
深度学习的前沿技术包括生成对抗网络(GANs)、自监督学习和Transformer模型。GANs通过生成器和判别器的对抗训练生成高质量数据,自监督学习利用数据的内在结构在无标签数据上学习有效特征,Transfor...

在Transformer模型中,Add&Norm(残差连接和层归一化)是两个重要的组成部分,它们共同作用于模型的各个层中,以提高模型的训练效率和性能。网络退化:网络退化(Degradation)是深度学习中一个...
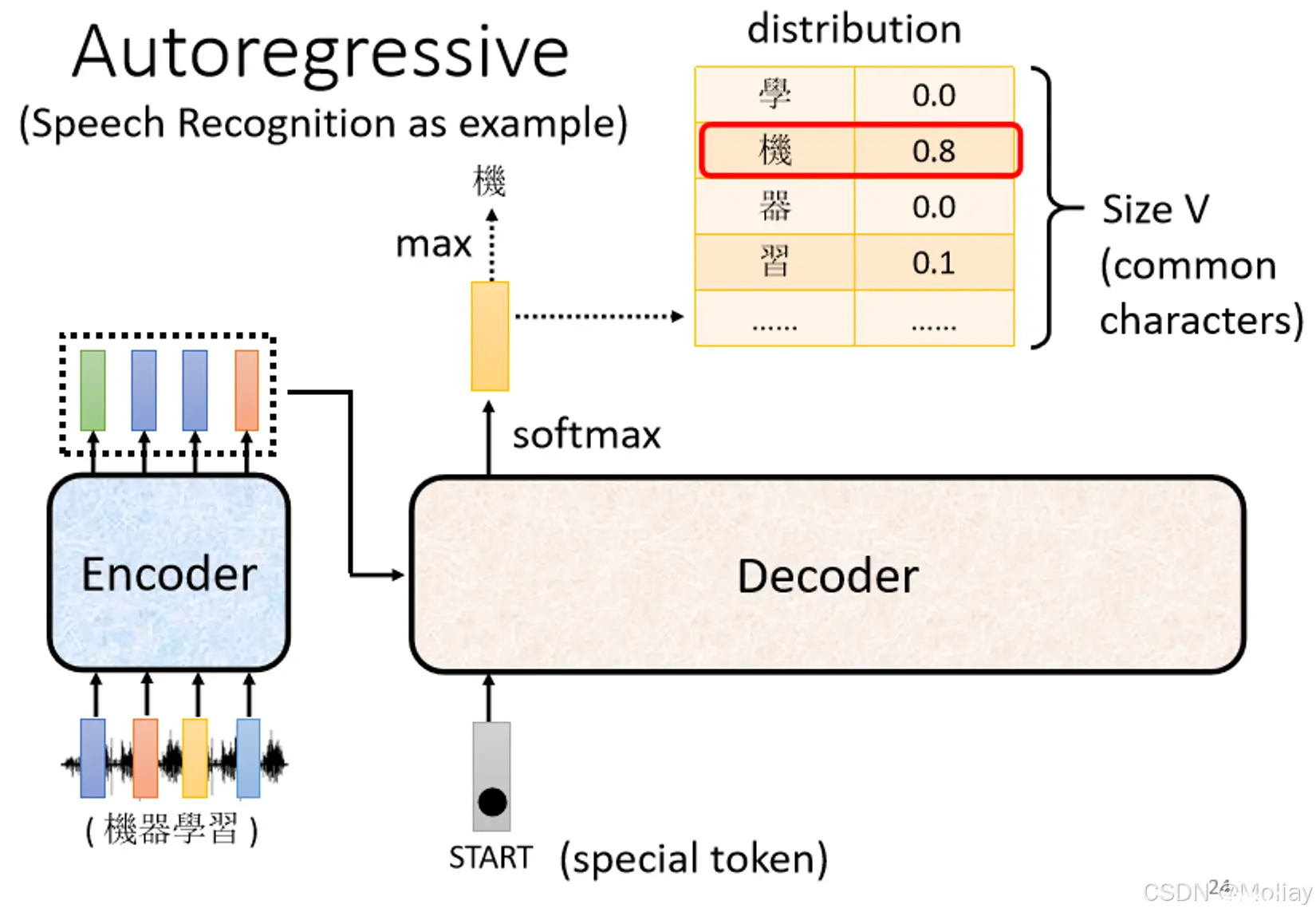
decoder会把自己的输出作为接下来的输入之一,当decoder看到错误的输入,再被decoder自己吃进去,可能会造成errorpropagation,一步错步步错。但是,在训练时,是对每一个生成的toke...

Transformer模型是一种在自然语言处理(NLP)及其他序列到序列(Seq2Seq)任务中广泛使用的深度学习模型框架。其基本原理和核心组件,尤其是自注意力机制(Self-AttentionMechanism)...
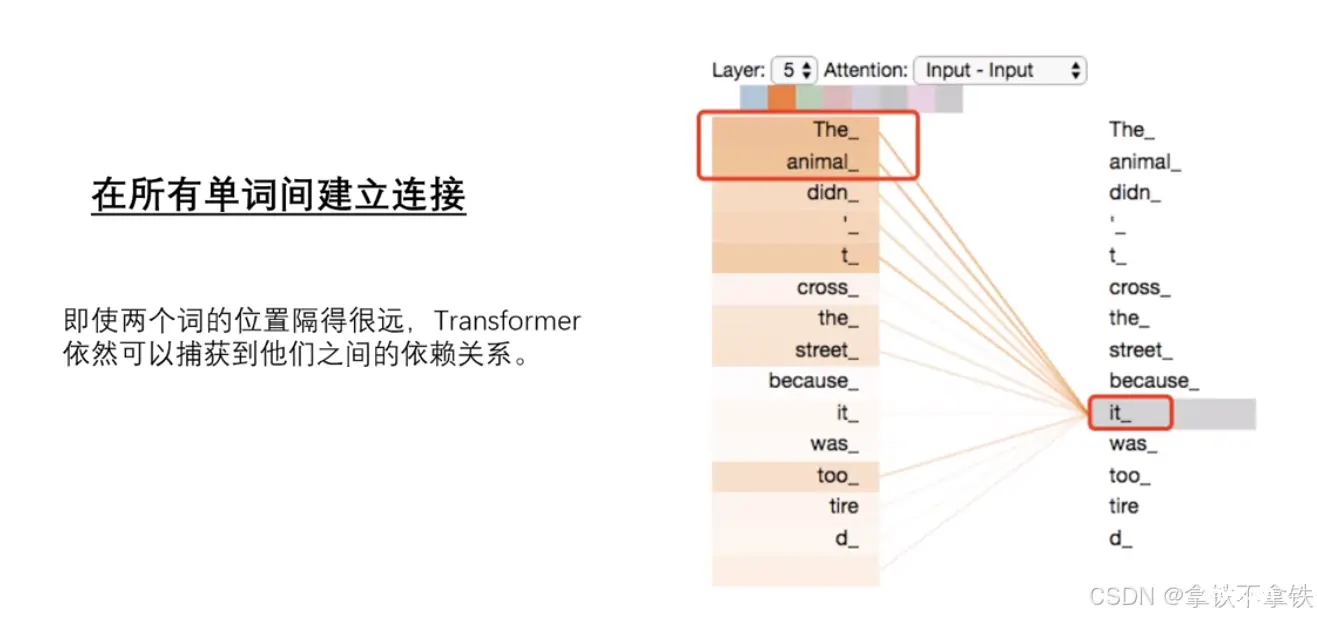
Transformer自注意力机制是一种在自然语言处理(NLP)领域中广泛使用的机制,特别是在Transformer模型中,这种机制允许模型在处理序列数据时,能够捕捉到序列内部不同位置之间的相互关系。1、查询(Q...

YOLOv8作为目标检测领域的最新版本,在速度和精度之间取得了良好的平衡。然而,随着计算机视觉任务的复杂性不断增加,YOLOv8的标准主干网络(Backbone)在处理高分辨率图像或多尺度目标时,可能存在一定的局限性。为了进一步提升YO...
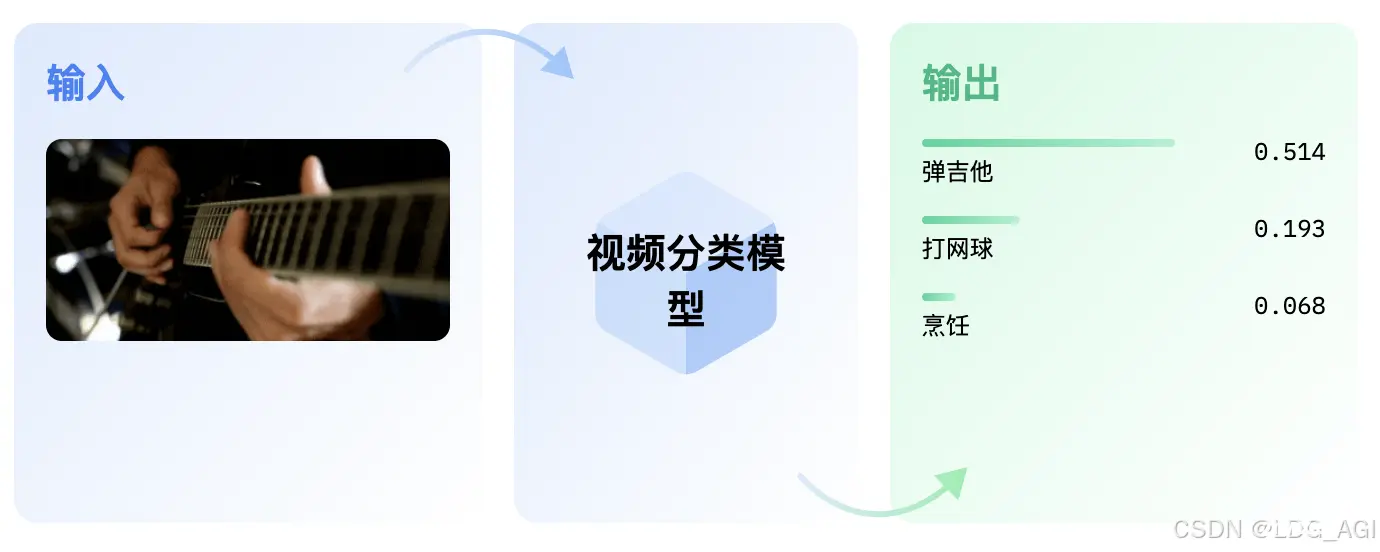
本文对transformers之pipeline的视频分类(video-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipelin...
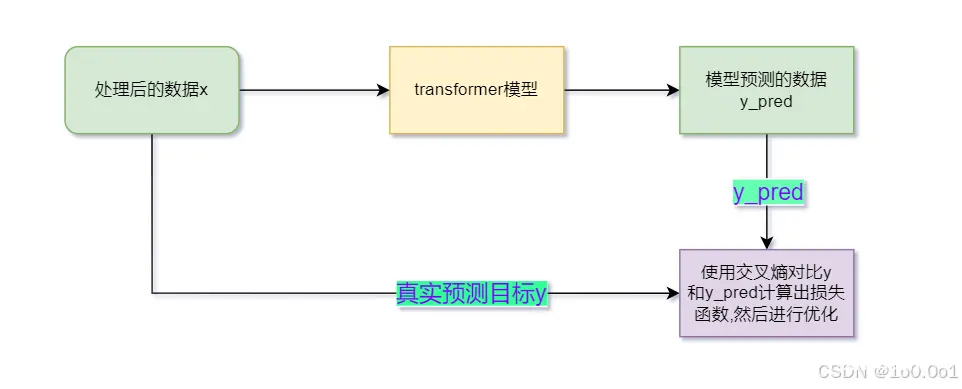
本文章基于使用了transformer模型去实现了一个英译中的模型,并参加了讯飞科大的NLP翻译比赛。...

创建一个形状为(max_len,d_model)的零矩阵#生成一个形状为(max_len,1)的位置索引矩阵#计算位置编码的分母项#对偶数维度进行正弦变换#对奇数维度进行余弦变换#添加批次维度...

安装pytorch2.2以上,启用sdpa(–opt-sdp-no-mem-attention,就可以不用安装xformers了。FlashAttention2是FlashAttention的改进...