Self-Attention 自注意力机制(一)——Attention 注意力机制
qiaoxinyu10623 2024-09-09 11:31:01 阅读 98
声明:本文章是根据网上资料,加上自己整理和理解而成,仅为记录自己学习的点点滴滴。可能有错误,欢迎大家指正。
1. 什么是注意力机制
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。

注意力机制其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的处理能力,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
图1可帮助大家较好地去理解注意力机制。Attention map展示了人类在看到一幅图像时,如何高效分配有限注意力资源。其中颜色更深的区域,如红色区域表明视觉系统更加关注的目标。从图中可以看出:人们首先会注意到动物的脸部,从而初步判断这可能是一只狼。

图1: 注意力示例图
上面所说的,我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
2. AI领域的Attention 机制
通俗的讲:注意力对于人来说可理解为“关注度”,对没有感情的机器来说其实就是赋予多少权重(比如0-1之间的小数),越重要的地方或者越相关的地方就赋予越高的权重。注意力机制从本质上讲和人类的选择性注意力机制类似,核心目标是从众多信息中选出对当前任务目标更加关键信息。
Attention 机制最早是在计算机视觉里应用的,随后在 NLP(Natural language processing,自然语言处理 ) 领域也开始应用了,真正发扬光大是在 NLP 领域,因为 2018 年 BERT(Bidirectional Encoder Representation from Transformers,双向Transformer的Encoder) 和 GPT 的效果出奇的好,进而走红。而 Transformer 和 Attention 这些核心开始被大家重点关注。

图2: AI领域的Attention 机制
在深度学习中,注意力机制通常应用于序列数据(如文本、语音或图像序列)的处理。其中,最典型的注意力机制包括自注意力机制、空间注意力机制(用于图像处理)和时间注意力机制(用于自然语言处理)。这些注意力机制允许模型对输入序列的不同位置分配不同的权重,以便在处理每个序列元素时专注于最相关的部分。
3.Encoder-Decoder(编码-解码)
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
3.1 Encoder-Decoder的介绍
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,它并不特值某种具体的算法,而是一类算法的统称。Encoder-Decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。Encoder-Decoder 这个框架很好的诠释了机器学习的核心思路:
将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题。
Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」,Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」


图3: Encoder与Decoder的框架
把 2 个环节连接起来,用通用的图来表达则是下面的样子:

图4: Encoder-Decoder的整体框架
关于 Encoder-Decoder,有2 点需要说明:
不论输入和输出的长度是什么,中间的「向量 c」 长度都是固定的(这也是它的缺陷)根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN (循环神经网络 – Recurrent Neural Network ),但通常是其变种 LSTM (长短期记忆网络 – Long short-term memory)或者 GRU )
只要是符合上面的框架,都可以统称为 Encoder-Decoder 模型。
3.2 Encoder-Decoder的应用
Encoder-Decoder框架应用广泛,如下图所示。

图5: Encoder-Decoder的应用
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。例如,对于句子对

,我们的目标是给定输入句子

,期待通过Encoder-Decoder框架来生成目标句子

。
和
可以是同一种语言,也可以是两种不同的语言。而
和
分别由各自的单词序列构成:


Encoder顾名思义就是对输入句子
进行编码,将输入句子通过非线性变换

转化为中间相量C(即中间语义):

对于解码器Decoder来说,其任务是根据输入句子
的中间相量C和之前已经生成的历史信息

,通过非线性变换

来生成i时刻要生成的单词

:

每个
都依次这么产生,那么看起来就是整个系统根据输入句子
生成了目标句子
。若输入句子
是中文句子,目标句子
是英文句子,那么解决机器翻译问题的Encoder-Decoder框架;若输入句子Source是一句问句,目标句子Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。
Encoder-Decoder框架不仅在文本领域广泛使用,在语音识别、图像处理等领域也常使用。如对语音识别来说,Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
3.3 Seq2Seq(序列到序列)
Encoder-Decoder框架之间只有一个「向量 c」来传递信息,且 c 的长度固定。然而许多重要的问题,例如机器翻译、语音识别、自动对话等,表示成序列后,其长度事先并不知道。因此如何突破先前深度神经网络的局限,使其可以适应这些场景,成为研究热点,Seq2Seq框架应运而生。
Seq2Seq(是 Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。例如下图:

图6:Seq2Seq示例
如上图:输入了 6 个汉字,输出了 3 个英文单词。输入和输出的长度不同。
3.4 「Seq2Seq」和「Encoder-Decoder」的关系
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。而 Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型(强调方法)的范畴。它们的范围关系如下所示:

图7:Seq2Seq和Encoder-Decoder的关系图
总结一下的话:
Seq2Seq 属于 Encoder-Decoder 的大范畴Seq2Seq 更强调目的(序列到序列的问题),Encoder-Decoder 更强调方法(编码-解码的一个过程)
3.5 Encoder的缺陷——信息的丢失
上文提到:Encoder(编码器)和 Decoder(解码器)之间只有一个「向量 c」来传递信息,且 c 的长度固定。为了便于理解,我们类比为「压缩-解压」的过程:将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。再将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。
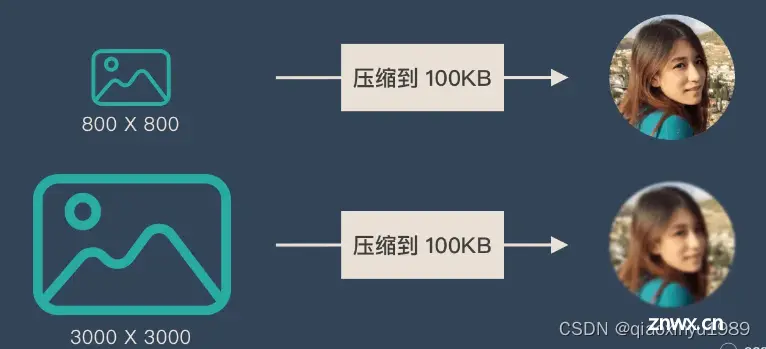
图7:信息丢失的示意图
Encoder-Decoder的缺陷 就是类似的问题:当输入信息太长时,会丢失掉一些信息。
4. Attention原理
Attention 机制就是为了解决「信息过长,信息丢失」的问题。
4.1 引入 Attention 的 Encoder-Decoder 模型
Attention 模型的特点是 Encoder 不再将整个输入序列编码为固定长度的「中间向量 C」 ,而是编码成一个向量的序列。引入了 Attention 的 Encoder-Decoder 模型如下图:

图8:引入Attention 的 Encoder-Decoder 模型图
下面的动图演示了attention 引入 Encoder-Decoder 框架下,完成机器翻译任务的大致流程。其中输入句子
是法语句子:"Je suis étudiant",目标句子
是英文句子:“I am a student”。

图9:引入Attention 的 Encoder-Decoder 的机器翻译动图
若按照Encoder-Decoder的框架(图4所示),我们的输出值
的表达式:
「向量 c」是由句子Source的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,如

,
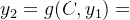
还是

,其句子Source中任意单词对生成某个目标单词
来说影响力都是相同的,无法体现对一个句子序列中不同语素的关注程度。这说明Encoder-Decoder没有体现出注意力。
而在自然语言中,一个句子中的不同部分是有不同含义和重要性的。比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。如果是做追逐角色分析的应用场景,训练的时候明显应该对Tom 这个词语做更多的关注。
在引入Attention机制的 Encoder-Decoder模型中,如图8所示。出现了

分别对应了

,这样输出值
的表达式也改变了:

目标句子就变成了

,

和

了。当
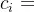
的取值不同,目标单词
的影响力是不同的。如Tom chase Jerry,在做追逐角色分析的应用场景中,会对Tom 这个词语分配更多的注意力(即权重

更大),从而提高模型的精度和效率。
问题是
如何计算?我们再看一副Attention的细节图:

图10:引入Attention 的 Encoder-Decoder 模型图
从图中可以看出,
是
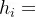
的加权的结果:

其中,

代表输入句子Source的长度,

代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而
则是Source输入句子中第j个单词的语义编码。
假设
下标i就是Tom Chase Jerry中的“ 汤姆” ,那么
就是3,h1=f(“Tom”),h2=f(“Chase”), h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示
的形成过程如下图所示。

图11: Attention的形成过程
这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道输入句子Source中各个单词的概率分布为:(Tom,0.6)(Chase,0.2) (Jerry,0.2) ?即如何计算
呢?这时候就用到我们的Softmax函数的原理(以第i个节点输出为例):

其中

为第i个节点的输出值,C为输出节点的个数,即分类的类别个数。所以,同理可得:

其中

为每一个输入位置
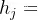
对当前位置i的影响。如果当前decoder阶段已经到了

,要进行下一个
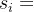
的预测了,则
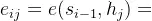
根据不同的Attention算法

的实现方式也不同:
Bahdanau Attention结构:

,其中U,V,W是模型的参数Luong Attention结构:

但是无论是Bahdanau Attention,还是Luong Attention,它们都属于Soft Attention的结构,都是通过Softmax来计算
。
4.2 Attention机制的本质思想
但是,Attention 并不一定要在 Encoder-Decoder 框架下使用的,他是可以脱离 Encoder-Decoder 框架的。下面的图片则是脱离 Encoder-Decoder 框架后的原理图解。

图12 Attention机制的本质思想
首先认识几个概念:
查询(Query): 指的是查询的范围,自主提示,即主观意识的特征向量键(Key): 指的是被比对的项,非自主提示,即物体的突出特征信息向量值(Value) : 则是代表物体本身的特征向量,通常和Key成对出现
我们可以这样来看待Attention机制(参考图12):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
上面的图看起来比较抽象,下面用一个例子来解释 attention 的原理:淘宝查找物品的过程。

在这个例子中,Query, Key 和 Value 的每个属性虽然在不同的空间,其实他们是有一定的潜在关系的,也就是说通过某种变换,可以使得三者的属性在一个相近的空间中。
至干Attention机制的且体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Querv和Key计算权重系数;第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理。这样,可以将Attention的计算过程抽象为如图展示的三个阶段。
阶段一:根据Query和Key计算两者之间的相关性或相似性(常见方法点积、余弦相似度,MLP网络),得到注意力得分(即权值系数);阶段二:将权值进行归一化,得到直接可用的权重阶段三:将权重和 value 进行加权求和,得到Attention Value(此时的V是具有一些注意力信息的,更重要的信息更关注,不重要的信息被忽视了);具体见下:

这三个阶段可以用下图表示:

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。