
ConvNeXtV2是ConvNeXt系列的改进版,通过优化卷积层和掩码自编码器技术,进一步提高了网络的表示能力。全卷积掩码自编码器(FCM)在处理高维特征图时具有出色的性能,尤其是在细粒度特征提取和上下文信息建模方面。YOLOv8引入...

FasterNeT是一种旨在极大优化推理速度的轻量级网络,通常用于移动设备和嵌入式系统。它通过减少参数量和计算量,提升了FPS(帧每秒),而且在不显著降低精度的前提下,提高了效率。轻量化卷积层:采用深度可分离卷积(D...

VanillaNet是华为最新推出的轻量级网络架构,专为在移动端和嵌入式设备上运行而设计。轻量化设计:通过简化卷积操作和减少参数量,VanillaNet可以在保证精度的前提下,大幅降低计算复杂度。深度可分离卷积:采用深度可分离卷积(De...

FasterNeT是一种新型轻量化神经网络架构,旨在在保证精度的同时极大地提高推理速度。其通过一系列结构创新(如GroupConvolution和LayerNorm)减少了计算复杂度,同时保持了较高的模型性能。将Faster...

ShuffleNetV1是由FacebookAIResearch团队提出的轻量级神经网络。其核心思想是通过分组卷积(GroupConvolution)和通道重排(ChannelShuffle)技术来减少模型参数和计算量,同时保持...
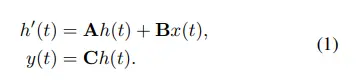
简单看看,文章介绍了Vim模型,这是一种新的通用视觉基础模型,它利用双向Mamba块(bidirectionalMambablocks(Vim))和位置嵌入(positionembeddings)来处理...

为了对改进后的YOLOv8模型进行训练,我们可以使用PyTorch的标准训练流程,并且结合前面提到的动态学习率调整和混合损失函数策略。#定义模型和损失函数#自定义数据增强])#训练循环。...

YOLOv10专栏持续复现网络上各种顶会内容,同时专栏内容可以用于YOLOv8改进~,欢迎大家订阅!!!_yolov10bifpn...

PPHGNetV2是由百度飞桨团队提出的一种轻量化特征提取网络,专为实时检测任务设计。其在架构上采用了深度可分离卷积、通道注意力机制和多尺度特征融合策略,使得网络在轻量化的同时保持了较高的特征提取能力。PPHGNetV2的这种设计思想非...

高效的多头注意力机制:相比传统的ViT,EfficientViT通过改进的多头注意力机制,降低了计算复杂度。轻量级设计:EfficientViT通过减少网络参数和计算量,实现了更低的延迟和更少的资源消耗。增强的特征提...