 Pod 的 Init 容器失败,kubelet 会不断地重启该 Init 容器直到该容器成功为止。 然而,如果 Pod 对应的 restartPolicy 值为 “Never”,k8s 不会重新启动 Pod。容器重启策略默认是Always。
为 Pod 设置 Init 容器需要在 Pod 的 spec 中添加 initContainers 字段, 该字段以 Container类型对象数组的形式组织,和应用的 containers 数组同级相邻。
Init 容器支持应用容器的全部字段和特性,包括资源限制、数据卷和安全设置。
如果为一个 Pod 指定了多个 Init 容器,这些容器会按顺序逐个运行。 每个 Init 容器必须运行成功,下一个才能够运行。当所有的 Init 容器运行完成时, k8s 才会为 Pod 初始化应用容器并像平常一样运行。
容器探针
官网:https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
当你使用 k8s 的时候,有没有遇到过 Pod 在启动后一会就挂掉然后又重新启动这样的恶性循环?你有没有想过 k8s 是如何检测 pod 是否还存活?虽然容器已经启动,但是 k8s 如何知道容器的进程是否准备好对外提供服务了呢?
k8s 探针(Probe)是用于检查容器运行状况的一种机制。探针可以检查容器是否正在运行,容器是否能够正常响应请求,以及容器内部的应用程序是否正常运行等。在 k8s 中,探针可以用于确定容器的健康状态,如果容器的健康状态异常,k8s 将会采取相应的措施,例如重启容器或将其从服务中删除。
为什么需要容器探针?
容器探针可以确保您的容器在任何时候都处于可预测的状态。
如果没有容器探针,那么容器对于 k8s 平台而言,就处于一个黑盒状态。下面是没有使用容器探针可能出现的一些 case:
容器未启动,负载均衡就把流量转发给容器,导致请求大量异常容器内服务不可用/发生异常,负载均衡把流量转发给容器,导致请求大量异常容器已经不正常工作(如容器死锁导致的应用程序停止响应),k8s 平台本身无法感知,不能即时低重启容器。
探测类型
针对运行中的容器,kubelet 可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
分别是Liveness Probe(存活探针)、Readiness Probe(就绪探针)、Startup Probe(启动探针)
# livenessProbe
用于检查容器是否正在运行,如果Liveness Probe检查失败,则Kubernetes将重启容器
# readinessProbe
用于检查容器是否能够正常响应请求,如果Readiness Probe检查失败,则Kubernetes将停止将流量发送到该容器
# startupProbe
用于检查容器内部的应用程序是否已经启动并且已经准备好接受流量,如果Startup Probe检查失败,则Kubernetes将重启容器
探针资源 yaml 中的常用的配置,如下。可根据具体的需求去设置,心跳机制
spec:
containers:
# 就绪探针
readinessProbe:
# 检测方式
httpGet:
# 超时时间
timeoutSeconds:
# 延迟时间
initialDelaySeconds:
# 失败次数限制
failureThreshold:
# 每多少秒检测一次
periodSeconds:
# 存活探针
livenessProbe:
# 检测方式
httpGet:
# 超时时间
timeoutSeconds:
# 延迟时间
initialDelaySeconds:
# 失败次数限制
failureThreshold:
# 每多少秒检测一次
periodSeconds:
探针机制
使用探针来检查容器有四种不同的方法。 每个探针都必须准确定义为这四种机制中的一种:请求-响应。
#exec
在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
#httpGet
对容器的 IP 地址上指定端口和路径执行 HTTP GET 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。
#tcpSocket
对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。如果远程系统 (容器)在打开连接后立即将其关闭,这算作是健康的。
#grpc
使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC健康检查。 如果响应的状态是"SERVING",则认为诊断成功。 gRPC 探针是一个 alpha 特性,只有在你启用了"GRPCContainerProbe"特性门控时才能使用。
探测结果
不管是那种每次探测都将获得以下三种结果之一:
Success(成功)容器通过了诊断。Failure(失败)容器未通过诊断。Unknown(未知)诊断失败,因此不会采取任何行动。
测试
编辑 yaml 文件my-liveness.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:# exec方式检测
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5# 容器启动成功后5s,开始执行探针检测
periodSeconds: 5# 每隔5s检测一次
从 yaml 文件中可以看出:首先创建目录/tmp/healthy,每隔5秒进行探针检测,检测目录是否存在,pod 创建完成后30s,删除目录,这时候探针就检测不到了,重复检测,在600秒后,pod 结束
启动 pod
[root@k8s-master k8s]# vim my-liveness.yaml
[root@k8s-master k8s]# kubectl apply -f my-liveness.yaml
pod/liveness-exec configured
查看 pod 描述信息
kubectl describe pod liveness-exec
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m26s default-scheduler Successfully assigned default/liveness-exec to k8s-node2
Normal Pulling 61s kubelet Pulling image "busybox"
Normal Pulled 45s kubelet Successfully pulled image "busybox" in 15.275s (15.275s including waiting)
Normal Created 45s kubelet Created container liveness
Normal Started 45s kubelet Started container liveness
Warning Unhealthy 1s (x3 over 11s) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 1s kubelet Container liveness failed liveness probe, will be restarted
可以看到,容器在创建30秒后Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory无法打开这个目录了,这时候容器探针检测失败,重新启动
我们这个案例是使用exec机制(在容器内执行指定命令)来检测探针是否成功,官网还有 httpGet 请求和 tcpSocket,自行测试即可
节点亲和性
问题:每次pod调度都是随机事件,不知道pod会被调度到哪一个节点
Scheduler 是 k8s 的调度器,主要的任务是把定义的 pod 分配到集群的节点上。听起来非常简单,但有很多要考虑的问题:
公平:如何保证每个节点都能被分配资源资源高效利用:集群所有资源最大化被使用效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作灵活:允许用户根据自己的需求控制调度的逻辑
Scheduler 是作为单独的程序运行的,启动之后会一直监听 API Server ,获取 Pod.Spec.NodeName 为空的 pod,对每个 pod 都会创建一个 binding,表明该 pod 应该放到哪个节点上。
调度的几个部分
首先是过滤掉不满足条件的节点,这个过程称为 predicate(预选);然后对通过的节点按照优先级排序,这个是 priority(优选);最后从中选择优先级最高的节点。
如果中间任何一步骤有错误,就直接返回错误(先预选,后优选)
Predicate(预选)有一系列的算法可以使用:
PodFitsResources:节点上剩余的资源是否大于 pod 请求的资源PodFitsHost:如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配PodFitsHostPorts:节点上已经使用的 port 是否和 pod 申请的 port 冲突PodSelectorMatches:过滤掉和 pod 指定的 label 不匹配的节点NoDiskConflict:已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读
如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态(pending:等待),不断重试调度,直到有节点满足条件。经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程:按照优先级大小对节点排序。
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。这些优先级选项包括:
LeastRequestedPriority:通过计算 CPU 和 Memory 的使用率来决定权重,使用率越低权重越高。换句话说,这个优先级指标倾向于资源使用比例更低的节点
BalancedResourceAllocation:节点上 CPU 和 Memory 使用率越接近,权重越高。这个应该和上面的一起使用,不应该单独使用
ImageLocalityPriority:倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高
通过算法对所有的优先级项目和权重进行计算,得出最终的结果
pod 与 node 的亲和性
pod.spec.nodeAffinity
preferredDuringSchedulingIgnoredDuringExecution(优先执行计划):软策略
requiredDuringSchedulingIgnoredDuringExecution(要求执行计划):硬策略
(preferred:首选,较喜欢 required:需要,必须)
键值运算关系
In:label 的值在某个列表中NotIn:label 的值不在某个列表中Gt:label 的值大于某个值Lt:label 的值小于某个值Exists:某个 label 存在DoesNotExist:某个 label 不存在
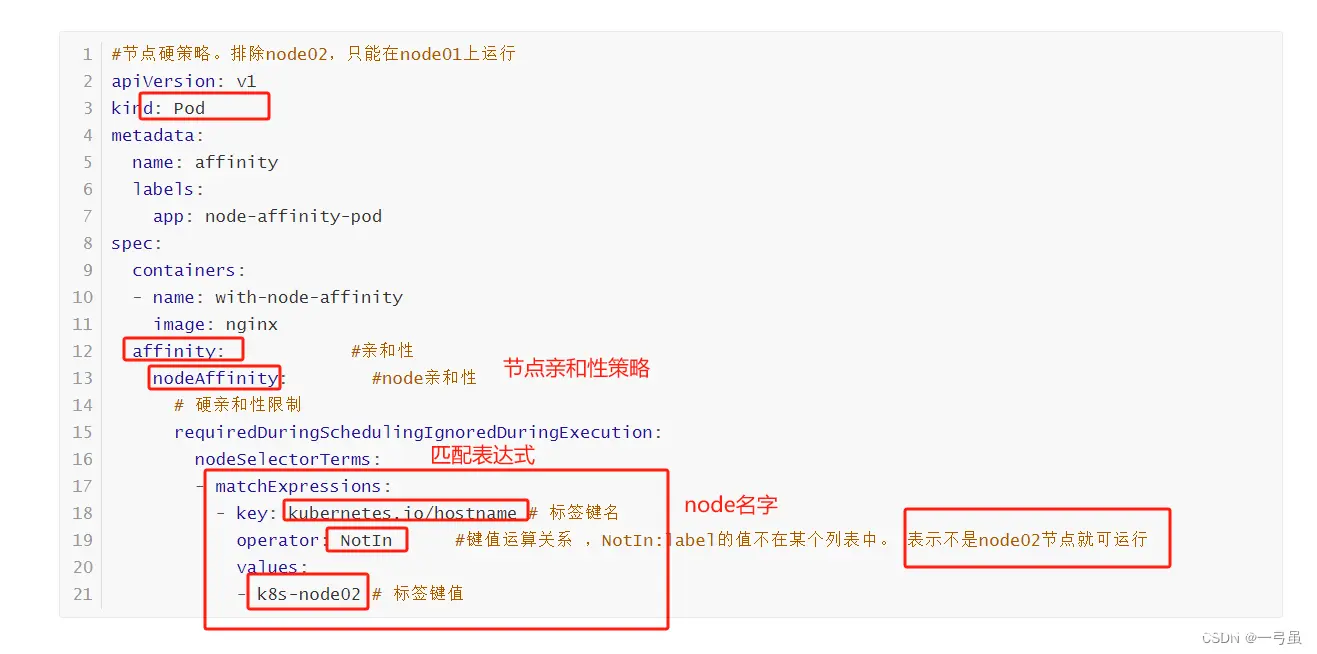
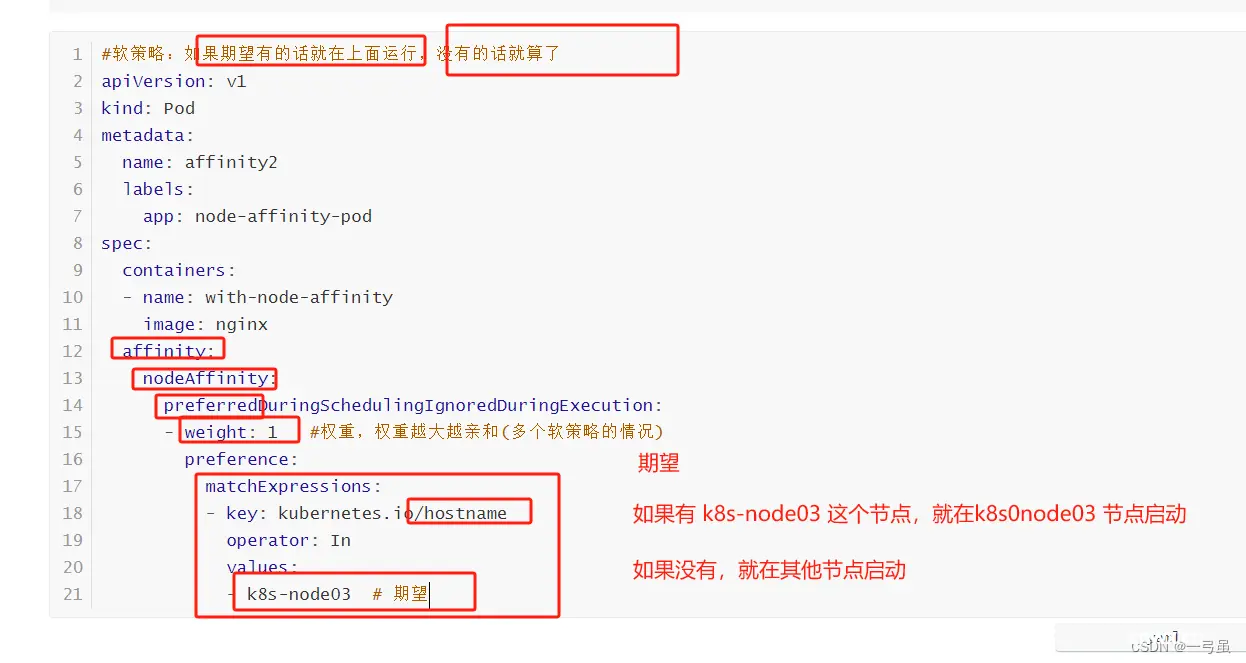
<code>#软硬策略(先满足硬策略再满足软策略)
apiVersion: v1
kind: Pod
metadata:
name: affinity2
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: nginx
affinity:
# 可以编写多个亲和性策略
nodeAffinity: #node亲和性
# 硬亲和性限制
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname # 标签键名
operator: NotIn #键值运算关系 ,NotIn:label的值不在某个列表中。 表示不是node02节点就可运行
values:
- k8s-node02 # 标签键值
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1 #权重,权重越大越亲和(多个软策略的情况)
preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-node03 # 期望是node03
pod 与 pod 的亲和性
pod.spec.affinity.podAffinity 亲和性 podAntiAffinity 反亲和性
preferredDuringSchedulingIgnoredDuringExecution:软策略requiredDuringSchedulingIgnoredDuringExecution:硬策略
要有选择中的 Pod —— 才可以说是 Pod 间 —— 也就是要有 labelSelector(若没有设置此字段,表示没有选中的 Pod)
topology 就是拓扑的意思,这里指的是一个拓扑域,是指一个范围的概念,比如一个 Node、一个机柜、一个机房或者是一个地区(如杭州、上海)等,实际上对应的还是 Node 上的标签。
topologyKey 可以理解为 Node 的 label,比如默认所有节点都会有 kubernetes.io/hostname 这 label,相应的值为节点名称,如 master01 节点的 label 为 kubernetes.io/hostname=master01,这种情况每个节点对应的值都不同。
pod亲和性调度需要各个相关的 pod 对象运行于"同一位置", 而反亲和性调度则要求他们不能运行于"同一位置",这里指定“同一位置” 是通过 topologyKey 来定义的。

在我这个集群中,找到我期望的pod启动节点:pod亲和性策略:标签: app=node-affinity-pod
反亲和性 podAntiAffinity
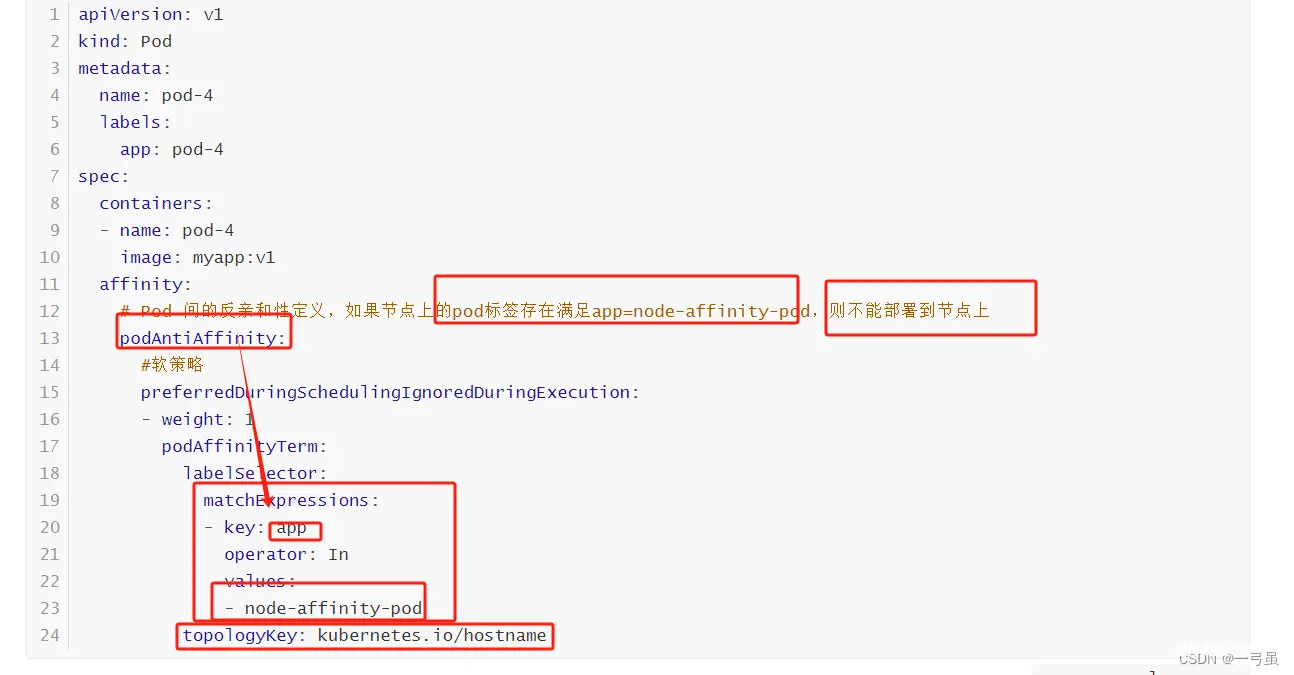
Taint 和 Toleration(污点和容忍)
所谓污点就是故意给某个节点服务器上设置个污点参数,那么你就能让生成 pod 的时候使用相应的参数去避开有污点参数的 node 服务器。而容忍呢,就是当资源不够用的时候,即使这个 node 服务器上有污点,那么只要 pod 的 yaml 配置文件中写了容忍参数,最终 pod 还是会容忍的生成在该污点服务器上。默认 master 节点是 NoSchedule(不会调度任何新的 Pod)。
污点(Taint)是应用在节点机器 node 上之上的,从这个名字就可以看出来,是为了排斥 pod 所存在的。
容忍度(Toleration)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。
Taint(污点)和 Toleration(容忍)可以作用于 node 和 pod 上,其目的是优化 pod 在集群间的调度,这跟节点亲和性类似,只不过它们作用的方式相反,具有 taint 的 node 和 pod 是互斥关系,而具有节点亲和性关系的 node 和 pod 是相吸的。另外还有可以给 node 节点设置 label,通过给 pod 设置 <code>nodeSelector 将 pod 调度到具有匹配标签的节点上。
Taint 和 toleration 相互配合,可以用来避免 pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 pod,是不会被该节点接受的。如果将 toleration 应用于 pod 上,则表示这些 pod 可以(但不要求)被调度到具有相应 taint 的节点上。
基本操作
查看某个节点的 Taint 信息
kubectl describe node nodename
[root@k8s-master01 ~]# kubectl describe node k8s-node01
......
Taints: <none> # 关注这个地方即可 ---没有设置过污点的节点属性中的参数是这样的Taints: <none>
......
为 node 设置 taint
使用 kubectl taint 命令可以给某个 Node 节点设置污点,Node 被设置上污点之后就和 Pod 之间存在了一种相斥的关系,可以让 Node 拒绝 Pod 的调度执行,甚至将 Node 已经存在的 Pod 驱逐出去。
每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。当前 taint effect 支持如下三个选项:
# NoSchedule:表示k8s将不会将Pod调度到具有该污点的Node上
# PreferNoSchedule:表示k8s将尽量避免将Pod调度到具有该污点的Node上
# NoExecute:表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod驱逐出去,赶到其它节点上
这也是为什么生成的pod不会分配到master的原因(因为天生就打了这个污点NoSchedule)
接下来我们给节点node1增加一个污点,它的键名是key1,键值是value1,效果是NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到node1这个节点。
为 node1 设置 taint:
kubectl taint nodes k8s-node1 key1=value1:NoSchedule
删除上面的 taint:
# 去除污点,最后一个"-"代表删除
kubectl taint nodes k8s-node1 key1:NoSchedule-
为 pod 设置 toleration
只要在 pod 的 spec 中设置 tolerations 字段即可,可以存在多个 key,如下所示:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
- key: "node.alpha.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
value 的值可以为 NoSchedule、PreferNoSchedule 或 NoExecute。tolerationSeconds 是当 pod 需要被驱逐时,可以继续在 node 上运行的时间。
多个污点匹配原则
可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。
k8s 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了 Pod 是否会被分配到该节点。
例如,假设您给一个节点添加了如下污点:
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
假定有一个 Pod,它有两个容忍度:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
上述 Pod 不会被分配到 node1 节点,因为其没有容忍度和第三个污点相匹配。
但是如果在给节点添加上述污点之前,该 Pod 已经在上述节点运行, 那么它还可以继续运行在该节点上,因为第三个污点是三个污点中唯一不能被这个 Pod 容忍的。
总结:
通过污点和容忍度,可以灵活地让 Pod 避开某些节点或者将 Pod 从某些节点驱逐。
如果您想将某些节点专门分配给特定的一组用户使用,您可以给这些节点添加一个污点(即, kubectl taint nodes nodename dedicated=groupName:NoSchedule), 然后给这组用户的 Pod 添加一个相对应的 toleration。
拥有上述容忍度的 Pod 就能够被分配到上述专用节点,同时也能够被分配到集群中的其它节点。
在部分节点配备了特殊硬件(比如 GPU)的集群中, 我们希望不需要这类硬件的 Pod 不要被分配到这些特殊节点,以便为后继需要这类硬件的 Pod 保留资源。
要达到这个目的,可以先给配备了特殊硬件的节点添加 taint (例如 kubectl taint nodes nodename special=true:NoSchedule 或 kubectl taint nodes nodename special=true:PreferNoSchedule), 然后给使用了这类特殊硬件的 Pod 添加一个相匹配的 toleration。
指定调度节点
亲和性和污点,容忍都比较含蓄。
指定调度节点是绝对指定目标,我就要这个 node
Pod.spec.nodeName 将 Pod 直接调度到指定的 Node 节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 7
template:
metadata:
labels:
app: nginx
spec:
nodeName: k8s-node01 #指定全在node01
containers:
- name: myweb
image: nginx
ports:
- containerPort: 80
Pod.spec.nodeSelector:通过 k8s 的 label-selector 机制选择节点,由调度器调度策略匹配 label,而后调度 Pod 到目标节点,该匹配规则属于强制约束
首先在 master 节点给需要调度的目标 node 打上 label,并在创建 pod 的 yaml 文件中指定 label 来使得 pod 创建的时候调度到指定标签的 node 节点。
# 首先给指定的 node 节点加上标签
kubectl label nodes kube-node01 disk=ssd
kubectl get nodes kube-node01 --show-labels |grep disk
# 编写 yaml 文件引入标签
[root@kube-master scheduler]# vim nodeLabels-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-busybox
spec:
replicas: 1
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
nodeSelector: # 定义 nodeSelector 参数
disk: ssd # 引入标签
指定在某台节点启动的命令: nodename 、nodeSelector(需要再node上指定labels)
Pod 相关配置完整图
认证与鉴权
官网:https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/
访问控制
客户端进行认证和鉴权操作
在 k8s 集群中,客户端通常有两类:
User Account:一般是独立于 k8s 之外的其他服务管理的用户账号
Service Account:k8s 管理的账号,用于为 Pod 中的服务进程在访问 k8s 时提供身份标识
ApiServer 是访问及管理资源对象的唯一入口。任何一个请求访问 ApiServer,都要经过下面三个流程:
Authentication(认证):身份鉴别,只有正确的账号才能够通过认证。Authorization(授权):判断用户是否有权限对访问的资源执行特定的动作。Admission Control(准入控制):用于补充授权机制以实现更加精细的访问控制功能.
认证管理
HTTP Token 认证:token 认证
HTTP Base 认证:用户名+密码
HTTPS 证书认证:CA 根证书认证
k8s 集群安全的最关键点在于如何识别并认证客户端身份,它提供了3种客户端身份认证方式:
HTTP Base 认证:通过用户名 + 密码的方式认证
这种认证方式是把 ”用户名:密码” 用 BASE64 算法进行编码后的字符审放在 HTTP 请求中的 Header Authrizaton 域里发送给服务端。服务端收到后进行解码,获取用户名及密码,然后进行用户身份认证的过程。
HTTP Token认证:通过一个 Token 来识别合法用户
这种认证方式是用一个很长的 Token 来表明客户身份的一种方式,每 Token 对应一个用户,当客户端发起 APi 调用请求时,在 HTTP Header 里放入 Token,API Server 接到 Token 后会跟服务器中保存的 token 进行比对,然后进行用户身份认证的过程.
HTTPS证书认证:基于CA根证书签名的双向数字证书认证方式
这种认证方式是安全性最高的一种方式,但是同时也是操作起来最麻烦的一种方式
HTTPS 认证大体分为3个过程:
证书申请和下发, HTTPS 通信双方的服务器向 CA 机构申请证书,CA 机构下发根证书、服务端证书及私钥给申请者客户端和服务端的双向认证
客户端向服务器端发起清求,服务端下发自己的证书给客户端, 客户端接收到证书后,通过私钥解密证书,在证书中获得服务端的公钥,客户端利用服务器端的公钥认证证书中的信息,如果一致,则认可这个服务器客户端发送自己的证书给服务器端,服务端接收到证书后,通过私钥解密证书,在证书中获得客户端的公钥,并用该公钥认证证书信息,确认客户端是否合法
服务端和客户端进行通信 服务端和客户端协商好加密方案后,客户端会产生一个随机的秘钥并加密,然后发送到服务端。服务器端接收这个秘钥后,双方按下来通信的所有内容都通过该随机秘钥加密。
注意:k8s 允许同时配置多种认证方式,只要其中任意一个方式认证通过即可。
授权管理
授权发生在认证成功之后,通过认证就可以知道请求用产是准,然后 k8s 会根据事先定义的授权策略来决定用户是否有权限访问,这个过程就称为授权。
鉴权:每个发送到 ApiServer 的请求都带上了用户和资源的信息:比发送求的用户、请求的路径资源 、请求的动作 get create delete等,授权就是根据文些信息和授权策路进行比较,如果符合策略,则认为授权通过,否则会返回错误。
API Server 目前支持以下几种授权策略:
AlwaysDeny:表示拒绝所有请求,一般用于测试AlwaysAllow:允许接收所有请求,相当于集群不需要授权流程 (k8s 默认的策略)ABA:基于属性的访问控制,表示使用用户配置的授权规则对用户请求进行匹配和控制Webhook:通过调用外部 REST 服务对用户进行授权Node:是一种专用模式,用于对 kubelet 发出的请求进行访问控制RBAC:基于角色的访问控制(kubeadm 安装方式下的默认选项)
RBAC(Role-Based Access Control)基于角色(Role-权限)的访问控制,主要是在描述一件事情: 给哪些对象授予了哪些权限
其中涉及到了下面几个概念:
资源:对集群中资源和非资源均拥有完整的覆盖对象:User、Groups, ServiceAccount角色:代表着一组定义在资源上的可操作动作(权限)的集合绑定:将定义好的角色跟用户绑定在一起, RBAC 引入了4个顶级资源对象 yaml kind类型。Role 、ClusterRole:角色,用于指定一组权限
一个角色就是一组权限的集合。apiGroups:支持的API组列表 ‘’apps", “autoscaling”, “batch”resources:支持的资源对象列表 “services”, “endpoints”, “pods” , “secrets” , “configmaps” , “crontabs”, “deployments”, “jobs”, “nodes”, “rolebindings”,“clusterroles”,“daemonsets”,“replicasets”,“statefulsets”,“horizontalpodautoscalers”,“replicationcontrollers”,“cronjobs”verbs:对资源对象的操作方法列表 “get”, “list”, “watch”, “create”, “update”, “patch”, “delete”, “exec” RoleBinding、ClusterRoleBinding:角色绑定,用于将角色 (权限) 赋予给对象
角色绑定用来把一个角色绑定到一个目标对象上,绑定目标可以是 User、Group 或者 ServiceAccount。RoleBinding 可以引用 ClusterRole,对属于同一命名空间内 ClusterRole 定义的资源主体进行授权。
准入控制
通过了前面的认证和授权之后,还需要经过准入控制处理通过之后,apiserver 才会处理这个请求。
准入控制机制是 k8s API Server 中一个非常强大的功能,它允许对进入 k8s 集群的请求做出控制。API Server 会在对象(如 Pod、Node、Service 等)被保存到 etcd 数据库之前,对该对象进行检查和修改。准入控制可用于实施强制性的数据验证、安全功能、自动化操作等功能。
一句话:就是在创建资源经过身份验证之后,kube-apiserver 在数据写入 etcd 之前做一次拦截,然后对资源进行更改、判断正确性等操作。
API Server 内置了许多准入控制器,常用的包含如下几种。
AlwaysAdmit:允许所有请求。AlwaysDeny:拒绝所有请求 ,仅应该用于测试。AlwaysPulllmages :总是下载镜像,即每次创建 Pod 对象之前都要去下载镜像,常用于多租户环境中以确保私有镜像仅能够被拥有权限的用户使用。NamespaceLifecycle :拒绝于不存在的名称空间中创建资源,而删除名称空间将会 级联删除其下的所有其他资源。LimitRanger :可用资源范围界定,用于监控对设置了 LimitRange 的对象所发出的 所有请求,以确保其资源、请求不会超限。ServiceAccount :用于实现 Service Account 管控机制的自动化,实现创建 Pod 对象 时自动为其附加相关的 Service Account 对象。PersistentVolumeLabel :为那些由云计算服务商提供的 PV 自动附加 region 或 zone 标签,以确保这些存储卷能够正确关联且仅能关联到所属的 region 或 zone。DefaultStorageClass :监控所有创建 PVC 对象的请求,以保证那些没有附加任何专 用 Storag巳Class 的请求会自动设定一个默认值。ResourceQuota : 用于对名称空间设置可用资源的上限,并确保在其中创建的任何设 置了资源限额的对象都不会超出名称空间的资源配额。DefaultTolerationSeconds :如果 Pod 对象上不存在污点宽容期限,则为它们设置默 认的宽容期,以宽容“ notready:N oExecute”和“ unreachable:N oExctute ”类的污点 5 分钟 时间。ValidatingAdmission Webhook :并行调用匹配当前请求的所有验证类的 Webhook, 任何一个校验失败,请求即失败。MutatingAdmissionWebhook :串行调用匹配当前请求的所有变异类的 Webhook, 每个调用都可能会更改对象。
一个很简单例子,例如我们要设置 Deployment 可以拥有的副本数量限制,那么可以定义如下所示的验证策略资源对象:
<code>apiVersion: admissionregistration.k8s.io/v1alpha1
kind: ValidatingAdmissionPolicy
metadata:
name: "demo-policy.example.com" # 策略对象
spec:
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
validations:
- expression: "object.spec.replicas <= 5"
该对象中的 expression 字段的值就是用于验证准入请求的 CEL 表达式,我们这里配置的 object.spec.replicas <= 5,就表示要验证对象的 spec.replicas 属性值是否大于 5,而 matchConstraints 属性则声明了该 ValidatingAdmissionPolicy 对象可以验证哪些类型的请求,我们这里是针对 Deployment 资源对象。
认证方案
kubeconfig:
kubeconfig 文件包含集群参数(CA证书、API Server地址),客户端参数,集群context信息(集群名称、用户名)。
ServiceAccount:
Pod 中的容器访问 API Server。因为 Pod 的创建和销毁是动态的,所以要为它手动生成证书是不可行的,k8s 使用 Service Account 解决 Pod 访问 API Server 的认证问题。
小结
API Server 是集群内部各个组件通讯的中介,也是外部控制的入口。k8s 使用认证(Authentication)、鉴权(Authorization)、准入控制(Admission Control)三步来确保 API Server 的安全。
认证和鉴权:
认证(authencation):通过只代表通讯双方是可信的鉴权(authorization):确定请求方有哪些资源权限
Service Count
UserAccount:给集群外用户访问 API Server,执行 kubectl 命令时用的就是该账号。它是全局性的,跨 namespace,通常为 admin,也可以自定义
<code>$ cat /root/.kube/config
users:
- name: kubernetes-admin
user:
ServiceAccount:Pod 容器访问 API Server 的身份认证。它与 namespace 绑定,每个 namespace(包含 default)都会自动创建一个默认的 SA。创建 Pod 时,如果未指定 SA, 则使用默认的 SA,可通过配置 spec.serviceAccount 指定 SA。
# default namespace SA
# kubectl get sa default -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2024-3-27T13:12:44Z"
name: default
namespace: default
resourceVersion: "368"
uid: e29de9ec-84ae-4e47-8778-dd8ed09e8f8d
SA 是一种特殊的 secret,类型为 kubernetes.io/service-account-token,它由三部分组成:
token:由 API Server 私钥签发的 JWT,Pod 访问 API Server 的凭证ca.crt:根证书,用于 Client 端验证 API Server 发送的证书,与 /etc/kubernetes/pki/ca.pem 一致namespace:该 service-account-token 的作用域名空间,Pod 所属 namespace
[root@k8s-master ~]# kubectl run -it nginx --image=nginx -- /bin/bash
If you don't see a command prompt, try pressing enter.
root@nginx:/# cd /run/secrets/kubernetes.io/serviceaccount/
root@nginx:/run/secrets/kubernetes.io/serviceaccount# ll
bash: ll: command not found
root@nginx:/run/secrets/kubernetes.io/serviceaccount# ls
ca.crtnamespace token
自定义SA
$ kubectl create ns my-ns
$ kubectl create sa my-sa -n my-ns
$ kubectl get sa -n my-ns
NAME SECRETS AGE
default 1 18s
my-sa 1 12s
$ kubectl get secret -n my-ns
NAME TYPE DATA AGE
default-token-xp4hg kubernetes.io/service-account-token 3 42s
my-sa-token-xs257 kubernetes.io/service-account-token 3 36s
资源属性
apiVersion: v1 # ServiceAccount所属的API群组及版本
kind: ServiceAccount # 资源类型标识
metadata:
name <string> # 资源名称
namespace <string> # ServiceAccount是名称空间级别的资源
automountServiceAccountToken <boolean> # 是否让Pod自动挂载API令牌
secrets <[]Object> # 以该SA运行的Pod所要使用的Secret对象组成的列表
apiVersion <string> # 引用的Secret对象所属的API群组及版本,可省略
kind <string> # 引用的资源的类型,这里是指Secret,可省略
name <string> # 引用的Secret对象的名称,通常仅给出该字段即可
namespace <string> # 引用的Secret对象所属的名称空间
uid <string> # 引用的Secret对象的标识符;
imagePullSecrets <[]Object> # 引用的用于下载Pod中容器镜像的Secret对象列表
name <string> # docker-registry类型的Secret资源的名称
Pod 中 SA 配置:
apiVersion: v1
kind: Pod
metadata:
name: nginx-sa
namespace: my-ns
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
serviceAccountName: my-sa # 指定 SA
RBAC
ServiceAccount 是 APIServer 的认证过程,而授权机制通过 RBAC:基于角色的访问控制实现(Role-based access control)
规则配置到角色上,用户就可以绑定角色获得对应的规则权限。
k8s 中所有资源对象都是模块化的 API 对象,允许执行 CRUD 操作:
资源:pods,configmaps,deployments,nodes,secrets,namespaces,services 等
动作:create,get,delete,list,update,edit,watch,exec,patch
Role 和 ClusterRole
Role:表示一组规则权限,权限只会增加(累加权限),它定义的规则,只适用于单个 namespace
ClusterRole:集群级别的权限控制
<code>apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: my-role
namespace: my-ns
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get","watch","list"]
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get","list","create","update","patch","delete","watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: my-clusterrole
rules:
- apiGroups: [""]
resources: ["services"]
verbs: ["get","create","list"]
系统默认的 ClusterRole: cluster-admin,具有所有资源的管理权限
$ kubectl get clusterrole cluster-admin -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: cluster-admin
rules:
- apiGroups:
- '*'
resources:
- '*'
verbs:
- '*'
- nonResourceURLs:
- '*'
verbs:
- '*'
Subject:
尝试访问和操作 API Server 的对象:
UserAccount:集群外的用户账号Group:用户组,集群中有一些默认创建的组,比如 cluster-adminServiceAccount:集群内的服务账号,它和 namespace 进行关联,适用于集群内部运行的应用程序,需要通过 API 来完成权限认证,所以在集群内部进行权限操作,我们都需要使用到 ServiceAccount
RoleBinding:将 Role 或 ClusterRole 授权给 Subject,它与 namespace 绑定
ClusterRoleBinding:将 ClusterRole 授权给 Subject,属于集群范围内的授权,与 namespace 无关
# 绑定 Role
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: my-rolebinding-1
namespace: my-ns
subjects:
- kind: User # 权限资源类型
name: kuangshen # 名称
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: my-role
apiGroup: rbac.authorization.k8s.io
# 绑定 ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: my-rolebinding-2
namespace: my-ns
subjects:
- kind: User
name: kuangshen
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: my-clusterrole
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-clusterrolebinding
subjects:
- kind: Group
name: developer
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: my-clusterrole
apiGroup: rbac.authorization.k8s.io
Helm 使用
Helm 是一个 k8s 应用的包管理工具,类似于 Ubuntu 的 APT 和 CentOS 中的 YUM。
Helm 使用 chart 来封装 k8s 应用的 yaml 文件,我们只需要设置自己的参数,就可以实现自动化的快速部署应用。
Helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 k8s 应用的部署和管理。
Helm 有一个跟 docker Hub 类似的应用中心(https://artifacthub.io/),我们可以在里面找到我们需要部署的应用。
helm 概述
Helm 是一个流行的 k8s 包管理工具,它用于简化在 k8s 上部署、管理和扩展应用程序的过程。Helm 允许用户定义可重复使用的 k8s 部署模板,称为 “charts”,并使用这些 charts 来创建、配置和管理 k8s 中的应用程序。
Helm 由两个核心组件组成:
Helm Client(helm):这是与用户交互的命令行工具。用户可以使用 Helm Client 来搜索、安装、升级和删除 charts,并管理 Helm Repositories(存储 charts 的位置)。
Tiller(已弃用):在 Helm 2.x 版本中,Tiller 是 Helm 的服务端组件,负责将 charts 渲染为 k8s 资源对象,并将它们部署到 k8s 集群中。然而,在 Helm 3.x 版本中,Tiller 已被移除,取而代之的是直接通过 Helm Client 与 k8s API 交互。
Helm 的主要优势在于它提供了模板化的部署方式,使得应用程序的部署过程更加可重复和可管理。通过使用 Helm,您可以轻松地创建自定义的 charts,并轻松地在不同的环境中部署和管理应用程序,从而提高了开发人员和运维人员的效率。
helm 优点
Helm 在 k8s 中具有许多优点,以下是其中一些主要优点:
简化部署和管理:Helm 允许用户将应用程序打包为可重复使用的 charts,简化了应用程序的部署和管理过程。通过使用 Helm,用户可以轻松地创建、安装、升级和删除应用程序,而无需手动处理底层的 k8s 资源对象。可重用的部署模板:Helm Charts 是可重用的部署模板,可以定义应用程序的整个部署配置,包括容器、服务、配置文件、存储卷等。这样,用户可以通过 Charts 快速创建和部署应用程序,减少了编写和维护大量 YAML 文件的工作量。版本控制和回滚:Helm 具备版本控制功能,可以管理不同版本的 Charts 和应用程序。这使得用户可以轻松地进行升级、回滚和管理应用程序的不同版本,提高了应用程序的可控性和可靠性。社区支持和生态系统:Helm 是一个开源项目,有一个活跃的社区支持和贡献。Helm 社区维护了一个官方的 Charts 仓库,其中包含了大量常用的应用程序 Charts,用户可以直接使用这些 Charts 来部署和管理应用程序。此外,还有许多第三方 Charts 仓库可供选择,扩展了 Helm 的功能和应用场景。可扩展性和灵活性:Helm 具有良好的扩展性和灵活性,用户可以根据自己的需求定制 Charts 和插件,以满足特定的部署和管理需求。用户可以根据需要配置应用程序的各种参数和选项,以适应不同的环境和场景。
总的来说,Helm 提供了简化和标准化 k8s 应用程序部署和管理的解决方案,使得用户能够更高效地进行应用程序的开发、部署和运维工作。
安装 helm
安装地址:https://helm.sh/zh/docs/intro/install/
# 国内下载不了
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
我们手动下载安装包
wget https://get.helm.sh/helm-v3.10.0-linux-amd64.tar.gz
[root@k8s-master home]# ll
total 14196
-rw-r--r-- 1 root root 14530566 Mar 27 04:05 helm-v3.10.0-linux-amd64.tar.gz
drwxr-xr-x 2 root root 4096 Mar 27 02:31 k8s
下载完成后,解压
# 解压压缩包
[root@k8s-master home]# tar -zxvf helm-v3.10.0-linux-amd64.tar.gz
linux-amd64/
linux-amd64/helm
linux-amd64/LICENSE
linux-amd64/README.md
[root@k8s-master home]# cd linux-amd64/
[root@k8s-master linux-amd64]# ll
total 43992
-rwxr-xr-x 1 3434 3434 45031424 Sep 22 2022 helm
-rw-r--r-- 1 3434 3434 11373 Sep 22 2022 LICENSE
-rw-r--r-- 1 3434 3434 3367 Sep 22 2022 README.md
# 在解压目中找到helm程序,移动到需要的目录中
[root@k8s-master linux-amd64]# mv helm /usr/local/bin
# 出现以下版本信息代表安装成功
[root@k8s-master linux-amd64]# helm version
version.BuildInfo{ Version:"v3.10.0", GitCommit:"ce66412a723e4d89555dc67217607c6579ffcb21", GitTreeState:"clean", GoVersion:"go1.18.6"}
添加一个稳定仓库
# 添加稳定仓库
[root@k8s-master linux-amd64]# helm repo add bitnami https://charts.bitnami.com/bitnami
"bitnami" has been added to your repositories
# 验证仓库是否添加完成
[root@k8s-master linux-amd64]# helm repo list
NAME URL
bitnamihttps://charts.bitnami.com/bitnami
三大概念
Chart 代表着 Helm 包。
它包含运行应用程序需要的所有资源定义和依赖,相当于模版。类似于 maven 中的 pom.xml、Apt中的 dpkb 或 Yum 中的 RPM。
Repository(仓库)用来存放和共享 charts。
不用的应用放在不同的仓库中。
Release 是运行 chart 的实例。
一个 chart 通常可以在同一个集群中安装多次。
每一次安装都会创建一个新的 release,release name 不能重复。
下载一个 mysql 来启动
helm 的仓库中心:https://artifacthub.io/,相当于 docker hub
进入这个页面搜索 mysql,里面有下载的命令以及配置参数的详细信息
下载命令:容器名为my-mysql
helm install my-mysql bitnami/mysql
参数:
--set:后面跟 key=value 的格式,用于配置使用容器的一些参数,key 在页面中有详细介绍--version:指定容器的 charts 的版本,默认是最新版
接下来我们下载一个 mysql 玩玩:
helm install my-mysql --set-string auth.rootPassword="123456" bitnami/mysqlcode>
[root@k8s-master linux-amd64]# helm install my-mysql --set-string auth.rootPassword="123456" bitnami/mysqlcode>
NAME: my-mysql
LAST DEPLOYED: Wed Mar 27 04:24:17 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: mysql
CHART VERSION: 10.1.0
APP VERSION: 8.0.36
# helm安装项目之后,它会帮我们生成一个详细的使用文档
** Please be patient while the chart is being deployed **
Tip:
Watch the deployment status using the command: kubectl get pods -w --namespace default
# 在k8s网络中如何访问该服务
Services:
echo Primary: my-mysql.default.svc.cluster.local:3306
Execute the following to get the administrator credentials:
echo Username: root
MYSQL_ROOT_PASSWORD=$(kubectl get secret --namespace default my-mysql -o jsonpath="{.data.mysql-root-password}" | base64 -d)code>
# 连接到数据库的方式
To connect to your database:
1. Run a pod that you can use as a client:
kubectl run my-mysql-client --rm --tty -i --restart='Never' --image docker.io/bitnami/mysql:8.0.36-debian-12-r8 --namespace default --env MYSQL_ROOT_PASSWORD=$MYSQL_ROOT_PASSWORD --command -- bashcode>
2. To connect to primary service (read/write):
mysql -h my-mysql.default.svc.cluster.local -uroot -p"$MYSQL_ROOT_PASSWORD"
WARNING: There are "resources" sections in the chart not set. Using "resourcesPreset" is not recommended for production. For production installations, please set the following values according to your workload needs:
- primary.resources
- secondary.resources
+info https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
它的本质是在我们的 k8s 集群上启动了一个 pod
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-mysql-1 1/1 Running 0 3m14s # stafulset类型的,可以部署有状态应用。
# **Release** 是运行 chart 的实例。
[root@k8s-master ~]# helm ls
NAME NAMESPACEREVISIONUPDATED STATUS CHART APP
my-mysqldefault 1 2024-3-27 13:38:53.228239944 +0800 CSTdeployedmysql-10.1.08.0.36
探究 helm
[root@k8s-master k8s]# helm create hello-world
Creating hello-world
[root@k8s-master k8s]# cd hello-world/
[root@k8s-master hello-world]# ll
total 16
drwxr-xr-x 2 root root 4096 Mar 27 04:44 charts# 当前我们创建的这个charts是否依赖与其他的charts,如果有就在这里面
-rw-r--r-- 1 root root 1147 Mar 27 04:44 Chart.yaml# charts信息
drwxr-xr-x 3 root root 4096 Mar 27 04:44 templates# k8s 资源文件, 模版 { { 插值 }}
-rw-r--r-- 1 root root 1878 Mar 27 04:44 values.yaml# 具体的值
[root@k8s-master hello-world]# cd templates/
[root@k8s-master templates]# ll
total 32
-rw-r--r-- 1 root root 1856 Mar 27 04:44 deployment.yaml
-rw-r--r-- 1 root root 1822 Mar 27 04:44 _helpers.tpl
-rw-r--r-- 1 root root 928 Mar 27 04:44 hpa.yaml
-rw-r--r-- 1 root root 2087 Mar 27 04:44 ingress.yaml
-rw-r--r-- 1 root root 1763 Mar 27 04:44 NOTES.txt
-rw-r--r-- 1 root root 328 Mar 27 04:44 serviceaccount.yaml
-rw-r--r-- 1 root root 373 Mar 27 04:44 service.yaml
drwxr-xr-x 2 root root 4096 Mar 27 04:44 tests
本质里面就是一堆 k8s 的资源文件,helm 启动这个 charts,相当于帮我们执行了 apply -f
我们可以检测这个 chart 是否有问题
helm lint charts目录
# 检测 charts 包是否有问题
[root@k8s-master ~]# helm lint ./hello-world/
==> Linting ./hello-world/
[INFO] Chart.yaml: icon is recommended
1 chart(s) linted, 0 chart(s) failed
这样就是没有问题
将 Helm Charts 渲染为 k8s 资源对象的 yaml 文件,而不进行实际的部署操作
helm template charts包名
这个命令非常有用,可以方便地查看 Charts 的最终生成结果
[root@k8s-master k8s]# helm template hello-world/
---
# Source: hello-world/templates/serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: release-name-hello-world
labels:
helm.sh/chart: hello-world-0.1.0
app.kubernetes.io/name: hello-world
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
---
# Source: hello-world/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: release-name-hello-world
labels:
helm.sh/chart: hello-world-0.1.0
app.kubernetes.io/name: hello-world
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
spec:
type: ClusterIP
ports:
- port: 80
targetPort: http
protocol: TCP
name: http
selector:
app.kubernetes.io/name: hello-world
app.kubernetes.io/instance: release-name
---
# Source: hello-world/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: release-name-hello-world
labels:
helm.sh/chart: hello-world-0.1.0
app.kubernetes.io/name: hello-world
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: hello-world
app.kubernetes.io/instance: release-name
template:
metadata:
labels:
app.kubernetes.io/name: hello-world
app.kubernetes.io/instance: release-name
spec:
serviceAccountName: release-name-hello-world
securityContext:
{ }
containers:
- name: hello-world
securityContext:
{ }
image: "nginx:1.16.0"
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
resources:
{ }
---
# Source: hello-world/templates/tests/test-connection.yaml
apiVersion: v1
kind: Pod
metadata:
name: "release-name-hello-world-test-connection"
labels:
helm.sh/chart: hello-world-0.1.0
app.kubernetes.io/name: hello-world
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
annotations:
"helm.sh/hook": test
spec:
containers:
- name: wget
image: busybox
command: ['wget']
args: ['release-name-hello-world:80']
restartPolicy: Never
安装
[root@k8s-master k8s]# helm install helloworld hello-world/
NAME: helloworld
LAST DEPLOYED: Wed Mar 27 04:56:06 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=hello-world,app.kubernetes.io/instance=helloworld" -o jsonpath="{.items[0].metadata.name}")code>
export CONTAINER_PORT=$(kubectl get pod --namespace default $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")code>
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORT
可以直接通过仓库找到 charts 来安装!
也可以自己编写 charts 包来安装!git 下载 charts
helm 部署 mysql 主从复制集群
https://artifacthub.io/packages/helm/bitnami/mysql
安装过程中有两种方式传递配置数据:
-f (或--values):使用 yaml 文件覆盖默认配置。可以指定多次,优先使用最右边的文件。--set:通过命令行的方式对指定项进行覆盖。
auth:
rootPassword: "123456"
primary:
persistence:
size: 2Gi
enabled: true
secondary:
replicaCount: 2
persistence:
size: 2Gi
enabled: true
architecture: replication
如果同时使用两种方式,则 --set中的值会被合并到 -f中,但是 --set中的值优先级更高。
主从复制原理:
通过部署无头服务(Headless Service)将写操作指向固定的数据库。
部署一个 Service 用来做读操作的负载均衡。
数据库之间通过同步程序保持数据一致。
初始化容器(Init Containers)
初始化容器(Init Containers)是一种特殊容器,它在 Pod 内的应用容器启动之前运行。
初始化容器未执行完毕或以错误状态退出,Pod 内的应用容器不会启动。
初始化容器需要在 <code>initContainers 中定义,与 containers 同级。
基于上面的特性,初始化容器通常用于
生成配置文件执行初始化命令或脚本执行健康检查(检查依赖的服务是否处于 Ready 或健康 Health 的状态)
这里有两个初始化容器。
init-mysql为 MySQL 实例分配server-id,并将mysql-0的配置文件设置为primary.cnf,其他副本设置为replica.cnfclone-mysql从前一个Pod中获取备份的数据文件放到自己的数据目录下
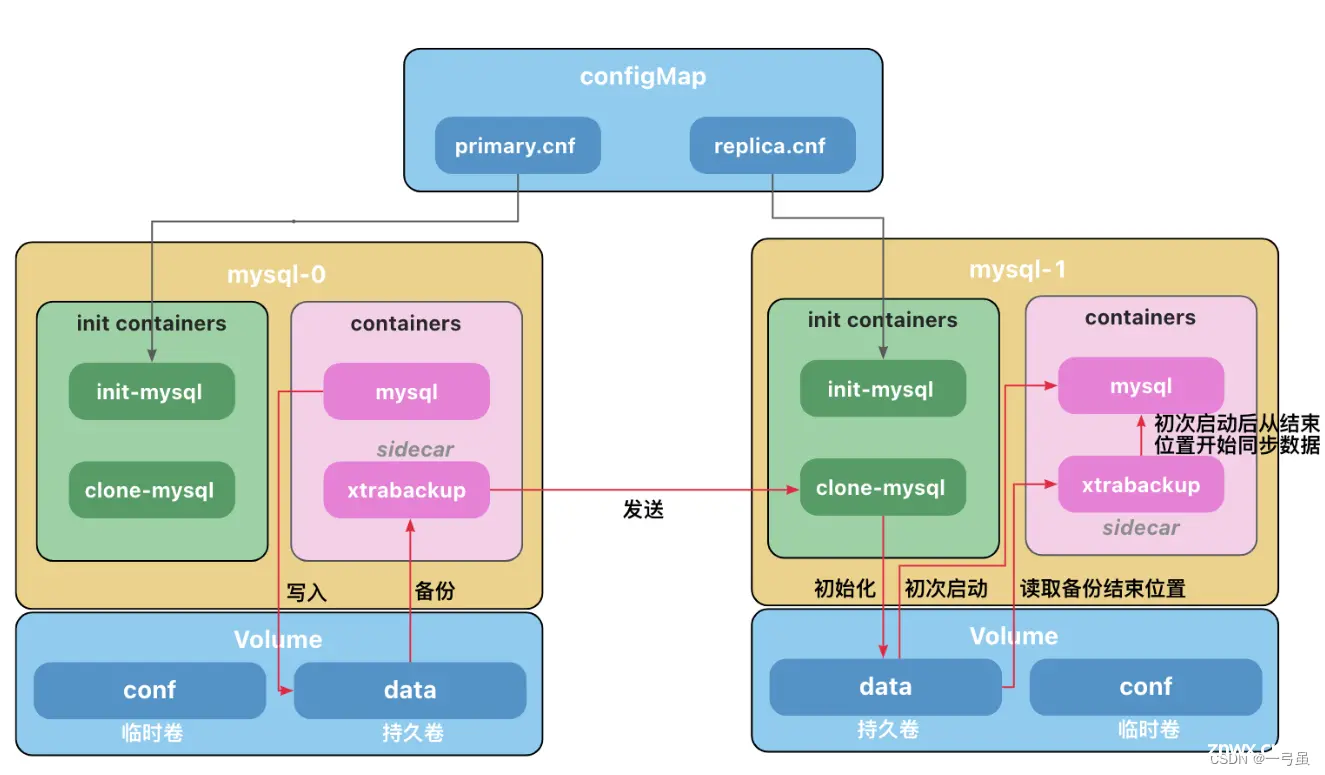
边车 Sidecar
Pod 中运行了2个容器,MySQL 容器和一个充当辅助工具的 xtrabackup 容器,我们称之为边车(sidecar)。
Xtrabackup 是一个开源的 MySQL 备份工具,支持在线热备份(备份时不影响数据读写),是目前各个云厂商普遍使用的 MySQL 备份工具。

<code>sidecar容器负责将备份的数据文件发送给下一个Pod,并在副本服务器初次启动时,使用数据文件完成数据的导入。
MySQL 使用bin-log同步数据,但是,当数据库运行一段时间后,产生了一些数据,这时候如果我们进行扩容,创建了一个新的副本,有可能追溯不到bin-log的源头(可能被手动清理或者过期自动删除),因此需要将现有的数据导入到副本之后,再开启数据同步,sidecar只负责数据库初次启动时完成历史数据导入,后续的数据 MySQL 会自动同步。
补充:端口转发,临时暴露服务
[root@k8s-master ~]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/my-db-mysql-primary-0 1/1 Running 0 15m
pod/my-db-mysql-secondary-0 1/1 Running 0 15m
pod/my-db-mysql-secondary-1 1/1 Running 0 13m
pod/nginx 1/1 Running 1 (<invalid> ago) 91m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d17h
service/my-db-mysql-primary ClusterIP 10.96.140.100 <none> 3306/TCP 15m
service/my-db-mysql-primary-headless ClusterIP None <none> 3306/TCP 15m
service/my-db-mysql-secondary ClusterIP 10.96.64.24 <none> 3306/TCP 15m
service/my-db-mysql-secondary-headless ClusterIP None <none> 3306/TCP 15m
NAME READY AGE
statefulset.apps/my-db-mysql-primary 1/1 15m
statefulset.apps/my-db-mysql-secondary 2/2 15m
[root@k8s-master ~]# kubectl port-forward pods/my-db-mysql-primary-0 --address=192.168.0.111 33060:3306
Forwarding from 192.168.0.111:33060 -> 3306
Handling connection for 33060
Handling connection for 33060
这个命令是前台命令,退出后,端口转发就失效了。常用来做测试。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。