屌炸的文本转语音AI——ChatTTS本地部署教程
vscene 2024-06-29 12:01:03 阅读 63
目录
1. 本地部署准备
1.1 下载 ChatTTS 代码
将代码库拷贝到本地,注意要在英文目录下
1.2 通过 modelscope 下载ChatTTS模型
2. 验证
2.1用 jupyter 验证
2.2 编写ttsollama.py代码
2.3 运行 ttsollama.py
2024年5月28日 开源的 ChatTTS 截至 6月5日 20.2k 星
ChatTTS:开源领域最强的文本到语音转换(TTS)模型!它允许用户将文本转换为语音。该模型主要面向学术研究和教育目的,不适用于商业或法律用途。它使用深度学习技术,能够生成自然流畅的语音输出,适合研究和开发语音合成技术的人员使用。
带有情绪控制语音堪比真人,可以方便制作有声小说,如果应用在线对话中很难分辨是否是真人。
在线体验地址:https://huggingface.co/2Noise/ChatTTS
1. 本地部署准备
国内镜像库地址:https://gitee.com/vscene/ChatTTS
1.1 下载 ChatTTS 代码
将代码库拷贝到本地,注意要在英文目录下
> git clone https://gitee.com/vscene/ChatTTS
> cd ChatTTS
> dir
1.2 通过 modelscope 下载ChatTTS模型
运行 python 并输入如下代码, 或者创建 download.py 并输入如下代码( python download.py进行下载)
from modelscope import snapshot_download
model_dir = snapshot_download('pzc163/chatTTS')
如果报错:ModuleNotFoundError: No module named 'modelscope'
说明没有安装 modelscope .
通过conda 创建 ChatTTS 环境 ,如果没有安装conda 请参考
手撸私有AI大模型——开发环境搭建miniconda_开发ai私有模型-CSDN博客
# 创建 ChatTTS python 运行环境,python 默认安装 3.11.5
> conda create -n ChatTTS
# 安装 modelscope
> pip install modelscope
下载完的模型数据默认在 C:\Users\Administrator\.cache\modelscope\hub\pzc163\chatTTS 目录
将 chatTTS 目录拷贝 到 ChatTTS 代码目录并覆盖其下的 "ChatTTS"目录
安装环境库依赖
> pip install -r requirements.txt
> pip install ChatTTS transformers torch omegaconf vocos openai IPython
2. 验证
2.1用 jupyter 验证
打开 vscode (需要安装jupyter 插件)
#在 git clone ChatTTS 目录下运行 code . [code 点] 命令启动 vscode
# 注意当前需要在 ChatTTS 的 conda 环境下
(ChatTTS) d:\code\ChatTTS > code.
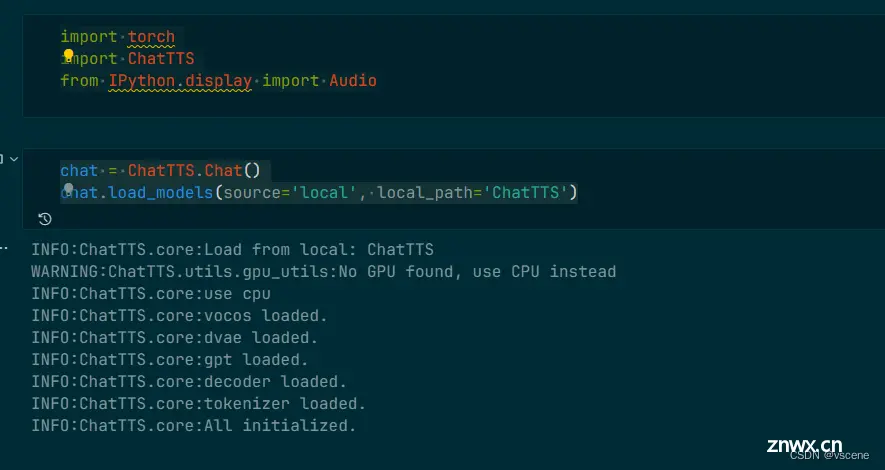
import torch
import ChatTTS
from IPython.display import Audio
chat = ChatTTS.Chat()
chat.load_models(source='local', local_path='ChatTTS')
执行效果
texts = ["What’s your name?",]*3 \
+ ["我是嫦娥六号,目前正在月亮上工作。"]*3 \
+["床前明月光,疑似地上霜。举头望明月,低头思故乡。"]
wavs = chat.infer(texts, use_decoder=True)
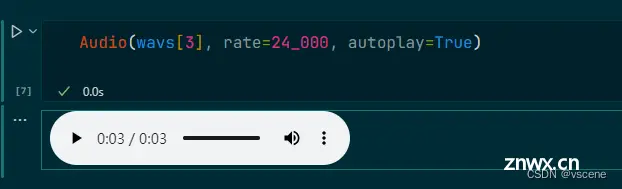
播放文本转语音结果 0-2 是 第一句, 3-5第二句,6是第三句
Audio(wavs[0], rate=24_000, autoplay=True)
Audio(wavs[3], rate=24_000, autoplay=True)
改变 wavs[?] 输出不同的声音
Audio(wavs[4], rate=24_000, autoplay=True)
Audio(wavs[6], rate=24_000, autoplay=True)
2.2 编写ttsollama.py代码
首先需要保证ollama 已经在本地运行. http://localhost:11434 可以正常访问
编写 ttsollama.py 代码
(这里用的是 qwen:7b 模型,如何部署ollama 和 qwen:7b 模型,可参考 之前的文档)
手撸私有AI大模型——ollama本地部署私有大模型_ollama 下载-CSDN博客
import torch
import ChatTTS
from IPython.display import Audio
import scipy
import numpy as np
chat = ChatTTS.Chat()
chat.load_models(source='local', local_path='ChatTTS')
def deterministic(seed=2222):
torch.manual_seed(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
from ChatTTS.experimental.llm import OllamaAPI
user_question = '用中文简单介绍北京中轴线'
texts = ["北京中轴线,是指北京自元大都、明清北京城以来北京城市东西对称布局建筑物的对称轴,北京市诸多其它建筑物亦位于此条轴线上。明清北京城的中轴线南起永定门,北至钟鼓楼直线距离长约7.8公里。"]
ollama_api = OllamaAPI(base_url="http://localhost:11434", model="qwen:7b")
text = ollama_api.call(user_question, prompt_version='deepseek')
text = ollama_api.call(text, prompt_version='deepseek_TN')
spk_stat = torch.load('ChatTTS/asset/spk_stat.pt')
rand_spk = torch.randn(768) * spk_stat.chunk(2)[0] + spk_stat.chunk(2)[1]
params_infer_code = {'spk_emb': rand_spk, 'temperature': .3}
params_refine_text = {'prompt': '[oral_2][laugh_1][break_6]'}
# 将infer函数中的文本参数替换为从LLM获取的text
wav = chat.infer(texts,
params_refine_text=params_refine_text, params_infer_code=params_infer_code)
Audio(wav[0], rate=24_000, autoplay=True)
# 导出音频
scipy.io.wavfile.write(filename = "./result.wav", rate = 24_000, data = wav[0].T)
在 experimental 目录下 创建 llm.py代码
from openai import OpenAI
prompt_dict = {
'deepseek': [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "你好,请注意你现在生成的文字要按照人日常生活的口吻,你的回复将会后续用TTS模型转为语音,并且请把回答控制在100字以内。并且标点符号仅包含逗号和句号,将数字等转为文字回答。"},
{"role": "assistant", "content": "好的,我现在生成的文字将按照人日常生活的口吻, 并且我会把回答控制在一百字以内, 标点符号仅包含逗号和句号,将阿拉伯数字等转为中文文字回答。下面请开始对话。"},],
'deepseek_TN': [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "你好,现在我们在处理TTS的文本输入,下面将会给你输入一段文本,请你将其中的阿拉伯数字等等转为文字表达,并且输出的文本里仅包含逗号和句号这两个标点符号"},
{"role": "assistant", "content": "好的,我现在对TTS的文本输入进行处理。这一般叫做text normalization。下面请输入"},
{"role": "user", "content": "We paid $123 for this desk."},
{"role": "assistant", "content": "We paid one hundred and twenty three dollars for this desk."},
{"role": "user", "content": "详询请拨打010-87124653"},
{"role": "assistant", "content": "详询请拨打零幺零,八七壹二四六五三"},
{"role": "user", "content": "罗森宣布将于7月24日退市,在华门店超6000家!"},
{"role": "assistant", "content": "罗森宣布将于七月二十四日退市,在华门店超过六千家。"},
],
}
# Ollama API
class OllamaAPI:
def __init__(self, base_url, model):
self.base_url = base_url
self.model = model
def call(self, user_question, temperature=0.3, prompt_version='kimi', **kwargs):
import requests
headers = {
'Content-Type': 'application/json',
}
data = {
"model": self.model,
"messages": prompt_dict[prompt_version] + [{"role": "user", "content": user_question}],
"temperature": temperature,
**kwargs
}
response = requests.post(self.base_url + "/v1/chat/completions", headers=headers, json=data)
response_data = response.json()
if response.status_code == 200:
return response_data['choices'][0]['message']['content']
else:
raise Exception(f"Error: {response_data}")
2.3 运行 ttsollama.py
# 运行 ttsollama.py 输出 result.wav
>python ttsollama.py
物理机只有CPU跑的比较慢, 但是本地部署免费 :)
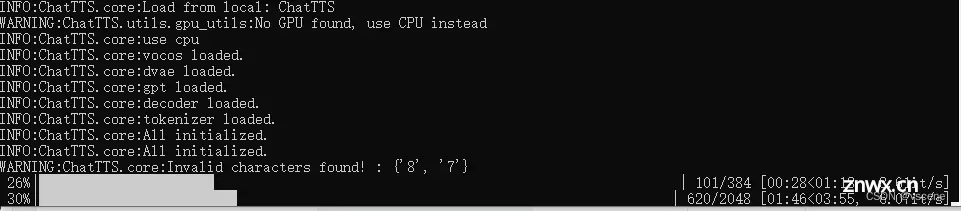
测试的结果7.8 公里中的 数字 7 和8 没有识别的很好
上一篇: 大数据毕业设计hadoop+spark+hive知识图谱新能源汽车数据分析可视化大屏 汽车推荐系统 新能源汽车推荐系统 汽车爬虫 汽车大数据 机器学习 人工智能 计算机毕业设计 Python毕业设计
下一篇: ChatPPT开启高效办公新时代,AI赋能PPT创作
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。