Python之Scrapy爬虫框架安装及使用详解
言程序plus 2024-07-06 12:05:06 阅读 66
声明
文章所涉及的内容仅为学习交流所用。
前言:
Scrapy 是用 Python 实现的一个为了采集网站数据、提取结构性数据而编写的应用框架。常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
一、安装 scrapy
<code>pip install scrapy
安装后,只要在命令终端输入 scrapy,提示类似以下结果,代表已经安装成功

二、Scrapy介绍
1.引擎(Engine)
– 引擎负责控制数据流在系统所有组件中的流向,并在不同的条件时触发相对应的事件。这个组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
2.调度器(Scheduler)
– 调度器从引擎接受请求并将它们加入队列,以便之后引擎需要它们时提供给引擎。初始爬取的URL和后续在网页中获取的待爬取的URL都将放入调度器中,等待爬取,同时调度器会自动去除重复的URL。如果特定的URL不需要去重也可以通过设置实现,如post请求的URL。
3.下载器(Downloader)
– 下载器的主要功能是获取网页内容,提供给引擎和Spiders。
4.Spiders
– Spiders是Scrapy用户编写用于分析响应,并提取Items或额外跟进的URL的一个类。每个Spider负责处理一个(一些)特定网站。
5.Item Pipelines
– Item Pipelines主要功能是处理被Spiders提取出来的Items。典型的处理有清理、验证及持久化(例如存取到数据库中)。当网页被爬虫解析所需的数据存入Items后,将被发送到
项目管道(Pipelines),并经过几个特定的次序处理数据,最后存入本地文件或数据库
6.下载器中间件(Downloader Middlewares)
– 下载器中间件是一组在引擎及下载器之间的特定钩子(specific hook),主要功能是处理下载器传递给引擎的响应(response)。下载器中间件提供了一个简便的机制,通过插
入自定义代码来扩展Scrapy功能。通过设置下载器中间件可以实现爬虫自动更换useragent、IP等功能
7.Spider中间件(Spider Middlewares)
– Spider中间件是一组在引擎及Spiders之间的特定钩子(specific hook),主要功能是处理Spiders的输入(响应)和输出(Items及请求)。Spider中间件提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
各组件之间的数据流向如图所示:
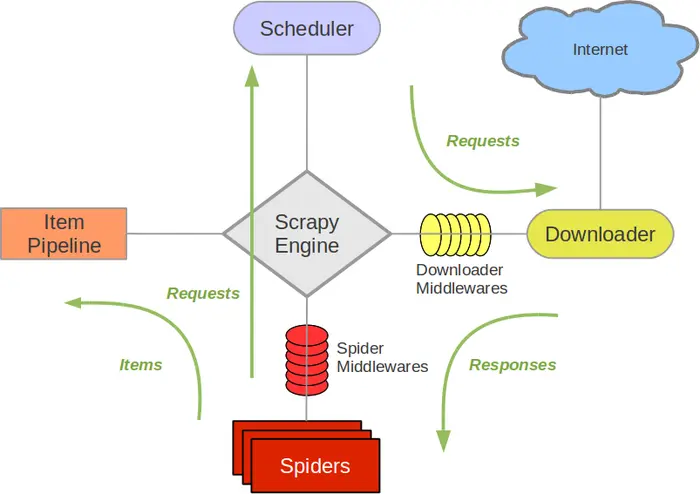
从初始URL开始,Scheduler会将其交给Downloader进行下载下载之后会交给Spider进行分析Spider分析出来的结果有两种一种是需要进一步抓取的链接,如 “下一页”的链接,它们会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline里,进行后期处理(详细分析、过滤、存储等)
三、Scrapy应用示例
1、新建项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
<code>scrapy startproject mySpider
其中: mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
scrapy.cfg: 项目的配置文件。mySpider/: 项目的Python模块,将会从这里引用代码。mySpider/items.py: 项目的目标文件。mySpider/pipelines.py: 项目的管道文件。mySpider/settings.py: 项目的设置文件。mySpider/spiders/: 存储爬虫代码目录。
2、创建爬虫
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
注意:
第一个参数是爬虫名字不是项目名字;
第二个参数是网站域名,是允许爬虫采集的域名。比如:baidu.com 不限制域名 可能爬到 zhihu.com 。后期可以更改,但要先有
生成的目录和文件结果:
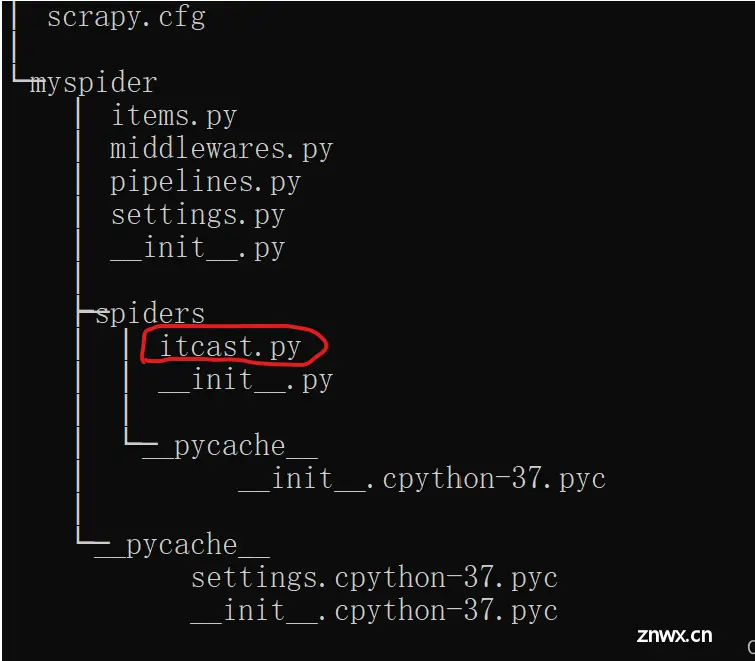
打开 mySpider/spider目录里的 itcast.py,默认代码如下
<code>import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
3、修改代码
# -*- coding: utf-8 -*-
import scrapy
# 以下三行是在 Python2.x版本中解决乱码问题,Python3.x 版本的可以去掉
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class Opp2Spider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.com']
start_urls = ['http://www.itcast.cn/']
def parse(self, response):
# 获取网站标题
context = response.xpath('/html/head/title/text()')
# 提取网站标题
title = context.extract_first()
print(title)
pass
4、执行命令scrapy crawl itcast,可以看到已经采集到标题结果
$ scrapy crawl itcast
...
...
传智播客官网-好口碑IT培训机构,一样的教育,不一样的品质
...
...
5、完善爬虫
完善内容:以采集 http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息为例
1、修改起始url
2、检查域名
3、在parse方法中实现采集逻辑
源代码:
items.py文件
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
itcastSpider.py 文件
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):code>
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
终端中输入命令:
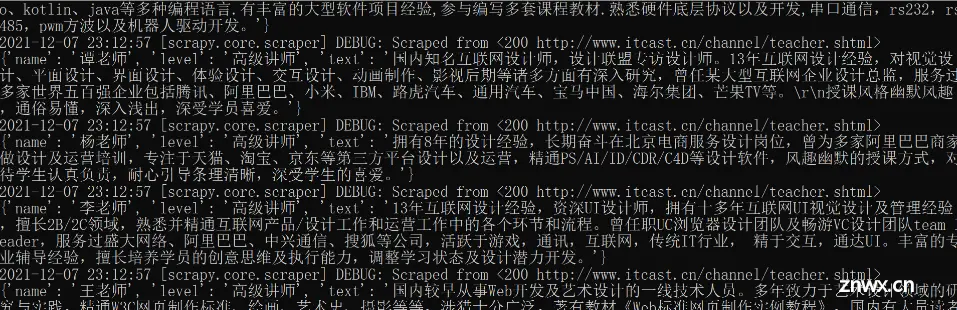
scrapy crawl itcast
部分结果示例:
注意:
scrapy.spider爬虫类中必须有名为parse的解析如果网站结构层次比较复杂,也可以自定义其他解析函数在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内(也就是说域名必须要在allowed_domains里面,否则会被拦截),但是start_urls中的url地址不受这个限制启动爬虫的时候注意启动的位置,要在项目路径下启动parse()函数中使用yield返回数据,解析函数中的yield能够传递的对象只能是:Baseitem,Request,dict,None
6、保存数据在文件中
将pipelines.py中的代码改为:
<code>from itemadapter import ItemAdapter
import json
class MyspiderPipeline:
def __init__(self):
self.file = open('itcast.json', 'w')
# 爬虫文件中提取数据的方法每yield一次item,就会运行一次
# 该方法为固定名称函数
def process_item(self, item, spider):
# print(item)
# 将字典数据序列化
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
# 将数据写入文件
self.file.write(json_data)
# 默认使用完管道后需要将数据返回给引擎
return item
def __del__(self):
self.file.close()
7、运行scrapy
scrapy crawl itcast
执行完命令后,可以看到我们采集的数据保存到了itcast.json中
最后给大家一个福利:

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。