Python爬虫大作业+数据可视化分析(抓取python职位)
程序员老冉 2024-07-06 09:35:02 阅读 75
文章目录
一、获取数据
1.导入相关库2、获取网页信息3.数据清洗4.爬取结果: 二、保存数据
1.保存到excel中2.保存到数据库中3.调用 三、使用flask,实现可视化
1.主函数2.可视化界面:
2.1职位信息展示+分页2.2使用echars制作图标2.3导入地图2.4制作词云
一、获取数据
运用正则表达式,找到相对应的数据,然后对数据进行清洗,最后保存数据,保存为excel文件和保存到数据库中。(这里用的是sqlite数据库)
1.导入相关库
<code>import re # 正则表达式,进行文字匹配
from urllib.request import Request
from urllib.request import urlopen # 制定URL,获取网页数据
from urllib.error import URLError as error
import json
import xlwt
import sqlite3
2、获取网页信息
爬取到的信息是很多,需要用正则表达式进行匹配,一个工作岗位有:8个属性,我只爬取职位名称、公司名称、公司链接、工资、工作地点、是否是实习、员工待遇。
def main():
baseurl = "https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
# 1.爬取网页
datalist = getData(baseurl)
savepath = "51job.xls"code>
jobpath = "newjob.db"
# 保存数据到表格
saveData(datalist, savepath)
# 保存数据到数据库
saveData2DB(datalist, jobpath)
# 爬取网页
def getData(baseurl):
datalist = []
for page in range(0, 30):
url1 = baseurl.format(page + 1)
html = askURL(url1) # 保存获取到的网页源码
# 2.逐一解析数据
html_data = re.findall('window.__SEARCH_RESULT__ =(.*?)</script>', html, re.S)
html_data = ''.join(html_data)
infodict = json.loads(html_data) # 将str类型的数据转换为dict类型
engine_jds = infodict['engine_jds']
for item in engine_jds:
data = []
job_href = item["job_href"] # 工作链接
name = item['job_name']
temp1 = re.sub('\t', '', name)
# 去掉括号中的内容,英文的括号要加反斜杠
temp2 = re.sub('\(.*?\)', '', temp1)
# 去掉括号中的内容,中文括号
job_name = re.sub('(.*?)', '', temp2)
job_company = item['company_name']
job_salary1 = item['providesalary_text']
if job_salary1:
job_salary = get_avgsalary(job_salary1)
else:
job_salary = ""
area = item["workarea_text"] # 工作地点
newarea = re.findall('(.*?)-', area, re.S)
job_area = ''.join(newarea)
demand = item['attribute_text'][1:]
job_requirements = ' '.join(demand)
if job_requirements.find(' ') != -1:
job_experience, job_education = job_requirements.split(' ')
else:
job_experience = job_requirements
job_fuli = item['jobwelf'] if item['jobwelf'] else '无'
if job_salary == "" or job_area == "" or job_education == "":
continue
else:
data.append(job_href)
data.append(job_name)
data.append(job_company)
data.append(job_salary)
data.append(job_area)
# data.append(job_requirements)
data.append(job_experience)
data.append(job_education)
data.append(job_fuli)
datalist.append(data)
# print(datalist)
return datalist
3.数据清洗
主要对薪资进行清洗,统一以万/月为单位,并取区间平均值。
# 对薪资进行数据清洗
def get_avgsalary(salary):
global avg_salary
if '-' in salary: # 针对10-20千/月或者10-20万/年的情况,包含-
low_salary = re.findall(re.compile('(\d*\.?\d+)'), salary)[0]
high_salary = re.findall(re.compile('(\d?\.?\d+)'), salary)[1]
avg_salary = (float(low_salary) + float(high_salary)) / 2
avg_salary = ('%.2f' % avg_salary)
if u'万' in salary and u'年' in salary: # 单位统一成万/月的形式
avg_salary = float(avg_salary) / 12
avg_salary = ('%.2f' % avg_salary) # 保留两位小数
elif u'千' in salary and u'月' in salary:
avg_salary = float(avg_salary) / 10
else: # 针对20万以上/年和100元/天这种情况,不包含-,取最低工资,没有最高工资
avg_salary = re.findall(re.compile('(\d*\.?\d+)'), salary)[0]
if u'万' in salary and u'年' in salary: # 单位统一成万/月的形式
avg_salary = float(avg_salary) / 12
avg_salary = ('%.2f' % avg_salary)
elif u'千' in salary and u'月' in salary:
avg_salary = float(avg_salary) / 10
elif u'元' in salary and u'天' in salary:
avg_salary = float(avg_salary) / 10000 * 21 # 每月工作日21天
avg_salary = str(avg_salary) + '万/月' # 统一薪资格式
return avg_salary
4.爬取结果:
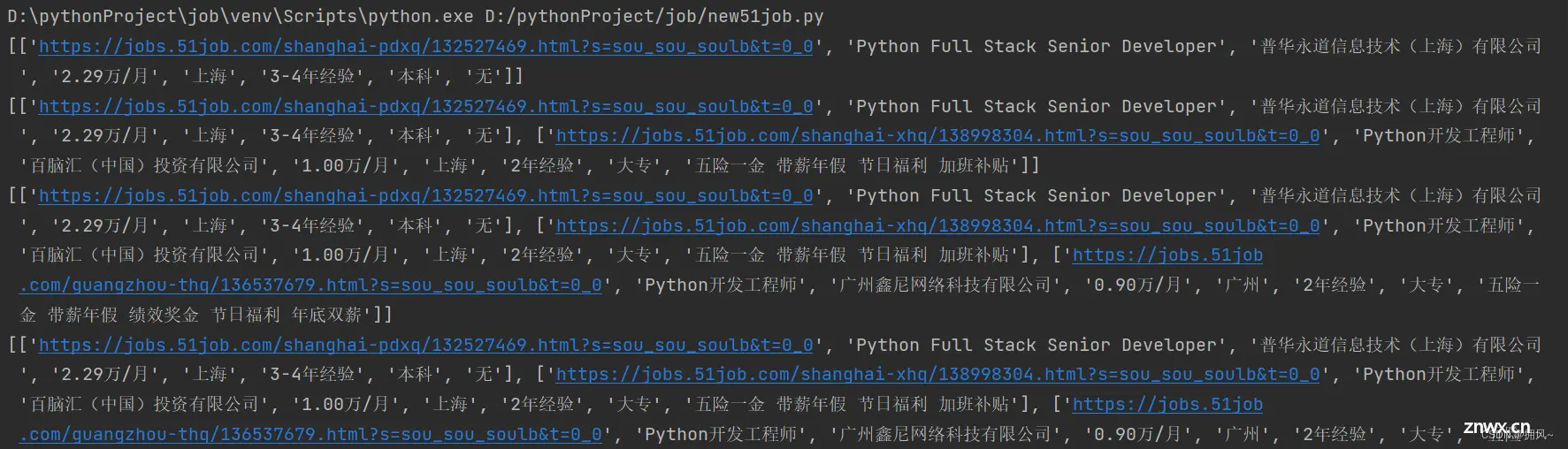
二、保存数据
1.保存到excel中
<code>def saveData(datalist, savepath):
print("sava....")
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建work对象code>
sheet = book.add_sheet('python', cell_overwrite_ok=True) # 创建工作表
col = ("工作链接", "工作名称", "公司", "薪资", "工作地区", "工作经验", "学历", "员工福利")
for i in range(0, 8):
sheet.write(0, i, col[i]) # 列名
for i in range(0, 1000):
# print("第%d条" %(i+1))
data = datalist[i]
for j in range(0, 8):
sheet.write(i + 1, j, data[j]) # 数据
book.save(savepath) # 保存数据
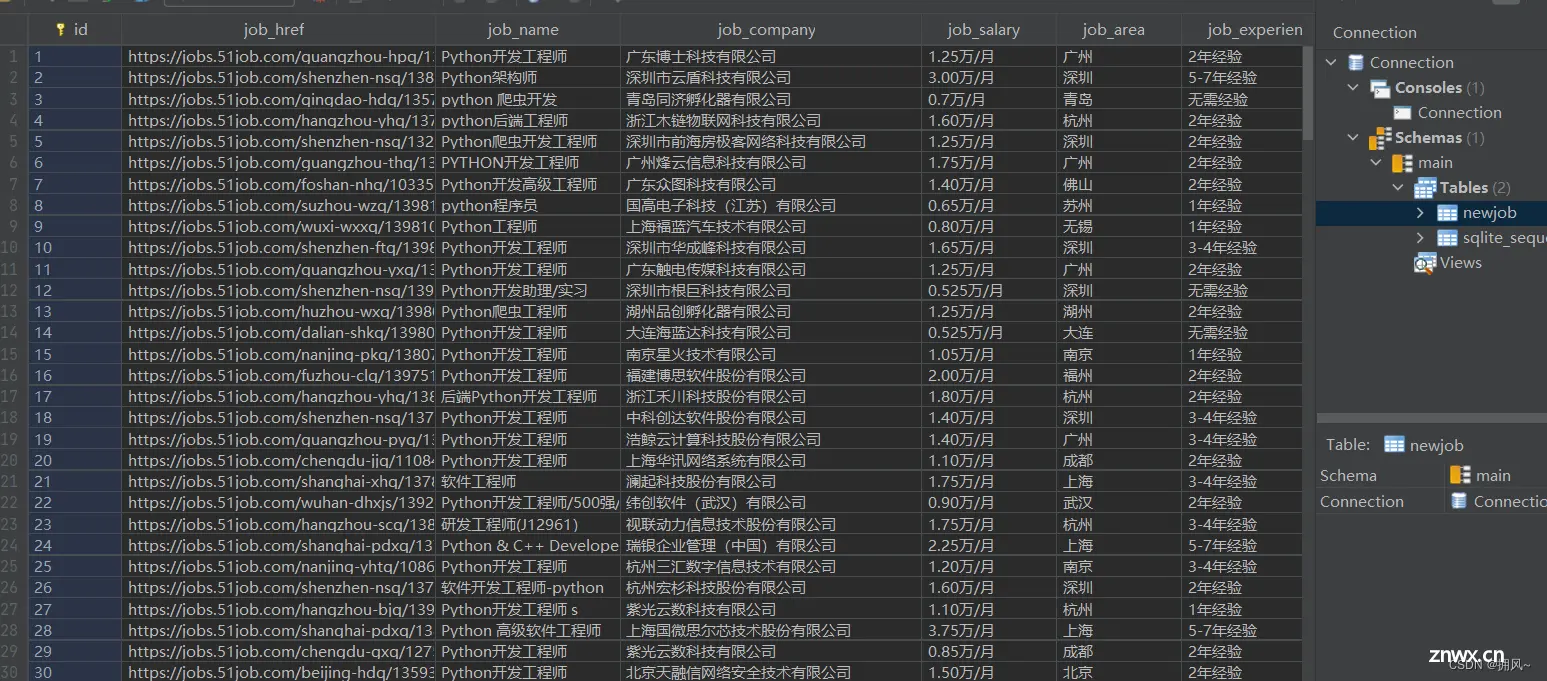
结果显示:

2.保存到数据库中
<code># 创建数据表 (表名为newjob)
def init_job(jobpath):
sql = '''
create table newjob
(
id integer primary key autoincrement,
job_href text,
job_name varchar,
job_company varchar,
job_salary text ,
job_area varchar ,
job_experience text,
job_education text,
job_fuli text
)
'''
conn = sqlite3.connect(jobpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
#将数据保存到数据库中
def saveData2DB(datalist, jobpath):
init_job(jobpath)
conn = sqlite3.connect(jobpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"' + str(data[index]) + '"'
sql = '''
insert into newjob (
job_href,job_name,job_company,job_salary,job_area,job_experience,job_education,job_fuli)
values(%s)''' % ",".join(data)
# print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
3.调用
在main函数中
<code> # 保存数据到表格
saveData(datalist, savepath)
# 保存数据到数据库
saveData2DB(datalist, jobpath)
三、使用flask,实现可视化
1.主函数
实现绘图、分词、连接数据库导入数据、制作词语等
import jieba # 分词作用
from matplotlib import pyplot as plt # 绘图作用,数据可视化
from wordcloud import WordCloud # 词云
from PIL import Image # 图片处理
import numpy as np # 矩阵运算
import sqlite3 # 数据库
# 准备词云所需要的词
con = sqlite3.connect("newjob.db")
cur = con.cursor()
sql = "select job_name from newjob"
data = cur.execute(sql)
test = ""
for item in data:
test = test + item[0]
# print(test)
cur.close()
con.close()
# 分词
cut = jieba.cut(test)
string = " ".join(cut)
print(len(string))
img = Image.open(r'static\assets\img\demo.png') # 打开图片
img_array = np.array(img) # 将图片转化为二维数组
wc = WordCloud(
background_color="white",code>
mask=img_array,
font_path="msyh.ttc" # 字体所在位置 c:\windows\fontscode>
)
wc.generate_from_text(string)
# 绘制图片
fip = plt.figure(1)
plt.imshow(wc)
plt.axis("off") # 是否显示坐标轴
# plt.show() #显示生成的词云图片
#输出词云图片到文件
plt.savefig(r'static\assets\img\demo1.jpg')
2.可视化界面:
2.1职位信息展示+分页
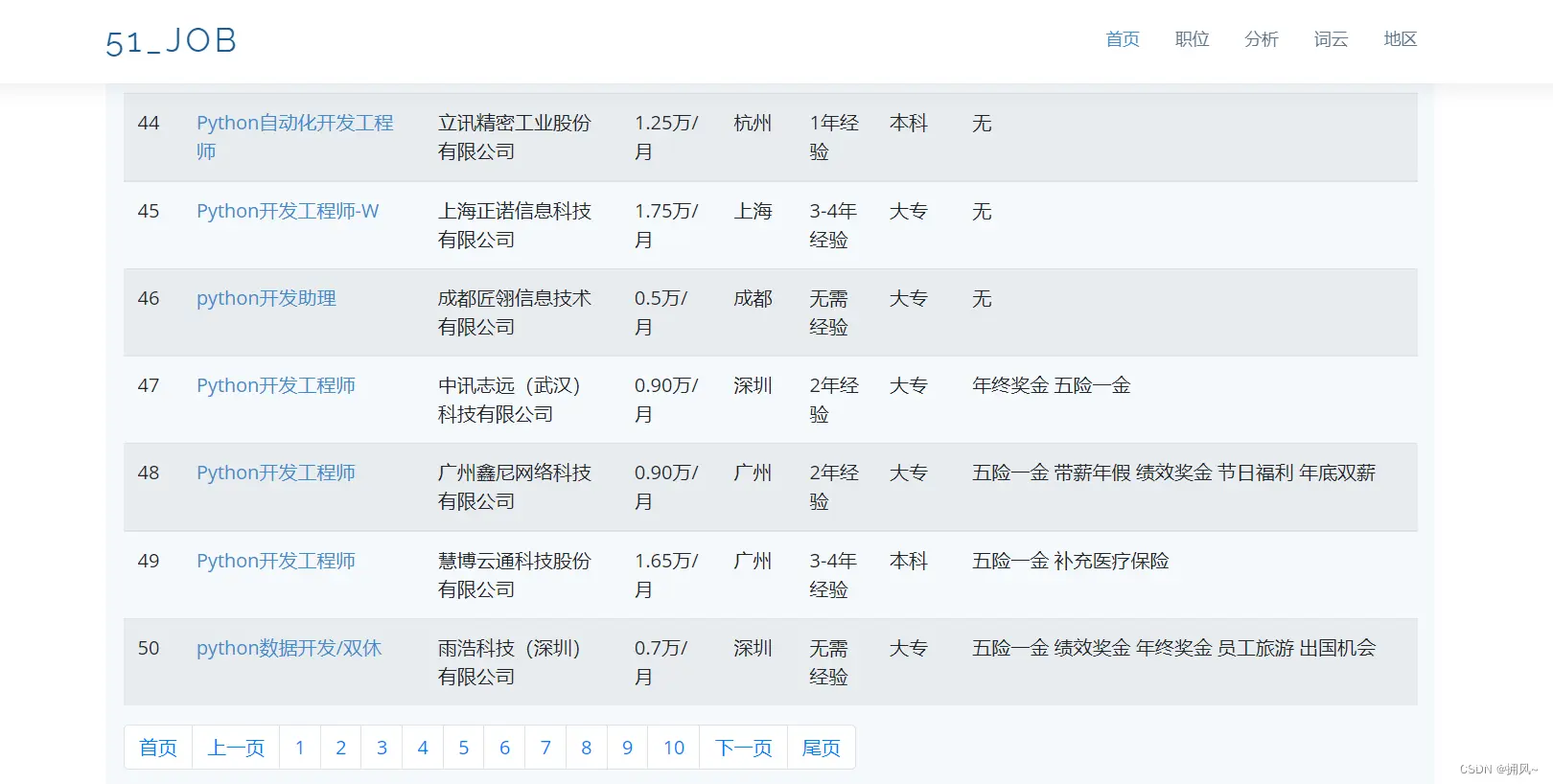
2.2使用echars制作图标

2.3导入地图

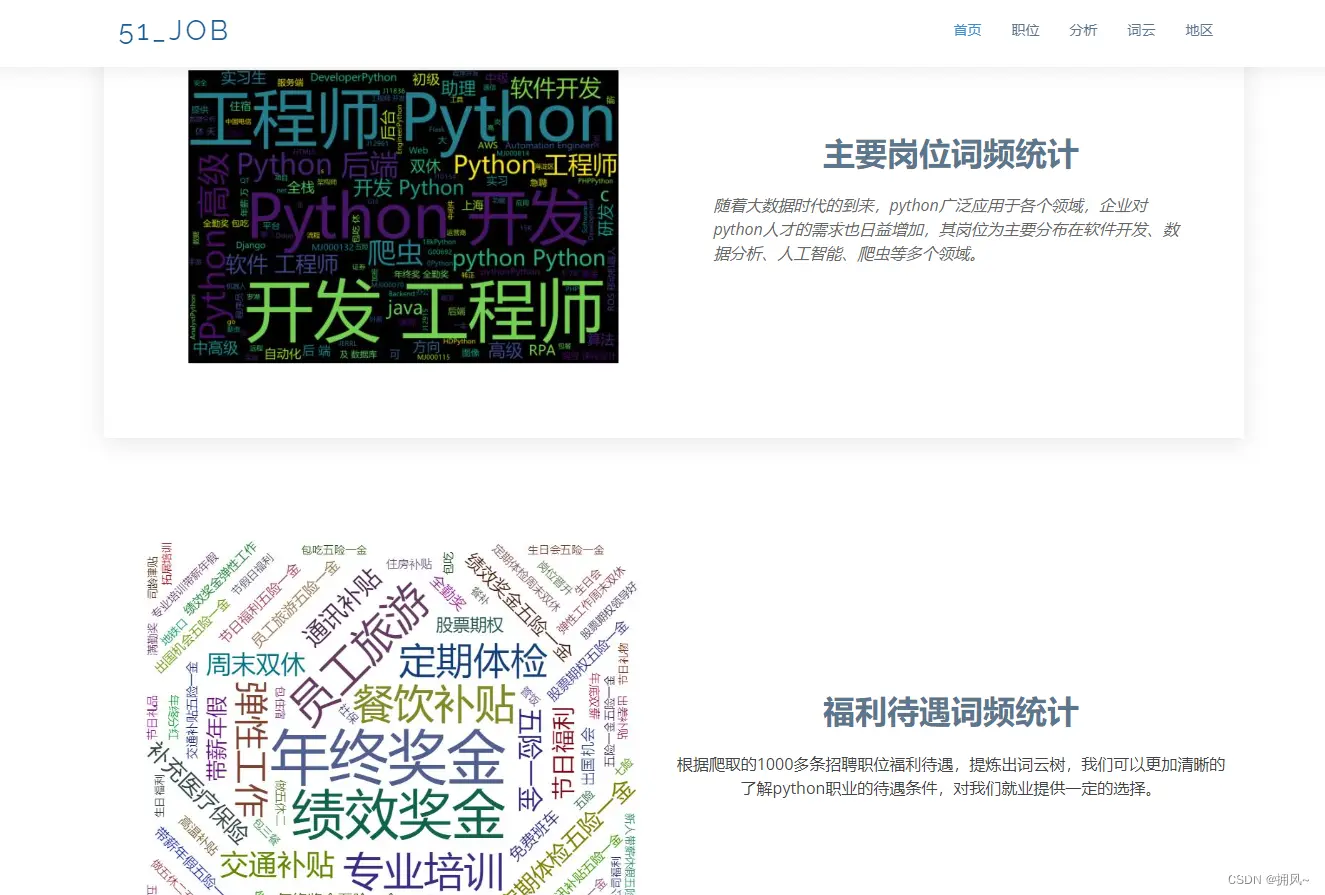
2.4制作词云
<code>import jieba # 分词作用
from matplotlib import pyplot as plt # 绘图作用,数据可视化
from wordcloud import WordCloud # 词云
from PIL import Image # 图片处理
import numpy as np # 矩阵运算
import sqlite3 # 数据库
# 准备词云所需要的词
con = sqlite3.connect("newjob.db")
cur = con.cursor()
sql = "select job_name from newjob"
data = cur.execute(sql)
test = ""
for item in data:
test = test + item[0]
# print(test)
cur.close()
con.close()
# 分词
cut = jieba.cut(test)
string = " ".join(cut)
print(len(string))
img = Image.open(r'static\assets\img\demo.png') # 打开图片
img_array = np.array(img) # 将图片转化为二维数组
wc = WordCloud(
background_color="white",code>
mask=img_array,
font_path="msyh.ttc" # 字体所在位置 c:\windows\fontscode>
)
wc.generate_from_text(string)
# 绘制图片
fip = plt.figure(1)
plt.imshow(wc)
plt.axis("off") # 是否显示坐标轴
# plt.show() #显示生成的词云图片
#输出词云图片到文件
plt.savefig(r'static\assets\img\demo1.jpg')
▍学习资源推荐
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉100道Python练习题👈
检查学习结果。

👉面试刷题👈


资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。