BLIP2-图像文本预训练论文解读
‘Atlas’ 2024-07-05 09:01:01 阅读 52
文章目录
摘要解决问题算法模型结构通过frozen图像编码器学习视觉语言表征图像文本对比学习(ITC)基于图像文本生成(ITG)图文匹配(ITM)
从大规模语言模型学习视觉到语言生成模型预训练预训练数据预训练图像编码器与LLM预训练设置
实验引导零样本图像到文本生成零样本VQA
图像描述视觉问答图像文本检索
限制结论
论文:
《BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models》
github:
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
摘要
训练大尺度视觉语言预训练模型成本比较高,BLIP-2,基于现有的图像编码器预训练模型,大规模语言模型进行预训练视觉语言模型;BLIP-2通过轻量级两阶段预训练模型Querying Transformer缩小模态之间gap,第一阶段从冻结图像编码器学习视觉语言表征,第二阶段基于冻结语言模型,进行视觉到语言生成学习;BLIP-2在各种视觉-语言模型达到SOTA。比如在zero-shot VQAv2上超越Flamingo80B 8.7%,也证明该模型可以根据自然语言指引进行zero-shot图像到文本生成。
解决问题
端到端训练视觉语言模型需要大尺度模型及大规模数据,该过程成本大,本文提出方法基于现有高质量视觉模型及语言大模型进行联合训练,为减少计算量及防止遗忘,作者对预训练模型进行frozen,为了将两任务对齐,作者提出Querying Transformer (Q- Former) 预训练,如图1,其将有用视觉特征传递至LLM输出目标文本。
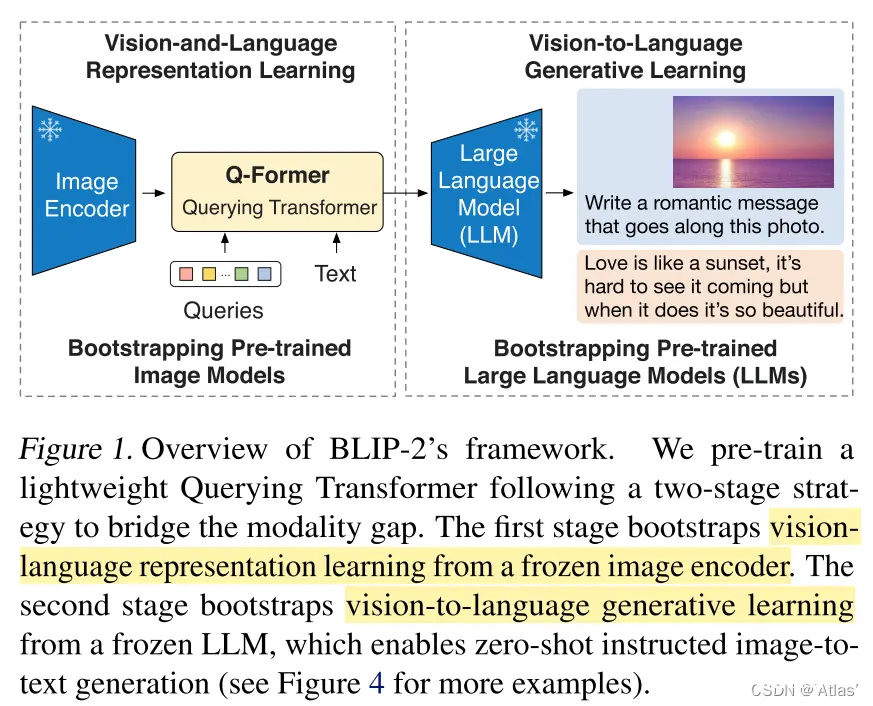
BLIP-2优势如下:
1、高效利用frozen预训练视觉及语言模型;
2、由于大规模语言模型能力,BLIP-2可以根据提示进行zero-shot图像到文本生成;
3、由于使用frozen单模态预训练模型,BLIP-2与现有SOTA方案相比,计算更加高效;
算法
为了对齐视觉特征到LLM文本空间,作者提出Q-Former,进行两阶段预训练:
1、图像编码器frozen进行学习视觉语言表征;
2、使用frozen LLM进行学习视觉到文本生成;
模型结构
如图2,Q-Former包括两个贡共享self-attention层的transformer子模块:图像transformer(Q-Former左半部分)与frozen image encoder相互作用提取视觉特征;文本transformer(Q-Former右半部分)可作为文本编码器,也可作为文本解码器。
可学习query embedding作为图像transformer输入,通过self-attention层相互作用,通过cross-attention层与frozen图像特征相互作用,query同时通过self-attention层与文本相互作用。根据预训练任务,作者使用不同self-attention mask控制query-text之间交互;作者使用
B
E
R
T
b
a
s
e
BERT_{base}
BERTbase初始化Q-Former,cross-attention层进行随机初始化;
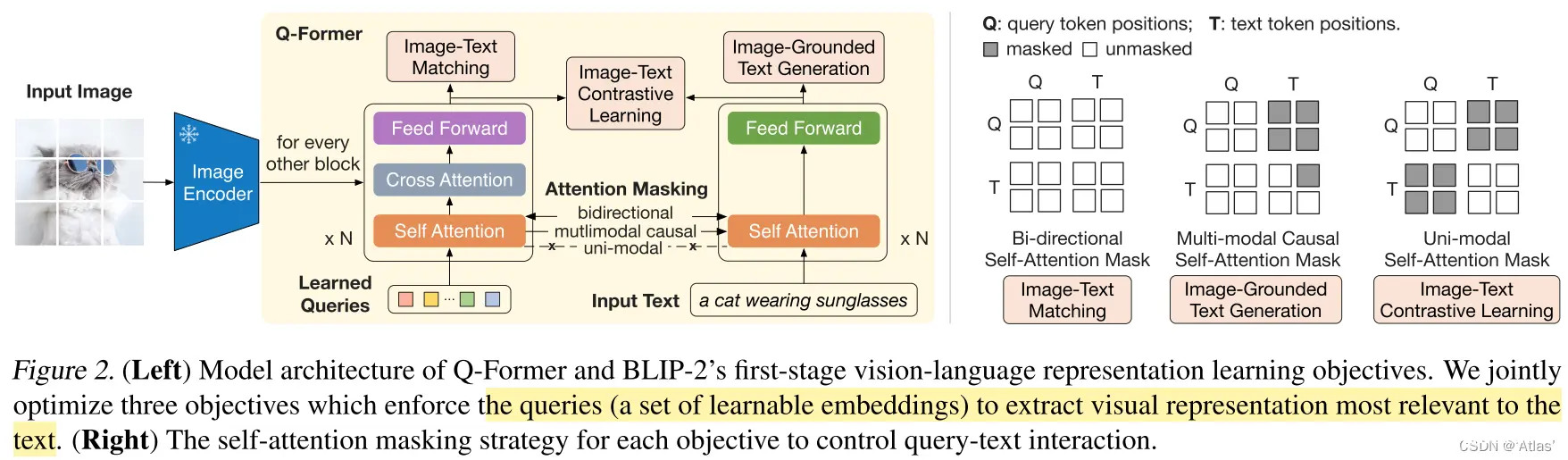
通过frozen图像编码器学习视觉语言表征
query通过学习提升与text相关视觉表征,受BLIP启发,作者通过3个目标函数,共享相同输入格式及模型参数,每个目标函数通过不同attention mask策略控制query与text之间相互影响,如图2所示;
图像文本对比学习(ITC)
ITC学习对齐图像表征与文本表征,通过比较成对与非成对的图像-文本相似度实现;计算过程如下:
计算image transformer输出query表征
Z
Z
Z(与可学习query长度相同)与text transformer输出文本表征
t
t
t 中【CLS】token相似性,选取最大值作为图像文本对相似度,为防止信息泄露,作者使用单模态self-attention mask,query与text不能互相可见,防止从文本直接学习;由于image encoder进行frozen,显存释放,可以使用batch负样本而不用像BLIP中使用队列。
基于图像文本生成(ITG)
ITG根据输入图像训练Q-Former生成文本,由于Q-Former不允许image encoder与text token直接交互,文本生成所需信息通过query进行提取,通过self-attention进行传递至text token,因此query需要捕获文本相关所有信息,作者使用多模态因果self-attention mask控制query-text交互,query无法获取text token,当前text token 可获取所有query及其之前text token。作者将【CLS】token替换为【DEC】token 作为解码任务标记;
图文匹配(ITM)
ITM为了学习精细化图像文本匹配,作者使用bi-dirention self-atttention mask,所有query与text相互可见,因此输出的query embedding Z捕获多模态信息,Z通过二类线性分类器获取logit,logit均值为匹配得分,作者使用《Align before Fuse》中难例负样本挖掘策略创建负样本对。
难例负样本挖掘策略:
当负样本的图像文本对有相同的语义但在细粒度细节上不同,那么该样本是难样本。作者通过对比相似度寻找batch内的 hard negatives。对于一个batch中的每一幅图像,作者根据对比相似性分布从相同的batch中抽取一个负文本,其中与图像更相似的文本有更高的可能被采样。同样的,作者还为每个文本采样一个hard negative图像。
从大规模语言模型学习视觉到语言生成
作者将Q-Former与LLM相连,后去LLM的语言生成能力。如图3,FC层映射输出的query embedding Z至LLM的text embedding;基于LLM Q-Former提取到的视觉表征作为soft visual prompt,由于Q-Former已经预训练用于提取对文本有用的视觉表征,减轻LLM学习视觉-文本对齐的负担。
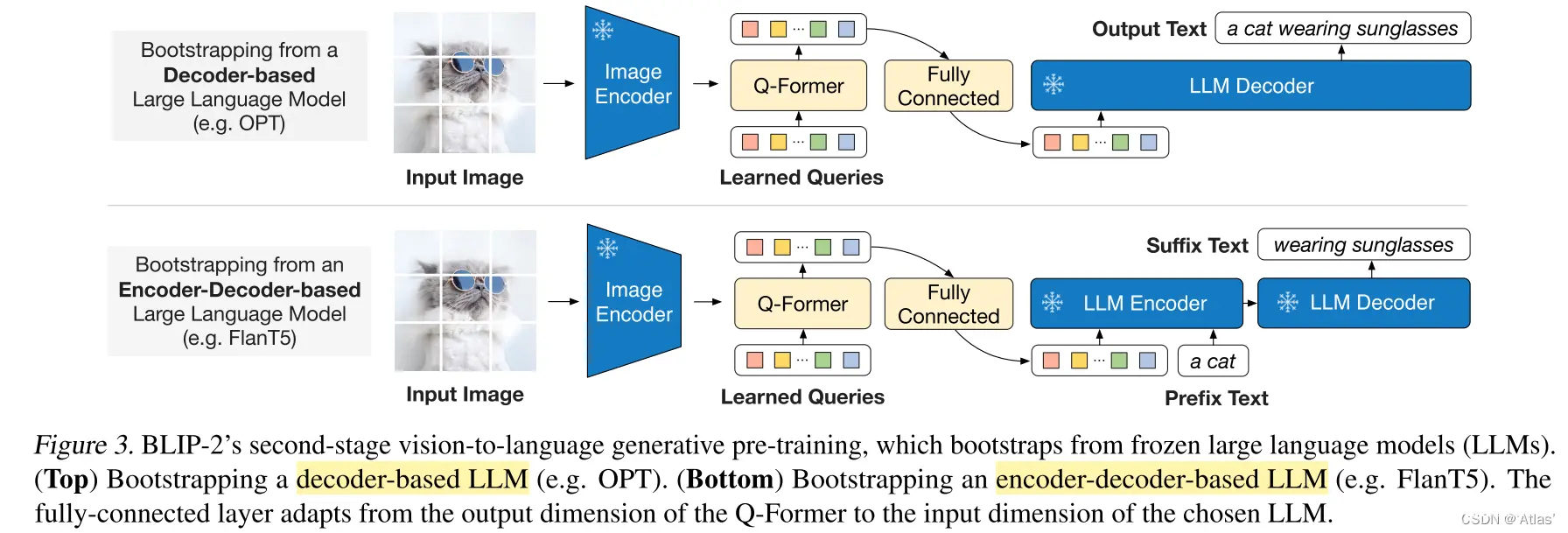
作者实验两种LLM,decoder-based LLM以及encoder-decoder-based LLM。
对于decoder-based LLM,作者使用language modeling loss进行预训练,frozen LLM进行文本生成;
对于encoder-decoder-based LLM,使用prefix language modeling loss预训练,将text分为两部分,text前半部分与视觉表征concat输入LLM编码器,后半部分作为LLM解码器的生成目标。
模型预训练
预训练数据
BLIP-2使用与BLIP相同数据,129M图片,包括COCO、Visual Genome、CC3M、CC12M、SBU,其中115M来自 LAION400M,使用CapFilt对网图进行生成caption,具体步骤如下:
1、使用
B
L
I
P
l
a
r
g
e
BLIP_{large}
BLIPlarge生成10个caption;
2、生成10个caption+原始web caption通过CLIP ViT-L/14模型与对应图像进行相似度排序;
3、选取top2作为该图的caption,以此作为训练数据;
预训练图像编码器与LLM
两个SOTA视觉transformer预训练模型:
ViT-L/14 from CLIP、ViT-G/14 from EVA-CLIP
移除ViT最后一层,使用倒数第二层特征。
LLM模型:
无监督训练的OPT作为decoder-based LLM
基于指令训练的FlanT5作为encoder-decoder-based LLM
预训练设置
第一阶段训练250k step,第二阶段训练80k step;ViT和LLM 转为FP16,FlanT5转为BFloat16,作者发现相对于32-bit,性能无下降;由于使用frozen模型,作者预训练比现在大规模VLP方法计算量都小,在16个A100(40G)上,对于ViT-G和FlanT5-XXL第一阶段训练耗时6天,第二阶段少于3天。
实验
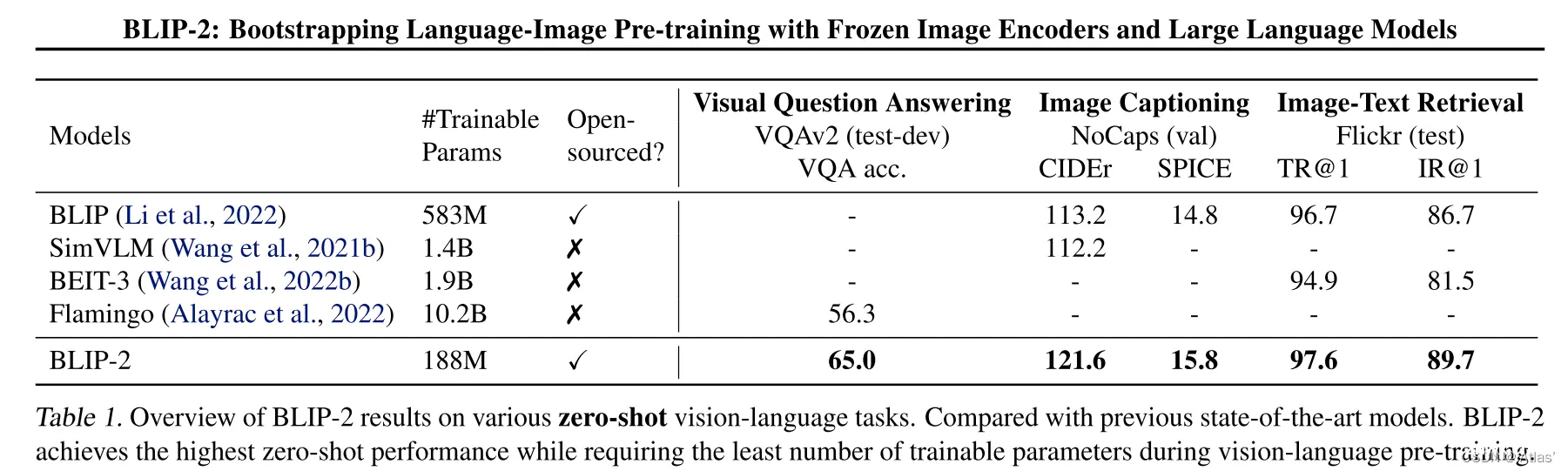
表1展示BLIP-2在各种零样本视觉语言任务上表现,与之前SOTA方法相比,性能得到改善,而且训练参数大量减少;
引导零样本图像到文本生成
BLIP-2使得LLM具有图像理解能力,同时保留遵循文本提示的能力;作者在视觉promt后增加简单文本promt,图4展示BLIP-2零样本图像文本生成能力,包括:视觉知识推理、视觉共鸣推理、视觉对话、个性化图像到文本生成等。

零样本VQA
表2表明,BLIP-2在VQAv2及GQA数据集达到SOTA。
表2得到一个有希望的发现:一个更好的图像编码器或LLM模型都将使得BLIP-2性能更好;
基于OPT或FlanT5,BLIP-2使用ViT-G性能超越使用VIT-L;
图像编码器固定,BLIP-2使用大LLM模型性能超越使用小模型;
在VQA上,基于指令训练的的FlanT5性能优于无监督训练的OPT;
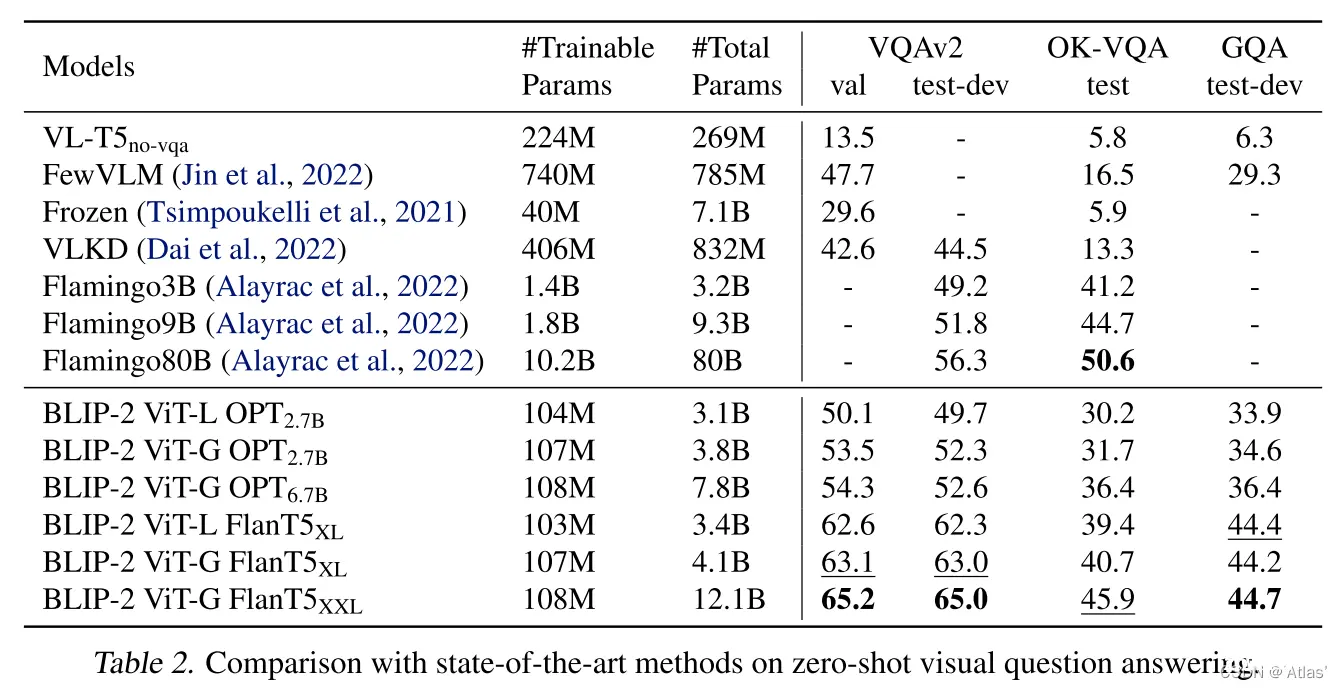
第一阶段预训练使得Q-Former学习与文本相关视觉表征,图5展示表征学习对生成式学习有效性,不进行表征学习,两种LLM模型在零样本VQA任务上性能大幅下降。
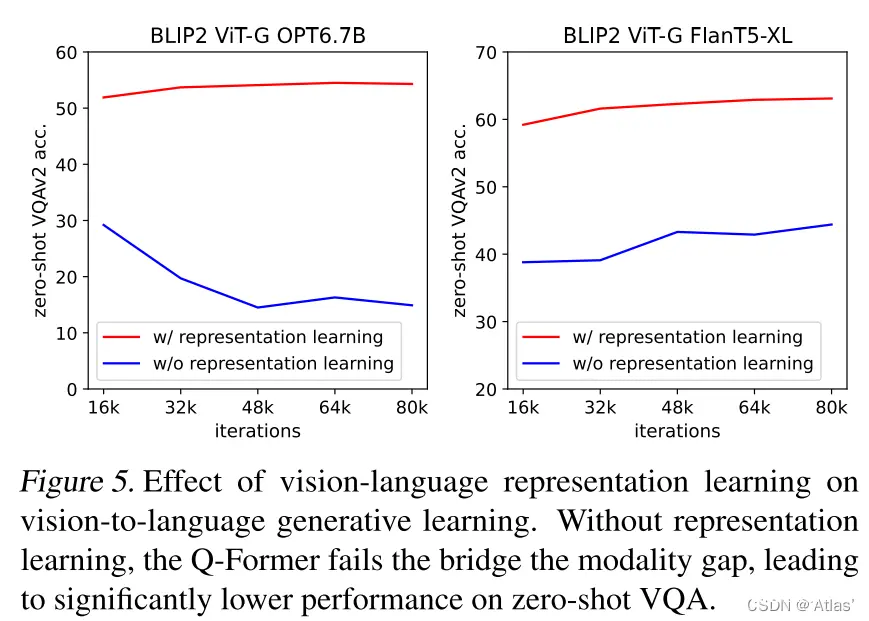
图像描述
表3表明,BLIP-2在NoCaps性能达到SOTA,证明对out-domain图像具有很强生成能力。
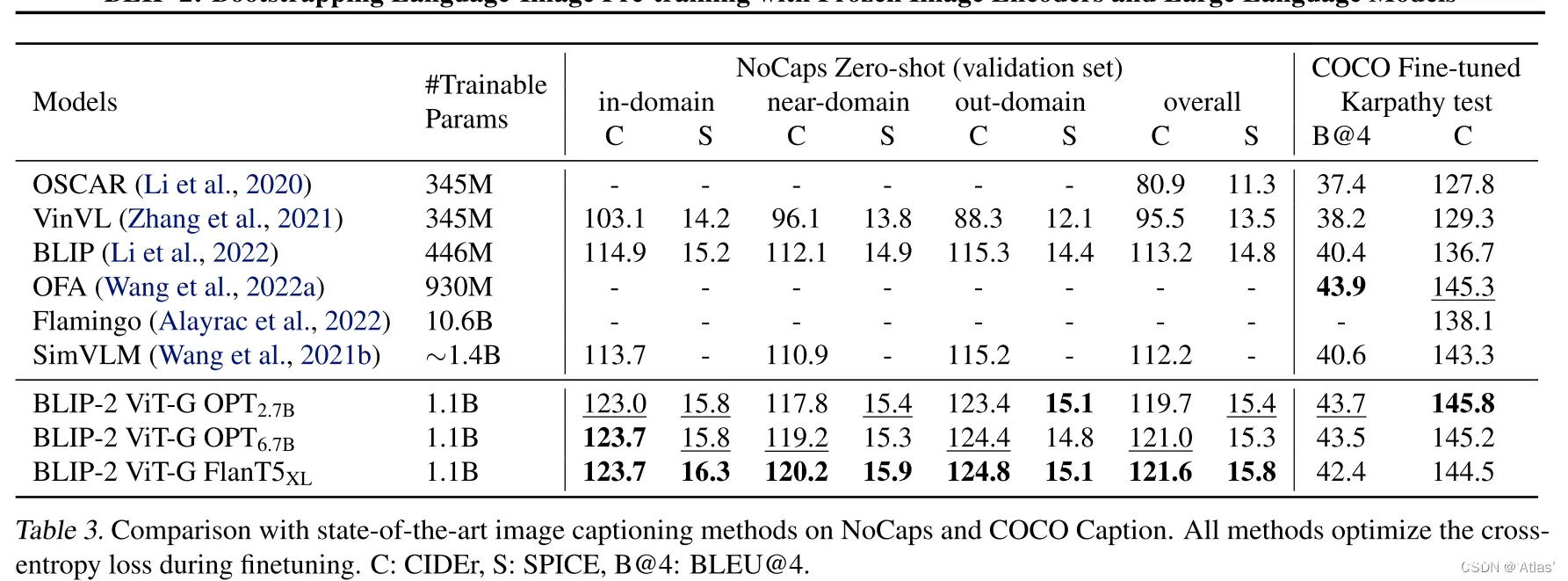
视觉问答
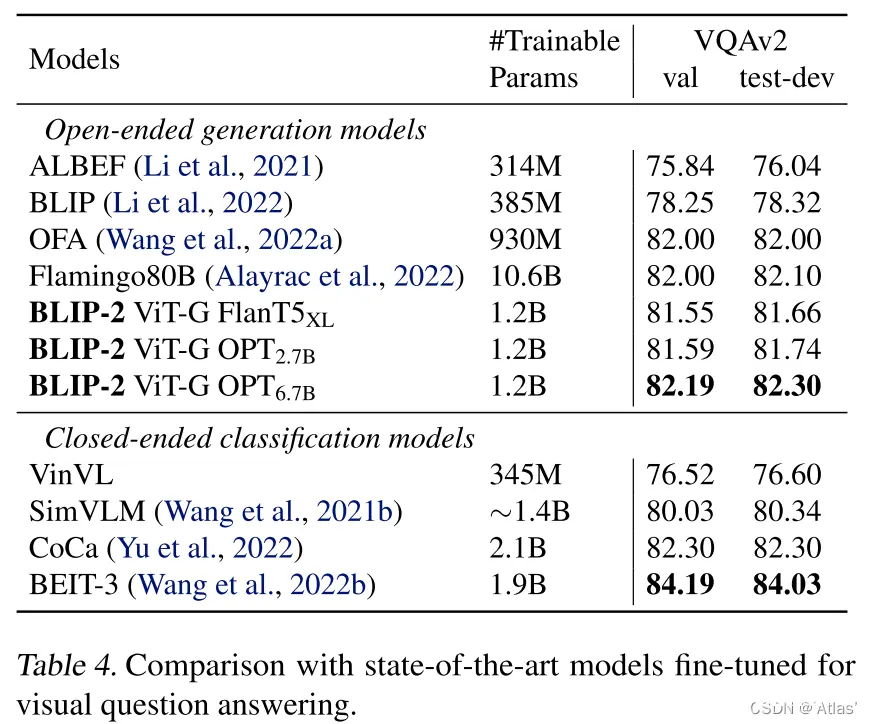
Q-Former的输出以及question作为LLM的输入,LLM生成对应answer,为了提取与问题相关图像特征,作者将question输入Q-Former,通过self-attention层与query进行交互,引导Q-Former的cross-attention层更加关注图中有效区域。表4表明BLIP-2在开放式生成模型中达到SOTA。
图像文本检索
图文检索不需要语言模型,作者在COCO数据集将图像编码器与Q-Former一起进行finetune,在COCO及Flickr30K数据集进行图像文本检索以及文本图像检索,作者首先根据图文特征相似度挑选128个样本,而后根据ITM score进行排序。
如表5,BLIP-2在零样本图文检索达到SOTA,相对现有方法,得到显著提升。
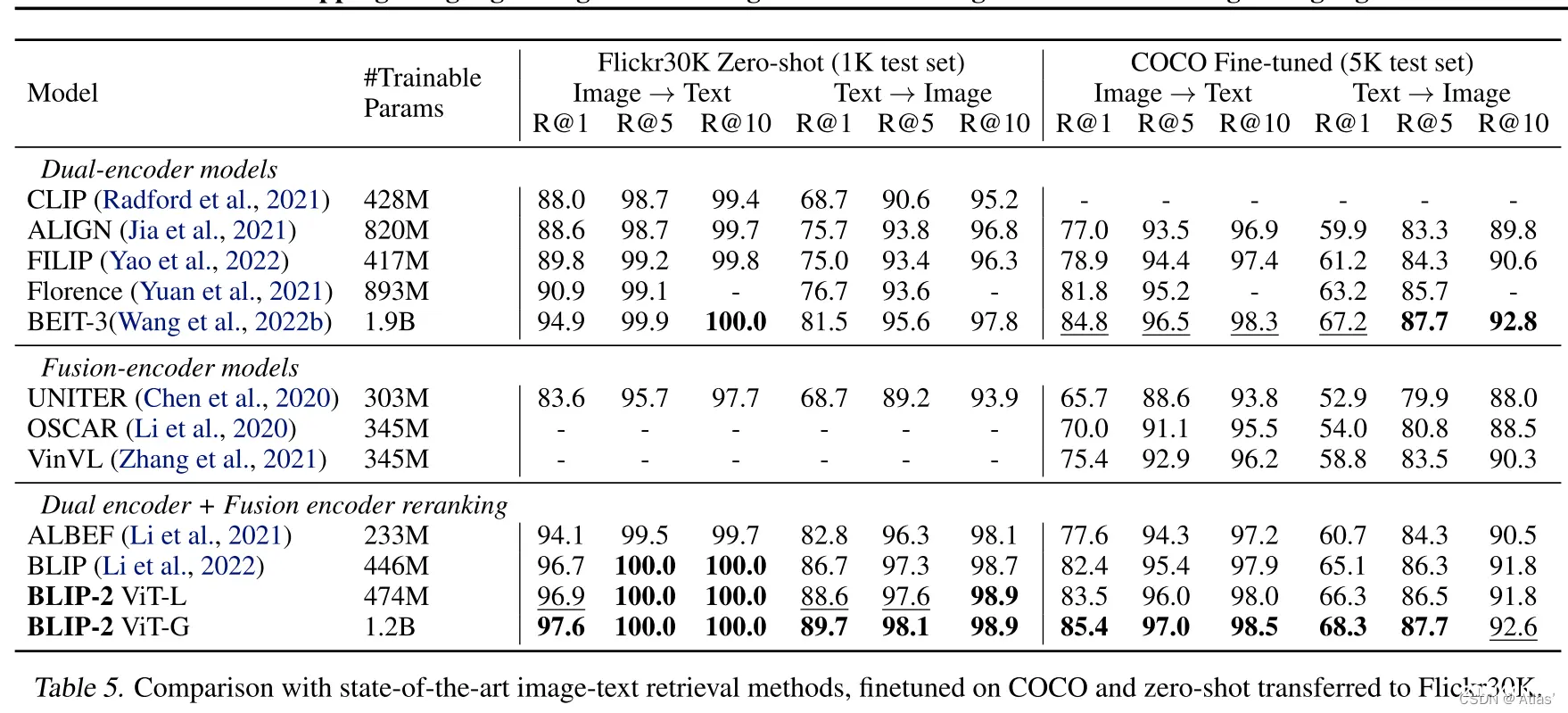
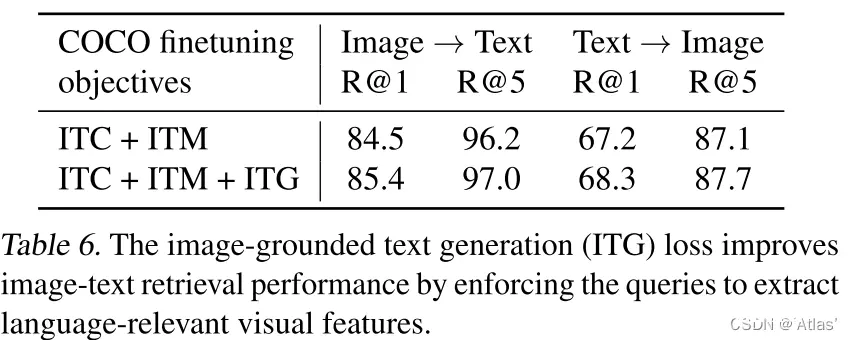
表6表明ITG损失对图文检索也有帮助,由于ITG损失版主query提取与文本相关视觉特征。
限制
当LLM模型使用上下文VQA样本时,BLIP-2并未在VQA任务上提升性能,作者归因于预训练数据集为仅有一对图像文本样本,无法学习一个序列中多个图像文本对之间相关性。
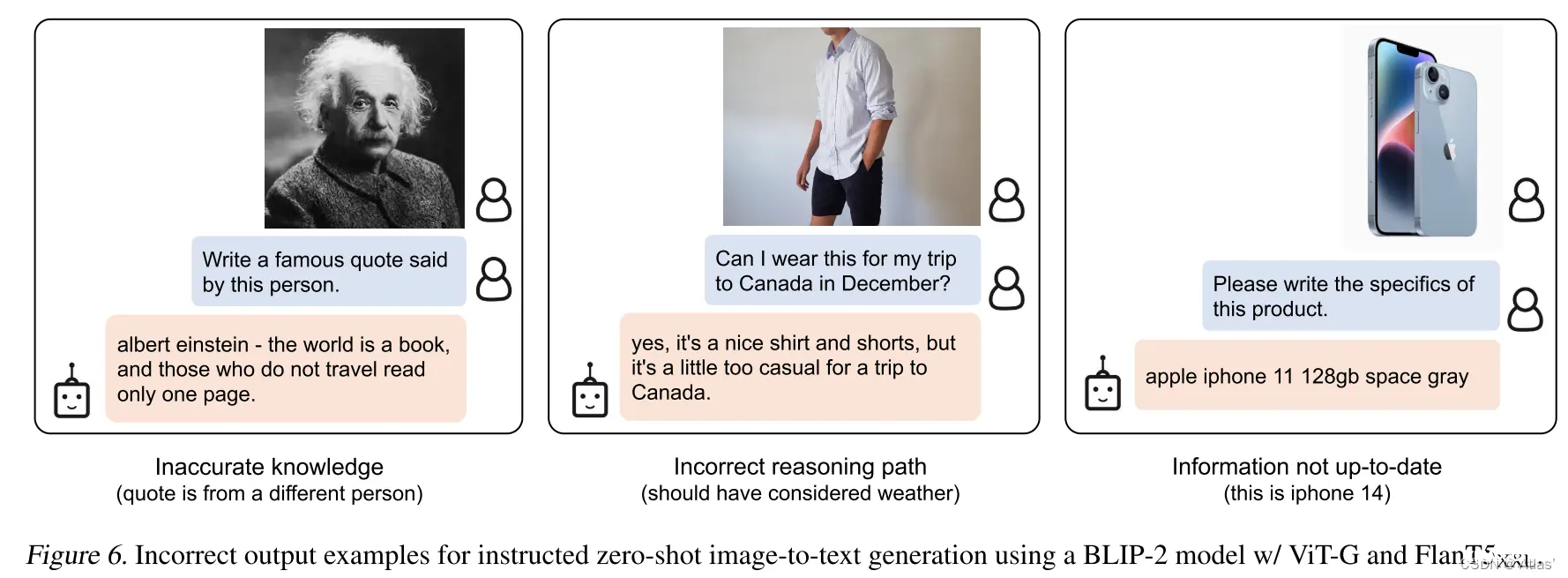
BLIP-2在图像文本生成任务仍存在一些不足:LLM不准确知识,不正确推理路径、对于一些新图像缺少相关信息,如图6所示。
结论
BLIP-2是一种通用且计算高效的视觉语言预训练方案,使用frozen 预训练图像编码器及LLM,在多个视觉语言任务达到SOTA,也证明了其在零样本instructed image-to-text生成能力。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。