
摘自知乎博主作者:月来客栈首先让我们先一起来看看作者当时为什么要提出Transformer这个模型?需要解决什么样的问题?现在的模型有什么样的缺陷?现在主流的序列模型都是基于复杂的循环神经网络或者是构造而来的Enc...

在医学图像分割领域,传统的U-Net模型已经取得了显著成果。然而,随着Transformer在计算机视觉领域的崛起,将其与U-Net结合的TransUNet模型成为了新的热门。TransUNet是一种融合了Tra...
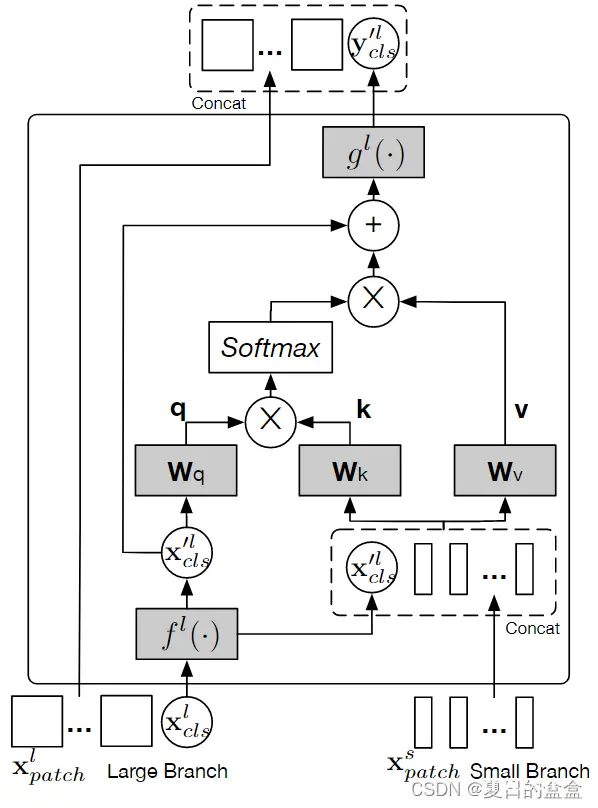
本文提出一个双分支transformer,来组合不同尺寸的图像块(即transformer中的token),以产生更强的图像特征。该方法处理具有不同计算复杂度的两个独立分支的小块和大块token,然后纯粹通过注意力多次...

DeformableAttention(可变形注意力)首先在2020年10月初商汤研究院的《DeformableDETR:DeformableTransformersforEnd-to-EndOb...
![[Algorithm] BEVformer 源码细节学习&&ubuntu20.04下的环境配置&&目标跑起开源代码&&论文学习笔记](/uploads/2024/08/31/1725088025706037101.webp)
之前学习了机器学习基础,神经网络基础,pytorch和Transformer基础,学习了几个demo并设计了一个demo任务,现在开始正式研究BEV相关内容。计划从源码和先跑起来入手,随后分模块逐步学习。期间分享...
C#Winform开源UI库,轻松开发Winform绚丽界面_winform第三方控件库...

本文对transformers之pipeline的问答(question-answering)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文...
true#函数调用变量要么都在同一行上,,【代码风格】,,4#当一行代码放不下,...

过去的几个月,我们目睹了使用基于transformer模型作为扩散模型的主干网络来进行高分辨率文生图(text-to-image,T2I)的趋势。和一开始的许多扩散模型普遍使用UNet架构不同,这些模型使用transformer架构作为扩散过程...
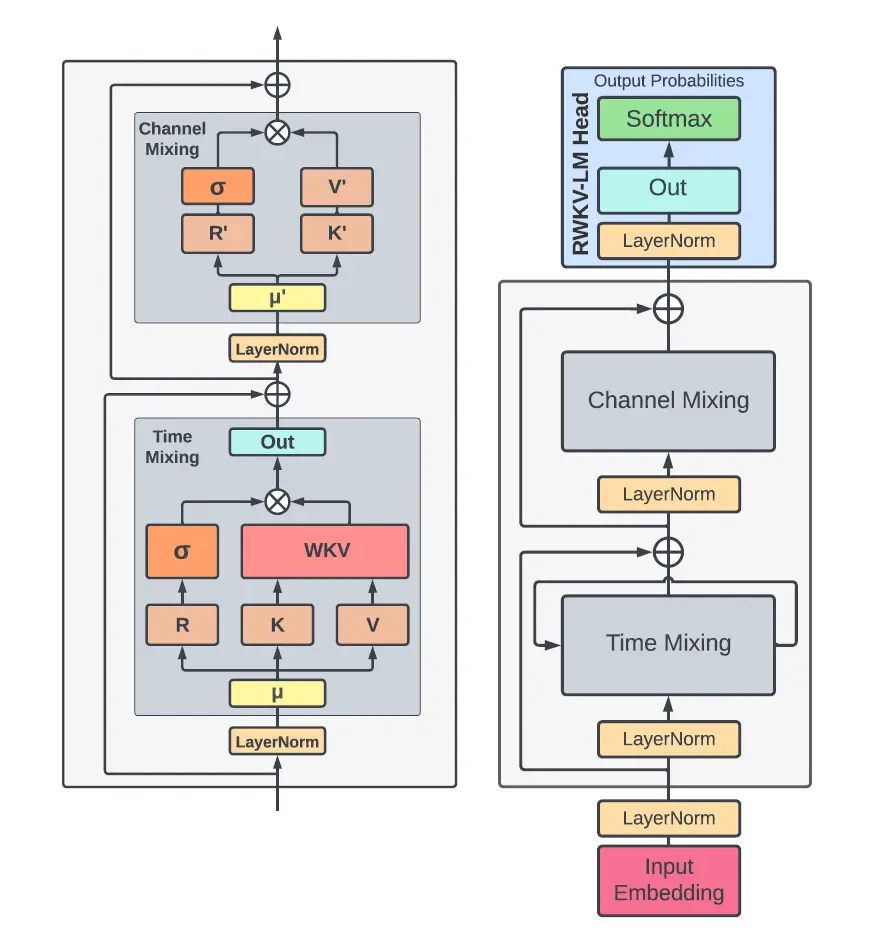
开源项目RWKV是一个“具有GPT级别LLM性能的RNN,也可以像transformer并行训练。它主要是解决了Transformer的高成本。注意力机制是Transformer霸权背后的驱动力之一。_r...