
LoRA作为一种创新的微调技术,通过低秩矩阵分解方法,实现了对大型生成模型的高效微调。在StableDiffusion模型中,LoRA技术被广泛应用于角色、风格、概念、服装和物体等不同分类的图像生成中。通过结...
ChatGLM3是智谱AI和清华大学KEG实验室联合发布的对话预训练模型。ChatGLM3-6B是ChatGLM3系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,Chat...
Hi,大家好,我是半亩花海。最近在尝试学习AIGC的内容,并报名参加了Datawhale举办的2024年AI第四期夏令营,主要学习内容是从零入门AI生图原理和实践。本次活动基于魔搭社区“可图Kolors-LoRA...

最近做了一个基于Qwen2-1.5B-Instruct模型的比赛,记录一下自己的微调过程。怕自己以后忘了我就手把手一步一步来记录了。大多数都是给小白看的,如果你是小白建议你用jupyter运行,按照我这个模块一块一块运...
在人工智能领域,自然语言处理(NLP)一直是研究的热点之一。随着深度学习技术的不断发展,大型预训练语言模型(如Qwen2-7B-Instruct)在理解与生成自然语言方面取得了显著的进展。然而,这些模型往往需...
Databricks的dolly-v2-3b是一种基于Databricks机器学习平台训练的指令跟随大型语言模型,可以用于商业用途,专为自然语言处理任务而设计。它能够理解和生成多种语言的文本,支持翻译、摘要...
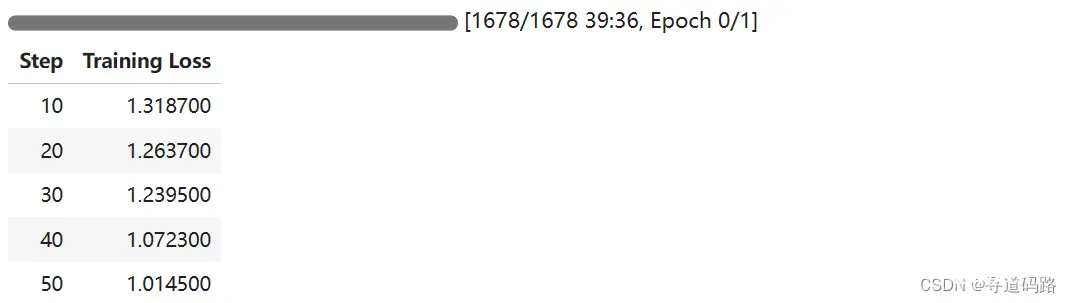
在人工智能领域,大型预训练语言模型(LargeLanguageModels,LLMs)已经成为推动自然语言处理(NLP)任务发展的重要力量。Llama2作为其中的一个先进代表,通过其庞大的参数规模和深度学习...
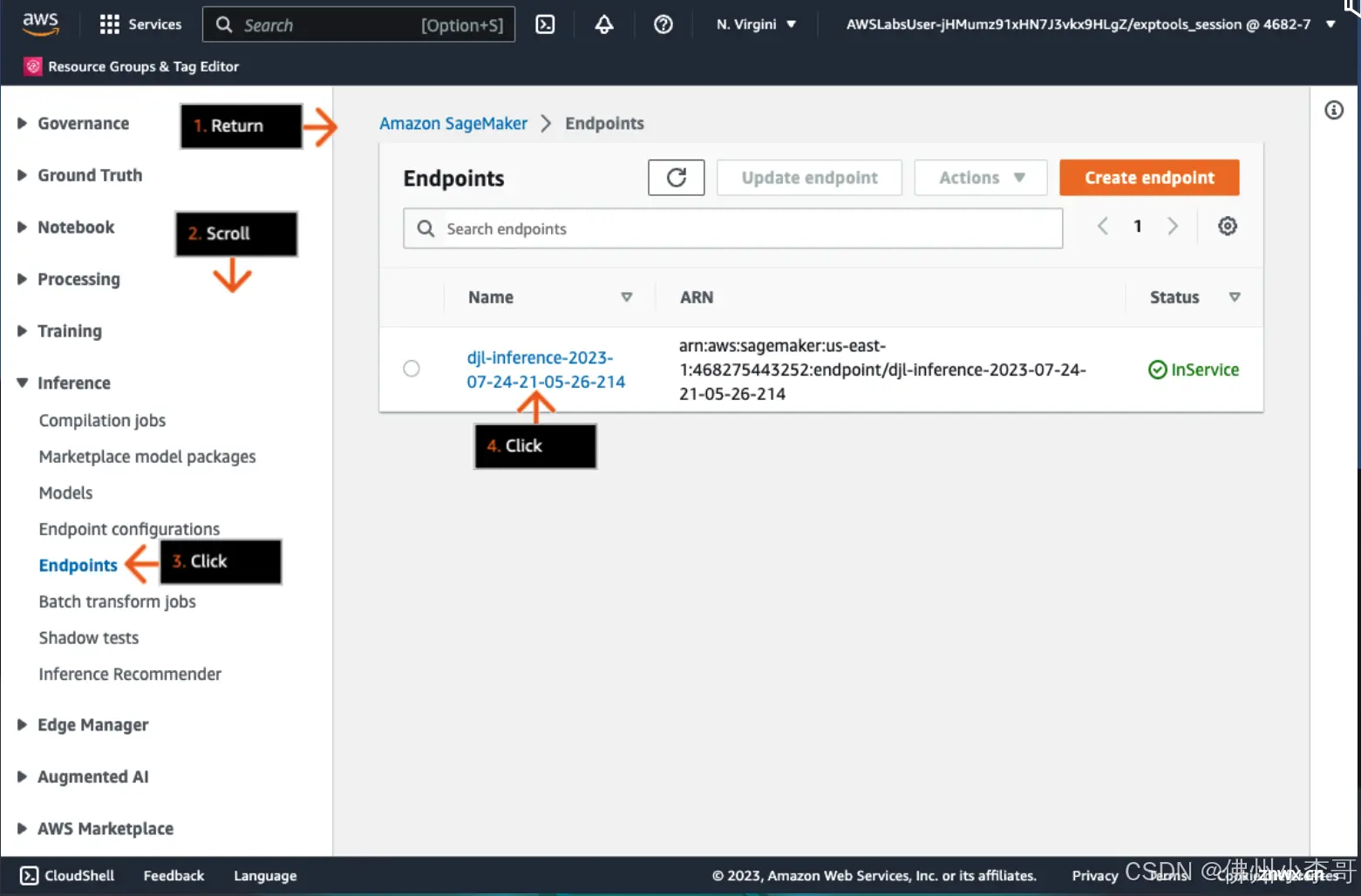
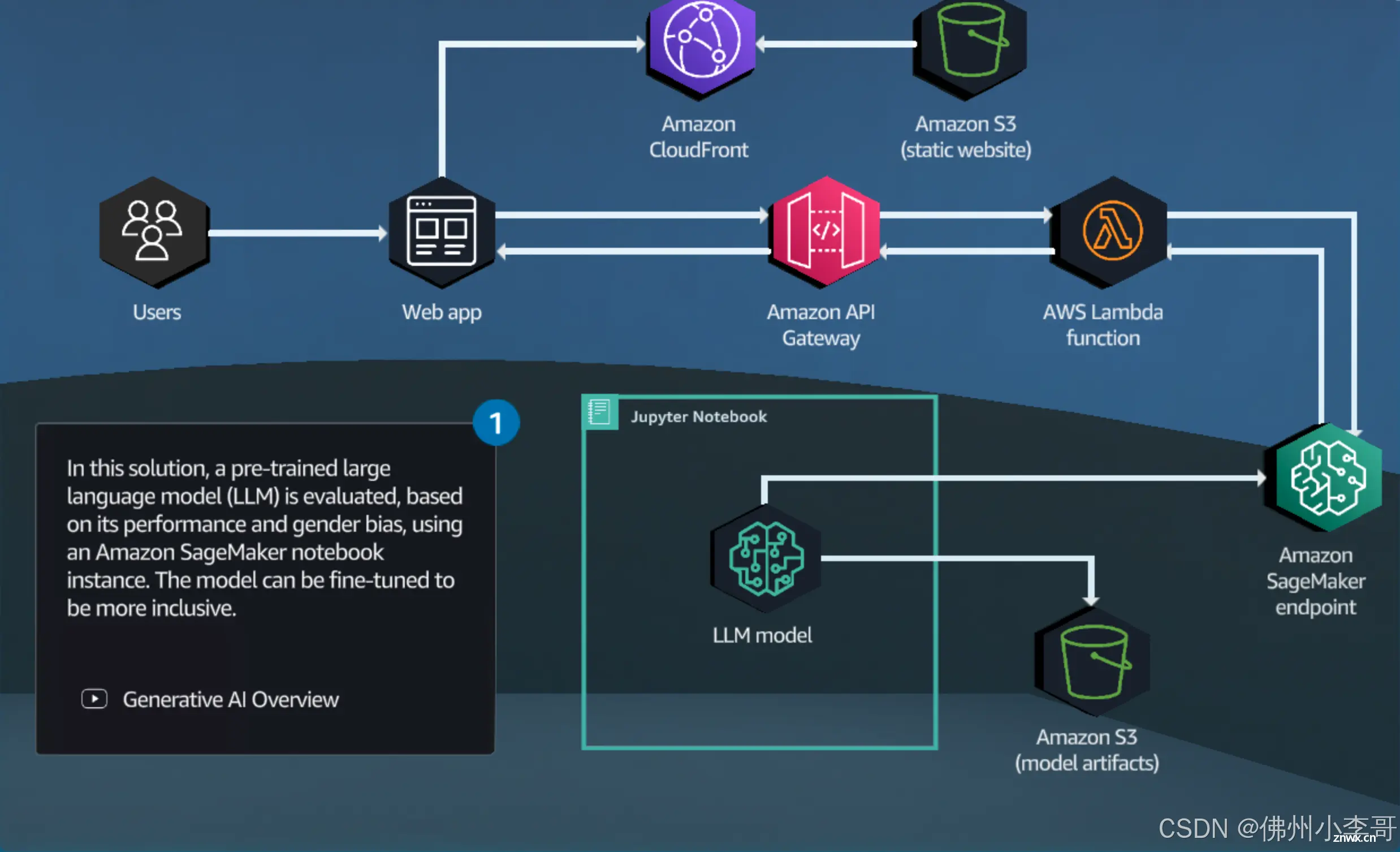
AmazonSageMaker是一个完全托管的机器学习服务(大家可以理解为Serverless的JupyterNotebook),专为应用开发和数据科学家设计,帮助他们快速构建、训练和部署机器学习模型。使用...

本教程详细介绍了LoRA参数高效微调技术,包括数据集准备和处理、模型加载、参数设置等,然后以Qwen2-0.5B预训练模型实践,进行了文本分类能力微调,微调过程通过SwanLab可视化界面查看,最终微调模型进行测试数据评估……...
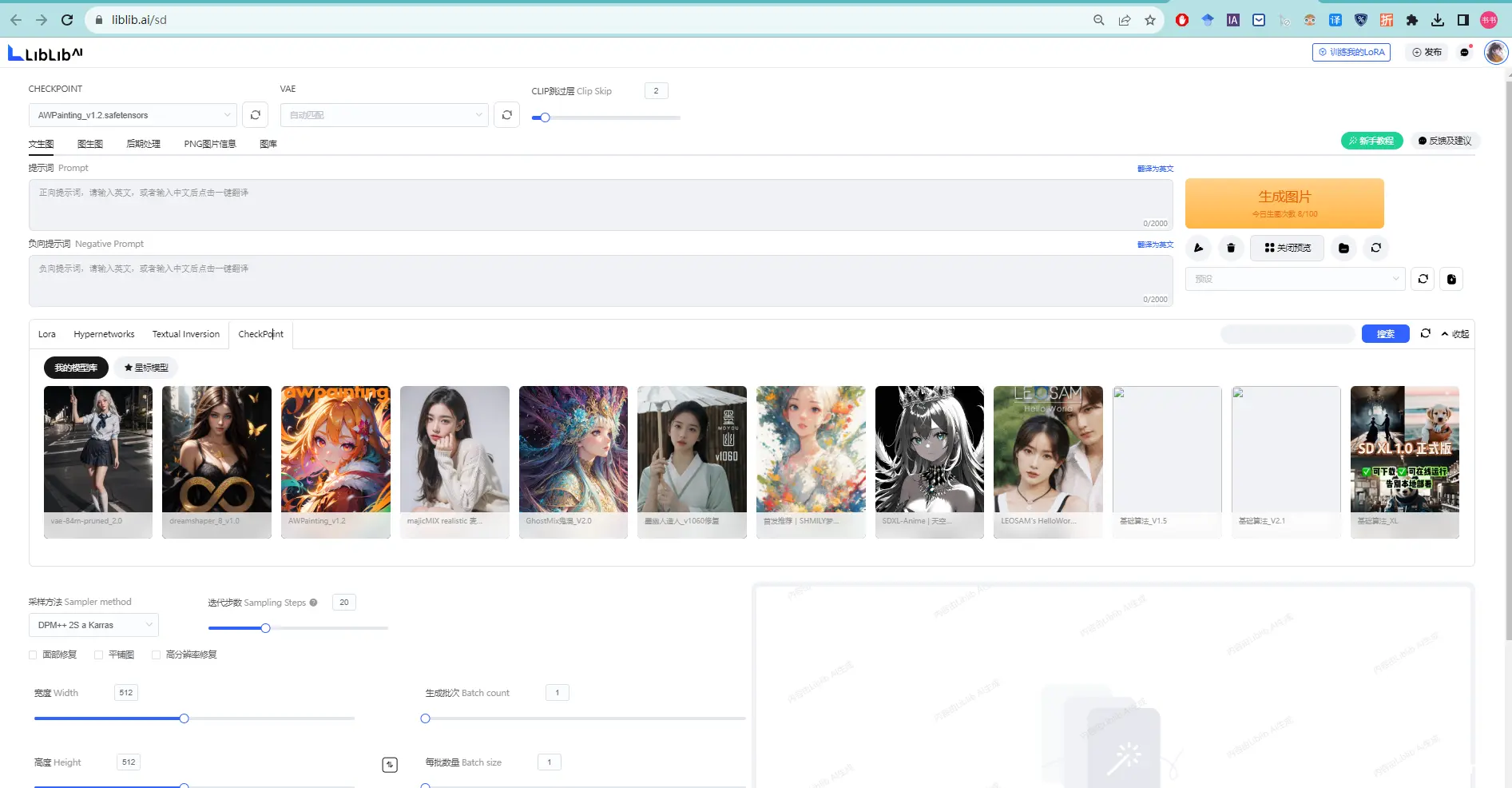
在哩布AI试用在线生成图片、训练Lora、上传AI生成图https://www.liblib.ai/_哩布哩布ai官网...