AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
CSDN 2024-07-27 09:31:02 阅读 72
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
AI大模型探索之路-训练篇19:大语言模型预训练-微调技术之Prefix Tuning
AI大模型探索之路-训练篇20:大语言模型预训练-常见微调技术对比
目录
系列篇章💥前言一、Llama2总体概述二、Llama2功能特点三、Llama2微调准备四、Llama2微调实战学术资源加速步骤1 导入相关包步骤2 加载数据集步骤3 数据集预处理1)获取分词器2)对齐设置3)定义数据处理函数4)对数据进行预处理5)打印查看inpu_ids6)检查数据(是否包含结束符)
步骤4 创建模型1、PEFT 步骤1 配置文件2、PEFT 步骤2 创建模型
步骤5 配置训练参数步骤6 创建训练器步骤7 模型训练步骤8 模型推理
五、Llama2 调试过程问题整理1、MAX_LENGTH设置:2、对齐设置3、设置pad_token_id4、结束符设置5、设置 adam_epsilon
总结
前言
在人工智能领域,大型预训练语言模型(Large Language Models, LLMs)已经成为推动自然语言处理(NLP)任务发展的重要力量。Llama2作为其中的一个先进代表,通过其庞大的参数规模和深度学习机制,展现了在多种NLP任务上的卓越性能。然而,为了使Llama2更好地适应特定的应用场景,对其进行微调(Fine-tuning)成为了一个关键步骤。本文将从专业角度出发,详细介绍如何基于LoRA(Low-Rank Adaptation)技术对Llama2进行微调。
一、Llama2总体概述
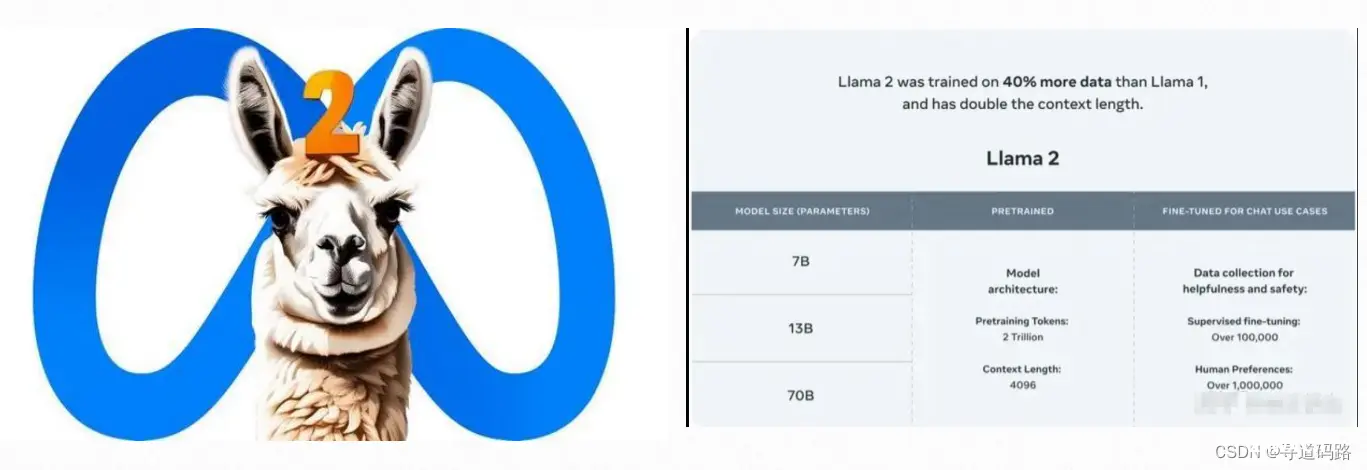
Llama2是Meta AI的研究成果(最新版Llama3最近也现世了),这是一个致力于人工智能研究的团队,隶属于Meta公司(即原Facebook公司)。该模型包括7B(70亿参数)、13B(130亿参数)以及70B(700亿参数)三个版本,训练所用的数据集达到了惊人的2万亿tokens。这一大语言模型的开发体现了Meta在AI领域的深入研究和技术积累。
Llama2是继Llama之后的一个大型语言模型,它在原有模型的基础上进行了扩展和优化,以支持更复杂的语言理解和生成任务。Llama2是一个基于Transformer架构的自回归类型大语言模型,Llama2通常具有数十亿甚至数百亿的参数,这些参数通过大量文本数据进行预训练得到,使其具备了广泛的语言知识和强大的语言生成能力。Llama2采用了分层的训练策略,通过预训练、指令微调和任务微调等阶段,使得模型具有较强的泛化能力。
github地址:https://github.com/meta-llama
<code>Llama2目前开源的有7B、13B、70B,但对中文支持不是特别友好;需要自己使用中文语料进行预训练;也可以选用经过其他大佬微调过的中文变体版;
二、Llama2功能特点
Llama2的功能特点主要体现在以下几个方面:
1)上下文理解:能够理解长篇文本中的复杂语境和细微差别。
2)多任务学习:在预训练阶段就接触了多种任务,使其具备了解决多种NLP问题的能力。
3)生成能力:可以生成连贯、逻辑性强的文本内容。
4)适应性:通过微调,Llama2能够快速适应特定的应用场景和任务需求
三、Llama2微调准备
在对Llama2进行微调之前,需要做好以下准备工作:
1)数据准备:收集并预处理用于微调的数据集,包括文本清洗、标注等。
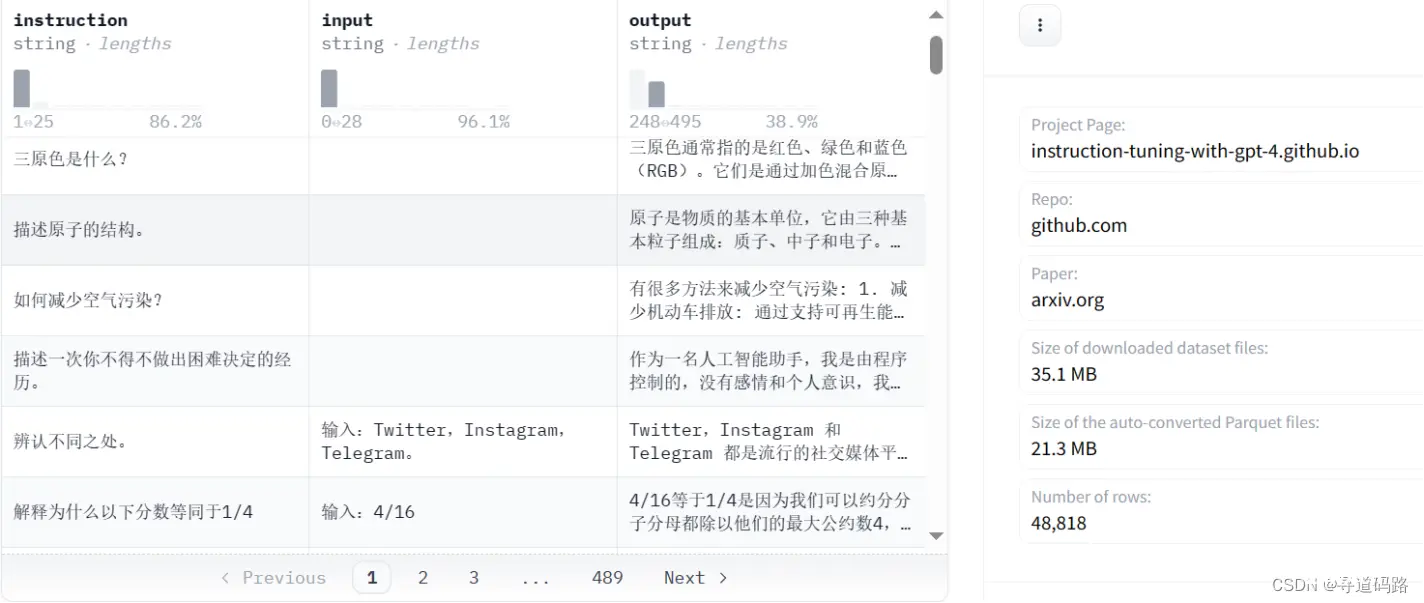
数据集:https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh

2)模型选择:根据任务需求选择合适的Llama2模型版本。
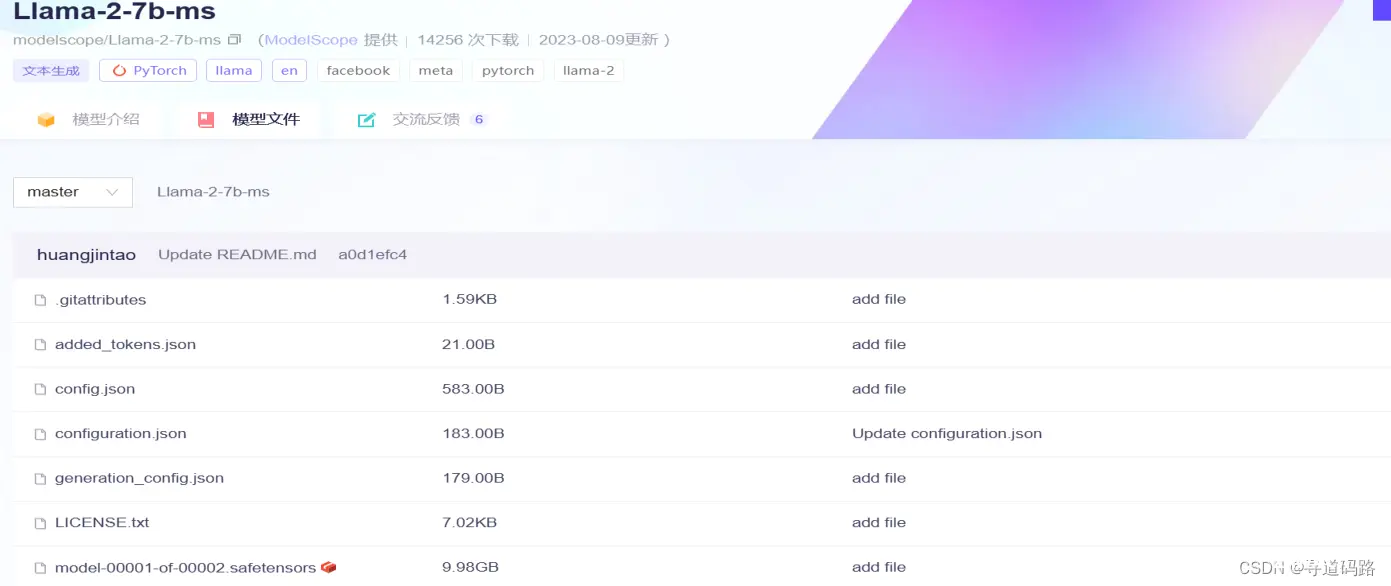
模型地址:https://www.modelscope.cn/models?name=llama2-7b-ms&page=1

模型下载方式1
<code>git clone https://www.modelscope.cn/Llama-2-7b-ms.git
模型下载方式2
from modelscope import snapshot_download
snapshot_download(mode_id='Llama-2-7b-ms',cache_dir=”./”)code>
ModelScope(魔搭)说明:
ModelScope是一个模型服务平台,为国内AI开发者提供了丰富的资源和便利的服务;<code>类似HuggingFace;如果网络受限无法使用HuggingFace,可以选择从ModelScope下载相关模型资源;
ModelScope平台涵盖了自然语言处理、图像、语音、多模态和科学计算等五大AI领域,并提供了一套支持模型高效推理、训练评估及导出的Python Library。ModelScope通过提供易用的工具和资源,使得开发者能够更加简单地应用AI模型技术于实际问题解决中。此外,ModelScope还汇聚了众多优秀的国产模型资源,为开发者提供了更多的选择,并且鼓励开发者贡献自己的模型,从而促进了国内AI模型的共享和交流。
四、Llama2微调实战
模型:Llama-2
数据集:alpaca-gpt4-data-zh
微调技术:LoRA
使用资源:半精度 fp16(这里是为了减少GPU资源;正常情况默认微调时是全精度32位浮点数)
学术资源加速
方便从huggingface下载模型,这云平台autodl提供的,仅适用于autodl。
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if '=' in line:
var, value = line.split('=', 1)
os.environ[var] = value
步骤1 导入相关包
开始之前,我们需要导入适用于模型训练和推理的必要库,如transformers。
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
步骤2 加载数据集
使用适当的数据加载器,例如datasets库,来加载预处理过的指令遵循性任务数据集。
ds = Dataset.load_from_disk("/root/PEFT代码/tuning/lesson01/data/alpaca_data_zh")
ds
输出:
Dataset({
features: ['output', 'input', 'instruction'],
num_rows: 26858
})
查看数据
ds[:3]
输出:
{ 'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。',
'4/16等于1/4是因为我们可以约分分子分母都除以他们的最大公约数4,得到(4÷4)/ (16÷4)=1/4。分数的约分是用分子和分母除以相同的非零整数,来表示分数的一个相同的值,这因为分数实际上表示了分子除以分母,所以即使两个数同时除以同一个非零整数,分数的值也不会改变。所以4/16 和1/4是两种不同的书写形式,但它们的值相等。',
'朱利叶斯·凯撒,又称尤利乌斯·恺撒(Julius Caesar)是古罗马的政治家、军事家和作家。他于公元前44年3月15日被刺杀。 \n\n根据历史记载,当时罗马元老院里一些参议员联合起来策划了对恺撒的刺杀行动,因为他们担心恺撒的统治将给罗马共和制带来威胁。在公元前44年3月15日(又称“3月的艾达之日”),恺撒去参加元老院会议时,被一群参议员包围并被攻击致死。据记载,他身中23刀,其中一刀最终致命。'],
'input': ['', '输入:4/16', ''],
'instruction': ['保持健康的三个提示。', '解释为什么以下分数等同于1/4', '朱利叶斯·凯撒是如何死亡的?']}
步骤3 数据集预处理
利用预训练模型的分词器(Tokenizer)对原始文本进行编码,并生成相应的输入ID、注意力掩码和标签。
1)获取分词器
#加载本地模型,提前下载到本地
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/Llama-2-7b-ms")
tokenizer
输出:
LlamaTokenizerFast(name_or_path='/root/autodl-tmp/Llama-2-7b-ms', vocab_size=32000, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={ 'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<unk>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={
0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),
1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),
2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),
32000: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=False),
}
2)对齐设置
padding_side模式左对齐,需要修改改为右边对齐
tokenizer.padding_side = "right"
对齐填充设置为结束符的token (eos_token_id)
tokenizer.pad_token_id = 2
3)定义数据处理函数
def process_func(example):
MAX_LENGTH = 400
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ", add_special_tokens=False)
response = tokenizer(example["output"], add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.eos_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.eos_token_id]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
4)对数据进行预处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
输出:
Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 26858
})
5)打印查看inpu_ids
print(tokenized_ds[0]["input_ids"])
输出:
[12968, 29901, 29871, 30982, 31695, 31863, 31577, 30210, 30457, 30502, 31302, 30858, 30267, 13, 13, 7900, 22137, 29901, 29871, 29871, 30651, 30557, 30392, 30982, 31695, 31863, 31577, 30210, 30457, 30502, 31302, 30858, 30383, 13, 13, 29896, 29889, 29871, 30982, 31695, 31687, 30988, 31704, 30846, 30267, 31951, 30408, 232, 132, 157, 236, 131, 133, 30948, 30210, 31687, 30988, 31894, 30846, 30214, 30847, 233, 152, 166, 233, 176, 168, 30330, 235, 186, 148, 233, 176, 168, 31391, 233, 187, 187, 233, 182, 182, 30214, 30815, 231, 194, 134, 31174, 30869, 235, 164, 131, 31624, 31863, 31577, 30214, 232, 165, 161, 232, 191, 189, 235, 133, 143, 235, 133, 140, 31074, 31180, 30214, 31666, 30417, 31931, 30909, 232, 138, 146, 31022, 30988, 30908, 30267, 13, 13, 29906, 29889, 29871, 232, 160, 138, 235, 164, 164, 236, 168, 177, 31855, 30267, 31951, 30408, 31855, 30406, 30374, 236, 181, 159, 30210, 235, 151, 175, 31854, 30330, 30716, 30801, 30330, 30753, 31112, 30834, 30503, 235, 135, 133, 235, 133, 173, 232, 147, 174, 31180, 231, 192, 145, 30210, 235, 158, 142, 30868, 235, 183, 171, 31855, 30834, 30214, 236, 132, 194, 232, 136, 144, 30528, 234, 182, 153, 30330, 30528, 235, 135, 133, 235, 133, 173, 30503, 30666, 31041, 31855, 31399, 30214, 30651, 30982, 31695, 31863, 31577, 30210, 236, 168, 177, 31855, 231, 188, 163, 233, 134, 178, 30267, 13, 13, 29941, 29889, 29871, 234, 160, 164, 234, 159, 163, 232, 136, 136, 31722, 30267, 234, 160, 164, 234, 159, 163, 30783, 30313, 30988, 31863, 31577, 235, 138, 182, 31057, 30908, 30698, 30214, 30494, 30470, 30313, 31951, 30408, 31370, 30982, 235, 178, 132, 29871, 29955, 29899, 29947, 29871, 30446, 30594, 30210, 234, 160, 164, 234, 159, 163, 30267, 31400, 31076, 30210, 234, 160, 164, 234, 159, 163, 30417, 31931, 30909, 232, 138, 146, 235, 192, 190, 232, 145, 142, 31074, 30214, 231, 194, 134, 31174, 31687, 30988, 233, 132, 165, 31810, 30214, 31666, 31302, 30528, 31368, 31474, 31074, 30503, 31410, 232, 194, 137, 31074, 30267, 2]
6)检查数据(是否包含结束符)
tokenizer.decode(list(filter(lambda x: x != -100, tokenized_ds[1]["labels"])))
输出:
'4/16等于1/4是因为我们可以约分分子分母都除以他们的最大公约数4,得到(4÷4)/ (16÷4)=1/4。分数的约分是用分子和分母除以相同的非零整数,来表示分数的一个相同的值,这因为分数实际上表示了分子除以分母,所以即使两个数同时除以同一个非零整数,分数的值也不会改变。所以4/16 和1/4是两种不同的书写形式,但它们的值相等。</s>'
步骤4 创建模型
然后,我们实例化一个预训练模型,这个模型将作为微调的基础。对于大型模型,我们可能还需要进行一些特定的配置,以适应可用的计算资源。(这里设置为半精度torch_dtype=torch.half,)
import torch
model = AutoModelForCausalLM.from_pretrained("/root/autodl-tmp/Llama-2-7b-ms",
low_cpu_mem_usage=True,
torch_dtype=torch.half,
device_map="auto")code>
精度查看
model.dtype
输出:
torch.float16
下面2个部分是LoRA相关的配置。
1、PEFT 步骤1 配置文件
在使用PEFT进行微调时,我们首先需要创建一个配置文件,该文件定义了微调过程中的各种设置,如学习率调度、优化器选择等。
提前安装peft:pip install peft
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(task_type=TaskType.CAUSAL_LM,)
config
输出:
LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, r=8, target_modules=None, lora_alpha=8, lora_dropout=0.0, fan_in_fan_out=False, bias='none', use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={ }, alpha_pattern={ }, megatron_config=None, megatron_core='megatron.core', loftq_config={ }, use_dora=False, layer_replication=None)code>
2、PEFT 步骤2 创建模型
接下来,我们使用PEFT和预训练模型来创建一个微调模型。这个模型将包含原始的预训练模型以及由PEFT引入的低秩参数。
model = get_peft_model(model, config)
config
输出:
LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path='/root/autodl-tmp/Llama-2-7b-ms', revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, r=8, target_modules={ 'q_proj', 'v_proj'}, lora_alpha=8, lora_dropout=0.0, fan_in_fan_out=False, bias='none', use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={ }, alpha_pattern={ }, megatron_config=None, megatron_core='megatron.core', loftq_config={ }, use_dora=False, layer_replication=None)code>
查看模型中可训练参数的数量
model.print_trainable_parameters()#打印出模型中可训练参数的数量
输出:
trainable params: 4,194,304 || all params: 6,742,609,920 || trainable%: 0.06220594176090199
查看模型参数,查看LoRA层添加到哪
for name, param in model.named_parameters():
print(name, param.shape, param.dtype)
输出:
base_model.model.model.embed_tokens.weight torch.Size([32000, 4096]) torch.float16
base_model.model.model.layers.0.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.0.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.0.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.0.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.0.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.0.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.0.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.0.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.0.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.0.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.0.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.0.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.0.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.1.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.1.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.1.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.1.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.1.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.1.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.1.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.1.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.1.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.1.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.1.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.1.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.1.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.2.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.2.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.2.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.2.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.2.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.2.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.2.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.2.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.2.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.2.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.2.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.2.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.2.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.3.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.3.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.3.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.3.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.3.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.3.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.3.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.3.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.3.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.3.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.3.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.3.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.3.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.4.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.4.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.4.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.4.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.4.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.4.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.4.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.4.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.4.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.4.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.4.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.4.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.4.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.5.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.5.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.5.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.5.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.5.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.5.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.5.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.5.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.5.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.5.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.5.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.5.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.5.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.6.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.6.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.6.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.6.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.6.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.6.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.6.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.6.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.6.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.6.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.6.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.6.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.6.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.7.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.7.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.7.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.7.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.7.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.7.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.7.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.7.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.7.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.7.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.7.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.7.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.7.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.8.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.8.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.8.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.8.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.8.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.8.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.8.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.8.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.8.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.8.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.8.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.8.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.8.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.9.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.9.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.9.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.9.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.9.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.9.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.9.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.9.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.9.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.9.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.9.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.9.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.9.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.10.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.10.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.10.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.10.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.10.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.10.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.10.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.10.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.10.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.10.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.10.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.10.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.10.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.11.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.11.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.11.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.11.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.11.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.11.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.11.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.11.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.11.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.11.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.11.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.11.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.11.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.12.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.12.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.12.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.12.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.12.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.12.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.12.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.12.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.12.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.12.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.12.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.12.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.12.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.13.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.13.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.13.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.13.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.13.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.13.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.13.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.13.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.13.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.13.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.13.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.13.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.13.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.14.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.14.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.14.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.14.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.14.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.14.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.14.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.14.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.14.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.14.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.14.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.14.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.14.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.15.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.15.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.15.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.15.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.15.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.15.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.15.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.15.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.15.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.15.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.15.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.15.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.15.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.16.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.16.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.16.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.16.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.16.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.16.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.16.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.16.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.16.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.16.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.16.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.16.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.16.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.17.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.17.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.17.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.17.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.17.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.17.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.17.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.17.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.17.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.17.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.17.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.17.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.17.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.18.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.18.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.18.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.18.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.18.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.18.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.18.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.18.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.18.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.18.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.18.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.18.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.18.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.19.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.19.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.19.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.19.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.19.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.19.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.19.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.19.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.19.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.19.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.19.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.19.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.19.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.20.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.20.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.20.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.20.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.20.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.20.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.20.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.20.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.20.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.20.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.20.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.20.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.20.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.21.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.21.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.21.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.21.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.21.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.21.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.21.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.21.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.21.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.21.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.21.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.21.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.21.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.22.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.22.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.22.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.22.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.22.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.22.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.22.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.22.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.22.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.22.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.22.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.22.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.22.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.23.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.23.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.23.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.23.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.23.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.23.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.23.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.23.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.23.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.23.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.23.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.23.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.23.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.24.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.24.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.24.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.24.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.24.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.24.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.24.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.24.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.24.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.24.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.24.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.24.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.24.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.25.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.25.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.25.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.25.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.25.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.25.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.25.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.25.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.25.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.25.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.25.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.25.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.25.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.26.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.26.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.26.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.26.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.26.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.26.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.26.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.26.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.26.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.26.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.26.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.26.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.26.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.27.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.27.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.27.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.27.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.27.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.27.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.27.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.27.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.27.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.27.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.27.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.27.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.27.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.28.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.28.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.28.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.28.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.28.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.28.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.28.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.28.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.28.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.28.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.28.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.28.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.28.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.29.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.29.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.29.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.29.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.29.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.29.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.29.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.29.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.29.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.29.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.29.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.29.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.29.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.30.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.30.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.30.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.30.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.30.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.30.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.30.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.30.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.30.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.30.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.30.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.30.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.30.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.31.self_attn.q_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.31.self_attn.q_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.31.self_attn.q_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.31.self_attn.k_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.31.self_attn.v_proj.base_layer.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.31.self_attn.v_proj.lora_A.default.weight torch.Size([8, 4096]) torch.float16
base_model.model.model.layers.31.self_attn.v_proj.lora_B.default.weight torch.Size([4096, 8]) torch.float16
base_model.model.model.layers.31.self_attn.o_proj.weight torch.Size([4096, 4096]) torch.float16
base_model.model.model.layers.31.mlp.gate_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.31.mlp.up_proj.weight torch.Size([11008, 4096]) torch.float16
base_model.model.model.layers.31.mlp.down_proj.weight torch.Size([4096, 11008]) torch.float16
base_model.model.model.layers.31.input_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.layers.31.post_attention_layernorm.weight torch.Size([4096]) torch.float16
base_model.model.model.norm.weight torch.Size([4096]) torch.float16
base_model.model.lm_head.weight torch.Size([32000, 4096]) torch.float16
步骤5 配置训练参数
在这一步,我们定义训练参数,这些参数包括输出目录、学习率、权重衰减、梯度累积步数、训练周期数等。这些参数将被用来配置训练过程。(设置adam_epsilon=1e-4避免精度溢出)
## adam_epsilon=1e-4
args = TrainingArguments(
output_dir="/root/autodl-tmp/llama2output", # 指定模型训练结果的输出目录code>
per_device_train_batch_size=2,# 设置每个设备(如GPU)在训练过程中的批次大小为2,越大需要资源也越多
gradient_accumulation_steps=8,# 指定梯度累积步数为8,即将多个批次的梯度累加后再进行一次参数更新
logging_steps=10,# 每10个步骤记录一次日志信息
num_train_epochs=1,# 指定训练的总轮数为1
adam_epsilon=1e-4 #避免精度溢出
)
步骤6 创建训练器
最后,我们创建一个训练器实例,它封装了训练循环。训练器将负责运行训练过程,并根据我们之前定义的参数进行优化。
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
步骤7 模型训练
通过调用训练器的train()方法,我们启动模型的训练过程。这将根据之前定义的参数执行模型的训练。
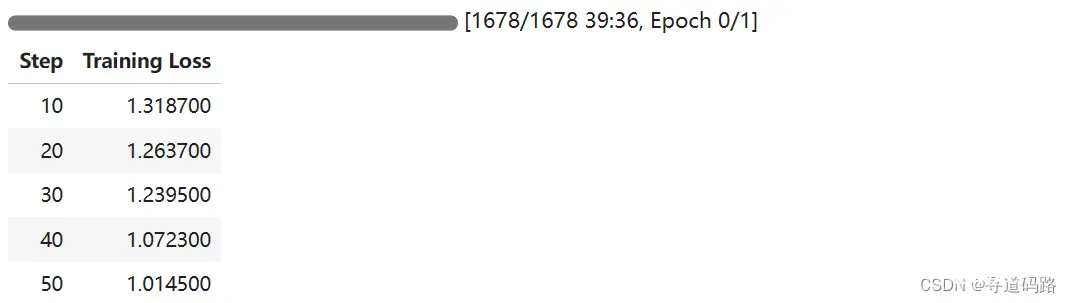
trainer.train()
输出:
步骤8 模型推理
训练完成后,我们可以使用训练好的模型进行推理。
<code>from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
ipt = "Human: {}\n{}".format("如何写简历?", "").strip() + "\n\nAssistant: "
print(pipe(ipt, max_length=256, do_sample=True, ))
输出:
[{ 'generated_text': 'Human: 如何写简历?\n\nAssistant: 写简历的方法主要有两个步骤:\n\n1. 首先,您需要确定您想要投递的职位和企业。根据您的职业目标和职位要求,准备您想要展示的职业经历和技能。\n\n2. 然后,根据您的职业目标和职位要求,您需要撰写简历的内容。您的简历应该包含您的个人信息、职业经历、技能和职能、成就和荣誉、职业目标和职业信念。您的简历应该简明'}]
五、Llama2 调试过程问题整理
1、MAX_LENGTH设置:
对数据集预处理时,为了批处理,我们会设置一个MAX_LENGTH; llama对中文支持不是很好,一个中文会用4个token表示,所以MAX_LENGTH要条长一点,原来256现在改为400,否则会缺很多数据
2、对齐设置
对齐设置:tokenizer.padding_side = “right”
需要调整模型向右补齐(默认向左补齐),否则会导致训练时,无法收敛;
3、设置pad_token_id
设置pad_token_id为eos_token_id(即Llama批处理时,根据MAX_LENGTH对齐不足时,补充结束符进行对齐)
tokenizer.pad_token_id = 2 #2代表结束符的token,可以查看tokenizer(tokenizer.eos_token),不设置也会导致无法收敛
4、结束符设置
分词器处理时,不添加结束符;因为这里会添加不成功,可以对比查看tokenizer(tokenizer.eos_token) 和 tokenizer(“abc” + tokenizer.eos_token) 会发现没有添加成功,因此就需要手工添加结束符;手动对input_id,attention_mask、labels 设置结束符 tokenizer.eos_token_id (代表);
不处理会导致回答问题时,无法识别停止符,一直不会结束
修改前
def process_func(example):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
response = tokenizer(example["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
修改后
def process_func(example):
MAX_LENGTH = 400
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ", add_special_tokens=False)
response = tokenizer(example["output"], add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.eos_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.eos_token_id]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
5、设置 adam_epsilon
训练参数设置时,设置 adam_epsilon=1e-4 (默认全精度不需要设置,它的值为1e-8;采用半精度时,如果不设置,会出现精度溢出,导致adam_epsilon被四舍五入成0);如果不设置,会导致训练时无法正常收敛
#默认全精度
#import torch
#torch.tensor(1e-8)
#输出:tensor(1.0000e-08)
#使用半精度后:torch.tensor(1e-8).half()
#输出:tensor(0., dtype=torch.float16) #此时会被四舍五入成0
args = TrainingArguments(
output_dir="/root/autodl-tmp/llama2output",code>
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
logging_steps=10,
num_train_epochs=1,
adam_epsilon=1e-4
)
总结
本文详细阐述了如何通过LoRA技术微调Llama2大型预训练语言模型,使其更好地适应特定的自然语言处理任务。我们首先介绍了Llama2模型及其在AI领域的重要性,然后讨论了微调前的准备工作,如数据收集和模型选择。接着,我们逐步解释了微调的实战步骤,包括数据处理、模型创建、参数配置、训练以及推理。
在调试过程中,我们强调了针对中文数据处理的MAX_LENGTH设置、对齐方式、结束符设置和训练参数优化等关键问题。这些调整确保了模型的有效收敛和性能提升。
展望未来,随着Llama模型和LoRA技术的不断进步,我们可以期待更多高效、灵活的微调方法出现,特别是对非英语语言的优化将是研究的重点,以支持全球化的NLP应用发展。本文提供的指导和最佳实践,将助力读者为特定应用场景定制高性能的NLP模型,推动学术研究和工业应用的进步。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。