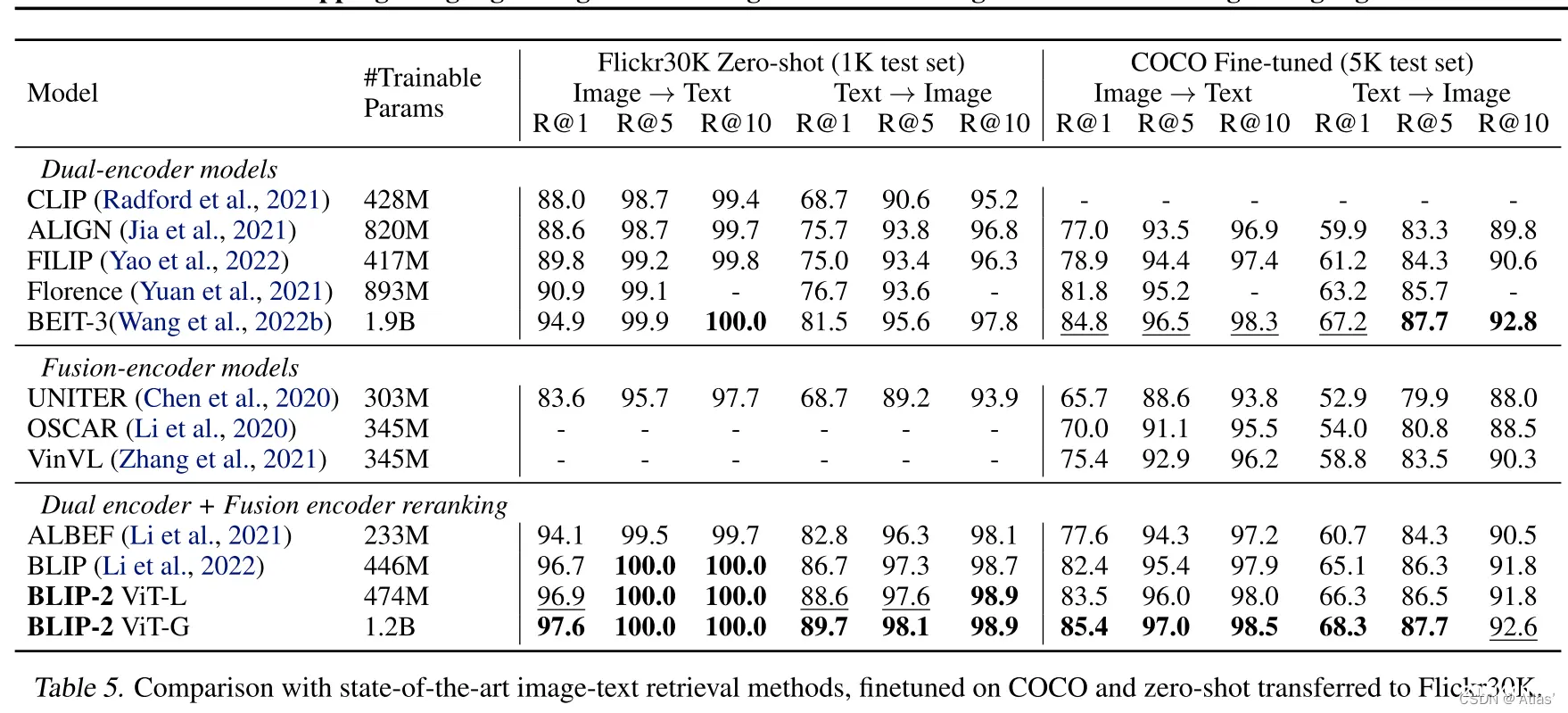
BLIP-2,基于现有的图像编码器预训练模型,大规模语言模型进行预训练视觉语言模型;BLIP-2通过轻量级两阶段预训练模型QueryingTransformer缩小模态之间gap,第一阶段从冻结图像编码器学习视...
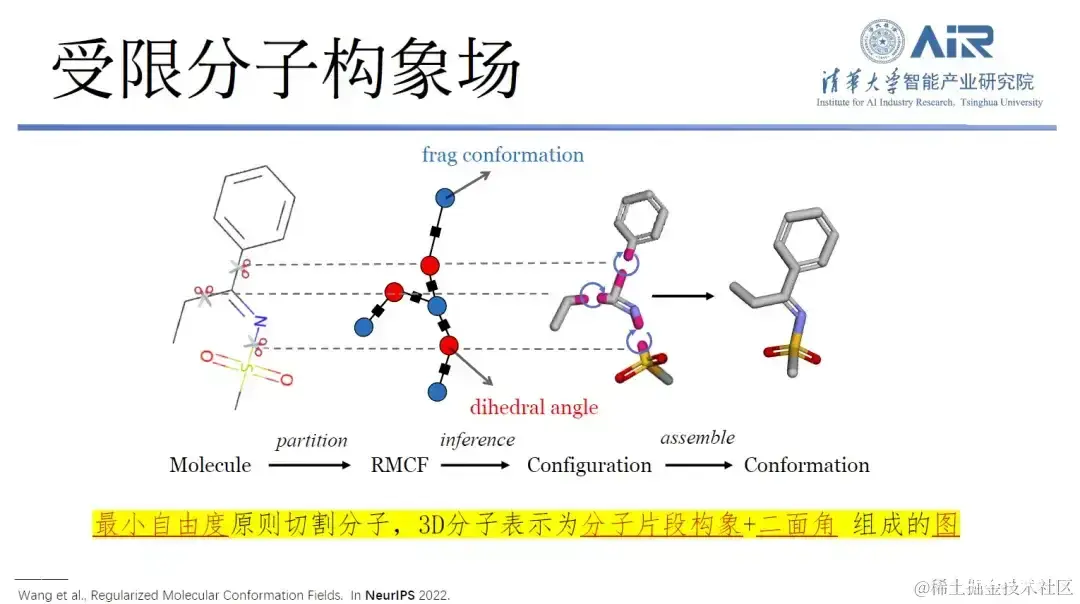
自去年9月份以来,周浩教授团队一直在进行这项工作,结合原子和氨基酸词汇表,可多尺度的实现蛋白质训练,在蛋白质和小分子联合任务中,ESM-AA的表现优于单独预训练基座,如ESM、其他蛋白质预训练或小分子预训...
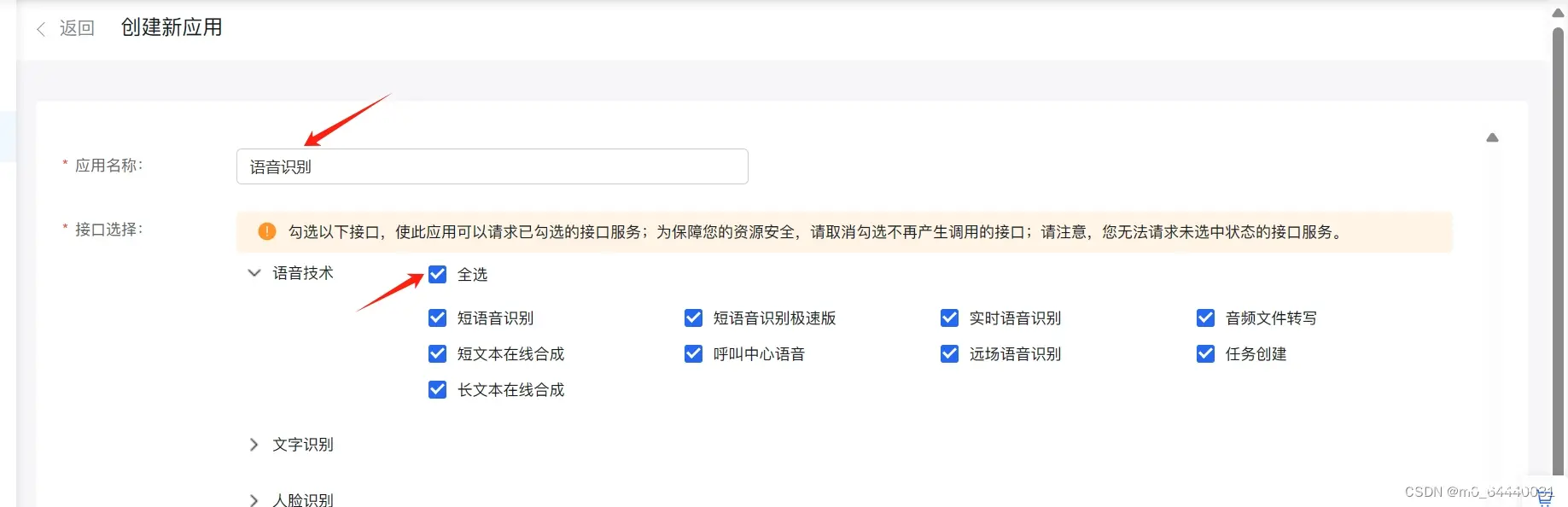
本文详细地梳理及实现了如何通过使用百度AI平台,将输入的文本转换成语音。_百度文本转语音开发流程前端...

从Adobeillustrator中提取文本以进行翻译,并在文本文件中翻译后写回Adobeillustrator。...

通义千问是阿里云自主研发的大语言模型。通义千问以用户以文本形式输入的指令(prompt)以及不定轮次的对话历史(history)作为输入,返回模型生成的回复作为输出。在这一过程中,文本将被转换为语言模型可以处理的...

本文概述了以Python为主的TTS开源项目的发展历程,重点介绍了深度学习技术如何革新语音合成,如Tacotron、Transformer-based模型、Bark、Whisper等。项目涵盖了语音合成、转换、识...

今天我们来学习一个有意思的多行文本输入打字效果,像是这样:这个效果其实本身并非特别困难,实现的方式也很多,在本文中,我们更多的会聚焦于整个多行打字效果最后的动态光标的实现。也就是如何在文本不断变长,在不确定行数的情况下,让文字的最末行右侧处,一直有一个不断...
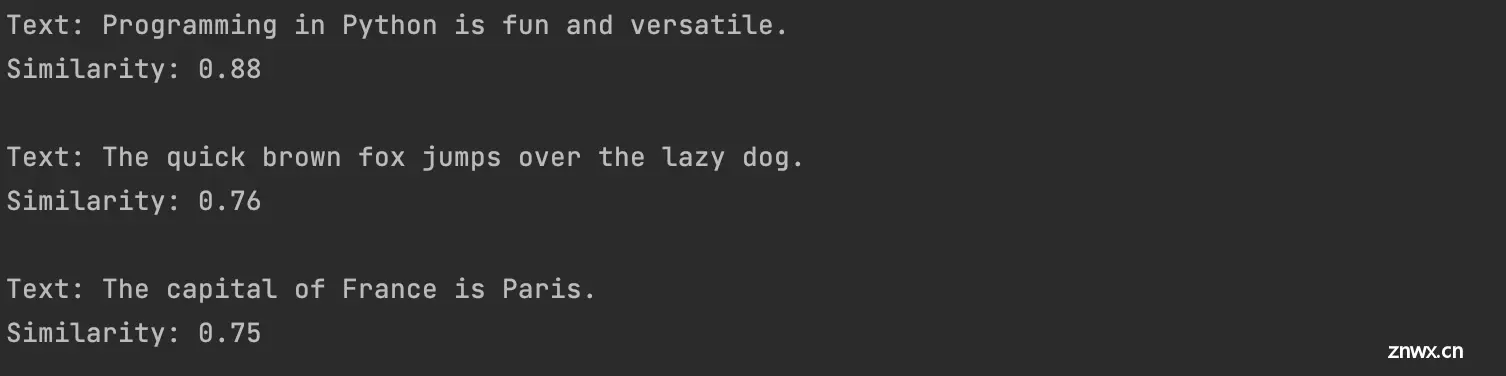
在大模型中,\"embedding\"指的是将某种类型的输入数据(如文本、图像、声音等)转换成一个稠密的数值向量的过程。这些向量通常包含较多维度,每一个维度代表输入数据的某种抽象特征或属性。Embedding的...
一周20.2K星!的文本转语音TTS模型--ChatTTS_chattts本地部署...

至此,我们已经完成了从零开始使用C#处理PDF文档,深度解析了如何使用iTextSharp和ImageSharp库实现读取PDF中的文本和图片的全流程。提供的代码示例和详细注释旨在帮助您快速理解和应用这些技术,为您...