大数据旅游数据分析:基于Python旅游数据采集可视化分析推荐系统
CSDN 2024-06-17 15:05:21 阅读 63
文章目录
基于Python旅游数据采集可视化分析推荐系统一、项目概述二、项目说明三、开发环境四、功能实现五、系统页面实现用户登录注册系统首页数据操作管理价格与销量分析旅游城市和景点等级分析旅游数据评分情况分析旅游数据评论情况分析旅游景点用户评论评分机器学习算法旅游景点及路线推荐Django系统后台管理 六、结语
基于Python旅游数据采集可视化分析推荐系统
一、项目概述
在互联网时代,各行各业的人们都在寻求增长点,人们的日常生活越来越离不开互联网。以旅游信息为例,线下大量的各种旅游信息基本只会出现在旅游会上,但是现如今,人们越来越重视时间成本,所以越来越多的年轻人在网上查找自己想要查找的旅游就业信息。然而,在互联网信息和海量数据源混合的情况下,如何快速精确的找到自己想要的数据是一个值得探讨的问题。
本系统主要针对解决获取旅游信息滞后、参加线下旅行社和人工检索时间成本高等问题,运用网络爬虫信息技术设计思想,实现了一个基于Python的旅游信息推荐系统。本系统以Python语言为基础,使用 requests爬虫对去哪儿旅行网站信息源进行抓取,针对网页信息编写抽取规则,对旅游信息进行必要的过滤和提取,使用MySql对旅游信息进行数据存储。然后使用 Python 开源web框架 Django进行系统搭建,基于旅游信息采用机器学习协同过滤推荐算法完成对用户的旅游信息推荐,完成整个爬取以及数据检索到成功进行旅游推荐的网页端操作展示。
二、项目说明
基于python旅游采集数据分析可视化推荐系统是基于Django框架开发的一个旅游信息采集和推荐的应用。该系统通过爬虫技术从各个旅游网站抓取旅游信息,并利用推荐算法对用户进行个性化推荐,同时提供可视化展示界面。
以下是该系统的主要功能和组成部分的介绍:
旅游信息采集:系统通过编写爬虫程序,定期从各大旅游网站抓取旅游景点、酒店、机票等相关信息,包括价格、评价、位置等。这些采集到的数据会被保存到数据库中供后续使用。
用户注册与登录:用户可以注册自己的账号,并通过登录来获取个性化推荐和享受更多功能。
个性化推荐:系统会根据用户的历史浏览记录、收藏记录以及其他行为数据,利用推荐算法生成个性化推荐结果。推荐算法使用协同过滤、内容过滤方法,根据用户的兴趣和偏好为其推荐最相关的旅游信息。
可视化展示界面:系统会将采集的旅游信息以可视化方式展示给用户,包括地图标记、图片展示、价格对比等功能。用户可以通过地图选择感兴趣的地区,查看该地区的旅游景点、酒店等信息。
用户交互和反馈:系统提供用户评价、评论和收藏等功能,用户可以对自己的旅游经历进行评价,同时也可以保存自己喜欢的旅游信息以便日后查看。
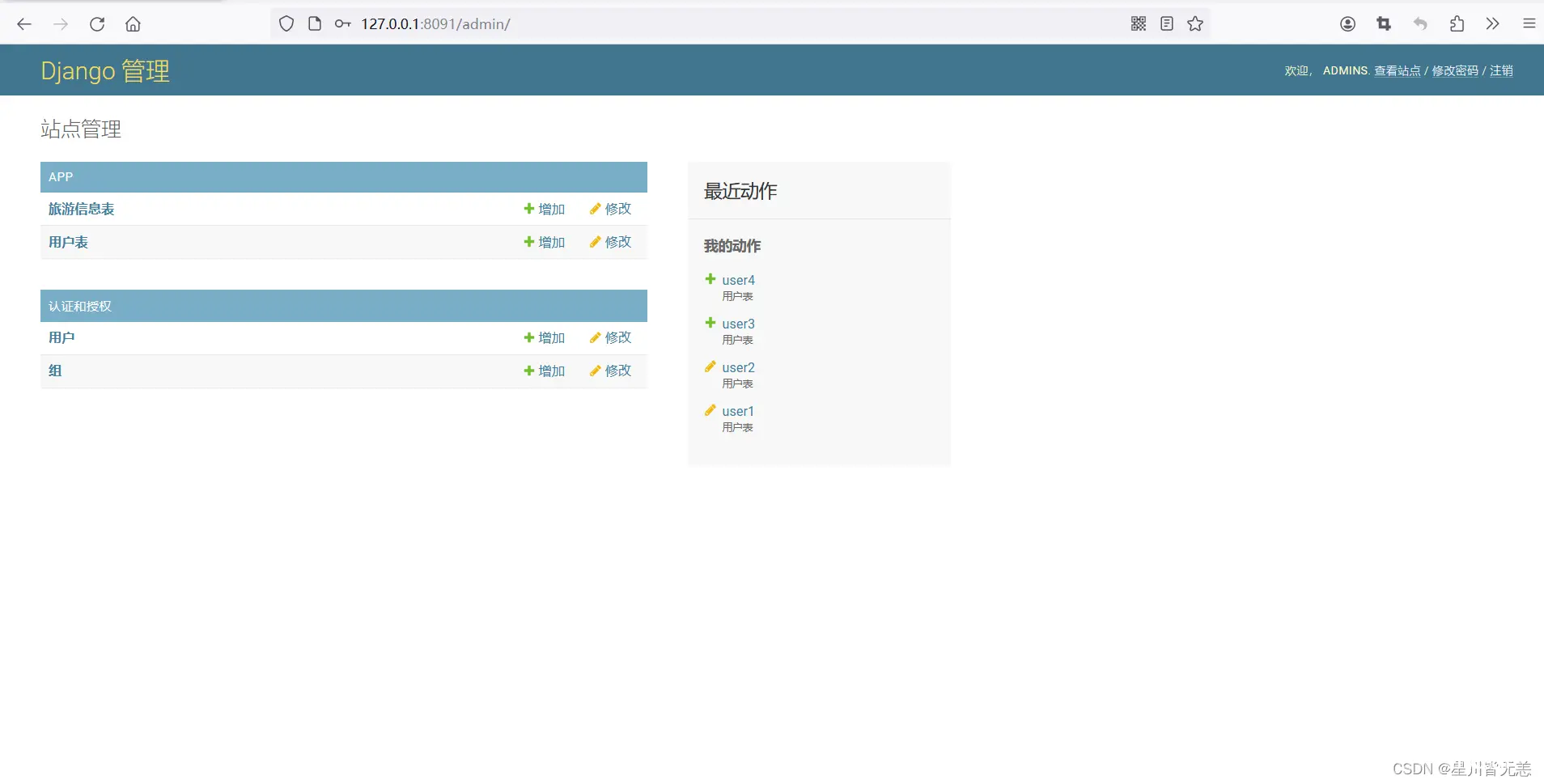
后台管理:系统提供一个后台管理界面,管理员可以对用户信息、采集的数据、推荐算法参数等进行管理和配置。
三、开发环境
| 开发环境 | 版本/工具 |
|---|---|
| PYTHON | 3.9.0 |
| 开发工具 | PyCharm2021.2.1 |
| 操作系统 | Windows 10 |
| 内存要求 | 16GB |
| 浏览器 | Firefox |
| 数据库 | MySQL 8.0.26 |
| 数据库工具 | Navicat 15 for MySQL |
| 项目技术栈 | Python语言、Django框架、MySQL数据库、requests网络爬虫技术、机器学习算法、BootStrap、数据可视化 |
四、功能实现
爬取数据源——去哪儿旅行 https://www.qunar.com/

系统爬虫部分核心代码
def spiderMain(self,resp,province): respJSON = resp.json()['data']['sightList'] for index,travel in enumerate(respJSON): print('正在爬取该页第%s数据' % str(index + 1)) time.sleep(2) detailAddress = travel['address'] discount = travel['discount'] shortIntro = travel['intro'] price = travel['qunarPrice'] saleCount = travel['saleCount'] try: level = travel['star'] + '景区' except: level = '未评价' title = travel['sightName'] cover = travel['sightImgURL'] sightId = travel['sightId'] # ================================= 详情爬取 detailUrl = self.detailUrl % sightId respDetailXpath = etree.HTML(self.send_request(detailUrl).text) score = respDetailXpath.xpath('//span[@id="mp-description-commentscore"]/span/text()') if not score: score = 0 star = 0 else: score = score[0] star = int(float(score)*10) commentsTotal = respDetailXpath.xpath('//span[@class="mp-description-commentCount"]/a/text()')[0].replace('条评论','') detailIntro = respDetailXpath.xpath('//div[@class="mp-charact-intro"]//p/text()')[0] img_list = respDetailXpath.xpath('//div[@class="mp-description-image"]/img/@src')[:6] # ================================= 评论爬取 commentSightId = respDetailXpath.xpath('//div[@class="mp-tickets-new"]/@data-sightid')[0] commentsUrl = self.commentUrl % commentSightId comments = [] try: commentsList = self.send_request(commentsUrl).json()['data']['commentList'] for c in commentsList: if c['content'] != '用户未点评,系统默认好评。': author = c['author'] content = c['content'] date = c['date'] score = c['score'] comments.append({ 'author': author, 'content': content, 'date': date, 'score': score }) except: comments = [] resultData = []
这里代码创建了一个 spider 类的实例对象 spiderObj,然后依次调用了该对象的 start() 方法和 save_to_sql() 方法。
spiderObj.start() 方法用于启动爬虫程序,即开始采集数据。
spiderObj.save_to_sql() 方法用于将爬取到的数据保存到 MySQL 数据库中。
if __name__ == '__main__': spiderObj = spider() #spiderObj.init() spiderObj.start() #采集数据 spiderObj.save_to_sql() #保存爬取的旅游数据到MySQL数据库
爬取数据过程截图如下:
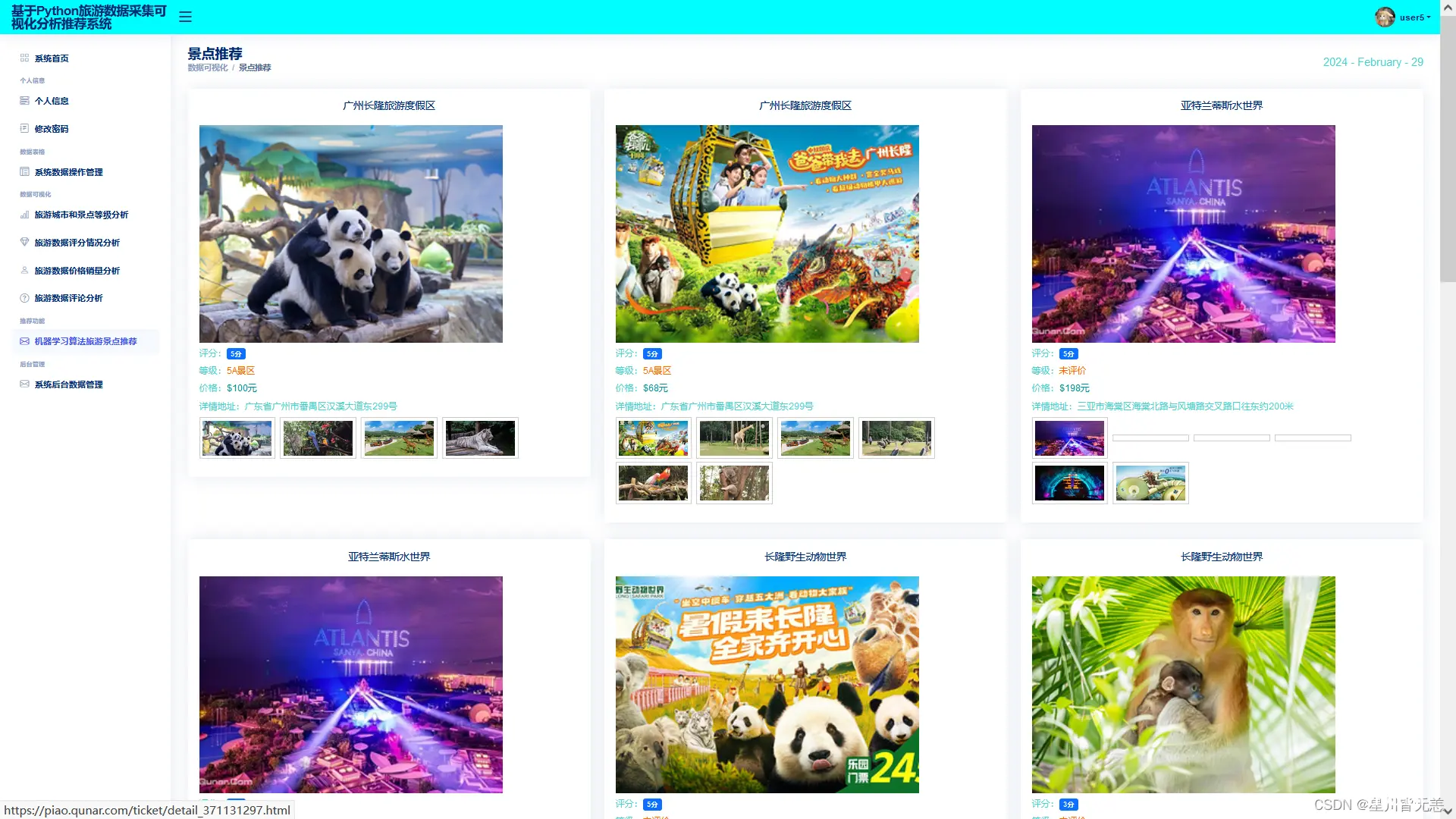
机器学习算法推荐部分是基于用户的协同过滤推荐算法,用于根据用户的评分数据推荐其可能喜欢的其他景点。
基于用户的协同过滤算法部分核心代码:
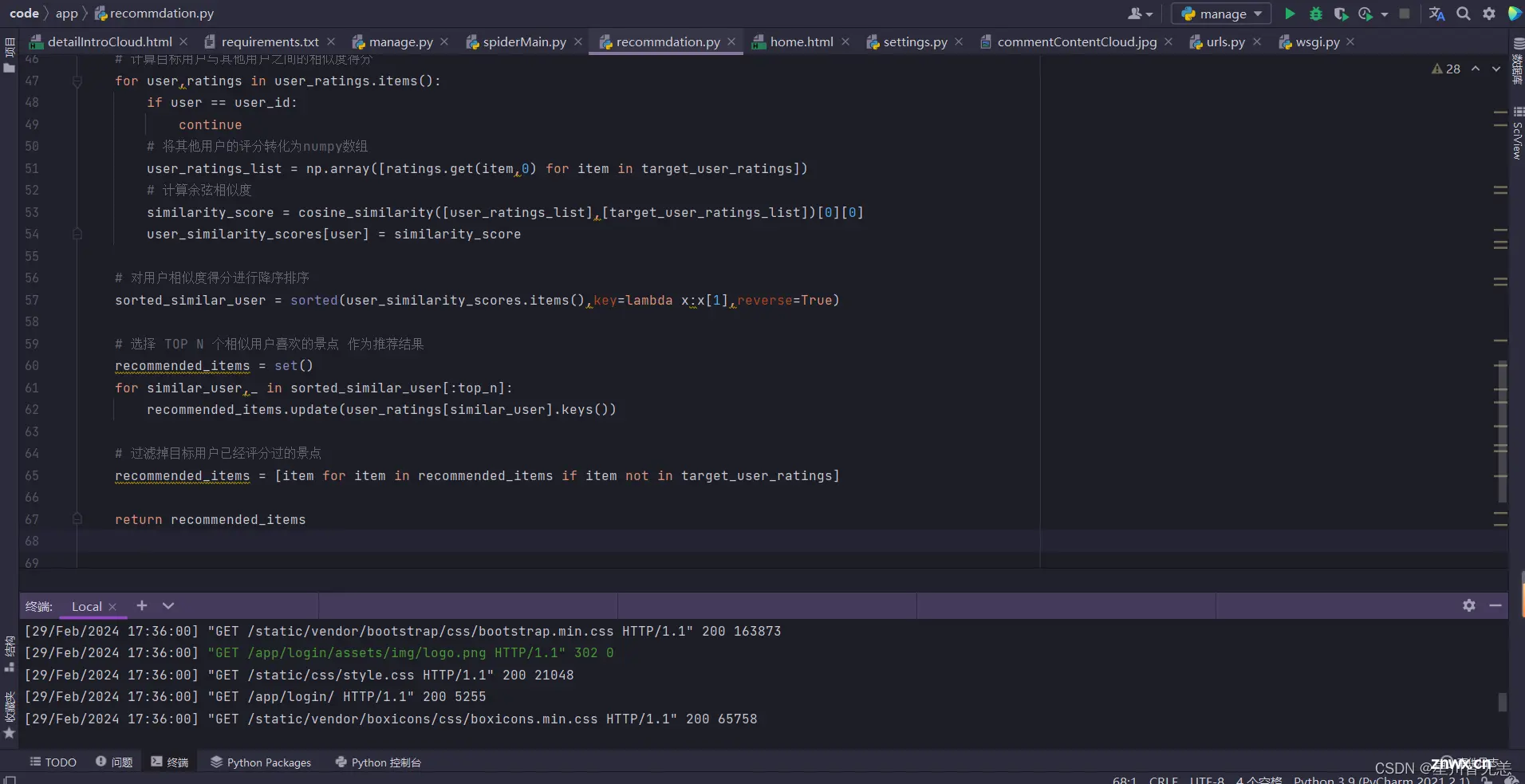
def user_bases_collaborative_filtering(user_id,user_ratings,top_n=20):# def user_bases_collaborative_filtering(user_id, user_ratings, top_n=3): # 获取目标用户的评分数据 target_user_ratings = user_ratings[user_id] # 初始化一个字段,用于保存其他用户与目标用户的相似度得分 user_similarity_scores = { } # 将目标用户的评分转化为numpy数组 target_user_ratings_list = np.array([ rating for _ , rating in target_user_ratings.items() ]) # 计算目标用户与其他用户之间的相似度得分 for user,ratings in user_ratings.items(): if user == user_id: continue # 将其他用户的评分转化为numpy数组 user_ratings_list = np.array([ratings.get(item,0) for item in target_user_ratings]) # 计算余弦相似度 similarity_score = cosine_similarity([user_ratings_list],[target_user_ratings_list])[0][0] user_similarity_scores[user] = similarity_score # 对用户相似度得分进行降序排序 sorted_similar_user = sorted(user_similarity_scores.items(),key=lambda x:x[1],reverse=True) # 选择 TOP N 个相似用户喜欢的景点 作为推荐结果 recommended_items = set() for similar_user,_ in sorted_similar_user[:top_n]: recommended_items.update(user_ratings[similar_user].keys()) # 过滤掉目标用户已经评分过的景点 recommended_items = [item for item in recommended_items if item not in target_user_ratings] return recommended_items user_bases_collaborative_filtering 函数接受三个参数: user_id: 目标用户的ID。user_ratings: 包含用户评分信息的字典,其中键是用户ID,值是包含景点及其评分的字典。top_n: 选择推荐结果的前N个景点,默认为20。 target_user_ratings = user_ratings[user_id]:获取目标用户的评分数据,即目标用户对各个景点的评分。user_similarity_scores = {}:初始化一个空字典,用于保存其他用户与目标用户的相似度得分。target_user_ratings_list = np.array([...]):将目标用户的评分转换为 NumPy 数组,以便后续计算余弦相似度。遍历 user_ratings 中的每个用户,计算目标用户与其他用户之间的相似度得分: 将其他用户的评分转化为 NumPy 数组。使用余弦相似度计算两个用户之间的相似度得分。将相似度得分存储在 user_similarity_scores 字典中。 sorted_similar_user = sorted(user_similarity_scores.items(),key=lambda x:x[1],reverse=True):对用户相似度得分进行降序排序,得到一个包含用户ID和相似度得分的元组列表。recommended_items = set():初始化一个集合,用于保存推荐的景点。遍历排序后的相似用户列表,选择前 top_n 个相似用户喜欢的景点,将这些景点添加到 recommended_items 集合中。recommended_items = [item for item in recommended_items if item not in target_user_ratings]:过滤掉目标用户已经评分过的景点,得到最终的推荐结果。返回 recommended_items,即推荐给目标用户的景点列表。
这个函数接受目标用户ID、用户评分字典以及要返回的推荐结果数量作为参数。它计算目标用户与其他用户的相似度得分,然后选择相似度最高的用户喜欢的景点作为推荐结果。
– 获取目标用户的评分数据
– 初始化一个字典,用于保存其他用户与目标用户的相似度得分
– 将目标用户的评分转化为numpy数组
– 计算目标用户与其他用户之间的相似度得分(余弦相似度)
– 对用户相似度得分进行降序排序
– 选择TOP N个相似用户喜欢的景点作为推荐结果
– 过滤掉目标用户已经评分过的景点
五、系统页面实现
启动项目,在终端窗口输入命令,这里我设置的端口在8091:
python manage.py runserver 8091
用户登录注册
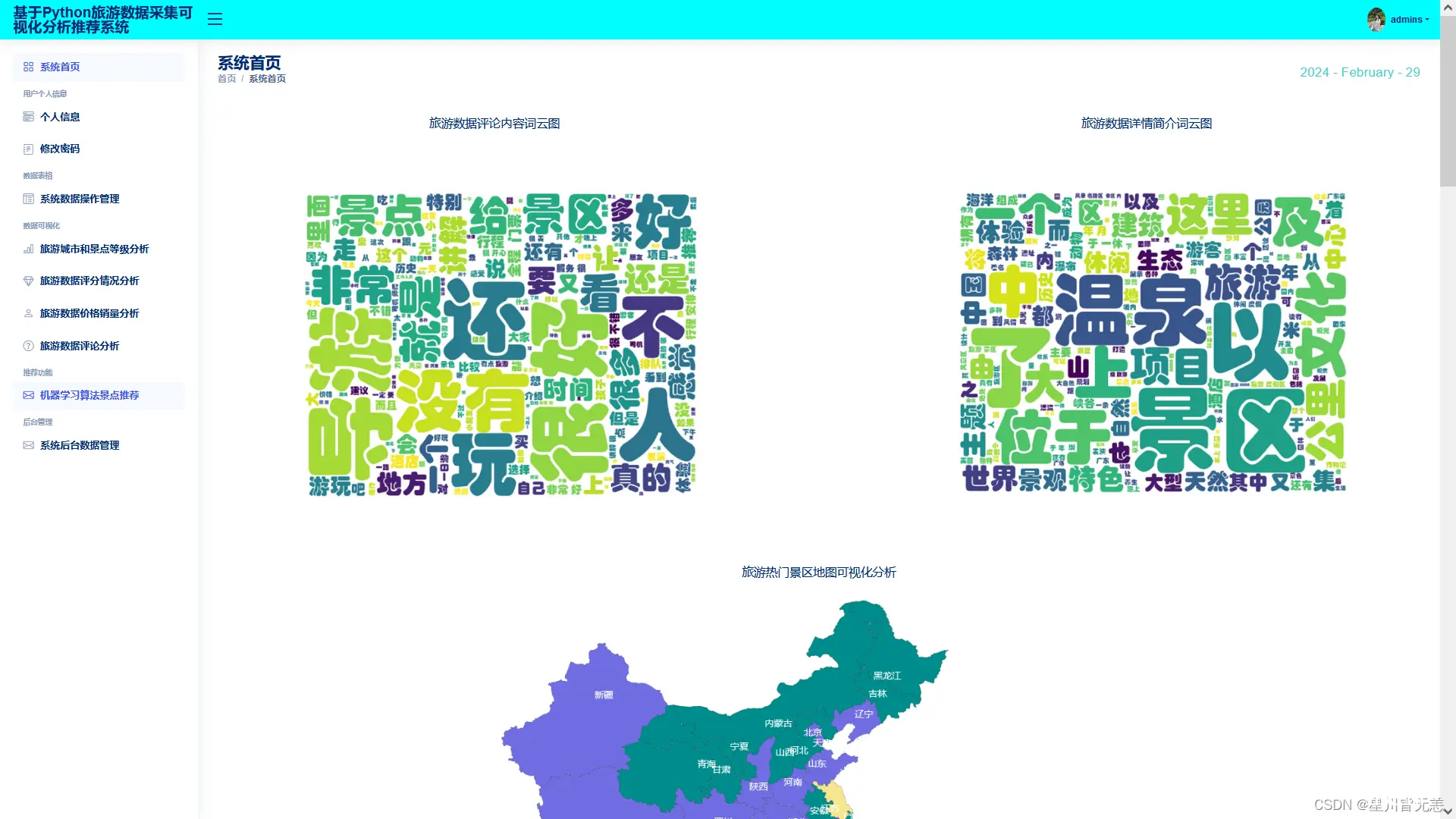
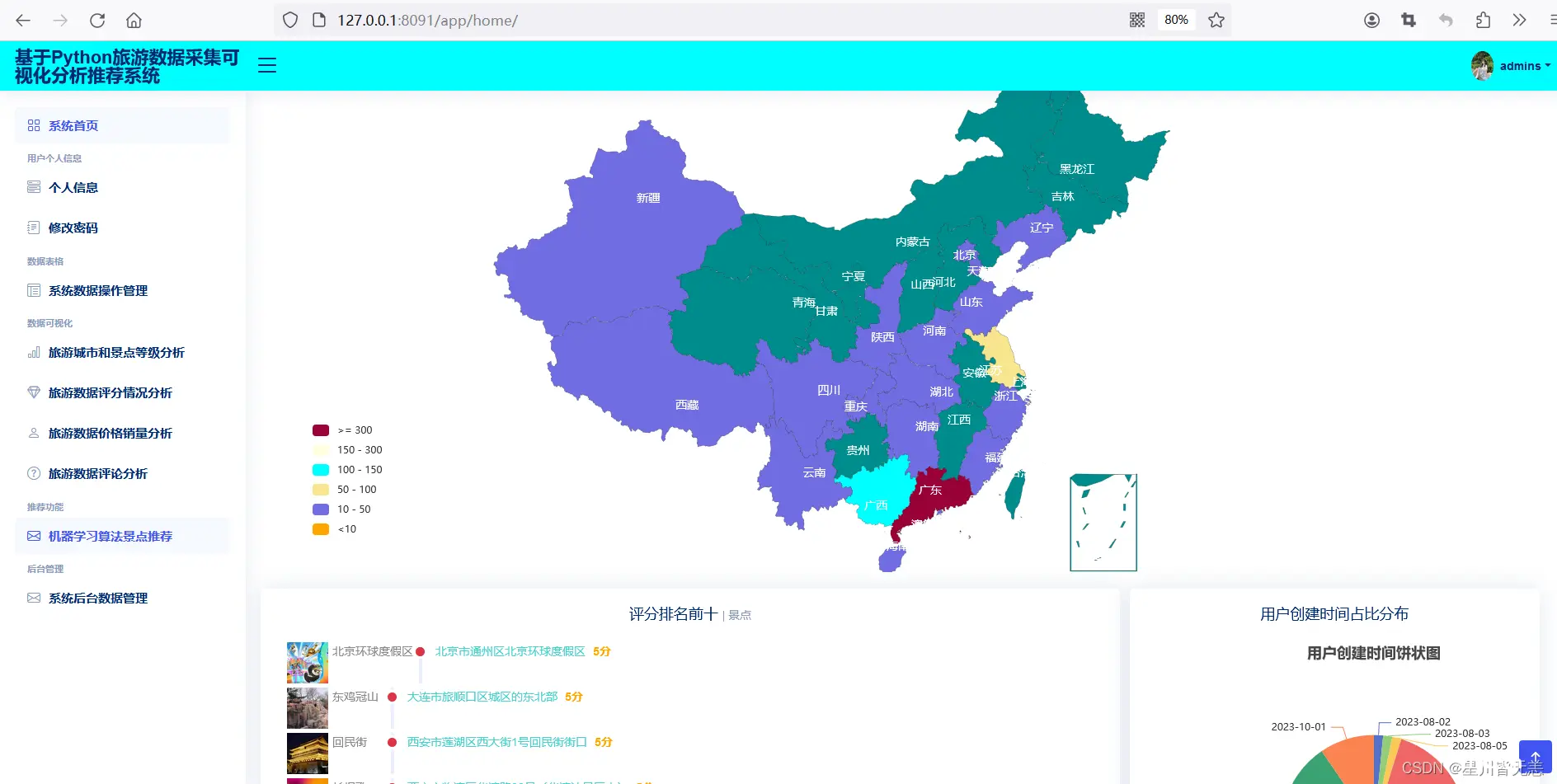
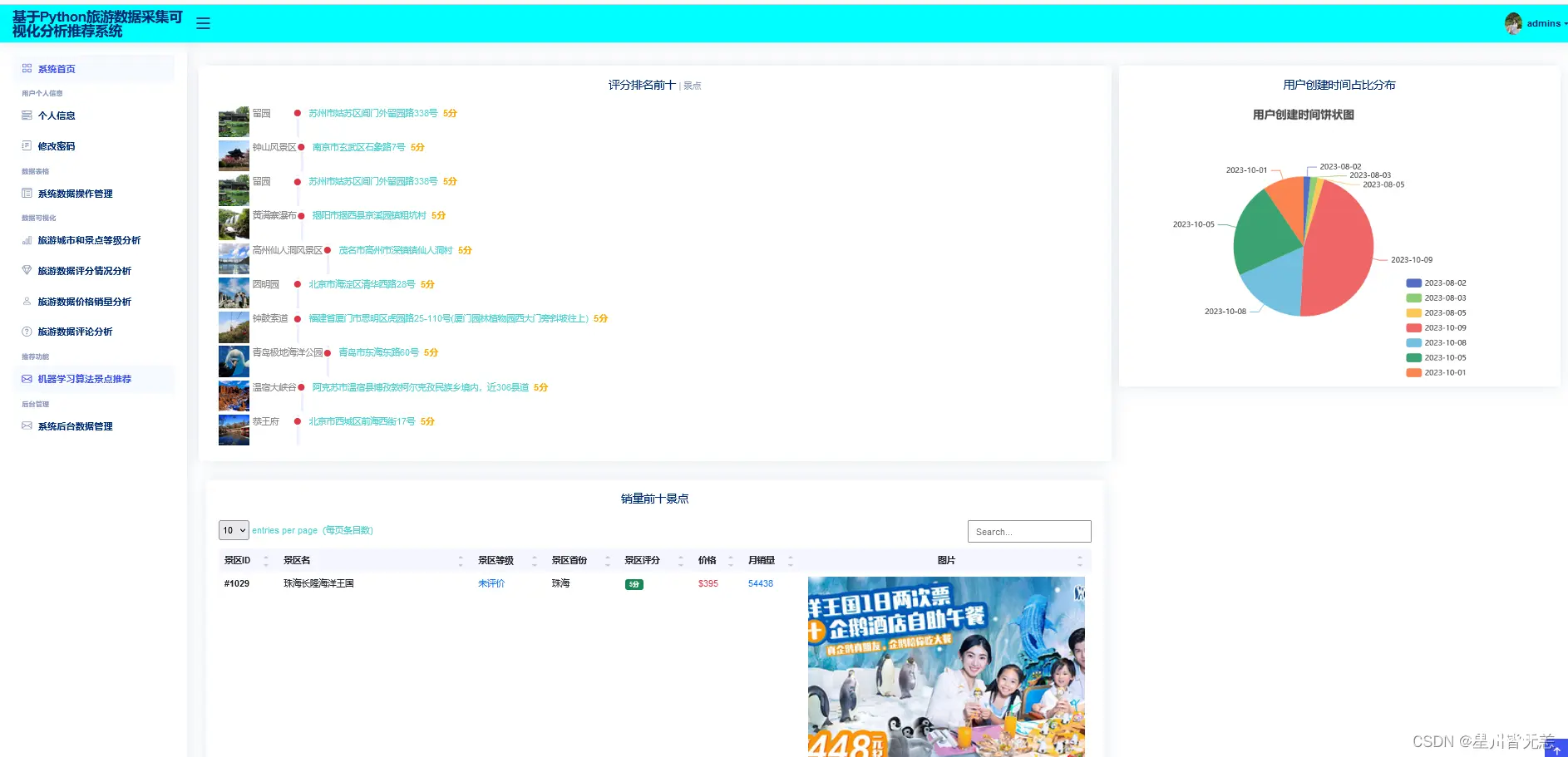
系统首页
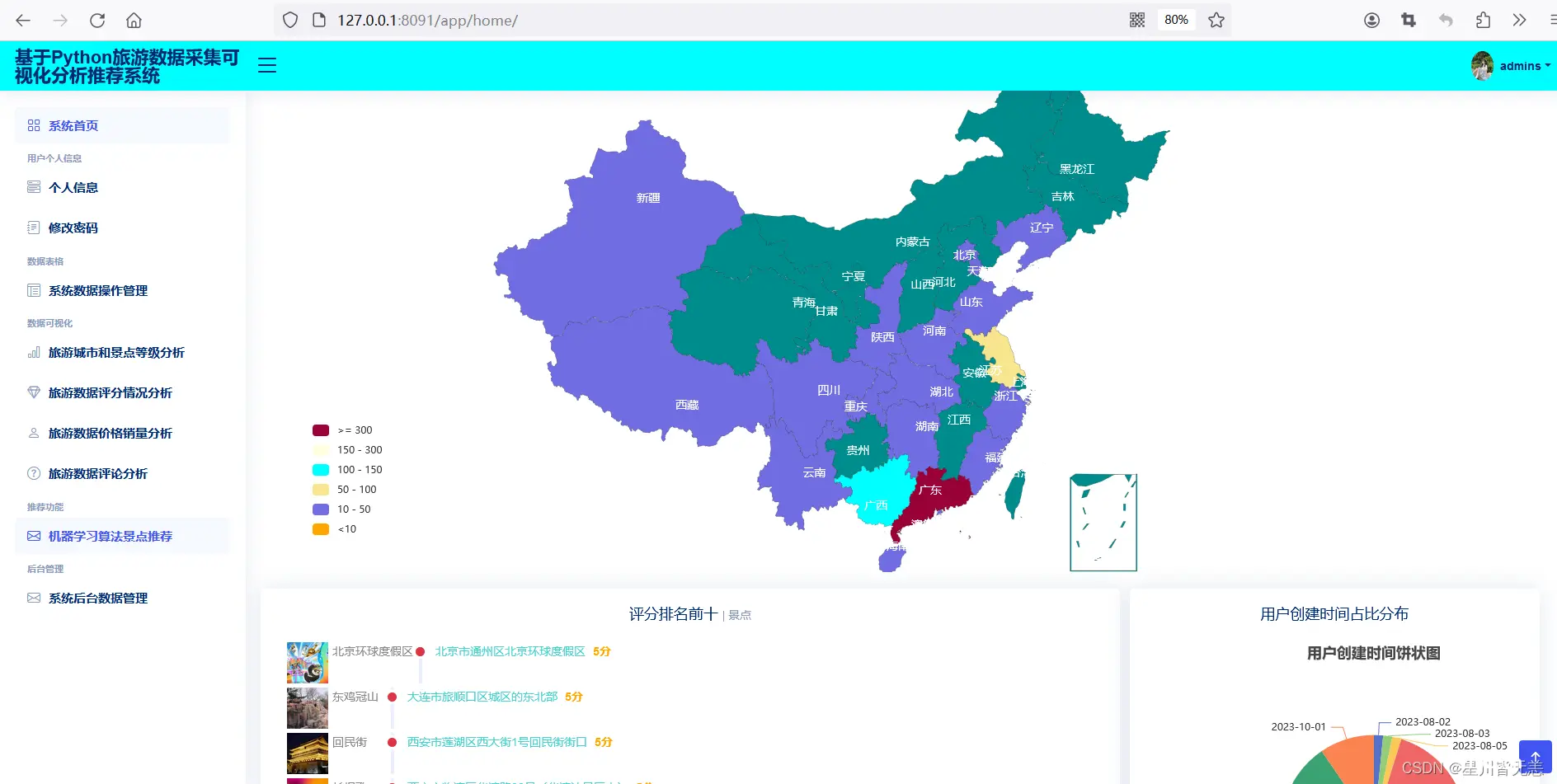
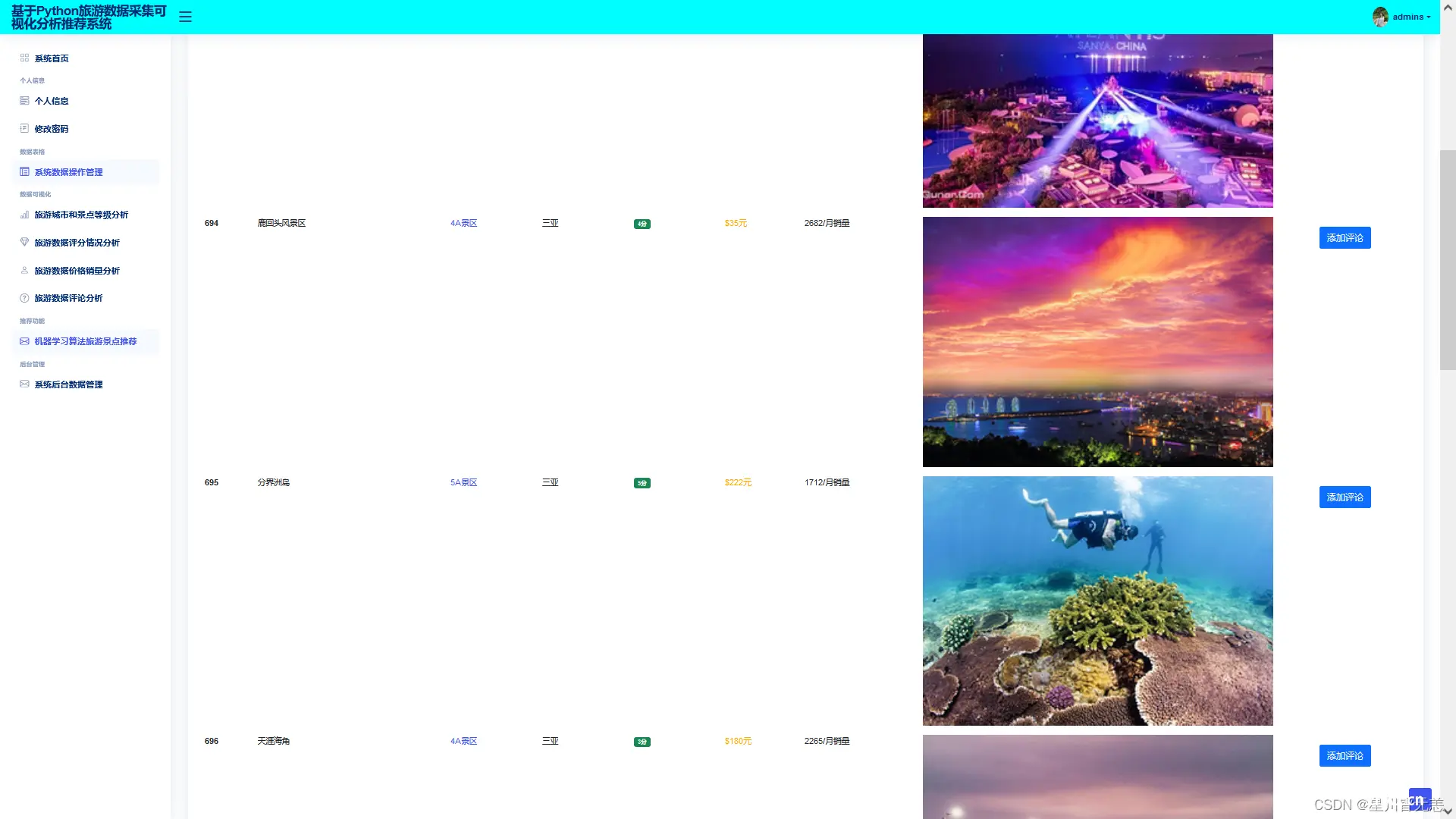
数据操作管理
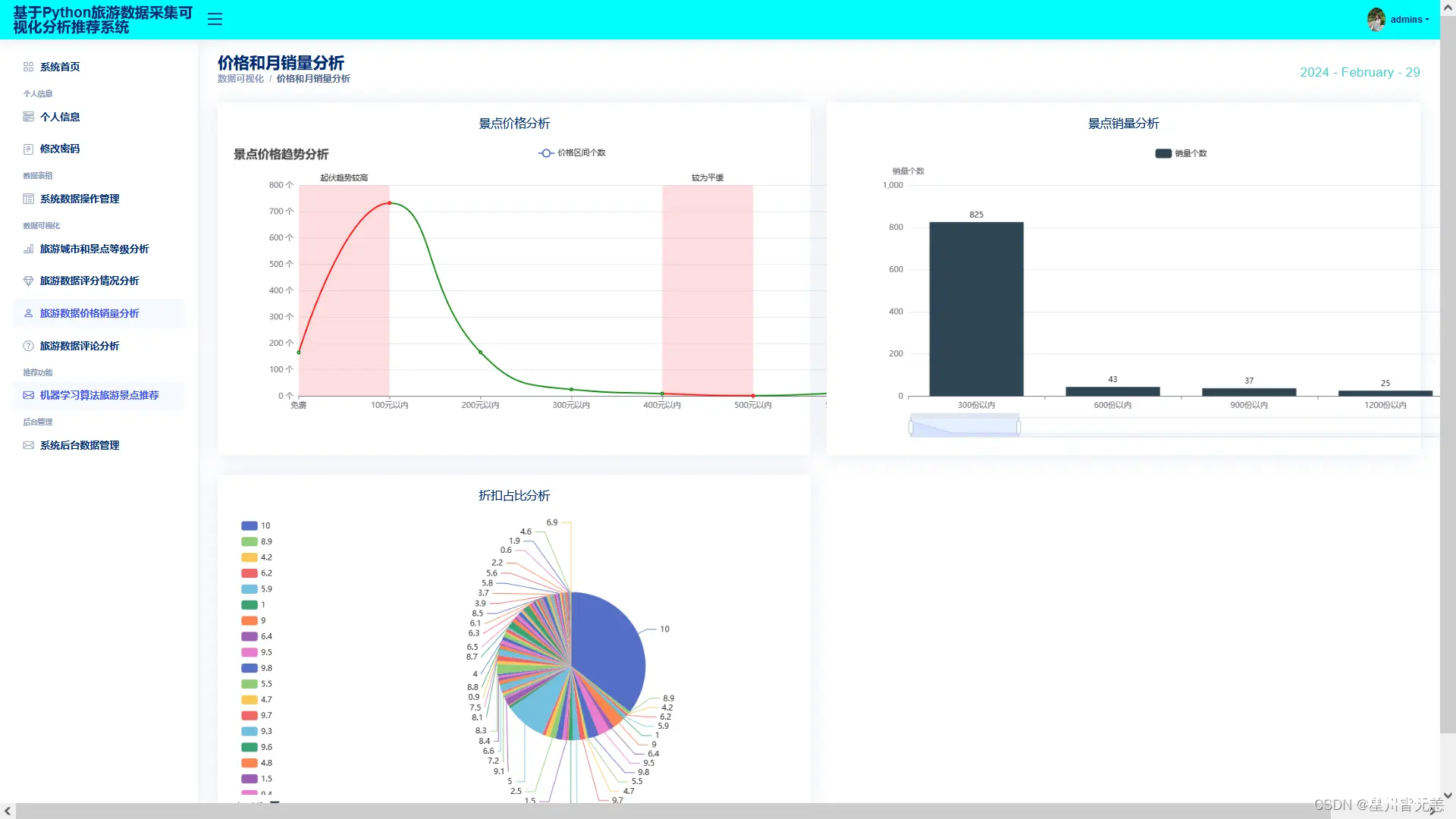
价格与销量分析
旅游城市和景点等级分析
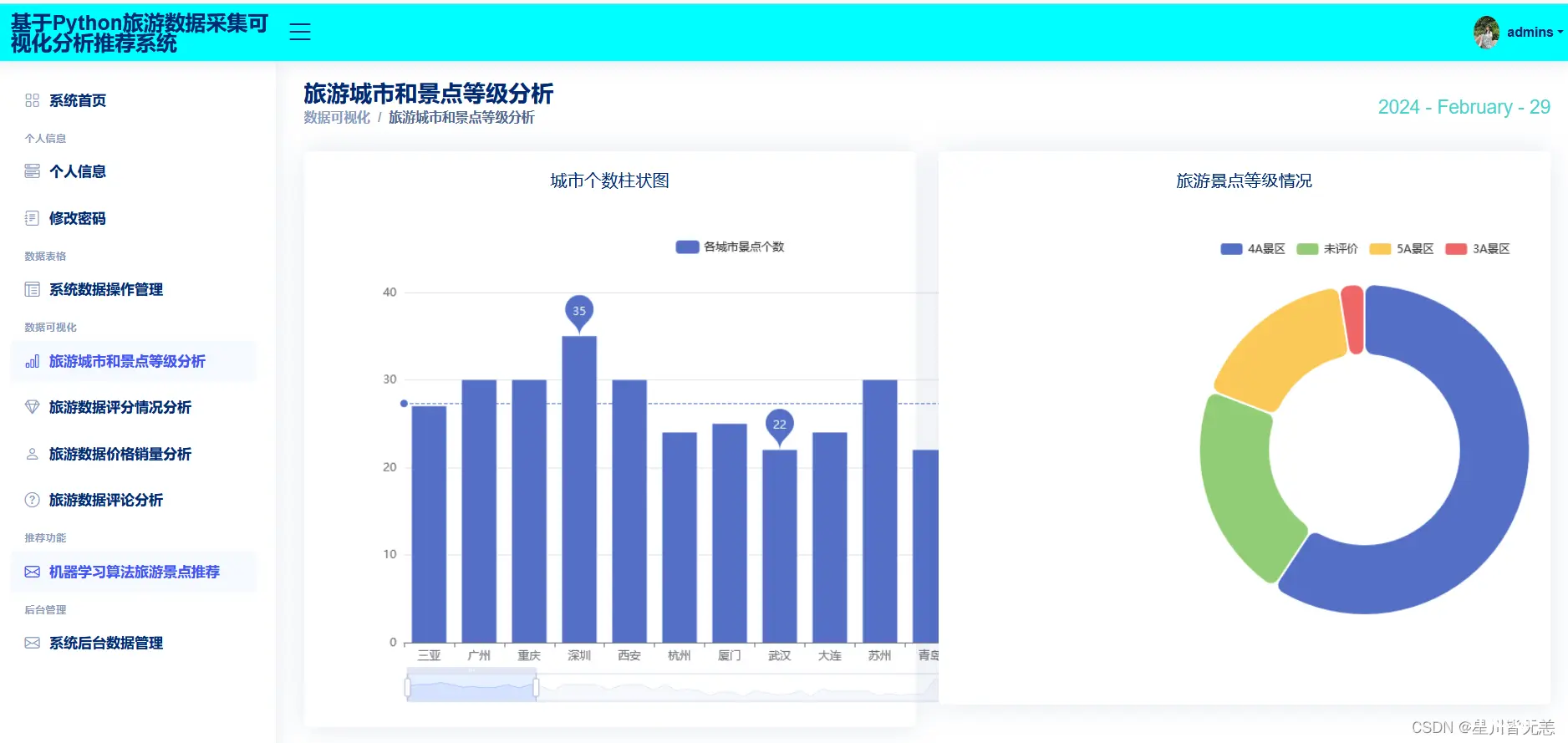
旅游数据评分情况分析
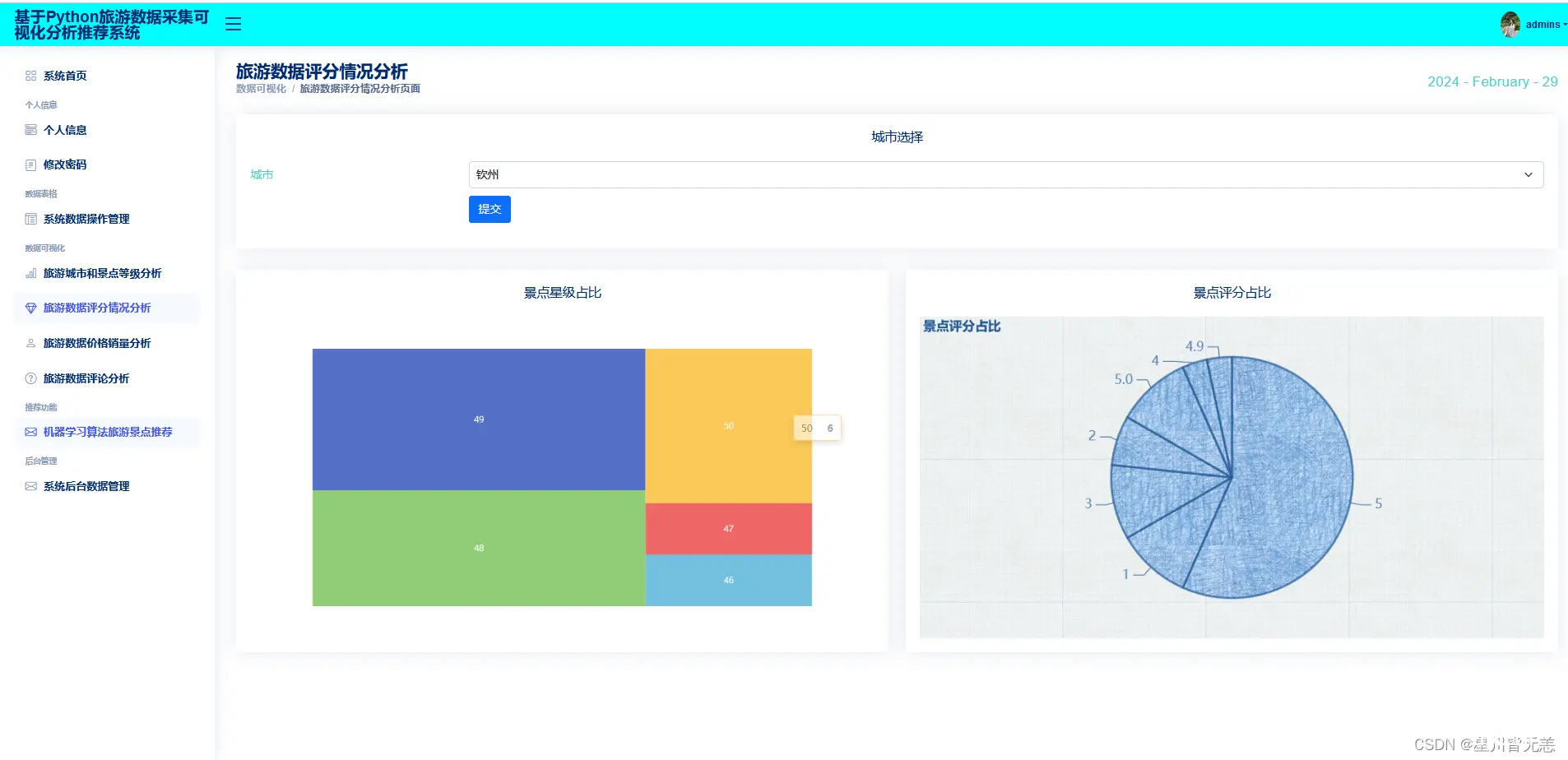
旅游数据评论情况分析
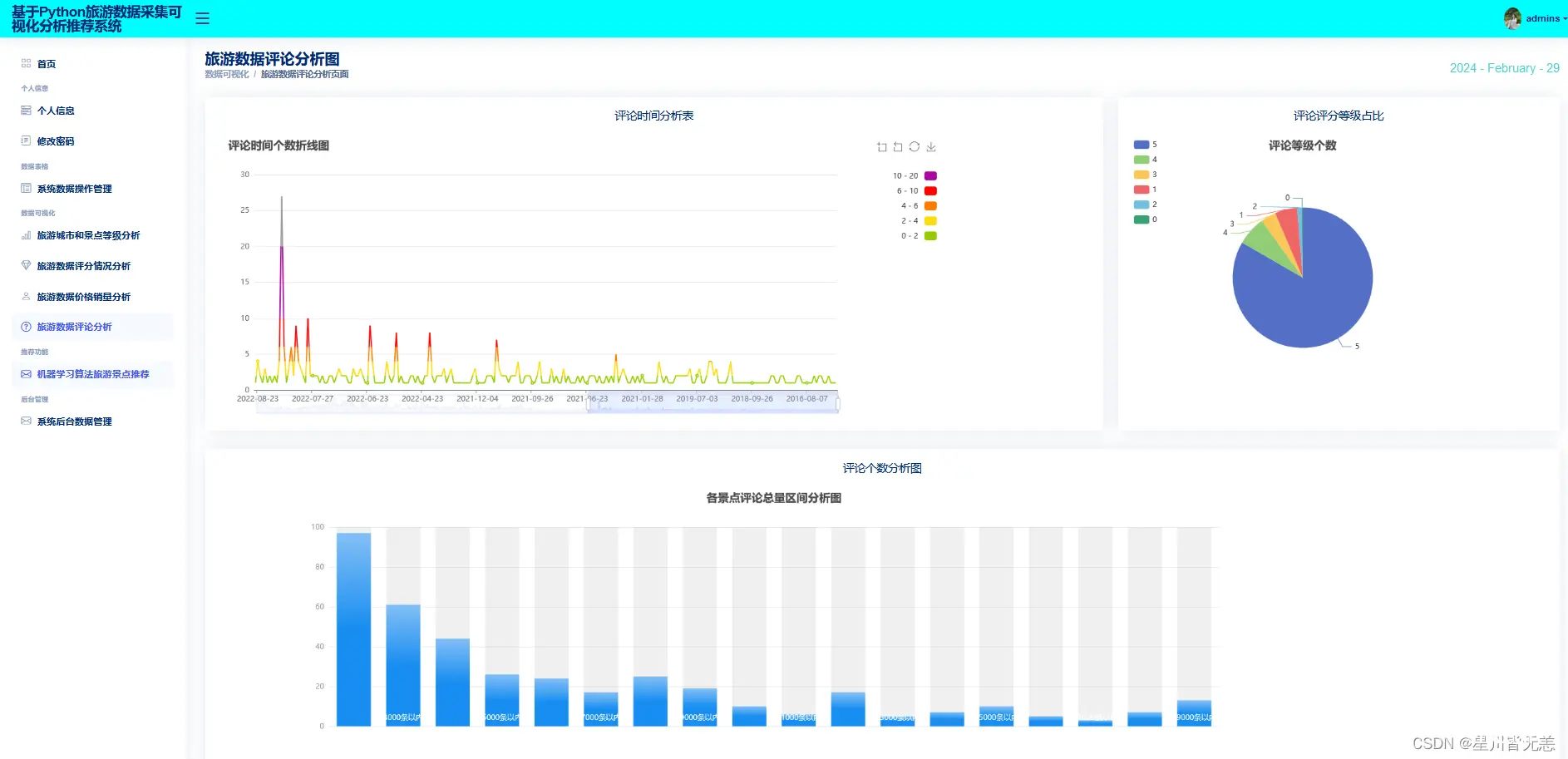
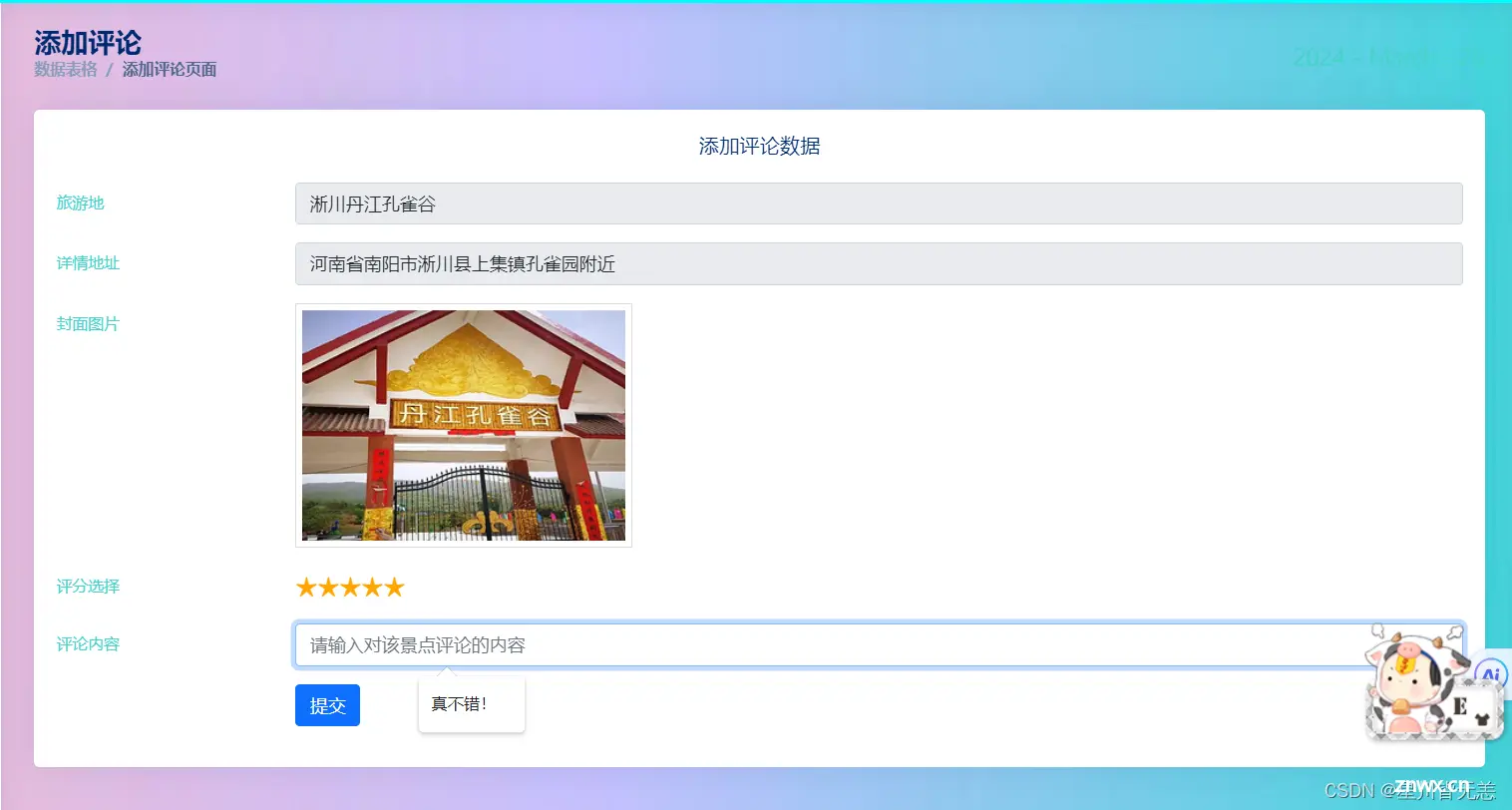
旅游景点用户评论评分
机器学习算法旅游景点及路线推荐
Django系统后台管理
http://127.0.0.1:8091/admin
六、结语
需项目资料/商业合作/交流探讨等可以添加下面个人名片,后续有时间会持续更新更多优质项目内容,感谢各位的喜欢与支持!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。