一文弄懂 Transformer模型(详解)
拿铁不拿铁 2024-08-17 09:01:03 阅读 65
在Transformer统治语言模型之前:RNN占主流
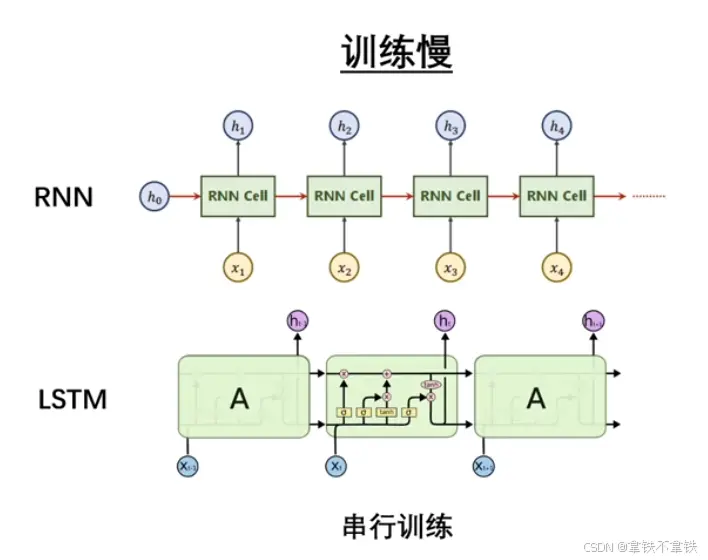
初始Transformer的优势(有两点)
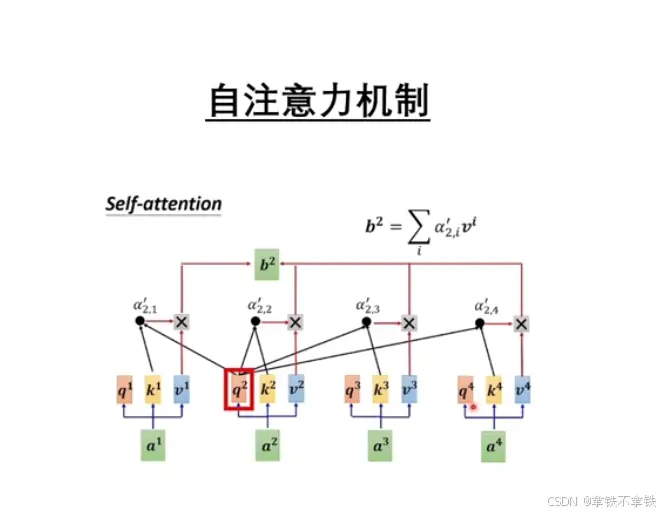
1、自注意力机制
Transformer自注意力机制是一种在自然语言处理(NLP)领域中广泛使用的机制,特别是在Transformer模型中,这种机制允许模型在处理序列数据时,能够捕捉到序列内部不同位置之间的相互关系。
自注意力机制的核心机制:
1、查询(Query)、键(Key)、值(Value):自注意力机制将输入序列中的每个元素视为一个查询,同时将序列中的所有元素视为键和值,每个元素都会生成对应的查询、键和值表示。
2、注意力分散:对于序列中的每个元素。模型会计算它与序列中其他所有元素的注意力分散。这些分数是通过查询和键的点积得到的,然后通常会通过一个缩放因子(通常是键的维度的梯度消失 平方根)来避免梯度小时的问题。
3、Softmax函数:注意力分数通过Softmax函数进行归一化,确保所有分数的和为1,归一化后的分数可以看作是每个元素对其他元素的注意力权重。
4、加权求和:每个元素的输出是其值表示与对应注意力权重的加权和。这允许模型在生成每个元素的输出时,考虑序列中其他元素的信息。
5、多头注意力:Transformer模型中的自注意力机制通常包含多头注意力,即模型会并行的执行多个子注意力过程,每个头学习到的注意力模式可以不同。最后,所有头的输出会被合并,以获得更全面的序列表示。
2、位置编码
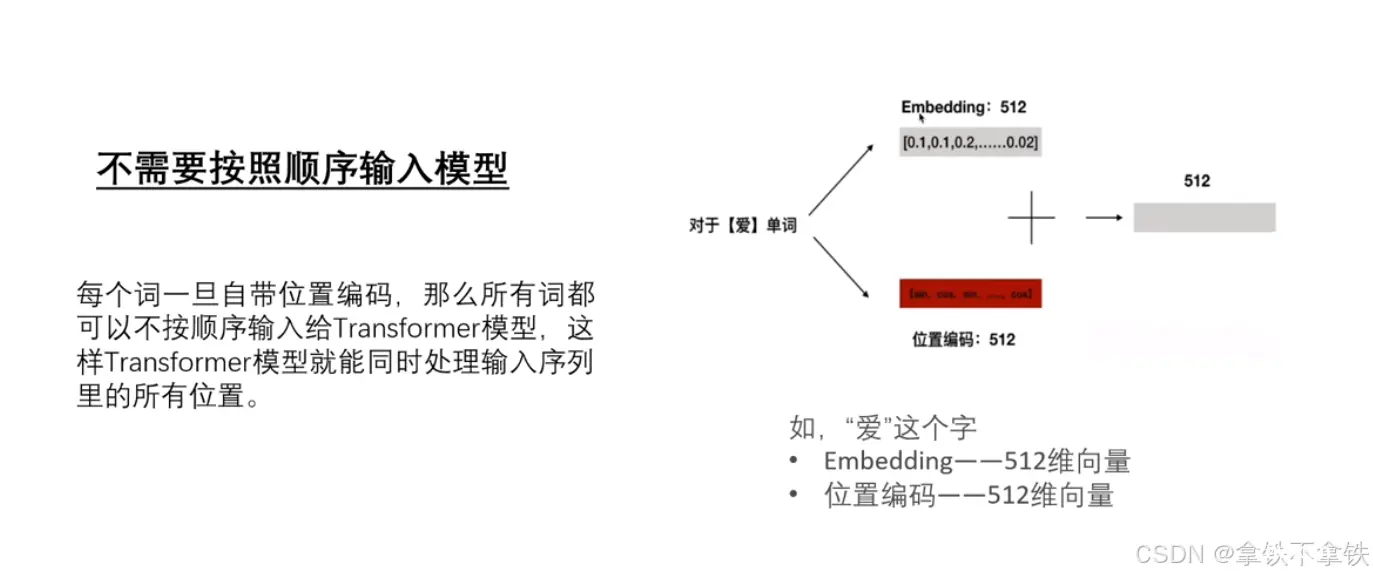
位置编码(Positional Encoding)是Transformer模型中的一个重要组成部分,用于给模型提供关于单词在序列中位置的信息,由于Transformer的自注意力机制本身并不包含任何关于序列中单词位置的信息,因此需要位置编码来弥补这一缺陷。
位置编码的主要方法:
1、固定位置的主要方法:这是最初在论文《Attention Is All You Need》中提出的方法。它通过将正弦和余弦函数的不同频率应用于序列中每个位置的维度来生成位置编码。具体来说,对于每个位置p和每个维度i,位置编码计算如下:

2、可学习位置编码:在某些变体的Transformer模型中,位置编码可以是可学习的参数,这就意识着它们在训练过程中通过反向传播进行挑战。
3、相对位置编码:在某些任务中,相对位置信息可能比绝对位置更加重要,相对位置编码通过计算单词对之间的相对位置来提供这种信息。
位置编码的作用:
1、提供序列顺序信息:位置编码使得模型能够理解序列中单词的顺序,这对于许多语言任务(如语法分析、文本生成等)至关重要。
2、增强模型的表达能力:通过位置编码,模型可以捕捉到单词之间的相对位置关系,增强了模型对序列数据的理解能力。
缺点在于:
1、固定编码的局限性:固定位置编码可能在某些情况不够灵活,无法适应所有类型的序列数据。
2、可学习编码的训练成本:可学习的位置编码需要额外的训练步骤,可能会增加模型训练的复杂性和计算成本
一、进入Transformer: 第一步---数据预处理
1、TOKEN化:Token化(或分词),是将句子、段落、文章等长文本分解为以字词(token)为单位的数据结构。
人话讲就是先把你的input拆分成计算机能处理的token,token就是一串整数数字,因为计算机是无法储存文字的,所以任何字符最终都得用数字来表示,有了数字表示的文本之后,再给它传入嵌入层。
2、Embedding:词嵌入,将一个token(标记)转化为一个向量,向量的信息更丰富,可以捕捉到token之间的语义和语法关系。
人话讲就是,嵌入层的作用是为了让每一个token用向量来表示。维度越大,向量长度越大,数据丰富度越大。
那么问题来了,token是一串整数数字,那向量也是一串整数数字,这两个数字有啥不一样呢?
答:这是因为token本身仅是表示自身,但是那个嵌入曾的向量里面就包含了词汇之间的语法语义关系。词向量更能处理词与词之间的关系。在论文里,向量的长度是512,GPT3是12288.所以可以想象一个词可以包含的信息有多么丰富。
通过编码器的嵌入词得到向量后,下一步是....
3、Position Encoding:加入位置编码,捕捉词在句子中的顺序关系,维度和嵌入层一样,得到一个包含位置信息的新向量。
也就是把用于表示各个词在文本里顺序的向量和上一步嵌入层得到的词向量做向量相加,最终把结果传给编码器。这样以来,模型既可以理解每个词的意义,又能捕捉词在句中的意思,从而理解不同词之间的顺序关系,最终得到语法、语义、位置信息的向量。
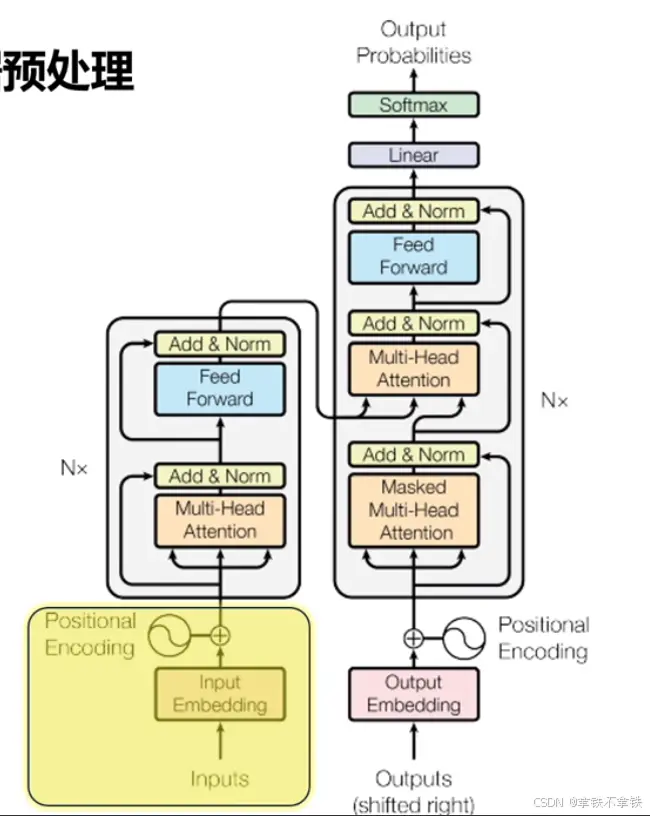
二、进入Transformer:第二步---编码器
接下来就是到编码器这个最核心的部分了。
它的主要任务是把输入转化成一种更抽象的表示形式,这个表示形式也是向量。除了保留输入文本的词汇信息和顺序关系,那最主要的一点就是要捕捉语法语义上的更深层次的关键特征。而捕捉关键特征的核心在于编码器里的自注意力机制。
Transformer论文里有这样一句话。Attention is all you need。注意力就是你需要的一切!
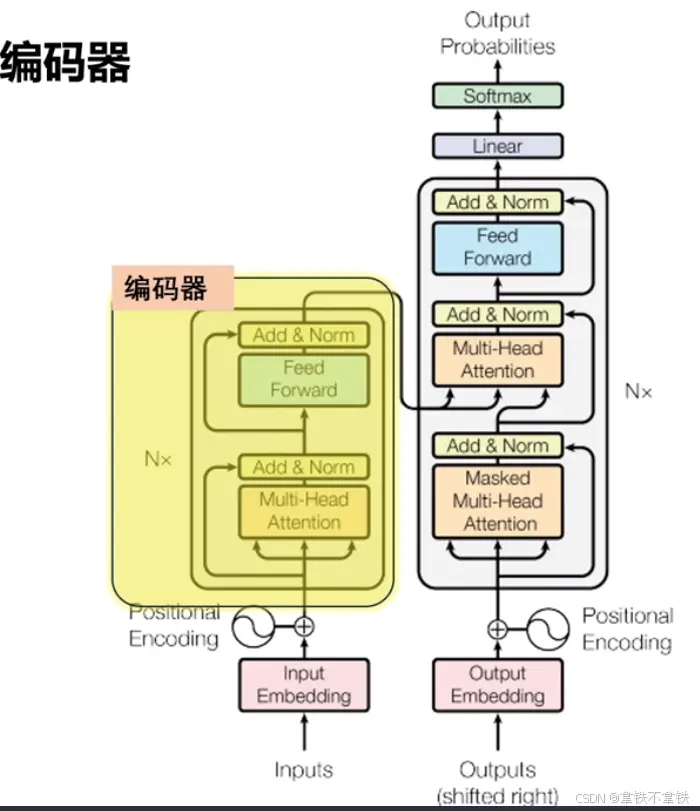
那这个过程我们来仔细聊聊。。。
下面是人话一点的解释:
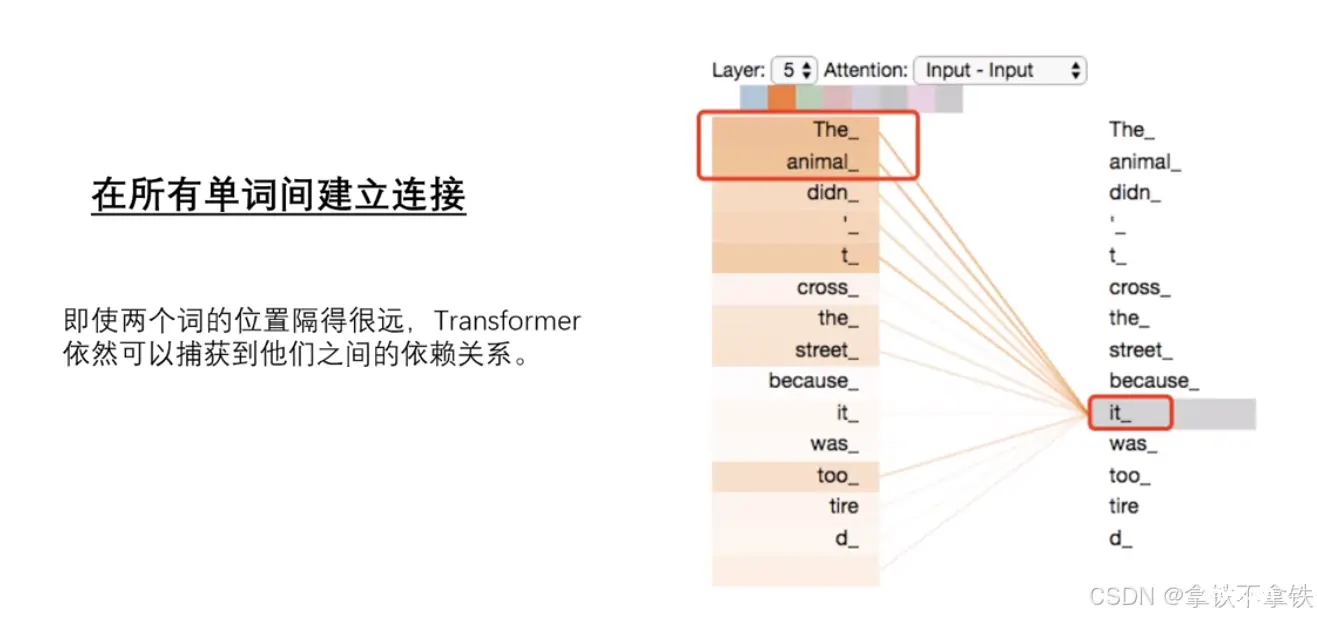
首先注意力机制会计算每对词之间的相关性来决定注意力权重,如果两个词之间的相关性更强,那么他们之间的注意力权重就会更高。
比如这个,咱们从语法来讲的话,it可以指animal也可以指street。但是子注意力机制发现了it与animal有更大的关联,所以给animal的权重会更大。每个词都会对其他任何词的权重进行加权求和,得到每个词的全新向量。
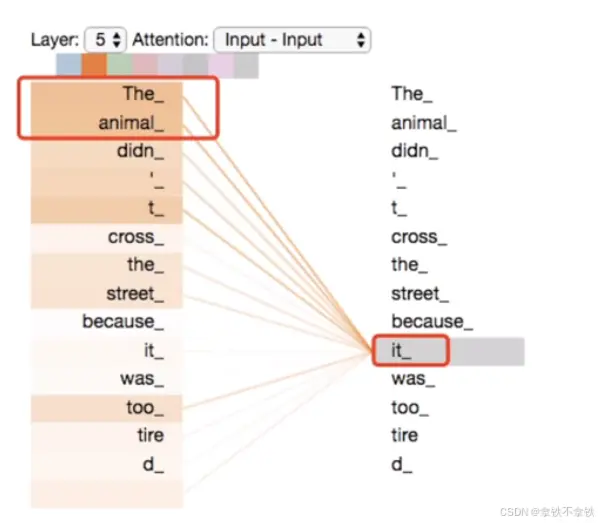
那么这个过程有助于模型捕捉。输入序列中词与词之间的全部的依赖关系,无论他们之间的距离有多远,经过自注意力模块在编码器输入的结果里,各个词的向量那就不仅包含了这个词本身的信息,还融合了上下文中的相关信息。也就是说,同一个词,在计算机看来,在不同的上下文语句中,都会有不同的向量表示。
值得一提的是,这样的自注意力模块在编码器中有多个,也叫多头自注意力。每个头都有它自己的注意力权重,也就是自己的侧重点。
假如:那么一个模型中有N个编码器则有M个自注意力,改模型能从不同角度出发,来关注文本里不同特征。有的可能注意名词、有的注意动词,也就是自注意力的权重。这样的权重是机器在大量的数据里面去提取、把握和调整的。(不共享权重)
而且多头自注意力模块的运算也是并行的,也就是计算互不影响。所以GPU天然的适合这种并行运算。
好了,在多头自注意力后面还有个前馈神经网络,它会对自注意力的输出做进一步的数值变换,增强模型的表达能力。
三、进入Transformer:第三步---解码器
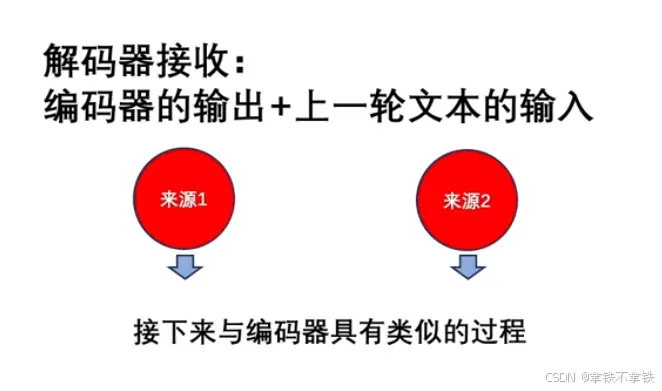
解码器也要进入嵌入层、位置编码、再输入多头自注意力模块。与编码器类似。
但是不同之处在于:当编码器在处理各个词的时候,会关注输入序列里所有其他词。而在解码器中,自注意力只会关注这个词和他前面的其他词,确保生成过程的顺序性和正确性。
所以解码器的多头自注意力也叫带掩码的自注意力
通过解码器最终的得到了包含输入序列的全局信息、关于当前位置信息和已生成的序列信息的新向量
四、进入Transformer:第四步---Linear层和Softmax层
1、Linear层:将输入的向量映射到一个更大的logits向量上。logis向量的长度通常与词汇表的大小
一致,假设输出词汇为10000,则logis向量的输出也为10000,每一个向量上的数字对应一个词汇
2、Softmax层:Softmax层将logis向量中的每一个数字都转换成0到1之间的概率值,这些概率值表示对应词汇在当前位置被选择的概率,并且所有位置的概率之和为1。
最后把解码器的结果输入到线性层和Softmax层,目的是为了把输入转化为词汇表的概率分布,这个概率分布代表下一个token被生成的概率。在大多数情况下,模型会选择概率最高的token作为下一个输出,那解码器本质上就是在猜下一个最可能的输出是谁。那解码器的一整个流程会重复多次,所以会有不断地不断地有新地token持续生成。直到生成的是一个用来表示输出序列结束的特殊token,那么我们就获得了来自解码器的完整序列。
拓展:Transformer的变形
以上全为原始Transformer的编码器和解码器的模式,随着研究的深入,发现编码器解码器可以独立的使用,目前有三个类别:

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。