Python网页处理与爬虫实战:使用Requests库进行网页数据抓取
Srlua小谢 2024-07-08 12:05:03 阅读 68
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨
🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:Python
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙


目录
Python网页处理与爬虫实战:使用Requests库进行网页数据抓取
问题概述
Python与网页处理
安装requests 库
网页爬虫
拓展:Robots 排除协议
requests 库的使用
requests 库概述
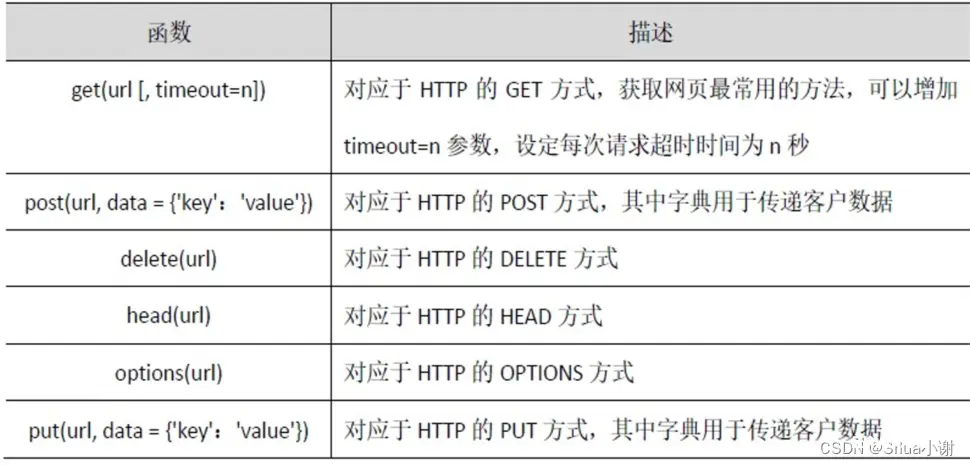
requests 库中的网页请求函数
网页请求函数
Response 对象的属性
Response 对象的方法
获取一个网页内容
Python网页处理与爬虫实战:使用Requests库进行网页数据抓取

问题概述
Python 语言实现网络爬虫的问题引入

Python与网页处理
Python 语言发展中有一个里程碑式的应用事件,即 美国谷歌( GOOGLE) 公司在搜索引擎后端采用 Python 语言进行链接处理和开发,这是该语言发展 成熟的重要标志。Python 语言的简洁性和脚本特点 非常适合链接和网页处理万维网(WWW)的快速发展带来了大量获取和提 交网络信息的需求,这产生了“网络爬虫”等一系列 应用。Python 语言提供了很多类似的函数库,包括urllib 、urllib2、urllib3、wget、scrapy、requests 等。 这些库作用不同、使用方式不同、用户体验不同。对于爬取回来的网页内容,可以通过re(正则表达 式)、beautifulsoup4等函数库来处理,随着该领 域各函数库的发展,本章将详细介绍其中最重要且最 主流的两个函数库:requests 和beautifulsoup4, 它们都是第三方库。
网络爬虫应用一般分为两个步骤:
(1)通过网络连接获取网页内容
(2)对获得的网页内容进行处理。
这两个步骤分别使用不同的函数库:requests 和 beautifulsoup4
安装requests 库
采用pip指令安装requests库,如果在Python2和Python3并存的系统中,采用pip3 指令 :\>pip install requests # 或者 pip3 install requests
采用pip或pip3指令安装beautifulsoup4库,注意,不要安装beautifulsoup库,后者由于年久失修 ,已经不再维护了 :\>pip install beautifulsoup4 # 或者 pip3 install beautifulsoup4
网页爬虫
使用Python语言实现网络爬虫和信息提交是非常简单的事情 ,代码行数很少,也无须知道网络通信等方面知识,非常适合 非专业读者使用。然而,肆意的爬取网络数据并不是文明现象 ,通过程序自动提交内容争取竞争性资源也不公平。就像那些 肆意的推销电话一样,他们无视接听者意愿,不仅令人讨厌也 有可能引发法律纠纷。
拓展:Robots 排除协议
Robots 排除协议(Robots Exclusion Protocol),也被称为爬虫协议,它是 网站管理者表达是否希望爬虫自动获取网络信息意愿的方法。管理者可以在网 站根目录放置一个robots.txt 文件,并在文件中列出哪些链接不允许爬虫爬取 。一般搜索引擎的爬虫会首先捕获这个文件,并根据文件要求爬取网站内容。
Robots 排除协议重点约定不希望爬虫获取的内容,如果没有该文件则表示网 站内容可以被爬虫获得,然而,Robots 协议不是命令和强制手段,只是国际 互联网的一种通用道德规范。绝大部分成熟的搜索引擎爬虫都会遵循这个协议 ,建议个人也能按照互联网规范要求合理使用爬虫技术。
——君子协议——
requests 库的使用
requests 库是一个简洁且简单的处理HTTP请求的第三方库。
requests 库概述
requests 的最大优点是程序编写过程更接近正常 URL 访问过程。
这个库建立在Python语言的urllib3库基础上,类似这种在其他函数库之上再封装功能提供更友好函数的方式在Python语言中十分常见。在Python的生态圈里,任何人都有通过技术创新或体验创新发表意 见和展示才华的机会。request 库支持非常丰富的链接访问功能,包括:国际域名和 URL 获取、HTTP 长连接和连接缓存、HTTP 会话和Cookie 保 持、浏览器使用风格的SSL 验证、基本的摘要认证、有效的键 值对Cookie 记录、自动解压缩、自动内容解码、文件分块上传 、HTTP(S) 代理功能、连接超时处理、流数据下载等。有关 requests 库的更多介绍请访问: http://docs.python‐requests.org
requests 库中的网页请求函数

get() 是获取网页最常用的方式 , 在调用requests.get()函数后,返回的网页内容会保存为一 个Response对象,其中,get()函数的参数url 必须 链接采用HTTP 或HTTPS方式访问
网页请求函数

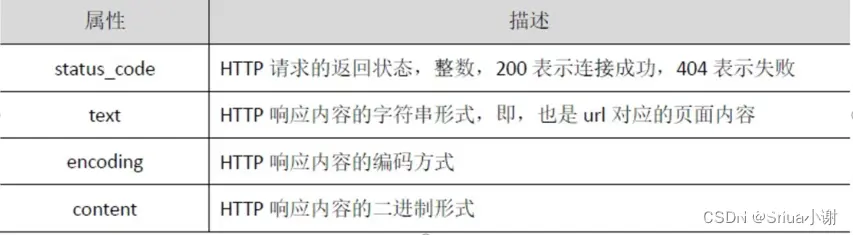
和浏览器的交互过程一样,requests.get()代表请求 过程,它返回的Response 对象代表响应。返回内容 作为一个对象更便于操作,Response 对象的属性如 下表所示,需要采用<a>.<b>形式使用。
Response 对象的属性
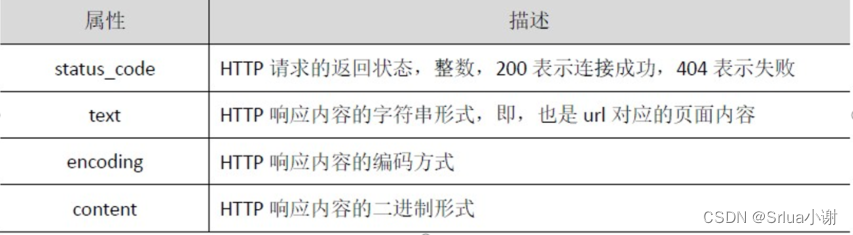
status_code 属性返回请求HTTP 后的状态,在处理数据之前要先判断状态情况,如果请求未被响应, 需要终止内容处理。 text 属性是请求的页面内容,以字符串形式展示。encoding 属性非常重要,它给出了返回页面内容的编码方式,可以通过对encoding属性赋值更改编码 方式,以便于处理中文字符 content 属性是页面内容的二进制形式

Response 对象的方法

json() 方法能够在HTTP响应内容中解析存在的 JSON 数据,这将带来解析HTTP的便利。 raise_for_status()方法能在非成功响应后产生异常,即只要返 回的请求状态status_code 不是200,这个方法会产生一个异 常,用于try…except 语句。使用异常处理语句可以避免设置一 堆复杂的if 语句,只需要在收到响应调用这个方法,就可以避 开状态字200 以外的各种意外情况。requests 会产生几种常用异常。当遇到网络问题时,如: DNS查询失败 、 拒绝连接等 , requests 会 抛 出 ConnectionError 异常;遇到无效HTTP 响应时,requests 则 会抛出HTTPError 异常;若请求url 超时,则抛出Timeout 异 常; 若请求超过了设定的最大重定向次数, 则会抛出一个 TooManyRedirects 异常
获取一个网页内容
实战示例:
Python爬虫项目实战案例-批量下载网易云榜单音乐保存至本地_python爬取制定名称歌曲并下载-CSDN博客

希望对你有帮助!加油!
若您认为本文内容有益,请不吝赐予赞同并订阅,以便持续接收有价值的信息。衷心感谢您的关注和支持!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。