强化学习笔记之【ACE:Off-PolicyActor-CriticwithCausality-AwareEntropyRegularization】
cnblogs 2024-10-17 16:13:00 阅读 80

2024年ICML文章,ACE:Off-PolicyActor-CriticwithCausality-AwareEntropyRegularization精读
强化学习笔记之【ACE:Off-PolicyActor-CriticwithCausality-AwareEntropyRegularization】
目录
- 强化学习笔记之【ACE:Off-PolicyActor-CriticwithCausality-AwareEntropyRegularization】
- 前言:
- 论文一览
- 论文摘要
- 论文主要贡献:
- 论文代码框架
- 1. 初始化模块
- 2. 因果发现模块
- 3. 策略优化模块
- 4. 重置机制模块
- 论文源代码主干
- 代码流程解释
- 论文模块代码及实现
- 因果发现模块
- 策略优化模块
- 1. 采样经验数据
- 2. 计算目标 Q 值
- 3. 更新 Q 网络
- 4. 策略网络更新
- 5. 自适应熵调节
- 6. 返回值
- 重置机制模块
- 重置逻辑
- 重置机制模块的原理
- 1. 计算梯度主导度 ( $\beta_\gamma $)
- 2. 软重置策略和 Q 网络
- 3. 策略和 Q 优化器的重置
- 4. 重置机制模块的应用
- a. 重置间隔达成时
- b. 主导梯度或因果效应差异满足条件时
- c. 总结
- 扰动因子的计算
- 扰动因子(factor)
- 组合扰动因子的公式
- 评估代码
- 1. 定期评估条件
- 2. 初始化评估列表
- 3. 进行评估
- 3.1 回合初始化
- 3.2 执行智能体动作
- 3.3 存储回合奖励
- 4. 计算平均奖励
- 5. 保存最佳模型
- 论文复现结果
前言:
至少先点个赞吧,写的很累的
该论文是清华项目组组内博士师兄写的文章,项目主页为ACE (ace-rl.github.io),于2024年7月发表在ICML期刊


因为最近组内(其实只有我)需要从零开始做一个相关项目,前面的几篇文章都是铺垫
本文章为强化学习笔记第5篇
本文初编辑于2024.10.5,好像是这个时间,忘记了,前后写了两个多星期
CSDN主页:https://blog.csdn.net/rvdgdsva
博客园主页:https://www.cnblogs.com/hassle
博客园本文链接:
论文一览
这篇强化学习论文主要介绍了一个名为 ACE 的算法,完整名称为 Off-Policy Actor-Critic with Causality-Aware Entropy Regularization,它通过引入因果关系分析和因果熵正则化来解决现有模型在不同动作维度上的不平等探索问题,旨在改进强化学习【注释1】中探索效率和样本效率的问题,特别是在高维度连续控制任务中的表现。
【注释1】:强化学习入门这一篇就够了
论文摘要
在policy【注释2】学习过程中,不同原始行为的不同意义被先前的model-free RL 算法所忽视。利用这一见解,我们探索了不同行动维度和奖励之间的因果关系,以评估训练过程中各种原始行为的重要性。我们引入了一个因果关系感知熵【注释3】项(causality-aware entropy term),它可以有效地识别并优先考虑具有高潜在影响的行为,以实现高效的探索。此外,为了防止过度关注特定的原始行为,我们分析了梯度休眠现象(gradientdormancyphenomenon),并引入了休眠引导的重置机制,以进一步增强我们方法的有效性。与无模型RL基线相比,我们提出的算法 ACE:Off-policyActor-criticwith Causality-awareEntropyregularization。在跨越7个域的29种不同连续控制任务中显示出实质性的性能优势,这强调了我们方法的有效性、多功能性和高效的样本效率。 基准测试结果和视频可在https://ace-rl.github.io/上获得。
【注释2】:强化学习算法中on-policy和off-policy
【注释3】:最大熵 RL:从Soft Q-Learning到SAC - 知乎
论文主要贡献:
【1】因果关系分析:通过引入因果政策-奖励结构模型,评估不同动作维度(即原始行为)对奖励的影响大小(称为“因果权重”)。这些权重反映了每个动作维度在不同学习阶段的相对重要性。
作出上述改进的原因是:考虑一个简单的例子,一个机械手最初应该学习放下手臂并抓住物体,然后将注意力转移到学习手臂朝着最终目标的运动方向上。因此,在策略学习的不同阶段强调对最重要的原始行为的探索是 至关重要的。在探索过程中刻意关注各种原始行为,可以加速智能体在每个阶段对基本原始行为的学习,从而提高掌握完整运动任务的效率。
此处可供学习的资料:
【2】因果熵正则化:在最大熵强化学习框架的基础上(如SAC算法),加入了因果加权的熵正则化项。与传统熵正则化不同,这一项根据各个原始行为的因果权重动态调整,强化对重要行为的探索,减少对不重要行为的探索。
作出上述改进的原因是:论文引入了一个因果策略-奖励结构模型来计算行动空间上的因果权重(causal weights),因果权重会引导agent进行更有效的探索, 鼓励对因果权重较大的动作维度进行探索,表明对奖励的重要性更大,并减少对因果权重较小的行为维度的探 索。一般的最大熵目标缺乏对不同学习阶段原始行为之间区别的重要性的认识,可能导致低效的探索。为了解决这一限制,论文引入了一个由因果权重加权的策略熵作为因果关系感知的熵最大化目标,有效地加强了对重要原始行为的探索,并导致了更有效的探索。
此处可供学习的资料:
【3】梯度“休眠”现象(Gradient Dormancy):论文观察到,模型训练时有些梯度会在某些阶段不活跃(即“休眠”)。为了防止模型过度关注某些原始行为,论文引入了梯度休眠导向的重置机制。该机制通过周期性地对模型进行扰动(reset),避免模型陷入局部最优,促进更广泛的探索。
作出上述改进的原因是:该机制通过一个由梯度休眠程度决定的因素间歇性地干扰智能体的神经网络。将因果关系感知探索与这种新颖的重置机制相结合,旨在促进更高效、更有效的探索,最终提高智能体的整体性能。
通过在多个连续控制任务中的实验,ACE 展示出了显著优于主流强化学习算法(如SAC、TD3)的表现:
- 29个不同的连续控制任务:包括 Meta-World(12个任务)、DMControl(5个任务)、Dexterous Hand(3个任务)和其他稀疏奖励任务(6个任务)。
- 实验结果表明,ACE 在所有任务中都达到了更好的样本效率和更高的最终性能。例如,在复杂的稀疏奖励场景中,ACE 凭借其因果权重引导的探索策略,显著超越了 SAC 和 TD3 等现有算法。
论文中的对比实验图表显示了 ACE 在多种任务下的显著优势,尤其是在稀疏奖励和高维度任务中,ACE 凭借其探索效率的提升,能更快达到最优策略。
论文代码框架
在ACE原论文的第21页,这玩意儿应该写在正篇的,害的我看了好久的代码去排流程
不过说实话这伪代码有够简洁的,代码多少有点糊成一坨了

这是一个强化学习(RL)算法的框架,具体是一个结合因果推断(Causal Discovery)的离策略(Off-policy)Actor-Critic方法。下面是对每个模块及其参数的说明:
1. 初始化模块
- Q网络 ( \(Q_\phi\) ):用于估计动作价值,(\phi) 是权重参数。
- 策略网络 ( $\pi_\theta $):用于生成动作策略,(\theta) 是其权重。
- 重放缓冲区 ($ D$ ):存储环境交互的数据,以便进行采样。
- 局部缓冲区 ( $D_c $):存储因果发现所需的局部数据。
- 因果权重矩阵 ($ B_{a \rightarrow r|s} $):用于捕捉动作与奖励之间的因果关系。
- 扰动因子 ( \(f\) ):用于对策略进行微小扰动,增加探索。
2. 因果发现模块
- 每 ( $$I$$ ) 步更新:
- 样本采样:从局部缓冲区 ( \(D_c\) ) 中抽样 ( \(N_c\) ) 条转移。
- 更新因果权重矩阵:调整 ($ B_{a \rightarrow r|s}$ ),用于反映当前策略和奖励之间的因果关系。
3. 策略优化模块
- 每个梯度步骤:
- 样本采样:从重放缓冲区 ( \(D\) ) 中抽样 ($ N$ ) 条转移。
- 计算因果意识熵 ( \(H_c(\pi(\cdot|s))\) ):衡量在给定状态下策略的随机性和确定性,用于修改策略。
- 目标 Q 值计算:更新目标 Q 值,用于训练 Q 网络。
- 更新 Q 网络:减少预测的 Q 值与目标 Q 值之间的误差。
- 更新策略网络:最大化当前状态下的 Q 值,以提高收益。
4. 重置机制模块
- 每个重置间隔:
- 计算梯度主导度 ( $\beta_\gamma $):用来量化策略更新的影响程度。
- 初始化随机网络:为新的策略更新准备初始权重 ( $\phi_i $)。
- 软重置策略和 Q 网络:根据因果权重进行平滑更新,帮助实现更稳定的优化。
- 重置策略和 Q 优化器:在重置时清空状态,以便进行新的学习过程。
论文源代码主干
源代码上千行呢,这里只是贴上main_casual里面的部分代码,并且删掉了很大一部分代码以便理清程序脉络
<code>def train_loop(config, msg = "default"):
# Agent
agent = ACE_agent(env.observation_space.shape[0], env.action_space, config)
memory = ReplayMemory(config.replay_size, config.seed)
local_buffer = ReplayMemory(config.causal_sample_size, config.seed)
for i_episode in itertools.count(1):
done = False
state = env.reset()
while not done:
if config.start_steps > total_numsteps:
action = env.action_space.sample() # Sample random action
else:
action = agent.select_action(state) # Sample action from policy
if len(memory) > config.batch_size:
for i in range(config.updates_per_step):
#* Update parameters of causal weight
if (total_numsteps % config.causal_sample_interval == 0) and (len(local_buffer)>=config.causal_sample_size):
causal_weight, causal_computing_time = get_sa2r_weight(env, local_buffer, agent, sample_size=config.causal_sample_size, causal_method='DirectLiNGAM')code>
print("Current Causal Weight is: ",causal_weight)
dormant_metrics = {}
# Update parameters of all the networks
critic_1_loss, critic_2_loss, policy_loss, ent_loss, alpha, q_sac, dormant_metrics = agent.update_parameters(memory, causal_weight,config.batch_size, updates)
updates += 1
next_state, reward, done, info = env.step(action) # Step
total_numsteps += 1
episode_steps += 1
episode_reward += reward
#* Ignore the "done" signal if it comes from hitting the time horizon.
if '_max_episode_steps' in dir(env):
mask = 1 if episode_steps == env._max_episode_steps else float(not done)
elif 'max_path_length' in dir(env):
mask = 1 if episode_steps == env.max_path_length else float(not done)
else:
mask = 1 if episode_steps == 1000 else float(not done)
memory.push(state, action, reward, next_state, mask) # Append transition to memory
local_buffer.push(state, action, reward, next_state, mask) # Append transition to local_buffer
state = next_state
if total_numsteps > config.num_steps:
break
# test agent
if i_episode % config.eval_interval == 0 and config.eval is True:
eval_reward_list = []
for _ in range(config.eval_episodes):
state = env.reset()
episode_reward = []
done = False
while not done:
action = agent.select_action(state, evaluate=True)
next_state, reward, done, info = env.step(action)
state = next_state
episode_reward.append(reward)
eval_reward_list.append(sum(episode_reward))
avg_reward = np.average(eval_reward_list)
env.close()
代码流程解释
初始化:
- 通过配置文件
config设置环境和随机种子。 - 使用
ACE_agent初始化强化学习智能体,该智能体会在后续过程中学习如何在环境中行动。 - 创建存储结果和检查点的目录,确保训练过程中的配置和因果权重会被记录下来。
- 初始化了两个重放缓冲区:
memory用于存储所有的历史数据,local_buffer则用于因果权重的更新。
- 通过配置文件
主训练循环:
采样动作:如果总步数较小,则从环境中随机采样动作,否则从策略中选择动作。通过这种方式,确保早期探索和后期利用。
更新因果权重:在特定间隔内,从局部缓冲区中采样数据,通过
get_sa2r_weight函数使用DirectLiNGAM算法计算从动作到奖励的因果权重。这个权重会作为额外信息,帮助智能体优化策略。更新网络参数:当
memory中的数据足够多时,开始通过采样更新Q网络和策略网络,使用计算出的因果权重来修正损失函数。记录与保存模型:每隔一定的步数,算法会测试当前策略的性能,记录并比较奖励是否超过历史最佳值,如果是,则保存模型的检查点。
使用
wandb记录训练过程中的指标,例如损失函数、奖励和因果权重的计算时间,这些信息可以帮助调试和分析训练过程。
论文模块代码及实现
因果发现模块
因果发现模块主要通过 get_sa2r_weight 函数实现,并且与 DirectLiNGAM 模型结合,负责计算因果权重。具体代码在训练循环中如下:
causal_weight, causal_computing_time = get_sa2r_weight(env, local_buffer, agent, sample_size=config.causal_sample_size, causal_method='DirectLiNGAM')code>
在这个代码段,get_sa2r_weight 函数会基于当前环境、样本数据(local_buffer)和因果模型(这里使用的是 DirectLiNGAM),计算与行动相关的因果权重(causal_weight)。这些权重会影响后续的策略优化和参数更新。关键逻辑包括:
- <li>采样间隔:因果发现是在
- 局部缓冲区:
local_buffer中存储了足够的样本(config.causal_sample_size),这些样本用于因果关系的发现。 - 因果方法:
DirectLiNGAM是选择的因果模型,用于从状态、行动和奖励之间推导出因果关系。
total_numsteps % config.causal_sample_interval == 0 时触发,确保只在指定的步数间隔内计算因果权重,避免每一步都进行因果计算,减轻计算负担。 因果权重计算完成后,程序会将这些权重应用到策略优化中,并且记录权重及计算时间等信息。
def get_sa2r_weight(env, memory, agent, sample_size=5000, causal_method='DirectLiNGAM'):code>
······
return weight, model._running_time
这个代码的核心是利用DirectLiNGAM模型计算给定状态、动作和奖励之间的因果权重。接下来,用LaTeX公式详细表述计算因果权重的过程:
- <li>
因果模型拟合:
将
X_ori转换为X是为了利用pandas数据框的便利性和灵活性使用 DirectLiNGAM 模型对矩阵 \(X\) 进行拟合,得到因果关系的邻接矩阵 \(A_{\text{model}}\):
\[A_{\text{model}} = \text{DirectLiNGAM}(X)
\]
该邻接矩阵表示状态、动作、奖励之间的因果结构,特别是从动作到奖励的影响关系。
提取动作对奖励的因果权重:
通过邻接矩阵提取动作对奖励的因果权重 \(w_{\text{r}}\),该权重从邻接矩阵的最后一行中选择与动作对应的元素:
\[w_{\text{r}} = A_{\text{model}}[-1, \, d_s:(d_s + d_a)]
\]
其中,\(d_s\) 是状态的维度,\(d_a\) 是动作的维度。
因果权重的归一化:
对因果权重 \(w_{\text{r}}\) 进行Softmax归一化,确保它们的总和为1:
\[w = \frac{e^{w_{\text{r},i}}}{\sum_{i} e^{w_{\text{r},i}}}
\]
调整权重的尺度:
最后,因果权重根据动作的数量进行缩放:
\[w = w \times d_a
\]
数据预处理:
将从memory中采样的states(状态)、actions(动作)和rewards(奖励)进行拼接,构建输入数据矩阵 \(X_{\text{ori}}\):
\[X_{\text{ori}} = [S, A, R]
\]
其中,\(S\) 代表状态,\(A\) 代表动作,\(R\) 代表奖励。接着,构建数据框 \(X\) 来进行因果分析。
最终输出的权重 \(w\) 表示每个动作对奖励的因果影响,经过归一化和缩放处理,可以用于进一步的策略调整或分析。
策略优化模块
以下是对函数工作原理的逐步解释:
策略优化模块主要由 agent.update_parameters 函数实现。agent.update_parameters 这个函数的主要目的是在强化学习中更新策略 (policy) 和价值网络(critic)的参数,以提升智能体的性能。这个函数实现了一个基于软演员评论家(SAC, Soft Actor-Critic)的更新机制,并且加入了因果权重与"休眠"神经元(dormant neurons)的处理,以提高模型的鲁棒性和稳定性。
critic_1_loss, critic_2_loss, policy_loss, ent_loss, alpha, q_sac, dormant_metrics = agent.update_parameters(memory, causal_weight, config.batch_size, updates)
通过 agent.update_parameters 函数,程序会更新以下几个部分:
- Critic网络(价值网络):
critic_1_loss和critic_2_loss分别是两个 Critic 网络的损失,用于评估当前策略的价值。 - Policy网络(策略网络):
policy_loss表示策略网络的损失,用于优化 agent 的行动选择。 - Entropy损失:
ent_loss用来调节策略的随机性,帮助 agent 在探索和利用之间找到平衡。 - Alpha:表示自适应的熵系数,用于调整探索与利用之间的权衡。
这些参数的更新在每次训练循环中被调用,并使用 wandb.log 记录损失和其他相关的训练数据。
update_parameters 是 ACE_agent 类中的一个关键函数,用于根据经验回放缓冲区中的样本数据来更新模型的参数。下面是对其工作原理的详细解释:
1. 采样经验数据
首先,函数从 memory 中采样一批样本(state_batch、action_batch、reward_batch、next_state_batch、mask_batch),其中包括状态、动作、奖励、下一个状态以及掩码,用于表示是否为终止状态。
state_batch, action_batch, reward_batch, next_state_batch, mask_batch = memory.sample(batch_size=batch_size)
state_batch:当前的状态。action_batch:在当前状态下执行的动作。reward_batch:执行该动作后获得的奖励。next_state_batch:执行动作后到达的下一个状态。mask_batch:掩码,用于表示是否为终止状态(1 表示非终止,0 表示终止)。
2. 计算目标 Q 值
利用当前策略(policy)网络,采样下一个状态的动作 next_state_action 和其对应的概率分布对数 next_state_log_pi。然后利用目标 Q 网络 critic_target 估计下一时刻的最小 Q 值,并结合奖励和折扣因子 \(\gamma\) 计算下一个 Q 值:
\[{min\_qf\_next\_target} = \min(Q_1^{\text{target}}(s', a'), Q_2^{{target}}(s', a')) - \alpha \cdot \log \pi(a'|s')
\\
{next\_q\_value} = r + \gamma \cdot \text{mask\_batch} \cdot {min\_qf\_next\_target}
\]
with torch.no_grad():
next_state_action, next_state_log_pi, _ = self.policy.sample(next_state_batch, causal_weight)
qf1_next_target, qf2_next_target = self.critic_target(next_state_batch, next_state_action)
min_qf_next_target = torch.min(qf1_next_target, qf2_next_target) - self.alpha * next_state_log_pi
next_q_value = reward_batch + mask_batch * self.gamma * (min_qf_next_target)
通过策略网络
self.policy为下一个状态next_state_batch采样动作next_state_action和相应的策略熵next_state_log_pi。使用目标 Q 网络计算
qf1_next_target和qf2_next_target,并取两者的最小值来减少估计偏差。最终使用贝尔曼方程计算
next_q_value,即当前的奖励加上折扣因子 \(\gamma\) 乘以下一个状态的 Q 值。这里,\(\alpha\) 是熵项的权重,用于平衡探索和利用的权衡,而
mask_batch是为了处理终止状态的情况。使用无偏估计来计算目标 Q 值。通过目标网络 (
critic_target) 计算出下一个状态和动作的 Q 值,并使用奖励和掩码更新当前 Q 值
3. 更新 Q 网络
接着,使用当前 Q 网络 critic 估计当前状态和动作下的 Q 值 \(Q_1\) 和 \(Q_2\),并计算它们与目标 Q 值的均方误差损失:
\[\text{qf1\_loss} = \text{MSE}(Q_1(s, a), \text{next\_q\_value})
\\
\text{qf2\_loss} = \text{MSE}(Q_2(s, a), \text{next\_q\_value})
\]
最终 Q 网络的总损失是两个 Q 网络损失之和:
\[\text{qf\_loss} = \text{qf1\_loss} + \text{qf2\_loss}
\]
然后,通过反向传播 qf_loss 来更新 Q 网络的参数。
qf1, qf2 = self.critic(state_batch, action_batch)
qf1_loss = F.mse_loss(qf1, next_q_value)
qf2_loss = F.mse_loss(qf2, next_q_value)
qf_loss = qf1_loss + qf2_loss
self.critic_optim.zero_grad()
qf_loss.backward()
self.critic_optim.step()
qf1和qf2是两个 Q 网络的输出,用于减少正向估计偏差。- 损失函数是 Q 值的均方误差(MSE),
qf1_loss和qf2_loss分别计算两个 Q 网络的误差,最后将两者相加为总的 Q 损失qf_loss。 - 通过
self.critic_optim优化器对损失进行反向传播和参数更新。
4. 策略网络更新
每隔若干步(通过 target_update_interval 控制),开始更新策略网络 policy。首先,重新采样当前状态下的策略 \(\pi(a|s)\),并计算 Q 值和熵权重下的策略损失:
\[\text{policy\_loss} = \mathbb{E}\left[ \alpha \cdot \log \pi(a|s) - \min(Q_1(s, a), Q_2(s, a)) \right]
\]
这个损失通过反向传播更新策略网络。
if updates % self.target_update_interval == 0:
pi, log_pi, _ = self.policy.sample(state_batch, causal_weight)
qf1_pi, qf2_pi = self.critic(state_batch, pi)
min_qf_pi = torch.min(qf1_pi, qf2_pi)
policy_loss = ((self.alpha * log_pi) - min_qf_pi).mean()
self.policy_optim.zero_grad()
policy_loss.backward()
self.policy_optim.step()
- 通过策略网络对当前状态
state_batch进行采样,得到动作pi及其对应的策略熵log_pi。 - 计算策略损失
policy_loss,即 \(\alpha\) 倍的策略熵减去最小的 Q 值。 - 通过
self.policy_optim优化器对策略损失进行反向传播和参数更新。
5. 自适应熵调节
如果开启了自动熵项调整(automatic_entropy_tuning),则会进一步更新熵项 \(\alpha\) 的损失:
\[\alpha_{\text{loss}} = -\mathbb{E}\left[\log \alpha \cdot (\log \pi(a|s) + \text{target\_entropy}) \right]
\]
并通过梯度下降更新 \(\alpha\)。
如果 automatic_entropy_tuning 为真,则会更新熵项:
if self.automatic_entropy_tuning:
alpha_loss = -(self.log_alpha * (log_pi + self.target_entropy).detach()).mean()
self.alpha_optim.zero_grad()
alpha_loss.backward()
self.alpha_optim.step()
self.alpha = self.log_alpha.exp()
alpha_tlogs = self.alpha.clone()
else:
alpha_loss = torch.tensor(0.).to(self.device)
alpha_tlogs = torch.tensor(self.alpha) # For TensorboardX logs
- 通过计算
alpha_loss更新self.alpha,调整策略的探索-利用平衡。
6. 返回值
qf1_loss,qf2_loss: 两个 Q 网络的损失policy_loss: 策略网络的损失alpha_loss: 熵权重的损失alpha_tlogs: 用于日志记录的熵权重next_q_value: 平均下一个 Q 值dormant_metrics: 休眠神经元的相关度量
重置机制模块
重置机制模块在代码中主要体现在 update_parameters 函数中,并通过梯度主导度 (dominant metrics) 和扰动函数 (perturbation functions) 实现对策略网络和 Q 网络的重置。
重置逻辑
函数根据设定的 reset_interval 判断是否需要对策略网络和 Q 网络进行扰动和重置。这里使用了"休眠"神经元的概念,即一些在梯度更新中影响较小的神经元,可能会被调整或重置。
函数计算了休眠度量 dormant_metrics 和因果权重差异 causal_diff,通过扰动因子 perturb_factor 来决定是否对网络进行部分或全部的扰动与重置。
重置机制模块的原理
重置机制主要由以下部分组成:
1. 计算梯度主导度 ( $\beta_\gamma $)
在更新策略时,计算主导梯度,即某些特定神经元或参数在更新中主导作用的比率。代码中通过调用 cal_dormant_grad(self.policy, type='policy', percentage=0.05)code> 实现这一计算,代表提取出 5% 的主导梯度来作为判断因子。
dormant_metrics = cal_dormant_grad(self.policy, type='policy', percentage=0.05)code>
根据主导度 ($ \beta_\gamma$ ) 和权重 ($ w$ ),可以得到因果效应的差异。代码里用 causal_diff 来表示因果差异:
\[\text{causal\_diff} = \max(w) - \min(w)
\]
2. 软重置策略和 Q 网络
软重置机制通过平滑更新策略网络和 Q 网络,避免过大的权重更新导致的网络不稳定。这在代码中由 soft_update 实现:
soft_update(self.critic_target, self.critic, self.tau)
具体来说,软更新的公式为:
\[\theta_{\text{target}} = \tau \theta_{\text{source}} + (1 - \tau) \theta_{\text{target}}
\]
其中,( \(\tau\) ) 是一个较小的常数,通常介于 ( [0, 1] ) 之间,确保目标网络的更新是缓慢的,以提高学习的稳定性。
3. 策略和 Q 优化器的重置
4. 重置机制模块的应用
每当经过一定的重置间隔时,判断是否需要扰动策略和 Q 网络。通过调用 perturb() 和 dormant_perturb() 实现对网络的扰动(perturbation)。扰动因子由梯度主导度和因果差异共同决定。
策略与 Q 网络的扰动会在以下两种情况下发生:
a. 重置间隔达成时
代码中每当更新次数 updates 达到设定的重置间隔 self.reset_interval,并且 updates > 5000 时,才会触发策略与 Q 网络的重置逻辑。这是为了确保扰动不是频繁发生,而是在经过一段较长的训练时间后进行。
具体判断条件:
if updates % self.reset_interval == 0 and updates > 5000:
b. 主导梯度或因果效应差异满足条件时
在达到了重置间隔后,首先会计算梯度主导度或因果效应的差异。这可以通过计算因果差异 causal_diff 或梯度主导度 dormant_metrics['policy_grad_dormant_ratio'] 来决定是否需要扰动。
梯度主导度计算方式通过
cal_dormant_grad()函数实现,如果梯度主导度较低,意味着网络中的某些神经元更新幅度过小,则需要对网络进行扰动。因果效应差异通过计算
causal_diff = np.max(causal_weight) - np.min(causal_weight)得到,如果差异过大,则可能需要重置。
然后根据这些值通过扰动因子 factor 进行判断:
factor = perturb_factor(dormant_metrics['policy_grad_dormant_ratio'])
如果扰动因子 ( \(\text{factor} < 1\) ),网络会进行扰动:
if factor < 1:
if self.reset == 'reset' or self.reset == 'causal_reset':
perturb(self.policy, self.policy_optim, factor)
perturb(self.critic, self.critic_optim, factor)
perturb(self.critic_target, self.critic_optim, factor)
c. 总结
- 更新次数达到设定的重置间隔,且经过了一定时间的训练(
updates > 5000)。 - 梯度主导度较低或因果效应差异过大,导致计算出的扰动因子 ( $\text{factor} < 1 $)。
这两种条件同时满足时,策略和 Q 网络将被扰动或重置。
扰动因子的计算
在这段代码中,factor 是基于网络中梯度主导度或者因果效应差异计算出来的扰动因子。扰动因子通过函数 perturb_factor() 进行计算,该函数会根据神经元的梯度主导度(dormant_ratio)或因果效应差异(causal_diff)来调整 factor 的大小。
扰动因子(factor)
扰动因子 factor 的计算公式如下:
\[\text{factor} = \min\left(\max\left(\text{min\_perturb\_factor}, 1 - \text{dormant\_ratio}\right), \text{max\_perturb\_factor}\right)
\]
其中:
(\(\text{dormant\_ratio}\)) 是网络中梯度主导度,即表示有多少神经元的梯度变化较小(或者接近零),处于“休眠”状态。
(\(\text{min\_perturb\_factor}\)) 是最小扰动因子值,代码中设定为
0.2。(\(\text{max\_perturb\_factor}\)) 是最大扰动因子值,代码中设定为
0.9。dormant_ratio:
- 表示网络中处于“休眠状态”的梯度比例。这个比例通常通过计算神经网络中梯度幅度小于某个阈值的神经元数量来获得。
dormant_ratio越大,表示越多神经元的梯度变化很小,说明网络更新不充分,需要扰动。
- 表示网络中处于“休眠状态”的梯度比例。这个比例通常通过计算神经网络中梯度幅度小于某个阈值的神经元数量来获得。
max_perturb_factor:
- 最大扰动因子值,用来限制扰动因子的上限,代码中设定为 0.9,意味着最大扰动幅度不会超过 90%。
min_perturb_factor:
- 最小扰动因子值,用来限制扰动因子的下限,代码中设定为 0.2,意味着即使休眠神经元比例很低,扰动幅度也不会小于 20%。
在计算因果效应的部分,扰动因子 factor 还会根据因果效应差异 causal_diff 来调整。causal_diff 是通过计算因果效应的最大值与最小值的差异来获得的:
\[\text{causal\_diff} = \max(\text{causal\_weight}) - \min(\text{causal\_weight})
\]
计算出的 causal_diff 会影响 causal_factor,并进一步对 factor 进行调整:
\[\text{causal\_factor} = \exp(-8 \cdot \text{causal\_diff}) - 0.5
\]
组合扰动因子的公式
最后,如果选择了因果重置(causal_reset),扰动因子将使用因果差异计算出的 causal_factor 进行二次调整:
\[\text{factor} = \text{perturb\_factor}(\text{causal\_factor})
\]
综上所述,factor 的最终值是由梯度主导度或因果效应差异来控制的,当休眠神经元比例较大或因果效应差异较大时,factor 会减小,导致网络进行扰动。
评估代码
这段代码主要实现了在强化学习(RL)训练过程中,定期评估智能体(agent)的性能,并在某些条件下保存最佳模型的检查点。我们可以分段解释该代码:
1. 定期评估条件
if i_episode % config.eval_interval == 0 and config.eval is True:
这部分代码用于判断是否应该执行智能体的评估。条件为:
i_episode % config.eval_interval == 0:表示每隔config.eval_interval个训练回合(i_episode是当前回合数)进行一次评估。config.eval is True:确保eval设置为True,也就是说,评估功能开启。
如果满足这两个条件,代码将开始执行评估操作。
2. 初始化评估列表
eval_reward_list = []
用于存储每个评估回合(episode)的累计奖励,以便之后计算平均奖励。
3. 进行评估
for _ in range(config.eval_episodes):
评估阶段将运行多个回合(由 config.eval_episodes 指定的回合数),以获得智能体的表现。
3.1 回合初始化
state = env.reset()
episode_reward = []
done = False
env.reset():重置环境,获得初始状态state。episode_reward:初始化一个列表,用于存储当前回合中智能体获得的所有奖励。done = False:用done来跟踪当前回合是否结束。
3.2 执行智能体动作
while not done:
action = agent.select_action(state, evaluate=True)
next_state, reward, done, info = env.step(action)
state = next_state
episode_reward.append(reward)
动作选择:
agent.select_action(state, evaluate=True)在评估模式下根据当前状态state选择动作。evaluate=True表示该选择是在评估模式下,通常意味着探索行为被关闭(即不进行随机探索,而是选择最优动作)。环境反馈:
next_state, reward, done, info = env.step(action)通过执行动作action,环境返回下一个状态next_state,当前奖励reward,回合是否结束的标志done,以及附加信息info。状态更新:当前状态被更新为
next_state,并将获得的奖励reward存储在episode_reward列表中。
循环持续,直到回合结束(即 done == True)。
3.3 存储回合奖励
eval_reward_list.append(sum(episode_reward))
当前回合结束后,累计奖励(sum(episode_reward))被添加到 eval_reward_list,用于后续计算平均奖励。
4. 计算平均奖励
avg_reward = np.average(eval_reward_list)
在所有评估回合结束后,计算 eval_reward_list 的平均值 avg_reward。这是当前评估阶段智能体的表现指标。
5. 保存最佳模型
if config.save_checkpoint:
if avg_reward >= best_reward:
best_reward = avg_reward
agent.save_checkpoint(checkpoint_path, 'best')
- 如果
config.save_checkpoint为True,则表示需要检查是否保存模型。 - 通过判断
avg_reward是否超过了之前的最佳奖励best_reward,如果是,则更新best_reward,并保存当前模型的检查点。
agent.save_checkpoint(checkpoint_path, 'best')
这行代码会将智能体的状态保存到指定的路径 checkpoint_path,并标记为 "best",表示这是性能最佳的模型。
论文复现结果
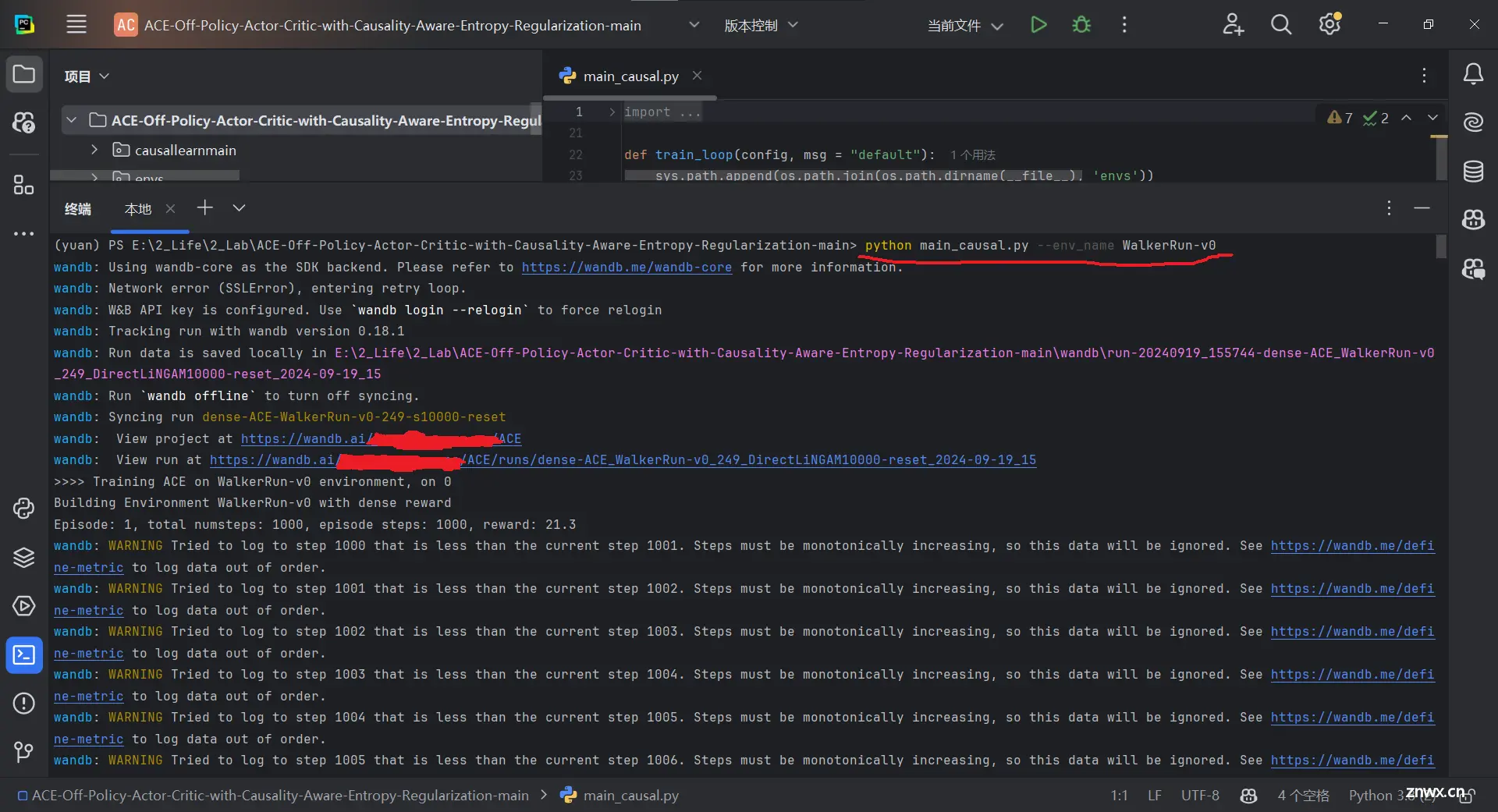
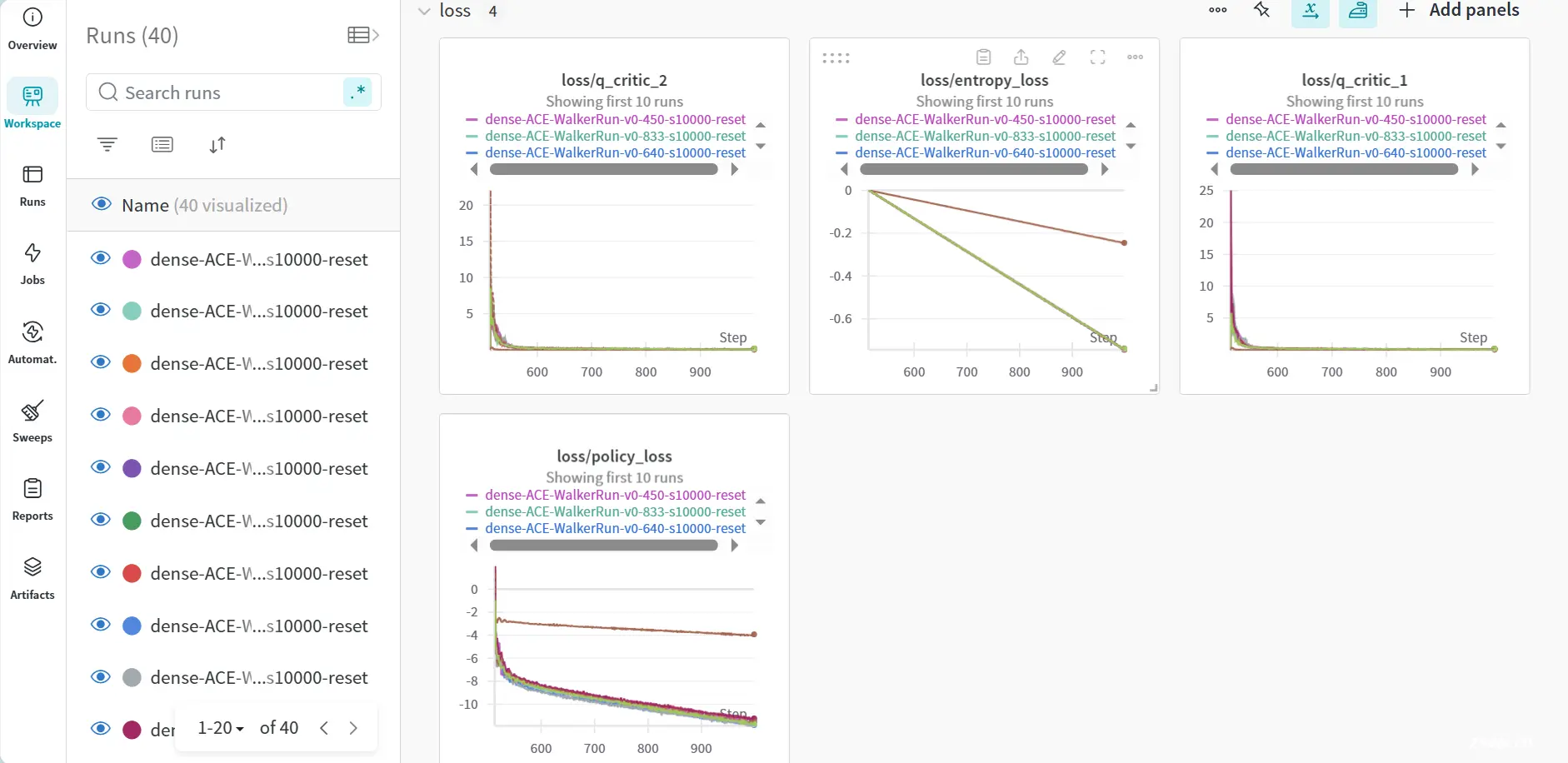
咳咳,可以发现程序只记录了 0~1000 的数据,从 1001 开始的每一个数据都显示报错所以被舍弃掉了。
后面重新下载了github代码包,发生了同样的报错信息
报错信息是:你在 X+1 轮次中尝试记载 X 轮次中的信息,所以这个数据被舍弃掉了
大概是主程序哪里有问题吧,我自己也没调 bug
不过这个项目结题了,主要负责这个项目的博士师兄也毕业了,也不好说些什么(虽然我有他微信),至少论文里面的模块挺有用的啊(手动滑稽)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。