
深度强化学习本文介绍:[Python]深度Q网络(DQN)实现[Python]REINFORCE算法实现[Results]运行结果随着深度学习的迅猛发展,深度强化学习(DeepReinforcement...

强化学习笔记之【DDPG算法】目录强化学习笔记之【DDPG算法】前言:原论文伪代码DDPG中的四个网络代码核心更新公式前言:本文为强化学习笔记第二篇,第一篇讲的是Q-learning和DQN就是因为DDPG引入了Actor-Critic模型,所以比D...

强化学习笔记之【Q-learning算法和DQN算法】前言:强化学习领域,繁冗复杂的大段代码里面,核心的数学公式往往只有20~40行,剩下的代码都是为了应用这些数学公式而服务的这可比遥感图像难太多了,乱七八糟的数学公式看得头大本文初编辑于2024.10...

2024年ICML文章,ACE:Off-PolicyActor-CriticwithCausality-AwareEntropyRegularization精读...

本项目旨在通过深度强化学习(DRL)技术,使智能体(Agent)能够自主学习并控制《吃豆人》游戏中的主角,以高效的方式吃掉所有豆子并避免被幽灵捕获。我们将使用深度学习网络(如卷积神经网络CNN)结合强化学习算法(如Q...

强化学习笔记之【SAC算法】前言:本文为强化学习笔记第四篇,第一篇讲的是Q-learning和DQN,第二篇DDPG,第三篇TD3TD3比DDPG少了一个target_actor网络,其它地方有点小改动CSDN主页:https://blog.csdn....

IsaacLab系列第三章,创建强化学习环境_isaaclab从入门到精通...

通过对Q-learning和PPO算法的深入剖析,可以看到强化学习的核心在于通过与环境的持续交互,智能体能够不断调整其策略或值函数,以实现最优决策。Q-learning通过更新Q表来找到最优策略,而...

本文详细介绍了强化学习的基础知识和基本算法,包括动态规划、蒙特卡洛方法和时序差分学习,解析了其核心概念、算法步骤及实现细节。关注作者,复旦AI博士,分享AI领域全维度知识与研究。拥有10+年AI领域研究经验、复旦机器人智能实验室成员,国家级大学生赛...
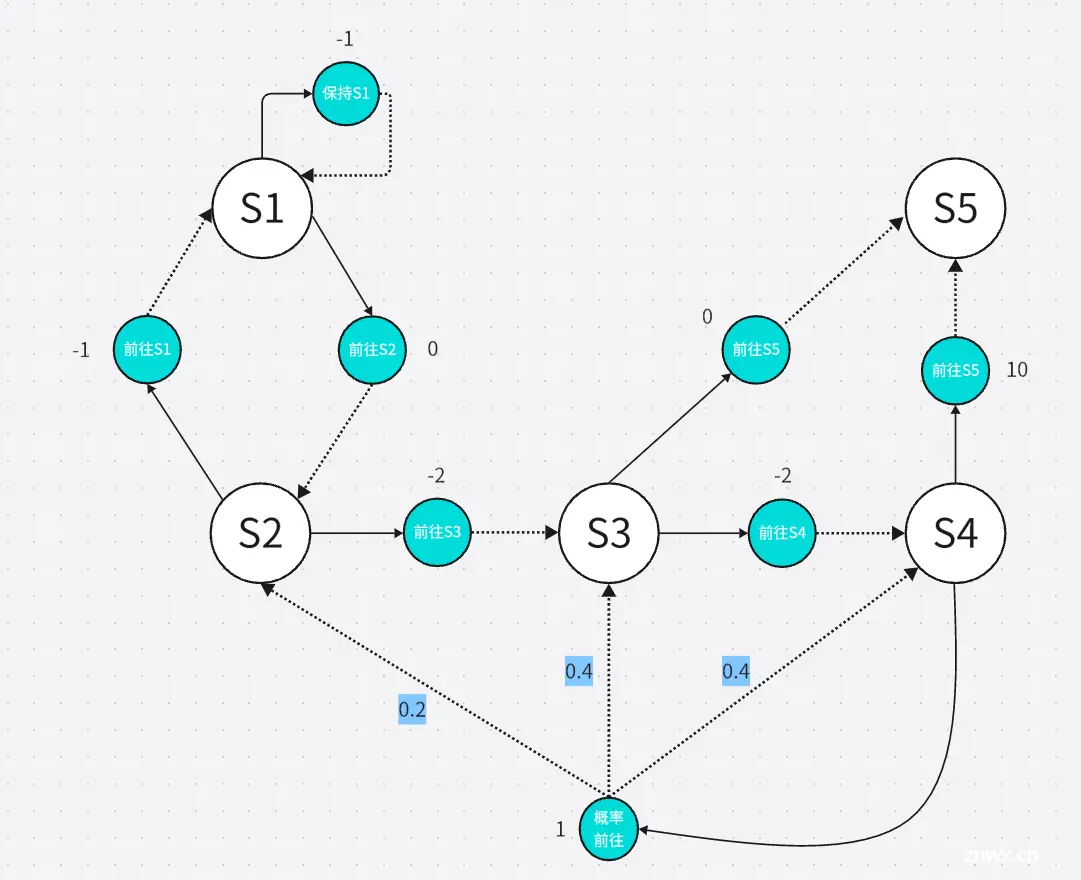
本文介绍了马尔可夫决策过程,其中包括了马尔可夫过程,马尔可夫奖励过程,马尔可夫决策过程,蒙特卡洛方法,占用度量等等知识,并附上具体实现的python代码_mdp代码...