python大作业:天气数据分析
秋澄orange 2024-06-22 10:35:01 阅读 76
有偿分享源码和.docx格式文档
一、设计要求1.1 csv文件的存储1.2 日平均气温趋势分析1.3 城市天气种类统计分析1.4 月平均气温趋势分析1.5 气温风力天气统计1.6 城市旅游季分析 二、设计方案2.1 整体思路2.2 库的使用2.3 工作分解结构2.4 自定义标准详解 三、设计代码四、实现效果4.1 csv文件的处理4.2 日平均气温趋势分析4.3 城市天气种类统计分析4.4 月平均气温趋势分析4.5 气温风力天气统计4.6 城市旅游季分析 五、设计总结5.1 matplotlib可视化5.1.1 绘图方法5.1.2 结构关系 5.1.3 绘图流程5.2 pandas数据清洗5.2.1 处理数据中的空值5.2.2 删除空格5.2.3 大小写转换5.2.4 更改数据格式5.2.5 更改列名称5.2.6 删除重复值5.2.7 修改及替换数据 5.3 参考文献
一、设计要求
1.1 csv文件的存储
首先,根据GitHub开源数据集进行数据清洗,获得题目要求csv数据;其次,将获取的数据信息利用电脑自带Excel功能存储到csv格式的文件中;然后,将文件命名为”城市名称.csv”;最后,其中每行数据格式要求为“日期(date),最高温(T_max),最低温(T_min),天气(weather),风向(wind)”;
(将获取的数据信息存储到csv格式的文件中,文件命名为”城市名称.csv”,其中每行数据格式为“日期,最高温,最低温,天气,风向”)
1.2 日平均气温趋势分析
首先,在csv文件中增加“平均温度(T_Average)”一列,平均温度=(最高温+最低温)/2,此处可以利用numpy库的np.mean()方法求解找到平均值后追加一列数据;然后通过matplotlib库的plt.plot()的方法在同一张图中绘制两个城市(南京、成都)一年的平均气温走势折线图;
(在数据中增加“平均温度”一列,其中:平均温度=(最高温+最低温)/2,在同一张图中绘制两个城市一年平均气温走势折线图)
1.3 城市天气种类统计分析
首先根据csv文件的天气(weather)一列统计两个城市各类天气的天数,将天气按照.split(“/”)分割成列表,利用set()方法去重统计出天气的种类;然后,根据天气的质量进行人工排序增加图表的可视化,再对每座城市的天数进行统计;最后绘制matplotlib条形图对比两座城市的天气情况;
(统计两个城市各类天气的天数,并绘制条形图进行对比)
1.4 月平均气温趋势分析
首先统计这两个城市每个月天数,由于在程序的开头已经实现了年份的统计,此处可以通过判断平闰年来统计每月天数,或者通过csv文件的天数进行统计;然后统计每个月的平均气温,将平均气温放在图表对象中;最后根据图表对象绘制月平均气温折线图;
(统计这两个城市每个月的平均气温,绘制折线图)
1.5 气温风力天气统计
首先,将风向进行分割split分割,分别判断白天夜间的风力是否小于5级别;同时判断平均气温(T_Average)是否大于10并且小于5;最后根据结果在控制台打印天数即可
(统计出这两个城市一年中,平均气温在10~25度,风力小于5级的天数)
1.6 城市旅游季分析
基于天气自然应用结合题目要求数据集,本此实验共自定义四大标准:
(1)风力大小,风力越小代表当地的天气情况相对较好
(2)温差,昼夜温差越小则代表当地天气状况良好
(3)平均温度,平均温度越靠近20℃,人体感到舒适程度越高
(4)适宜天气数,天气为晴天或者多云的天数,代表适合出游的天气数量
为四大标准进行权重分配,对每一标准的权重比例进行赋值,标准的值进行降序排序,权重从高到低依次为4 3 2 1。注意,如果标准值相同则赋值相同,以前一权重为准。
(自定义标准,分析这两个城市适合旅游的季节)
二、设计方案
2.1 整体思路
通过选取中国东西部两座代表性城市南京、成都分析两地天气状况,通过可视化技术呈现出两地气候的差异,为人们的旅游出现提供建议。
2.2 库的使用
针对关键问题,本次设计共利用到如下表1所示库以及库的解决的问题
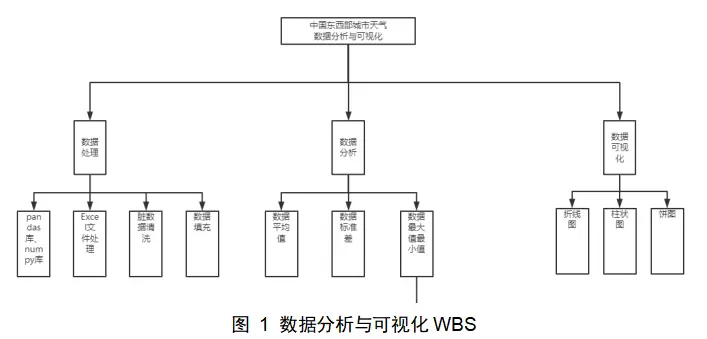
2.3 工作分解结构
2.4 自定义标准详解
按照设计要求,共有四大标准,实现方法如下:
(1)列表字典citySeason存储城市的季节
为了方便后期数据的处理,标准的使用了列表字典的数据结构进行存储
(2)for循环设置citySeason值
通过一次遍历csv文件可以找到全部的标准,实现代码见三设计代码
(3)sorted方法设置权重
将列表字典按照标准用sorted方法排序,赋以权重即可实现权重的设置
(4)寻找权重最大
利用numpy的np.max()方法寻找权重的最大值
(5)函数的封装
将代码重构实现函数封装,传入参数为城市的csv数据,返回值为空,功能:寻找并打印适宜季节
三、设计代码
有偿分享源码和.docx格式文档(可编辑)
四、实现效果
4.1 csv文件的处理
两个csv文件分别为NanJing.csv和ChengDu.csv,每一列分别是
①日期date,
②最高温T_max
③最低温T_min
④天气weather
⑤风向wind_direction
处理结果如下图2所示
4.2 日平均气温趋势分析
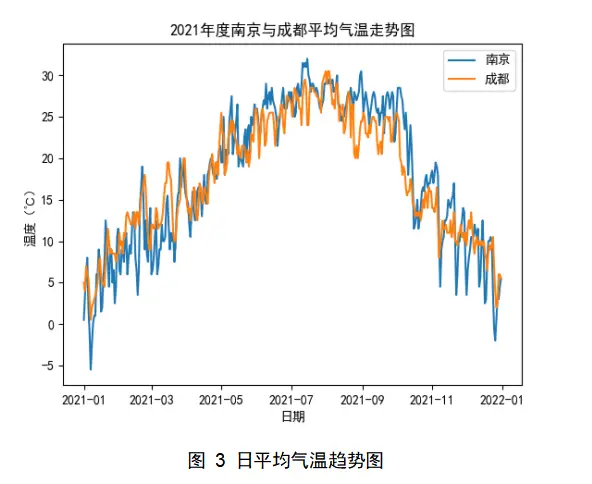
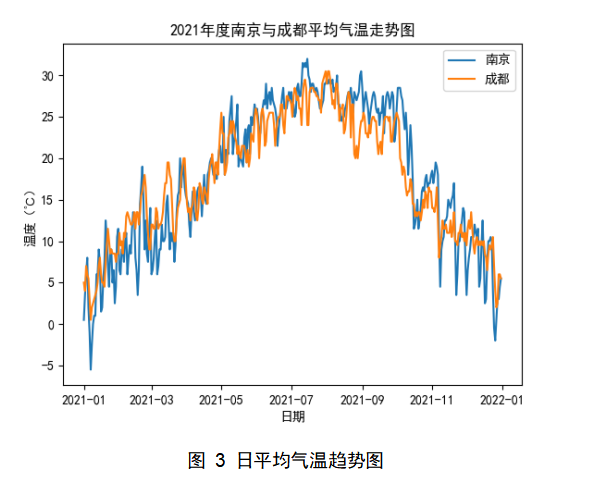
在日平均气温趋势分析中,用到了折线图来反映温度趋势,在同一图中呈现两地趋势进行对比。如下图3所示,横纵代表日期,纵轴代表温度,区间为-5~30℃;蓝色折线代表南京,橙色折线代表成都;据图可分析出在冬季成都的气温比南京要高,夏季成都比南京的气温低,即所谓的成都冬暖夏凉的来由。
4.3 城市天气种类统计分析
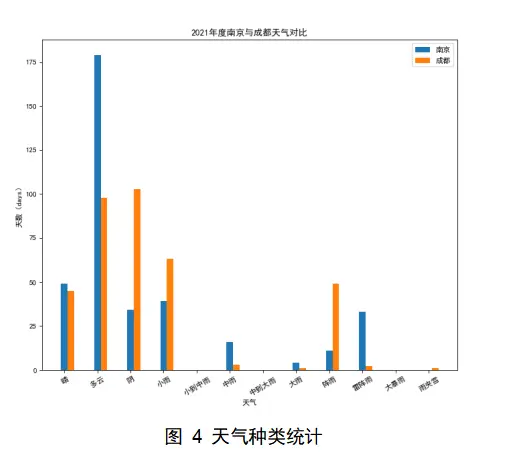
在城市天气种类统计分析中,共有12类天气,质量从好到坏依次为 ‘晴’, ‘多云’, ‘阴’, ‘小雨’, ‘小到中雨’, ‘中雨’, ‘中到大雨’, ‘大雨’, ‘阵雨’, ‘雷阵雨’, ‘大暴雨’, ‘雨夹雪’,利用双柱状图实现两地天气种类的对比。如下图4所示,横轴代表天气种类,纵轴代表天数数量,区间为0~175days,蓝色折线代表南京,橙色折线代表成都;据图可分析出,南京的高质量天气数量与成都持平,成都的阴天或者小于远高于南京,若分析降雨量应该还要加入降雨量的统计
4.4 月平均气温趋势分析
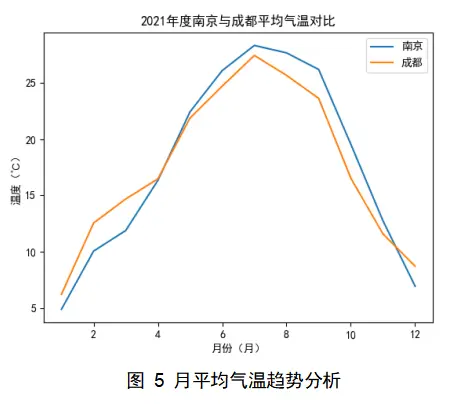
早月平均气温趋势分析中,将每月的平均气温通过折线图呈现,在同一图中呈现两地平均气温对比。如图5所示,横纵代表日期,纵轴代表温度,区间为-5~30℃;蓝色折线代表南京,橙色折线代表成都;据图可分析出成都2 3 4 12月的气温要高于南京,4到11月要低于南京,再次验证了成都是冬暖夏凉的城市。

4.5 气温风力天气统计
根据题目要求设计方案编码统计出平均气温在10~25度,风力小于5级南京为134天,成都为203天,运行结果如下图6所示

4.6 城市旅游季分析
根据自定义四大标准统计出南京的四季情况如下,分别为序号,季节,风力,温差,平均气温。适合天气数量,天数,权重。按照权重分配得出秋季的权重最高,故南京的适合旅游的季节为秋季。

五、设计总结
5.1 matplotlib可视化
5.1.1 绘图方法
通过这次绘图过程,对matplotlib图表绘制所使用的函数和方法印象加深。
plot()函数包含了很多基础的绘图功能,用它来绘制线图;
scatter()函数用以绘制散点图;
xlim() / ylim()用于设置坐标轴的数值显示范围;
xlabel() / ylabel()用于设置坐标轴的标签;
grid()函数用于设置图形中的网格线;
axhline() / axvline():用于设置水平参考线和垂直参考线。
axhspan() / axvspan()用于设置平行于x轴/y轴的参考区域;
annotate():添加指向性注释文本,灵活调整注释的位置以及指示箭头的样式,
text():图形中的注释,但它跟annotate()的区别是它用于添加不带指向性箭头的文本注释; title():形的标题;
5.1.2 结构关系
理解了figure与asex之间的关系,先建画板再建子图,再赋值给对象
fig=plt.figure(figsize=(6,6),dpi=100,facecolor=’#dfd7d7’)
#用add_subplot划分子图ax
ax=fig.add_subplot(1,1,1)
学习了子图之间并列关系,若无先赋值给对象,那么就要按代码顺序plt.绘图。赋值给对象后,对象没有包含的方法就需要用set_函数调用。
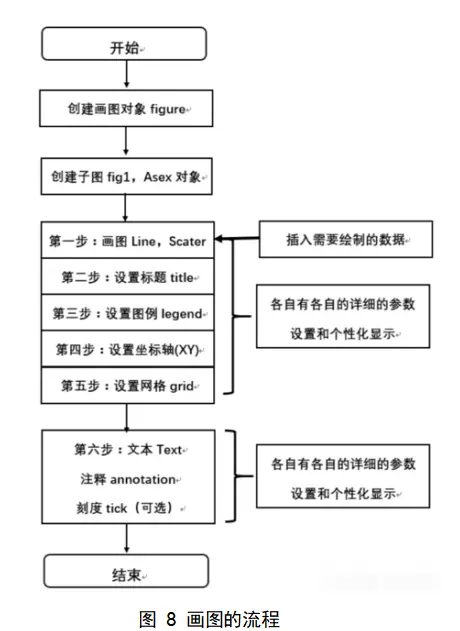
5.1.3 绘图流程

5.2 pandas数据清洗
本次实验用到了pandas数据清洗部分方法,在此进行简单的技术总结(表格代码在jupyter notebook中实现)
5.2.1 处理数据中的空值
我们在处理真实的数据时,往往会有很多缺少的的特征数据,就是所谓的空值,必须要进行处理才能进行下一步分析
空值的处理方式有很多种,一般是删除或者填充
(1)使用dropna函数删除空值
import pandas as pddata=pd.read_csv('成绩表.csv',encoding='gbk')data.dropna(how='any')
(2)用fillna函数实现空值的填充
①使用数字0填充数据表中的空值
data.fillna(value=0)
②使用平均值填充数据表中的空值
data['语文'].fillna(data['语文'].mean())
5.2.2 删除空格
pandas删除空格也很方便,主要使用map函数
data['姓名']=data['姓名'].map(str.strip)data
5.2.3 大小写转换
pandas中转换函数也为upper()和lower()
data['拼音']=data['拼音'].str.upper()datadata['拼音']=data['拼音'].str.lower()data
5.2.4 更改数据格式
pandas使用astype来修改数据格式,以将“语文”列改成整数为例
data['语文'].dropna(how='any').astype('int')
5.2.5 更改列名称
pandas使用rename函数更改列名称,代码如下:
data.rename(columns={ '语文':'语文成绩'})
5.2.6 删除重复值
pandas使用drop_duplicates函数删除重复值
data['数学'].drop_duplicates() #默认删除后面的重复值
5.2.7 修改及替换数据
pandas中使用replace函数实现数据替换
data['姓名'].replace('成 功','失 败')
5.3 参考文献
[1]韦依洋,吴一凡,李永远.Python技术在数据可视化中的应用研究[J].福建电脑,2022,38(01):27-31.DOI:10.16707/j.cnki.fjpc.2022.01.007.
[2]李成渊,俞越,彭伟明.大数据环境下北京冬奥、杭州亚运历史同期气候可视化设计——以数据抓取部分为例[J].江苏科技信息,2019,36(31):75-77.
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。