在处理复杂数据时,可以通过引入,让模型根据输入数据的特点动态调整关注点,聚焦最关键的信息,来提高模型的处理能力和效率。这种比传统方法更高效、灵活的技术足以应对各种复杂任务和挑战,具有强大的适应性,因此它的应用范围非...

本文介绍了如何将TripletAttention注意力机制集成到YOLOv8中,并详细讲解了集成的原理、实现步骤、代码示例以及模型部署与应用的细节。通过引入TripletAttention机制,我们能够显著提升YOLOv8在目标检测任务...

Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点注意力机制其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的...

YOLOv10专栏持续复现网络上各种顶会内容,同时专栏内容可以用于YOLOv8改进~,欢迎大家订阅!!!_yolov10bifpn...

通过这种方式,SELA可以更好地捕捉到图像中细粒度的局部信息,增强了对局部特征的敏感度。到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机...
神经网络训练不起来怎么办(5):批次标准化(BatchNormalization)简介_哔哩哔哩_bilibiliTask3:《深度学习详解》-3.7批量归一化-**产生不好训练的误差表面的原因**:输入特征不同维度的值范围差距大可能导致误差表面不...
编码器部分:由N个编码器层堆叠而成,每个编码器层由两个子层连接结构组成,第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接,第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接�...

摘自知乎博主作者:月来客栈首先让我们先一起来看看作者当时为什么要提出Transformer这个模型?需要解决什么样的问题?现在的模型有什么样的缺陷?现在主流的序列模型都是基于复杂的循环神经网络或者是构造而来的Enc...
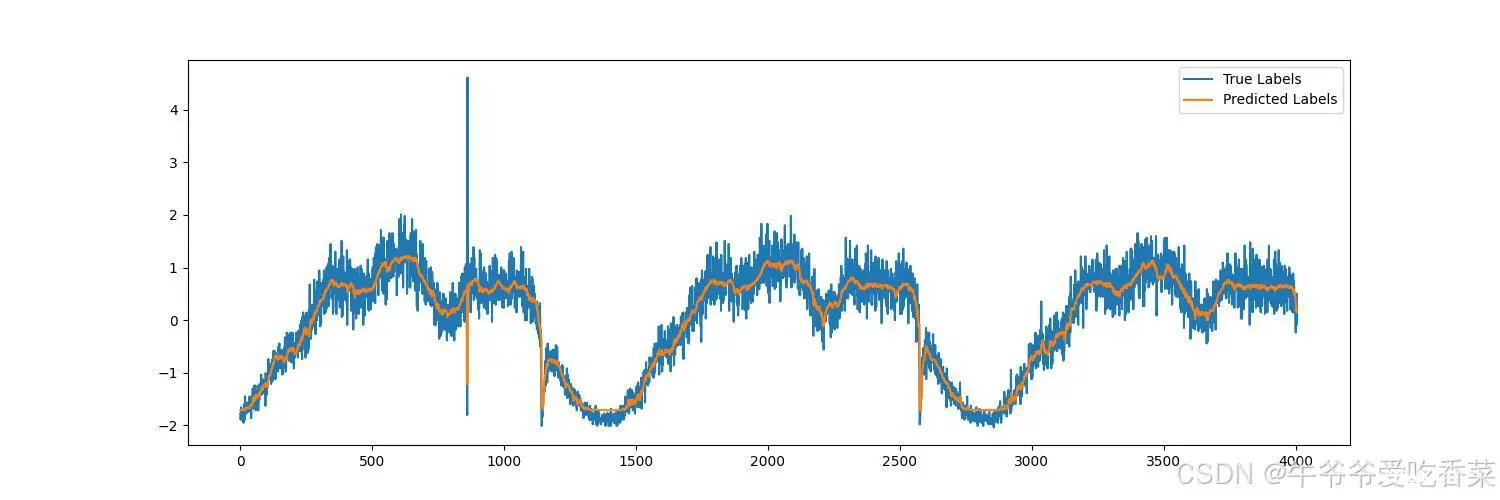
本文讲述了注意力机制在出租车客流预测方面的作用,详细介绍了模型代码结构以及模型的调参过程,可以很好的理解模型结构。_cnn+lstm实例...

LSKAttention是一种基于大核卷积的注意力机制,通过引入不同尺寸的卷积核来捕获图像中的多尺度特征信息。多尺度信息捕捉:通过大核卷积的感受野,能够有效捕捉目标物体的多尺度特征信息。增强全局特征:相比于小卷积核,大卷积核能够更好地捕...