Transformer模型:人工智能技术发展的里程碑
运维开发王义杰 2024-06-25 17:01:12 阅读 55
在当今人工智能领域,Transformer模型已经成为了一种划时代的技术,它不仅在自然语言处理(NLP)领域取得了突破性的进展,也为其他机器学习任务提供了新的思路和方法。我们今天将深入探讨Transformer模型,包括它的工作原理、对人工智能技术发展的影响,以及它在实际应用中的表现。
Transformer模型简介
Google对Transformer模型的贡献
Google在人工智能领域的贡献是不可小觑的,尤其是在Transformer模型的研究和发展中。Transformer模型最初由Vaswani等人在2017年的论文《Attention is All You Need》中提出。这一模型的核心思想是利用“自注意力(Self-Attention)”机制来捕捉输入数据中的内在关系,无需依赖传统的循环神经网络(RNN)或卷积神经网络(CNN)结构。Transformer模型的提出,标志着从序列处理的角度进入了一个新的时代,它使模型能够更加高效地处理和理解语言。Google的研究人员通过创新的自注意力机制,成功解决了之前依赖RNN和CNN处理序列数据时面临的挑战,如长依赖问题和计算效率低下。
Google研究人员Ashish Vaswani是《Attention is All You Need》论文的第一作者,也是Transformer模型的主要发明者之一。Vaswani在Google工作期间,与其他合作者一起开发了Transformer模型,对自然语言处理和机器学习领域做出了重大贡献。他的这一成就不仅推动了NLP技术的进步,也为后续的研究者和开发者提供了新的工具和思路,极大地扩展了人工智能的应用范围。
Google长期以来一直致力于人工智能技术的研究与开发,尤其关注于如何通过技术创新来解决复杂的问题。在自然语言处理领域,Google的研究人员一直在探索更有效的模型架构,以提高机器理解和生成语言的能力。Transformer模型的成功,可以说是Google在人工智能研究领域持续努力和创新精神的一个体现。它不仅证明了自注意力机制的强大能力,也为后续的研究和应用开辟了新的道路。
Google及其研究人员,特别是Ashish Vaswani等人对Transformer模型的贡献,是整个人工智能领域共同进步和发展的重要一环。他们的工作不仅极大地推动了自然语言处理技术的发展,也促进了人工智能在更广泛领域中的应用和探索。随着技术的不断进步,我们期待在未来见证更多基于Transformer模型的创新和突破。
工作原理
Transformer模型的核心是自注意力机制,它可以同时处理输入序列中的所有元素,捕捉元素之间的关系。这种机制通过计算输入序列中每个元素对其他元素的“注意力”分数来工作,使模型能够专注于输入中最相关的部分。此外,Transformer还采用了多头注意力(Multi-Head Attention)机制,增加了模型捕捉不同子空间表示的能力。
模型的另一个关键特性是它的编码器-解码器结构。编码器负责处理输入数据,而解码器则负责生成输出。每个编码器和解码器层都包含自注意力机制和前馈神经网络,而且通过残差连接和层归一化,极大地提高了模型的训练效率和稳定性。
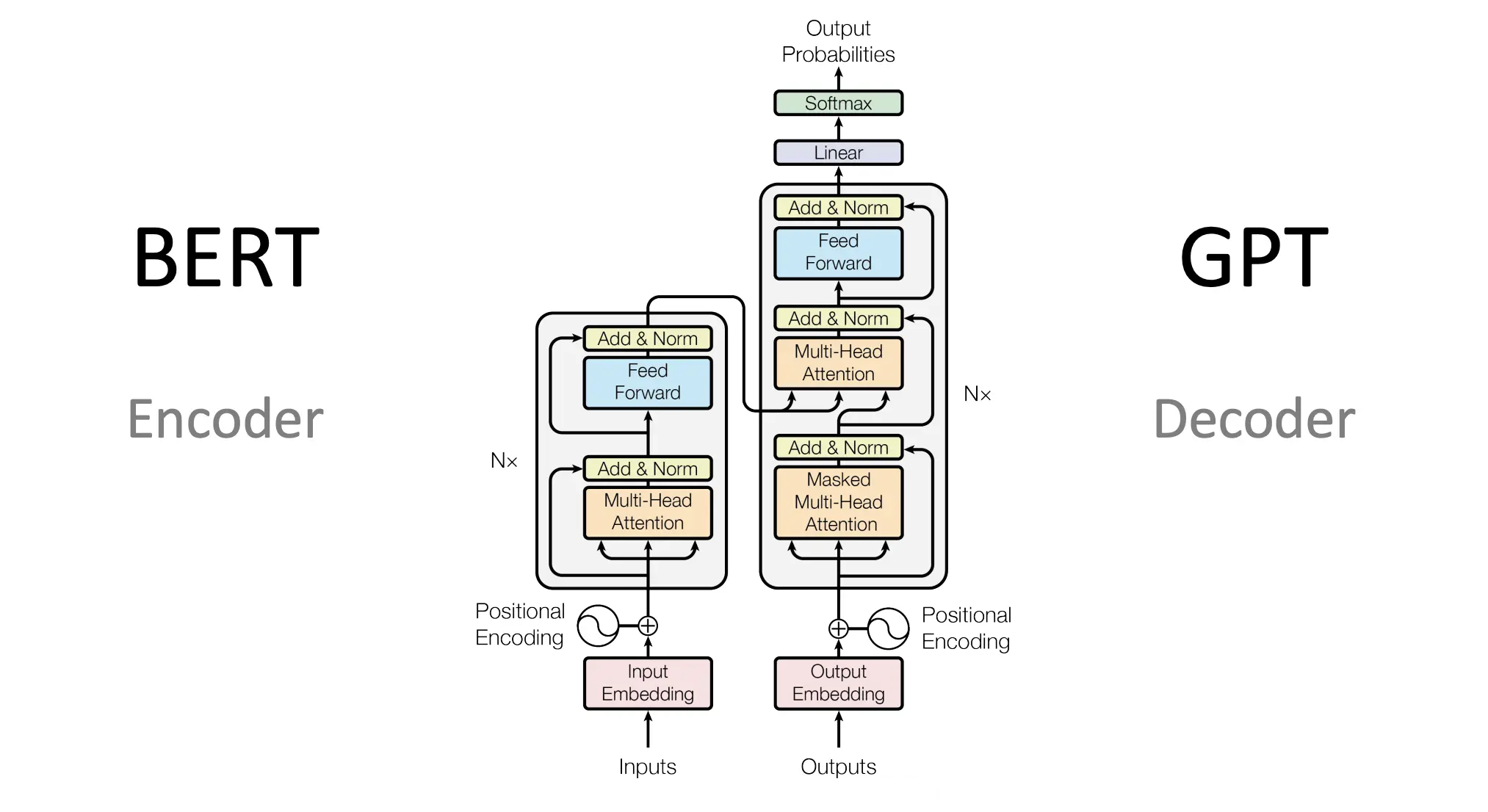
对AI技术发展的影响
Transformer模型对人工智能技术的发展产生了深远的影响。首先,它极大地提高了机器对自然语言的处理能力,推动了机器翻译、文本摘要、情感分析等NLP任务的进展。此外,Transformer的设计理念也被应用于视觉领域,如ViT(Vision Transformer)证明了Transformer结构在图像识别任务上的有效性。
更重要的是,基于Transformer模型的大规模语言模型,如GPT系列,已经展示了惊人的生成能力和多领域适应性。这些模型不仅能够生成连贯的文本,还能进行代码生成、艺术创作等,极大地扩展了人工智能的应用范围。
实际应用
在实际应用中,Transformer模型已经成为了众多技术产品和服务的核心。从自动回复、聊天机器人到内容推荐系统,Transformer的应用几乎遍及每一个使用到自然语言处理的领域。其出色的性能和灵活性,使得它成为了当前最受欢迎的人工智能模型之一。
结论
Transformer模型的发明无疑是人工智能领域的一大里程碑。它不仅革新了自然语言处理的方法,也为未来的人工智能研究和应用提供了新的方向。随着技术的进一步发展,我们期待看到Transformer及其衍生模型在更多领域中的创新应用。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。