
使用docker集成vllm实现模型推理加速,并使用Tools(工具)增强模型的能力和准确性...

本文探讨了评估LLM输出结果的一些技术,从人工评估到自动化评估。其中:一方面,自动化评估的时间成本效率更高,在某些情况下是非常实用的选择,例如在早期原型设计阶段。另一方面,人工评估仍然是获得模型应用准确性和实用性...

如果你已探索过豆包Ai、Kimi、智谱清言等生成式AI工具,那么你对“prompt”(提示词)这一核心概念一定有自己的认知和理解。这里所谓的提示词,其实就是人和AI交互时的输入,是连接你与AI创意源泉的桥梁,“pro...

通过vLLM的Docker镜像,快速体验Qwen2-VL-7B-Instruct推理效果_qwen2-vldocker部署...
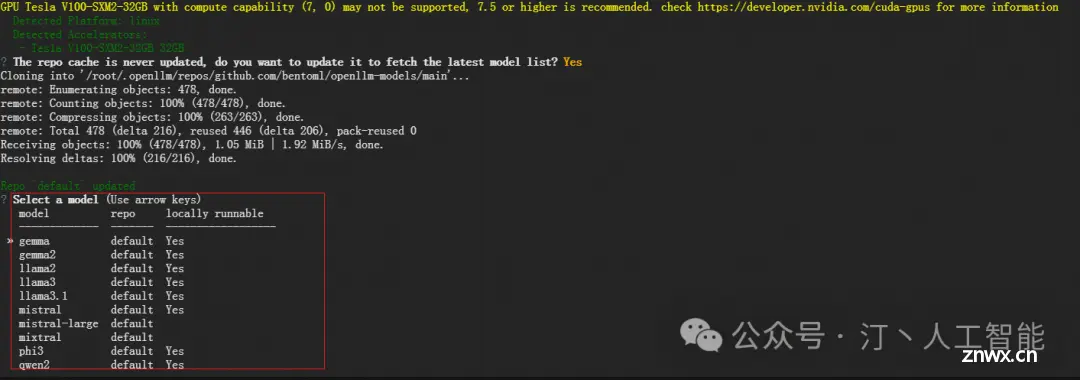
Ollama是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。,这是Ollama的官网地址:https://ollama.com/以下是其主要特点和功能概述:1简化部署:Ollama...

编写符合行业规范的代码是一项重要的专业技能!_vscode代码格式化...
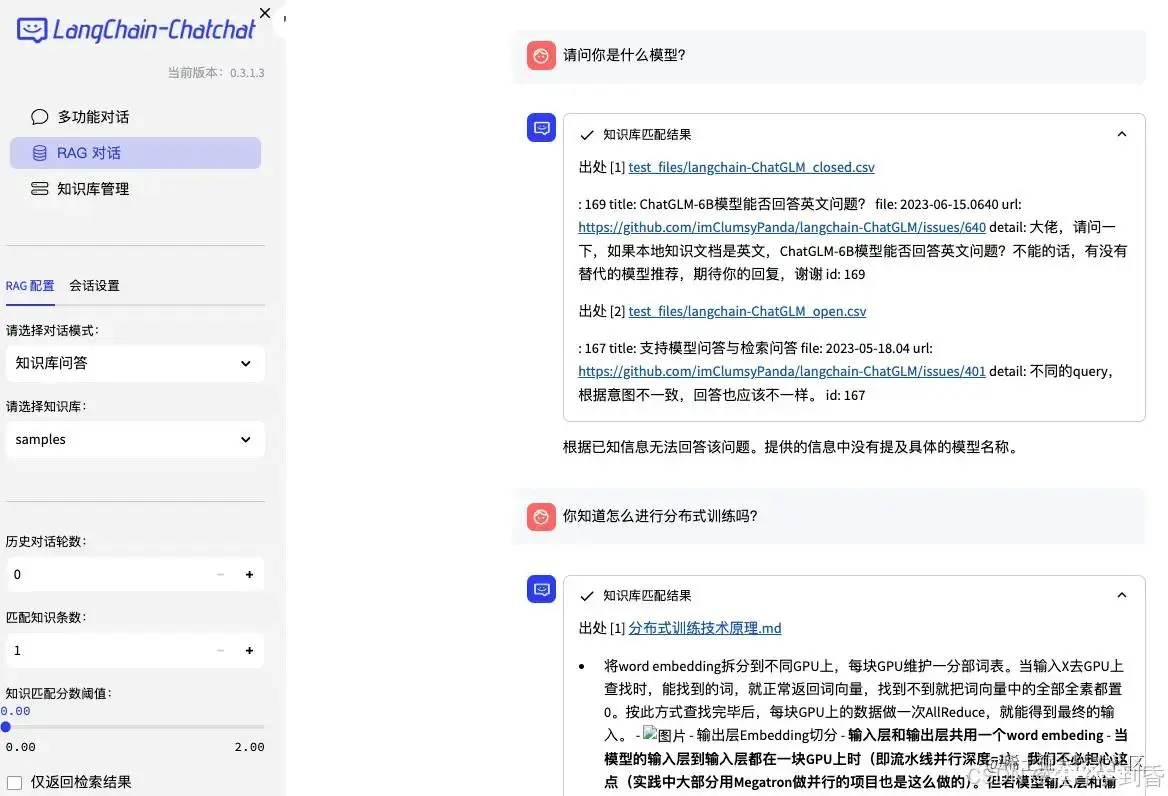
【LLM大模型】Langchain-Chatchat源码部署测试_langchain-chatchat...
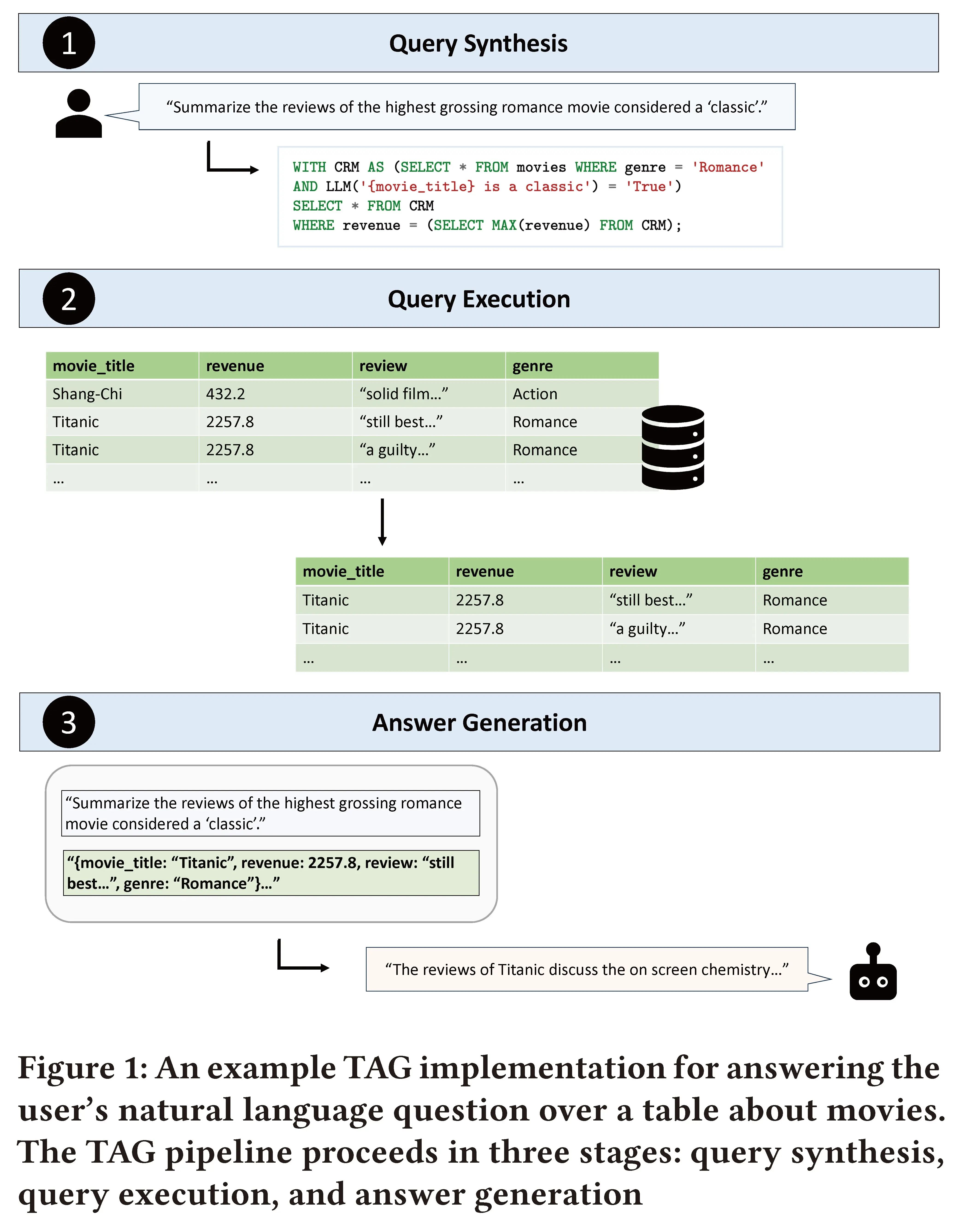
LLMs之SQL:《Text2SQLisNotEnough:UnifyingAIandDatabaseswithTAG》翻译与解读目录《Text2SQLisNotEnough:Unif...

样本数量一般1万左右的高质量样本即可达到良好效果。对于简单任务,100-300条数据足够;中等难度任务需1000条以上;高难度任务需3000条甚至更多,可能达到10万条。样本质量样本质量优先于数量,高质量样本更有效。需...

环境搭建系统环境需要Nvidia显卡,至少8G显存,且专用显存与共享显存之和大于20G建议将非安装版的环境文件都放到非系统盘,方便重装或移植以Windows11为例,非安装环境文件都放在E盘下设置自定义Path文件夹创建E:\mypath文...