[Algorithm] BEVformer 源码细节学习&&ubuntu20.04下的环境配置&&目标跑起开源代码&&论文学习笔记
HERR_QQ 2024-08-31 15:07:03 阅读 82
写在前面
计划从源码和先跑起来入手,随后分模块逐步学习。期间分享自己的困惑,有趣高效的语法现象。
之前学习了机器学习和神经网络(RNN) pytorch使用等相关知识,进行了两个demo的实战
如果对安装不感兴趣,欢迎大佬们阅读第二步交流指点。
学习资源 (不断更新)
深蓝学院好老哥的解读论文bilibili小哥论文学习视频,有点乱事后看见的复现老哥早看见就抄作业了,22下安装太折腾了解读1解读2
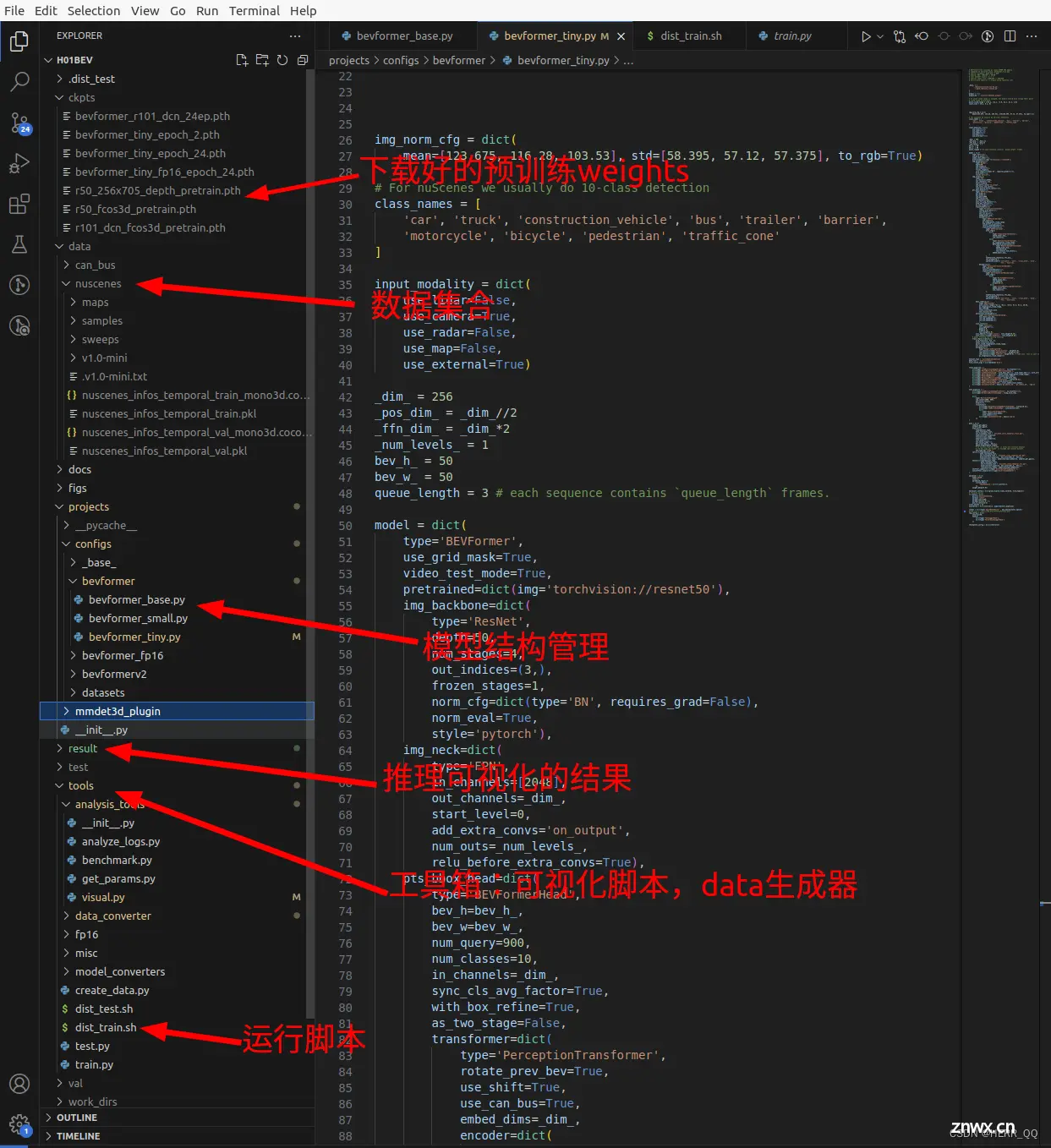
第一步目标把开源代码跑起来
环境准备
https://zhuanlan.zhihu.com/p/424817205
可以按照以上内容先安装号显卡驱动、Cuda和配置路径。
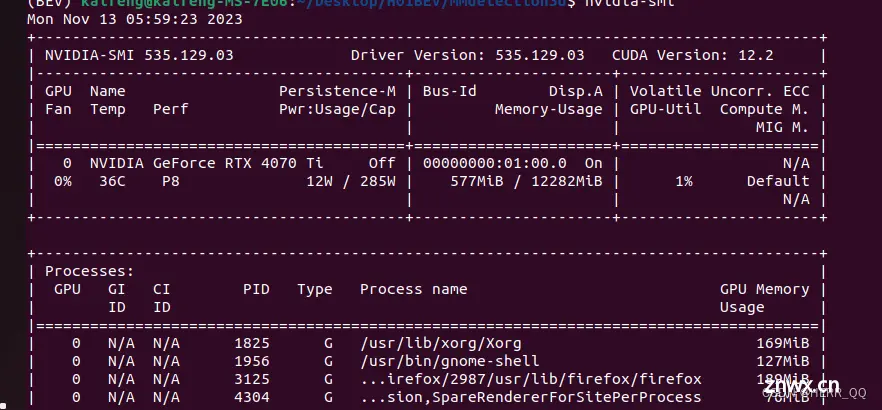
显卡驱动安装后 我用smi显示不出来显卡信息。
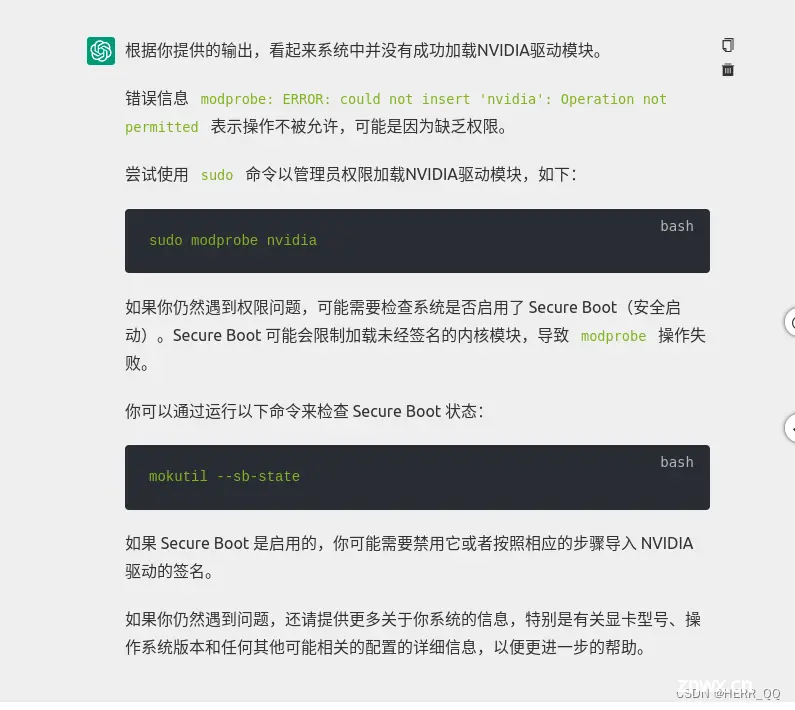
我明明在自带的software中心中的driver选择了驱动,但是smi命令找不到显卡信息,最后通过gpt查询,原来显卡驱动一直没有加载。因为我开起来secure boot的签名验证。关闭secure boot 就好了。
BEV 相关环境准备
首先 conda 和pip换源操作可以参考:https://blog.csdn.net/h904798869/article/details/131719404
或者单用
<code>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple +包名
阿里云镜像:https://mirrors.aliyun.com/pypi/simple/
清华大学镜像:https://pypi.tuna.tsinghua.edu.cn/simple/
安装建议严格按照文档说明来,其中mmdection的内容建议按照maptr的来
BEVFormer
MapTR
其中:
Building wheel for mmcv-full (setup.py) … / 这一步很慢,安心等待mmdection 用maptr的方法安装https://github.com/zhiqi-li/storage/releases 这里我是用Windows的梯直接去仓库拿的,贼快包括预训练参数也可以直接挂梯子作者仓库去拿download安装cuda,cuda是系统级的东西不会在自己conda虚拟环境下,安装完成后别忘记添加路径,同时如果驱动安装好了就不必安装cuda自带的驱动,这里都有写明白https://blog.csdn.net/h904798869/article/details/131719404
记录我安装的几个问题 :
第一个大报错 是mmdetection编译报错,
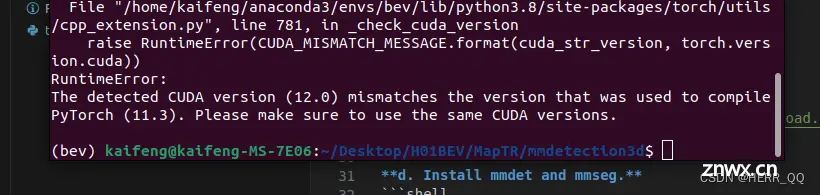
查询了很久 发现根源是我的系统找不到有效的cuda
这里贴两个帖子,他们在讲解 pytorch cuda 和显卡驱动的 辩证关系
基本就是在排查 GPU驱动 Cuda版本 Pytorch版本之间的问题
https://zhuanlan.zhihu.com/p/658800083
https://zhuanlan.zhihu.com/p/91334380 我认为这个讲的最好
https://blog.csdn.net/qq_41094058/article/details/116207333
大家也可以使用我下面的代码验证以下
驱动安装说明
用nvcc -v可以看到cuda版本
在conda list中确认其他库的版本
lspci | grep -i nvidia 查看显卡型号
import torch
print('CUDA 可用:', torch.cuda.is_available())
if torch.cuda.is_available():
print('可用的 CUDA 设备数:', torch.cuda.device_count())
print('当前 CUDA 设备索引:', torch.cuda.current_device())
print('当前 CUDA 设备名称:', torch.cuda.get_device_name(torch.cuda.current_device()))
else:
print('CUDA 不可用')
import torch, torchvision
print(torch.__version__, torch.cuda.is_available())
# Pytorch 实际使用的运行时的 cuda 目录
import torch.utils.cpp_extension
print(torch.utils.cpp_extension.CUDA_HOME)
# 编译该 Pytorch release 版本时使用的 cuda 版本
import torch
print(torch.version.cuda )
如果pytorch成功导入了,但是出现false 则说明cuda设备不可用,可以去NVidia官网自动查找对应驱动https://www.nvidia.com/Download/index.aspx
以下是cuda的安装地址
https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=runfile_local
此外也可以使用ubantu系统自己查到的驱动

或者也可以使用
如此我可以使用上面的代码打印出内容了

我的nvidia-smi命令也可以正常输出了
但依然有报错
我cuda toolkit和 nvidia driver是版本是可以匹配的,但cuda版本太高了我去

然后重新严格安装配环境教程安装了cuda,不追求自己研究了
第二个大报错 安装 Detectron2
<code>python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
长时间等待而后报错
git clone git@github.com:facebookresearch/detectron2.git
然后本地安装
pip install .
第一次接触的库的笔记:
mmcv-full是一个针对计算机视觉任务的开源工具库
MMDetection(Masked Object Detection)是一个开源计算机视觉库,用于目标检测任务。它提供了丰富的目标检测算法和模型,包括 Faster R-CNN、Mask R-CNN 等
MMsegmentation(Image Segmentation)是一个开源计算机视觉库,用于图像分割任务。它包含了多种图像分割算法和模型,如 U-Net、DeepLabV3 等。
Detectron2 是由Facebook AI Research(FAIR)开发的开源目标检测库。它是原始 Detectron 库的继任者,为构建计算机视觉模型提供了灵活和模块化的框架,特别适用于目标检测和实例分割等任务
数据集下载
下载车身can数据、车辆位姿数据、地图场景数据、Camera Lidar传感器数据

把map解压后的三个文件放入到mini的maps文件夹中
展示结构如下


将data放入beformer下,然后
<code>python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0-mini --canbus ./data
在其后按照提示和教程缺啥补啥
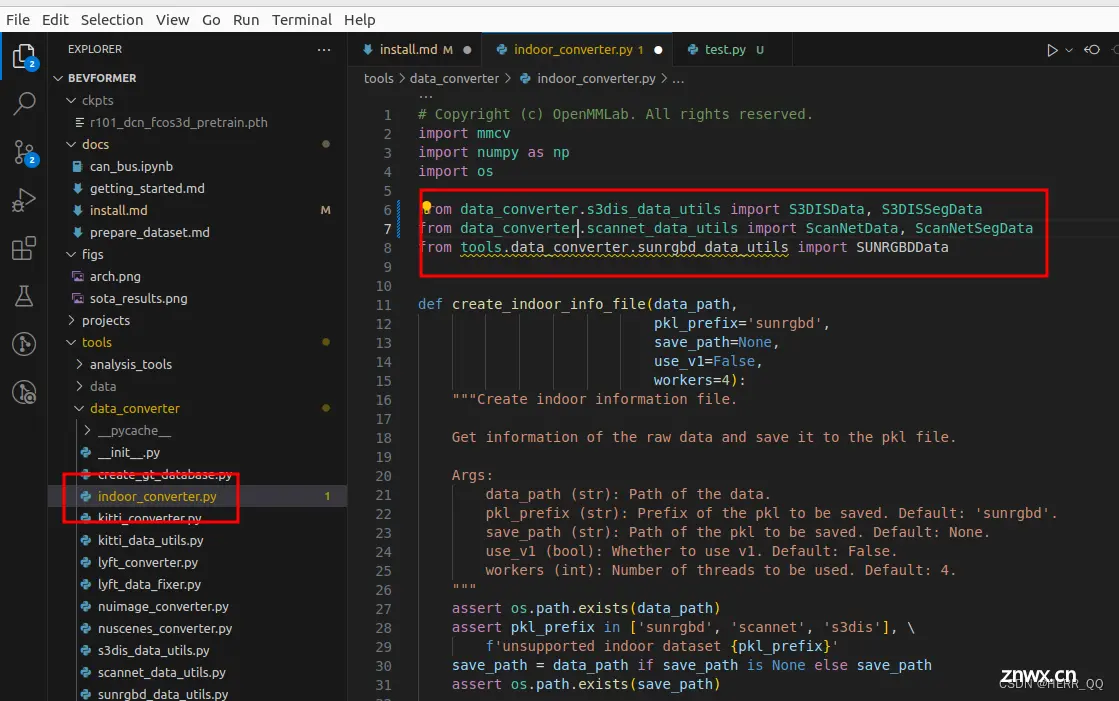
报错就把这里将所有的data.converter 前面的tools去掉
训练 测试 画图
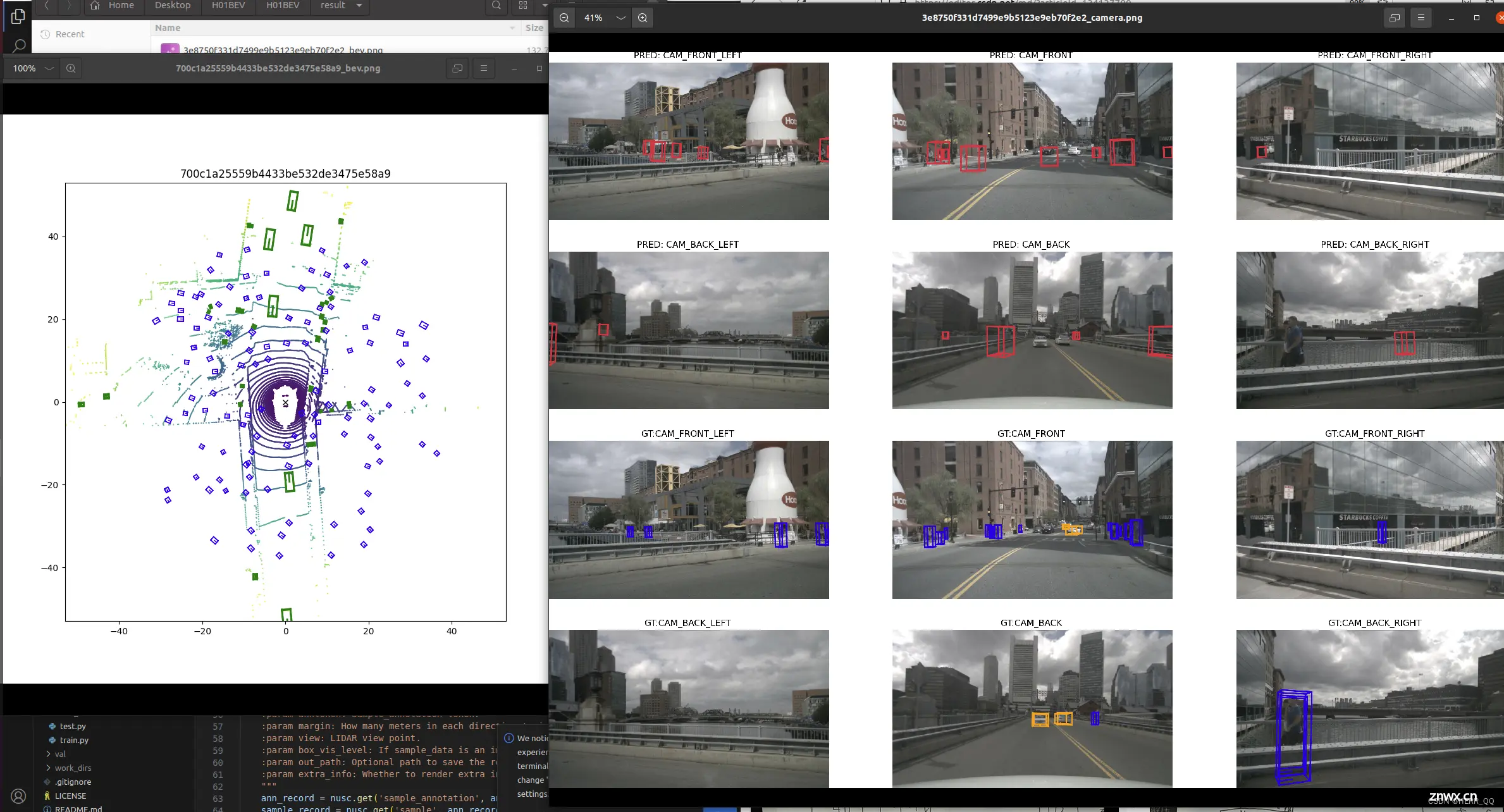
BEV复现教程 结果如下,看起来还不太准确。
环境和数据整理完毕后,按照教程进行,我的显卡可以跑small 和Tiny,把base替换成一位上即可。

第二步开始论文详细阅读和代码解读
第二步论文阅读
论文初步阅读
两个注意力机制为代码和文章重点解读部分



论文细节阅读
代码结构
模型结构使用config管理参数的方式,在bevformer_XXX.py中是参数,具体的模型搭建其实在bevformer_head.py中 组件在modules中可以找到

再次整理细节重点学习 (全代码阅读 TSA SCA MSD,后面两节按照执行顺序总结的代码整理较乱,日后缓慢更新 )
重点是Encoder中的 BEVFormerLayer,有作者提出的Temporalsellfattention SpatialCrossAttention 和可变形注意力
由于代码使用了注册器,不太好直接寻找跳转链路,可以使用断点的方式按照顺序阅读。这里不做顺序阅读,而是将multi_scale_deformable_attn_function.py、spatial_cross_attention.py、temporal_self_attention.py的内容,有价值的每一句做注释解读,贴在下面。拓展语法和概念等则写于本章最后面。
temporal_self_attention.py 的解读
# ---------------------------------------------
# Copyright (c) OpenMMLab. All rights reserved.
# ---------------------------------------------
# Modified by Zhiqi Li
# ---------------------------------------------
from projects.mmdet3d_plugin.models.utils.bricks import run_time
from .multi_scale_deformable_attn_function import MultiScaleDeformableAttnFunction_fp32
from mmcv.ops.multi_scale_deform_attn import multi_scale_deformable_attn_pytorch
import warnings
import torch
import torch.nn as nn
from mmcv.cnn import xavier_init, constant_init
from mmcv.cnn.bricks.registry import ATTENTION
import math
from mmcv.runner.base_module import BaseModule, ModuleList, Sequential
from mmcv.utils import (ConfigDict, build_from_cfg, deprecated_api_warning,
to_2tuple)
from mmcv.utils import ext_loader
ext_module = ext_loader.load_ext(
'_ext', ['ms_deform_attn_backward', 'ms_deform_attn_forward'])
@ATTENTION.register_module()
class TemporalSelfAttention(BaseModule):
"""An attention module used in BEVFormer based on Deformable-Detr.
`Deformable DETR: Deformable Transformers for End-to-End Object Detection.
<https://arxiv.org/pdf/2010.04159.pdf>`_.
Args:
embed_dims (int): The embedding dimension of Attention.
Default: 256.
num_heads (int): Parallel attention heads. Default: 64.
num_levels (int): The number of feature map used in
Attention. Default: 4.
num_points (int): The number of sampling points for
each query in each head. Default: 4.
im2col_step (int): The step used in image_to_column.
Default: 64.
dropout (float): A Dropout layer on `inp_identity`.
Default: 0.1.
batch_first (bool): Key, Query and Value are shape of
(batch, n, embed_dim)
or (n, batch, embed_dim). Default to True.
norm_cfg (dict): Config dict for normalization layer.
Default: None.
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None.
num_bev_queue (int): In this version, we only use one history BEV and one currenct BEV.
the length of BEV queue is 2.
"""
# embed_dims (int): 注意力机制的嵌入维度。
# num_heads (int): 注意力机制中并行的注意头数。
# num_levels (int): 使用的特征图的数量。
# num_points (int): 每个注意头中每个查询点的采样点数。
# im2col_step (int): 在图像到列矩阵转换中使用的步长。
# dropout (float): 应用于 inp_identity 的 Dropout 层的丢弃率。
# batch_first (bool): Key、Query 和 Value 的形状是否为 (batch, n, embed_dim) 或 (n, batch, embed_dim)。
# norm_cfg (dict): 用于规范化层的配置字典。
# init_cfg (obj: mmcv.ConfigDict): 用于初始化的配置对象。
# num_bev_queue (int): 在这个版本中,我们只使用一个历史 Bird's Eye View(BEV)和一个当前 BEV。BEV 队列的长度为 2。
def __init__(self,
embed_dims=256,
num_heads=8,
num_levels=4,
num_points=4,
num_bev_queue=2,
im2col_step=64,
dropout=0.1,
batch_first=True,
norm_cfg=None,
init_cfg=None):
super().__init__(init_cfg)
if embed_dims % num_heads != 0:#检查 embed_dims 特征维度是否可以被 num_heads 多头数量 整除,否则引发错误。
raise ValueError(f'embed_dims must be divisible by num_heads, '
f'but got { embed_dims} and { num_heads}')
dim_per_head = embed_dims // num_heads # 多头注意力量 划分特征
self.norm_cfg = norm_cfg
self.dropout = nn.Dropout(dropout)
self.batch_first = batch_first
self.fp16_enabled = False
# you'd better set dim_per_head to a power of 2
# which is more efficient in the CUDA implementation
def _is_power_of_2(n):
if (not isinstance(n, int)) or (n < 0):
raise ValueError(
'invalid input for _is_power_of_2: {} (type: {})'.format(
n, type(n)))
return (n & (n - 1) == 0) and n != 0
if not _is_power_of_2(dim_per_head):
warnings.warn(
"You'd better set embed_dims in "
'MultiScaleDeformAttention to make '
'the dimension of each attention head a power of 2 '
'which is more efficient in our CUDA implementation.')
self.im2col_step = im2col_step
self.embed_dims = embed_dims
self.num_levels = num_levels
self.num_heads = num_heads
self.num_points = num_points
self.num_bev_queue = num_bev_queue
# 用于生成采样偏移的线性层。
self.sampling_offsets = nn.Linear(
embed_dims*self.num_bev_queue, num_bev_queue*num_heads * num_levels * num_points * 2)
# 用于生成注意力权重的线性层
self.attention_weights = nn.Linear(embed_dims*self.num_bev_queue,
num_bev_queue*num_heads * num_levels * num_points)
#: 用于投影值的线性层。
self.value_proj = nn.Linear(embed_dims, embed_dims)
#用于输出投影的线性层。
self.output_proj = nn.Linear(embed_dims, embed_dims)
self.init_weights()
def init_weights(self):
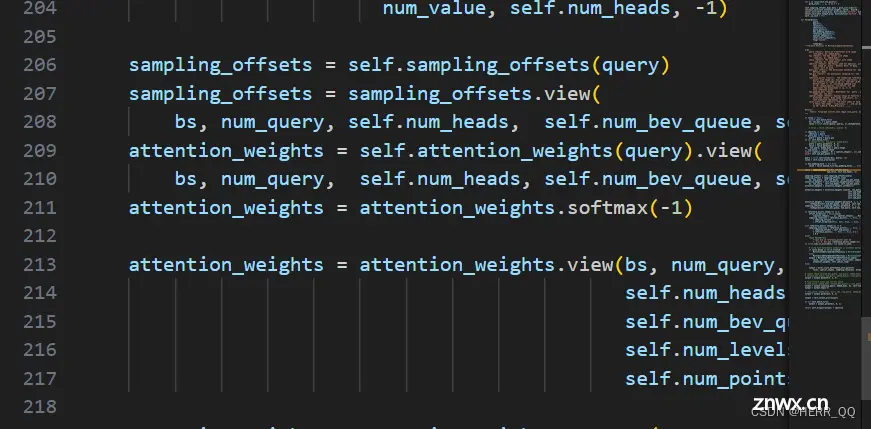
"""Default initialization for Parameters of Module."""
constant_init(self.sampling_offsets, 0.)
thetas = torch.arange(
self.num_heads,
dtype=torch.float32) * (2.0 * math.pi / self.num_heads)
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (grid_init /
grid_init.abs().max(-1, keepdim=True)[0]).view(
self.num_heads, 1, 1,
2).repeat(1, self.num_levels*self.num_bev_queue, self.num_points, 1)
for i in range(self.num_points):
grid_init[:, :, i, :] *= i + 1
self.sampling_offsets.bias.data = grid_init.view(-1)
#用于将参数初始化为常量值。
constant_init(self.attention_weights, val=0., bias=0.)
#用于使用 Xavier 初始化参数
xavier_init(self.value_proj, distribution='uniform', bias=0.)code>
xavier_init(self.output_proj, distribution='uniform', bias=0.)code>
self._is_init = True
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
level_start_index=None,
flag='decoder',code>
**kwargs):
"""Forward Function of MultiScaleDeformAttention.
Args:
query (Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
key (Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
value (Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`.
identity (Tensor): The tensor used for addition, with the
same shape as `query`. Default None. If None,
`query` will be used.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, num_levels, 2),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (Tensor): Spatial shape of features in
different levels. With shape (num_levels, 2),
last dimension represents (h, w).
level_start_index (Tensor): The start index of each level.
A tensor has shape ``(num_levels, )`` and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
"""
# 输入参数:
# query (Tensor): Transformer 的查询张量,形状为 (num_query, bs, embed_dims)。
# key (Tensor): 键张量,形状为 (num_key, bs, embed_dims)。
# value (Tensor): 值张量,形状为 (num_key, bs, embed_dims)。
# identity (Tensor): 用于加法的张量,与 query 形状相同。如果为None,将使用 query。
# query_pos (Tensor): 用于 query 的位置编码。
# key_padding_mask (Tensor): 用于 query 的 ByteTensor,形状为 [bs, num_key]。
# reference_points (Tensor): 归一化的参考点,形状为 (bs, num_query, num_levels, 2),或 (N, Length_{query}, num_levels, 4)。这用于变形注意力。
# spatial_shapes (Tensor): 不同层级中特征的空间形状,形状为 (num_levels, 2),其中最后一个维度表示 (h, w)。
# level_start_index (Tensor): 每个层级的起始索引,形状为 (num_levels,)。
# 输出:
# 返回值: 形状为 [num_query, bs, embed_dims] 的张量,表示前向传播的结果。
# flag: 一个字符串参数,可能用于指定这个操作是在编码器(encoder)还是解码器(decoder)中。
if value is None:
assert self.batch_first
bs, len_bev, c = query.shape # (num_query, bs, embed_dims)
value = torch.stack([query, query], 1).reshape(bs*2, len_bev, c)
#获取 query 张量的形状信息,并利用 torch.stack 和 reshape 函数将其复制为 value 张量
# value = torch.cat([query, query], 0)
if identity is None:
identity = query
if query_pos is not None:
query = query + query_pos
# 将位置编码加入到q中
if not self.batch_first:
# change to (bs, num_query ,embed_dims)
query = query.permute(1, 0, 2)
value = value.permute(1, 0, 2)
#按照惯例整理顺序
bs, num_query, embed_dims = query.shape
_, num_value, _ = value.shape# (num_key, bs, embed_dims)
assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
# (num_levels, 2),其中最后一个维度表示 (h, w) ???没看懂
assert self.num_bev_queue == 2
query = torch.cat([value[:bs], query], -1)
value = self.value_proj(value)
#将 query 连接到 value 的前部分,并对 value 应用 self.value_proj
# 我的理解,由于value是上一时刻和上上bev的信息,如此增加模型在进行自注意力计算时对上下文的理解,而线性变换
#将输入数据映射到一个更高维度的空间,以便提高模型的表示能力
#gpt说如果一个查询需要依赖较远的位置的信息,通过将值信息添加到查询前面,
# 可以使得模型更容易捕捉到这些长距离的依赖关系,提高了模型对整个序列的建模能力。
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0)
#如果存在 key_padding_mask,则使用 masked_fill 将 value 进行填充
value = value.reshape(bs*self.num_bev_queue,
num_value, self.num_heads, -1)
sampling_offsets = self.sampling_offsets(query)
sampling_offsets = sampling_offsets.view(
bs, num_query, self.num_heads, self.num_bev_queue, self.num_levels, self.num_points, 2)
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_bev_queue, self.num_levels * self.num_points)
attention_weights = attention_weights.softmax(-1)
# 利用线性层计算采样offset和权重,并且把权重归一化
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_bev_queue,
self.num_levels,
self.num_points)
attention_weights = attention_weights.permute(0, 3, 1, 2, 4, 5)\
.reshape(bs*self.num_bev_queue, num_query, self.num_heads, self.num_levels, self.num_points).contiguous()
sampling_offsets = sampling_offsets.permute(0, 3, 1, 2, 4, 5, 6)\
.reshape(bs*self.num_bev_queue, num_query, self.num_heads, self.num_levels, self.num_points, 2)
#根据 reference_points 的形状不同(2 或 4),计算 sampling_locations
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :]
#NONE插入维度
#将采样偏移 sampling_offsets 转化为相对于输入空间的实际位置。
elif reference_points.shape[-1] == 4:
sampling_locations = reference_points[:, :, None, :, None, :2] \
+ sampling_offsets / self.num_points \
* reference_points[:, :, None, :, None, 2:] \
* 0.5
else:
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get { reference_points.shape[-1]} instead.')
if torch.cuda.is_available() and value.is_cuda:
# using fp16 deformable attention is unstable because it performs many sum operations
if value.dtype == torch.float16:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
else:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
# output shape (bs*num_bev_queue, num_query, embed_dims)
# (bs*num_bev_queue, num_query, embed_dims)-> (num_query, embed_dims, bs*num_bev_queue)
output = output.permute(1, 2, 0)
# fuse history value and current value
# (num_query, embed_dims, bs*num_bev_queue)-> (num_query, embed_dims, bs, num_bev_queue)
output = output.view(num_query, embed_dims, bs, self.num_bev_queue)
output = output.mean(-1)
#计算 output 张量中每个元素在最后一个维度上的均值
# (num_query, embed_dims, bs)-> (bs, num_query, embed_dims)
output = output.permute(2, 0, 1)
output = self.output_proj(output)
# out再整一次变换
if not self.batch_first:
output = output.permute(1, 0, 2)
return self.dropout(output) + identity
# 加一次dropout防止过拟合,同时引入残差连接或者跳跃连接,从而帮助梯度传播以及加速模型的训练
SCA
# ---------------------------------------------
# Copyright (c) OpenMMLab. All rights reserved.
# ---------------------------------------------
# Modified by Zhiqi Li
# ---------------------------------------------
from mmcv.ops.multi_scale_deform_attn import multi_scale_deformable_attn_pytorch
import warnings
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmcv.cnn import xavier_init, constant_init
from mmcv.cnn.bricks.registry import (ATTENTION,
TRANSFORMER_LAYER,
TRANSFORMER_LAYER_SEQUENCE)
from mmcv.cnn.bricks.transformer import build_attention
import math
from mmcv.runner import force_fp32, auto_fp16
from mmcv.runner.base_module import BaseModule, ModuleList, Sequential
from mmcv.utils import ext_loader
from .multi_scale_deformable_attn_function import MultiScaleDeformableAttnFunction_fp32, \
MultiScaleDeformableAttnFunction_fp16
from projects.mmdet3d_plugin.models.utils.bricks import run_time
ext_module = ext_loader.load_ext(
'_ext', ['ms_deform_attn_backward', 'ms_deform_attn_forward'])
@ATTENTION.register_module()
class SpatialCrossAttention(BaseModule):
"""An attention module used in BEVFormer.
Args:
embed_dims (int): The embedding dimension of Attention.
Default: 256. 是bev线性变换后注意里特征数量
num_cams (int): The number of cameras 摄像头的数量
dropout (float): A Dropout layer on `inp_residual`.
Default: 0.. 为了防止过拟合dropout层参数
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None. 初始化参数
deformable_attention: (dict): The config for the deformable attention used in SCA. SCA的可变性注意力参数
"""
def __init__(self,
embed_dims=256,
num_cams=6,
pc_range=None,
dropout=0.1,
init_cfg=None,
batch_first=False,
deformable_attention=dict(
type='MSDeformableAttention3D',code>
embed_dims=256,
num_levels=4),
**kwargs
):
super(SpatialCrossAttention, self).__init__(init_cfg)
self.init_cfg = init_cfg
self.dropout = nn.Dropout(dropout)
self.pc_range = pc_range
self.fp16_enabled = False
self.deformable_attention = build_attention(deformable_attention)
self.embed_dims = embed_dims
self.num_cams = num_cams
self.output_proj = nn.Linear(embed_dims, embed_dims)
self.batch_first = batch_first
self.init_weight()
def init_weight(self):
"""Default initialization for Parameters of Module."""
xavier_init(self.output_proj, distribution='uniform', bias=0.)code>
#以上初始化和TSA基本一致,没有笔记内容
@force_fp32(apply_to=('query', 'key', 'value', 'query_pos', 'reference_points_cam'))
def forward(self,
query,
key,
value,
residual=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
reference_points_cam=None,
bev_mask=None,
level_start_index=None,
flag='encoder',code>
**kwargs):
"""Forward Function of Detr3DCrossAtten.
Args:
query (Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
#Q
#网上解释num_query类似于 DETR里面的 object_queries,也就是最多预测多少个目标
key (Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
# k
value (Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`. (B, N, C, H, W)
residual (Tensor): The tensor used for addition, with the
same shape as `x`. Default None. If None, `x` will be used.
#残差
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
# q 和 k的位置编码
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, 4),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
# 参考点归一化
数据标准化( Standardization )是将数据转换为均值为0,方差为1的数据,也就是将数据按比例缩放,
使得其分布具有标准正态分布。 数据归一化( Normalization )
是将数据转换为满足0≤x≤1的数据,也就是将数据缩放到 [0,1]区间。
#num_levels:The number of feature map used in
Attention 被用于注意力的特征地图的数量
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
#k 注意力掩码
spatial_shapes (Tensor): Spatial shape of features in
different level. With shape (num_levels, 2),
last dimension represent (h, w).
#空间形状,在不同level的特征的空间形状,最后一个维度2是(h,w)
level_start_index (Tensor): The start index of each level.
A tensor has shape (num_levels) and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
# 开始遍历的index
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
# 返回查询数量 批次 特征数量
"""
if key is None:
key = query
if value is None:
value = key
if residual is None:
inp_residual = query
# 残差链接网络传输值被初始化为query
slots = torch.zeros_like(query)
# 以 query的shape初始化 slot
if query_pos is not None:
query = query + query_pos
# 同样地把线性层学习到的query位置编码和query叠加到一起
bs, num_query, _ = query.size()#(num_query, bs, embed_dims)
#这里是不是错了? 在input地方的备注维度顺序不同?
D = reference_points_cam.size(3)
indexes = []
for i, mask_per_img in enumerate(bev_mask):
index_query_per_img = mask_per_img[0].sum(-1).nonzero().squeeze(-1)
indexes.append(index_query_per_img)
max_len = max([len(each) for each in indexes])
# 每个特征点对应一个mask点,特征点的值为false,就可以将其在注意力中抛弃
# 举例子说明:如果mask_per_img =m torch.tensor([[1, 0, 1, 0],[1, 1, 0, 1]])
# sum_per_img = mask_per_img.sum(-1) 得到tensor[2,3]
# nonzero_indices = sum_per_img.nonzero() 得到tensor [[0],[1]]
# index_query_per_img = nonzero_indices.squeeze(-1)去除上一步操作后多出来的维度
# 得到[0,1]
# 最后用indexes 储存计算好的indices
# each camera only interacts with its corresponding BEV queries. This step can greatly save GPU memory.
queries_rebatch = query.new_zeros(
[bs, self.num_cams, max_len, self.embed_dims])
reference_points_rebatch = reference_points_cam.new_zeros(
[bs, self.num_cams, max_len, D, 2])
for j in range(bs):
for i, reference_points_per_img in enumerate(reference_points_cam):
index_query_per_img = indexes[i]
queries_rebatch[j, i, :len(index_query_per_img)] = query[j, index_query_per_img]
reference_points_rebatch[j, i, :len(index_query_per_img)] = reference_points_per_img[j, index_query_per_img]
#重新计算q和reference point 根据上一步计算的index
num_cams, l, bs, embed_dims = key.shape
key = key.permute(2, 0, 1, 3).reshape(
bs * self.num_cams, l, self.embed_dims)
value = value.permute(2, 0, 1, 3).reshape(
bs * self.num_cams, l, self.embed_dims)
queries = self.deformable_attention(query=queries_rebatch.view(bs*self.num_cams, max_len, self.embed_dims), key=key, value=value,
reference_points=reference_points_rebatch.view(bs*self.num_cams, max_len, D, 2), spatial_shapes=spatial_shapes,
level_start_index=level_start_index).view(bs, self.num_cams, max_len, self.embed_dims)
# 使用可变形注意力
for j in range(bs):
for i, index_query_per_img in enumerate(indexes):
slots[j, index_query_per_img] += queries[j, i, :len(index_query_per_img)]
# 用计算好的 queries和indexed更新slots
count = bev_mask.sum(-1) > 0
# 将bev_mask 按照最后一个维度相加 判断是否大于0 结果储存在count中
count = count.permute(1, 2, 0).sum(-1)
count = torch.clamp(count, min=1.0) # 将count的元素的 最小值设为1
slots = slots / count[..., None]
slots = self.output_proj(slots)
return self.dropout(slots) + inp_residual # [num_query, bs, embed_dims].
@ATTENTION.register_module()
class MSDeformableAttention3D(BaseModule):
"""An attention module used in BEVFormer based on Deformable-Detr.
`Deformable DETR: Deformable Transformers for End-to-End Object Detection.
<https://arxiv.org/pdf/2010.04159.pdf>`_.
Args:
embed_dims (int): The embedding dimension of Attention.
Default: 256.
num_heads (int): Parallel attention heads. Default: 64.
num_levels (int): The number of feature map used in
Attention. Default: 4.
num_points (int): The number of sampling points for
each query in each head. Default: 4.
im2col_step (int): The step used in image_to_column.
Default: 64.
dropout (float): A Dropout layer on `inp_identity`.
Default: 0.1.
batch_first (bool): Key, Query and Value are shape of
(batch, n, embed_dim)
or (n, batch, embed_dim). Default to False.
norm_cfg (dict): Config dict for normalization layer.
Default: None.
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None.
"""
# embed_dims(嵌入维度):注意力机制中的嵌入维度。默认为256,影响了注意力机制中的向量表示维度。
# num_heads(注意力头数):并行的注意力头数。默认为64,控制了注意力机制中多头注意力的并行数量。
# num_levels(特征图数量):注意力中使用的特征图数量。默认为4,影响了注意力机制中特征图的层级数。
# num_points(采样点数):每个注意力头中每个查询点的采样点数。默认为4,决定了每个头部的注意力机制对查询点进行采样的数量。
# im2col_step(image_to_column 步长):在 image_to_column 操作中使用的步长。
# dropout(丢弃率):应用于 inp_identity 的 Dropout 层的丢弃率。默认为0.1,用于在训练中随机丢弃输入张量中的一部分元素,以防止过拟合。
# batch_first(批次优先):用于指定输入张量的维度顺序。如果为 True,表示输入张量的形状是(batch, n, embed_dim),否则为 (n, batch, embed_dim)。默认为 False。
# norm_cfg(归一化层配置):用于归一化层的配置字典。默认为 None,
# init_cfg(初始化配置):初始化配置的配置对象。
def __init__(self,
embed_dims=256,
num_heads=8,
num_levels=4,
num_points=8,
im2col_step=64,
dropout=0.1,
batch_first=True,
norm_cfg=None,
init_cfg=None):
super().__init__(init_cfg)
if embed_dims % num_heads != 0:
raise ValueError(f'embed_dims must be divisible by num_heads, '
f'but got { embed_dims} and { num_heads}')
dim_per_head = embed_dims // num_heads # 每一个头的特征数量
self.norm_cfg = norm_cfg
self.batch_first = batch_first
self.output_proj = None
self.fp16_enabled = False
# you'd better set dim_per_head to a power of 2
# which is more efficient in the CUDA implementation
def _is_power_of_2(n):
if (not isinstance(n, int)) or (n < 0):
raise ValueError(
'invalid input for _is_power_of_2: {} (type: {})'.format(
n, type(n)))
return (n & (n - 1) == 0) and n != 0
if not _is_power_of_2(dim_per_head):
warnings.warn(
"You'd better set embed_dims in "
'MultiScaleDeformAttention to make '
'the dimension of each attention head a power of 2 '
'which is more efficient in our CUDA implementation.')
self.im2col_step = im2col_step
self.embed_dims = embed_dims
self.num_levels = num_levels
self.num_heads = num_heads
self.num_points = num_points
self.sampling_offsets = nn.Linear(
embed_dims, num_heads * num_levels * num_points * 2)
self.attention_weights = nn.Linear(embed_dims,
num_heads * num_levels * num_points)
self.value_proj = nn.Linear(embed_dims, embed_dims)
# 同 TSA的注意力
self.init_weights()
def init_weights(self):
"""Default initialization for Parameters of Module."""
constant_init(self.sampling_offsets, 0.)
#极坐标网格构建
# 创建一个0到2pi 等分为8分的tensor
thetas = torch.arange(
self.num_heads,
dtype=torch.float32) * (2.0 * math.pi / self.num_heads)
# 初始化grid
#利用三角函数计算每个角度对应的余弦和正弦值,然后通过torch.stack在最后一个维度
#将这两个值堆叠在一起形成一个形状为(num_heads, 2)的张量。
# 这个张量的每一行表示一个角度对应的极坐标中的(x, y)坐标,
# 使用grid_init.abs().max(-1, keepdim=True)[0]计算每个行向量的绝对值中的最大值,
# 并在最后一个维度上保持维度。然后,将grid_init除以这个最大值,实现归一化。
# 最后,通过view函数将结果变形成形状为(num_heads, 1, 1, 2)的张量
#最终的输出是一个形状为(num_heads, 1, 1, 2)的张量,
# 表示了num_heads个头部的极坐标网格。每个头部的网格用一个(x, y)坐标表示,
# 这个坐标在单位圆上,且在整个num_heads中均匀分布
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (grid_init /
grid_init.abs().max(-1, keepdim=True)[0]).view(
self.num_heads, 1, 1,
2).repeat(1, self.num_levels, self.num_points, 1)
## 遍历第二个维度上,通过这种方式记录是第几个采样点的极坐标
for i in range(self.num_points):
grid_init[:, :, i, :] *= i + 1
#grid_init.view(-1) 将 grid_init 张量展平为一个一维张量
self.sampling_offsets.bias.data = grid_init.view(-1)
constant_init(self.attention_weights, val=0., bias=0.)
xavier_init(self.value_proj, distribution='uniform', bias=0.)code>
xavier_init(self.output_proj, distribution='uniform', bias=0.)code>
self._is_init = True
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
level_start_index=None,
**kwargs):
"""Forward Function of MultiScaleDeformAttention.
Args:
query (Tensor): Query of Transformer with shape
( bs, num_query, embed_dims).
key (Tensor): The key tensor with shape
`(bs, num_key, embed_dims)`.
value (Tensor): The value tensor with shape
`(bs, num_key, embed_dims)`.
identity (Tensor): The tensor used for addition, with the
same shape as `query`. Default None. If None,
`query` will be used.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, num_levels, 2),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (Tensor): Spatial shape of features in
different levels. With shape (num_levels, 2),
last dimension represents (h, w).
level_start_index (Tensor): The start index of each level.
A tensor has shape ``(num_levels, )`` and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
"""
if value is None:
value = query
if identity is None:
identity = query
if query_pos is not None:
query = query + query_pos
if not self.batch_first:
# change to (bs, num_query ,embed_dims)
query = query.permute(1, 0, 2)
value = value.permute(1, 0, 2)
bs, num_query, _ = query.shape
bs, num_value, _ = value.shape
assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
value = self.value_proj(value)
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0)
value = value.view(bs, num_value, self.num_heads, -1)
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points)
attention_weights = attention_weights.softmax(-1)
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_levels,
self.num_points)
if reference_points.shape[-1] == 2:
"""
For each BEV query, it owns `num_Z_anchors` in 3D space that having different heights.
After proejcting, each BEV query has `num_Z_anchors` reference points in each 2D image.
For each referent point, we sample `num_points` sampling points.
For `num_Z_anchors` reference points, it has overall `num_points * num_Z_anchors` sampling points.
"""
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
bs, num_query, num_Z_anchors, xy = reference_points.shape
reference_points = reference_points[:, :, None, None, None, :, :]
sampling_offsets = sampling_offsets / \
offset_normalizer[None, None, None, :, None, :]
bs, num_query, num_heads, num_levels, num_all_points, xy = sampling_offsets.shape
sampling_offsets = sampling_offsets.view(
bs, num_query, num_heads, num_levels, num_all_points // num_Z_anchors, num_Z_anchors, xy)
sampling_locations = reference_points + sampling_offsets
bs, num_query, num_heads, num_levels, num_points, num_Z_anchors, xy = sampling_locations.shape
assert num_all_points == num_points * num_Z_anchors
sampling_locations = sampling_locations.view(
bs, num_query, num_heads, num_levels, num_all_points, xy)
elif reference_points.shape[-1] == 4:
assert False
else:
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get { reference_points.shape[-1]} instead.')
# sampling_locations.shape: bs, num_query, num_heads, num_levels, num_all_points, 2
# attention_weights.shape: bs, num_query, num_heads, num_levels, num_all_points
#准备步骤基本可TSA相同
if torch.cuda.is_available() and value.is_cuda:
if value.dtype == torch.float16:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
else:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
if not self.batch_first:
output = output.permute(1, 0, 2)
return output
拓展
关于embedding
embedding层的作用
我的理解,在之前NLP的学习中,一个词语放入到语义中可以使用一个多维度的向量在超空间里分解他的含义,然后这个向量(坐标亦或位置),表现出来这个字和不同维度轴的相关程度,从而说明了这个词语的含义。
gpt解释:
Embedding 层在深度学习中主要用于将高维的离散数据映射到低维的连续空间
Embedding 层将输入的离散数据,比如单词、类别标签等,映射到一个固定维度的实数向量。这使得模型能够更好地理解和处理这些数据,因为连续向量包含了更多的信息
Embedding 层会根据模型的训练数据学习出适合任务的特征表示。这意味着相似的类别或单词在嵌入空间中会有相似的表示,这有助于提高模型的泛化能力
Embedding 层可以将高维的离散数据映射到低维的连续空间。这有助于减少模型的参数数量,提高训练和推理效率
与独热编码等稀疏表示相比,Embedding 层提供了密集的表示,其中每个维度都包含信息。这可以减少存储需求,并更有效地传达模型学到的知识
其中:
• 连续的向量: 意味着向量的每个元素都可以是任意实数,而不仅仅是整数。在嵌入层中,这通常是为了获得更灵活、更具表达力的表示。
• 低维向量: 意味着向量的维度相对较低。在嵌入的上下文中,这有助于减少模型参数的数量,同时保留重要的特征。低维度的表示通常更容易被模型学习和泛化。
gpt举例:
一个emmeding的简单使用
import torch
import torch.nn as nn
# 假设我们有一个词汇表的大小为10,每个词的嵌入维度为3
vocab_size = 10
embedding_dim = 3
# 创建一个 Embedding 层
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 定义一个输入,包含三个词的索引
input_indices = torch.tensor([1, 5, 9], dtype=torch.long)
# 将输入传递给嵌入层,得到嵌入向量
embedded_vector = embedding_layer(input_indices)
# 输出嵌入向量
print(embedded_vector)
tensor([[-2.8465, 0.1365, -0.4851],
[ 0.4402, -0.3163, -0.8770],
[-0.4027, -0.1626, 0.3808]], grad_fn=<EmbeddingBackward0>)
“每个词的嵌入维度为3” 意味着在嵌入层中为每个词分配的嵌入向量的维度是3。嵌入向量是一个实数向量,用于表示模型学习到的词汇表中每个词的语义信息。
在这个特定的例子中,每个词都被映射到一个包含3个实数值的向量。这三个值构成了嵌入向量的三个维度。这种表示是通过训练神经网络从数据中学习得到的,网络通过反向传播算法来调整嵌入向量的权重,以最好地适应训练数据。
通常,嵌入维度的选择是一个超参数,可以根据具体任务和数据的性质进行调整。较大的嵌入维度可以提供更丰富的语义信息,但也需要更多的计算资源。一般而言,在实际应用中,嵌入维度的选择可能会在试验和验证中进行调整,以找到适合特定任务的最佳值。
关于xavier
对于网络的每一层初始化权重时,使得输入和输出的方差相等。这有助于避免在网络的前向传播和反向传播中引入梯度爆炸或梯度消失的问题。
权重初始化解释集合
摘读如下
Xavier初始化,也称为Glorot初始化,是一种常用的参数初始化方法,旨在有效地初始化神经网络中的权重。它的设计思想是根据前一层和后一层的神经元数量来设置权重的初始值,以保持信号在前向传播过程中的适当范围;其核心思想是,保持输入信号和梯度的方差在不同层之间大致相等,避免在深层网络中产生梯度消失或梯度爆炸的问题。这种初始化方法有助于提供合适的梯度范围,促进网络的稳定训练和收敛。。具体而言,对于具有线性激活函数(如sigmoid和tanh)的网络层,Xavier初始化将权重初始化为均匀分布或高斯分布,其方差取决于前一层神经元数量n和后一层神经元数量m。
对于均匀分布的Xavier初始化(均匀版):
从均匀分布中随机初始化权重矩阵W,范围为[-a, a],其中a = sqrt(6 / (n + m))。
对于高斯分布的Xavier初始化(高斯版):
从高斯分布中随机初始化权重矩阵W,均值为0,方差为variance,其中variance = 2 / (n + m)。 核心设计思想解释
当我们训练深度神经网络时,梯度的传播是非常关键的。如果梯度在每一层传播时逐渐消失,即梯度接近于零,那么底层的参数将很难更新,导致网络难以学习有效的表示。相反,如果梯度在每一层传播时逐渐增大,即梯度爆炸,那么参数更新的幅度会非常大,导致训练不稳定甚至无法收敛。因此,要保持输入信号和梯度的方差在不同层之间大致相等,以确保在前向传播和反向传播过程中,信号和梯度能够保持合适的范围,从而促进网络的稳定训练和收敛。
如何保证输入信号和梯度的方差在不同层之间大致相等呢?在Xavier初始化中,存在递归的思想,其计算方式是递归的,即权重的初始范围是根据前一层和后一层的神经元数量进行计算的。
好的,让我们来看一个具有5层的神经网络的例子,以解释Xavier初始化是如何工作的。假设我们有一个具有以下结构的神经网络:输入层(100个神经元)
隐藏层1(80个神经元) - 隐藏层2(60个神经元) - 隐藏层3(40个神经元) - 输出层(10个神经元)。现在,我们将使用Xavier初始化来初始化每一层的权重。
对于隐藏层1,我们需要计算它的权重初始范围。根据Xavier初始化的公式,我们需要知道前一层和后一层的神经元数量。在这种情况下,前一层是输入层,有100个神经元,后一层是隐藏层1本身,有80个神经元。根据公式,我们可以计算权重初始范围a:a
= sqrt(6 / (100 + 80)) ≈ 0.136。现在,我们可以从均匀分布[-0.136, 0.136]中随机初始化隐藏层1的权重矩阵。
接下来,我们继续计算隐藏层2的权重初始范围。前一层是隐藏层1,有80个神经元,后一层是隐藏层2本身,有60个神经元。我们使用相同的公式来计算权重初始范围a:a
= sqrt(6 / (80 + 60)) ≈ 0.153。然后,我们从均匀分布[-0.153, 0.153]中随机初始化隐藏层2的权重矩阵。
类似地,我们可以计算隐藏层3和输出层的权重初始范围,并进行相应的初始化。
通过这样的递归计算和初始化过程,Xavier初始化确保了每一层的权重都与前一层和后一层的神经元数量相关联。这有助于平衡信号和梯度的传播,避免梯度消失或梯度爆炸问题,从而提高神经网络的训练稳定性和收敛性能。
关于stack 和 reshape和permute和cat和view和NONE的用法
tmp_prev_bev = prev_bev[:, i].reshape(
bev_h, bev_w, -1).permute(2, 0, 1)
有我不熟悉的语法 gpt查询如下:
A:
prev_bev[:, i]:表示选择 prev_bev 张量中的所有行 (😃 和第 i 列。这样得到的是形状为 (bev_h * bev_w, embed_dims) 的二维张量,其中 embed_dims 表示每个位置的嵌入维度。
.reshape(bev_h, bev_w, -1):通过 reshape 操作将上述选择的二维张量重新塑造为三维张量,形状为 (bev_h, bev_w, -1)。这里的 -1 表示根据其他维度的大小自动计算。这一步的目的是将先前的BEV重新排列成3D形状,其中 bev_h 和 bev_w 分别是BEV的高度和宽度。
.permute(2, 0, 1):通过 permute 操作将三维张量的轴重新排列,得到 (embed_dims, bev_h, bev_w) 的形状。这一步的目的是将第三个维度(原先的嵌入维度)移动到第一个维度,以适应后续的旋转操作。
Q:torch.stack([query, query], 1).reshape(bs*2, len_bev, c) 这个操作会做什么 举一个例子说明
A:
假设 query 的形状为 (num_query, bs, embed_dims),则 torch.stack([query, query], 1) 的结果将会是一个形状为 (num_query, 2, bs, embed_dims) 的四维张量。这是因为 torch.stack 在指定的维度上创建一个新的维度,将两个 query 张量叠加在一起。
接下来,reshape(bs2, len_bev, c) 将该四维张量重新塑造为一个三维张量,其中第一维的大小是 bs2,第二维的大小是 len_bev,第三维的大小是 c。这样做的结果是,原本在第二维上叠加的两个 query 张量现在在第一维上连接在一起,形成了一个新的张量。
举例来说,如果 query 的形状为 (3, 4, 5),那么经过这个操作后,value 的形状将变为 (6, 4, 5)。在这个例子中,原本有3个 query 张量,经过操作后在第一维上连接成了6个。这种操作有时候可以用于复制张量,使其在某个维度上重复出现
Q:query = torch.cat([value[:bs], query], -1) 这一句话语法怎么解释 用一个实际例子说明
A:
这行代码使用 torch.cat 函数将 value 张量的前 bs 个元素(沿着第一个维度)与 query 张量连接在一起,连接的维度是最后一个维度(-1 表示最后一个维度)。
具体来说,如果 value 的形状是 (2*bs, len_bev, c),而 query 的形状是 (bs, num_query, embed_dims),则经过这行代码后,query 的形状将变为 (bs, num_query, embed_dims + c)。
这样的操作可以用一个实际例子来说明。假设 bs=2,len_bev=3,c=4,num_query=5,embed_dims=6,那么:
value 张量的形状为 (4, 3, 4),其中 4 表示 2*bs。
query 张量的形状为 (2, 5, 6)。
通过 torch.cat([value[:bs], query], -1) 操作:
value[:bs] 选择了 value 张量的前两个部分,形状为 (2, 3, 4)。
将选中的 value[:bs] 与 query 张量连接在一起,连接的维度是最后一个维度,即 embed_dims 的维度。
最终得到的 query 张量的形状为 (2, 5, 10),其中 10 是 6 (embed_dims) + 4 ©。
Q:view 强行该百年数据形状出错了怎么办,总数丢失
A;
如果使用 view 操作改变张量的形状,确实可能导致数据丢失。在上面的例子中,如果不能整除原始张量的总元素数目和新形状中的总元素数目,那么会引发一个错误,因为 view 操作要求总元素数目保持不变。
在实际应用中,为了避免数据丢失,通常会在进行形状变换之前检查总元素数目是否一致。可以使用 numel() 方法来获取张量的元素总数,然后进行比较。
Q:NONE 代表啥
A:
[:, :, None, :, None, :]: 在第二个维度和第四个维度之间插入一个新的维度,以及在第四个维度和第六个维度之间插入一个新的维度。
Q:output = output.mean(-1)
A:
举例说明,假设 output 的形状是 (100, 64, 32, 8),那么 output.mean(-1) 的结果将是一个形状为 (100, 64, 32) 的张量,其中每个元素是原始张量中相应位置上的最后一个维度的均值。
这种操作通常用于降维或者对数据进行汇聚,计算每个子序列或者向量在某个方向上的平均值
python
import torch
# 假设 output 是一个形状为 (100, 64, 32, 8) 的张量
output = torch.randn(100, 64, 32, 8)
# 新形状
new_shape = (5, 16, 4, 8)
# 检查元素总数是否一致
if output.numel() == torch.tensor(new_shape).prod():
output_reshaped = output.view(*new_shape)
# 继续处理
else:
print("无法使用 view 操作进行形状变换,因为元素总数不一致。")
在实际的深度学习应用中,有时候可能会使用一些灵活的方法,比如使用 -1 作为 view 操作中的一个维度,让 PyTorch 自动计算该维度的大小,以保证总元素数目一致。不过,这样的操作需要谨慎使用,确保不会引入不必要的错误。
Bilibili视频学习笔记 :BEVFormerHead Forward 函数开始
forward(self, mlvl_feats, img_metas, prev_bev=None, only_bev=False)
输入和输出:
Args:
mlvl_feats (tuple[Tensor]):上游网络的特征,是主要的输入一个6张图的Features Map,是一个具有形状(B, N, C, H, W)的张量元组,其中B是批大小,N是摄像头数量,C是通道数量,H和W是高度和宽度。
prev_bev: 先前的鸟瞰图(BEV)特征。 only_bev: 一个布尔值,指示是否仅使用编码器计算 BEV 特征。
Returns:
all_cls_scores (Tensor): 分类头的输出,形状为 [nb_dec, bs, num_query, cls_out_channels]。 注意,cls_out_channels 包括背景。
all_bbox_preds (Tensor): 回归头的 Sigmoid 输出,使用归一化坐标格式 (cx, cy, w, l, cz, h, theta, vx, vy)。 形状为 [nb_dec, bs, num_query, 9]。
初始化:
bs, num_cam, _, _, _ = mlvl_feats[0].shape
dtype = mlvl_feats[0].dtype
从mlvl_feats中提取一些属性,如批大小(bs)和摄像头数量(num_cam)。 根据mlvl_feats中的第一个元素的类型初始化数据类型(dtype)。 获取查询和BEV嵌入。
BEV掩码和位置编码:
object_query_embeds = self.query_embedding.weight.to(dtype)
bev_queries = self.bev_embedding.weight.to(dtype)
bev_mask = torch.zeros((bs, self.bev_h, self.bev_w),
device=bev_queries.device).to(dtype)
bev_pos = self.positional_encoding(bev_mask).to(dtype)
创建BEV掩码并计算BEV特征的位置编码。关于embedding可以查看第init中的解释
positional_encoding的内容可以见Transformer的学习笔记,我的理解。把位置做一个编码,位置的关系也可以作为一个“特征”,去学习空间结构位置的关系对结果造成的贡献。
positional_encoding的位置
positional_encoding-》build_positional_encoding-》POSITIONAL_ENCODING-》LearnedPositionalEncoding
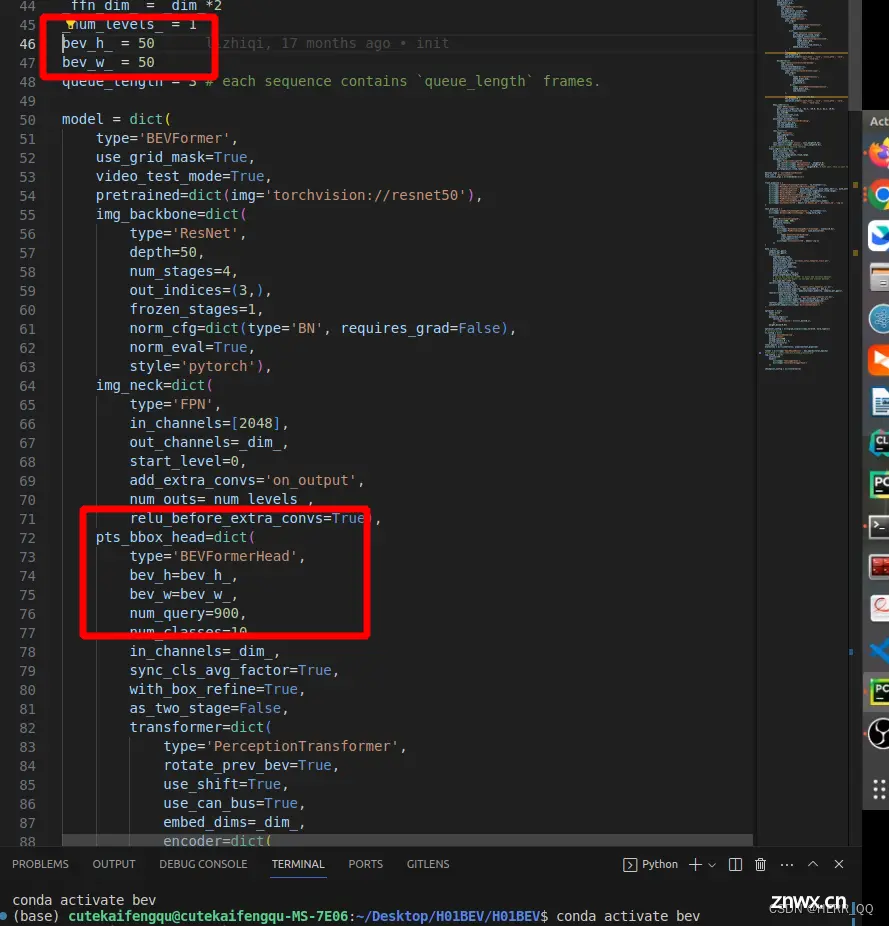
init 的参数可以在config文件:BEVformer_tiny中找到.
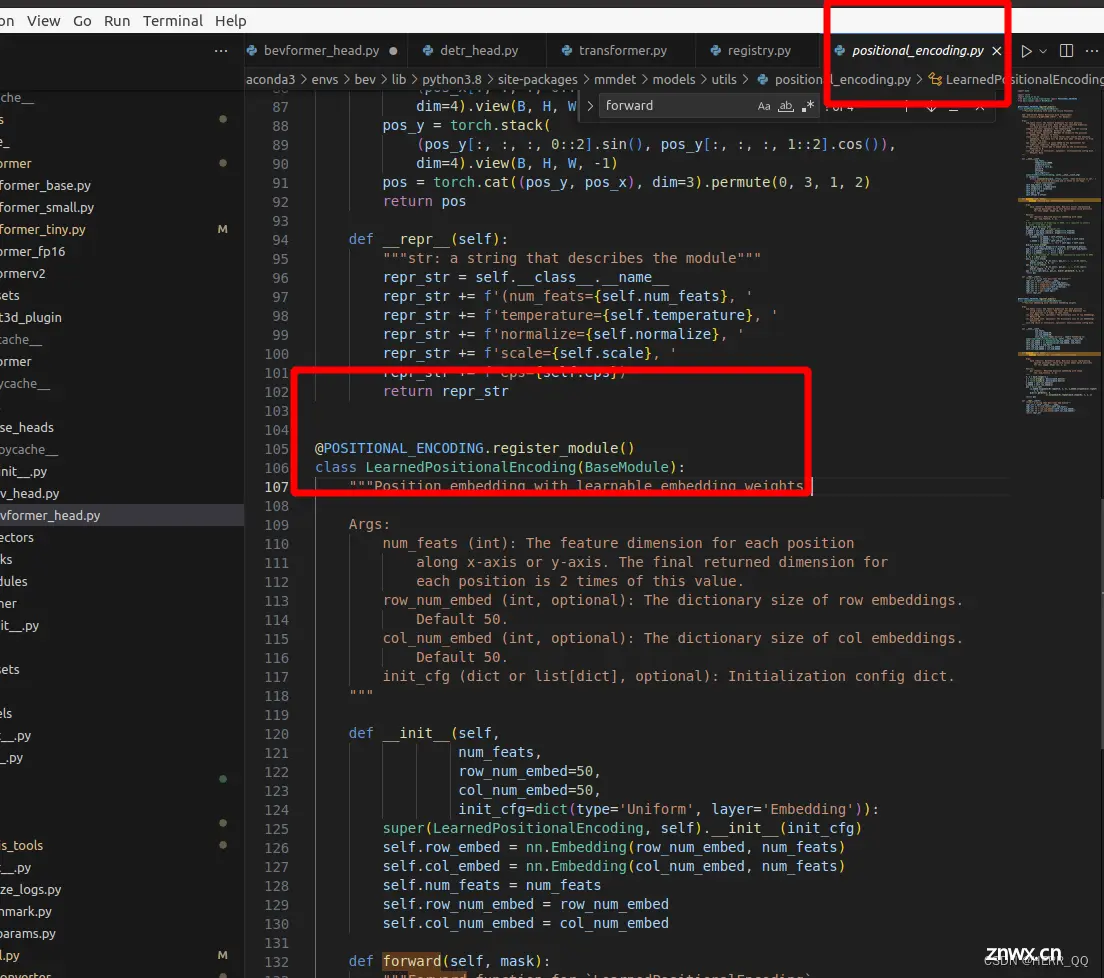
对LearnedPositionalEncoding的解读:
LearnedPositionalEncoding 类继承自 BaseModule,并接受一些参数,包括:
num_feats:每个位置在 x 轴或 y 轴上的特征维度,最终每个位置的返回维度是这个值的两倍。
row_num_embed:行嵌入的字典大小,默认为 50。
col_num_embed:列嵌入的字典大小,默认为 50。
init_cfg:初始化配置字典,用于初始化权重。
在初始化函数中,创建了两个嵌入层 self.row_embed 和 self.col_embed,分别用于行和列的嵌入。这两个嵌入层的输入是对应的嵌入字典大小,输出维度为 num_feats。此外,还存储了一些参数,如 num_feats,row_num_embed,col_num_embed。
forward 方法接受一个二进制掩码 mask,其中非零值表示被忽略的位置,而零值表示图像的有效位置。在前向传播中,首先通过 torch.arange 创建了 x 和 y 的坐标,然后通过行和列的嵌入层得到相应的嵌入向量。最后,将这些嵌入向量按照指定的方式拼接并重复,形成最终的位置编码张量 pos。pos 的形状是 [bs, num_feats2, h, w],其中 bs 是批大小,num_feats2 是每个位置的最终维度,h 和 w 是图像的高度和宽度。
epr方法用于返回一个描述模块的字符串,其中包含模块的参数信息。
条件执行:
<code>if only_bev:
如果only_bev为真,则返回使用self.transformer.get_bev_features()从编码器获取的BEV特征。 否则,执行完整的前向传播。 (这里up解释,结构需要上一帧数的信息,我回头再看一下)
同时这里也将准备信息输入transformer模型,然后获得raw output。 Transformer 展开见组件学习中
完整的前向传播:
使用各种参数调用self.transformer,包括mlvl_feats、查询和BEV嵌入以及图像元数据。结果存储在变量outputs中。
处理输出:
从outputs中提取相关信息,包括bev_embed、hs、init_reference和inter_references。 对hs进行排列,以改变维度的顺序。 对不同级别(lvl)的特征进行迭代,并在每个级别上执行计算。
坐标变换:
通过添加和对特定元素应用sigmoid来转换回归输出(tmp)。这涉及到对坐标进行操作并在特定元素上应用sigmoid。
堆叠输出:
堆叠在不同级别获得的输出类别和坐标。
输出字典:
创建一个输出字典(outs),包含鸟瞰图嵌入(bev_embed)、所有类别分数(outputs_classes)、所有边界框预测(outputs_coords)
组件学习(详细展开上一节中的组件学习)
if not self.as_two_stage:
self.bev_embedding = nn.Embedding(
self.bev_h * self.bev_w, self.embed_dims)
self.query_embedding = nn.Embedding(self.num_query,
self.embed_dims * 2)
embedding
self.bev_embedding 是一个用于嵌入鸟瞰图(BEV)特征的嵌入层。nn.Embedding 是一个常用于处理离散型输入的层,它将输入的整数索引映射到相应的嵌入向量。在这里,self.bev_embedding 的输入是鸟瞰图的高度和宽度的乘积(self.bev_h * self.bev_w),输出是一个嵌入维度为 self.embed_dims 的嵌入向量。这个嵌入向量可以捕捉到输入鸟瞰图的空间信息。
self.query_embedding 是用于嵌入查询(query)的嵌入层。这里的输入是查询的数量(self.num_query),输出是一个嵌入维度为 self.embed_dims * 2 的嵌入向量。
简单的说作用是确定位置用。
我们使用的tiny是50*50
拓展
我的理解,在之前NLP的学习中,一个词语放入到语义中可以使用一个多维度的向量在超空间里分解他的含义,然后这个向量(坐标亦或位置),表现出来这个字和不同维度轴的相关程度,从而说明了这个词语的含义。
gpt举例:
一个emmeding的简单使用
<code>import torch
import torch.nn as nn
# 假设我们有一个词汇表的大小为10,每个词的嵌入维度为3
vocab_size = 10
embedding_dim = 3
# 创建一个 Embedding 层
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 定义一个输入,包含三个词的索引
input_indices = torch.tensor([1, 5, 9], dtype=torch.long)
# 将输入传递给嵌入层,得到嵌入向量
embedded_vector = embedding_layer(input_indices)
# 输出嵌入向量
print(embedded_vector)
tensor([[-2.8465, 0.1365, -0.4851],
[ 0.4402, -0.3163, -0.8770],
[-0.4027, -0.1626, 0.3808]], grad_fn=<EmbeddingBackward0>)
“每个词的嵌入维度为3” 意味着在嵌入层中为每个词分配的嵌入向量的维度是3。嵌入向量是一个实数向量,用于表示模型学习到的词汇表中每个词的语义信息。
在这个特定的例子中,每个词都被映射到一个包含3个实数值的向量。这三个值构成了嵌入向量的三个维度。这种表示是通过训练神经网络从数据中学习得到的,网络通过反向传播算法来调整嵌入向量的权重,以最好地适应训练数据。
通常,嵌入维度的选择是一个超参数,可以根据具体任务和数据的性质进行调整。较大的嵌入维度可以提供更丰富的语义信息,但也需要更多的计算资源。一般而言,在实际应用中,嵌入维度的选择可能会在试验和验证中进行调整,以找到适合特定任务的最佳值
PerceptionTransformer (重点!)
从重中之重 Encoder入手 在modules的 transformer中

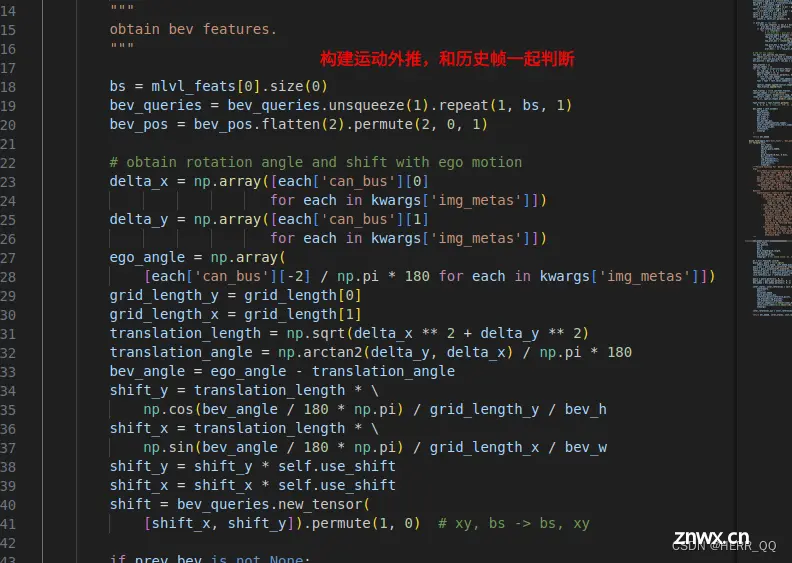
运动学对齐信息
输入和之前基本解释了,grid_length=[0.512, 0.512],代表每一个格子的现实长度,用于在格子中作现实世界和虚拟格子的变换

计算上一帧和本帧位置的偏移量,做一个时空对齐:
获取自我运动信息:
delta_x 和 delta_y 分别表示每个样本中车辆自我运动的x和y方向的变化。
ego_angle 表示车辆自我运动的角度计算平移量和旋转角度:
translation_length 表示车辆自我运动的平移量的长度,通过计算x和y方向的平方和的平方根得到。
translation_angle 表示车辆自我运动的平移方向的角度,通过使用反正切函数计算。
bev_angle 表示BEV中的旋转角度,由车辆自我运动的角度减去平移方向的角度得到。
shift_y 和 shift_x 表示BEV中的平移量,通过使用平移长度和旋转角度计算。应用平移操作:
shift_y 和 shift_x 分别乘以 self.use_shift,这是一个控制平移幅度的标志。
shift 是一个 PyTorch 张量,表示BEV中的平移,形状为 (bs, 2)。旋转先前的BEV:
如果存在 prev_bev,则检查其形状是否为 (bs, bev_h * bev_w, embed_dims),如果不是,则进行维度调整。如果设置了 self.rotate_prev_bev 为 True,则对每个样本中的先前BEV执行旋转操作。
通过获取每个样本的旋转角度,并使用 rotate 函数,对先前BEV进行旋转操作。
最终将旋转后的BEV重新调整为适应模型的形状。
can信息处理
其中can_bus_mlp 可以跳转定义看到 把18维度的can信息映射了新的维度,视频up解说为把can信息也隐式的加入道路学习feature中
encoder学习 (在Perception TF中被调用,构建在encoder.py中)
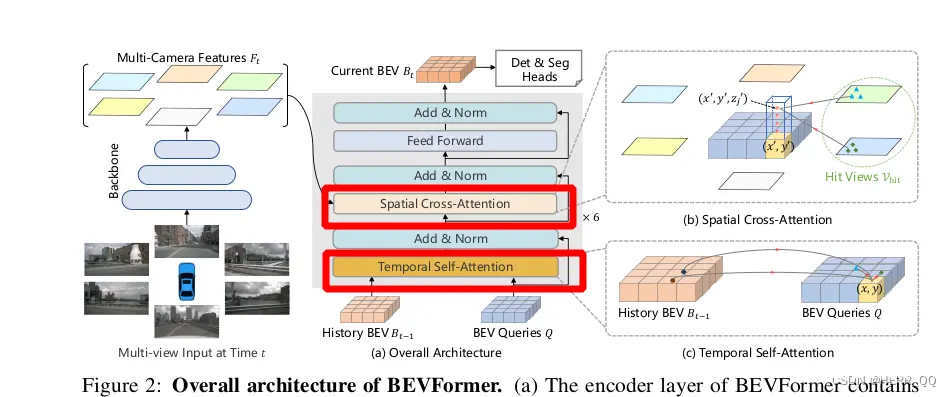
以上就是6组backbone的循环对应下图 TSA SCA FFN,可以对照论文解读开始研究了。

TSA解读
找参考点

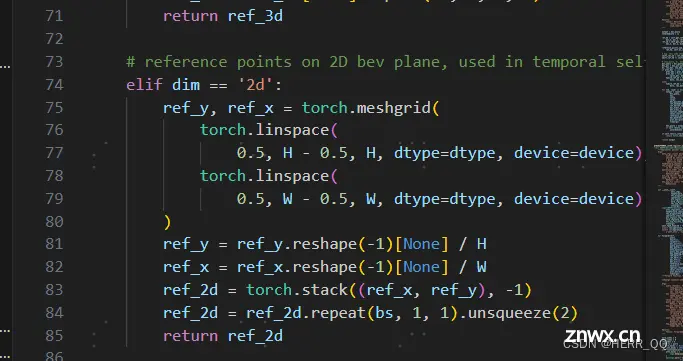
torch.linspace(0.5, H - 0.5, H)生成从 0.5 到 H - 0.5 的等间隔序列,后者同理。
torch.meshgrid 生成了两个张量 ref_y 和 ref_x,它们分别代表垂直和水平方向的坐标。假设 H 表示高度,W 表示宽度,那么 ref_y 的形状是 (H, W),ref_x 的形状也是 (H, W)。
ref_y = ref_y.reshape(-1)[None] / H:
ref_y.reshape(-1) 将 ref_y 展平为一维张量,形状变为 (H * W)。因为 ref_y 开始是一个二维 (H, W) 的网格,展平后总共有 H * W 个元素。
[None] 在 PyTorch 中是用来增加一个维度的,这里增加了一个维度,将一维张量变成了二维,形状为 (1, H * W)。
最后,对这个二维张量中的每个元素都除以 H,对每个坐标点进行了标准化。因此,最终 ref_y 的形状是 (1, H * W)。
ref_2d = torch.stack((ref_x, ref_y), -1) 因为 ref_x 和 ref_y 都是形状为 (1, HW) 的二维张量,沿着最后一个维度堆叠相当于将它们合并成一个形状为 (1, HW, 2) 的三维张量
ref_2d.repeat(bs, 1, 1)
repeat 函数用于沿着指定的维度重复张量。在这里,bs 表示重复的次数,1 和 1 表示在其余两个维度上不进行重复。这将导致 ref_2d 在第一个维度上被重复 bs 次
unsqueeze(2) 操作在第三个维度上增加一个维度。在这里,它将 ref_2d 的形状从 (bs, HW, 2) 变成了 (bs, HW, 1, 2)
整个操作的目的是将原始的 ref_2d 张量在批处理维度上进行复制,并在最后增加一个额外的维度
扩展
关于stack,ref_2d = torch.stack((ref_x, ref_y), -1)
<code>ref_x = torch.tensor([[0.1, 0.2, 0.3, 0.4, 0.5, 0.6]])
ref_y = torch.tensor([[0.6, 0.5, 0.4, 0.3, 0.2, 0.1]])
ref_2d = torch.stack((ref_x, ref_y), -1)
#结果
tensor([[[0.1000, 0.6000],
[0.2000, 0.5000],
[0.3000, 0.4000],
[0.4000, 0.3000],
[0.5000, 0.2000],
[0.6000, 0.1000]]])
利用shift 做参考点时空间对齐
如果有历史,则把历史和现在bev参考点叠加,如果没有则加两次当前的。
进入·BEVFormerLayer类中寻找TSA层
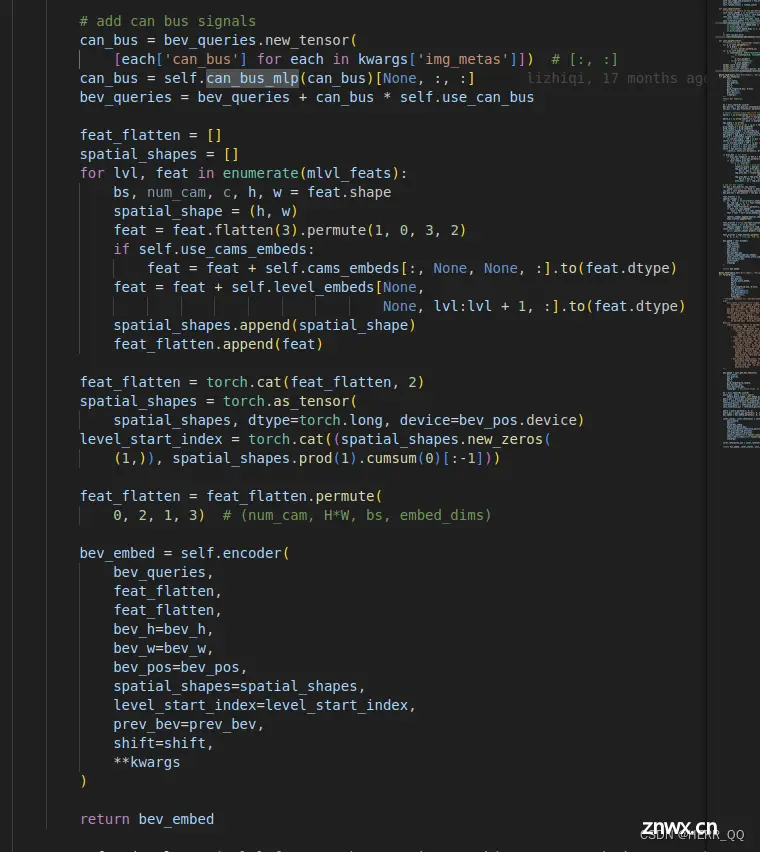
详细代码见temporal_self_attention,value是上一帧pre_bev(事实上是本轮和上一帧一起的stack),query是本轮bev_query,key没有用。

如果没有上一帧,用两个本轮叠加
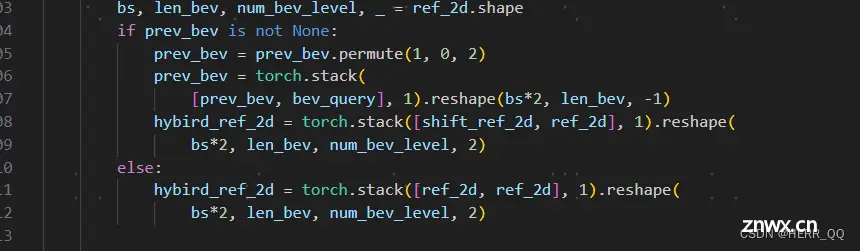
位置编码
多头注意力处理 多头注意力优点和用法在transformer学习笔记有记录
位置掩码
为可变形注意力取点,代码里取4个点
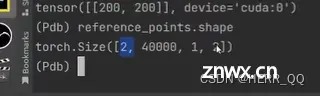
1是 批次 40000是bev base 的200*200的特征空间大小 8个多头 2点历史帧 4个注意力的点 2为xy坐标
用于计算到reference point 的偏移量
而attention_weights 用于从4个点中确定最需要关心的点 然后把四个点的权重归一化
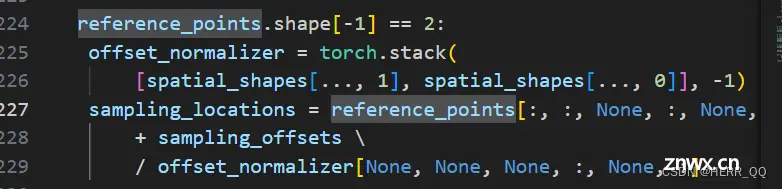
2是reference 和 shifted reference
sampling_locations 是真正意义上的采样点

2 是bev 和prev bev
每一个头的4个点就出来了
可变形注意力 在multi_scale_deformable_attn_function 中
代码结构(按照代码运行流程forward顺序再次解读)
推理流程按照forward即代码运行顺序,总结流程,直接在代码中注释,
参考来源
tools\ test.py
2. projects/mmdet3d_plugin/bevformer/apis/test.py
<code>def custom_multi_gpu_test(model, data_loader, tmpdir=None, gpu_collect=False):
"""
Args:
model (nn.Module): Model to be tested.
data_loader (nn.Dataloader): Pytorch data loader.
tmpdir (str): Path of directory to save the temporary results from
different gpus under cpu mode.
gpu_collect (bool): Option to use either gpu or cpu to collect results.
Returns:
list: The prediction results. 包含box框和
"""
model.eval()
# 设置模型为推理模式
bbox_results = []
mask_results = []
dataset = data_loader.dataset
rank, world_size = get_dist_info()
if rank == 0:
prog_bar = mmcv.ProgressBar(len(dataset))
time.sleep(2) # This line can prevent deadlock problem in some cases.
have_mask = False
for i, data in enumerate(data_loader):
#取index 和每一个创建的data单元
with torch.no_grad():
#关闭记录梯度
result = model(return_loss=False, rescale=True, **data)
# 进入到下一个处理环节
# encode mask results
if isinstance(result, dict): # 如果result是字典
if 'bbox_results' in result.keys():#寻找键 bbox。。。
bbox_result = result['bbox_results']
batch_size = len(result['bbox_results'])
bbox_results.extend(bbox_result) # 加入result所有结果
if 'mask_results' in result.keys() and result['mask_results'] is not None:
mask_result = custom_encode_mask_results(result['mask_results'])
mask_results.extend(mask_result)
have_mask = True
else:
batch_size = len(result)
bbox_results.extend(result)
#############省略######################
return { 'bbox_results': bbox_results, 'mask_results': mask_results}
projects/mmdet3d_plugin/bevformer/detectors/bevformer.py
def forward(self, return_loss=True, **kwargs):
"""Calls either forward_train or forward_test depending on whether
return_loss=True.
Note this setting will change the expected inputs. When
`return_loss=True`, img and img_metas are single-nested (i.e.
torch.Tensor and list[dict]), and when `resturn_loss=False`, img and
img_metas should be double nested (i.e. list[torch.Tensor],
list[list[dict]]), with the outer list indicating test time
augmentations.
"""
if return_loss:
return self.forward_train(**kwargs)
else:
return self.forward_test(**kwargs)
# 根据loss标志位决定是测试准确度还是训练模式,不同模式得返回值不同
forward_test
def forward_test(self, img_metas, img=None, **kwargs):
#############省略######################
new_prev_bev, bbox_results = self.simple_test(
img_metas[0], img[0], prev_bev=self.prev_frame_info['prev_bev'], **kwargs)
# During inference, we save the BEV features and ego motion of each timestamp.
return bbox_results
simple_test
def simple_test(self, img_metas, img=None, prev_bev=None, rescale=False):
"""Test function without augmentaiton."""
img_feats = self.extract_feat(img=img, img_metas=img_metas)
# self.extract_feat 主要包括两个步骤 img_backbone、img_neck,通过卷积提取特征
# 网络为resnet + FPN
# 如果是base模型,img_feats 为四个不同尺度的特征层
bbox_list = [dict() for i in range(len(img_metas))]
new_prev_bev, bbox_pts = self.simple_test_pts(
img_feats, img_metas, prev_bev, rescale=rescale)
for result_dict, pts_bbox in zip(bbox_list, bbox_pts):
result_dict['pts_bbox'] = pts_bbox
return new_prev_bev, bbox_list
simple_test_pts
# 对特征层进行编解码
outs = self.pts_bbox_head(x, img_metas, prev_bev=prev_bev)
projects/mmdet3d_plugin/bevformer/dense_heads/bevformer_head.py
class BEVFormerHead(DETRHead):
"""Head of Detr3D.
Args:
with_box_refine (bool): Whether to refine the reference points
in the decoder. Defaults to False.
as_two_stage (bool) : Whether to generate the proposal from
the outputs of encoder.
transformer (obj:`ConfigDict`): ConfigDict is used for building
the Encoder and Decoder.
bev_h, bev_w (int): spatial shape of BEV queries.
"""
if not self.as_two_stage:
#设定位置编码
self.bev_embedding = nn.Embedding(
self.bev_h * self.bev_w, self.embed_dims)
self.query_embedding = nn.Embedding(self.num_query,
self.embed_dims * 2)
#####################省略########################
def forward(self, mlvl_feats, img_metas, prev_bev=None, only_bev=False):
"""Forward function.
Args:
mlvl_feats (tuple[Tensor]): Features from the upstream
network, each is a 5D-tensor with shape
(B, N, C, H, W).
prev_bev: previous bev featues
only_bev: only compute BEV features with encoder.
Returns:
all_cls_scores (Tensor): Outputs from the classification head, \
shape [nb_dec, bs, num_query, cls_out_channels]. Note \
cls_out_channels should includes background.
all_bbox_preds (Tensor): Sigmoid outputs from the regression \
head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \
Shape [nb_dec, bs, num_query, 9].
"""
# mlvl_feats: (tuple[Tensor]) FPN网络输出的多尺度特征
# prev_bev: 上一时刻的 bev_features
# all_cls_scores: 所有的类别得分信息
# all_bbox_preds: 所有预测框信息
bs, num_cam, _, _, _ = mlvl_feats[0].shape
dtype = mlvl_feats[0].dtype
# 给出数据类型
# 特征编码 (900,512) (900,256) concate (900 + 256)
object_query_embeds = self.query_embedding.weight.to(dtype)
# [2500,256] bev特征图的大小,最终bev的大小为 50*50,每个点的channel维度为256。
bev_queries = self.bev_embedding.weight.to(dtype)
# [1, 256, 50, 50] 可学习的位置编码
bev_mask = torch.zeros((bs, self.bev_h, self.bev_w),
device=bev_queries.device).to(dtype)
bev_pos = self.positional_encoding(bev_mask).to(dtype)
if only_bev: # only use encoder to obtain BEV features, TODO: refine the workaround
return self.transformer.get_bev_features(
mlvl_feats,
bev_queries,
self.bev_h,
self.bev_w,
grid_length=(self.real_h / self.bev_h,
self.real_w / self.bev_w),
bev_pos=bev_pos,
img_metas=img_metas,
prev_bev=prev_bev,
)
else:
# 进入transformer1
outputs = self.transformer(
mlvl_feats,
bev_queries,
object_query_embeds,
self.bev_h,
self.bev_w,
grid_length=(self.real_h / self.bev_h,
self.real_w / self.bev_w),
bev_pos=bev_pos,
reg_branches=self.reg_branches if self.with_box_refine else None, # noqa:E501
cls_branches=self.cls_branches if self.as_two_stage else None,
img_metas=img_metas,
prev_bev=prev_bev
)
8.projects/mmdet3d_plugin/bevformer/modules/transformer.py
@auto_fp16(apply_to=('mlvl_feats', 'bev_queries', 'object_query_embed', 'prev_bev', 'bev_pos'))
def forward(self,
mlvl_feats,
bev_queries,
object_query_embed,
bev_h,
bev_w,
grid_length=[0.512, 0.512],
bev_pos=None,
reg_branches=None,
cls_branches=None,
prev_bev=None,
**kwargs):
# 获得bev特征 temporal_self_attention + spatial_cross_attention
bev_embed = self.get_bev_features(
mlvl_feats,
bev_queries,
bev_h,
bev_w,
grid_length=grid_length,
bev_pos=bev_pos,
prev_bev=prev_bev,
**kwargs) # bev_embed shape: bs, bev_h*bev_w, embed_dims
# 可以进入encoder
inter_states, inter_references = self.decoder(
query=query,
key=None,
value=bev_embed,
query_pos=query_pos,
reference_points=reference_points,
reg_branches=reg_branches,
cls_branches=cls_branches,
spatial_shapes=torch.tensor([[bev_h, bev_w]], device=query.device),
level_start_index=torch.tensor([0], device=query.device),
**kwargs)
# decoder 进入 decoder
return bev_embed, inter_states, init_reference_out, inter_references_out
# 返回bevformer_head.py
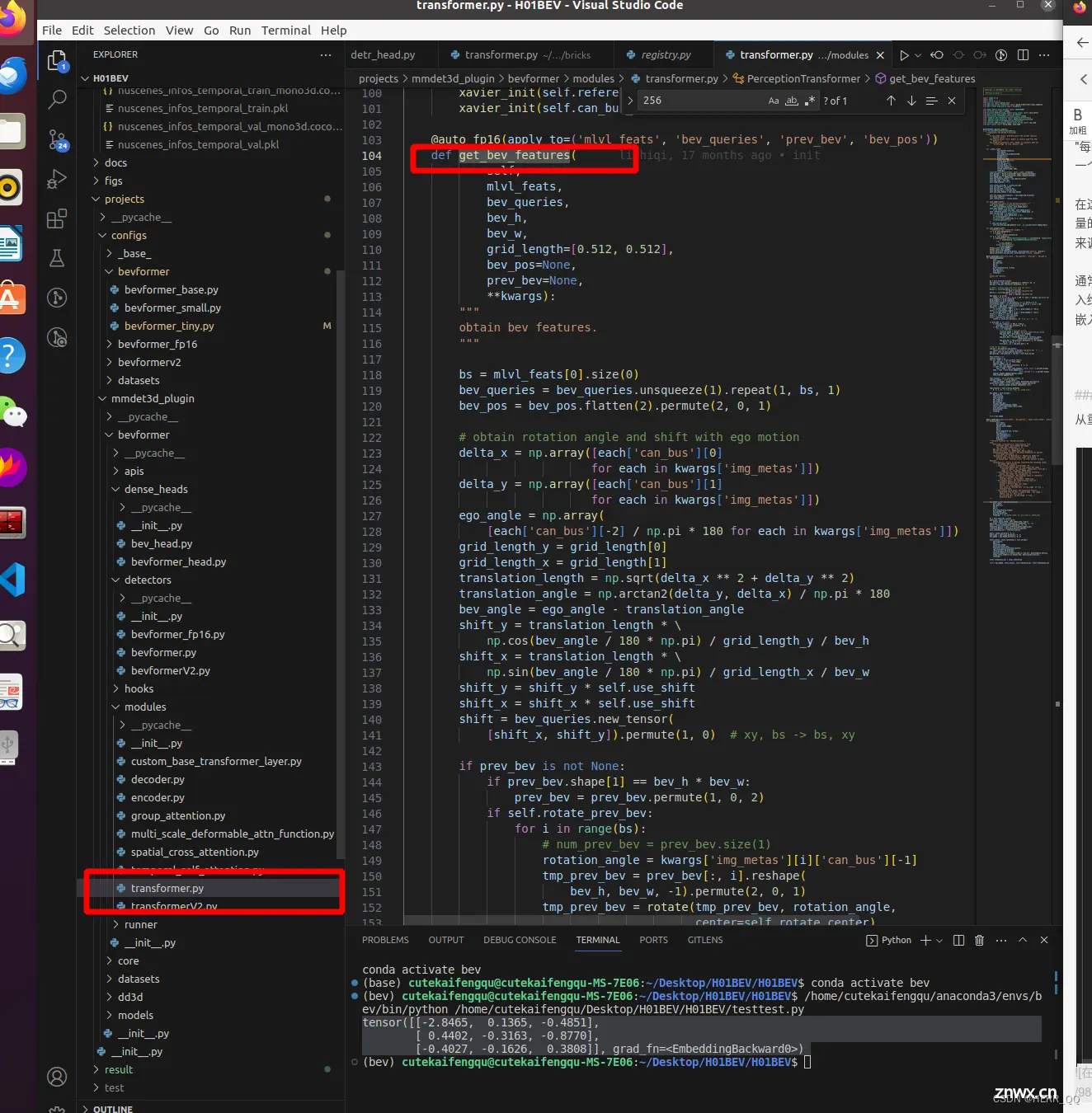
get_bev_features
def get_bev_features(
self,
mlvl_feats,
bev_queries,
bev_h,
bev_w,
grid_length=[0.512, 0.512],
bev_pos=None,
prev_bev=None,
**kwargs):
# 车身底盘信号:速度、加速度等
# 当前帧的bev特征与历史特征进行 时间、空间上的对齐
bs = mlvl_feats[0].size(0)
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1)
bev_pos = bev_pos.flatten(2).permute(2, 0, 1)
# 展平bev_Pos
# obtain rotation angle and shift with ego motion
delta_x = np.array([each['can_bus'][0]
for each in kwargs['img_metas']])
delta_y = np.array([each['can_bus'][1]
for each in kwargs['img_metas']])
ego_angle = np.array(
[each['can_bus'][-2] / np.pi * 180 for each in kwargs['img_metas']])
grid_length_y = grid_length[0]
grid_length_x = grid_length[1]
translation_length = np.sqrt(delta_x ** 2 + delta_y ** 2)
translation_angle = np.arctan2(delta_y, delta_x) / np.pi * 180
# 计算偏移量
bev_angle = ego_angle - translation_angle
shift_y = translation_length * \
np.cos(bev_angle / 180 * np.pi) / grid_length_y / bev_h
shift_x = translation_length * \
np.sin(bev_angle / 180 * np.pi) / grid_length_x / bev_w
shift_y = shift_y * self.use_shift
shift_x = shift_x * self.use_shift
shift = bev_queries.new_tensor(
[shift_x, shift_y]).permute(1, 0) # xy, bs -> bs, xy
if prev_bev is not None:
if prev_bev.shape[1] == bev_h * bev_w:
prev_bev = prev_bev.permute(1, 0, 2)
if self.rotate_prev_bev:
for i in range(bs):
# num_prev_bev = prev_bev.size(1)
rotation_angle = kwargs['img_metas'][i]['can_bus'][-1]
tmp_prev_bev = prev_bev[:, i].reshape(
bev_h, bev_w, -1).permute(2, 0, 1)
tmp_prev_bev = rotate(tmp_prev_bev, rotation_angle,
center=self.rotate_center)
tmp_prev_bev = tmp_prev_bev.permute(1, 2, 0).reshape(
bev_h * bev_w, 1, -1)
prev_bev[:, i] = tmp_prev_bev[:, 0]
# add can bus signals
# 将can信息加入Q
can_bus = bev_queries.new_tensor(
[each['can_bus'] for each in kwargs['img_metas']]) # [:, :]
can_bus = self.can_bus_mlp(can_bus)[None, :, :]
bev_queries = bev_queries + can_bus * self.use_can_bus
feat_flatten = []
spatial_shapes = []
for lvl, feat in enumerate(mlvl_feats):
bs, num_cam, c, h, w = feat.shape
spatial_shape = (h, w)
feat = feat.flatten(3).permute(1, 0, 3, 2)
if self.use_cams_embeds:
feat = feat + self.cams_embeds[:, None, None, :].to(feat.dtype)
feat = feat + self.level_embeds[None,
None, lvl:lvl + 1, :].to(feat.dtype)
spatial_shapes.append(spatial_shape)
feat_flatten.append(feat)
feat_flatten = torch.cat(feat_flatten, 2)
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=bev_pos.device)
# 每一个维度的起始点
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
feat_flatten = feat_flatten.permute(
0, 2, 1, 3) # (num_cam, H*W, bs, embed_dims)
# 获得bev特征
bev_embed = self.encoder(
bev_queries,
feat_flatten,
feat_flatten,
bev_h=bev_h,
bev_w=bev_w,
bev_pos=bev_pos,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
prev_bev=prev_bev,
shift=shift,
**kwargs
)
return bev_embed
projects/mmdet3d_plugin/bevformer/modules/encoder.py
def get_reference_points(H, W, Z=8, num_points_in_pillar=4, dim='3d', bs=1, device='cuda', dtype=torch.float):code>
# 获取参考点
"""Get the reference points used in SCA and TSA.
Args:
H, W: spatial shape of bev.
Z: hight of pillar.
D: sample D points uniformly from each pillar.
device (obj:`device`): The device where
reference_points should be.
Returns:
Tensor: reference points used in decoder, has \
shape (bs, num_keys, num_levels, 2).
"""
def forward(self,
bev_query,
key,
value,
*args,
bev_h=None,
bev_w=None,
bev_pos=None,
spatial_shapes=None,
level_start_index=None,
valid_ratios=None,
prev_bev=None,
shift=0.,
**kwargs):
"""Forward function for `TransformerDecoder`.
Args:
bev_query (Tensor): Input BEV query with shape
`(num_query, bs, embed_dims)`.
key & value (Tensor): Input multi-cameta features with shape
(num_cam, num_value, bs, embed_dims)
reference_points (Tensor): The reference
points of offset. has shape
(bs, num_query, 4) when as_two_stage,
otherwise has shape ((bs, num_query, 2).
valid_ratios (Tensor): The radios of valid
points on the feature map, has shape
(bs, num_levels, 2)
Returns:
Tensor: Results with shape [1, num_query, bs, embed_dims] when
return_intermediate is `False`, otherwise it has shape
[num_layers, num_query, bs, embed_dims].
"""
#通过叠加历史特征和偏移量得到当前帧特征点
ref_3d = self.get_reference_points(
bev_h, bev_w, self.pc_range[5]-self.pc_range[2], self.num_points_in_pillar, dim='3d', bs=bev_query.size(1), device=bev_query.device, dtype=bev_query.dtype)code>
ref_2d = self.get_reference_points(
bev_h, bev_w, dim='2d', bs=bev_query.size(1), device=bev_query.device, dtype=bev_query.dtype)code>
reference_points_cam, bev_mask = self.point_sampling(
ref_3d, self.pc_range, kwargs['img_metas'])
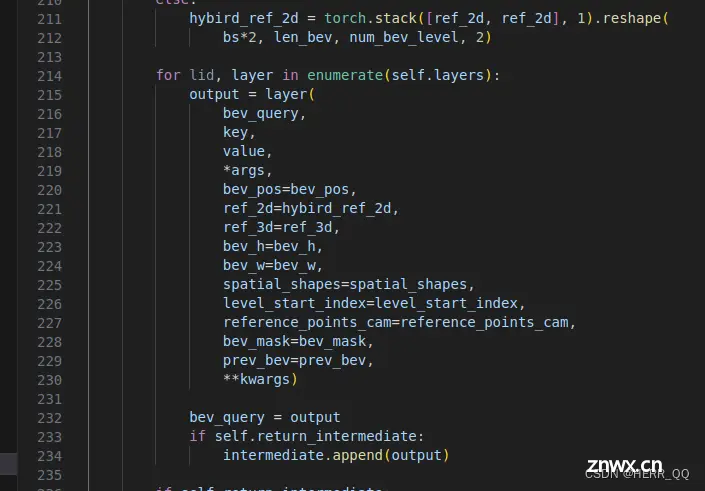
for lid, layer in enumerate(self.layers):
output = layer(
bev_query,
key,
value,
*args,
bev_pos=bev_pos,
ref_2d=hybird_ref_2d,
ref_3d=ref_3d,
bev_h=bev_h,
bev_w=bev_w,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
reference_points_cam=reference_points_cam,
bev_mask=bev_mask,
prev_bev=prev_bev,
**kwargs) #进行6次重复
BEVFormerLayer 即为论文中的图
<code> for layer in self.operation_order:
# temporal self attention
if layer == 'self_attn': # 时间自注意力
query = self.attentions[attn_index](
query,
prev_bev,
prev_bev,
identity if self.pre_norm else None,
query_pos=bev_pos,
key_pos=bev_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=query_key_padding_mask,
reference_points=ref_2d,
spatial_shapes=torch.tensor(
[[bev_h, bev_w]], device=query.device),
level_start_index=torch.tensor([0], device=query.device),
**kwargs)
attn_index += 1
identity = query
elif layer == 'norm': #
query = self.norms[norm_index](query)
norm_index += 1
# spaital cross attention
elif layer == 'cross_attn': # 交叉空间注意力
query = self.attentions[attn_index](
query,
key,
value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=key_pos,
reference_points=ref_3d,
reference_points_cam=reference_points_cam,
mask=mask,
attn_mask=attn_masks[attn_index],
key_padding_mask=key_padding_mask,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
**kwargs)
attn_index += 1
identity = query
elif layer == 'ffn': # 全连接输出
query = self.ffns[ffn_index](
query, identity if self.pre_norm else None)
ffn_index += 1
return query
projects/mmdet3d_plugin/bevformer/modules/temporal_self_attention.py
时间自注意力
self.im2col_step = im2col_step
self.embed_dims = embed_dims # bev 特征维度
self.num_levels = num_levels #多尺度特征层
self.num_heads = num_heads# 多头数量
self.num_points = num_points#采样点数
self.num_bev_queue = num_bev_queue # bev特征长度 时序上
self.sampling_offsets = nn.Linear(
embed_dims*self.num_bev_queue, num_bev_queue*num_heads * num_levels * num_points * 2) # 利用线形层学习采样偏移
self.attention_weights = nn.Linear(embed_dims*self.num_bev_queue,
num_bev_queue*num_heads * num_levels * num_points)# 利用线形层学习注意权重
self.value_proj = nn.Linear(embed_dims, embed_dims)
self.output_proj = nn.Linear(embed_dims, embed_dims)
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
level_start_index=None,
flag='decoder',code>
**kwargs):
"""Forward Function of MultiScaleDeformAttention.
Args:
query (Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
key (Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
value (Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`.
identity (Tensor): The tensor used for addition, with the
same shape as `query`. Default None. If None,
`query` will be used.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, num_levels, 2),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (Tensor): Spatial shape of features in
different levels. With shape (num_levels, 2),
last dimension represents (h, w).
level_start_index (Tensor): The start index of each level.
A tensor has shape ``(num_levels, )`` and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
"""
# query 以当前时刻得bev特征Q查询上一时刻和上上时刻的bev特征值KV
#query: (1, 2500, 256) 当前时刻的bev特征图
#key: (2, 2500, 256) 上一个时刻的以及上上时刻的bev特征
#value: (2, 2500, 256) 上一个时刻的以及上上时刻的bev特征
#query_pos: 可学习的位置编码
#reference_points:每个bev特征点对应的坐标
value = torch.stack([query, query], 1).reshape(bs*2, len_bev, c)
# value 变化为用当前bev特征叠加
query = query + query_pos
# Q 加上位置编码信息
# 将前一时刻的bev和当前时刻的bev特征再特征维度上进行叠加
query = torch.cat([value[:bs], query], -1)
# 学习前一时刻和当前时刻的bev特征
value = self.value_proj(value)
# 从当前时刻的bev_query 学习到 参考点的偏置
sampling_offsets = self.sampling_offsets(query)
用于学习每个特征点之间的权重
attention_weights = self.attention_weights(query)
#多尺度可变性注意力
if value.dtype == torch.float16:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
else:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
# 线性层
output = self.output_proj(output)
# 残差链接
return self.dropout(output) + identity
返回到 projects/mmdet3d_plugin/bevformer/modules/encoder.py 中
Projects\mmdet3d_plugin\bevformer\modules\multi_scale_deformable_attn_function.py
Args:
value (Tensor): The value has shape
(bs, num_keys, mum_heads, embed_dims//num_heads)
value_spatial_shapes (Tensor): Spatial shape of
each feature map, has shape (num_levels, 2),
last dimension 2 represent (h, w)
sampling_locations (Tensor): The location of sampling points,
has shape
(bs ,num_queries, num_heads, num_levels, num_points, 2),
the last dimension 2 represent (x, y).
attention_weights (Tensor): The weight of sampling points used
when calculate the attention, has shape
(bs ,num_queries, num_heads, num_levels, num_points),
im2col_step (Tensor): The step used in image to column.
Returns:
Tensor: has shape (bs, num_queries, embed_dims)
"""
projects/mmdet3d_plugin/bevformer/modules/spatial_cross_attention.py
pc_range:真实世界的尺度```
query (Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
key (Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
value (Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`. (B, N, C, H, W)
residual (Tensor): The tensor used for addition, with the
same shape as `x`. Default None. If None, `x` will be used.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, 4),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{ query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (Tensor): Spatial shape of features in
different level. With shape (num_levels, 2),
last dimension represent (h, w).
level_start_index (Tensor): The start index of each level.
A tensor has shape (num_levels) and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims]
MSDeformableAttention3D
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
level_start_index=None,
**kwargs):
"""Forward Function of MultiScaleDeformAttention.
Args:
query (Tensor): Query of Transformer with shape
( bs, num_query, embed_dims).
key (Tensor): The key tensor with shape
`(bs, num_key, embed_dims)`.
value (Tensor): The value tensor with shape
`(bs, num_key, embed_dims)`.
identity (Tensor): The tensor used for addition, with the
same shape as `query`. Default None. If None,
`query` will be used.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, num_levels, 2),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (Tensor): Spatial shape of features in
different levels. With shape (num_levels, 2),
last dimension represents (h, w).
level_start_index (Tensor): The start index of each level.
A tensor has shape ``(num_levels, )`` and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
"""
projects/mmdet3d_plugin/bevformer/modules/decoder.py
"""Forward function for `TransformerDecoderLayer`.
**kwargs contains some specific arguments of attentions.
Args:
query (Tensor): The input query with shape
[num_queries, bs, embed_dims] if
self.batch_first is False, else
[bs, num_queries embed_dims].
key (Tensor): The key tensor with shape [num_keys, bs,
embed_dims] if self.batch_first is False, else
[bs, num_keys, embed_dims] .
value (Tensor): The value tensor with same shape as `key`.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`.
Default: None.
attn_masks (List[Tensor] | None): 2D Tensor used in
calculation of corresponding attention. The length of
it should equal to the number of `attention` in
`operation_order`. Default: None.
query_key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_queries]. Only used in `self_attn` layer.
Defaults to None.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_keys]. Default: None.
Returns:
Tensor: forwarded results with shape [num_queries, bs, embed_dims]. """
return output, reference_points
# 返回到 projects/mmdet3d_plugin/bevformer/modules/transformer.py
上一篇: 国内服务器安装Docker提示Failed to connect to download.docker.com port 443的解决方案
下一篇: 树莓派Raspberry Pi 5系列 -- 硬件篇第四章 -- 树莓派5 安装烧录ubuntu24.04操作系统
本文标签
[Algorithm] BEVformer 源码细节学习&&ubuntu20.04下的环境配置&&目标跑起开源代码&&论文学习笔记
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。