完整且详细的Yolov8复现+训练自己的数据集
咕哥 2024-07-06 12:35:02 阅读 93
Yolov8 的源代码下载:ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)

https://github.com/ultralytics/ultralytics
Yolov8的权重下载:Releases · ultralytics/assets · GitHubUltralytics assets. Contribute to ultralytics/assets development by creating an account on GitHub.

https://github.com/ultralytics/assets/releases
yolov8做了更简单的部署,可以用于检测,分类,分割等,速度更快,精度更高。具体yolov8的复现可以参考:
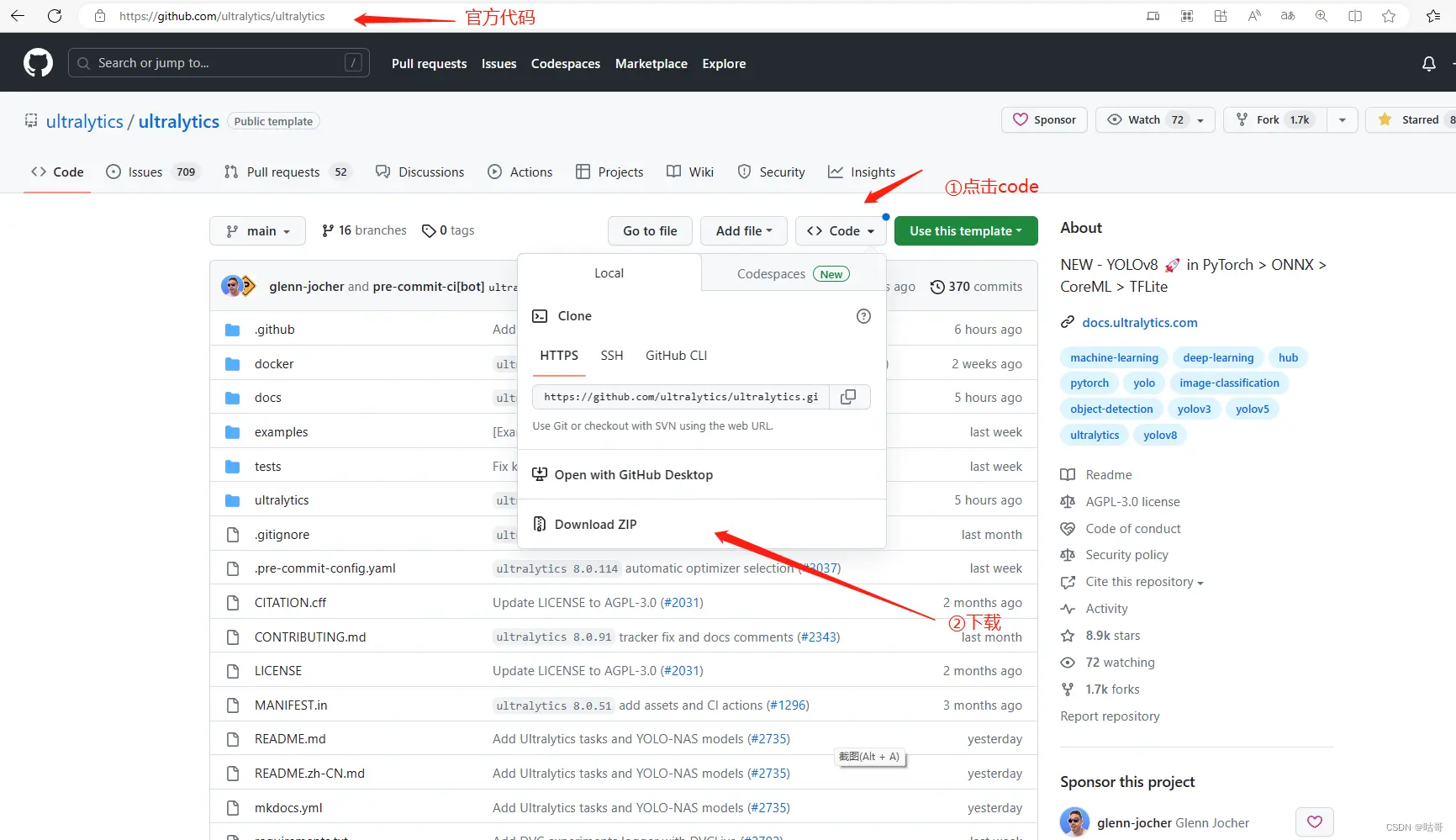
一、代码,权重的下载
1. 打开上面的源代码地址,下载源代码压缩包。
2.下载后解压。
3.权重的下载 :建议点击上面的链接直接下载,后面的predict.py虽然设置了自动下载,但是往往因为网络或者环境配置的问题cut掉。因为作者复现的是检测任务,权重放在detect文件下。

二、配置环境
1.建议每次做新项目都重建一个新环境,避免了各种包的版本的冲突,同时也为了避免在新项目跑通后旧项目又要重新配置环境的麻烦,所以重建环境是不错的选择。
1.打开Anaconda Prompt(如果没有Anaconda,建议下载一个,在配置环境的方面还是很方便的,具体的下载方式参考:(54条消息) 史上最全最详细的Anaconda安装教程_OSurer的博客-CSDN博客
https://blog.csdn.net/wq_ocean_/article/details/103889237?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168653306416782427441050%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168653306416782427441050&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-103889237-null-null.142%5Ev88%5Econtrol,239%5Ev2%5Einsert_chatgpt&utm_term=anaconda%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B&spm=1018.2226.3001.4187 )
2.具体操作:
(1) 创建环境
<code>conda create -n yolov8 python==3.7
(官方要求>=3.7,所以python3.8也完全可以)
(2)激活环境
conda activate yolov8
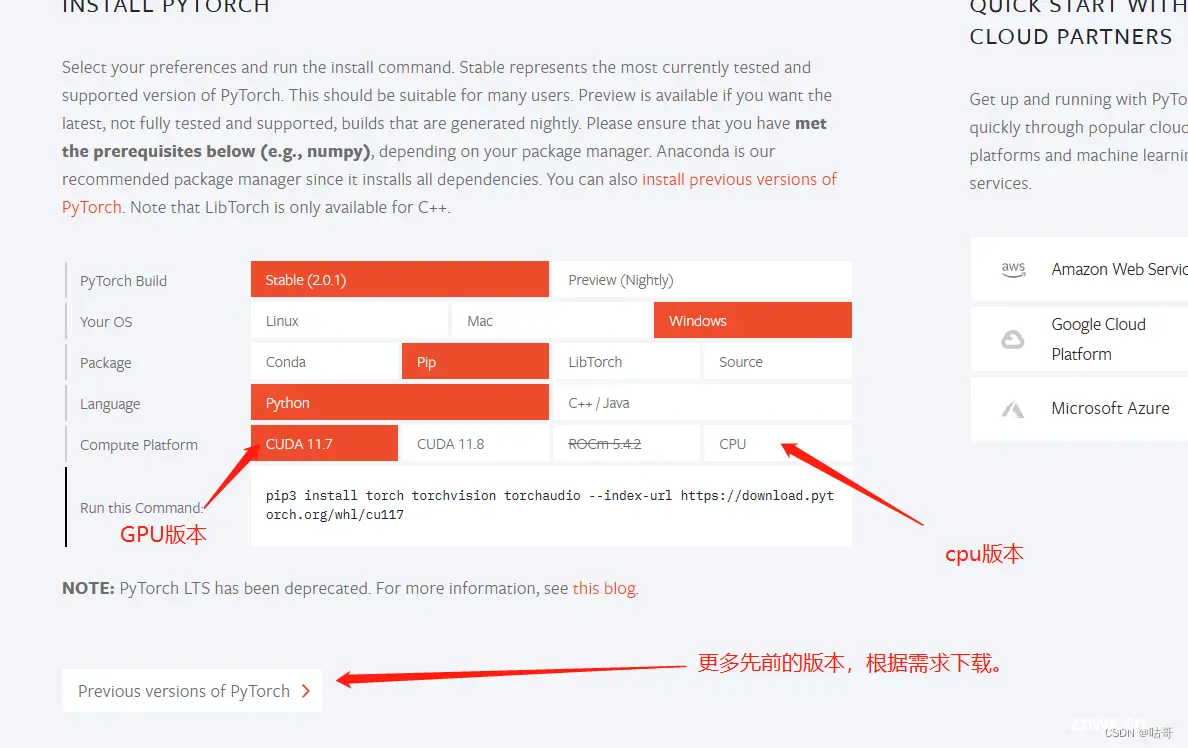
(3)下载Pytorch,这个步骤也十分重要!根据自己电脑配置下载。官方要求Pytorch>=1.7。
首先查看自己的显卡配置:win+R ,输入nvidia-smi
去官网下载对应或者不大于箭头指出的版本,官网地址:PyTorch
https://pytorch.org/
pip下载会比conda下载略快。
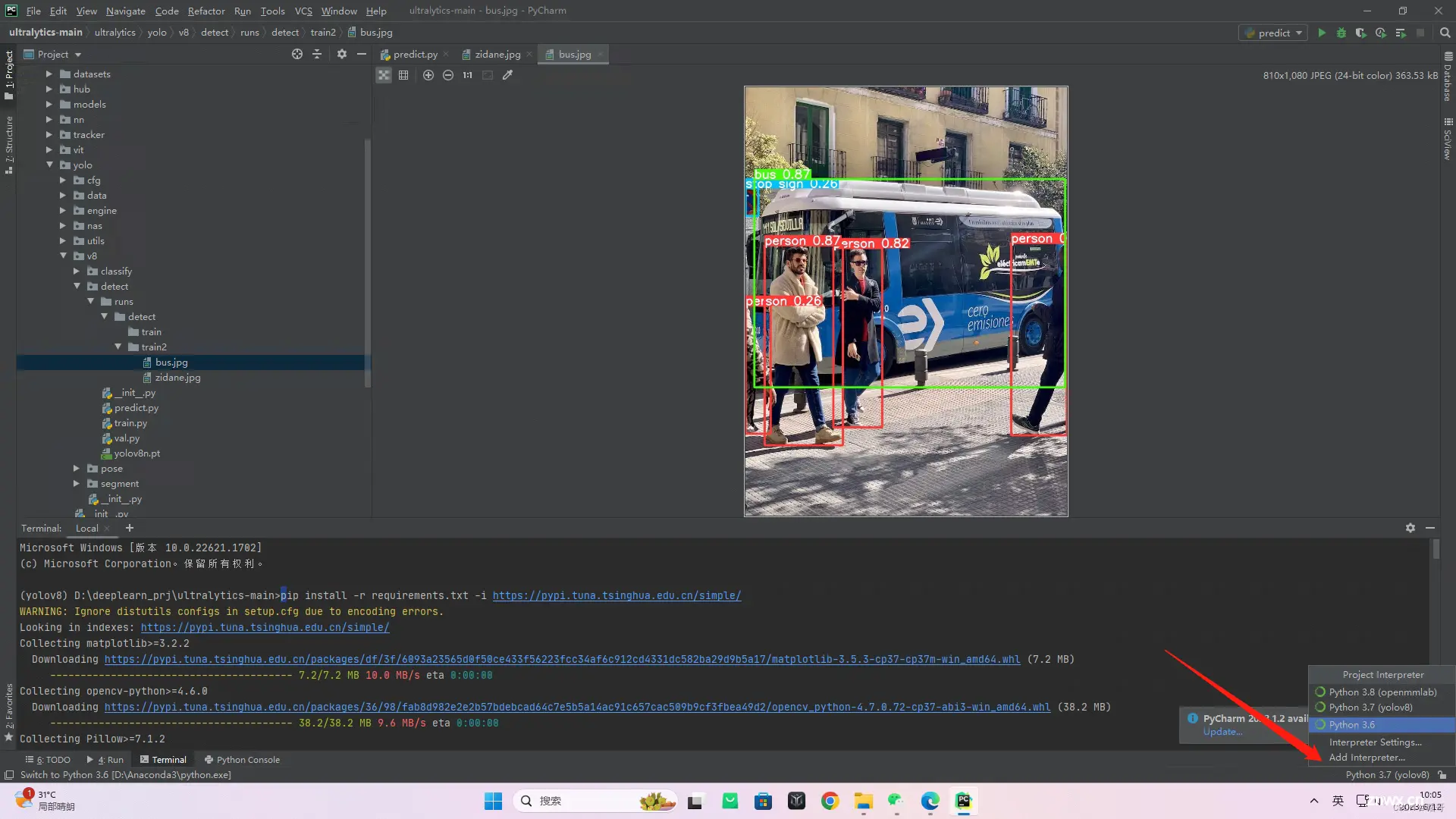
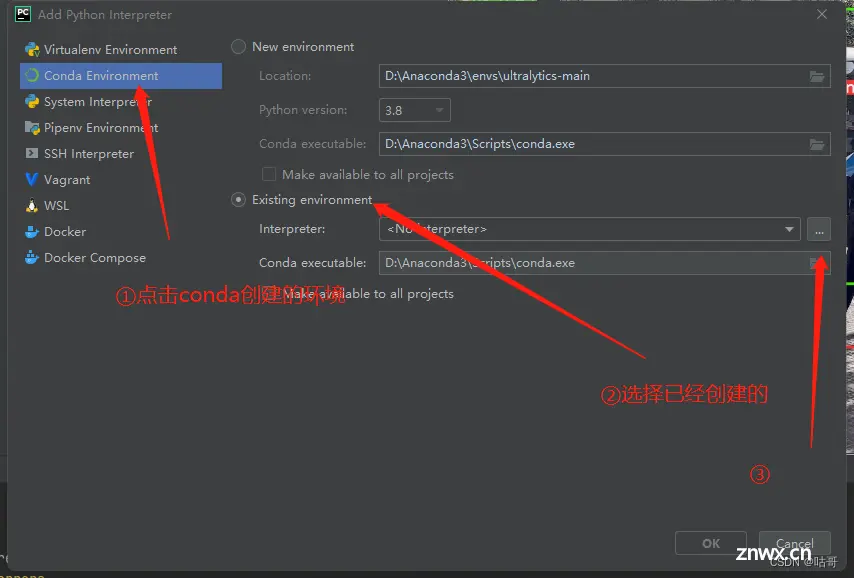
(4)配置好环境后,使用pycharm打开源代码工程文件
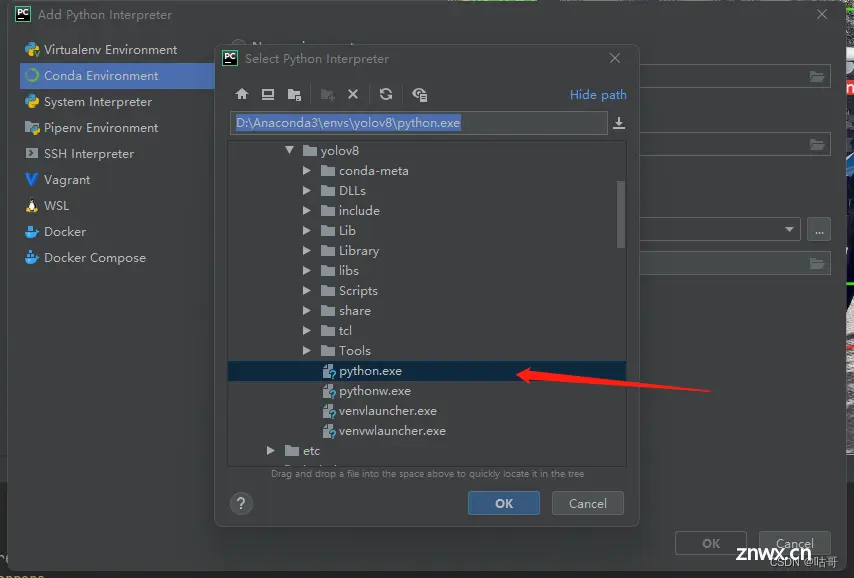
(5)选择下载的yolov8环境。
选择python.exe文件。
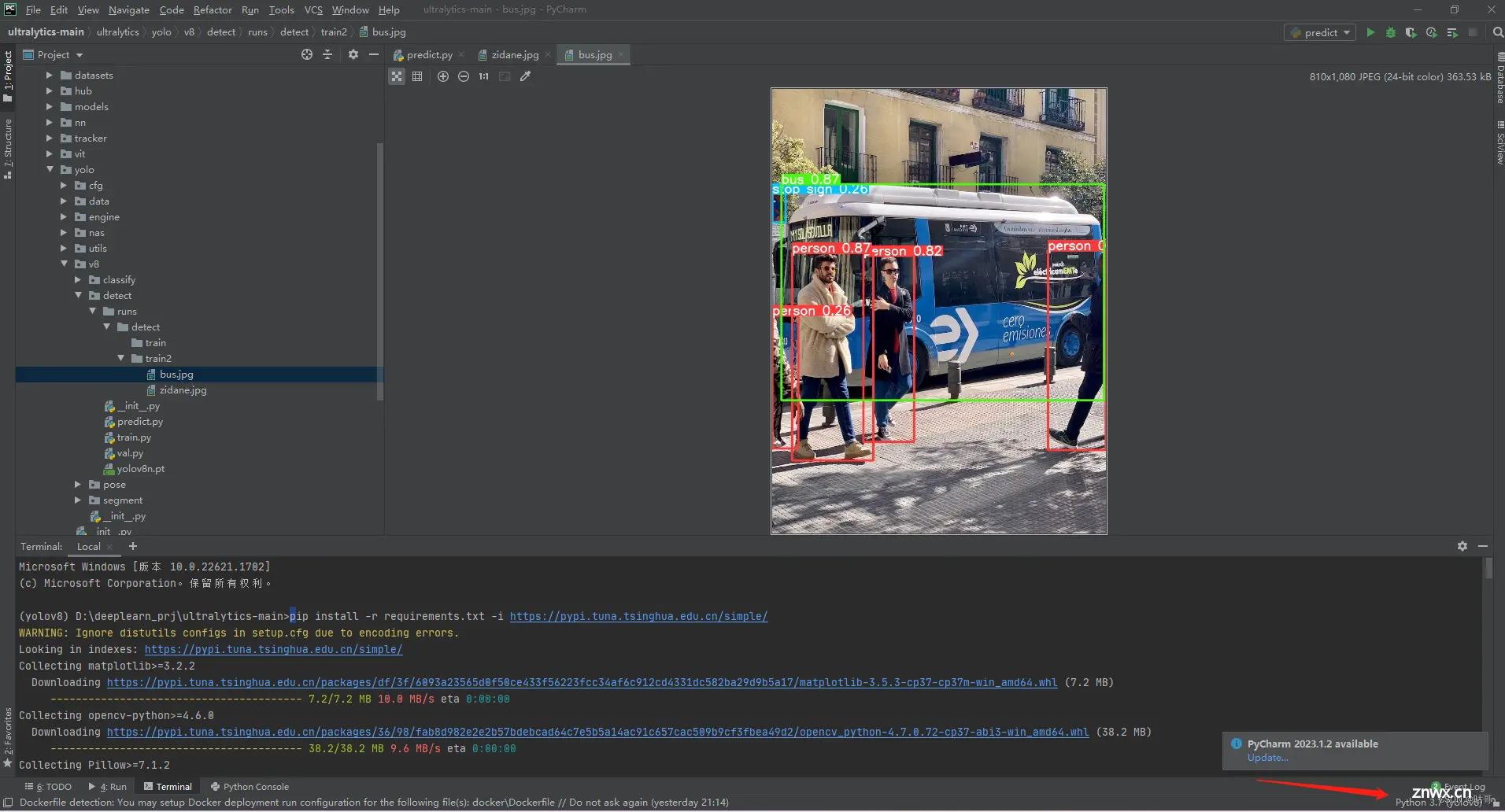
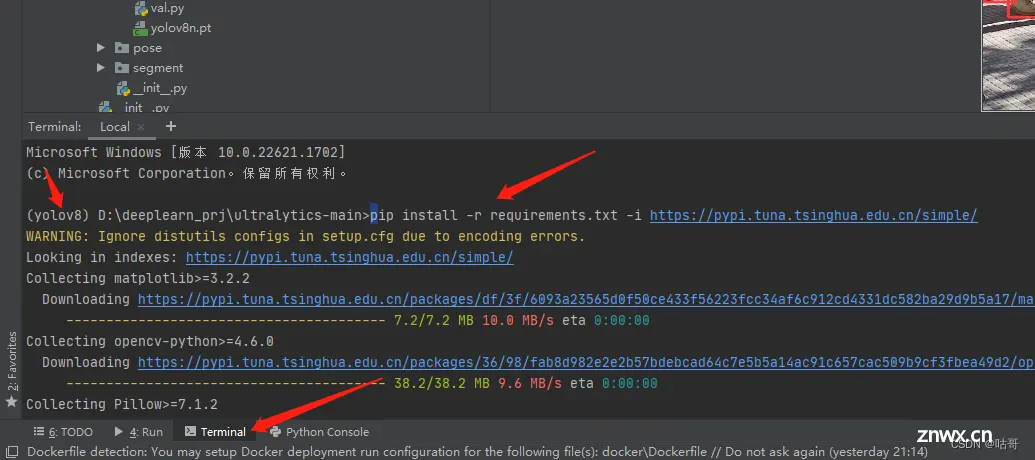
(6)配置yolov8要求的包,点击Temina,输入代码:
<code>pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
-i https://pypi.tuna.tsinghua.edu.cn/simple/这是一次性换源代码,要关掉梯子才能链接。

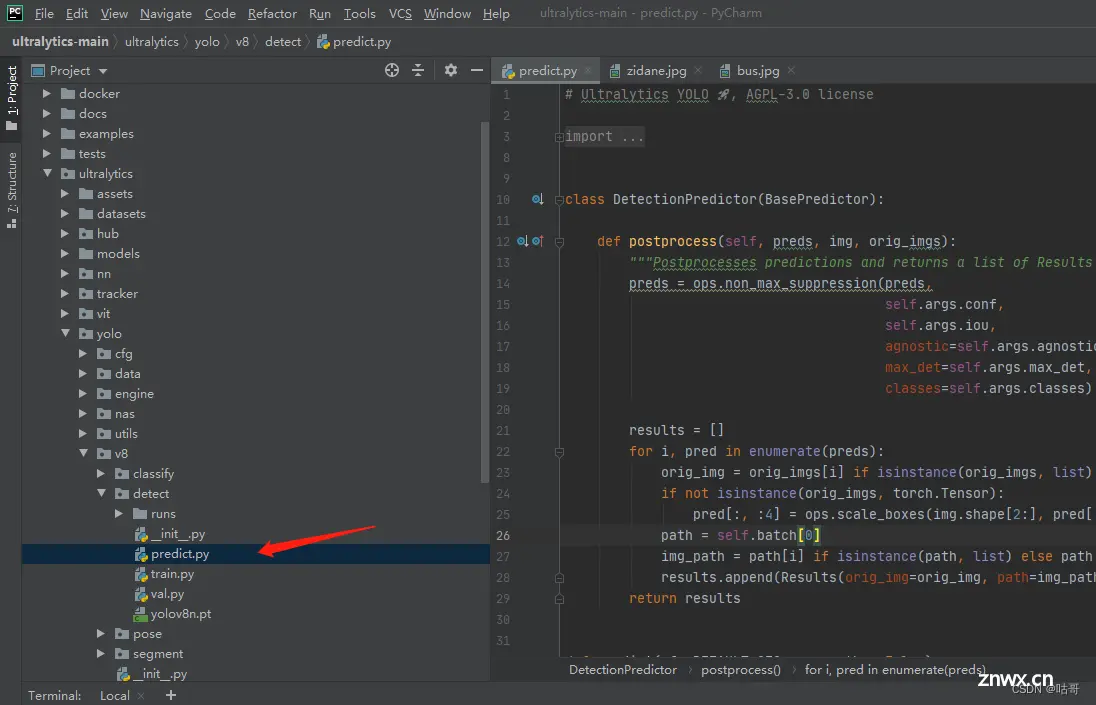
三、验证一下代码是否可以预测例子
1.打开predict.py
2.直接运行,结果会保存在runs里。
3.可能碰见的错误是关于torchvision版本的问题,重新安装即可。

四、制作自己的数据集
先介绍YoLov 8 最终所需要的数据集格式:
datasets
|-images
|--train
|--val
|--test
|-labels
|--train
|--val
|--test
1.Yolo要求的数据标签为.txt
2.与Yolov7 和v5 一样,可以使用labelme标注数据集,yolov8支持多种数据集格式,我是采用上面的格式跑通了,具体制作的过程可参考:
(60条消息) YOLOv5系列 1、制作自己的数据集_yolov5数据集制作_冯璆鸣的博客-CSDN博客

https://blog.csdn.net/fjlaym/article/details/123992962?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168722415116800180654496%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168722415116800180654496&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-123992962-null-null.142%5Ev88%5Econtrol,239%5Ev2%5Einsert_chatgpt&utm_term=yolov5%E5%88%B6%E4%BD%9C%E8%87%AA%E5%B7%B1%E7%9A%84%E6%95%B0%E6%8D%AE%E9%9B%86&spm=1018.2226.3001.41873.制作好数据集后,建立.yaml文件,可建在任何位置,建议与v8其他yaml文件放在一起,修改路径就会方便很多。
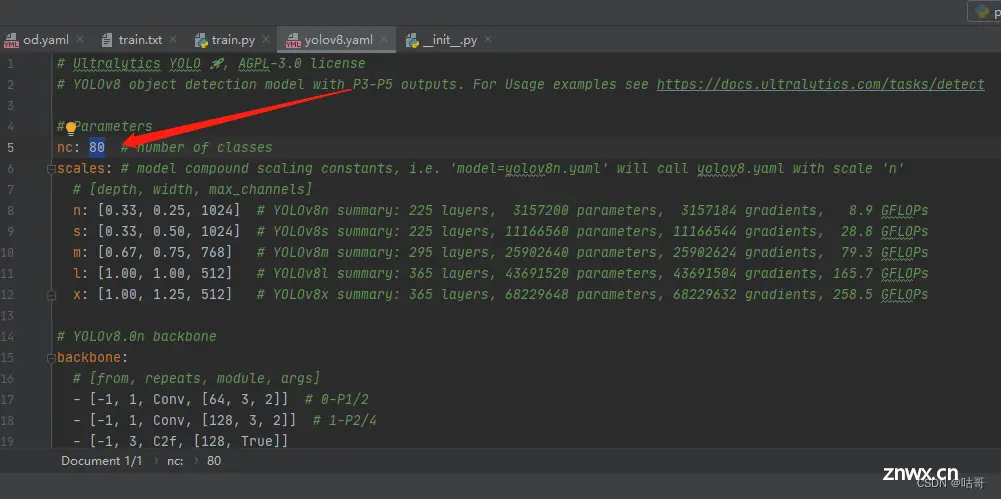
(1)修改模型配置文件
选择yolov8.yaml,修改nc为自己数据集所需检测类别的个数
(2)修改数据加载配置文件,建议全部使用绝对路径
<code>train: "D:/ultralytics-main/datasets/belt/train.txt"
val: "D:/ultralytics-main/datasets/belt/train.txt"
nc: 1
names: ["1"]
至此,所有的配置已经完成。
五、训练自己的数据集
(1)yolo提供自己的指令模式,在调参方面十分方便,当然不下载也可以,直接在文件修改和运行也无碍。
在Terminal下直接运行:
pip install ultralytics
(2)训练:
yolo train data=你的配置文件(xx.yaml)的绝对路径 model=yolov8s.pt epochs=300 imgsz=640 batch=8 workers=0 device=0
如果想使用多卡训练,device='\0,1,2,xxx\'
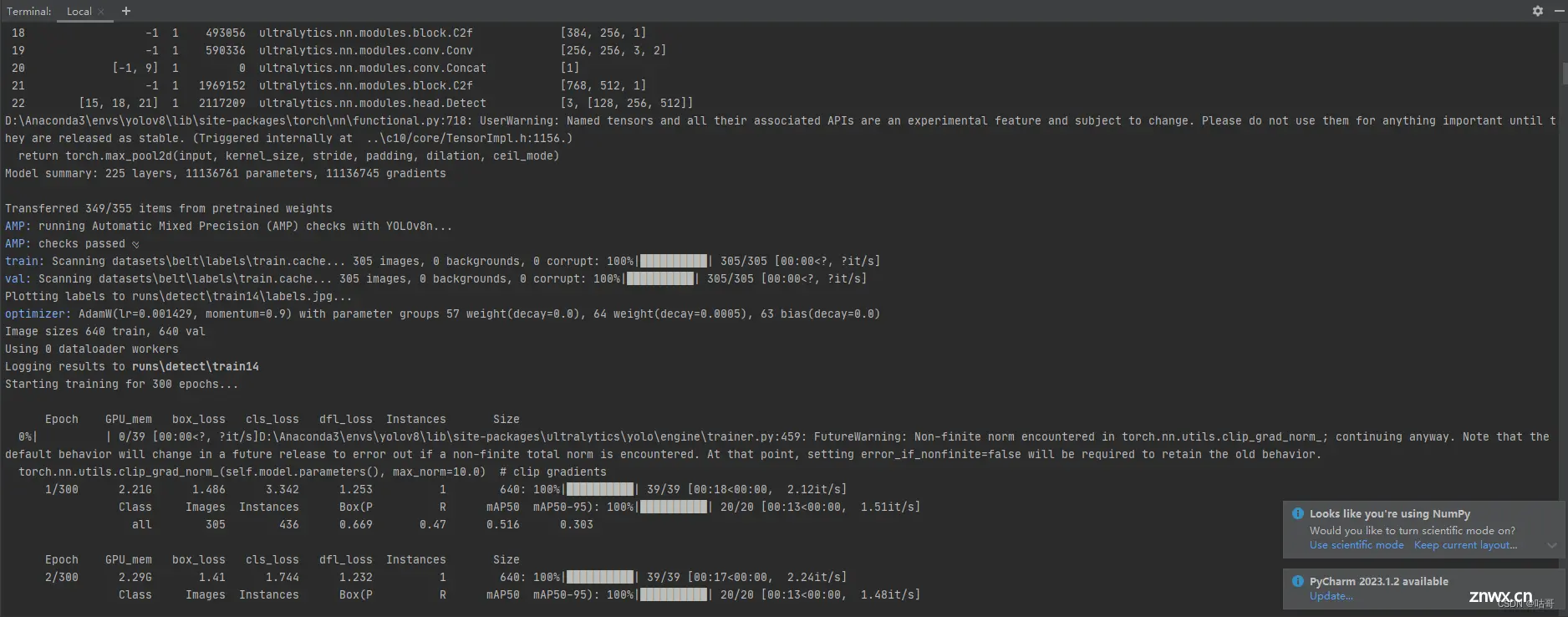
(3)训练过程首先会显示你所使用的训练的硬件设备信息,然后下一段话则是你的参数配置,紧接着是backbone信息,最后是加载信息,并告知你训练的结果会保存在runs\detect\trainxx。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。