基于注意力机制的CNN-LSTM的出租车客流预测模型及实例
牛爷爷爱吃香菜 2024-08-25 17:31:01 阅读 95
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
目录
文章目录
前言
一、注意力机制是什么?
1. 基本概念
2. 工作原理
3. 应用场景
4. 优势
二、模型理解与调整
1.模型架构
2.模型代码介绍
(1)数据输入
(2)卷积层
(3)Dropout 正则化
(4)双向 LSTM 层:
(5)再次 Dropout 正则化:
(6)注意力机制:
(7)展平层:
(8)全连接输出层:
(9)模型组装:
3. 模型调参
(1)整体思路
(2)优化器选择
三、实例分析
1. 客流量代表性区域选择
2. 特征选择-相关性分析
3.数据输入
4.模型输出
四、部分代码
总结
前言
本文讲述了注意力机制在出租车客流预测方面的作用,详细介绍了模型代码结构以及模型的调参过程,可以很好的理解模型结构。
一、注意力机制是什么?
注意力机制(Attention Mechanism)是一种计算模型中常用的技术,它模拟了人类在处理信息时的注意力分配过程。在深度学习领域,特别是在自然语言处理(NLP)和计算机视觉(CV)等任务中,注意力机制被广泛应用。
1. 基本概念
在传统的神经网络中,输入数据通过固定的权重和结构,一次性传递给下一层网络进行处理。然而,这种方式可能会导致信息丢失或混淆,尤其是当输入数据的长度变化或者数据中包含重要信息时。
注意力机制的提出解决了这一问题,它通过动态地给予输入数据不同的权重,使得模型可以专注于输入数据的不同部分,从而提升了模型的表现。
2. 工作原理
注意力机制的工作原理可以概括为以下几个步骤:
特征提取:首先,模型会对输入数据进行特征提取,将其转换为一个特征向量或特征矩阵。注意力分配:在这一步骤中,模型会计算出每个输入元素(或其特征)的注意力权重。这些权重决定了模型在处理过程中关注每个输入元素的程度。加权求和:根据计算得到的注意力权重,对输入数据的不同部分进行加权求和,生成加权的特征向量或特征矩阵。输出生成:最后,基于加权和后的特征向量或特征矩阵,模型可以生成相应的输出,用于下游任务的处理。
3. 应用场景
注意力机制在各种深度学习模型中被广泛应用,包括但不限于:
机器翻译:在序列到序列(seq2seq)模型中,注意力机制帮助模型决定在翻译输出时需要关注输入句子的哪些部分,特别是在长句子翻译中效果显著。文本摘要:用于确定生成摘要时需要关注输入文本的哪些句子或单词,以保留最重要的信息。图像描述生成:在生成图像描述时,注意力机制可以帮助模型选择要描述的特定区域或对象。语音识别:用于确定在识别语音时需要注意哪些声学特征或时间步长。
4. 优势
引入注意力机制的优势主要体现在以下几个方面:
提升模型性能:通过动态地调整输入数据的关注度,模型可以更好地处理长序列或复杂数据,提升了模型的泛化能力和表现。解释性强:注意力权重可以被视为模型决策的一种解释,帮助理解模型在特定任务中的工作方式。处理长距离依赖:在处理长序列数据时,注意力机制可以帮助模型捕捉到序列中不同部分之间的依赖关系,而传统的固定权重模型可能会忽略这些信息。
二、模型理解与调整
1.模型架构
代码如下(示例):
<code>def attention_model():
inputs = Input(shape=(TIME_STEPS, INPUT_DIMS))
x = Conv1D(filters=64, kernel_size=1, activation='relu')(inputs) # , padding = 'same'code>
x = Dropout(0.3)(x)
# lstm_out = Bidirectional(LSTM(lstm_units, activation='relu'), name='bilstm')(x)code>
# For GPU you can use CuDNNLSTM
lstm_out = Bidirectional(LSTM(lstm_units, return_sequences=True))(x)
lstm_out = Dropout(0.3)(lstm_out)
attention_mul = attention_3d_block(lstm_out)
attention_mul = Flatten()(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)code>
#output = Dense(1, activation='linear')(attention_mul)code>
model = Model(inputs=[inputs], outputs=output)
return model
模型结构可视化
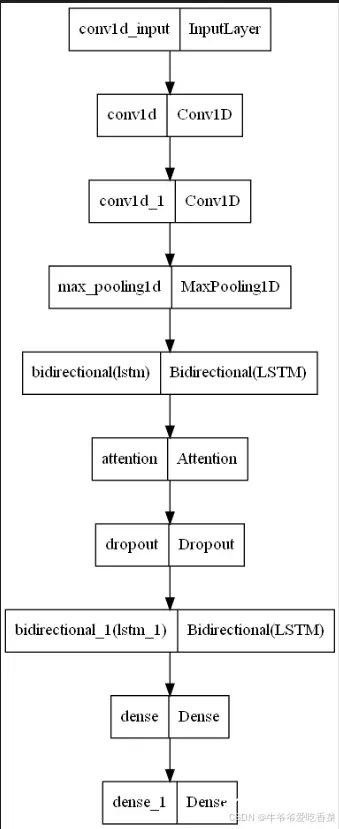
2.模型代码介绍
(1)数据输入
代码如下(示例):
<code>inputs = Input(shape=(TIME_STEPS, INPUT_DIMS))
该处表示模型的数据输入 ,因为考虑到影响出租车客流的特征变量不止一个,因此模型输入为多变量输入。
TIME_STEPS表示时间步长。 时间步长(time step)在深度学习模型中的作用主要体现在处理序列数据时,尤其是时间序列数据或文本序列中。以下是时间步长在模型原理层面的主要作用:
序列建模和顺序信息处理:在处理序列数据时,如文本或时间序列,每个时间步代表一个序列中的特定位置或时间点。模型根据时间步长依次处理序列中的每个元素,从而捕捉数据中的顺序信息和演变趋势。建立长期依赖关系:时间步长使得模型能够处理序列中的长期依赖关系。例如,在时间序列分析中,模型需要考虑到过去时刻的信息,以便更好地预测未来时刻的值。通过逐步处理每个时间步,模型可以有效地学习和利用序列中的时间相关信息。输入数据结构化和特征提取:在卷积神经网络(CNN)和循环神经网络(RNN,包括LSTM和GRU等)中,时间步长决定了输入数据的结构化方式。CNN可以利用滑动窗口在不同时间步上提取局部特征,而LSTM等RNN类型则通过递归地更新隐藏状态来捕捉序列中的长期依赖关系。模型的状态更新和传播:对于循环神经网络(RNN)及其变种(如LSTM),时间步长决定了每个时间步上的隐藏状态更新和传播方式。每个时间步的输入和当前状态将影响下一个时间步的状态计算,从而形成对整个序列的动态建模。注意力机制的应用:注意力机制通常依赖于序列中各个时间步的特征向量来计算注意力权重。时间步长影响了模型在计算注意力时考虑的特征数量和顺序,从而影响模型在不同位置上的关注程度。
总之,时间步长在深度学习模型中扮演着关键角色,通过定义和处理序列数据的顺序和结构,使得模型能够有效地理解和利用输入数据的时序特征,从而提高模型在序列预测、分类、生成等任务中的表现能力。一般来说TIME_STEP设置为60即可。
INTUP_DIMS表示模型输入的特征变量数。
(2)卷积层
x = Conv1D(filters=64, kernel_size=1, activation='relu')(inputs) # , padding = 'same'code>
Conv1D 是一维卷积层,这里用于处理序列数据。filters=64 指定了输出的特征图数量,kernel_size=1 定义了卷积核的大小,activation='relu'code> 是激活函数。这一层用于从输入数据中提取局部特征。
(3)Dropout 正则化
x = Dropout(0.3)(x)
Dropout 层有助于防止模型过拟合,这里丢弃率为 30%。
(4)双向 LSTM 层:
# lstm_out = Bidirectional(LSTM(lstm_units, activation='relu'), name='bilstm')(x)code>
# For GPU you can use CuDNNLSTM
lstm_out = Bidirectional(LSTM(lstm_units, return_sequences=True))(x)
Bidirectional 函数创建一个双向的 LSTM 层,LSTM 层具有 lstm_units 个单元,return_sequences=True 表示输出整个序列而不是仅输出最后一个时间步的状态。这一层用于捕捉输入序列中的长期依赖关系。如果想调整LSTM层类型,只需将Bidirectional 删除或更换即可。
(5)再次 Dropout 正则化:
lstm_out = Dropout(0.3)(lstm_out)
对 LSTM 层的输出进行再次 Dropout 处理,防止过拟合。
(6)注意力机制:
attention_mul = attention_3d_block(lstm_out)
attention_3d_block 是一个自定义的函数或模块,用于实现注意力机制,从 LSTM 输出中加强重要的特征。
(7)展平层:
attention_mul = Flatten()(attention_mul)
Flatten 层将多维的输入展平为一维,为接下来的全连接层准备数据。
(8)全连接输出层:
output = Dense(1, activation='sigmoid')(attention_mul)code>
Dense 层定义了一个全连接层,输出维度为 1,使用 sigmoid 激活函数,适合二分类任务。如果要进行回归任务,可以选择 activation='linear'code>。
(9)模型组装:
model = Model(inputs=[inputs], outputs=output)
使用 Model 函数将输入和输出层实例化为一个模型对象。
3. 模型调参
(1)整体思路
模型的参数可以通过以下步骤进行:
调整LSTM层的单元数(units):这是最基本的调整之一。增加单元数可以增加模型的容量,但也可能增加过拟合的风险。你可以尝试不同的单元数,并观察模型的性能。调整LSTM层的层数:增加LSTM层的层数可能会增加模型的复杂度,但也可能增加训练时间。增加层数可能有助于模型学习更复杂的模式,但也可能增加过拟合的风险。使用Dropout:在LSTM层之间添加Dropout层可以帮助减少过拟合。你可以尝试不同的Dropout比例,通常在0.2到0.5之间。调整学习率:学习率是优化器的一个关键参数,影响模型的训练速度和性能。较小的学习率可能需要更多的训练时间,但通常能够更好地收敛到全局最优解。尝试不同的优化器:Adam、RMSprop和SGD等优化器都有不同的特点。选择适合你问题的优化器可能会改善模型的性能。调整批量大小:批量大小影响模型在每次迭代中看到的样本数量。较大的批量大小可能会加快训练速度,但较小的批量大小可能有助于模型更好地泛化。使用更多的训练数据:更多的数据通常能够帮助模型更好地泛化,减少过拟合的风险。尝试不同的输入特征:尝试使用不同的特征组合或工程特征来训练模型,有时候可以改善模型的性能。使用更长的训练时间:有时候简单增加训练时间就能够提高模型的性能。使用交叉验证:如果你的数据集足够大,使用交叉验证来评估不同参数设置下模型的性能是一个好方法。
(2)优化器选择
不同的优化器适用于不同类型的数据和问题。以下是几种常见的优化器以及它们适用的情况:
Adam(自适应矩估计优化器):适用于大多数情况,通常是默认选择。对于大多数深度学习任务,Adam通常表现良好,因为它自适应地调整学习率。对于具有稀疏梯度的问题,Adam通常表现优于其他优化器。RMSprop(均方根传递优化器):适用于循环神经网络(RNN)等序列数据处理任务。在处理梯度爆炸或梯度消失问题时,RMSprop通常比其他优化器更有效。对于非平稳目标函数和数据的情况,RMSprop通常表现良好。SGD(随机梯度下降):当数据集较小或数据稀疏时,SGD可能更适合。在资源有限的情况下,SGD可能更容易实现和计算,因为它不需要存储Adam和RMSprop等优化器所需的额外状态。当学习率调整得当时,SGD可以达到与Adam和RMSprop相媲美的性能。AdaGrad(自适应梯度算法):适用于稀疏数据或具有不同特征频率的问题。它通过自适应地调整学习率来对不同的特征进行不同的更新,从而在处理具有不同特征频率的问题时表现良好。
选择优化器通常取决于你的数据集、问题类型以及试验的结果。在实践中,你可能需要尝试不同的优化器,并根据验证集的性能选择最合适的优化器。
三、实例分析
以上海市2016年8月1日-8月31日的出租车订单数据为例,同时收集每日的天气数据包括最高气温,最低气温,天气类型考虑作为影响出租车客流量的的相关变量,通过增加数据维度,可以提高模型精度。
1. 客流量代表性区域选择
通过对出租车总体客流量的上下车经纬度坐标进行聚类分析处理,旨在确定具有最高客流量代表性的区域。首先进行聚类分析,然后对每个聚类的经纬度进行中心化处理,以确定每个聚类上下车的中心经纬度坐标。
| 聚类编号
| O
| D
| ||
| 中心经度坐标
| 中心维度坐标
| 中心经度坐标
| 中心维度坐标
| |
| 聚类1
| 121.36265
| 31.19710
| 121.41472
| 31.14503
|
| 聚类2
| 121.52358
| 31.28561
| 121.44738
| 31.22738
|
| 聚类3
| 121.54025
| 31.19927
| 121.55014
| 31.22588
|
| 聚类4
| 121.45265
| 31.22563
| 121.33034
| 31.20941
|
| 聚类5
| 121.42512
| 31.31261
| 121.47322
| 31.30893
|
| 聚类6
| 121.38790
| 31.10479
| 121.32928
| 30.99452
|
| 聚类7
| 121.73519
| 31.15932
| 121.73132
| 31.146280
|
2. 特征选择-相关性分析
由于数据量过于庞大,我们选择了上海市徐汇区作为研究对象,着眼于交通小区。为了确定客流量我们将订单时间间隔设定为一分钟,同时统计该区域每分钟的订单数量,为了深入探究各变量对结果的影响,本文进行了相关性分析,具体结果如下
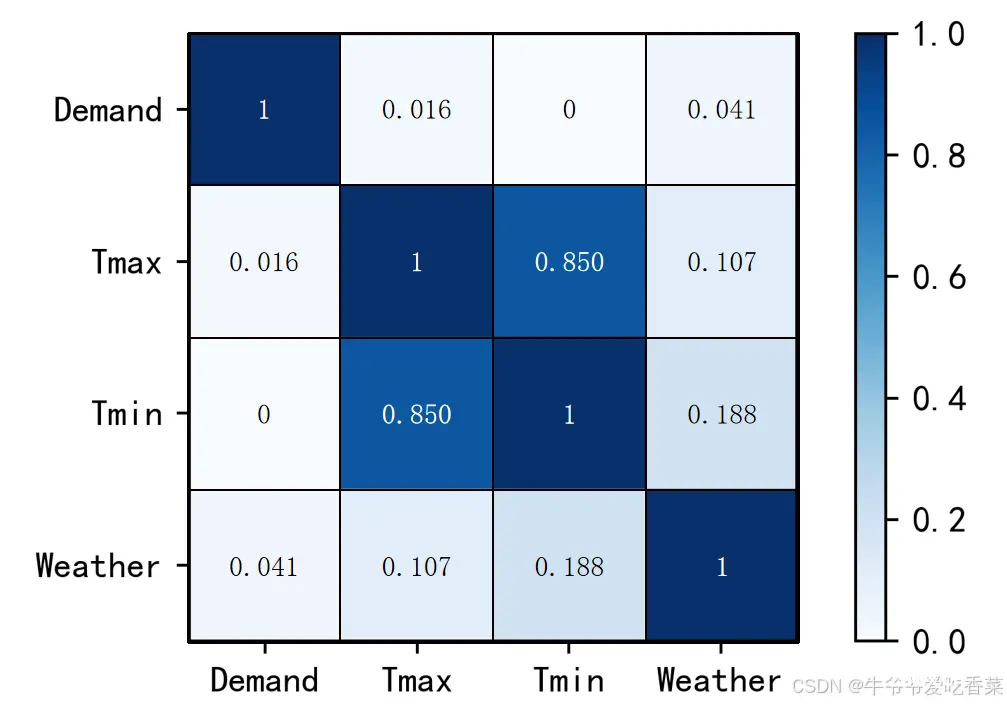
由相关性图可以看出影响出租车客流量的显著变量包括天气类型(Weather)和最高气温(Tmax) 。
3.数据输入
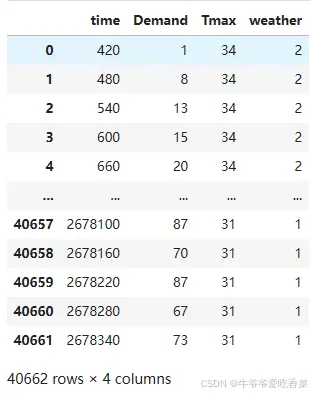
如图,数据维度为三,共含40662条数据。同时,将对客流量进行归一化处理后作为模型的输入数据。在调试过程中BiLSTM模型多次出现过拟合现象,然而CNN-BiLSTM模型以及本文提出的CNN-BiLSTM-Attention模型基本不会出现过拟合现象。可能的原因有以下四点:
特征提取能力更强:CNN在输入数据中提取特征时,能够有效地捕获局部特征和空间结构,从而降低了数据的维度。这种特性有助于减少模型对训练数据中的噪声或不相关特征的拟合,从而降低过拟合的风险。参数共享:CNN在卷积层中使用参数共享的机制,这意味着同一个卷积核会在整个输入中移动并提取相似的特征。这种参数共享可以有效地减少模型的参数数量,降低模型的复杂度,从而减少过拟合的可能性。局部感知:CNN对输入数据的局部区域进行感知,并通过池化层逐渐降低数据的空间维度,这有助于模型更好地理解数据的结构和模式。这种局部感知和空间降维有助于模型更好地泛化到未见过的数据。注意力机制:引入注意力机制可以使模型更加关注重要的特征或上下文,从而提高模型对输入的理解能力。在CNN-BiLSTM-Attention模型中,注意力机制有助于模型更好地学习输入序列中的关键信息,减少对无关信息的过度拟合。
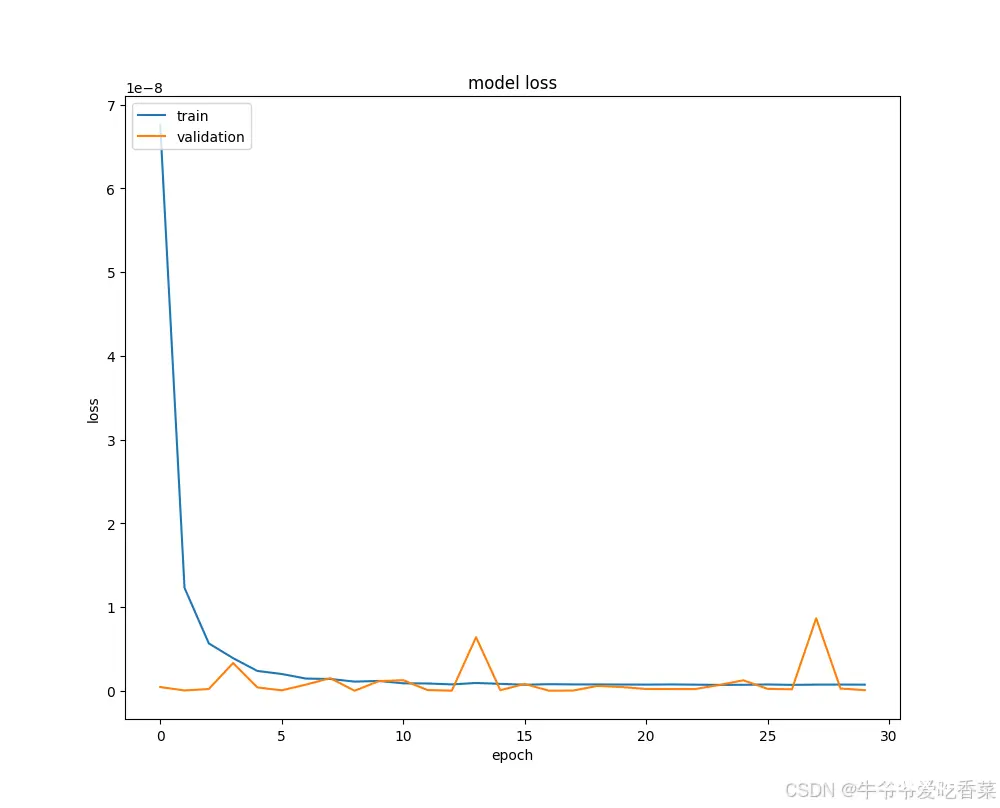
4.模型输出
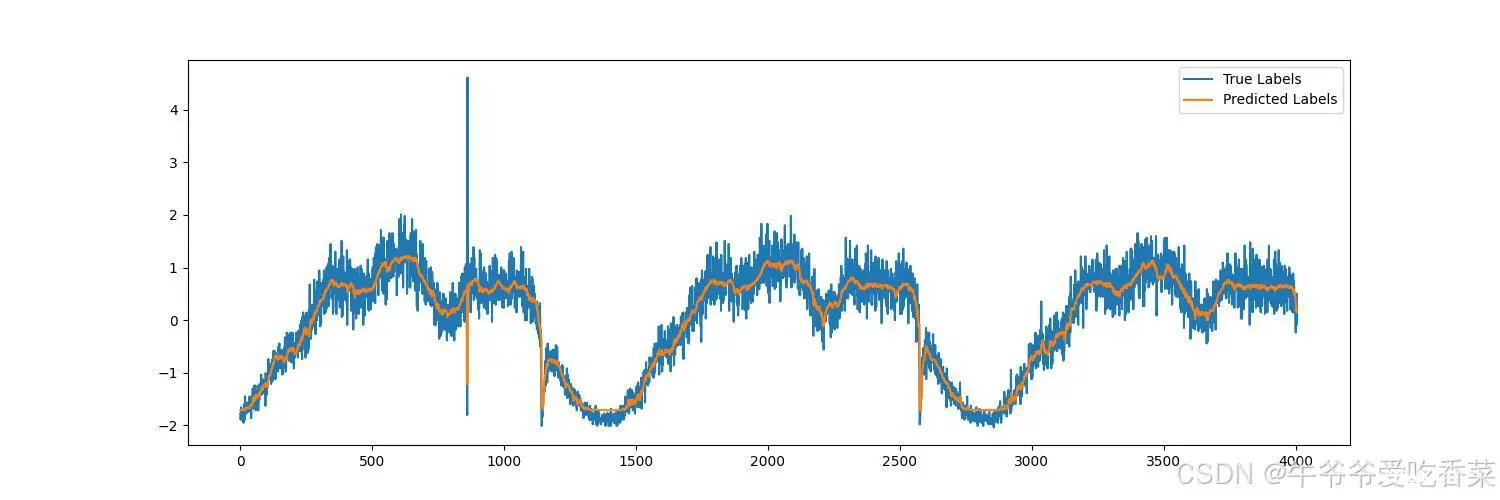
四、部分代码
<code>from keras.utils import plot_model
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
def get_activations(model, inputs, print_shape_only=False, layer_name=None):
# From: https://github.com/philipperemy/keras-visualize-activations
activations = []
inp = model.input
if layer_name is None:
outputs = [layer.output for layer in model.layers]
else:
outputs = [layer.output for layer in model.layers if layer.name == layer_name] # all layer outputs
funcs = [K.function([inp] + [K.learning_phase()], [out]) for out in outputs] # evaluation functions
layer_outputs = [func([inputs, 1.])[0] for func in funcs]
for layer_activations in layer_outputs:
activations.append(layer_activations)
if print_shape_only:
print(layer_activations.shape)
else:
print(layer_activations.shape)
print(layer_activations)
return activations
def get_data(n, input_dim, attention_column=1):
"""
:param n: the number of samples to retrieve.
:param input_dim: the number of dimensions of each element in the series.
:param attention_column: the column linked to the target. Everything else is purely random.
:return: x: model inputs, y: model targets
"""
x = np.random.standard_normal(size=(n, input_dim))
y = np.random.randint(low=0, high=2, size=(n, 1))
x[:, attention_column] = y[:, 0]
return x, y
def get_data_recurrent(n, time_steps, input_dim, attention_column=10):
"""
:param n: the number of samples to retrieve.
:param time_steps: the number of time steps of your series.
:param input_dim: the number of dimensions of each element in the series.
:param attention_column: the column linked to the target. Everything else is purely random.
:return: x: model inputs, y: model targets
"""
x = np.random.standard_normal(size=(n, time_steps, input_dim))
y = np.random.randint(low=0, high=2, size=(n, 1))
x[:, attention_column, :] = np.tile(y[:], (1, input_dim))
return x, y
def get_data_recurrent2(n, time_steps, input_dim, attention_dim=5):
x = np.random.standard_normal(size=(n, time_steps, input_dim))
y = np.random.randint(low=0, high=2, size=(n, 1))
x[:,:,attention_dim] = np.tile(y[:], (1, time_steps))
return x,y
from keras.layers import Input, Dense, LSTM ,Conv1D,Dropout,Bidirectional,Multiply
from keras.models import Model
#from attention_utils import get_activations
from keras.layers import Multiply
from keras.layers.core import *
from keras.layers import LSTM
from keras.models import *
SINGLE_ATTENTION_VECTOR = False
def attention_3d_block(inputs):
# inputs.shape = (batch_size, time_steps, input_dim)
input_dim = int(inputs.shape[2])
a = inputs
a = Dense(input_dim, activation='softmax')(a)code>
if SINGLE_ATTENTION_VECTOR:
a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a)code>
a = RepeatVector(input_dim)(a)
a_probs = Permute((1, 2), name='attention_vec')(a)code>
#output_attention_mul = merge([inputs, a_probs], name='attention_mul', mode='mul')code>
output_attention_mul = Multiply()([inputs, a_probs])
return output_attention_mul
# Another way of writing the attention mechanism is suitable for the use of the above error source:https://blog.csdn.net/uhauha2929/article/details/80733255
def attention_3d_block2(inputs, single_attention_vector=False):
# If the upper layer is LSTM, you need return_sequences=True
# inputs.shape = (batch_size, time_steps, input_dim)
time_steps = K.int_shape(inputs)[1]
input_dim = K.int_shape(inputs)[2]
a = Permute((2, 1))(inputs)
a = Dense(time_steps, activation='softmax')(a)code>
if single_attention_vector:
a = Lambda(lambda x: K.mean(x, axis=1))(a)
a = RepeatVector(input_dim)(a)
a_probs = Permute((2, 1))(a)
# Multiplied by the attention weight, but there is no summation, it seems to have little effect
# If you classify tasks, you can do Flatten expansion
# element-wise
output_attention_mul = Multiply()([inputs, a_probs])
return output_attention_mul
如需完整代码,三连私信
总结
鉴于LSTM模型在权重分配上存在不足,而CNN神经网络具有强大的特征提取能力,注意力机制通过动态分配权重来处理长期依赖问题。将LSTM、CNN模型及注意力机制结合,成功提出了基于注意力机制的CNN-LSTM-Attention客流量预测模型。 最后,通过决定系数(R²)、平均绝对误差(MAE)和loss曲线稳定的迭代次数(Epoch)对各模型进行评估,实验结果显示CNN-BiLSTM-Attention模型在预测性能上相对其他模型表现更优。
实例中也存在不足,可能还有潜在的特征变量未被发现,同时序列数据也可以通过去趋势化提升数据平稳性,增强模型预测能力,突出周期性或季节性变化。
上一篇: 为什么多模态大模型中使用Q-Former的工作变少了?附Q-Former结构简介
下一篇: 【Windows环境下nerfstudio环境配置及复现(含tinycudann安装、poster数据)】
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。