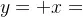
自注意力机制是Transformer模型的核心,它允许模型在编码每个单词时同时关注序列中的其他单词,从而捕捉到单词之间的依赖关系。位置编码的生成使用了正弦和余弦函数的不同频率,以确保编码在不同维度上具有不同的模式...
Mamba是一种新的状态空间模型架构,在语言建模等信息密集数据上显示出良好的性能,而以前的二次模型在Transformers方面存在不足。Mamba基于结构化状态空间模型的,并使用FlashAttention...

深度学习的前沿技术包括生成对抗网络(GANs)、自监督学习和Transformer模型。GANs通过生成器和判别器的对抗训练生成高质量数据,自监督学习利用数据的内在结构在无标签数据上学习有效特征,Transfor...

Transformer模型是一种在自然语言处理(NLP)及其他序列到序列(Seq2Seq)任务中广泛使用的深度学习模型框架。其基本原理和核心组件,尤其是自注意力机制(Self-AttentionMechanism)...
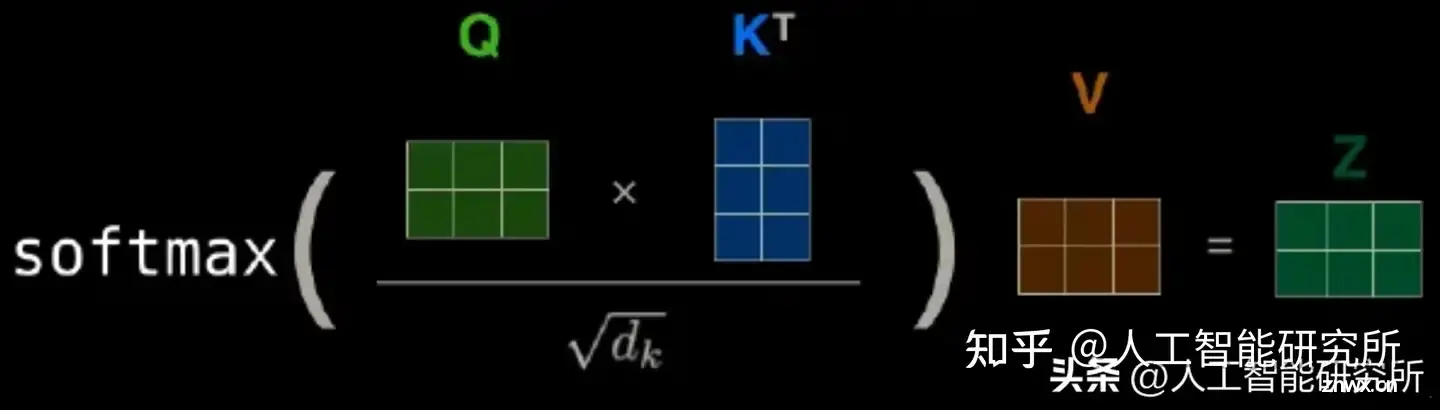
Transformer自注意力机制是一种在自然语言处理(NLP)领域中广泛使用的机制,特别是在Transformer模型中,这种机制允许模型在处理序列数据时,能够捕捉到序列内部不同位置之间的相互关系。1、查询(Q...
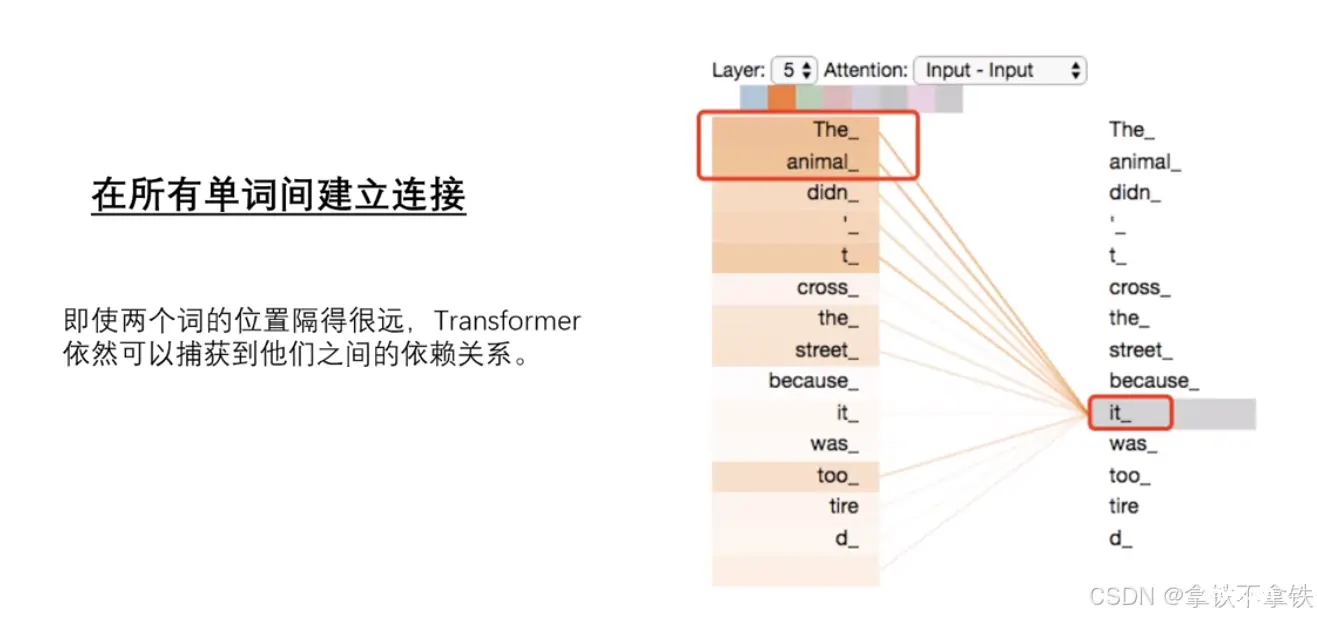
transformer结构是google在2017年的AttentionIsAllYouNeed论文中提出,在NLP的多个任务上取得了非常好的效果,可以说目前NLP发展都离不开transformer。最...
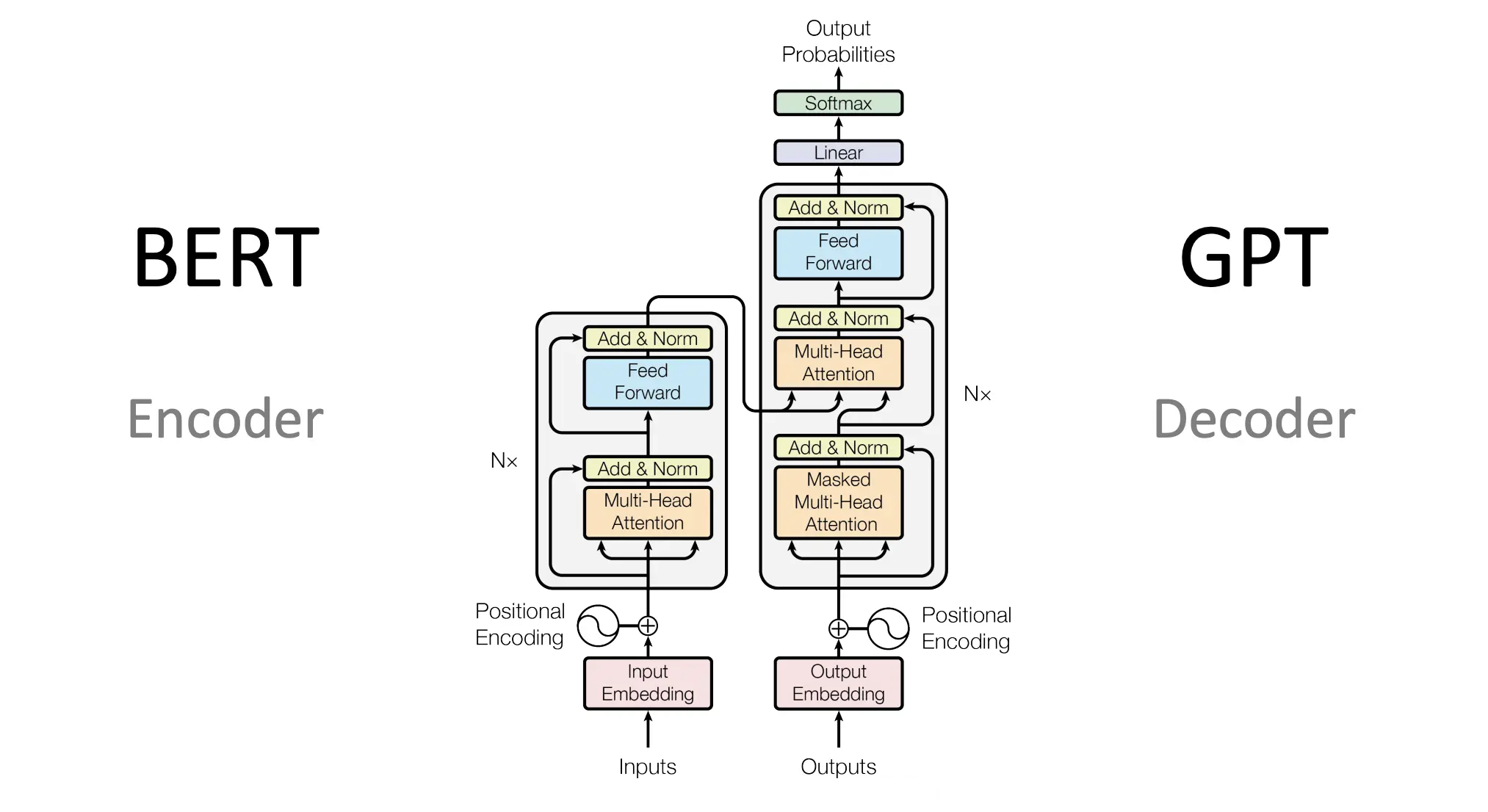
Google在人工智能领域的贡献是不可小觑的,尤其是在Transformer模型的研究和发展中。Transformer模型最初由Vaswani等人在2017年的论文《AttentionisAllYouNe...

写在前面在本文中,我们利用Nixtla的NeuralForecast框架,实现多种基于Transformer的时序预测模型,包括:Transformer,Informer,Autoformer,FEDfor...
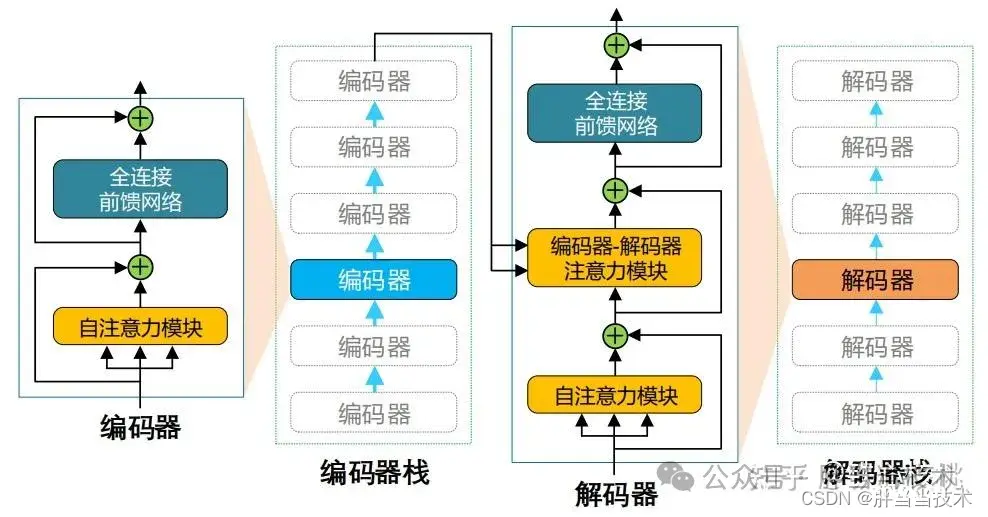
上篇文章以对话模式为例讲了目前人工智能的整体架构,但是大模型依然有很多细节问题,这里作者讲一讲目前的Transformers模型原理。_人工智能transformer...