语义分割快速入门教程(mmsegmentation平台)
Kevin_wzf 2024-08-17 09:01:04 阅读 89
引言
最近项目用到语义分割相关的技术,跟目标检测一样,离不开标注数据集、制作训练数据、模型训练、模型推理测试几个环节,找到了一个比较好的平台mmsegmentation,是香港中文大学-商汤科技联合实验室(MMLab)推出的一个集齐目标检测、语义分割等深度学习的框架和平台,让小白也能快速将论文中的算法模型、网络结构复现落地应用,工欲善其事,必先利其器,那就从搭建环境开始吧!
目录
引言
一、搭建环境
1. 安装cuda、cudnn
2. 安装pytorch-gpu
3. 安装MMCV
4.安装mmsegmentation
5.测试验证
二、制作数据集
1. 搭建环境
2.数据转码和划分数据集
三、模型训练
1.配置文件
2.注意事项
四、模型推理预测
1.单张图片推理
2.视频流推理
3.摄像头推理预测
致谢
一、搭建环境
参考链接:Get started: Install and Run MMSeg
1. 安装cuda、cudnn
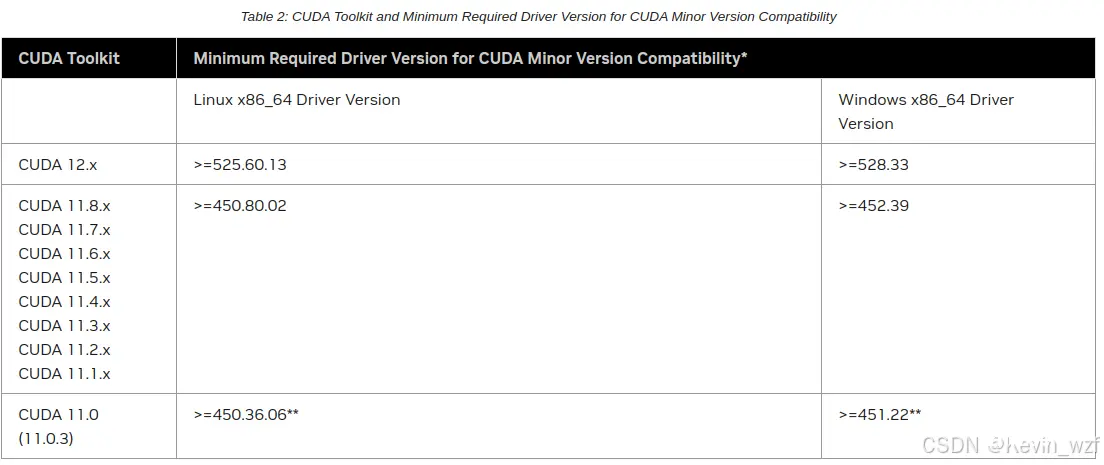
我这边电脑是有两台笔记本,一个是RTX3060(6G独显)的天选2笔记本,另一个是GTX 1050Ti 的戴尔笔记本,安装好显卡驱动,用nvidia-smi可以查看电脑支持CUDA的最高版本,这里以我的电脑为例,最高支持到CUDA 12.2,而目前pytorch-gpu版本是只兼容到12.1,所以为了适配性,建议安装不大于12.1的CUDA版本

这里有显卡驱动与支持CUDA版本对应关系表 ,如果是要安装CUDA 12.X版本,显卡驱动不低于于525.60.13
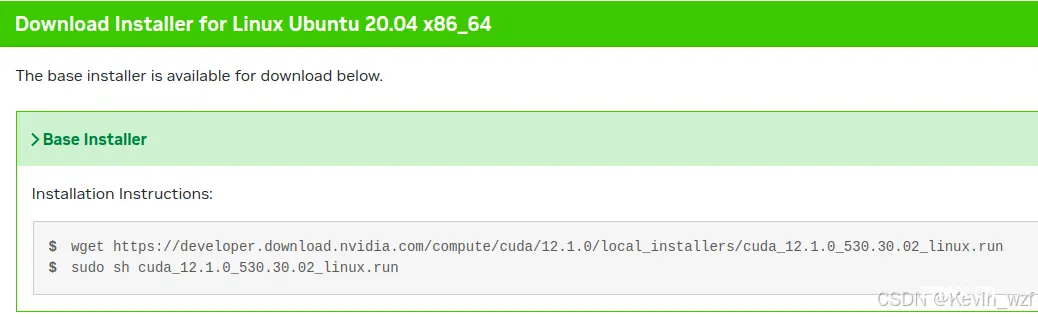
到官网CUDA Toolkit 和 cuDNN Archive 安装对应的版本包
我这边安装的是CUDA 12.1 和 CUDNN 8.9.2 版本,因为之前天选2电脑是安装了CUDA 12.0版本,在安装mmsegmentation平台环境报错,当时一直无法安装通过,最后把之前的CUDA版本卸载了,重新安装了CUDA才行,希望大家避开这个坑!!!
<code>wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
sudo sh cuda_12.1.0_530.30.02_linux.run
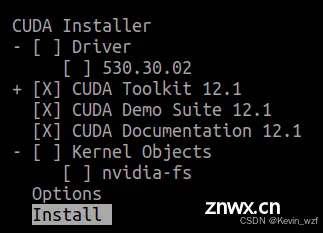
除了驱动无须安装,其他可以正常安装,安装完后在 ~/.zshrc 和 或 ~/.bashrc 文件末尾添加CUDA环境变量,并且生效即可
<code>$ sudo gedit ~/.zshrc
$ source ~/.zshrc
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda
解压下载的cudnn压缩包,并且将对应的CUDNN的软件链库拷贝到对应CUDA目录下并赋予权限,可参考这个安装教程
tar -xf cudnn-linux-x86_64-8.9.2.26_cuda12-archive.tar.xz
# dell@wu in ~/cudnn-linux-x86_64-8.9.2.26_cuda12-archive [22:49:11]
$ sudo cp -d lib/* /usr/local/cuda-12.1/lib64/
$ sudo cp include/* /usr/local/cuda-12.1/include/
$ sudo chmod a+r /usr/local/cuda-12.1/include/cudnn.h /usr/local/cuda-12.1/lib64/libcudnn*

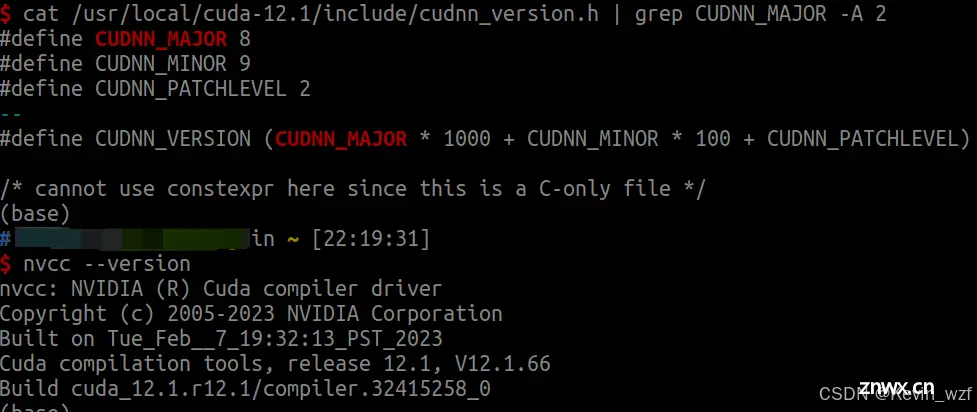
安装完毕之后,可以输入以下命令查看安装的版本
<code>cat /usr/local/cuda-12.1/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
nvcc --version
2. 安装pytorch-gpu
创建虚拟环境之后,根据自己电脑配置情况选择对应的pytorch-gpu版本,我这里两台电脑环境有些差异,天选2安装了pytorch-gpu 2.2.0,但戴尔电脑安装了pytorch-gpu 2.1.0,因为我后面在戴尔电脑按照天选2的一样环境安装,发现错误,具体可以往下看,所有只能把pytorch版本往后退。
<code>conda create --name mmsegmentation python=3.8
conda activate mmsegmentation
RTX 3060 天选2电脑环境:
torch 2.2.2
torchaudio 2.2.2
torchvision 0.17.2
mmcv 2.1.0
mmengine 0.10.3
mmsegmentation 1.2.2 /home/mmsegmentation
numpy 1.24.4
onnxruntime 1.15.1
opencv-python 4.9.0.80
openmim 0.3.9
GTX 1050Ti 戴尔电脑环境:
torch 2.1.0+cu121
torchaudio 2.1.0+cu121
torchvision 0.16.0+cu121
mmcv 2.1.0
mmengine 0.10.3
mmsegmentation 1.2.2 /home/mmsegmentation
numpy 1.23.5
onnx 1.4.1
onnxruntime 1.18.1
opencv-python 4.7.0.72
openmim 0.3.9
3. 安装MMCV
MMCV官网教程
pip install -U openmim
mim install mmcv==2.1.0
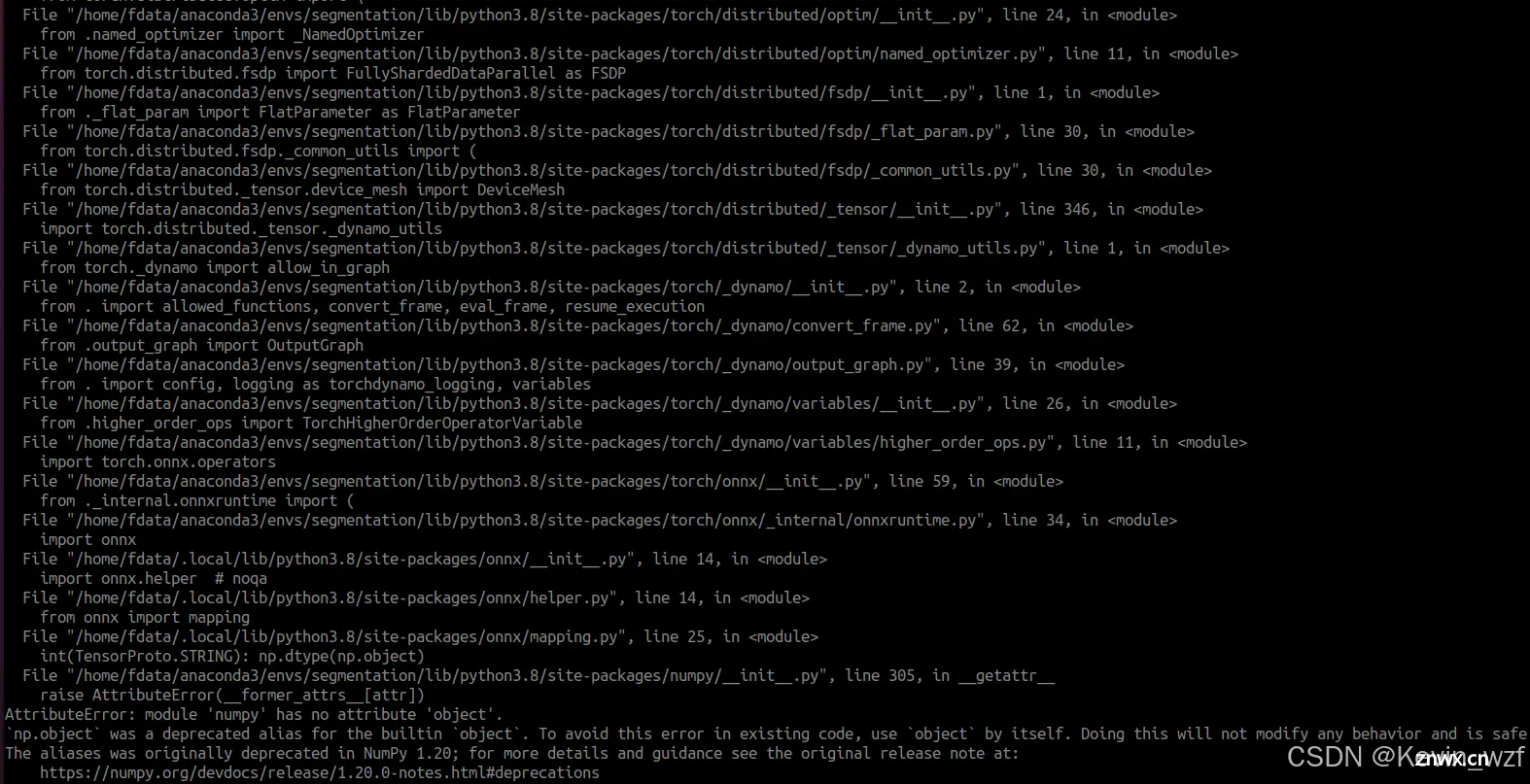
记住这里安装mmcv,最好是指定版本2.1.0,切勿直接执行 mim install mmcv (避坑)!!!,否则它是默认安装最新版本,有可能出现环境不兼容的问题,我4月底在天选2电脑安装的版本是 mmcv 2.1.0,当时是没有任何问题。但最近在戴尔电脑安装的时候,发现mmcv 更新到最新版本 2.2.0,而我的numpy 默认装了1.24.x版本,结果导致出现 module 'numpy' has no attribute 'object' [closed] 错误,后来尝试把numpy版本降到1.23.5版本,但运行的时候,仍有如下错误,貌似是mmcv 2.2.0版本不兼容,我就尝试把conda的虚拟环境重新卸载和安装,折腾了好几次还是失败。最后只能把pytorch版本降到 2.1.0,重新走一遍流程,参考这个教程才算成功安装成功。
pip install mmcv==2.1.0 -f https://download.openmmlab.com/mmcv/dist/cu121/torch2.1/index.html

<code>Traceback (most recent call last):
File "demo/image_demo.py", line 6, in <module>
from mmseg.apis import inference_model, init_model, show_result_pyplot
File "/root/mmsegmentation/mmseg/__init__.py", line 61, in <module>
assert (mmcv_min_version <= mmcv_version < mmcv_max_version), \
AssertionError: MMCV==2.2.0 is used but incompatible. Please install mmcv>=2.0.0rc4.
4.安装mmsegmentation
<code>git clone -b main https://github.com/open-mmlab/mmsegmentation.git
cd mmsegmentation
pip install -v -e .
5.测试验证
mim download mmsegmentation --config pspnet_r50-d8_4xb2-40k_cityscapes-512x1024 --dest .
python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --out-file result.jpg


二、制作数据集
1. 搭建环境
这里我推荐用X-AnyLabeling,这个本身集合目标检测、语义分割算法模型,快速进行图像数据标注,建议大家用conda单独创建一个虚拟环境,按照下述步骤安装配置环境
<code>git clone https://github.com/CVHub520/X-AnyLabeling.git
# upgrade pip to its latest version
pip install -U pip
pip install -r requirements-gpu-dev.txt
python anylabeling/app.py
大家可以在X-AnyLabeling v0.2.0 或者X-AnyLabeling 模型库 这里找到对应的算法模型权重包,提前下载,参考加载内置模型 教程来配置相关文件,就可以用SAM(Segment Anything Model )模型(SAM是Meta 公司提出的分割一切模型)完成大部分场景的自动标注
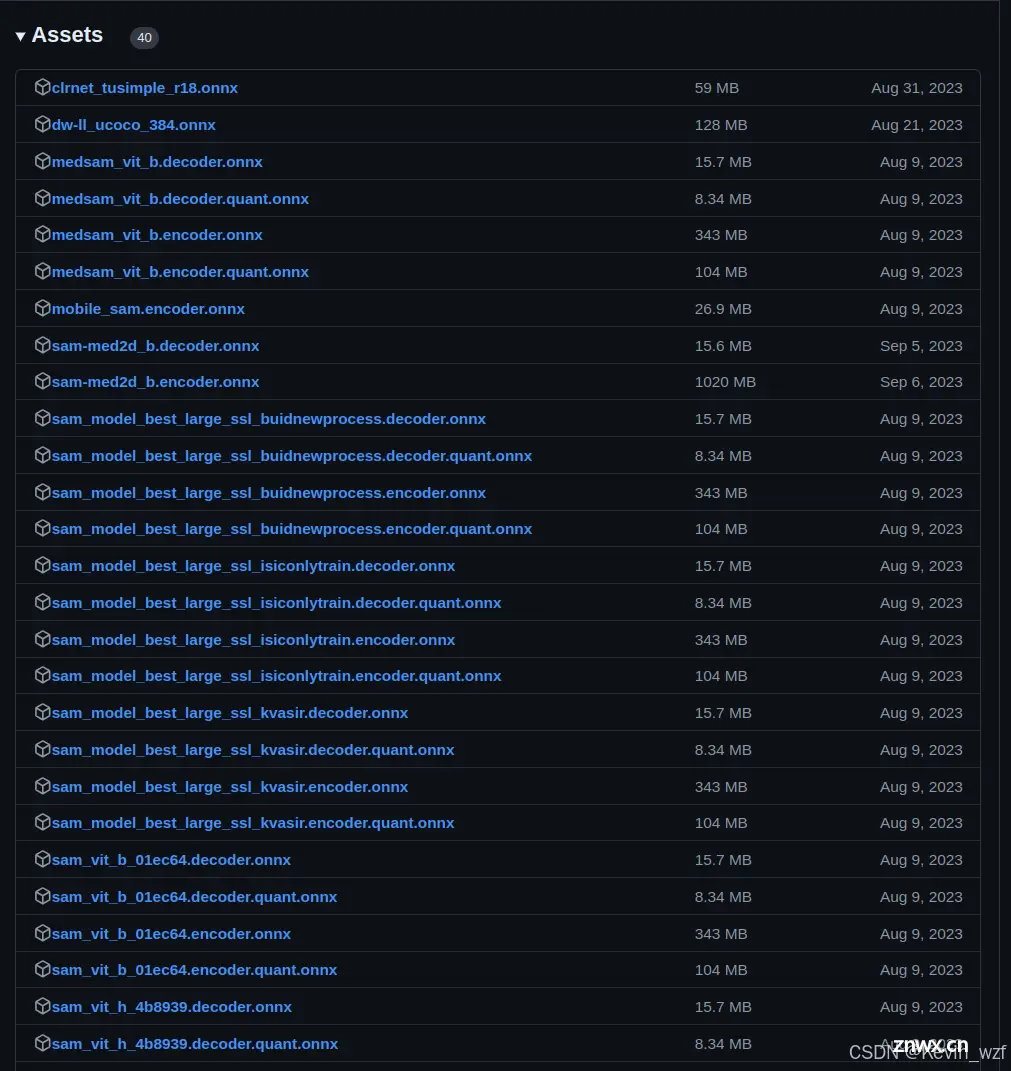
下载权重文件和对应的.yaml配置文件,放在model路径下,把对应的encoder_model_path 和 decoder_model_path 替换成自己本地的模型权重路径,最后选择加载自定义模型,即可使用


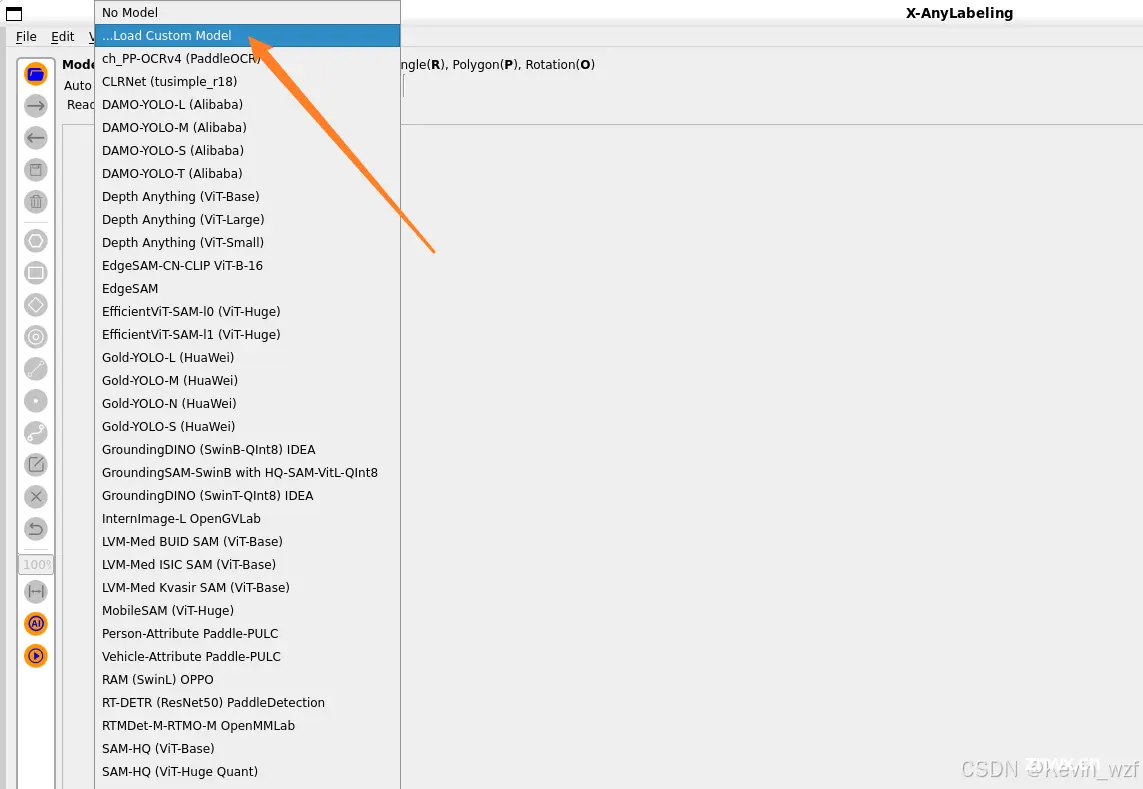
执行下面命令即可运行界面
<code>python3 anylabeling/app.py
标注数据时,几点提醒:
1.关闭 Save With Image Data(不会把图片信息记录在.json文件里)
2.选择 Save Automatically,自动保存
3.标注生成的.json文件保存到跟图片同一个路径下

生成的json文件内容如下:
<code>{
"version": "2.3.5",
"flags": {},
"shapes": [
{
"label": "watermelon",
"points": [
[
329.0,
12.0
],
[
329.0,
31.0
],
[
330.0,
32.0
],
[
330.0,
33.0
],
[
329.0,
34.0
],
[
329.0,
36.0
],
[
330.0,
37.0
],
[
330.0,
58.0
],
[
331.0,
59.0
],
[
331.0,
64.0
],
[
332.0,
65.0
],
[
348.0,
65.0
],
[
349.0,
64.0
],
[
350.0,
64.0
],
[
351.0,
65.0
],
[
359.0,
65.0
],
[
360.0,
64.0
],
[
363.0,
64.0
],
[
364.0,
65.0
],
[
370.0,
65.0
],
[
371.0,
64.0
],
[
373.0,
64.0
],
[
374.0,
65.0
],
[
376.0,
65.0
],
[
377.0,
64.0
],
[
378.0,
65.0
],
[
392.0,
65.0
],
[
393.0,
66.0
],
[
394.0,
66.0
],
[
396.0,
64.0
],
[
396.0,
62.0
],
[
397.0,
61.0
],
[
397.0,
54.0
],
[
398.0,
53.0
],
[
398.0,
48.0
],
[
399.0,
47.0
],
[
399.0,
43.0
],
[
400.0,
42.0
],
[
400.0,
38.0
],
[
401.0,
37.0
],
[
401.0,
29.0
],
[
404.0,
26.0
],
[
404.0,
25.0
],
[
405.0,
24.0
],
[
405.0,
19.0
],
[
404.0,
18.0
],
[
404.0,
17.0
],
[
403.0,
16.0
],
[
403.0,
15.0
],
[
402.0,
14.0
],
[
402.0,
13.0
],
[
400.0,
11.0
],
[
400.0,
10.0
],
[
399.0,
10.0
],
[
398.0,
9.0
],
[
391.0,
9.0
],
[
390.0,
8.0
],
[
382.0,
8.0
],
[
381.0,
9.0
],
[
379.0,
9.0
],
[
378.0,
8.0
],
[
376.0,
8.0
],
[
375.0,
9.0
],
[
374.0,
9.0
],
[
373.0,
8.0
],
[
371.0,
8.0
],
[
370.0,
9.0
],
[
368.0,
9.0
],
[
367.0,
8.0
],
[
364.0,
8.0
],
[
363.0,
9.0
],
[
362.0,
8.0
],
[
360.0,
8.0
],
[
359.0,
9.0
],
[
356.0,
9.0
],
[
355.0,
8.0
],
[
354.0,
9.0
],
[
348.0,
9.0
],
[
347.0,
10.0
],
[
345.0,
10.0
],
[
344.0,
9.0
],
[
343.0,
9.0
],
[
342.0,
10.0
],
[
337.0,
10.0
],
[
336.0,
11.0
],
[
334.0,
11.0
],
[
333.0,
10.0
],
[
332.0,
10.0
],
[
330.0,
12.0
]
],
"group_id": null,
"description": "",
"difficult": false,
"shape_type": "polygon",
"flags": {},
"attributes": {}
},
{
"label": "lawn",
"points": [
[
0.0,
0.0
],
[
0.0,
115.0
],
[
2.0,
116.0
],
[
13.0,
138.0
],
[
24.0,
150.0
],
[
35.0,
157.0
],
[
52.0,
160.0
],
[
76.0,
159.0
],
[
83.0,
152.0
],
[
89.0,
143.0
],
[
93.0,
130.0
],
[
92.0,
128.0
],
[
93.0,
120.0
],
[
95.0,
118.0
],
[
100.0,
118.0
],
[
109.0,
122.0
],
[
123.0,
122.0
],
[
138.0,
132.0
],
[
150.0,
131.0
],
[
161.0,
124.0
],
[
164.0,
125.0
],
[
211.0,
124.0
],
[
218.0,
126.0
],
[
226.0,
134.0
],
[
229.0,
135.0
],
[
232.0,
139.0
],
[
237.0,
142.0
],
[
248.0,
143.0
],
[
256.0,
140.0
],
[
267.0,
130.0
],
[
270.0,
120.0
],
[
274.0,
115.0
],
[
279.0,
112.0
],
[
286.0,
111.0
],
[
288.0,
109.0
],
[
293.0,
109.0
],
[
294.0,
108.0
],
[
292.0,
104.0
],
[
293.0,
100.0
],
[
298.0,
101.0
],
[
297.0,
105.0
],
[
298.0,
106.0
],
[
311.0,
102.0
],
[
311.0,
101.0
],
[
304.0,
101.0
],
[
301.0,
96.0
],
[
293.0,
98.0
],
[
290.0,
95.0
],
[
290.0,
92.0
],
[
288.0,
89.0
],
[
289.0,
86.0
],
[
288.0,
84.0
],
[
289.0,
81.0
],
[
288.0,
51.0
],
[
284.0,
46.0
],
[
232.0,
22.0
],
[
227.0,
21.0
],
[
208.0,
11.0
],
[
203.0,
10.0
],
[
194.0,
5.0
],
[
182.0,
2.0
],
[
180.0,
0.0
]
],
"group_id": null,
"description": "",
"difficult": false,
"shape_type": "polygon",
"flags": {},
"attributes": {}
}
],
"imagePath": "2.jpg",
"imageData": null,
"imageHeight": 480,
"imageWidth": 640,
"text": ""
}
2.数据转码和划分数据集
把标注的数据转成整数掩码格式数据,可参考子濠师兄的Label2Everything代码 和 B站教程,我自己把代码修改了一下,可以运行以下代码,Dataset_Path是之前标注生成的.json文件和图片的文件夹,修改自己的路径和类别之后,就可以批量转成掩码格式数据并划分训练和测试数据集
import os
import json
import numpy as np
import cv2
import shutil
from tqdm import tqdm
import random
Dataset_Path = '/home/labelme/examples/garden'
# 每个类别的信息及画mask的顺序(按照由大到小,由粗到精的顺序)
class_info = [
{'label': 'dog', 'type': 'polygon', 'color': 1}, # polygon 多段线
{'label': 'person', 'type': 'polygon', 'color': 2},
]
# 按顺序将mask绘制在空白图上
def labelme2mask_single_img(img_path, labelme_json_path):
'''
输入原始图像路径和labelme标注路径,输出 mask
'''
img_bgr = cv2.imread(img_path)
img_mask = np.zeros(img_bgr.shape[:2]) # 创建空白图像 0-背景
with open(labelme_json_path, 'r', encoding='utf-8') as f:code>
labelme = json.load(f)
for one_class in class_info: # 按顺序遍历每一个类别
for each in labelme['shapes']: # 遍历所有标注,找到属于当前类别的标注
if each['label'] == one_class['label']:
if one_class['type'] == 'polygon': # polygon 多段线标注
# 获取点的坐标
points = [np.array(each['points'], dtype=np.int32).reshape((-1, 1, 2))]
# 在空白图上画 mask(闭合区域)
img_mask = cv2.fillPoly(img_mask, points, color=one_class['color'])
elif one_class['type'] == 'line' or one_class['type'] == 'linestrip': # line 或者 linestrip 线段标注
# 获取点的坐标
points = [np.array(each['points'], dtype=np.int32).reshape((-1, 1, 2))]
# 在空白图上画 mask(非闭合区域)
img_mask = cv2.polylines(img_mask, points, isClosed=False, color=one_class['color'],
thickness=one_class['thickness'])
elif one_class['type'] == 'circle': # circle 圆形标注
points = np.array(each['points'], dtype=np.int32)
center_x, center_y = points[0][0], points[0][1] # 圆心点坐标
edge_x, edge_y = points[1][0], points[1][1] # 圆周点坐标
radius = np.linalg.norm(np.array([center_x, center_y] - np.array([edge_x, edge_y]))).astype(
'uint32') # 半径
img_mask = cv2.circle(img_mask, (center_x, center_y), radius, one_class['color'],
one_class['thickness'])
else:
print('未知标注类型', one_class['type'])
return img_mask
os.chdir(Dataset_Path)
os.mkdir('ann_dir')
os.chdir('img_dir')
for img_path in tqdm(os.listdir()):
try:
labelme_json_path = os.path.join('../', 'labelme_jsons', '.'.join(img_path.split('.')[:-1]) + '.json')
img_mask = labelme2mask_single_img(img_path, labelme_json_path)
mask_path = img_path.split('.')[0] + '.png'
cv2.imwrite(os.path.join('../', 'ann_dir', mask_path), img_mask)
except Exception as E:
print(img_path, '转换失败', E)
# 划分训练-测试集
os.chdir(Dataset_Path)
os.mkdir('train')
os.mkdir('val')
test_frac = 0.2 # 测试集比例
random.seed(123) # 随机数种子,便于复现
folder = 'img_dir'
img_paths = os.listdir(folder)
random.shuffle(img_paths) # 随机打乱
val_number = int(len(img_paths) * test_frac) # 测试集文件个数
train_files = img_paths[val_number:] # 训练集文件名列表
val_files = img_paths[:val_number] # 测试集文件名列表
print('数据集文件总数', len(img_paths))
print('训练集文件个数', len(train_files))
print('测试集文件个数', len(val_files))
for each in tqdm(train_files):
src_path = os.path.join(folder, each)
dst_path = os.path.join('train', each)
shutil.move(src_path, dst_path)
for each in tqdm(val_files):
src_path = os.path.join(folder, each)
dst_path = os.path.join('val', each)
shutil.move(src_path, dst_path)
shutil.move('train', 'img_dir/train')
shutil.move('val', 'img_dir/val')
folder = 'ann_dir'
os.mkdir('train')
os.mkdir('val')
for each in tqdm(train_files):
src_path = os.path.join(folder, each.split('.')[0] + '.png')
dst_path = os.path.join('train', each.split('.')[0] + '.png')
shutil.move(src_path, dst_path)
for each in tqdm(val_files):
src_path = os.path.join(folder, each.split('.')[0] + '.png')
dst_path = os.path.join('val', each.split('.')[0] + '.png')
shutil.move(src_path, dst_path)
shutil.move('train', 'ann_dir/train')
shutil.move('val', 'ann_dir/val')
三、模型训练
在开始训练数据之前,我认真地、反复阅读了几篇文章,按照他们的步骤,配置了参数文件训练
超详细!手把手带你轻松用 MMSegmentation 跑语义分割数据集
【Python】mmSegmentation语义分割框架教程(1.x版本)
mmsegmentation 训练自己的数据集
但是结果还是报一些奇怪的错误(KeyError: 'dataset_type is not in the mmseg::dataset registry),我在github上issue反映了具体的问题
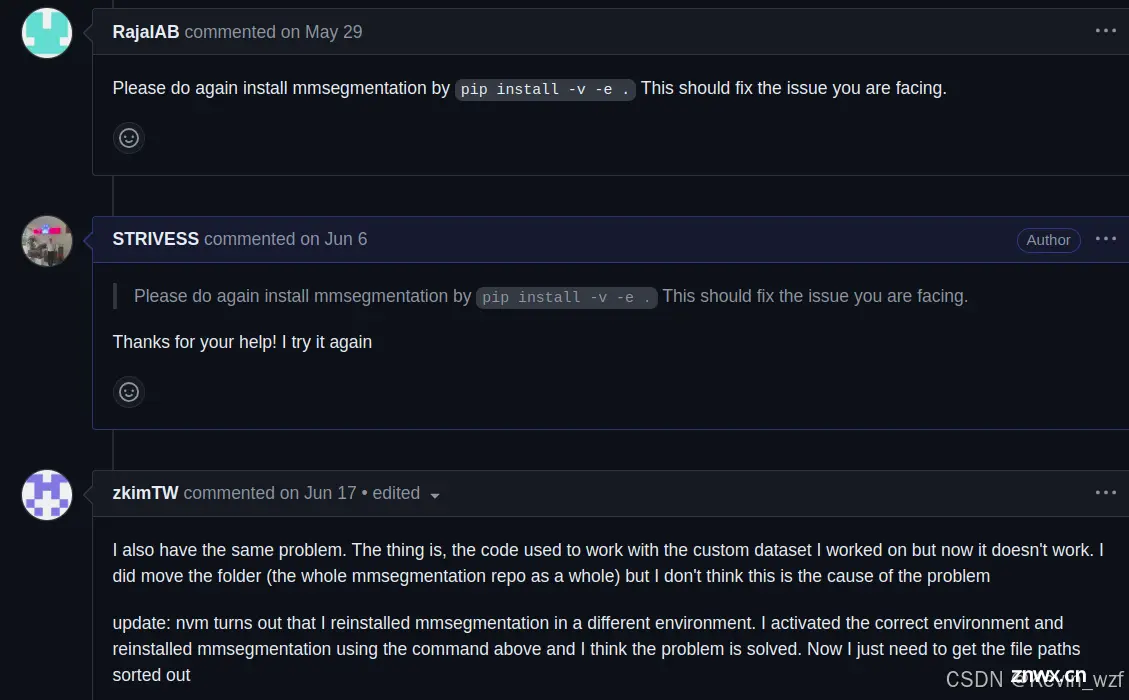
后来我还是参考了教程同济子豪兄——两天搞定人工智能毕业设计之【语义分割】,才顺利训练,感谢他的无私开源(代码链接),让人少走很多弯路
1.配置文件
自己可根据实际情况选择对应网络结构模型来配置文件,示例如下:
mmsegmentation/mmseg/datasets/watermelon_dataset.pymmsegmentation/mmseg/datasets/init.pymmsegmentation/configs/base/datasets/watermelon_segmentation_pipeline.pymmsegmentation/configs/pspnet/pspnet_r50-d8_4xb2-40k_watermelon_segmen-512x1024.py
第一个文件 mmsegmentation/mmseg/datasets/watermelon_dataset.py
大家可以自定义训练数据集名称,以及命名数据集的classes和修改不同类别对应的palette
<code>import mmengine.fileio as fileio
from mmseg.registry import DATASETS
from .basesegdataset import BaseSegDataset
@DATASETS.register_module()
class WatermelonSegmentationDataset(BaseSegDataset):
METAINFO = dict(
classes=('background', 'red', 'green', 'white', 'seed-black', 'seed-white'),
palette=[[127, 127, 127], [200, 0, 0], [0, 200, 0], [144, 238, 144], [30, 30, 30], [251, 189, 8]])
def __init__(self,
img_suffix='.jpg',code>
seg_map_suffix='.png',code>
reduce_zero_label=False,
**kwargs) -> None:
super().__init__(
img_suffix=img_suffix,
seg_map_suffix=seg_map_suffix,
reduce_zero_label=reduce_zero_label,
**kwargs)
assert fileio.exists(
self.data_prefix['img_path'], backend_args=self.backend_args)
在第二个文件 mmsegmentation/mmseg/datasets/init.py 的末尾添加自定义数据集的类名
__all__ = [
'BaseSegDataset', 'BioMedical3DRandomCrop', 'BioMedical3DRandomFlip',
'CityscapesDataset', 'PascalVOCDataset', 'ADE20KDataset',
'PascalContextDataset', 'PascalContextDataset59', 'ChaseDB1Dataset',
'DRIVEDataset', 'HRFDataset', 'STAREDataset', 'DarkZurichDataset',
'NightDrivingDataset', 'COCOStuffDataset', 'LoveDADataset',
'MultiImageMixDataset', 'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset',
'LoadAnnotations', 'RandomCrop', 'SegRescale', 'PhotoMetricDistortion',
'RandomRotate', 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray',
'RandomCutOut', 'RandomMosaic', 'PackSegInputs', 'ResizeToMultiple',
'LoadImageFromNDArray', 'LoadBiomedicalImageFromFile',
'LoadBiomedicalAnnotation', 'LoadBiomedicalData', 'GenerateEdge',
'DecathlonDataset', 'LIPDataset', 'ResizeShortestEdge',
'BioMedicalGaussianNoise', 'BioMedicalGaussianBlur',
'BioMedicalRandomGamma', 'BioMedical3DPad', 'RandomRotFlip',
'SynapseDataset', 'REFUGEDataset', 'MapillaryDataset_v1',
'MapillaryDataset_v2', 'Albu', 'LEVIRCDDataset',
'LoadMultipleRSImageFromFile', 'LoadSingleRSImageFromFile',
'ConcatCDInput', 'BaseCDDataset', 'DSDLSegDataset', 'BDD100KDataset',
'NYUDataset', 'HSIDrive20Dataset', 'WatermelonSegmentationDataset'
]
第三个文件 mmsegmentation/configs/base/datasets/watermelon_segmentation_pipeline.py 是训练数据和预处理配置文件,大家根据自己的情况修改data_root和crop_size,其他可以默认不改
# dataset settings
dataset_type = 'WatermelonSegmentationDataset'
# 数据集路径(相对于mmsegmentation主目录)
data_root = '/home/deep_learning_collection/mmsegmentation/data/watermelon/'
crop_size = (512, 512) # 输入模型的图像裁剪尺寸,一般是128的倍数,越小显存开销越少
train_pipeline = [
dict(type='LoadImageFromFile'),code>
dict(type='LoadAnnotations'),code>
dict(
type='Resize',code>
# scale=(720, 1280),
scale=(2048, 1024),
ratio_range=(0.5, 2.0),
keep_ratio=True),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),code>
dict(type='RandomFlip', prob=0.5),code>
dict(type='PhotoMetricDistortion'),code>
dict(type='PackSegInputs')code>
]
test_pipeline = [
dict(type='LoadImageFromFile'),code>
# dict(type='Resize', scale=(720, 1280), keep_ratio=True),code>
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),code>
# add loading annotation after ``Resize`` because ground truth
# does not need to do resize data transform
dict(type='LoadAnnotations'),code>
dict(type='PackSegInputs')code>
]
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
tta_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),code>
dict(
type='TestTimeAug',code>
transforms=[[
dict(type='Resize', scale_factor=r, keep_ratio=True)code>
for r in img_ratios
],
[
dict(type='RandomFlip', prob=0., direction='horizontal'),code>
dict(type='RandomFlip', prob=1., direction='horizontal')code>
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]])code>
]
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='InfiniteSampler', shuffle=True),code>
dataset=dict(
type='dataset_type',code>
data_root='data_root',code>
data_prefix=dict(
img_path='img_dir/train', seg_map_path='ann_dir/train'),code>
pipeline='train_pipeline'))code>
val_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),code>
dataset=dict(
type='dataset_type',code>
data_root='data_root',code>
data_prefix=dict(
img_path='img_dir/val', seg_map_path='ann_dir/val'),code>
pipeline='test_pipeline'))code>
test_dataloader = 'val_dataloader'
# val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'], ignore_index=2)code>
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice', 'mFscore'])code>
test_evaluator = val_evaluator
第四个文件 mmsegmentation/configs/pspnet/pspnet_r50-d8_4xb2-40k_watermelon_segmen-512x1024.py,是调用网络模型和之前配置好的文件
# _base_ = [
# '../_base_/models/pspnet_r50-d8.py', '../_base_/datasets/lawn_segmentation_pipeline.py',
# '../_base_/default_runtime.py', '../_base_/schedules/schedule_40k.py'
# ]
_base_ = [
'/home/deep_learning_collection/mmsegmentation/configs/_base_/models/pspnet_r50-d8.py',
'/home/deep_learning_collection/mmsegmentation/configs/_base_/datasets/watermelon_segmentation_pipeline.py',
'/home/deep_learning_collection/mmsegmentation/configs/_base_/default_runtime.py',
'/home/deep_learning_collection/mmsegmentation/configs/_base_/schedules/schedule_40k.py'
]
crop_size = (512, 1024)
data_preprocessor = dict(size=crop_size)
model = dict(data_preprocessor=data_preprocessor)
运行以下代码,就会生成一个包含所有配置好训练参数等信息的文件,其实就会开始愉快地训练
python3 tools/train.py configs/pspnet/pspnet_r50-d8_4xb2-40k_watermenlon_segmen-512x1024.py
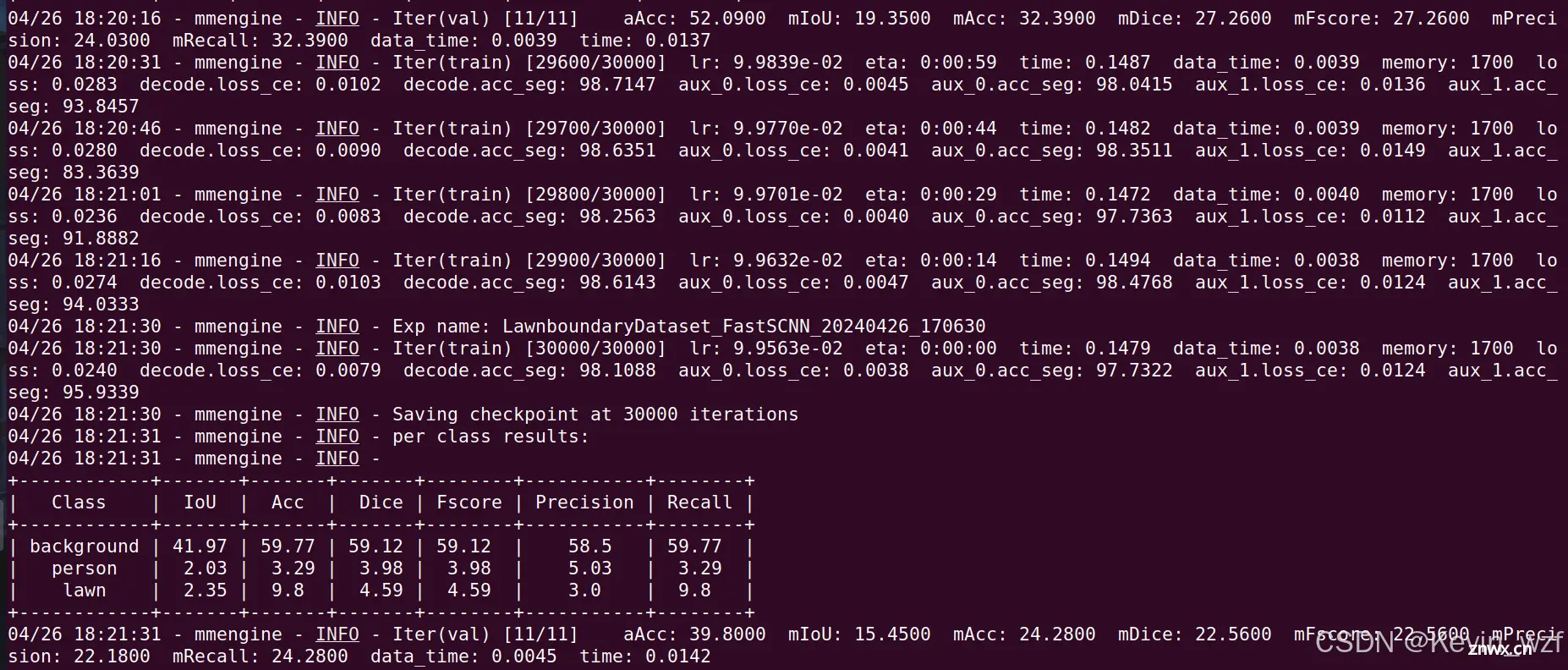
2.注意事项
但是我这边不知道为什么训练的时候出现最开始提及的错误,后来我这边把所有之前的配置信息写在一个代码文件,直接运行,就跑通了,只要修改好data_root,crop_size,dataset_type名称,以及train/val/test对应的type类型,训练次数可以根据实际情况调整,train_cfg = dict(max_iters=30000, type='IterBasedTrainLoop', val_interval=1000),其他可以默认不改。
<code>crop_size = (
512,
512,
)
data_preprocessor = dict(
bgr_to_rgb=True,
mean=[
123.675,
116.28,
103.53,
],
pad_val=0,
seg_pad_val=255,
size=(
512,
1024,
),
std=[
58.395,
57.12,
57.375,
],
type='SegDataPreProcessor')code>
data_root = '/home/deep_learning_collection/mmsegmentation/data/watermelon/'
dataset_type = 'WatermelonSegmentationDataset'
default_hooks = dict(
checkpoint=dict(
by_epoch=False,
interval=2500,
max_keep_ckpts=2,
save_best='mIoU',code>
type='CheckpointHook'),code>
logger=dict(interval=100, log_metric_by_epoch=False, type='LoggerHook'),code>
param_scheduler=dict(type='ParamSchedulerHook'),code>
sampler_seed=dict(type='DistSamplerSeedHook'),code>
timer=dict(type='IterTimerHook'),code>
visualization=dict(type='SegVisualizationHook'))code>
default_scope = 'mmseg'
env_cfg = dict(
cudnn_benchmark=True,
dist_cfg=dict(backend='nccl'),code>
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0))code>
img_ratios = [
0.5,
0.75,
1.0,
1.25,
1.5,
1.75,
]
load_from = None
log_level = 'INFO'
log_processor = dict(by_epoch=False)
model = dict(
auxiliary_head=[
dict(
align_corners=False,
channels=32,
concat_input=False,
in_channels=128,
in_index=-2,
loss_decode=dict(
loss_weight=0.4, type='CrossEntropyLoss', use_sigmoid=True),code>
norm_cfg=dict(requires_grad=True, type='BN'),code>
num_classes=2,
num_convs=1,
type='FCNHead'),code>
dict(
align_corners=False,
channels=32,
concat_input=False,
in_channels=64,
in_index=-3,
loss_decode=dict(
loss_weight=0.4, type='CrossEntropyLoss', use_sigmoid=True),code>
norm_cfg=dict(requires_grad=True, type='BN'),code>
num_classes=2,
num_convs=1,
type='FCNHead'),code>
],
backbone=dict(
align_corners=False,
downsample_dw_channels=(
32,
48,
),
fusion_out_channels=128,
global_block_channels=(
64,
96,
128,
),
global_block_strides=(
2,
2,
1,
),
global_in_channels=64,
global_out_channels=128,
higher_in_channels=64,
lower_in_channels=128,
norm_cfg=dict(requires_grad=True, type='BN'),code>
out_indices=(
0,
1,
2,
),
type='FastSCNN'),code>
data_preprocessor=dict(
bgr_to_rgb=True,
mean=[
123.675,
116.28,
103.53,
],
pad_val=0,
seg_pad_val=255,
size=(
512,
1024,
),
std=[
58.395,
57.12,
57.375,
],
type='SegDataPreProcessor'),code>
decode_head=dict(
align_corners=False,
channels=128,
concat_input=False,
in_channels=128,
in_index=-1,
loss_decode=dict(
loss_weight=1, type='CrossEntropyLoss', use_sigmoid=True),code>
norm_cfg=dict(requires_grad=True, type='BN'),code>
num_classes=2,
type='DepthwiseSeparableFCNHead'),code>
test_cfg=dict(mode='whole'),code>
train_cfg=dict(),
type='EncoderDecoder')code>
norm_cfg = dict(requires_grad=True, type='BN')code>
optim_wrapper = dict(
clip_grad=None,
optimizer=dict(lr=0.12, momentum=0.9, type='SGD', weight_decay=4e-05),code>
type='OptimWrapper')code>
optimizer = dict(lr=0.12, momentum=0.9, type='SGD', weight_decay=4e-05)code>
param_scheduler = [
dict(
begin=0,
by_epoch=False,
end=160000,
eta_min=0.0001,
power=0.9,
type='PolyLR'),code>
]
randomness = dict(seed=0)
resume = False
test_cfg = dict(type='TestLoop')code>
test_dataloader = dict(
batch_size=8,
dataset=dict(
data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),code>
data_root='/home/deep_learning_collection/mmsegmentation/data/watermelon/',code>
pipeline=[
dict(type='LoadImageFromFile'),code>
dict(keep_ratio=True, scale=(
2048,
1024,
), type='Resize'),code>
dict(type='LoadAnnotations'),code>
dict(type='PackSegInputs'),code>
],
type='WatermelonSegmentationDataset'),code>
num_workers=4,
persistent_workers=True,
sampler=dict(shuffle=False, type='DefaultSampler'))code>
test_evaluator = dict(
iou_metrics=[
'mIoU',
'mDice',
'mFscore',
], type='IoUMetric')code>
test_pipeline = [
dict(type='LoadImageFromFile'),code>
dict(keep_ratio=True, scale=(
2048,
1024,
), type='Resize'),code>
dict(type='LoadAnnotations'),code>
dict(type='PackSegInputs'),code>
]
train_cfg = dict(max_iters=30000, type='IterBasedTrainLoop', val_interval=1000)code>
train_dataloader = dict(
batch_size=16,
dataset=dict(
data_prefix=dict(
img_path='img_dir/train', seg_map_path='ann_dir/train'),code>
data_root='/home/deep_learning_collection/mmsegmentation/data/watermelon/',code>
pipeline=[
dict(type='LoadImageFromFile'),code>
dict(type='LoadAnnotations'),code>
dict(
keep_ratio=True,
ratio_range=(
0.5,
2.0,
),
scale=(
2048,
1024,
),
type='RandomResize'),code>
dict(
cat_max_ratio=0.75, crop_size=(
512,
512,
), type='RandomCrop'),code>
dict(prob=0.5, type='RandomFlip'),code>
dict(type='PhotoMetricDistortion'),code>
dict(type='PackSegInputs'),code>
],
type='WatermelonSegmentationDataset'),code>
num_workers=8,
persistent_workers=True,
sampler=dict(shuffle=True, type='InfiniteSampler'))code>
train_pipeline = [
dict(type='LoadImageFromFile'),code>
dict(type='LoadAnnotations'),code>
dict(
keep_ratio=True,
ratio_range=(
0.5,
2.0,
),
scale=(
2048,
1024,
),
type='RandomResize'),code>
dict(cat_max_ratio=0.75, crop_size=(
512,
512,
), type='RandomCrop'),code>
dict(prob=0.5, type='RandomFlip'),code>
dict(type='PhotoMetricDistortion'),code>
dict(type='PackSegInputs'),code>
]
tta_model = dict(type='SegTTAModel')code>
tta_pipeline = [
dict(file_client_args=dict(backend='disk'), type='LoadImageFromFile'),code>
dict(
transforms=[
[
dict(keep_ratio=True, scale_factor=0.5, type='Resize'),code>
dict(keep_ratio=True, scale_factor=0.75, type='Resize'),code>
dict(keep_ratio=True, scale_factor=1.0, type='Resize'),code>
dict(keep_ratio=True, scale_factor=1.25, type='Resize'),code>
dict(keep_ratio=True, scale_factor=1.5, type='Resize'),code>
dict(keep_ratio=True, scale_factor=1.75, type='Resize'),code>
],
[
dict(direction='horizontal', prob=0.0, type='RandomFlip'),code>
dict(direction='horizontal', prob=1.0, type='RandomFlip'),code>
],
[
dict(type='LoadAnnotations'),code>
],
[
dict(type='PackSegInputs'),code>
],
],
type='TestTimeAug'),code>
]
val_cfg = dict(type='ValLoop')code>
val_dataloader = dict(
batch_size=8,
dataset=dict(
data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),code>
data_root='/home/deep_learning_collection/mmsegmentation/data/watermelon/',code>
pipeline=[
dict(type='LoadImageFromFile'),code>
dict(keep_ratio=True, scale=(
2048,
1024,
), type='Resize'),code>
dict(type='LoadAnnotations'),code>
dict(type='PackSegInputs'),code>
],
type='WatermelonSegmentationDataset'),code>
num_workers=4,
persistent_workers=True,
sampler=dict(shuffle=False, type='DefaultSampler'))code>
val_evaluator = dict(
iou_metrics=[
'mIoU',
'mDice',
'mFscore',
], type='IoUMetric')code>
vis_backends = [
dict(type='LocalVisBackend'),code>
]
visualizer = dict(
name='visualizer',code>
type='SegLocalVisualizer',code>
vis_backends=[
dict(type='LocalVisBackend'),code>
])
work_dir = '/home/deep_learning_collection/mmsegmentation/outputs/watermenlon_FastSCNN'
四、模型推理预测
这里提供单张图片、视频流、接入摄像头的推理预测代码,只要把上述的运行代码文件+训练好权重模型对应放好,就可以正常使用了
1.单张图片推理
import numpy as np
import matplotlib.pyplot as plt
from mmseg.apis import init_model, inference_model, show_result_pyplot
import mmcv
import cv2
# 模型 config 配置文件
config_file = '/home/mmsegmentation/Zihao-Configs/ZihaoDataset_FastSCNN_20230818.py'
# 模型 checkpoint 权重文件
checkpoint_file = '/home/mmsegmentation/outputs/20240425_211259/best_mIoU_iter_30000.pth'
# device = 'cpu'
device = 'cuda:0'
model = init_model(config_file, checkpoint_file, device=device)
img_path = '/home/mmsegmentation/data/Watermelon87_Semantic_Seg_Mask/img_dir/val/watermelon-medium.jpg'
img_bgr = cv2.imread(img_path)
result = inference_model(model, img_bgr)
result.keys()
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
pred_mask.shape
np.unique(pred_mask)
plt.figure(figsize=(8, 8))
plt.imshow(pred_mask)
plt.savefig('outputs/K1-1.jpg')
plt.show()
2.视频流推理
import time
import numpy as np
from tqdm import tqdm
import cv2
import moviepy.editor as mp
import mmcv
from mmseg.apis import init_model, inference_model
def init():
config_file ='/home/mmsegmentation/Zihao-Configs/WatermelonDataset_FastSCNN.py'
checkpoint_file ='/home/mmsegmentation/checkpoint/WatermelonDataset_FastSCNN.pth'
# 计算硬件
# device = 'cpu'
device = 'cuda:0'
global model
model = init_model(config_file, checkpoint_file, device=device)
palette = [
['background', [127, 127, 127]],
['red', [200, 0, 0]],
['green', [0, 200, 0]],
['white', [144, 238, 144]],
['seed-black', [30, 30, 30]],
['seed-white', [251, 189, 8]]
]
global palette_dict
palette_dict = {}
for idx, each in enumerate(palette):
palette_dict[idx] = each[1]
global opacity
opacity = 0.4 # 透明度,越大越接近原图
def process_frame(img_bgr):
# 语义分割预测
result = inference_model(model, img_bgr)
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
# 将预测的整数ID,映射为对应类别的颜色
pred_mask_bgr = np.zeros((pred_mask.shape[0], pred_mask.shape[1], 3))
for idx in palette_dict.keys():
pred_mask_bgr[np.where(pred_mask == idx)] = palette_dict[idx]
pred_mask_bgr = pred_mask_bgr.astype('uint8')
# 将语义分割预测图和原图叠加显示
pred_viz = cv2.addWeighted(img_bgr, opacity, pred_mask_bgr, 1 - opacity, 0)
return pred_viz
def generate_video(input_path='videos/robot.mp4'):code>
filehead = input_path.split('/')[-1]
# print("filehead", filehead)
output_path = "/home/Video/watermelon/out-" + filehead
print('视频开始处理', input_path)
# 获取视频总帧数
cap = cv2.VideoCapture(input_path)
frame_count = 0
while (cap.isOpened()):
success, frame = cap.read()
frame_count += 1
if not success:
break
cap.release()
print('视频总帧数为', frame_count)
# cv2.namedWindow('Crack Detection and Measurement Video Processing')
cap = cv2.VideoCapture(input_path)
frame_size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
out = cv2.VideoWriter(output_path, fourcc, fps, (int(frame_size[0]), int(frame_size[1])))
# 进度条绑定视频总帧数
with tqdm(total=frame_count - 1) as pbar:
try:
while (cap.isOpened()):
success, frame = cap.read()
if not success:
break
# 处理帧
# frame_path = './temp_frame.png'
# cv2.imwrite(frame_path, frame)
try:
frame = process_frame(frame)
except:
print('报错!')
pass
if success == True:
# cv2.imshow('Video Processing', frame)
out.write(frame)
# 进度条更新一帧
pbar.update(1)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
except:
print('中途中断')
pass
cv2.destroyAllWindows()
out.release()
cap.release()
print('视频已保存', output_path)
def main():
init()
generate_video(input_path='/home/Video/watermelon_seg.mp4')code>
if __name__ == "__main__":
main()
3.摄像头推理预测
(此处我增加边缘检测,可以提取轮廓)
import time
import numpy as np
import cv2
import os
import matplotlib.pyplot as plt
import mmcv
from mmseg.apis import init_model, inference_model
import serial
import time
import threading
# 载入训练好的模型
# 模型 config 配置文件
def init():
config_file = '/home/mmsegmentation/Zihao-Configs/WatermelonDataset_FastSCNN.py'
checkpoint_file = '/home/mmsegmentation/checkpoint/WatermelonDataset_FastSCNN.pth'
# device = 'cpu'
device = 'cuda:0'
global model
model = init_model(config_file, checkpoint_file, device=device)
palette = [
['background', [127, 127, 127]],
['red', [200, 0, 0]],
['green', [0, 200, 0]],
['white', [144, 238, 144]],
['seed-black', [30, 30, 30]],
['seed-white', [251, 189, 8]]
]
global palette_dict
palette_dict = {}
for idx, each in enumerate(palette):
palette_dict[idx] = each[1]
global opacity
opacity = 0.4 # 透明度,越大越接近原图
class Canny:
def gaussian_blur(self, image, kernel_size):
blurred = cv2.GaussianBlur(image, (kernel_size, kernel_size), 0)
return blurred
def erode(self, image, kernel_size, iterations=1):
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_size, kernel_size))
eroded = cv2.erode(image, kernel, iterations=iterations)
return eroded
def dilate(self, image, kernel_size, iterations=1):
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_size, kernel_size))
dilated = cv2.dilate(image, kernel, iterations=iterations)
return dilated
def opening(self, image, kernel_size):
opened = cv2.morphologyEx(image, cv2.MORPH_OPEN,
cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_size, kernel_size)))
return opened
def closing(self, image, kernel_size):
closed = cv2.morphologyEx(image, cv2.MORPH_CLOSE,
cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_size, kernel_size)))
return closed
def canny_edge_detection(self, image, threshold1, threshold2):
edges = cv2.Canny(image, threshold1, threshold2)
return edges
canny = Canny()
def Canny_detect(seg_image):
# 在进行边缘检测前,将图像通道转成RGB
seg_image = cv2.cvtColor(seg_image, cv2.COLOR_BGR2RGB)
blurred = canny.gaussian_blur(seg_image, 9)
eroded = canny.erode(blurred, 9, 2)
dilated = canny.dilate(eroded, 9, 2)
opened = canny.opening(dilated, 9)
closed = canny.closing(opened, 9)
# Canny边缘检测
edges = canny.canny_edge_detection(closed, 100, 200)
return edges
# 逐帧处理函数
def process_frame(img_bgr):
global message
# 记录该帧开始处理的时间
start_time = time.time()
# 语义分割预测
result = inference_model(model, img_bgr)
# 提取了预测的语义分割掩码,并将其转换为 NumPy 数组,pred_mask 是一个二维数组,表示图像中每个像素的预测类别
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
# 创建了一个与 pred_mask 相同大小的全零数组 pred_mask_bgr,用于存储彩色掩码图像
pred_mask_bgr = np.zeros((pred_mask.shape[0], pred_mask.shape[1], 3))
# 将预测的整数ID,映射为对应类别的颜色
for idx in palette_dict.keys():
# 将 pred_mask 中值为 idx 的像素索引位置,对应的 pred_mask_bgr 中的像素值设置为 palette_dict[idx],
# 即根据类别标签将掩码转换为彩色图像
pred_mask_bgr[np.where(pred_mask == idx)] = palette_dict[idx]
# 将 pred_mask_bgr 数组的数据类型转换为无符号8位整数(uint8),以便在后续使用中正确表示图像的像素值范围
# pred_mask_bgr是语义分割预测图像
pred_mask_bgr = pred_mask_bgr.astype('uint8')
# 把语义分割预测图像进行图像滤波处理、边缘检测,canny边缘检测后图像变成了二值化图像
canny_viz = Canny_detect(pred_mask_bgr)
# 将语义分割预测图和原图叠加显示
pred_viz = cv2.addWeighted(img_bgr, opacity, pred_mask_bgr, 1 - opacity, 0)
# 调整尺寸,确保原图和处理后的图像具有相同的尺寸
canny_viz = cv2.resize(canny_viz, (pred_viz.shape[1], pred_viz.shape[0]))
# 转换颜色空间,确保原图和处理后的图像具有相同的通道数
canny_viz = cv2.cvtColor(canny_viz, cv2.COLOR_GRAY2RGB)
# 合并语义分割图像和canny边缘检测图像,横向显示
merged_image_horizontal = cv2.hconcat([pred_viz, canny_viz])
end_time = time.time()
FPS = 1 / (end_time - start_time)
# 在画面上写字:图片,字符串,左上角坐标,字体,字体大小,颜色,字体粗细
scaler = 1 # 文字大小
FPS_string = 'FPS {:.2f}'.format(FPS)
img_bgr = cv2.putText(merged_image_horizontal, FPS_string, (10 * scaler, 20 * scaler), cv2.FONT_HERSHEY_SIMPLEX, 0.75 * scaler,(255, 0, 255), 2 * scaler)
return img_bgr
def main():
init()
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(0)
try:
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success: # 如果获取画面不成功,则退出
print('获取画面不成功,退出')
break
frame = process_frame(frame)
cv2.namedWindow('my_window', cv2.WINDOW_NORMAL)
cv2.resizeWindow('my_window', int(frame.shape[1] * 1.4), int(frame.shape[0] * 1.4))
cv2.imshow('my_window', frame)
key_pressed = cv2.waitKey(60) # 每隔多少毫秒毫秒,获取键盘哪个键被按下
if key_pressed in [ord('q'), 27]: # 按键盘上的q或esc退出(在英文输入法下)
break
finally:
ser.close()
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
致谢
最后感谢子濠师兄的开源作品以及 MMLab 实验室开源的框架和平台,让小白也能快速上手,感受深度学习的强大和 AI 带给人们的便利性,如果对大家有帮助,麻烦点个赞,我会不定期更新一些好的文章,与君共勉。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。