华为云发布EMS弹性内存存储服务,打破AI内存墙
华为云开发者联盟 2024-07-27 10:01:03 阅读 70
6月21日,在华为开发者大会2024上,华为云CTO张宇昕以“AI Native的华为云,系统创新 X 服务重塑,赋能万千开发者”为主题发表演讲,全面介绍了华为云如何通过“为AI” 进行全栈系统性创新,同时“用AI”重塑系列云服务,从而打造AI Native的云。并正式发布了华为云存储重磅新品EMS弹性内存存储服务。
张宇昕表示,目前AI业界普遍认为显存容量和带宽不足已经成为限制AI训练和推理过程中算力发挥的关键障碍,这就是业界常说的AI内存墙难题。华为云为解决该难题,首创EMS弹性内存存储服务,在NPU计算层和持久化存储层的两层架构之间增加弹性内存存储层,成功打破AI内存墙,实现显存按需扩展。目前EMS弹性内存存储服务已经在华为内部IT系统和多个行业核心业务系统得到应用。

华为云CTO张宇昕
据相关统计数据,显存容量增长速度远远落后于大模型存储需求的增长速度。如下图所示,典型的Transformer大模型的参数量每两年以240倍的速度增长,而业界典型的AI NPU卡的显存容量仅每两年翻两倍。这种大模型参数量与AI NPU卡显存容量增长速度之间的巨大差距,意味着在训练和推理时客户往往不得不采用堆砌AI NPU卡数量的方式获得更大的显存容量,这将造成大量昂贵AI算力的浪费,增加了客户的AI训练和推理的成本。
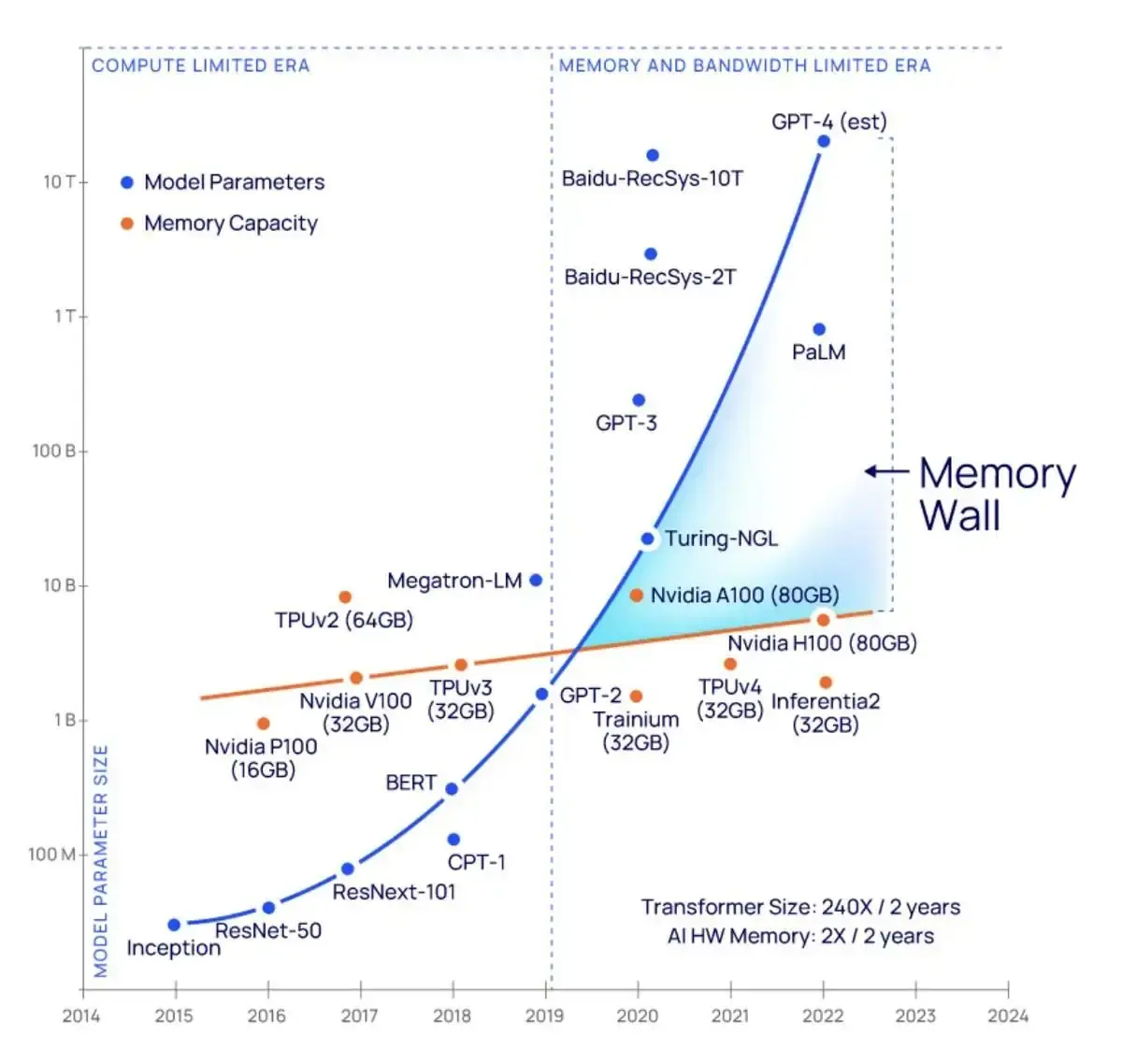
SOTA模型的参数量增长趋势和AI硬件显存容量增长趋势
本次华为云发布的EMS弹性内存存储服务,基于Memory Pooling专利技术,将显存与DRAM进行池化和整合,把传统的云基础设施“计算-存储”分离池化的两层架构升级为“计算-内存-存储”分离池化的三层架构。AI算力和内存(显存+DRAM)进行了解耦,实现了“显存扩展”、“算力卸载”、“以存代算”三大功能来打破AI内存墙。

大模型训练通常采用参数并行,将模型参数分别存到多张卡的显存中。在使用EMS后,通过“显存扩展”功能我们将模型参数进行分层存储,频繁更新的参数存储在显存中,不频繁更新的参数存储在EMS中,这样就不再需要依赖增加AI加速卡来堆砌显存容量了。华为云只用了不到一半的NPU卡就存下了盘古大模型5.0,NPU部署数量降低了50%。
大模型推理过程包括模型计算和KV相关的计算,其中模型计算显存占用较小,但是算力需求却很高。与之相反,KV相关计算的显存占用很大,AI算力需求却并不高。这两种计算过程对算力和显存容量的不同需求造成AI NPU卡不能很好地发挥性能。
例如,华为的一款NPU卡在运行大模型推理时本来只能支持8个并发。我们将KV相关计算任务卸载到EMS中,而模型计算仍在NPU中进行。单卡的并发提升到了16个,AI推理性能提升100%。
最后是以存代算。大模型推理中为了节省显存,历史对话的KV计算结果都不会保存,后续推理都只能重新计算KV,导致新推理请求的首Token时延超过1秒,影响了推理体验。现在,通过EMS对显存进行扩展后,我们可以将历史KV计算结果保存在EMS中,供后续推理直接调用。优化后推理首Token时延降低到0.2秒以内,降低了80%。
EMS弹性内存存储是业界云厂商中首个在实际场景中得到使用的内存存储服务,通过Memory Pooling专利技术实现了“显存扩展”、“算力卸载”、“以存代算”三大功能来打破内存墙。不仅如此,面向整个AI场景,华为云还形成了EMS弹性内存存储+SFS Turbo弹性文件存储+OBS对象存储的AI-Native智算存储解决方案,实现万亿模型存的下,训练任务恢复快,海量数据存的起,全面引领AI时代数据存储变革,帮助客户构建AI Native的基础设施。
点击关注,第一时间了解华为云新鲜技术~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。