【人工智能】Transformers之Pipeline(十四):问答(question-answering)
CSDN 2024-08-31 12:01:02 阅读 67

目录
一、引言
二、问答(question-answering)
2.1 概述
2.2 bert的改进模型—RoBERTa(Robustly optimized BERT approach)
2.2.1 技术背景
2.2.2 RoBERTa的改进点
2.2.3 RoBERTa模型结构
2.3 应用场景
2.4 pipeline参数
2.4.1 pipeline对象实例化参数
2.4.2 pipeline对象使用参数
2.4.3 pipeline返回参数
2.5 pipeline实战
2.6 模型排名
三、总结
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型
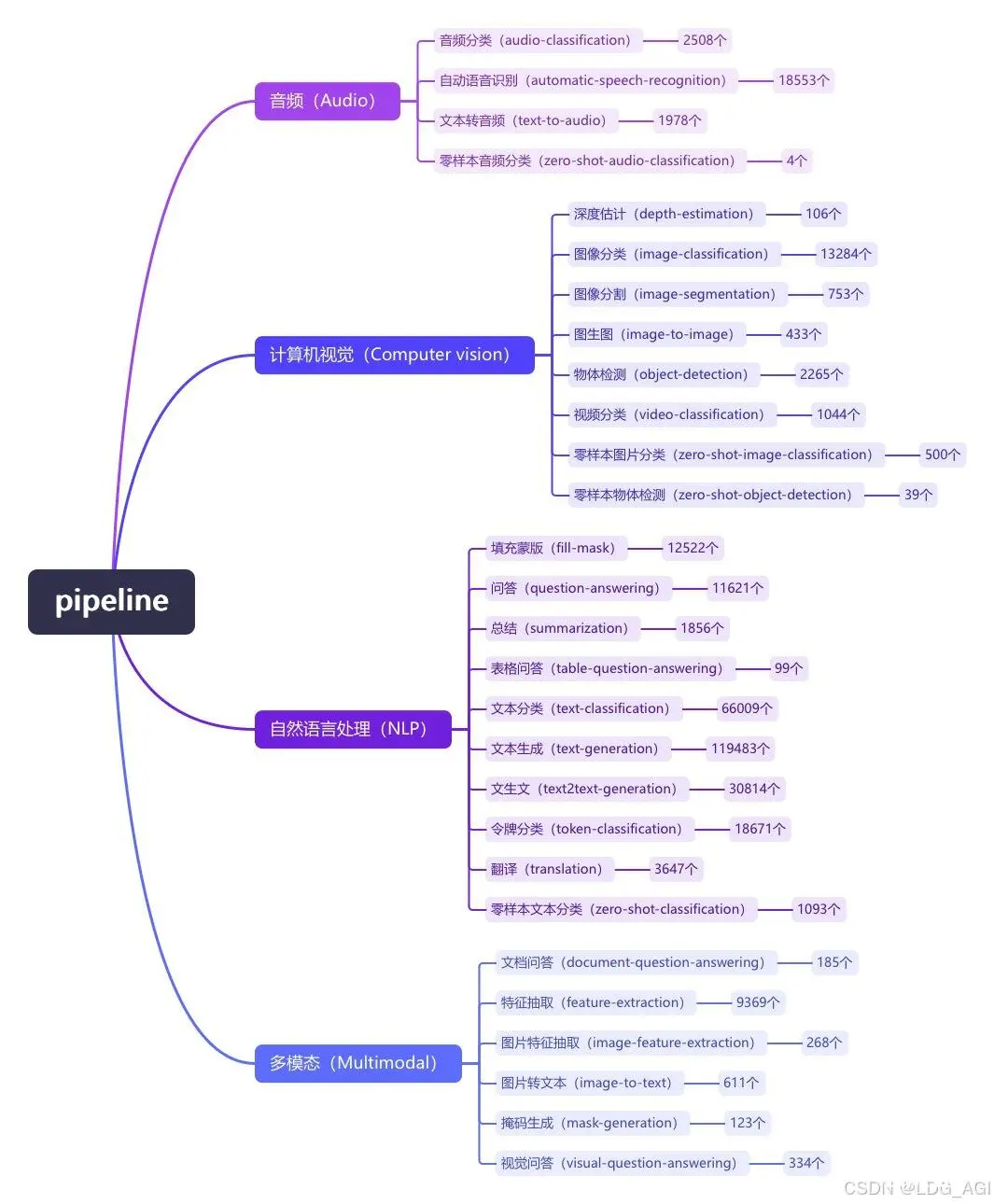
今天介绍NLP自然语言处理的第二篇:问答(question-answering),在huggingface库内有1.2万个问答(question-answering)模型,最典型的是在bert上的改进模型RoBERTa。
二、问答(question-answering)
2.1 概述
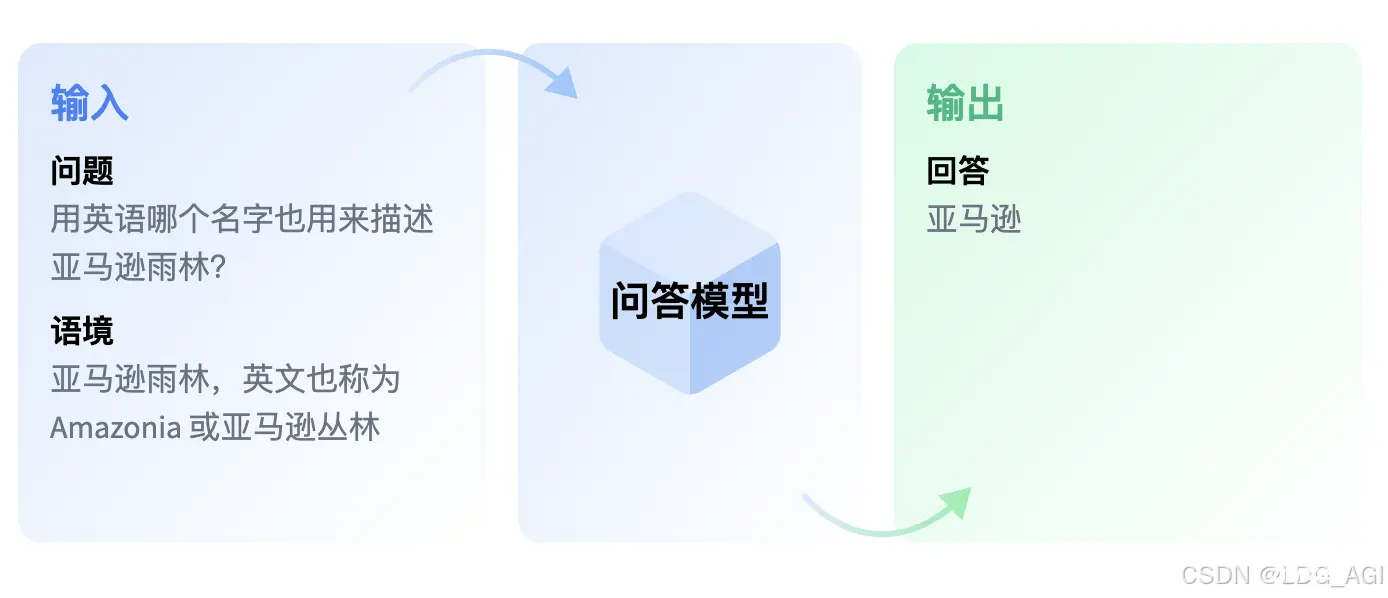
问答模型可以从给定的文本中检索问题的答案,这对于在文档中搜索答案非常有用。一些问答模型可以在没有上下文的情况下生成答案!
2.2 bert的改进模型—RoBERTa(Robustly optimized BERT approach)
2.2.1 技术背景
最初的BERT预训练模型并没有得到很好的训练,导致其在下游任务上的性能比之后发布的模型性能要略差(例如XLNet),但实际上,BERT模型的性能还有提升的空间,通过对BERT预训练过程的优化,可以进一步提升下游任务的表现,并且具有更强的鲁棒性
2.2.2 RoBERTa的改进点
RoBERTa主要通过以下四种方式来提升BERT性能:
更长的训练步数、更大的Batch Size、更多的数据;移除NSP训练目标;更长的序列;将静态mask改为动态mask。
RoBERTa已经被广泛的应用于各类由BERT衍生的模型参数初始化,可以视为是完全体形态的BERT。
2.2.3 RoBERTa模型结构
RoBERTa只是应用了更好的训练技巧, 因此整体结构是没有发生任何变化的。其模型结构与BERT模型结构相同。
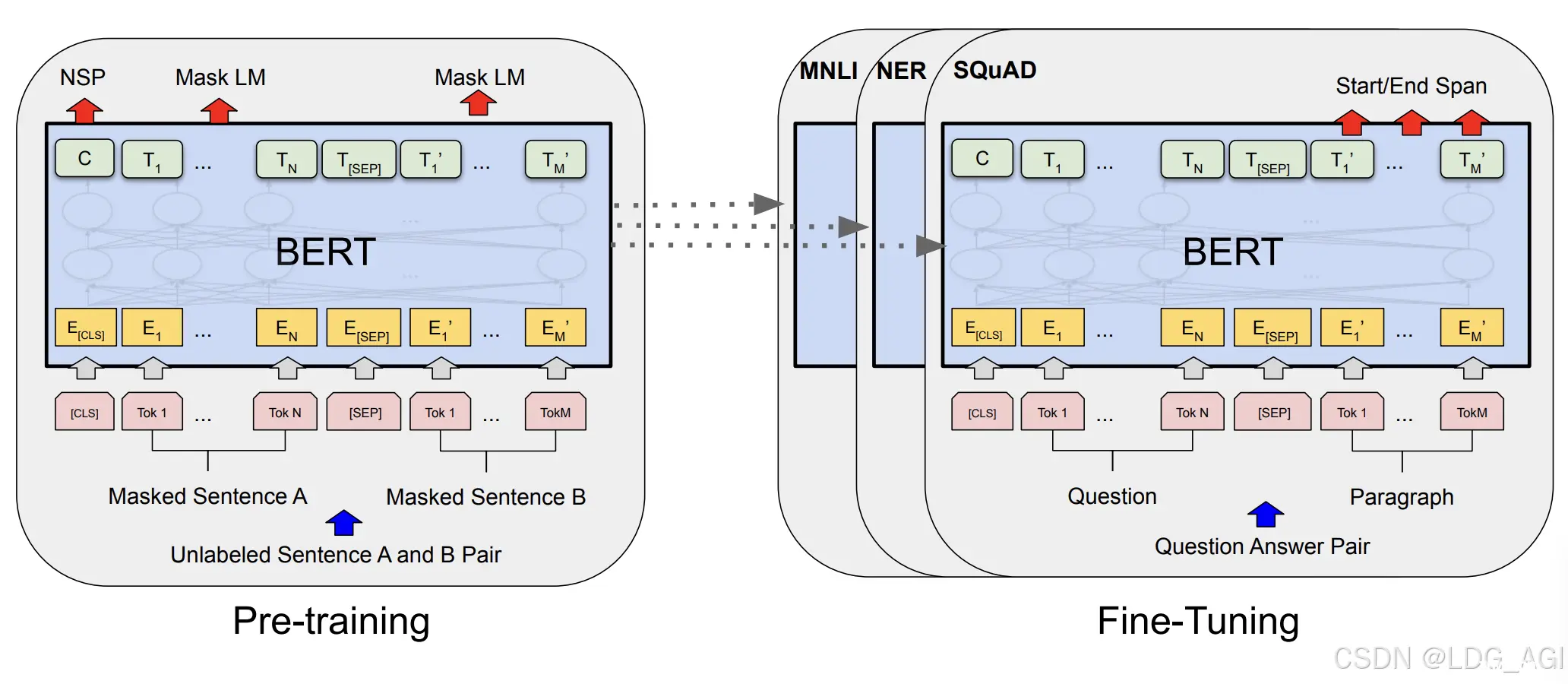
更多关于RoBERTa的原理、预训练和微调方法可以参考【NLP】预训练语言模型——RoBERTa
2.3 应用场景
问题回答(Question Answering):ROBERTA 可以用于问答系统中,帮助用户找到特定问题的答案。例如,在一个常见的问题库中,有一条问题是“什么是机器学习?” ROBERTA 可以被训练成能够识别出这个问题,并输出相应的答案。阅读理解(Reading Comprehension):ROBERTA 也可以用于阅读理解任务中,帮助用户更好地理解文本内容。例如,在一个文章中,有一段描述机器学习的原理,ROBERTA 可以被训练成能够回答关于这段文字的问题,如“机器学习是什么?”、“机器学习有哪些应用场景?”开放域问答(Open-Domain Question Answering):ROBERTA 还可以用于开放域问答任务中,这意味着系统需要从大量的文本数据中找到答案,而不是依赖于特定的问题库。例如,用户提出的一个开放域的问题是“机器学习在医疗领域有哪些应用?” ROBERTA 可以被训练成能够从互联网上找到的文章和研究论文中找到相关的答案。
2.4 pipeline参数
2.4.1 pipeline对象实例化参数
model(PreTrainedModel或TFPreTrainedModel)— 管道将使用其进行预测的模型。 对于 PyTorch,这需要从PreTrainedModel继承;对于 TensorFlow,这需要从TFPreTrainedModel继承。tokenizer ( PreTrainedTokenizer ) — 管道将使用 tokenizer 来为模型编码数据。此对象继承自 PreTrainedTokenizer。modelcard(<code>str或
ModelCard,可选)— 属于此管道模型的模型卡。framework(str,可选)— 要使用的框架,"pt"适用于 PyTorch 或"tf"TensorFlow。必须安装指定的框架。task(str,默认为"")— 管道的任务标识符。num_workers(int,可选,默认为 8)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的工作者数量。batch_size(int,可选,默认为 1)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的批次的大小,对于推理来说,这并不总是有益的,请阅读使用管道进行批处理。args_parser(ArgumentHandler,可选) - 引用负责解析提供的管道参数的对象。device(int,可选,默认为 -1)— CPU/GPU 支持的设备序号。将其设置为 -1 将利用 CPU,设置为正数将在关联的 CUDA 设备 ID 上运行模型。您可以传递本机torch.device或str太torch_dtype(str或torch.dtype,可选) - 直接发送model_kwargs(只是一种更简单的快捷方式)以使用此模型的可用精度(torch.float16,,torch.bfloat16...或"auto")binary_output(bool,可选,默认为False)——标志指示管道的输出是否应以序列化格式(即 pickle)或原始输出数据(例如文本)进行。
2.4.2 pipeline对象使用参数
args(
SquadExample或列表)——包含问题和上下文的SquadExample一个或多个。SquadExampleX(SquadExample或列表SquadExample,可选) - 一个或多个SquadExample包含问题和上下文(将以与传递第一个位置参数相同的方式处理)。data(SquadExample或列表SquadExample,可选) -SquadExample包含问题和上下文的一个或多个(将以与作为第一个位置参数传递相同的方式处理)。question(str或List[str])——一个或多个问题(必须与论点结合使用context)。context(str或List[str])—— 与问题相关的一个或多个上下文(必须与论点结合使用question)。topk(可选int,默认为 1)— 返回的答案数量(将按可能性顺序选择)。请注意,如果上下文中没有足够的选项,我们将返回少于 topk 个答案。doc_stride(int,可选,默认为 128)— 如果上下文太长,无法与模型的问题相匹配,则会将其分成几个部分,并有一定的重叠。此参数控制重叠的大小。max_answer_len(int,可选,默认为 15)——预测答案的最大长度(例如,只考虑长度较短的答案)。max_seq_len (int,可选,默认为 384) — 传递给模型的每个块的标记中整个句子(上下文 + 问题)的最大长度。如果需要,上下文将被分成几个块(使用doc_stride重叠)。max_question_len (int,可选,默认为 64) — 标记化后问题的最大长度。如果需要,它将被截断。handle_impossible_answer(bool,可选,默认为False)——我们是否接受不可能作为答案。align_to_words(bool,可选,默认为True)— 尝试将答案与真实单词对齐。提高空格分隔语言的质量。可能会损害非空格分隔语言(如日语或中文)的质量
2.4.3 pipeline返回参数
score(
float)—— 与答案相关的概率。start (int) — 答案的字符起始索引(在输入的标记化版本中)。end (int) — 答案的字符结束索引(在输入的标记化版本中)。answer(str) — 问题的答案。
2.5 pipeline实战
采用pipeline,使用google的bert中文版模型bert-base-chinese对文本进行补全。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
qa = pipeline(model="deepset/roberta-base-squad2", task="question-answering")code>
output = qa(question="Where do I live?", context="My name is Wolfgang and I live in Berlin")code>
print(output)
执行后,自动下载模型文件并进行识别:

2.6 模型排名
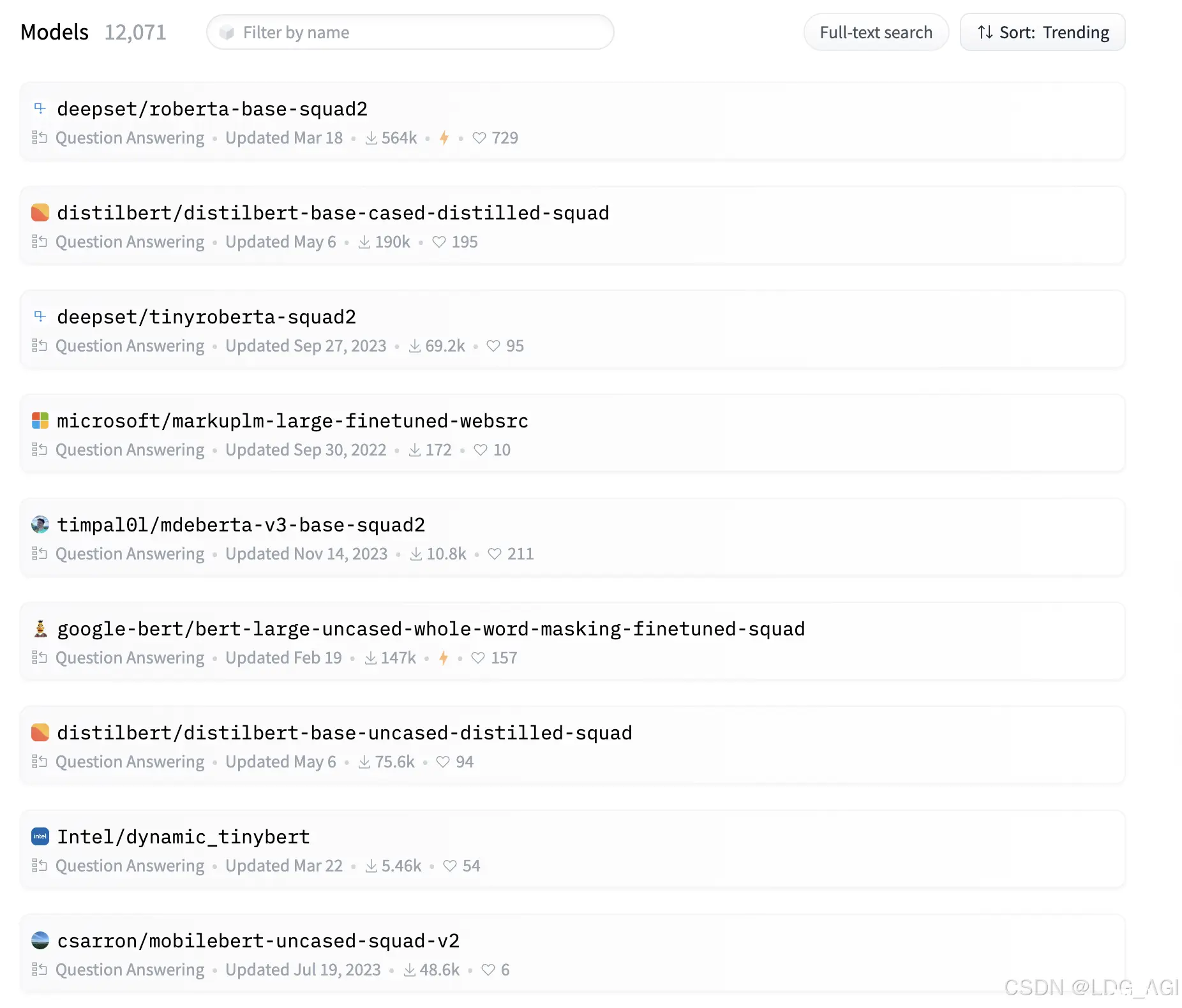
在huggingface上,我们将填充蒙版(fill-mask)模型按下载量从高到低排序,总计1.2万个模型,排名第一的当属google-bert/bert-base-uncased。
三、总结
本文对transformers之pipeline的问答(question-answering)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用NLP中的问答(question-answering)模型。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《Transformers-Pipeline概述》
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
《Transformers-Pipeline 第一章:音频(Audio)篇》
【人工智能】Transformers之Pipeline(一):音频分类(audio-classification)
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio/text-to-speech)
【人工智能】Transformers之Pipeline(四):零样本音频分类(zero-shot-audio-classification)
《Transformers-Pipeline 第二章:计算机视觉(CV)篇》
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
【人工智能】Transformers之Pipeline(八):图生图(image-to-image)
【人工智能】Transformers之Pipeline(九):物体检测(object-detection)
【人工智能】Transformers之Pipeline(十):视频分类(video-classification)
【人工智能】Transformers之Pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
《Transformers-Pipeline 第三章:自然语言处理(NLP)篇》
【人工智能】Transformers之Pipeline(十三):填充蒙版(fill-mask)
【人工智能】Transformers之Pipeline(十四):问答(question-answering)
【人工智能】Transformers之Pipeline(十五):总结(summarization)
【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
【人工智能】Transformers之Pipeline(二十一):翻译(translation)
【人工智能】Transformers之Pipeline(二十二):零样本文本分类(zero-shot-classification)
《Transformers-Pipeline 第四章:多模态(Multimodal)篇》
【人工智能】Transformers之Pipeline(二十三):文档问答(document-question-answering)
【人工智能】Transformers之Pipeline(二十四):特征抽取(feature-extraction)
【人工智能】Transformers之Pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】Transformers之Pipeline(二十六):图片转文本(image-to-text)
【人工智能】Transformers之Pipeline(二十七):掩码生成(mask-generation)
【人工智能】Transformers之Pipeline(二十八):视觉问答(visual-question-answering)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。