【Python&语义分割】Segment Anything(SAM)模型详细使用教程+代码解释(一)
RS迷途小书童 2024-07-04 14:05:02 阅读 70
原创作者:RS迷途小书童
博客地址:https://blog.csdn.net/m0_56729804?type=blog
1 Segment Anything介绍
1.1 概况
Meta AI 公司的 Segment Anything 模型是一项革命性的技术,该模型能够根据文本指令或图像识别,实现对任意物体的识别和分割。这一模型的推出,将极大地推动计算机视觉领域的发展,并使得图像分割技术进一步普及化。
论文地址:https://arxiv.org/abs/2304.02643
项目地址:Segment Anything
1.2 使用方法
具体使用方法上,Segment Anything 提供了简单易用的接口,用户只需要通过提示,即可进行物体识别和分割操作。例如在图片处理中,用户可以通过 Hover & Click 或 Box 等方式来选取物体。值得一提的是,SAM 还支持通过上传自己的图片进行物体分割操作,提取物体用时仅需数秒。
总的来说,Meta AI 的 Segment Anything 模型为我们提供了一种全新的物体识别和分割方式,其强大的泛化能力和广泛的应用前景将极大地推动计算机视觉领域的发展。未来,我们期待看到更多基于 Segment Anything 的创新应用,以及在科学图像分析、照片编辑等领域的广泛应用。

2 代码复现+讲解
2.1 用于生成显示掩膜的函数(初始化)
里面包含三个封装好的函数,一个是生成掩膜(分割的轮廓)的函数,一个是显示标记点(自己选择需要分割的目标)的函数,一个是显示标记框(需要分割的目标)的函数。
<code>import cv2
import sys
import torch
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',code>
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',code>
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))code>
2.2 模型预加载
这里包含的代码是打开图片,转换图片格式以及加载模型。注意这里的模型要和你定义的模型类型保持一致(官网给出了三种模型)。模型比较大,我已经将模型以及Segment Anything的包下载至网盘中了,需要的可以在我之前发布的SAM模型安装教程的文章2.2.2小节中下载:【Python&语义分割】Segment Anything(SAM)模型介绍&安装教程
image = cv2.imread(r'B:/truck.jpg') # 读取的图像以NumPy数组的形式存储在变量image中
print("[%s]正在转换图片格式......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 将图像从BGR颜色空间转换为RGB颜色空间,还原图片色彩(图像处理库所认同的格式)
print("[%s]正在初始化模型参数......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
# plt.figure(figsize=(10, 10)) # 创建一个新的图形窗口,设置其大小为10x10英寸
# plt.imshow(image) # 使用imshow函数在创建的图形窗口中显示图像
# plt.axis('on') # 开启图像坐标轴,使得图像下的像素坐标可以显示出来
# plt.show() # 显示已经创建的图形窗口和其中的内容
sys.path.append("..") # 将当前路径上一级目录添加到sys.path列表,这里模型使用绝对路径所以这行没啥用
sam_checkpoint = "G:/Neat Download Manager/Misc/sam_vit_b_01ec64.pth" # 定义模型路径
model_type = "vit_b" # 定义模型类型
device = "cuda" # "cpu" or "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device) # 定义模型参数
predictor = SamPredictor(sam) # 调用预测模型
predictor.set_image(image)
# 调用`SamPredictor.set_image`来处理图像以产生一个图像嵌入。`SamPredictor`会记住这个嵌入,并将其用于随后的掩码预测
2.3 单点输入mask,分割一个目标
这里的input_point指你想分割的兴趣点(图片坐标),这里的input_label代表目标的标签,如果你想要分割它input_label的值就为1,如果想排除它则值为0。
# --------------------------------------单点输入--------------------------------------
print("【单点分割阶段】")
print("[%s]正在分割图片......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
input_point = np.array([[250, 187]])
# 单点 prompt 输入格式为(x, y)和并表示出点所带有的标签1(前景点)或0(背景点)。
input_label = np.array([1]) # 点所对应的标签
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()
masks, scores, logit = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True, # 为False时,它将返回一个掩码
)
# print(masks.shape) # (3, 2160, 3840)波段,高,宽
for i, (mask, score) in enumerate(zip(masks, scores)):
# 三个置信度不同的图
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i + 1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()
单点输入时,会出现三种不同置信度结果的图,可以自己选择。



2.4 多点输入masks,分割一/多个目标
这里的目标点可以同时输入多个,不同的lable可以控制不同的分割效果。如果label均为1,则将两个点分割成同一目标(单个输入点不明确,需要让模型返回了与其一致的多个对象)。如果label一个为1,一个为0则分割一个,排除一个。下面第一张图是label均为1的效果,第二张图为一个1,一个0的效果。此外还可以将先前迭代的掩码(logits值)提供给模型以帮助预测。
<code># --------------------------------------多点输入--------------------------------------
print("【多点分割阶段】")
print("[%s]正在分割图片......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
input_point = np.array([[250, 184], [562, 322]])
input_label = np.array([1, 0]) # input_label = np.array([1, 0])负点区域,用来排除该点
mask_input = logit[np.argmax(scores), :, :] # Choose the model's best mask
# 将先前迭代的掩码logit值提供给模型以帮助预测
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
mask_input=mask_input[None, :, :],
multimask_output=False,
)
# print(masks.shape) # output: (1, 600, 900)
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()


2.5 矩形输入mask,分割一个目标
SAM支持将xyxy格式(左上和右下角坐标)的矩形作为输入,将框内的主体目标识别出来。
<code># --------------------------------------矩形输入--------------------------------------
print("【矩形分割阶段】")
print("[%s]正在分割图片......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
input_box = np.array([212, 300, 350, 437])
masks, _, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box[None, :],
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
plt.show()

2.6 矩形+点同时输入masks,分割一个目标
点和矩形可以同时输入,只需定义这两种类型的label即可。在这里,这可以用来只选择卡车的轮胎(将车轴部分设置为负点),而不是整个车轮。需要注意的是矩形的label只能为1(正类)。
<code># --------------------------------------点&矩形输入--------------------------------------
print("【单点&矩形分割阶段】")
print("[%s]正在分割图片......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
input_box = np.array([215, 310, 350, 430]) # 只能默认框住正类
input_point = np.array([[287, 375]])
input_label = np.array([0]) # 将点设置为负点
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box,
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

2.7 多个矩形输入masks,分割多个目标
SamPredictor函数可以使用predict_tarch方法对同一图像输入多个提示(点、矩形)。该方法假设输入点已经是tensor张量,且boxes信息与image size相符合(已有来自对象检测器的输出结果)。
SamPredictor函数(也可以使用segment_anything.utils.transforms)可以将矩形信息编码为特征向量(以实现对多个矩形的支持,transformed_boxes),然后预测masks。
<code># --------------------------------------多矩形输入--------------------------------------
print("【多矩形分割阶段】")
print("[%s]正在分割图片......" % datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
input_boxes = torch.tensor([
[75, 275, 1725, 850],
[425, 600, 700, 875],
[1375, 550, 1650, 800],
[1240, 675, 1400, 750],
], device=predictor.device) # 假设为目标检测的预测结果
input_boxes = input_boxes/2
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2])
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
# print(masks.shape) # batch_size,num_predicted_masks_per_input,H,W ------>[4, 1, 600, 900]
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes:
show_box(box.cpu().numpy(), plt.gca())
plt.axis('off')
plt.show()
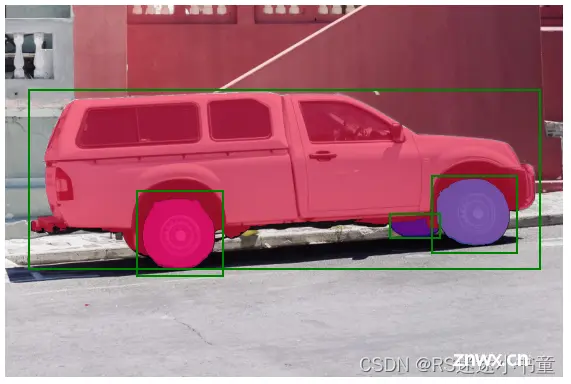
3 总结
3.1 不足之处
以上代码来源于官方的demo,自己修改了一部分。官方的源码只能简单的进行点/矩形输入,每次分割前都需要手动确定目标的图片坐标(x,y)。如果分割做成交互式的会更好,例如我点击图片中的某个点,它就分某个目标。
另外官方的demo并没有保存图片的函数,如果3S工作者或者其他有需要的领域,可能需要保存分割后的mask就需要自己开发。我这里指的是单独保存mask,掩膜叠加底图显示的保存了也没啥用=。=
3.2 改进
官方还有一个全局分割的demo我还没有分享,那个我已经加入了保存mask的代码,所以就没跟这篇文章一起分享,后面会分享给大家。此外我还编了一个单点输入mask的交互式操作的代码,后面都会分享给大家。
总的来说,Segment Anything是真的强,官方的模型不夸张的说真的可以坐到分割万物。我自己拿高分辨率的遥感影像也试了试,建筑、树木、道路都分的还不错。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。