人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法
汀、人工智能 2024-07-03 13:01:04 阅读 99
人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法
1.SFT 监督微调
1.1 SFT 监督微调基本概念
SFT(Supervised Fine-Tuning)监督微调是指在源数据集上预训练一个神经网络模型,即源模型。然后创建一个新的神经网络模型,即目标模型。目标模型复制了源模型上除了输出层外的所有模型设计及其参数。这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。源模型的输出层与源数据集的标签紧密相关,因此在目标模型中不予采用。微调时,为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。在目标数据集上训练目标模型时,将从头训练到输出层,其余层的参数都基于源模型的参数微调得到。
1.2 监督微调的步骤
具体来说,监督式微调包括以下几个步骤:
预训练 首先在一个大规模的数据集上训练一个深度学习模型,例如使用自监督学习或者无监督学习算法进行预训练;微调 使用目标任务的训练集对预训练模型进行微调。通常,只有预训练模型中的一部分层被微调,例如只微调模型的最后几层或者某些中间层。在微调过程中,通过反向传播算法对模型进行优化,使得模型在目标任务上表现更好;评估 使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标。
1.3 监督微调的特点
监督式微调能够利用预训练模型的参数和结构,避免从头开始训练模型,从而加速模型的训练过程,并且能够提高模型在目标任务上的表现。监督式微调在计算机视觉、自然语言处理等领域中得到了广泛应用。然而监督也存在一些缺点。首先,需要大量的标注数据用于目标任务的微调,如果标注数据不足,可能会导致微调后的模型表现不佳。其次,由于预训练模型的参数和结构对微调后的模型性能有很大影响,因此选择合适的预训练模型也很重要。
1.4 常见案例
样例 1
在计算机视觉中,低层的网络主要学习图像的边缘或色斑,中层的网络主要学习物体的局部和纹理,高层的网络识别抽象的语义,如下图所示。因此,可以把一个神经网络分成两块:
低层的网络进行特征抽取,将原始信息变成容易被后面任务使用的特征;
输出层的网络进行具体任务的预测。输出层因为涉及到具体任务没办法在不同任务中复用,但是低层的网络是具有通用型的,可以应用到其他任务上。

下图表示的是将预训练模型的前 L-1 层的参数复制到微调模型,而微调模型的输出层参数随机初始化。在训练过程中,通过设置很小的学习率,从而达到微调的目的。
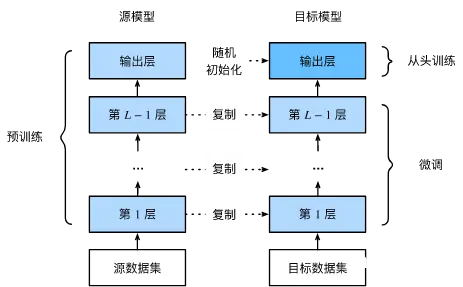
样例 2
BERT 模型是 Google AI 研究院提出的一种预训练模型,通过预训练 + 微调的方式于多个 NLP 下游任务达到当时最先进水平,如实体识别、文本匹配、阅读理解等。与样例 1 一样,BERT 模型微调时,将预训练好的模型参数复制到微调模型,而输出层参数随机初始化。
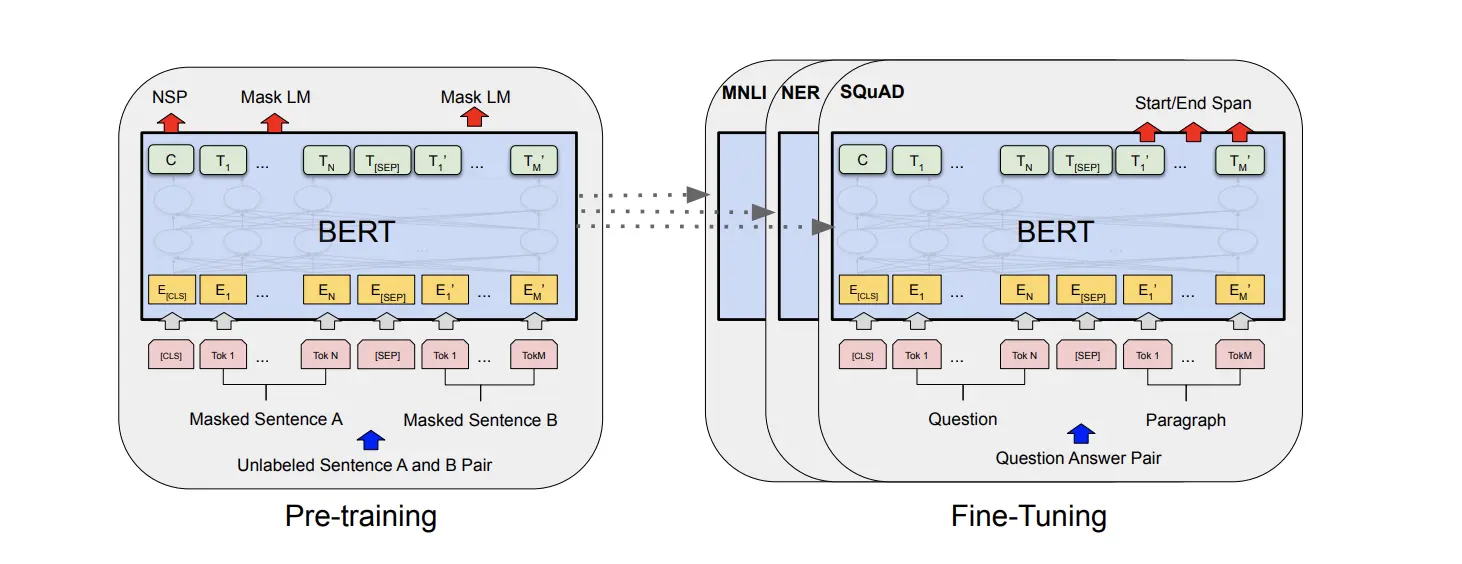
1.5 SFT 监督微调的主流方法
随着技术的发展,涌现出越来越多的大语言模型,且模型参数越来越多,比如 GPT3 已经达到 1750 亿的参数量,传统的监督微调方法已经不再能适用现阶段的大语言模型。为了解决微调参数量太多的问题,同时也要保证微调效果,急需研发出参数高效的微调方法(Parameter Efficient Fine Tuning, PEFT)。目前,已经涌现出不少参数高效的微调方法,其中主流的方法包括:
LoRAP-tuning v2Freeze
2. LoRA 微调方法
2.1 LoRA 微调方法的基本概念
LoRA(Low-Rank Adaptation of Large Language Models),直译为大语言模型的低阶自适应。LoRA 的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型参数参与微调类似的效果。
随着大语言模型的发展,模型的参数量越来越大,比如 GPT-3 参数量已经高达 1750 亿,因此,微调所有模型参数变得不可行。LoRA 微调方法由微软提出,通过只微调新增参数的方式,大大减少了下游任务的可训练参数数量。
2.2 LoRA 微调方法的基本原理
神经网络的每一层都包含矩阵的乘法。这些层中的权重矩阵通常具有满秩。当适应特定任务时,预训练语言模型具有低的 “内在维度”,将它们随机投影到更小的子空间时,它们仍然可以有效地学习。
在大语言模型微调的过程中,LoRA 冻结了预先训练好的模型权重,并将<code>可训练的秩的分解矩阵注入到 Transformer 体系结构的每一层。例如,对于预训练的权重矩阵W0,可以让其更新受到用低秩分解表示后者的约束:
W
0
+
△
W
=
W
0
+
B
A
W0+△W=W0+BA
W0+△W=W0+BA
其中:
W
0
∈
R
d
×
k
,
B
∈
R
d
×
r
,
A
∈
R
r
×
k
W0∈Rd×k,B∈Rd×r,A∈Rr×k
W0∈Rd×k,B∈Rd×r,A∈Rr×k
而且,秩r≪min(d,k),
此时,修正后的正向传播计算公式就变成:
h
=
W
0
x
+
△
W
x
=
W
0
x
+
B
A
x
h=W0x+△Wx=W0x+BAx
h=W0x+△Wx=W0x+BAx
在模型微调时,W0被冻结,不接受梯度更新,只微调参数A和B。与所有参数参与模型微调相比,此时该步骤模型微调的参数量由d×k变成d×r+r×k,而r≪min(d,k),因此微调参数量大量减少了。
如下图所示,LoRA 微调时,对A使用随机高斯初始化,对B使用零初始化,因此ΔW=BA在训练开始时为零。
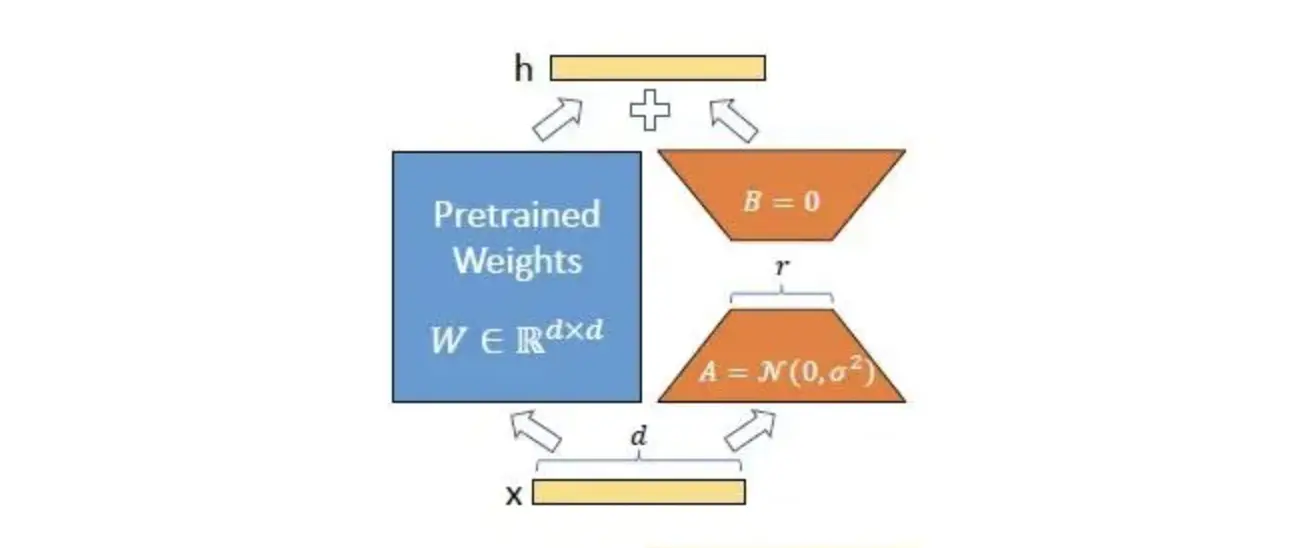
对 Transformer 的每一层结构都采用 LoRA 微调的方式,最终可以使得模型微调参数量大大减少。当部署到生产环境中时,只需要计算和存储<code>W=W0+BA,并像往常一样执行推理。与其它方法相比,没有额外的延迟,因为不需要附加更多的层。
在 Transformer 体系结构中,自注意力机制模块中有四个权重矩阵 (Wq、Wk、Wv、Wo), MLP 模块中有两个权重矩阵。LoRA 在下游任务微调时,只调整自注意力机制模块的权重,并冻结 MLP 模块。所以对于大型 Transformer,使用 LoRA 可减少高达 2/3 的显存(VRAM)使用量。比如在 GPT-3 175B 上,使用 LoRA 可以将训练期间的 VRAM 消耗从 1.2TB 减少到 350GB。
2.3 LoRA 微调方法的主要优势
预训练模型参数可以被共享,用于为不同的任务构建许多小的 LoRA 模块。冻结共享模型,并通过替换矩阵 A 和 B 可以有效地切换任务,从而显著降低存储需求和多个任务切换的成本。
当使用自适应优化器时,由于不需要计算梯度以及保存太多模型参数,LoRA 使得微调效果更好,并将微调的硬件门槛降低了 3 倍。
低秩分解采用线性设计的方式使得在部署时能够将可训练的参数矩阵与冻结的参数矩阵合并,与完全微调的方法相比,不引入推理延迟。
LoRA 与其它多种微调方法不冲突,可以与其它微调方法相结合,比如下节实训将要介绍的前缀调优方法等。
3. P-tuning v2 微调方法
3.1 P-tuning v2 微调方法的相关技术
传统的微调方法需要微调整个预训练语言模型,对于大语言模型的微调需要大量的资源和时间,急需更加高效的微调方法。理解 P-tuning v2 微调方法,首先需要了解 prefix-tuning 微调方法和 P-tuning v1 微调方法。
3.1.1 Prefix-tuning 微调方法
Prefix-tuning 微调方法在模型中加入 prefix,即连续的特定任务向量,微调时只优化这一小段参数。对于条件生成任务,如下图所示,其输入是文本x,输出是序列y。
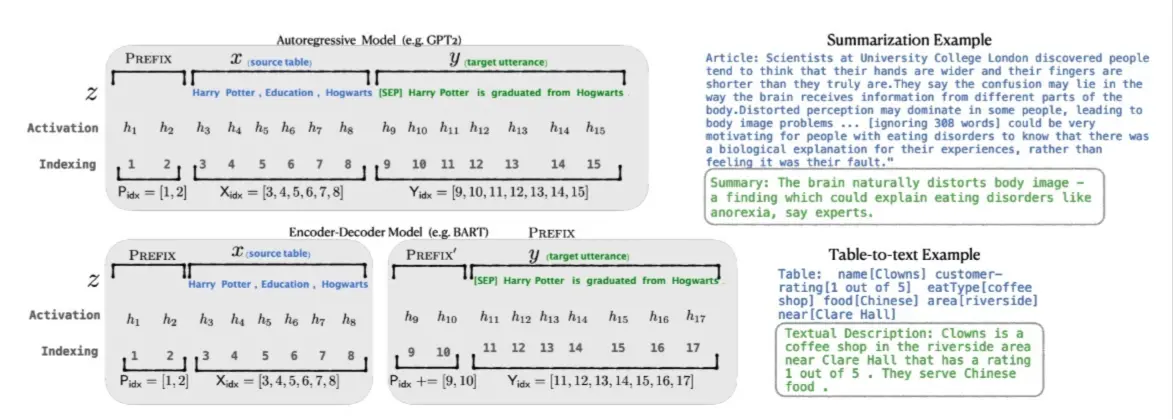
在上图中,<code>z=[x;y]是x和y的拼接,Xidx和Yidx表示序列的索引,hi∈Rd表示每个时刻i下的激活值,hi=[hi(1);...;hi(n)]表示当前时刻所有层输出向量的拼接,hi(j)是时刻i的第j层 Transformer 的输出,于是自回归语言模型计算每一时刻的输出hi即:
h
i
=
L
M
ϕ
(
z
i
,
h
<
i
)
hi=LMϕ(zi,h<i)
hi=LMϕ(zi,h<i)
hi的最后一层用来计算下一个词的分布:
p
ϕ
(
z
i
+
1
∣
h
≤
i
)
=
s
o
f
t
m
a
x
(
W
ϕ
h
i
(
n
)
)
pϕ(zi+1∣h≤i)=softmax(Wϕhi(n))
pϕ(zi+1∣h≤i)=softmax(Wϕhi(n))
其中ϕ是语言模型的参数。在自回归语言模型前添加 prefix 后,z=[PREFIX;x;y]或者z=[PREFIX;x;PREFIX;y],Pidx表示 prefix 的索引,|Pidx|表示 prefix 的长度。Prefix-tuning 通过初始化可训练矩阵Pθ(维度为∣Pidx×dim(hi)∣) 来存储 prefix 参数:
KaTeX parse error: Expected '}', got 'EOF' at end of input: …<i),otherwise
训练对象与 Fine-tuning 相同,但语言模型的参数ϕ固定,仅 prefix 参数θ是可训练的参数。因此hi是可训练的Pθ的函数。
3.1.2 P-tuning v1 微调方法
P-tuning v1 微调方法是将 Prompt 加入到微调过程中,只对 Prompt 部分的参数进行训练,而语言模型的参数固定不变。如下图所示:
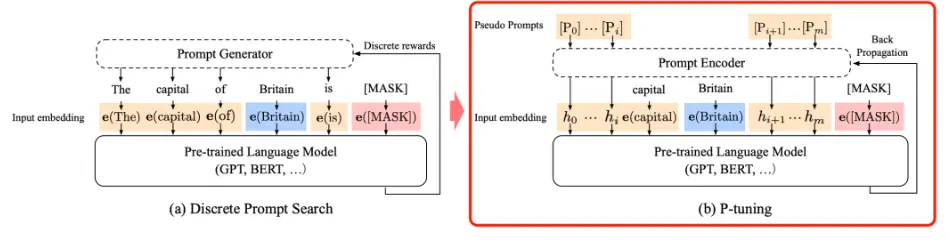
P-tuning v1 设计一个自动的生成连续 prompt 的方法来提升模型的微调效果。由上图,P-tuning v1 的模版可以用下面公式表示:
h
0
,
.
.
.
,
h
i
,
e
(
x
)
,
h
i
+
1
,
.
.
.
,
h
m
,
e
(
y
)
{h0,...,hi,e(x),hi+1,...,hm,e(y)}
h0,...,hi,e(x),hi+1,...,hm,e(y)
其中<code>h代表 P-tuning v1 的连续 prompt 表征,e代表一个预训练的语言模型,x代表数据的原始输入,y代表数据的标签。在面对下游任务微调是,通过优化h的参数来进行模型微调:
h
0
:
m
=
a
r
g
h
m
i
n
L
(
M
(
x
,
y
)
)
h^0:m=arghminL(M(x,y))
h0:m=arghminL(M(x,y))
3.1.3 存在不足
P-tuning v1 微调方法缺少普遍性。实验表明,当模型规模超过 100 亿个参数时,P-tuning v1 可以与全参数微调方法相媲美,但对于那些较小的模型,P-tuning v1 方法和全参数微调方法的表现有很大差异,效果很差。同时,P-tuning v1 缺少跨任务的通用性,在序列标注任务中的有效性没有得到验证。序列标注需要预测一连串的标签,而且大都是无实际意义的标签,对于 P-tuning v1 微调方法极具挑战。此外,当模型层数很深时,微调时模型的稳定性难以保证。模型层数越深,第一层输入的 prompt 对后面的影响难以预估。
3.2 P-tuning v2 微调方法的原理
P-tuning v2 微调方法是 P-tuning v1 微调方法的改进版,同时借鉴了 prefix-tuning 微调的方法。如下图所示:

与 P-tuning v1 微调方法相比,P-tuning v2 微调方法采用了 prefix-tuning 的做法,在输入前面的每一层都加入可微调的参数。在 prefix 部分,每一层的 transformer 的 embedding 输入都需要被微调,而 P-tuning v1 只在第一层进行微调。同时,对于 prefix 部分,每一层 transformer 的输入不是从上一层输出,而是随机初始化的 embedding 作为输入。
此外,P-Tuning v2 还包括以下改进:
移除 Reparamerization 加速训练方式;采用多任务学习优化:基于多任务数据集的 Prompt 进行预训练,然后再适配的下游任务。舍弃词汇 Mapping 的 Verbalizer 的使用,重新利用 [CLS] 和字符标签,跟传统微调方法一样利用 cls 或者 token 的输出做自然语言理解,以增强通用性,可以适配到序列标注任务。
3.3 P-tuning v2 微调方法优点
P-tuning v2 微调方法解决了 P-tuning v1 方法的缺陷,是一种参数高效的大语言模型微调方法。
P-tuning v2 微调方法仅精调 0.1% 参数量(固定 LM 参数),在各个参数规模语言模型上,均取得和 Fine-tuning 相比肩的性能,解决了 P-tuning v1 在参数量不够多的模型中微调效果很差的问题。如下图所示(横坐标表示模型参数量,纵坐标表示微调效果):
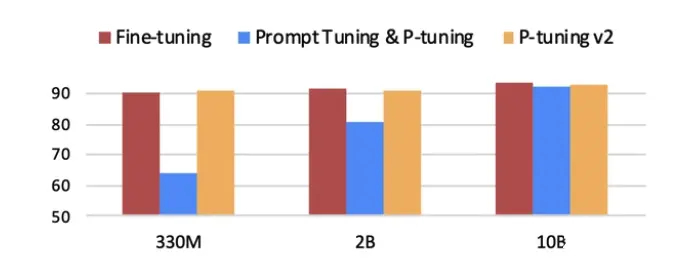
将 Prompt tuning 技术首次拓展至序列标注等复杂的 NLU 任务上,而 P-tuning v1 在此任务上无法运作。
4. Freeze 监督微调方法
4.1 Freeze 微调方法的概念
Freeze 方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行 TP 或 PP 操作,就可以对大模型进行训练。在语言模型模型微调中,Freeze 微调方法仅微调 Transformer 后几层的全连接层参数,而冻结其它所有参数。
4.2 Freeze 微调方法的原理
Freeze 微调方法为什么只微调 Transformer 后几层的全连接层参数呢?下面对其原因进行展开讲述。
Transformer 模型主要由自注意力层和全连接层(FF 层)构成。对于 Transformer 的每一层结构,自注意力层的参数量为<code>4⋅d2,即WQ、WQ、WQ和WQ ∈Rd×d;FF 层的参数量为8⋅d2,即W1∈Rd×4d,W2∈Rd×4d。因此 FF 层占据了模型的32的参数,具有重要的研究价值。Transformer 的全连接层网络结构图如下图所示:
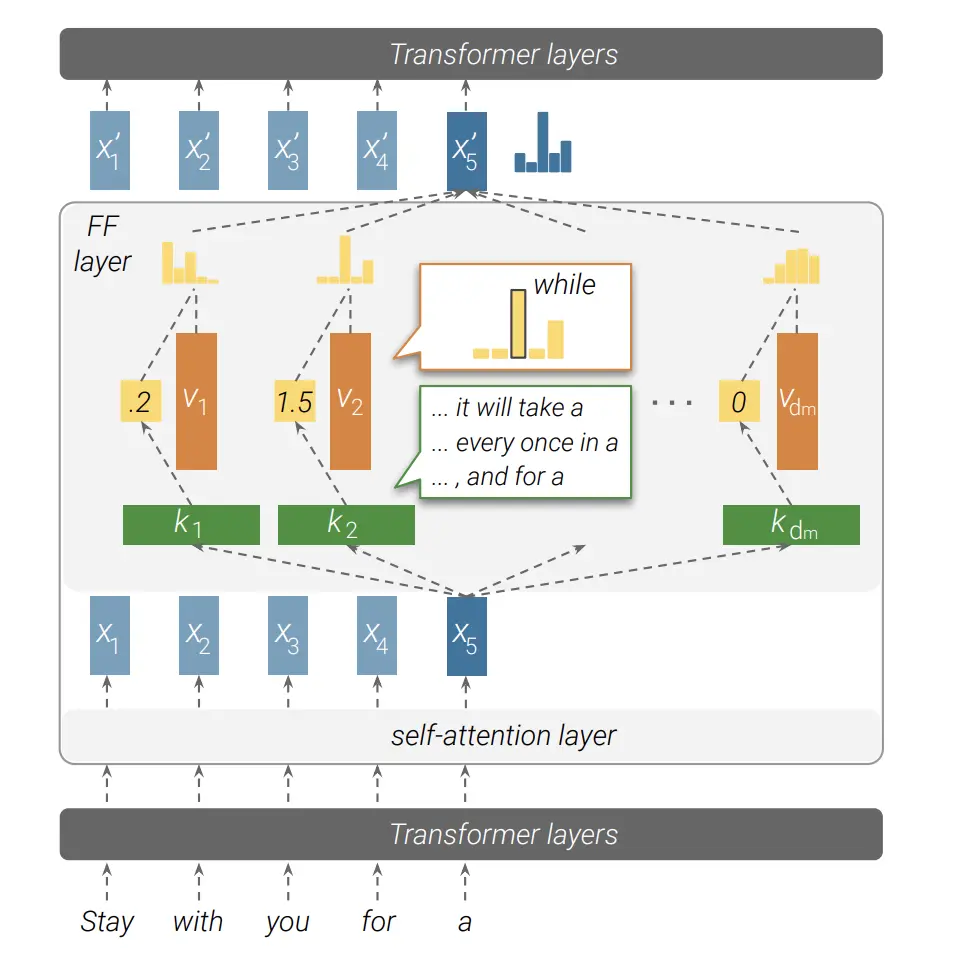
Transformer 的 FF 层可以视为一个 key-value memory,其中每一层的 key 用于捕获输入序列的特征,value 可以基于 key 捕获的特征,给出下一个 token 的词表分布。Transformer 每一层的 FF 层是由多个 key-value 组合而成,然后结合残差连接对每层结果细化,最终产生模型的预测结果。FF 层的公式可以表示为:
F
F
(
x
)
=
f
(
x
⋅
K
T
)
⋅
V
FF(x)=f(x⋅KT)⋅V
FF(x)=f(x⋅KT)⋅V
其中<code>K,V∈Rdm×d是可训练的参数矩阵,f是非线性激活函数,如 ReLU。
此外,实验表明,Transformer 的浅层倾向于提取出浅层特征,深层倾向于提取语义特征,如下图所示。层数越深提取的语义特征所占的比例越重。
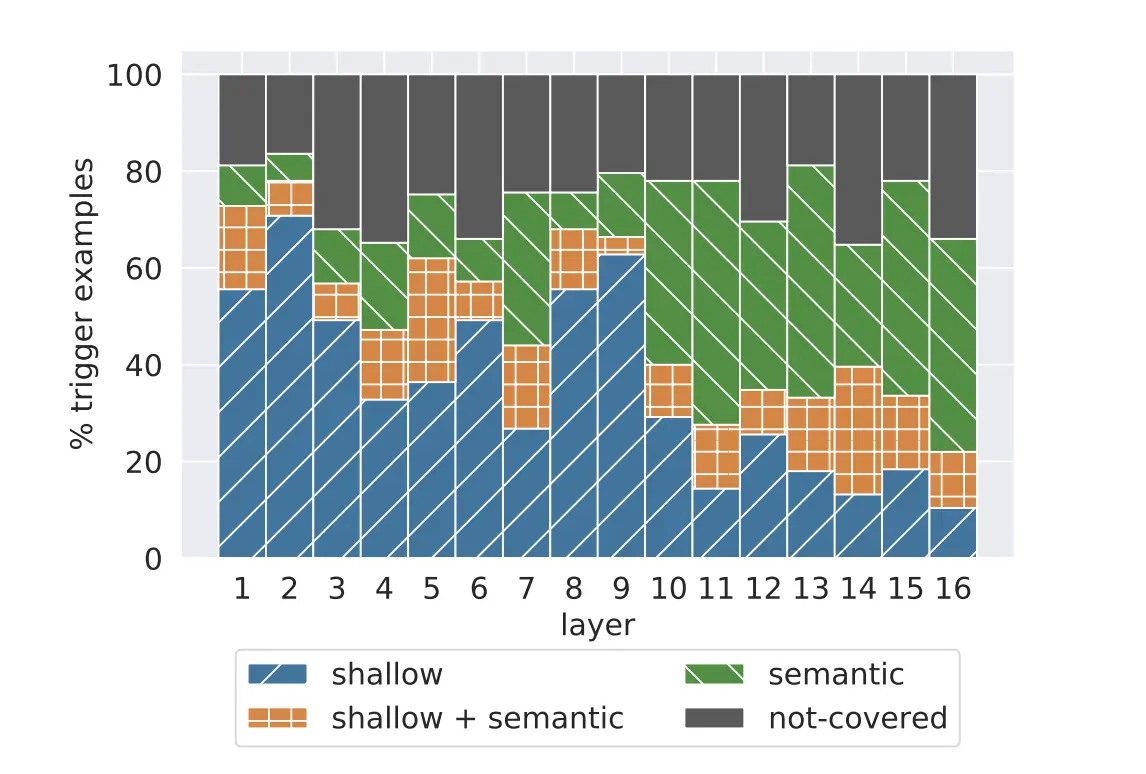
对于各类不同的 NLP 任务,浅层特征往往是具有 “共性”,而主要区别在于各自深层次的语义特征。因此,通过仅微调 Transformer 后几层的全连接层参数,在保证参数高效微调的前提下,可以最大程度的发挥大语言模型的微调作用。
4.3 Freeze 微调方法的优势
大量减少了大语言模型的微调参数,是一种参数高效的微调方法;由于只需微调高层特征,加快了模型的收敛,节约了微调的时间;最大程度地保留了大语言模型预训练所学习到的语言的 “共性”,可解释性较强。
5.关键知识点总结
SFT监督微调时监督微调时,学习率通常会设置得很小
常见误区:1.监督微调需要大量的训练时间和数据 2.监督微调将复制源模型的所有参数至目标模型 3.监督微调只需要几十条监督数据即可
监督微调常见任务:1.用中文预训练BERT模型完成中文实体识别任务 2.训练语言模型GPT3 3.UIE模型在垂直领域的数据集上微调
常见误区:在ImageNet上的预训练的模型再来训练目标检测任务 (则不是)
目前,主流的SFT监督方法包括:LoRA、P-tuning v2、Freeze
LoRA微调方法预训练的模型参数不参与微调,LoRA微调方法一般会在各层新增参数,LoRA微调方法的核心思想是利用<code>高阶矩阵秩的分解来减少微调参数量
LoRA微调方法的优势:减少大语言预训练模型微调的参数量、节省成本、能取得与全模型微调类似的效果
LoRA微调方法不会 对Transformer的每个权重矩阵采用秩分解。
P-tuning v2微调方法是在P-tuning v1的基础上引入了prefix-tuning的思想
常见误区:1.P-tuning v1微调方法能微调实体识别的任务、2.P-tuning v1微调方法在效果上可以媲美全参数微调的方式 3.P-tuning v2微调方法在自然语言理解任务上表现不佳
P-tuning v2微调方法原理方面:1.P-tuning v2微调方法在transformer的每一层都加入了prefix、2.P-tuning v2微调方法采用了多任务学习、3.P-tuning v2微调方法prefix部分的参数不是由上一层的prefix输出来输入
常见误区:P-tuning v2微调方法微调的参数对象是每一层离散表示的prefix
P-tuning v2微调方法解决了P-tuning v1微调方法中序列标注任务不佳、普遍性很差等问题。
Freeze微调优点:1.Freeze微调方法是一种参数高效的微调方法 2.大语言模型的后几层网络主要提取的是语义特征,前几层主要提取的是文本的表层特征 3.Transformer的全连接层参数量多于自注意力层参数量
refix输出来输入
常见误区:P-tuning v2微调方法微调的参数对象是每一层离散表示的prefix
P-tuning v2微调方法解决了P-tuning v1微调方法中序列标注任务不佳、普遍性很差等问题。
Freeze微调优点:1.Freeze微调方法是一种参数高效的微调方法 2.大语言模型的后几层网络主要提取的是语义特征,前几层主要提取的是文本的表层特征 3.Transformer的全连接层参数量多于自注意力层参数量

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。