
1.什么是WebScraper。...

定义:深度优先搜索是一种遍历或搜索树或图的算法,从起始节点开始,一直沿着一个分支走到底,再回溯到上一个节点继续搜索下一个分支,直到遍历完所有节点。特点递归:通常用递归实现,或者使用栈来模拟递归过程。内存占用...

不过从数据来看,爬取的数据存在重复的情况,但是此时由于请求次数过多,已经触发了B站的风控策略,暂时没法继续调试了,剩下的去重工作就交给你了,年轻人!B站目前视频搜索结果的分页策略是每页36条数据,假设我们以第4...
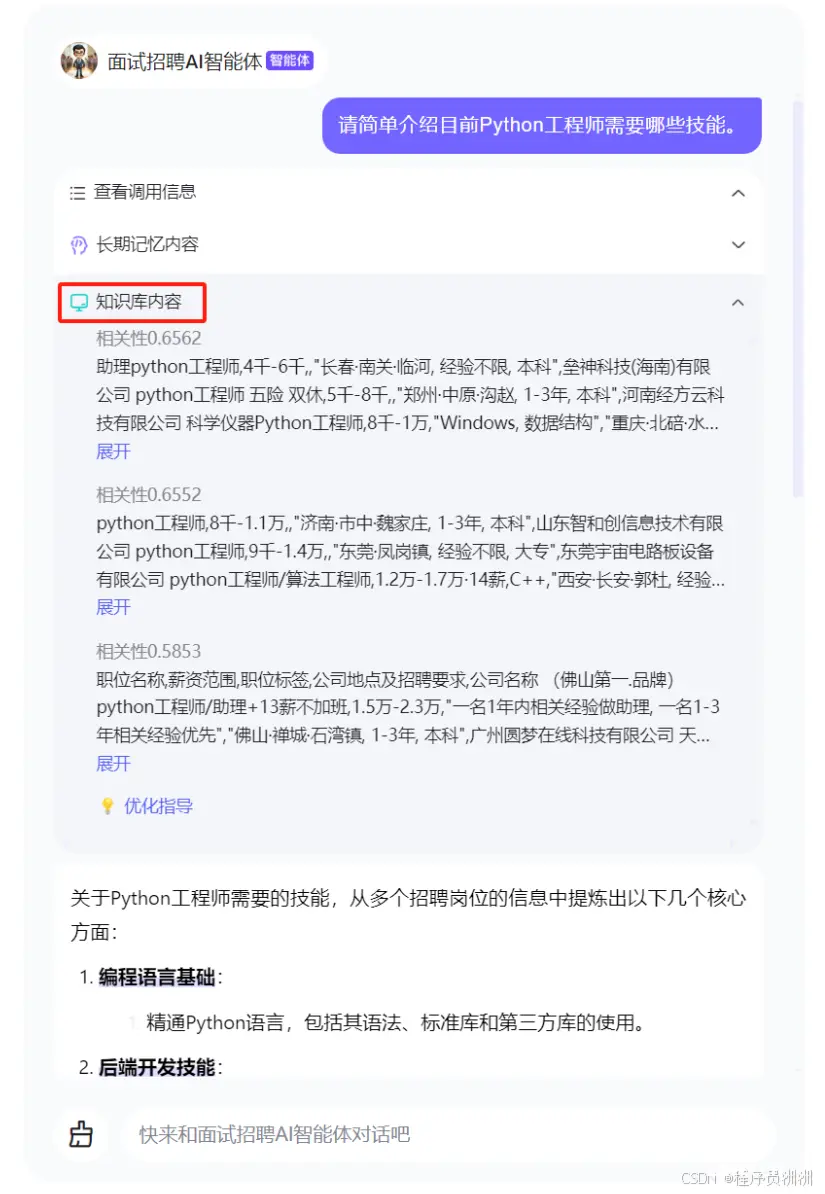
使用亮数据代理IP+Python爬虫批量爬取招聘信息训练面试类百度文心一言AI智能体...
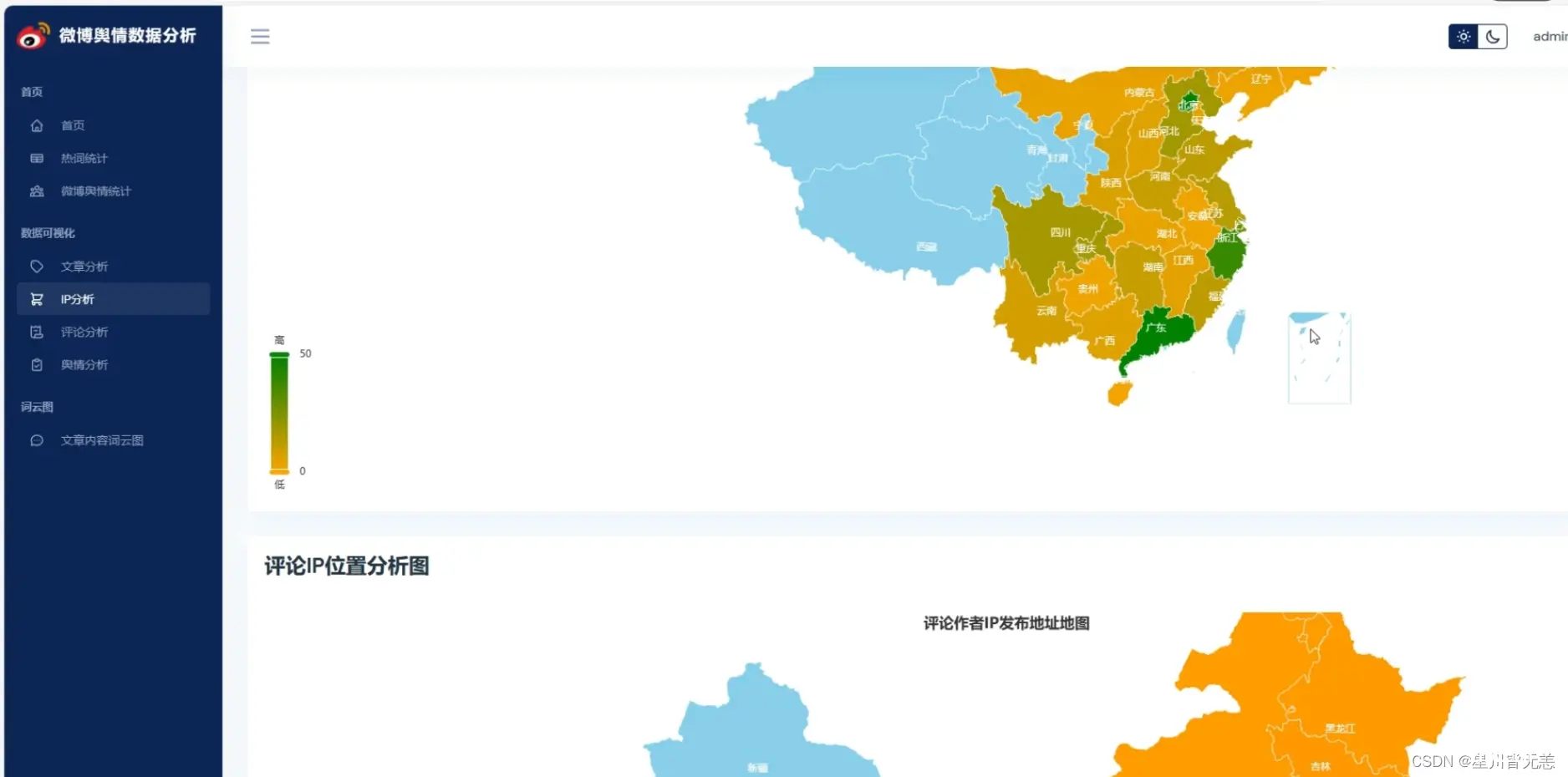
基于Python的微博舆情数据爬虫可视化分析系统,结合了NLP情感分析、爬虫技术和机器学习算法。该系统的主要目标是从微博平台上抓取实时数据,对这些数据进行情感分析,并通过可视化方式呈现分析结果,以帮助用户更好地了...
有用户反馈称使用微软必应搜索和谷歌搜索发现存在不少知乎乱码内容,即搜索结果里知乎内容的标题和正文内容都可能是乱码的,但抓取的正文前面一些段落内容可以正常查看。从最开始知乎屏蔽其他搜索引擎只允许百度和搜狗到必应搜索结果...

request库支持非常丰富的链接访问功能,包括:国际域名和URL获取、HTTP长连接和连接缓存、HTTP会话和Cookie保持、浏览器使用风格的SSL验证、基本的摘要认证、有效的键值对Cook...
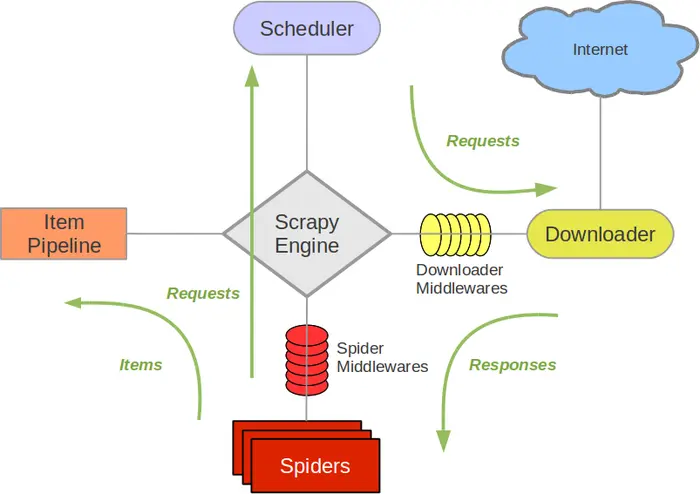
Scrapy是用Python实现的一个为了采集网站数据、提取结构性数据而编写的应用框架。常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过Scrapy框架实现一个爬虫,抓...
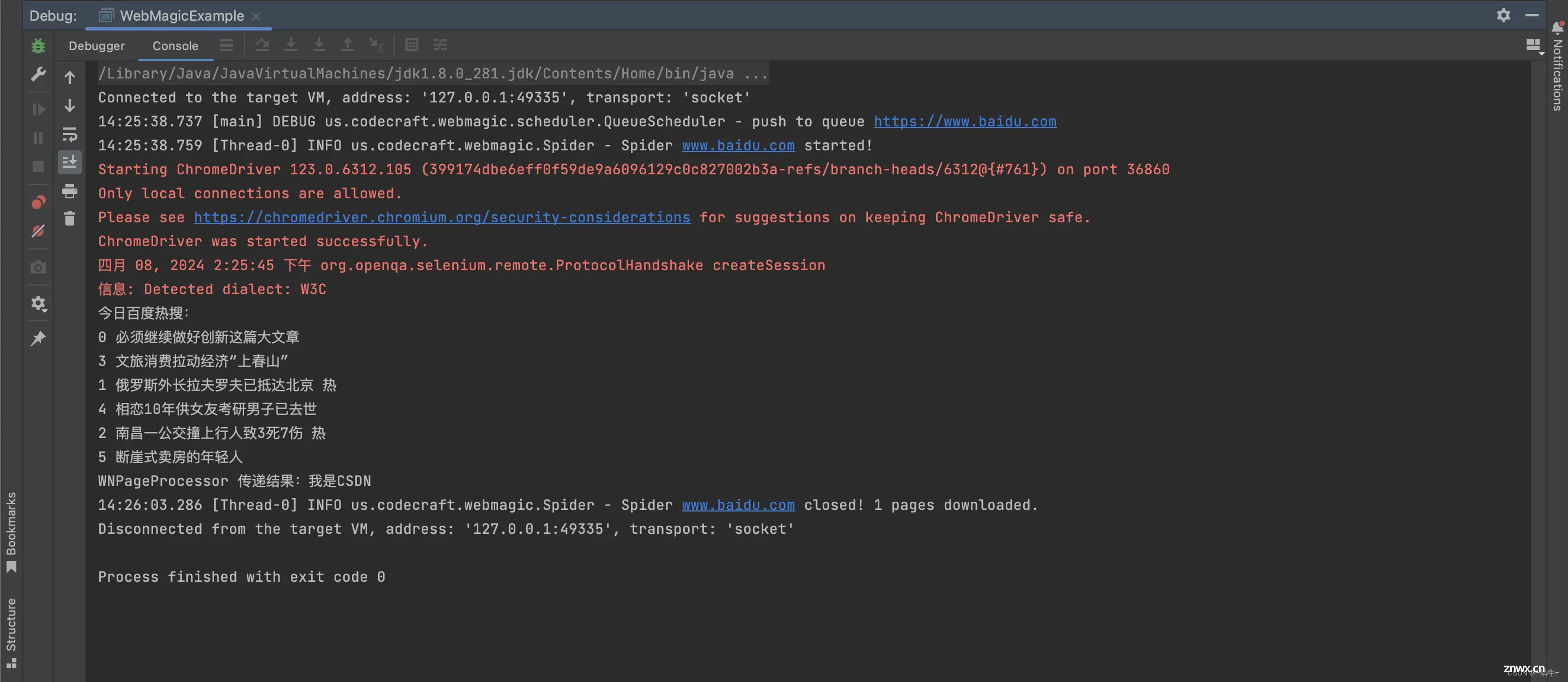
在当今信息爆炸的时代,网络数据的获取和处理变得至关重要。对于Java开发者而言,掌握高效的网页抓取技术是提升数据处理能力的关键。本文将深入探讨三款广受欢迎的Java网页抓取工具:Jsoup、HtmlUnit...
👉Python学习路线汇总👈Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)👉Pytho...