Linux之进程概念
二进制掌控者 2024-10-04 08:07:04 阅读 69
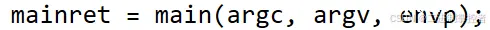
作者主页: 作者主页
本篇博客专栏:Linux专栏
创作时间 :2024年9月28日

基本概念:
进程说白了其实就是一个程序的执行实例,正在执行的程序。
在内核层面来说,就是一个担当分配资源(CPU时间,内存)的实体
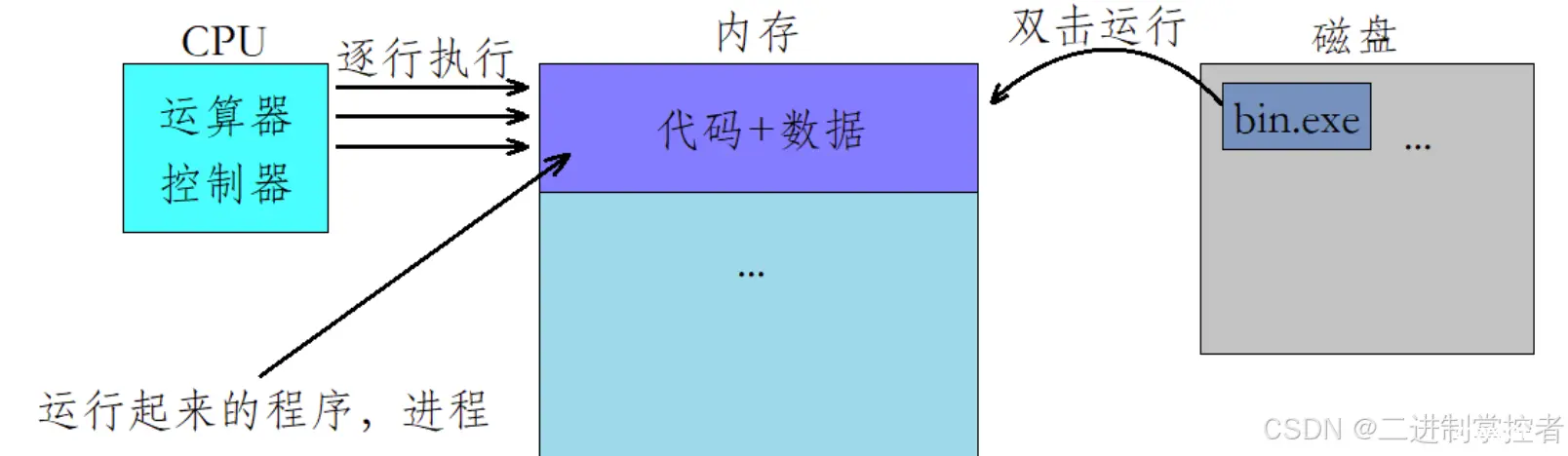
写过代码的都知道,当你的代码进行编译链接之后就会形成一个可执行的程序了,这个程序本质上是一个文件,是放在磁盘上的。当我们双击这个程序让他运行起来之后,本质上是让这个程序加载到内存当中去了,因为只有加载到内存当中去CPU才能对他进行逐语句执行,而一旦将这个程序加载到内存之后,我们就不应该叫他程序了,严格意义上应该称他为进程。

描述进程-PCB
系统中可以同时存在大量的进程,当我们使用ps aux命令时便可以看见此时存在的所有进程
当我们电脑开机时,打开的第一个程序其实就是操作系统(即操作系统是第一个加载到系统中的),我们都知道操作系统是管理工作的,其中一个就是进程管理,那么我们电脑上这么多的进程,操作系统是如何进行管理的呢?
这时我想首先告诉大家一个六字真言:就是先描述,再组织,操作系统管理也是如此,操作系统作为管理者是不需要直接和被管理者进行沟通的,当一个进程出现时,操作系统会直接对其进行描述,然后对他的管理其实就是对其描述信息的管理,进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合,这个就是PCB。
操作系统将每一个进程进行描述,形成一个个的进程控制块(PCB),并且通过双链表的形式将他们连接起来。
这样,操作系统只要拿到这个双链表的头指针就可以对这个双链表进行管理,这样操作系统对各个进程的管理就变成了对双链表的管理。
例如我们创建一个进程时首先就是将改进程的代码和数据加载到内存,然后操作系统对此进程进行描述形成对应的进程控制块(PCB),并将这个PCB插入到双链表中,想要退出这个进程时就直接从双链表当中删去这个节点(PCB)即可。这样一来,操作系统对于进程的管理就变成了对一个双链表的增删查改。
task_struct --PCB的一种
进程控制块(PCB)是描述进程的,再c++中我们称之为面向对象,而在c语言当中我们称之为结构体,因为Linux是用C语言写的,当然PCB也是用c语言写的了,也就是用结构体来实现的。
PCB实际上是对进程控制块的统称,在Linux中描述进程的结构体叫做task_structtask_struct是Linux中的一种数据结构,他会被装载到RAM(内存)里并包含进程的信息
task_struct 内容分类
task_struct 就是Linux中的进程控制块,它包含着以下的一些信息。
标识符:描述本进程的唯一标识符,用来区别其他标识符状态:任务状态,退出代码,推出信号等优先级:相对于其他进程的优先级程序计数器:程序中即将被执行的下一条指令的地址内存地址:包含程序代码和进程相关的指针,还有和其他进程共享的内存块中的指针上下文数据:进程执行时处理器的寄存器中的数据I/O状态信息:包含显示的I/O请求等记账信息:可能包含处理器时间的总和等其他信息
查看进程
通过系统目录来查看信息:
在根目录下有一个名为proc的系统文件夹,其中包含了大量进程信息,其中一些子目录的名字为数字

这些数字其实是一某一进程的PID,对应的文件夹中记录中对应进程的各种信息,想要查看直接输入ls /proc/对应的数字 即可
通过ps命令查看:
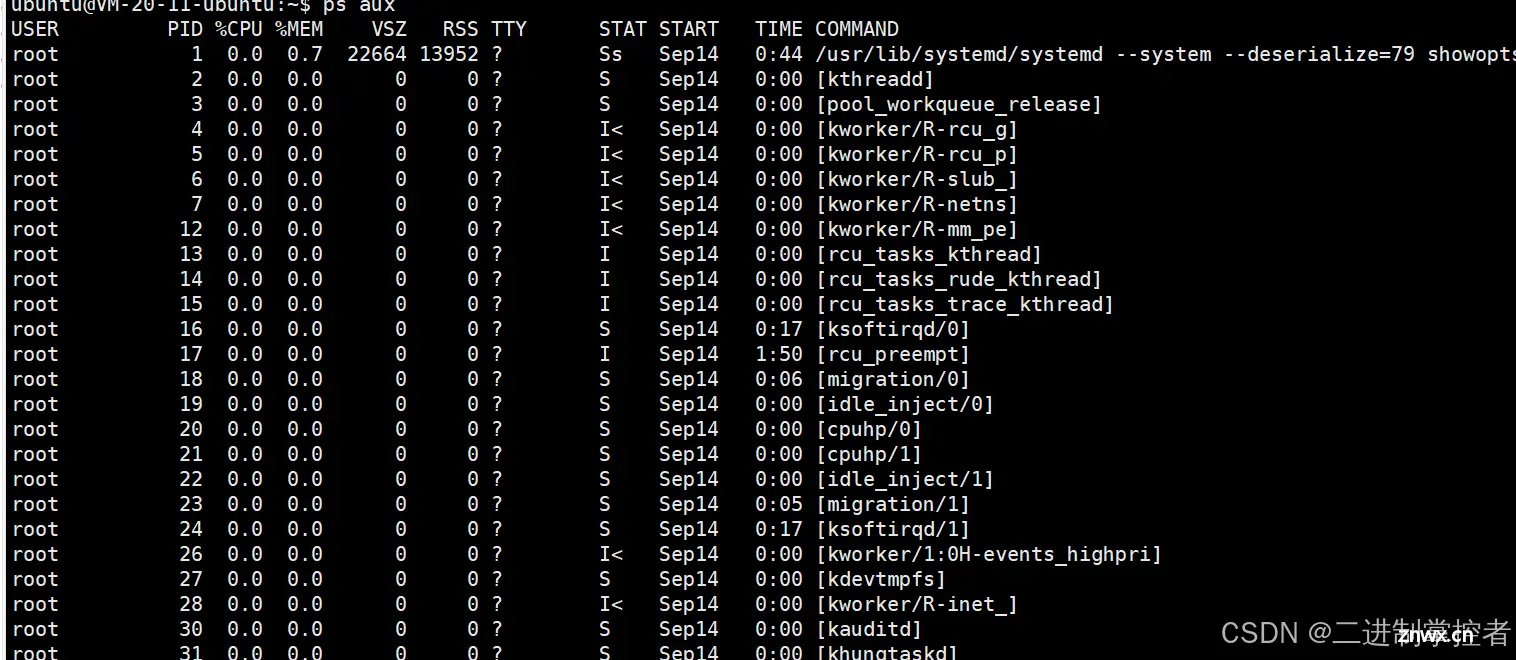
ps与对应的指令想叠加,便可以显示对应的进程的信息
<code> ps aux | head -1 && ps aux | grep proc | grep -v grep
通过系统调用获得对应的进程的PID和PPID
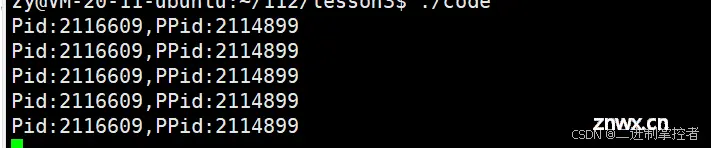
通过系统调用函数,getpid和getppid两个函数分别可以获得对应进程的PID和PPID

当我们执行该程序之后,这个程序会不停的执行下去
我们通过ps命令得到对应进程的PID和PPID,就可以发现和getpid与getppid得到的值是一模一样的
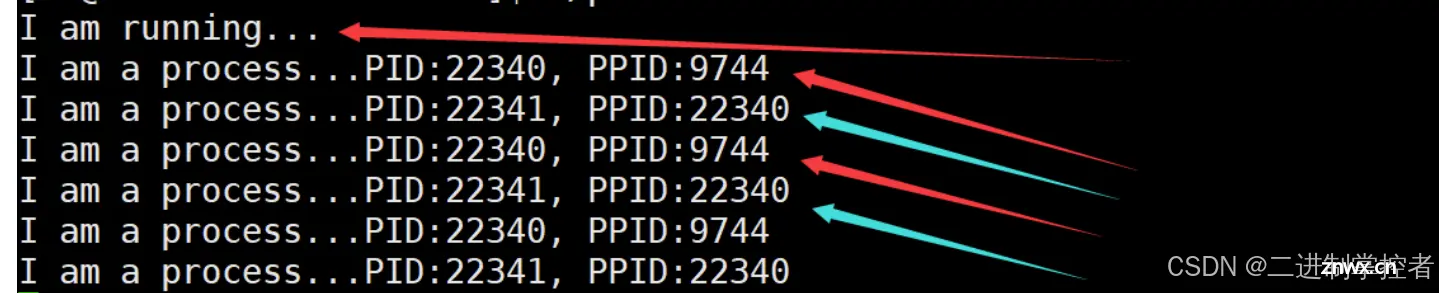
通过系统调用创建进程-fork初始
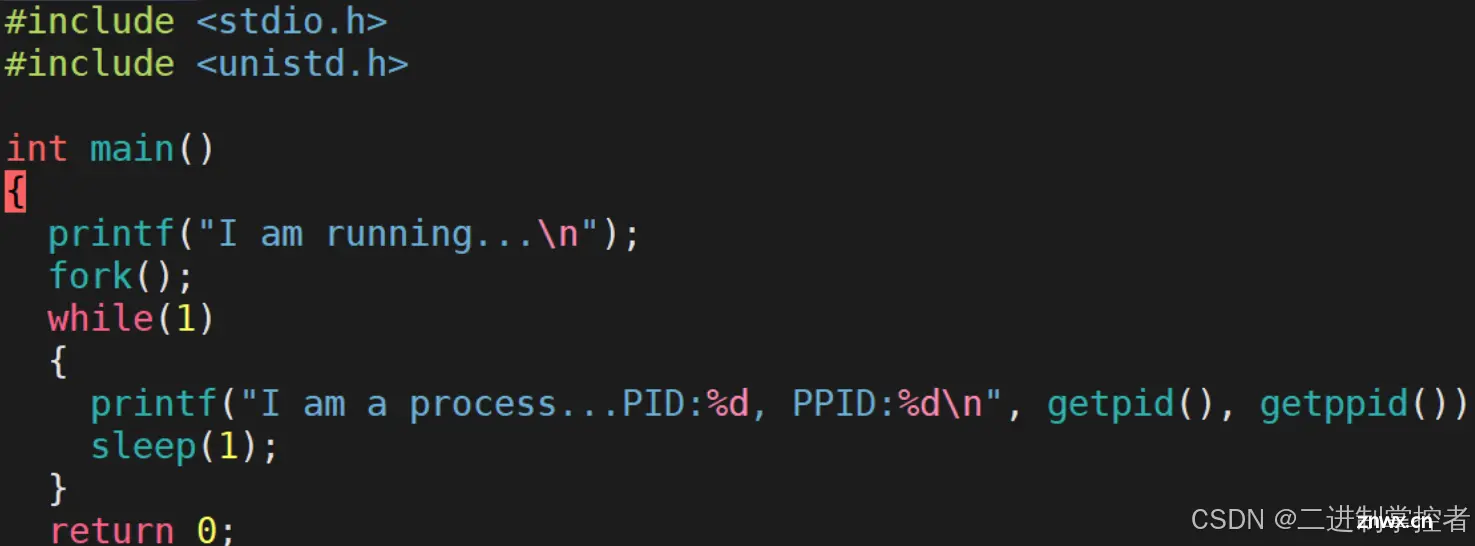
fork函数创建子程序

加入fork函数之后,运行结果如下:
循环打印两行数据,这两行数据分别为:第一行是该进程的PID和PPID,第二行是fork创建的子进程的PID和PPID,我们可以发现fork创建的子进程的PPID是子进程的PID,说明这两个进程的关系为父子关系。
同样,操作系统也会为这个新建的进程创建PCB。
我们知道加载到内存中的数据和代码是属于父进程的,那么子进程的数据和代码又是从哪里来的呢?

我们可以看到,fork之前的代码是父进程自己执行的,之后的代码是父子进程都执行
需要注意的是,虽然父子进程共享代码了,但是其实是各自开辟空间(采用写时拷贝);
小贴士:使用fork函数创建子进程后就有了两个进程,这两个进程的调度顺序是不确定的,取决于操作系统调度算法具体的实现。
fork返回值:
1.如果fork函数创建子进程成功,那么在父进程中返回父进程的pid,子进程的返回0
2.如果创建失败,那么父进程的返回-1.
Linux运行状态:
一个进程都创建而产生到因撤销而销毁的整个生命期间,有时占有处理器执行,有时虽然可以运行但是分不到处理器。有时虽然有空闲处理器但是由于待某个时间的发生而无法执行,这一切就说明进程和程序有区别,进程是活动的且状态变化的,所以叫做进程
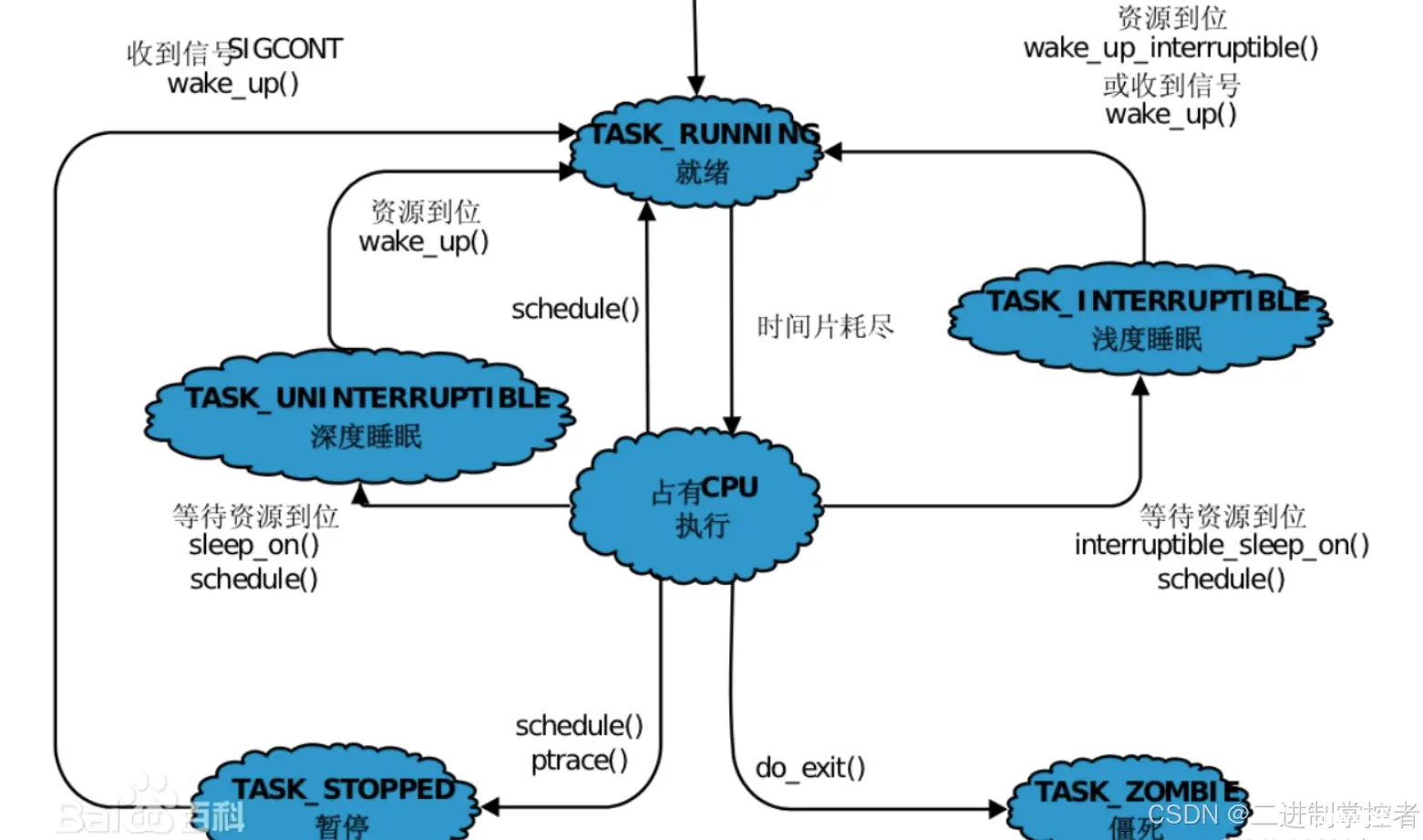
这里我们具体谈一下进程中的一些状态:
Linux源代码中对于一些状态的定义:
<code>/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char *task_state_array[] = {
"R (running)", /* 0*/
"S (sleeping)", /* 1*/
"D (disk sleep)", /* 2*/
"T (stopped)", /* 4*/
"T (tracing stop)", /* 8*/
"Z (zombie)", /* 16*/
"X (dead)" /* 32*/
};
运行状态——R
一个程序处于运行状态,并不一定一定处于运行当中,一个进程处于R状态,表示处于运行当中或者处于运行队列(runqueue)当中,所有会存在多个进程同时处于R状态。
浅睡眠状态——S
一个进程处于浅睡眠状态,也叫可中断睡眠状态,意味着等待某件事情的完成,处于浅睡眠状态的进程随时可以被唤醒,也可以随时被杀掉
当我们在一个进程中加入sleep(100),意思就是在这里休息一百秒,此时编译运行之后就会出现浅睡眠状态。
深睡眠状态——D
一个进程处于深度睡眠状态,表示这个进程不可以被杀掉,即便是操作系统也是不可以的,只有这个进程自动唤醒才可以恢复,该进程也被称为不可中睡眠状态。
例如:某一进程对磁盘进行写入操作时,再写入期间,就会处于D状态,是无法被杀掉的,因为该进程必须磁盘回复是否写入成功,以做出相应的回应
暂停状态——T
在Linux中,我们可以通过向进程发送SIGSTOP信号使进程进入暂停状态(T),发送SIGCONT可以让处于暂停状态的进程继续运行。
僵尸状态——Z
当一个进程将要退出的时候,在系统层面,这个系统曾经申请的资源并不会被马上释放,而是暂时存储一段时间,以供操作系统或者其父进程进行读取,如果信息一直未被读取,则相关数据会一直存在,不会被释放掉的,如果一个进程等待着数据被读取,那么我们就说他正处在僵尸状态。
僵尸状态时应该存在的,因为我们调用一个程序时,调用方是应该知道这个完成情况的,所以僵尸状态必须是要存在的,以便后续的相关操作。
例如我们在编写程序时都会在最后写一个return 0,它的作用就是告诉操作系统这个程序顺利完成结束了。
在Linux中,我们可以通过echo $命令来获取最近的一次进程的退出码
死亡状态——X
死亡状态只是一个返回状态,当一个进程的信息被退出之后,该进程申请的资源会立即被释放,所以你不会在进程状态中看到死亡状态。
僵尸进程
前面我们已经说过僵尸状态的概念,相信大家也有了一个大致的了解,而处于僵尸状态的进程,就被称为僵尸进程。
例如,对于下面的代码,当程序执行五次之后,子进程便会退出,但是父进程不知道它退出了,那么此时子进程就处于僵尸状态。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("I am running...\n");
pid_t id = fork();
if(id == 0){ //child
int count = 5;
while(count){
printf("I am child...PID:%d, PPID:%d, count:%d\n", getpid(), getppid(), count);
sleep(1);
count--;
}
printf("child quit...\n");
exit(1);
}
else if(id > 0){ //father
while(1){
printf("I am father...PID:%d, PPID:%d\n", getpid(), getppid());
sleep(1);
}
}
else{ //fork error
}
return 0;
}
运行该代码之后,我们可以通过下面这个简单的脚本进行监控
while :; do ps axj | head -1 && ps axj | grep proc | grep -v grep;echo "######################";sleep 1;done
运行之后我们发现:当子进程退出之后,子进程就会编程僵尸状态。
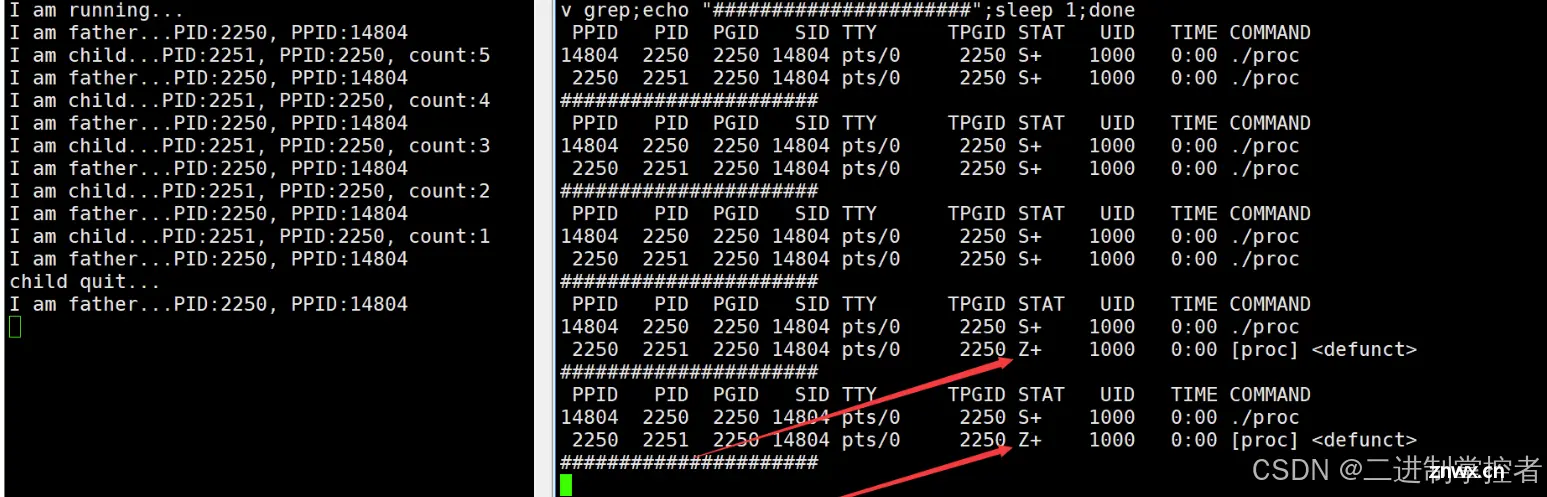
僵尸进程的危害:
僵尸进程的退出状态会一直维持下去,因为它需要告诉父进程执行的相应的结果信息。但是父进程一直在不停的执行,所以子进程就一直处于僵尸状态僵尸进程的信息会一直存在与task_struct(PCB)中,所以PCB就需要一直去维护若一个父进程创建了多个子进程,并且不对其进行回收,那么就会造成资源浪费,因为数据结构对象本身就要占据内存僵尸进程越来越多,申请的资源无法进行回收,那么僵尸进程越多,实际可用的资源就越少,也就是说僵尸进程会造成内存泄漏
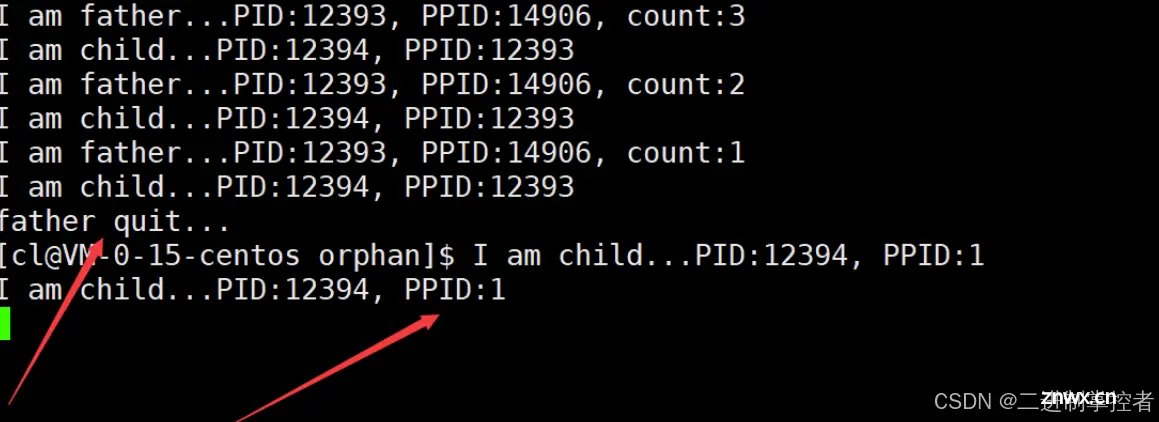
孤儿进程:
孤儿进程是指在操作系统中,其父进程已经结束(正常或异常终止),但该进程本身还在继续运行的进程。当一个进程创建子进程后,如果父进程在子进程结束之前就已经退出,那么子进程就会成为孤儿进程。例如,一个父进程启动了一个子进程,之后父进程由于某种原因(如完成了它的任务或者遇到了错误而终止)退出,此时子进程就变成了孤儿进程。
对于以下代码,父进程执行五次后退出,子进程就变成了孤儿进程:
<code>#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("I am running...\n");
pid_t id = fork();
if(id == 0){ //child
int count = 5;
while(1){
printf("I am child...PID:%d, PPID:%d\n", getpid(), getppid(), count);
sleep(1);
}
}
else if(id > 0){ //father
int count = 5;
while(count){
printf("I am father...PID:%d, PPID:%d, count:%d\n", getpid(), getppid(), count);
sleep(1);
count--;
}
printf("father quit...\n");
exit(0);
}
else{ //fork error
}
return 0;
}
观察代码运行,会发现父进程退出后,子进程的PPID变成了1,这就说明他被一号进程领养了
进程优先级:
基本概念:
什么是进程优先级?优先级实际上就是进程获取某些资源的先后顺序,而进程优先级实际上就是进程获取CPU资源分配的先后顺序,就是指进程的优先权,优先权高的进程具有优先执行的权力
为什么要有进程优先级?
进程优先级存在的主要原因就是我们的资源是有限的,就像我们的电脑,一般都是单CPU的,一个CPU一次只能执行一个进程,而进程有多个,所以需要存在进程优先级,确定获取CPU资源的先后顺序。
查看系统进程
在Linux中输入ps -l可以看到以下的东西:

我列出其中重要的几个信息:
UID:代表着执行者的身份PID:代表这个进程的代号PPID:代表着这个进程由哪一个进程发展而来,即父进程的代号PRI:代表这个进程的可被执行的优先级,值越小越早被执行NI:代表着这个进程的nice值
PRI和NI
PRI代表着进程的优先级,这个值越小进程的优先级越高NI代表着nice值,其表示进程可被执行的优先级的修正数值PRI(new)=PRI(old)+NI;若NI值为负值,那么PRI变小,优先级变高调整进程的优先级,在Linux下就是调整NI,即nice值NI的范围是-20-19,也就是说进程优先级一共分为四十个级别
注意:在Linux系统中,PRI默认的值是80,也就是PRI=80+NI。
当我们创建一个进程之后,我们可以通过ps -al查看进程的优先级。
通过top命令修改进程优先级
这里的top命令其实就相当于Windows中的任务管理器,可以调整进程优先级。
使用top命令后按r,然后输入要调整的进程的PID,然后调整后的nice值即可
注意:要想将nice调整为负值,需要加上sudo提升权限
通过renice调整进程优先级
输入 renice +更改后的nice +PID即可
四个重要概念:
竞争性:由于只有一个CPU,所以资源有限,会出现资源竞争,为了高效完成任务,合理分配CPU资源,所以会出现进程优先级
独立性:多进程之间运行需要独享各种资源,运行期间互不打扰
并发:即多个进程在一个进程下采用进程切换的方式,在一段时间段内,让多个进程都得以共同推进,称之为并发
并行:多个进程在多个CPU下同时进行
环境变量:
基本概念
环境变量一般是指在操作系统中指定操作系统运行环境的一些参数
常见环境变量
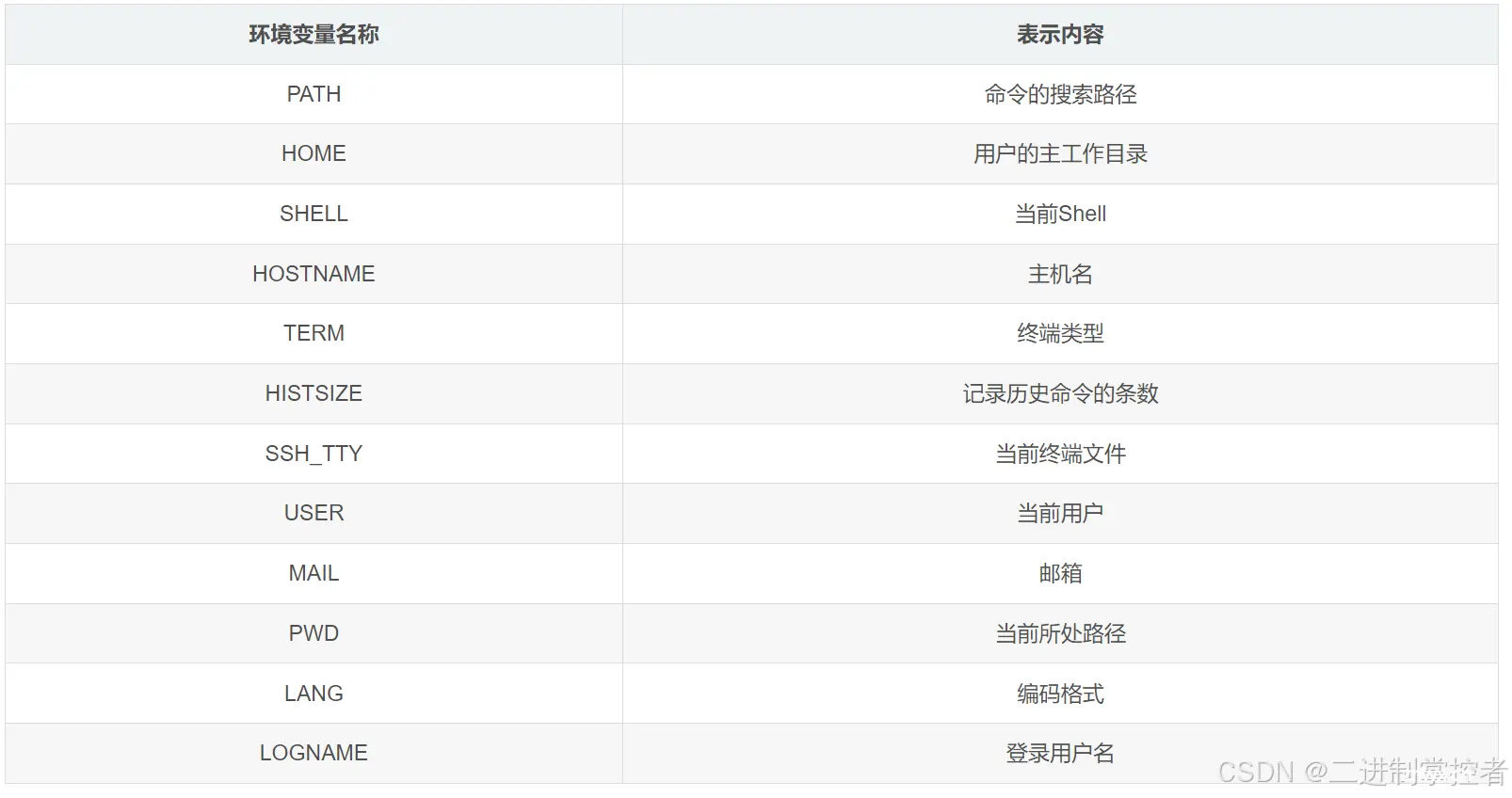
PATH:指定命令的搜索路径HOME:指定用户的主工作目录SHELL:当前shell,他的值一般是/bin/bash
查看当前环境变量的方法
使用echo来查看:
echo $NAME //NAME为待查看的环境的名称
测试PATH
大家有没有想过这样一个问题:为什么执行ls命令时不用带./,而在执行我们自己的可执行程序时就必须要带上?
容易理解的是,我们在执行一个程序的时候,必须要先找到他在哪里,既然不带ls就可以执行ls,说明操作系统可以找到他,而系统找不到我们的可执行程序,必须带上./来说明他在我们的当前目录下。
而系统就是通过环境变量PATH来找到ls的,查看环境变量PATH,可以看到下面内容:
可以看到很多路径,这些路径通过冒号隔开,然后执行ls命令时,系统会从左到右开始寻找ls命令
而ls命令确实存在与这些路径中的某个路径下面。
那我们可不可以让自己的可执行程序不带./就执行呢
两个方法:
一个就是在系统默认的路径下创建这个程序,然后生成可执行程序或者将这个可执行程序拷贝到PATH的某一个路径下面将可执行程序所在的路径导入到PATH这个路径下面
部分环境变量说明:
set:显示本地定义的shell变量和环境变量
unset:清楚环境变量
通过代码来获取环境变量:
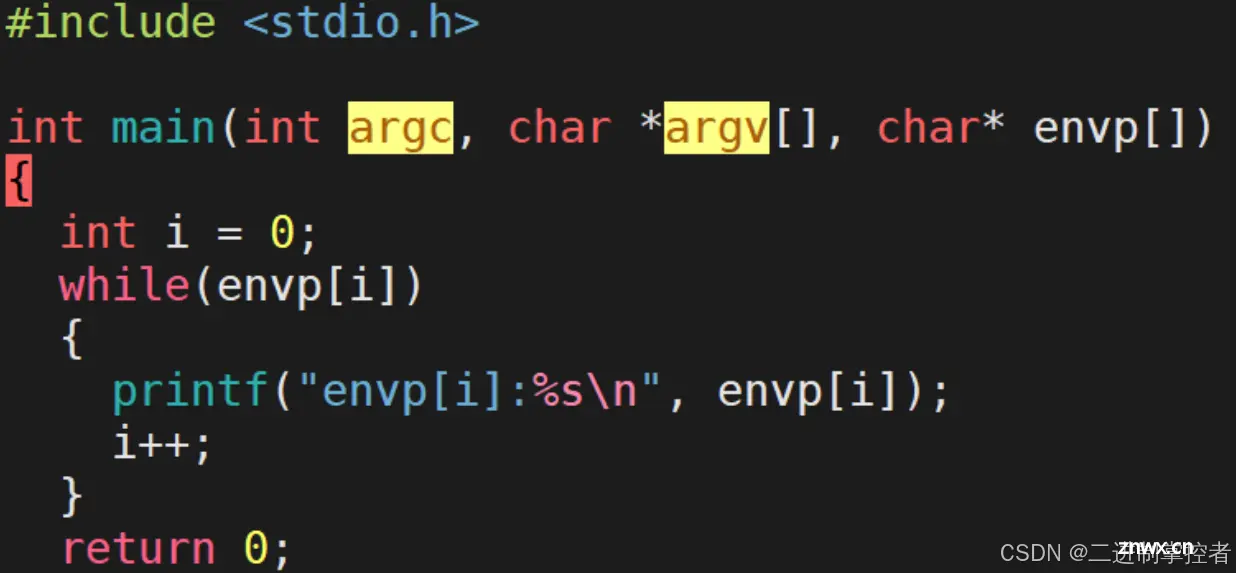
你知道main函数其实是由参数的嘛?
我们平常情况不会使用他,所以基本不会写出来。
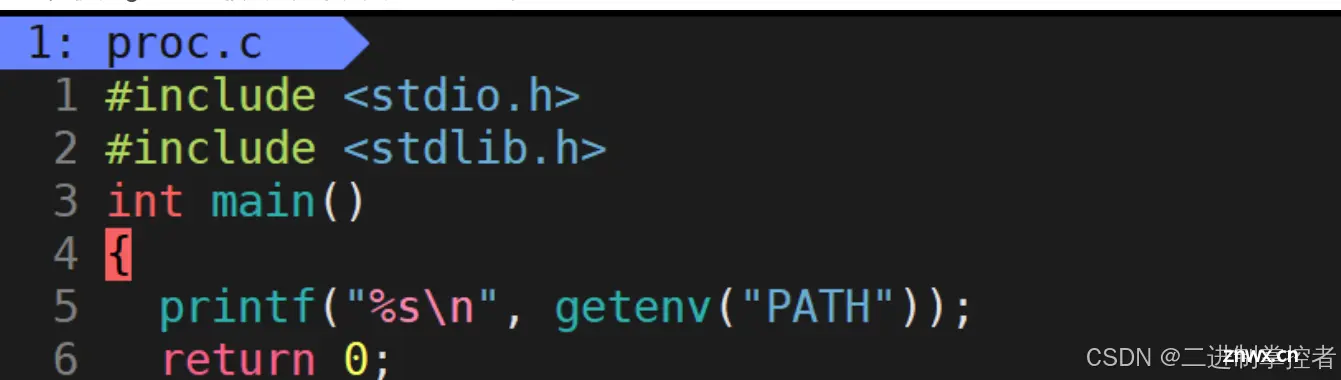
在这里我们可以看到,调用main函数时向其传递了三个参数。
我们先来说说前两个参数
我们在Linux下写下这个程序并运行:
<code>
#include <stdio.h>
int main(int argc,char *argv[])
{
for(int i=0;i<argc;i++)
{
printf("argv[%d]:%s\n",i,argv[i]);
}
return 0;
}
执行结果如下:
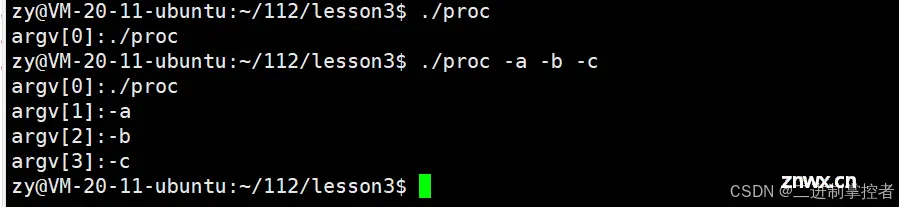
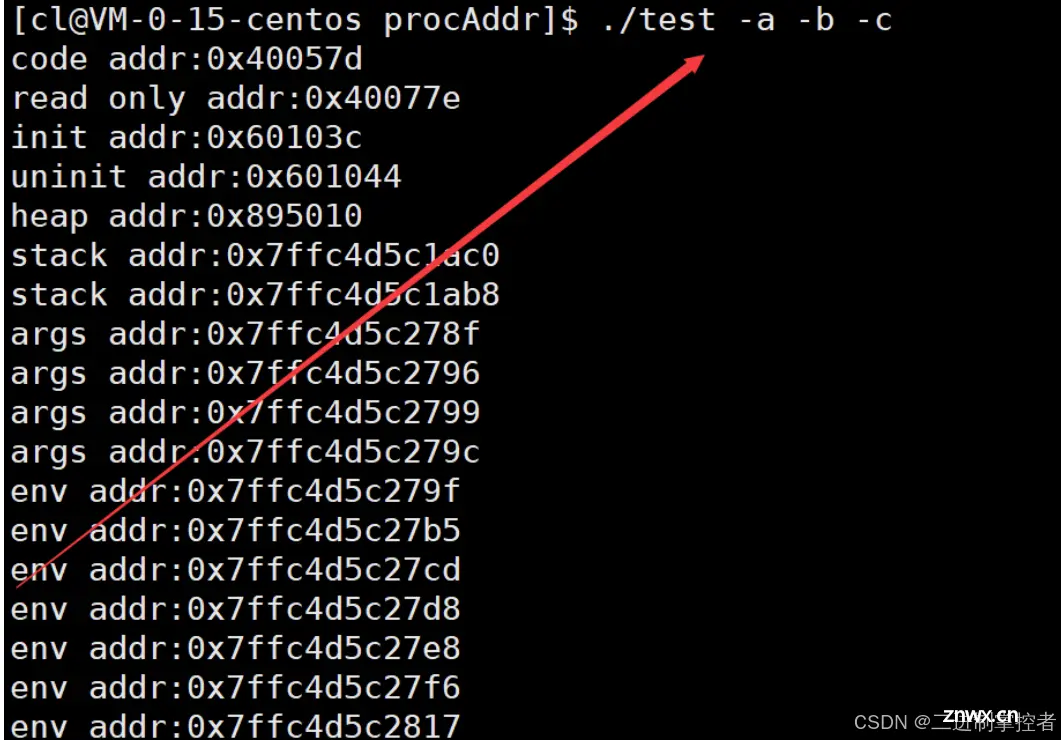
现在我们来说说main函数中的前两个参数,其中的第二个参数是一个字符指针数组,数组中第一个字符指针存储的是可执行程序的位置,其余字符指针存储的是所给的若干选项。最后一个指针为空,而前面那个第一个参数就代表着字符指针数组中有效元素的个数

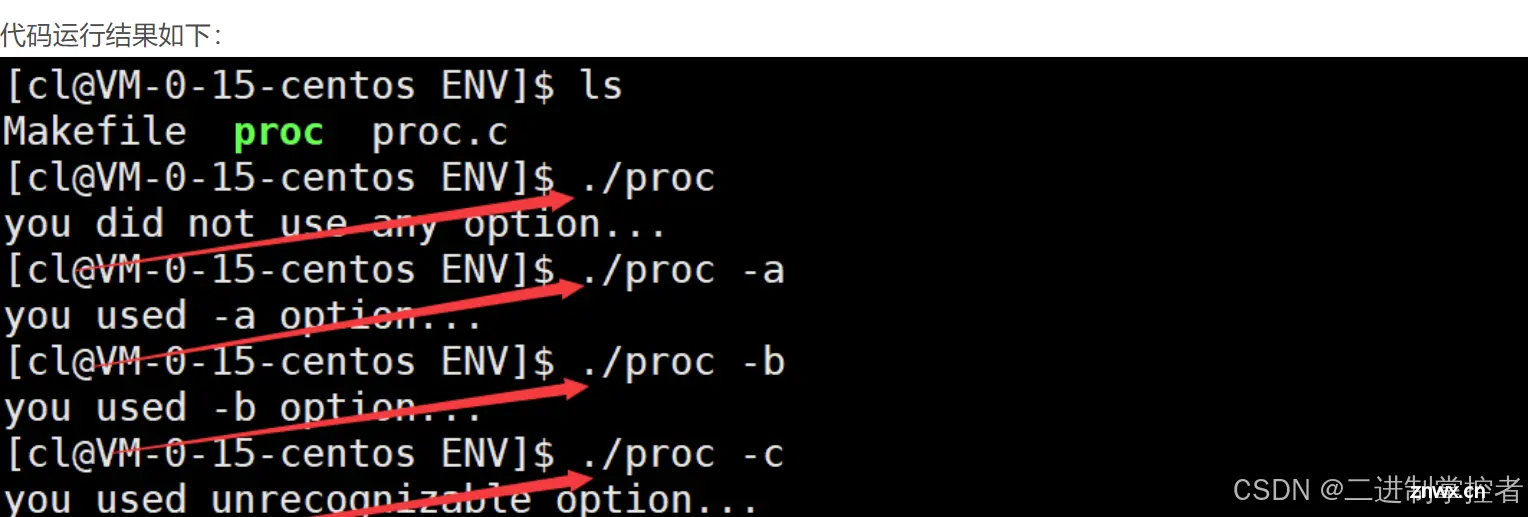
下面我们来写一个简单的代码,这个代码运行起来之后会根据你所给的选项的不同给出不同的提示语句:
现在我们来说说main的第三个参数:
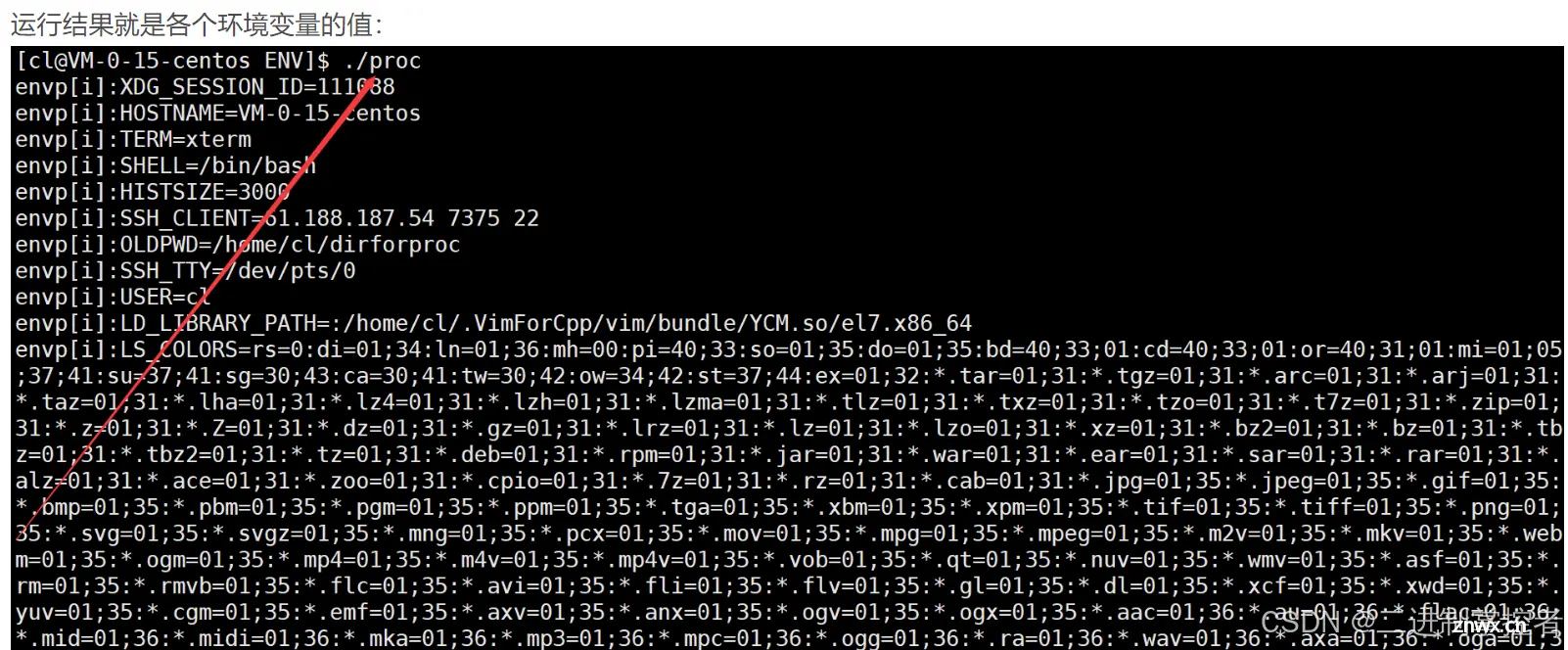
main的第三个参数实际上是接受的环境变量表
可通过他获得系统的环境变量:
通过系统调用获取环境变量:

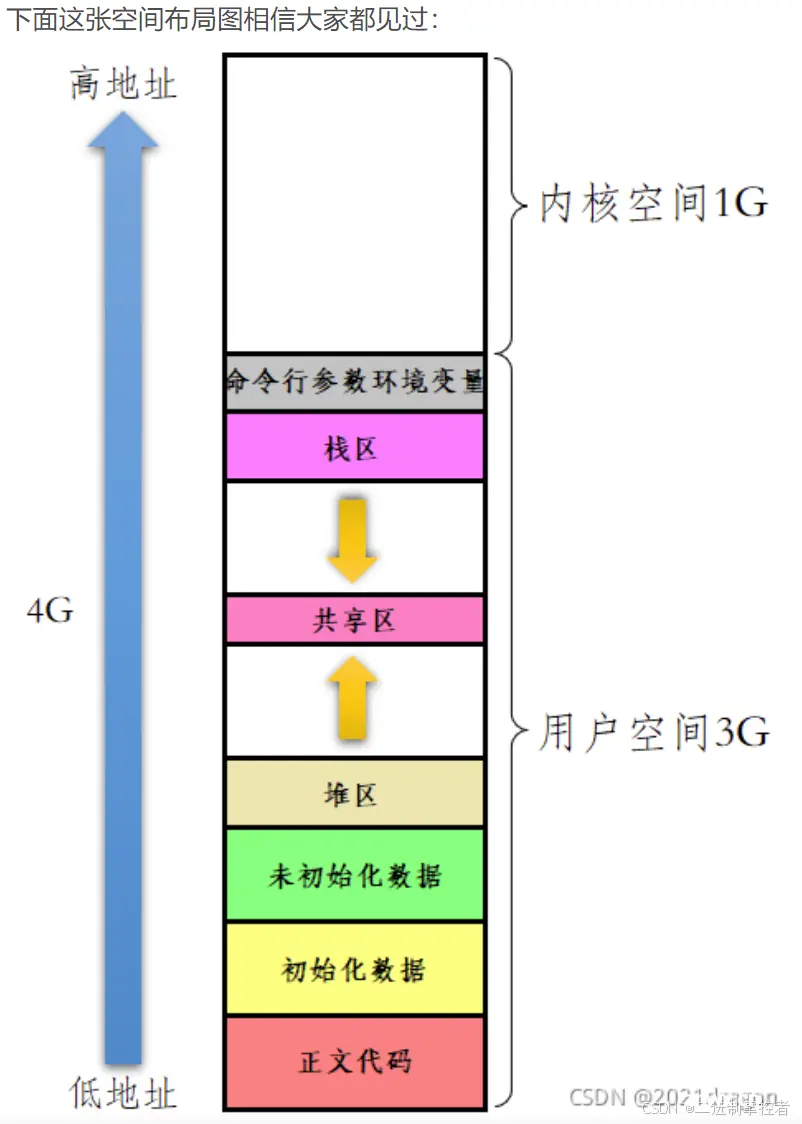
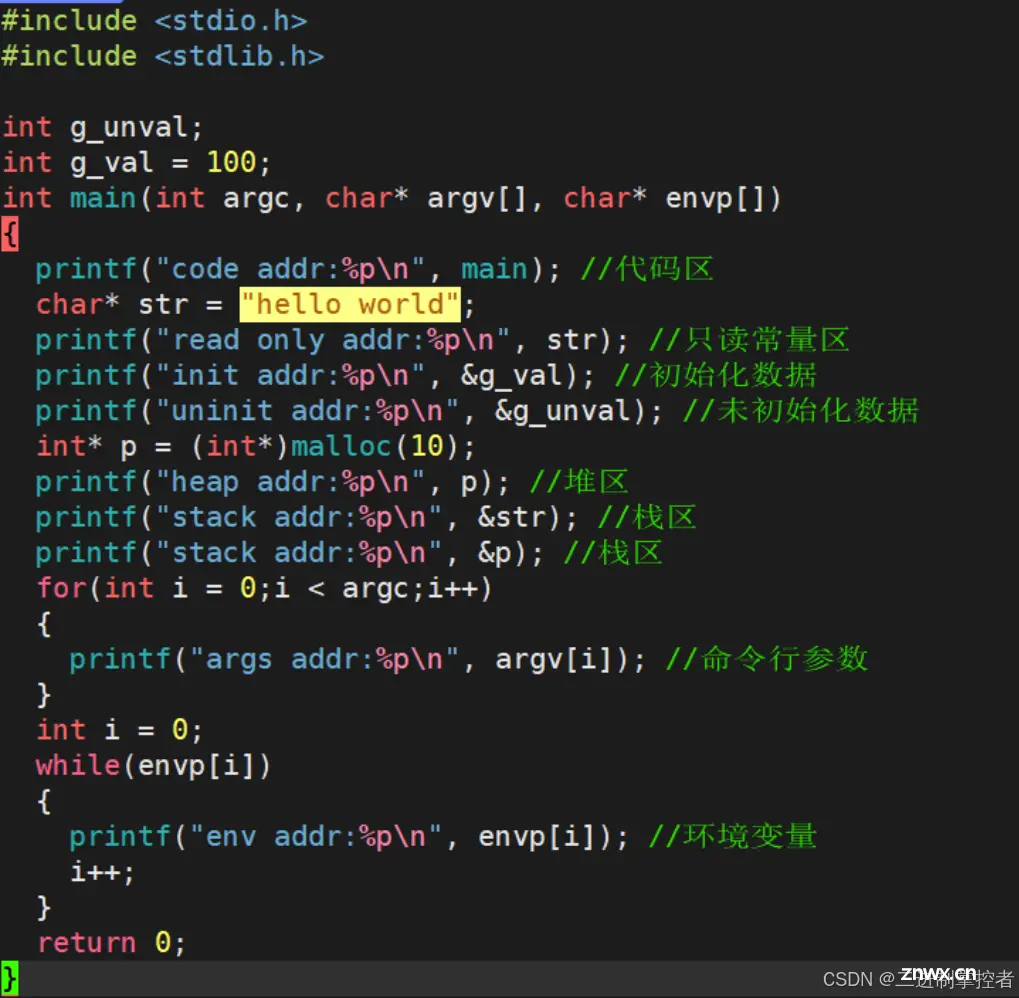
程序地址空间:

下面我们来验证一下:

最后:
十分感谢你可以耐着性子把它读完和我可以坚持写到这里,送几句话,对你,也对我:
1.一个冷知识:
屏蔽力是一个人最顶级的能力,任何消耗你的人和事,多看一眼都是你的不对。
2.你不用变得很外向,内向挺好的,但需要你发言的时候,一定要勇敢。
正所谓:君子可内敛不可懦弱,面不公可起而论之。
3.成年人的世界,只筛选,不教育。
4.自律不是6点起床,7点准时学习,而是不管别人怎么说怎么看,你也会坚持去做,绝不打乱自己的节奏,是一种自我的恒心。
5.你开始炫耀自己,往往都是灾难的开始,就像老子在《道德经》里写到:光而不耀,静水流深。
最后如果觉得我写的还不错,请不要忘记点赞✌,收藏✌,加关注✌哦(。・ω・。)
愿我们一起加油,奔向更美好的未来,愿我们从懵懵懂懂的一枚菜鸟逐渐成为大佬。加油,为自己点赞!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。