Datawhale AI夏令营第四期魔搭-AIGC文生图方向Task1笔记
Hidewong 2024-08-10 13:01:01 阅读 64
不用写一行代码,只需要跟着步骤点点点,就可以完成task01!
本笔记可视作学习手册速通指南的扩充版本。
灰色的备注是关于该步骤的解释和拓展,可以先跳过,等走完所有步骤再回头看!
第一步 搭建代码环境
1.1 阿里云PAI-DSW申请
阿里云PAI-DSW(Data Science Workshop)是一个云端的开发工具平台,就像是你租用了一台非常强大的远程电脑主机。这台“主机”提供了你需要的一切工具和资源来创建和训练AI模型,不用担心你自己的电脑性能是否足够强大。
在本次比赛中,PAI-DSW的作用是:
训练模型: 使用PAI-DSW的计算能力,你可以训练你的LoRA模型,让它学会如何生成各种风格的图片。
管理项目: 在PAI-DSW上,你可以组织和管理你的项目文件和数据,包括代码的存放以及模型和输出的存储等。
所以,我们第一步需要进入阿里云PAI-DSW官网来开通领取5000算力时,为接下来环境的搭建等后续工作做准备。
点击任一红色箭头指向的蓝色链接
阿里云免费试用 - 阿里云
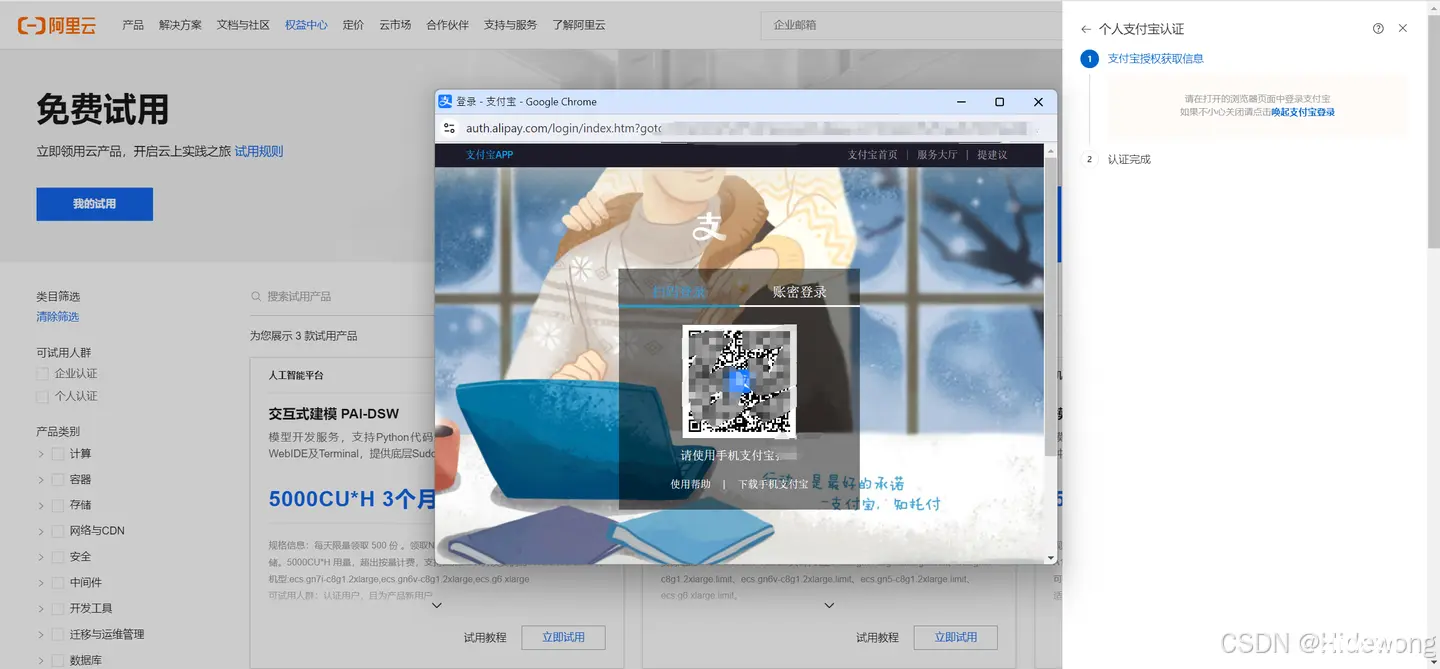
弹出窗口,打开支付宝扫码,点击授权
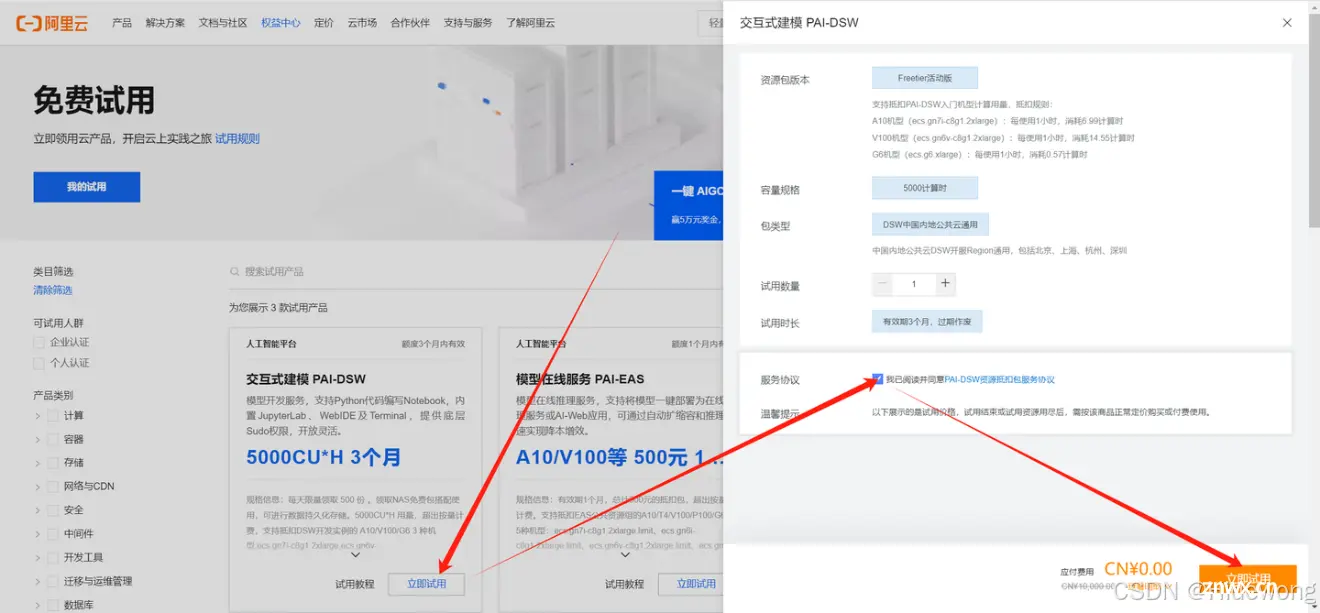
标回到原窗口,再次点击“立即试用”—>勾选—>“立即试用”题
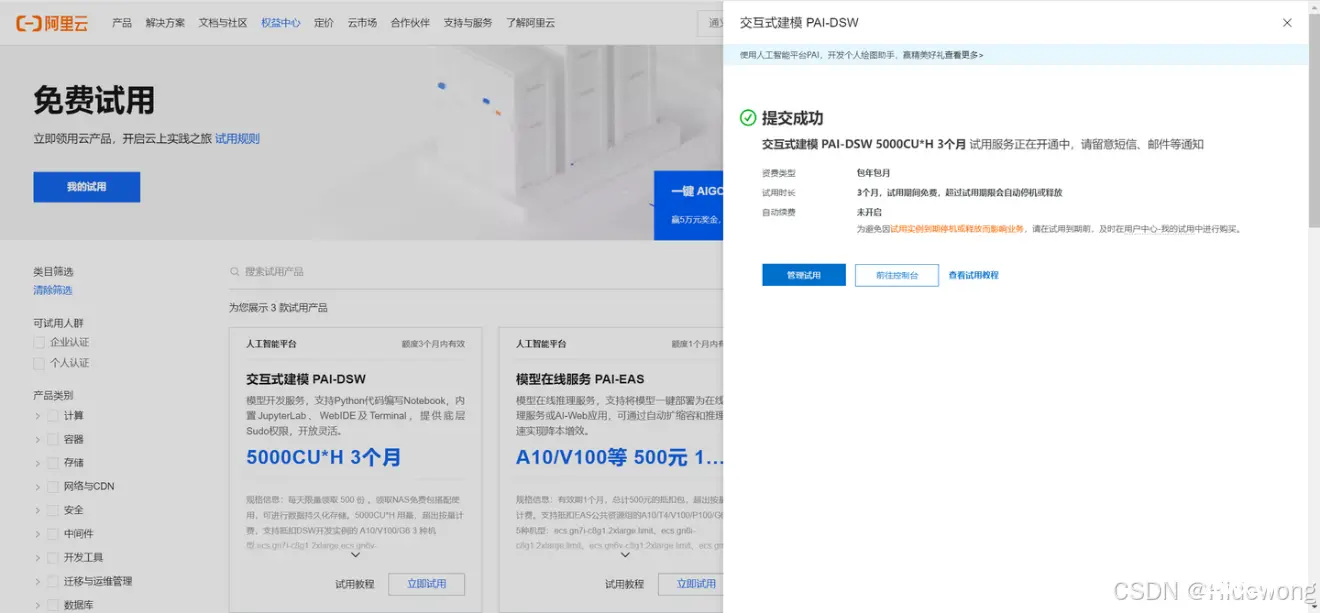
显示此界面即可关闭该网页
1.2 授权魔搭社区
魔搭社区(ModelScope)是阿里云推出的AI模型开源社区,旨在为开发者提供一站式的模型体验、下载、调优、训练、推理和部署服务。社区涵盖了广泛的AI模型和数据集,支持多模态(包括文本、图像、声音等)和多领域(如智能语音、图像处理、自然语言处理等)的应用。
魔搭社区类似于阿里云PAI-DSW这台性能强大的主机的操作系统。你可以在魔搭社区中创建和管理你的项目,进行模型训练等。
魔搭社区的作用:
创建PAI实例: 在魔搭社区中创建你的PAI实例,设置工作环境。
Notebook功能支持: 魔搭社区与阿里云合作,提供由阿里云支持的Notebook功能,方便你进行代码编写和模型训练。
上传和分享模型: 将你训练好的LoRA模型上传到魔搭社区,分享给评委和其他参赛者。
发布作品: 在魔搭社区的讨论区发布你的8图故事作品,展示你的图像风格和故事情节。
所以,接下来,我们来到魔搭社区官网,绑定阿里云PAI-DSW。
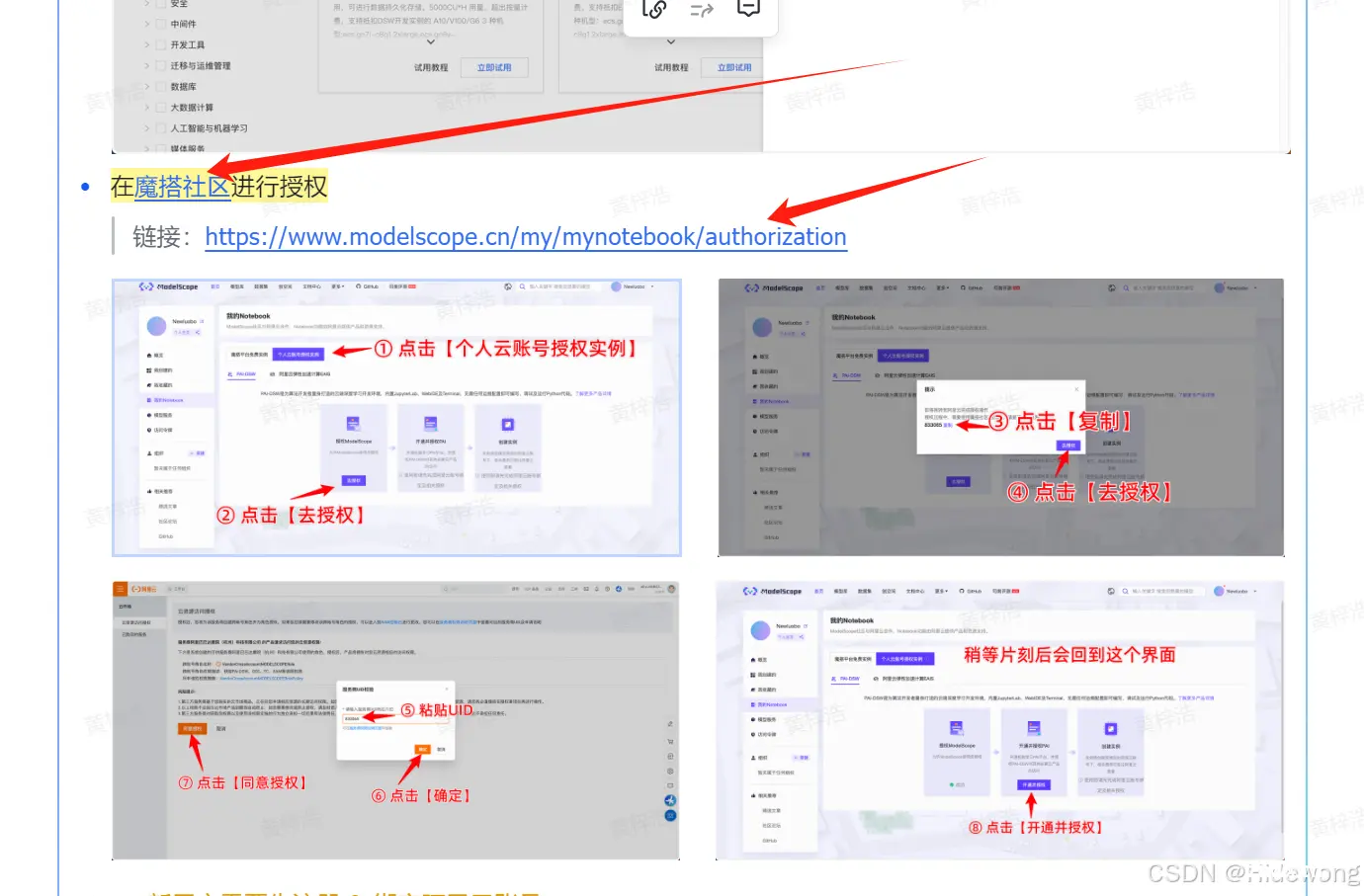
点击任一红色箭头指向的蓝色链接
魔搭社区
如果没有登录过就点击“登录/注册”,然后回到教程点击刚刚的蓝色链接
魔搭社区
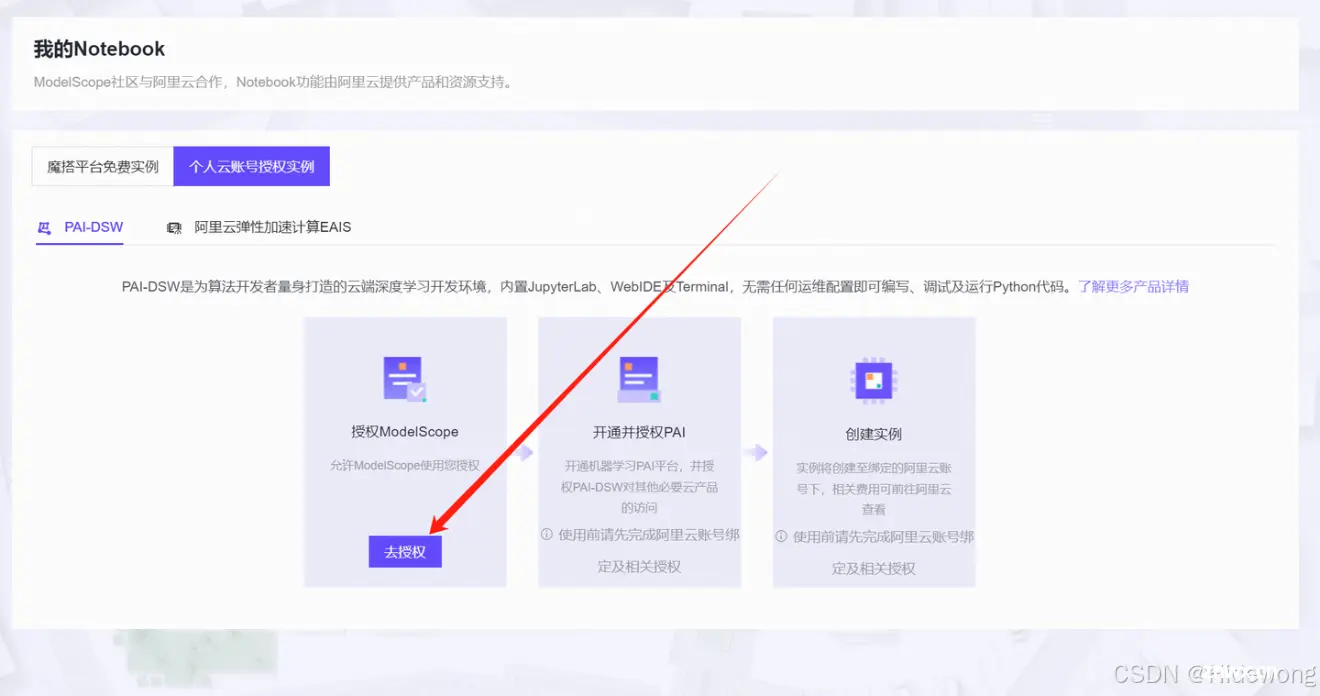
点击“去授权”
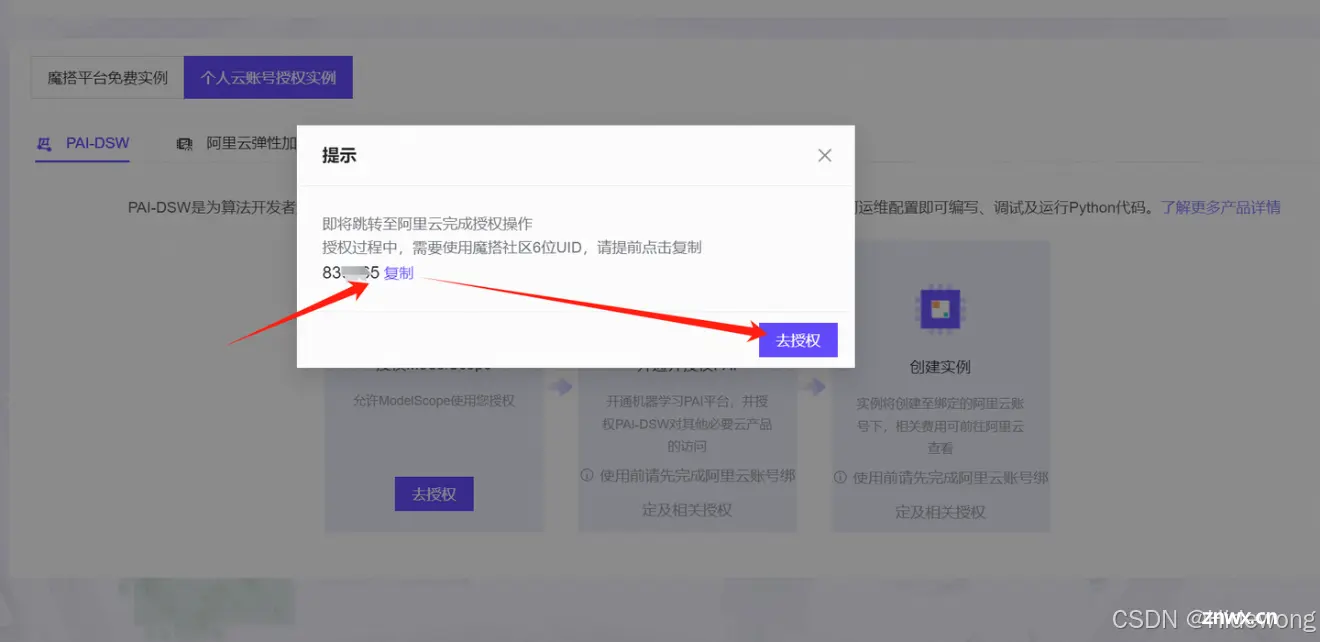
点击“复制”—>“去授权”
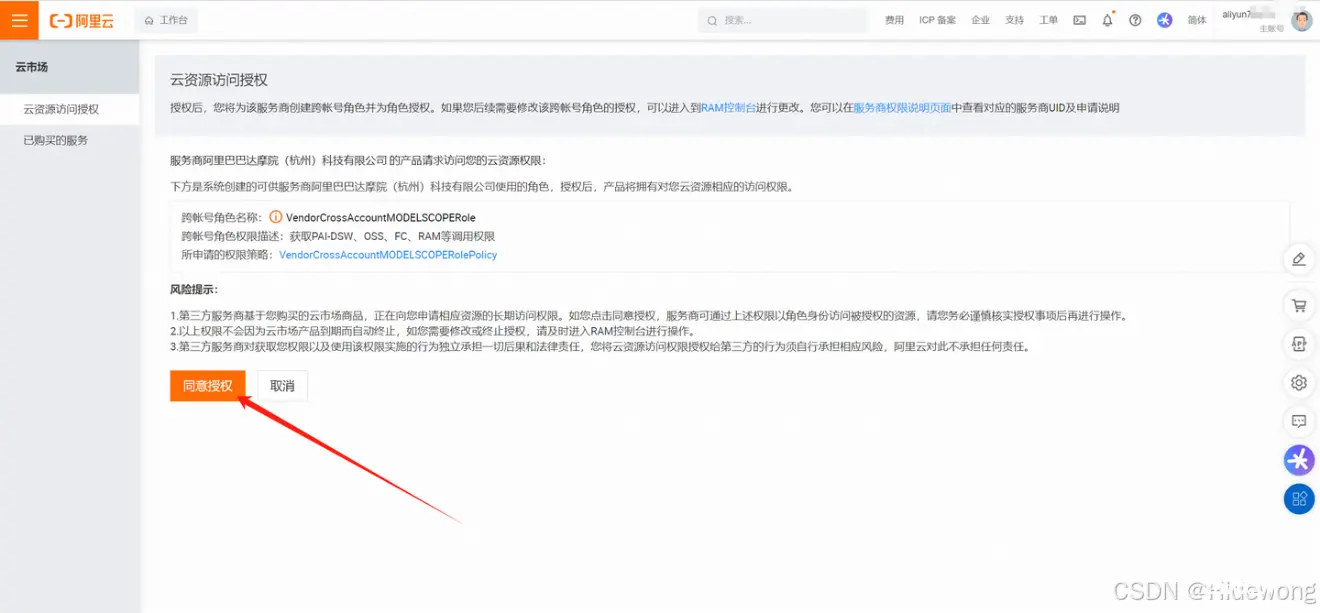
点击“同意授权”
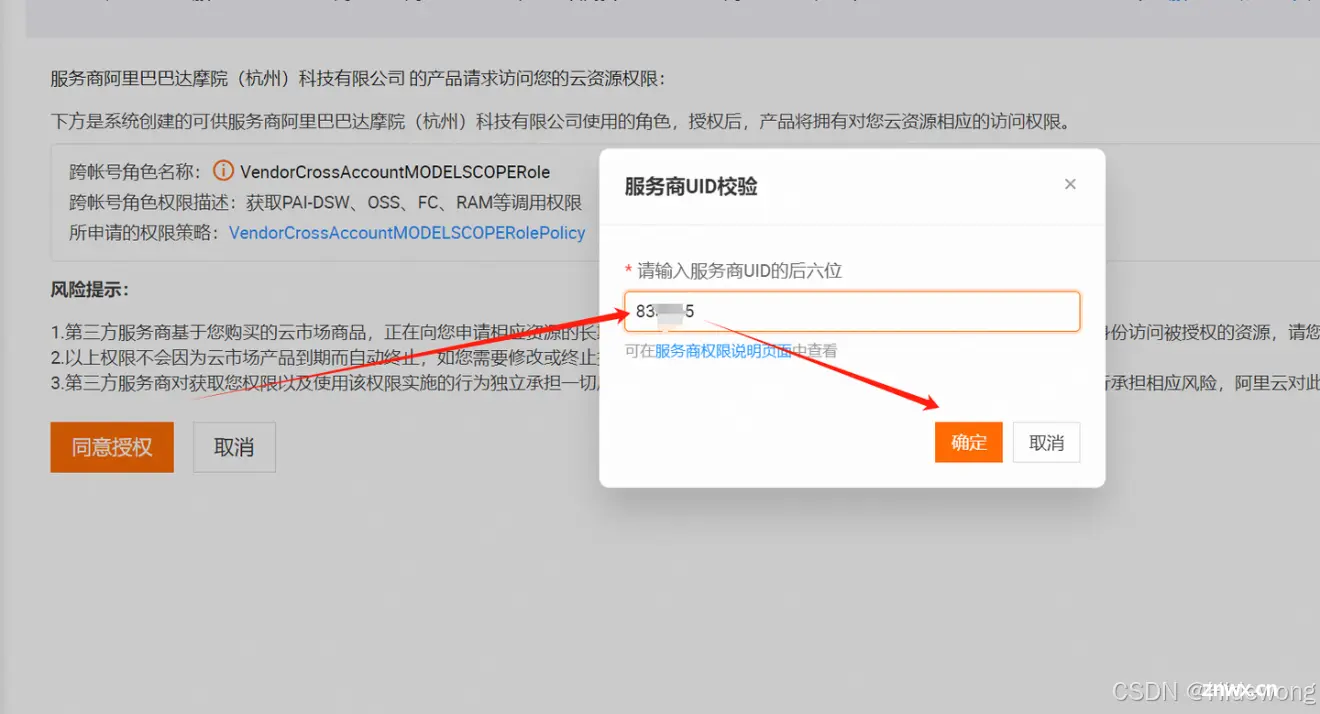
粘贴刚刚复制的UID,点击“确定”
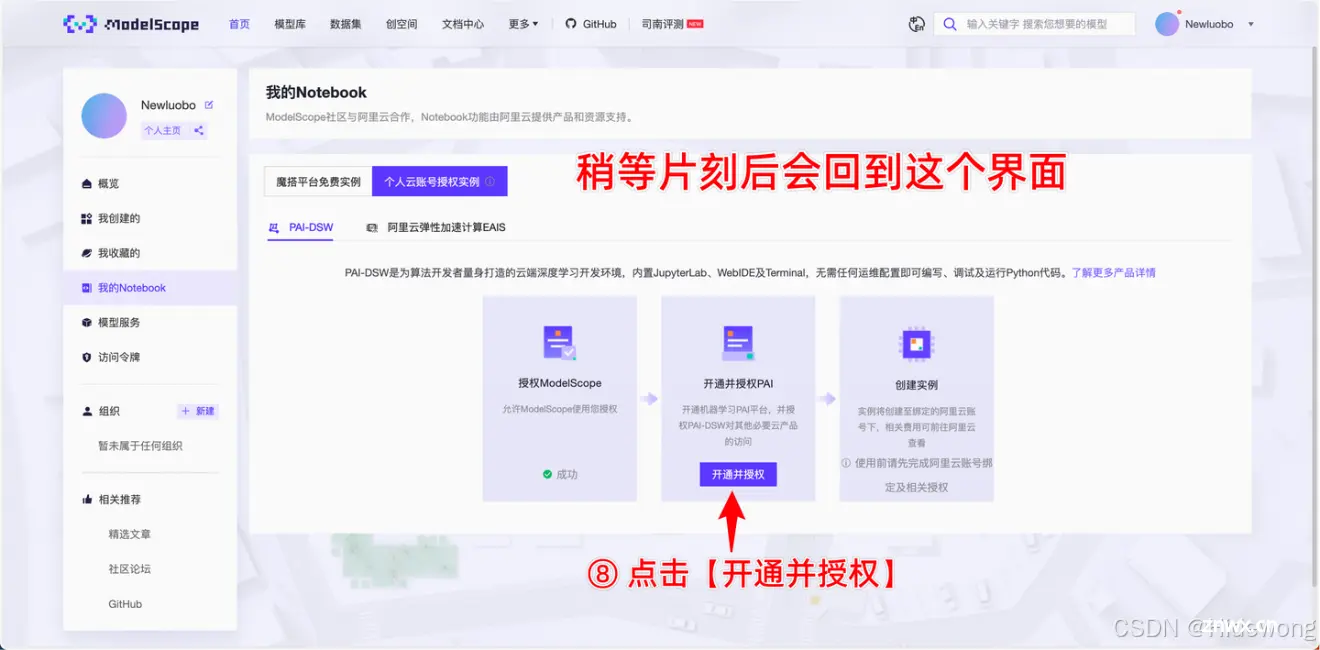
1.3 报名参赛
本夏令营和比赛紧密结合,通过实时提交结果返回成绩来检验自己的学习成果。
可图Kolors-LoRA风格故事挑战赛,旨在通过生成图片来讲述连贯的故事,并培养大家的AI实践能力,与本赛道密切相关。
下一步是报名参赛,由于第一步已经注册登录阿里云,所以省去再次登录等步骤。
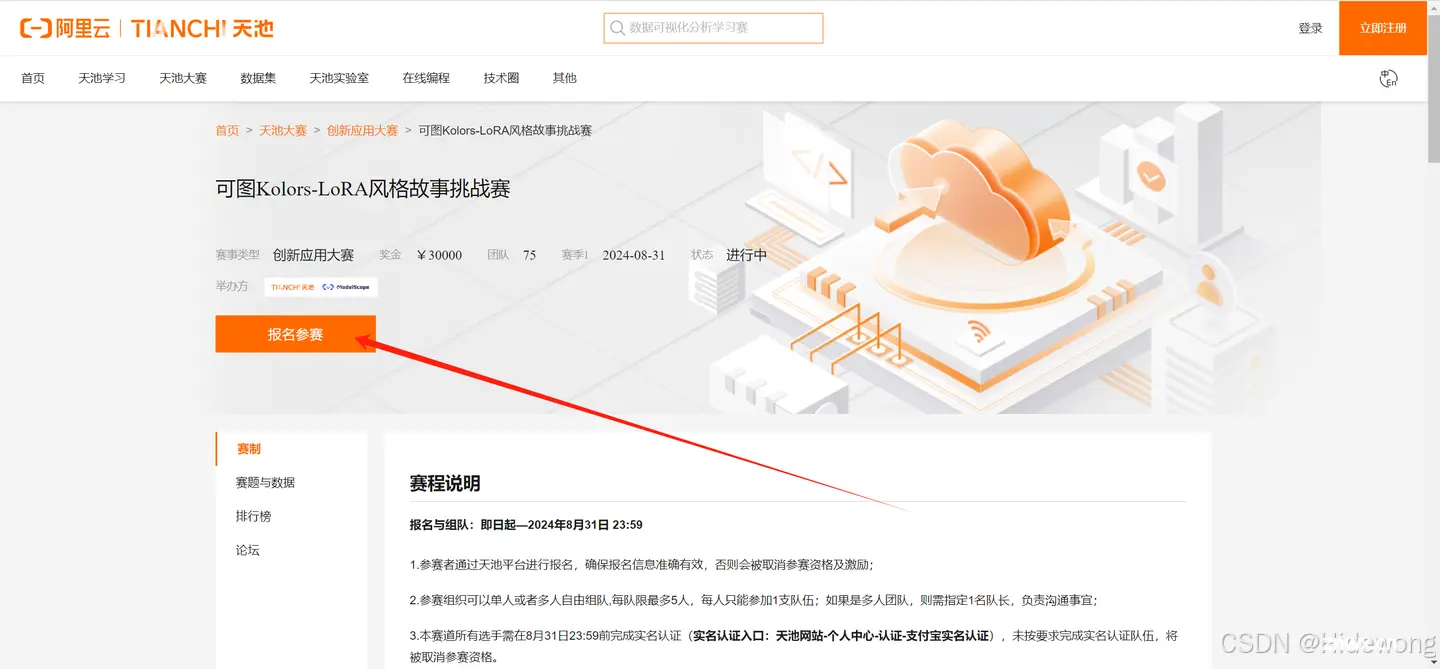
可图Kolors-LoRA风格故事挑战赛_创新应用大赛_天池大赛-阿里云天池的赛制
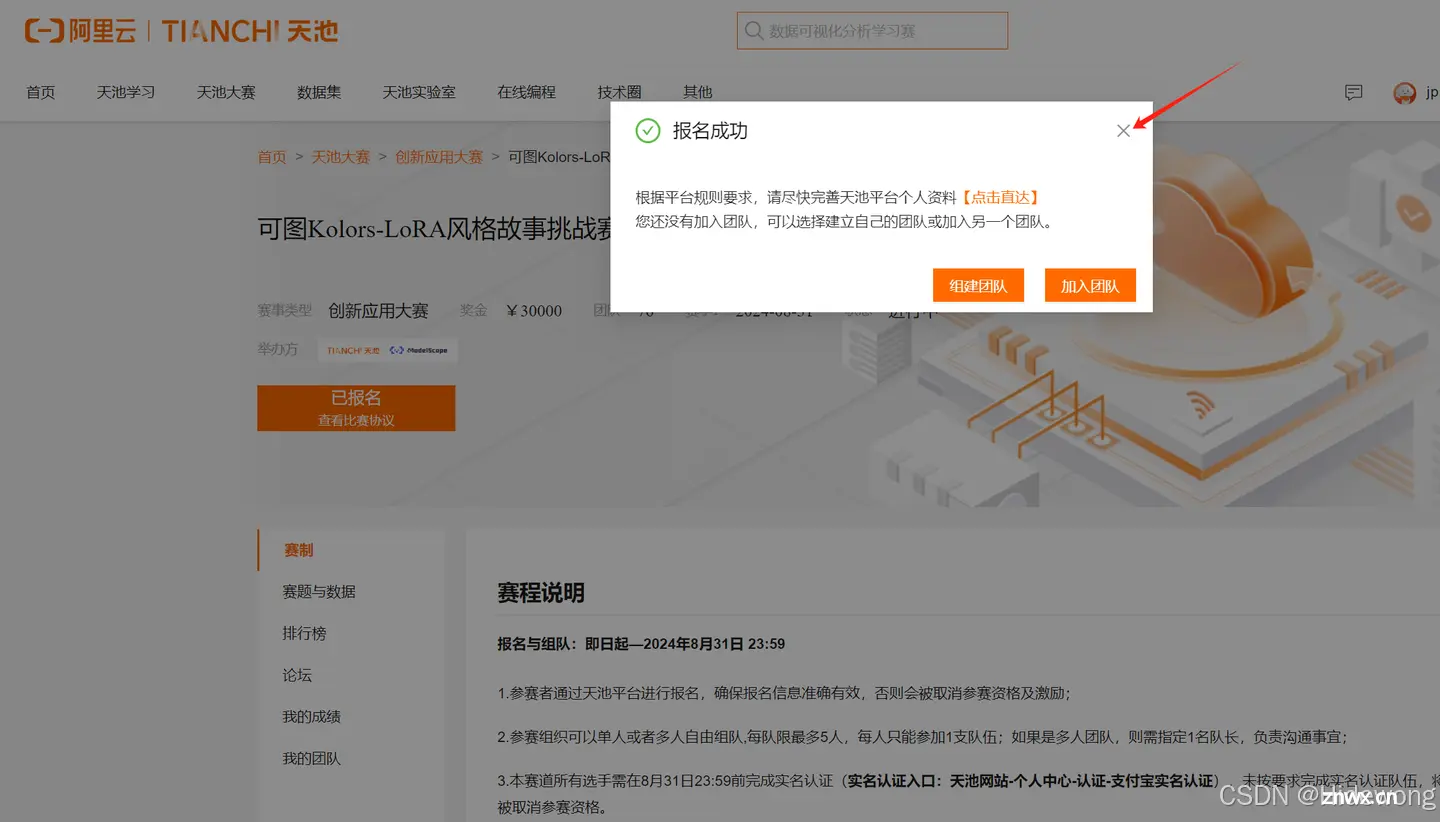
关闭窗口即可,无需组建或加入团队
1.4 创建PAI实例
PAI实例可以看作是操作系统中的一个账户,如果要和这个系统交互,那么系统中至少有一个账户。每个账户都有自己独立的工作空间和资源,互不干扰。
在本次比赛中,创建PAI实例的作用是:
训练模型: 使用PAI实例的计算资源来训练你的LoRA模型,让它学会生成各种风格的图片。
管理项目: 在PAI实例中存储和管理你的代码、数据和模型文件,确保所有项目文件都井井有条。
确保资源独立: 确保本比赛项目和其他项目互不干扰,以后需要用到PAI,可以创建新的实例,而不需要基于本比赛项目的实例。
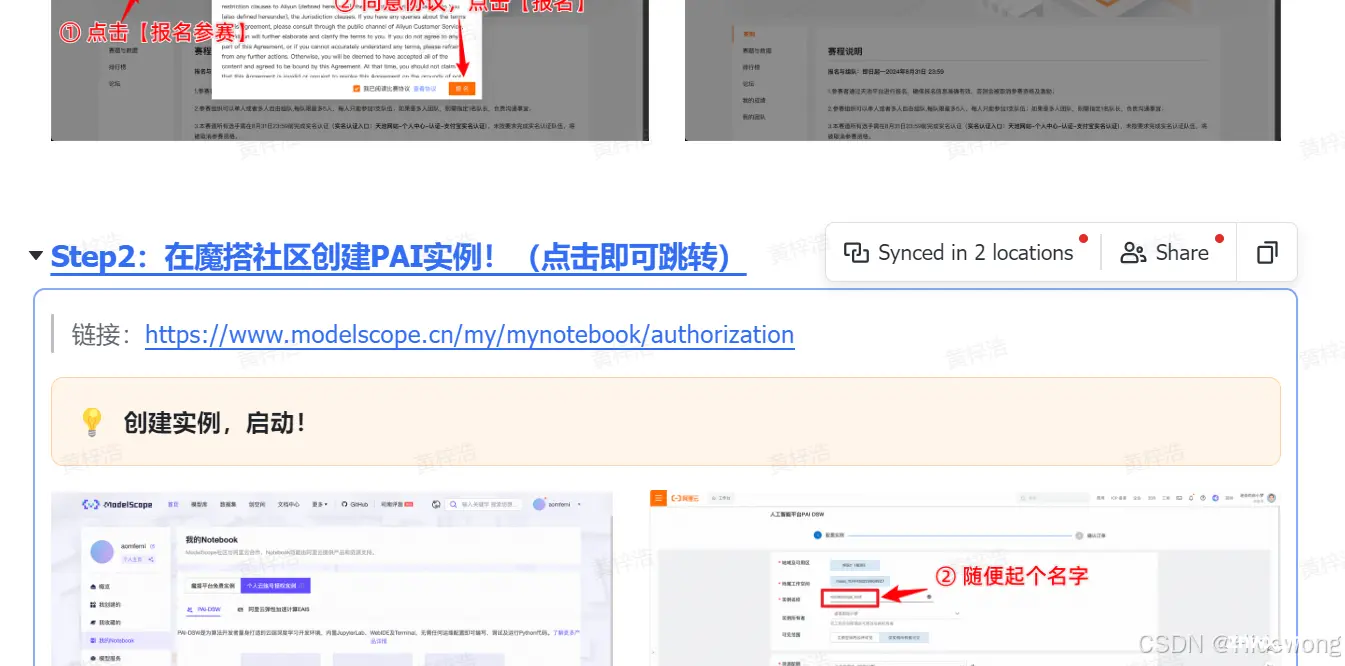
回到魔搭界面,如果已经关闭可以点击蓝色链接跳转
魔搭社区
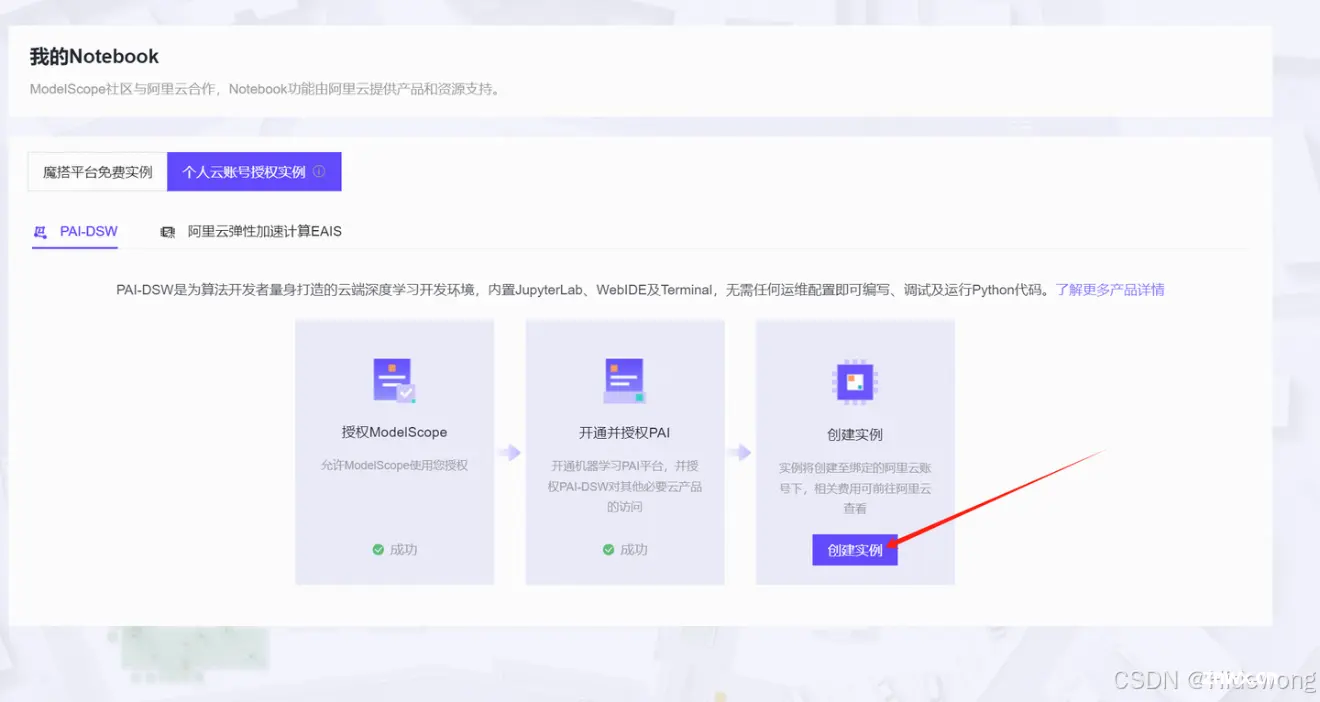
点击“创建实例”
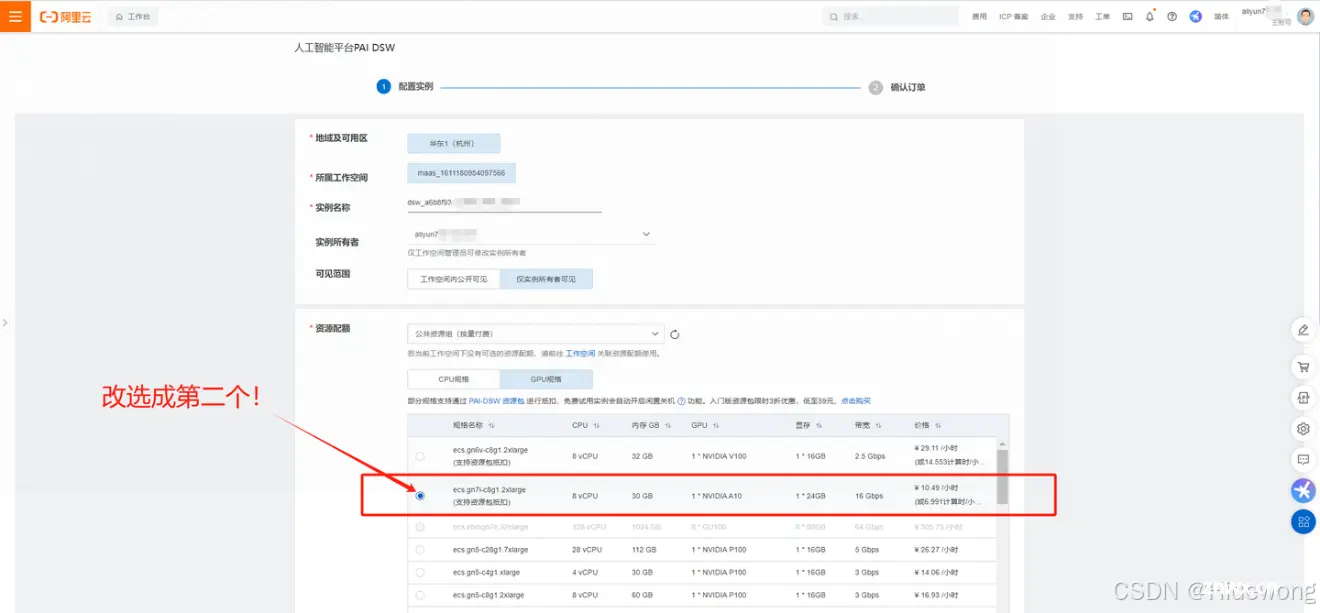
这里要改选成第二个,其他地方不用改动
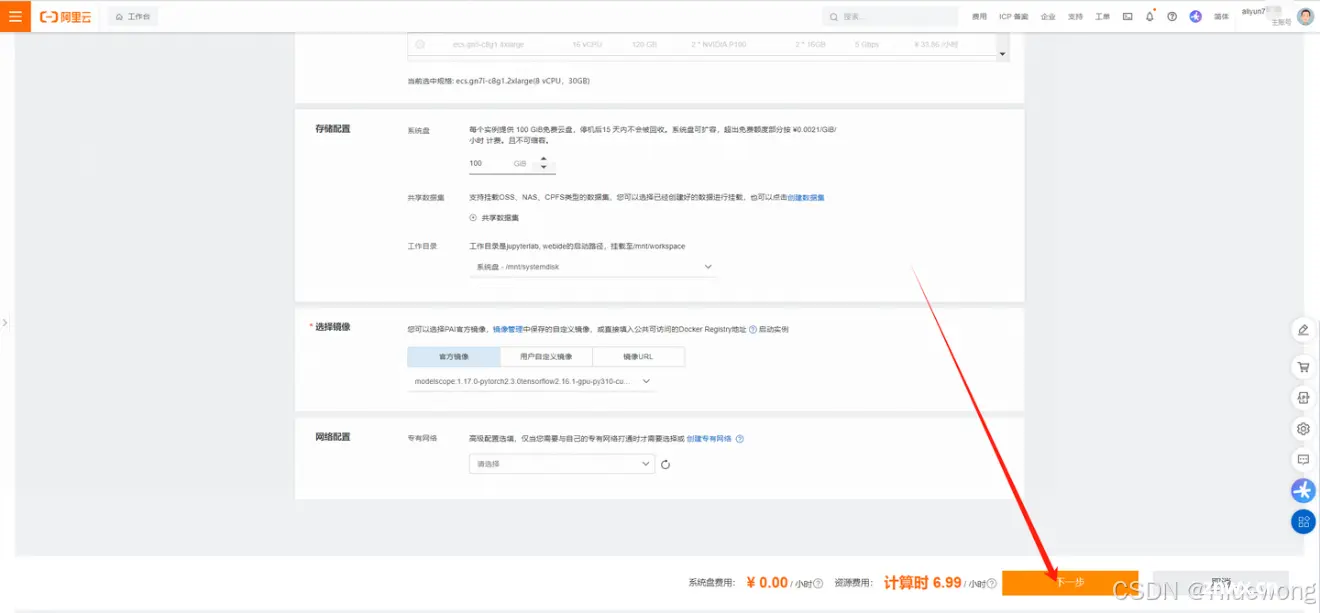
往下滑,点击“下一步”,然后点击“创建实例”
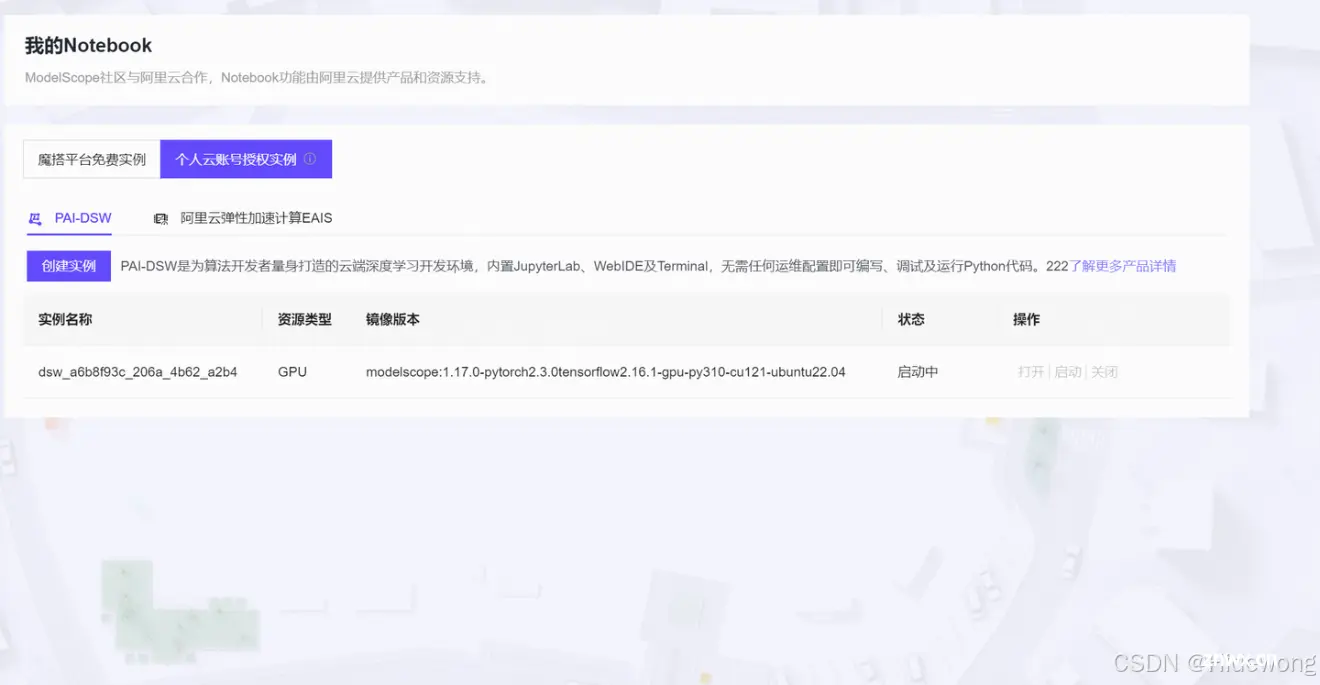
自动跳转回该界面,等待约2-3分钟,状态变为“运行中”,点击其右侧的“打开”
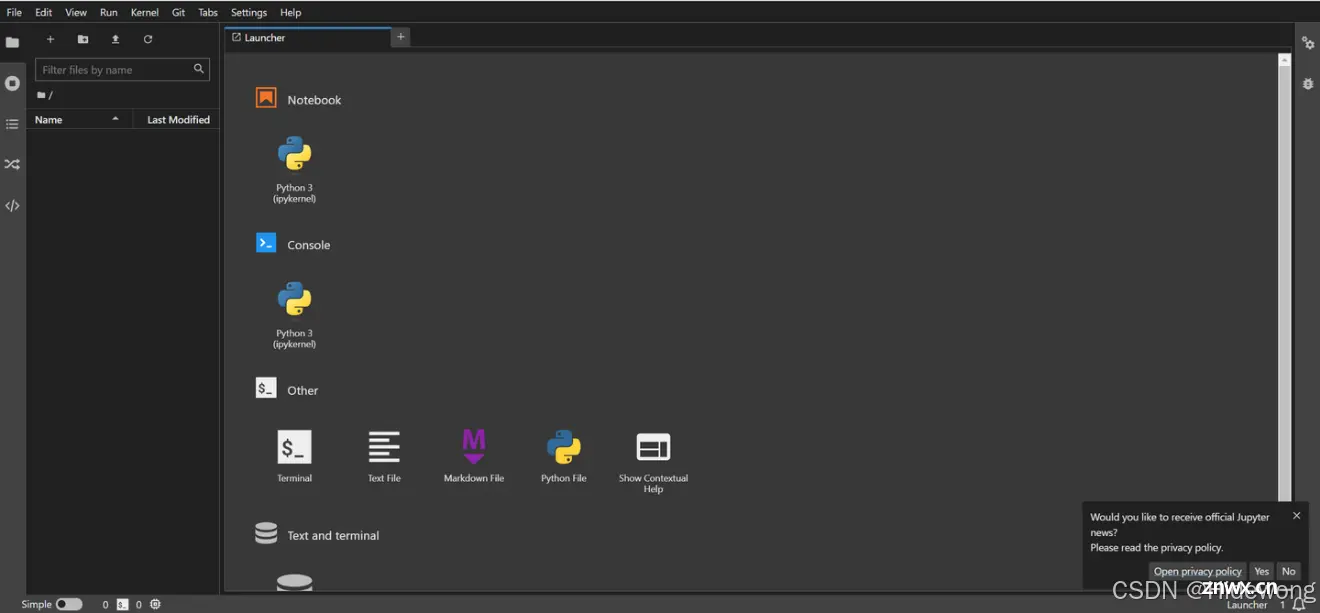
跳转至该界面,已经成功一半了!
第二步 30分钟体验一站式Baseline
正如一开始所说,你不需要写一行代码,因为代码已经现成完整、可以直接运行。
我们以后的学习将会围绕看懂代码,修改一点点代码,优化代码性能以达到更好的更满意的结果。
但是接下来,你只需要跟着步骤一步一步动动鼠标跑通Baseline,就可以得到你的第一个结果!
2.1 下载赛题数据和Baseline
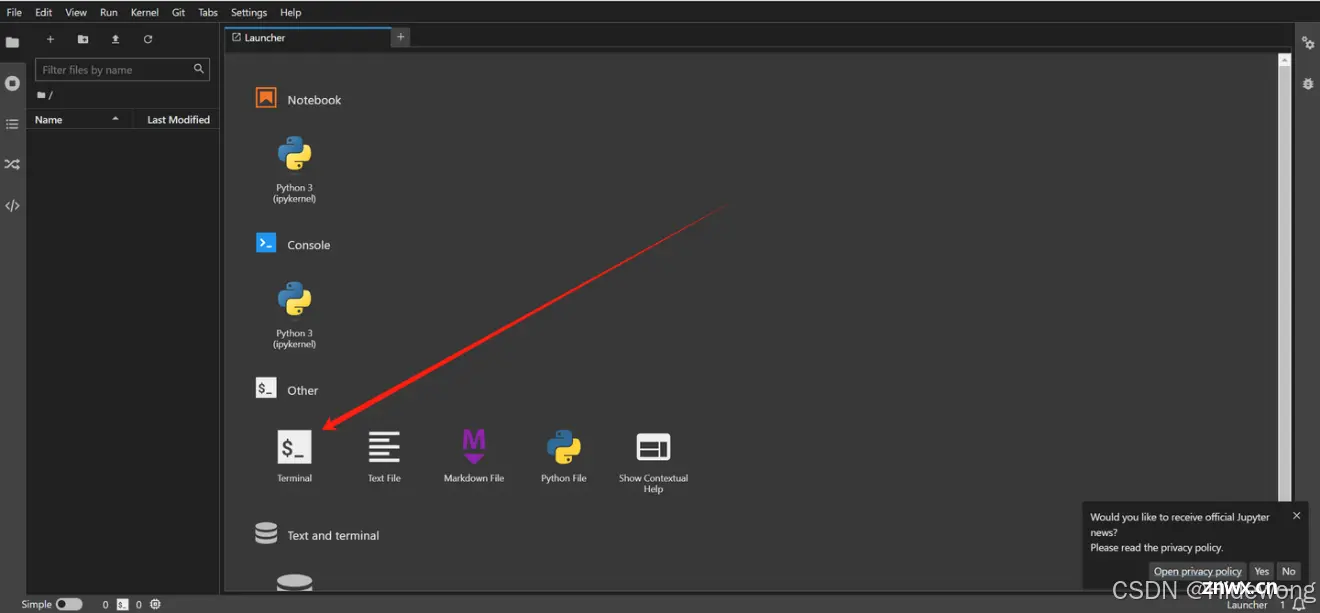
点击Terminal
在使用阿里云PAI-DSW进行AI文生图比赛时,你需要通过终端(Terminal)执行一些命令来获取和准备必要的资源。这些命令的主要作用如下:
为什么需要在终端输入 <code>git lfs install 和
git clone命令?
1.
git lfs install
作用:
git lfs(Git Large File Storage)是一个用于处理大文件的Git扩展工具。执行git lfs install是为了安装和配置这个工具,使其能够在Git中处理大文件。
原因: 在AI模型和数据集中,通常包含一些较大的文件,例如图像或模型参数。这些文件可能会超过普通Git仓库的处理能力。
git lfs可以帮助你管理和下载这些大文件,确保你的项目能够顺利运行。
2.
git clone https://www.modelscope.cn/datasets/maochase/kolors.git
作用:
git clone命令用于从远程仓库下载整个项目到本地计算机。这个命令会将位于ModelScope上的Kolors数据集代码和相关文件复制到你的PAI实例中。
原因: 你需要这个数据集来训练你的LoRA模型。通过
git clone下载数据集,可以确保你拥有最新版本的数据和代码,以便开始进行训练和开发。
这些步骤是为了准备你的工作环境,确保你可以顺利进行模型训练和项目开发。
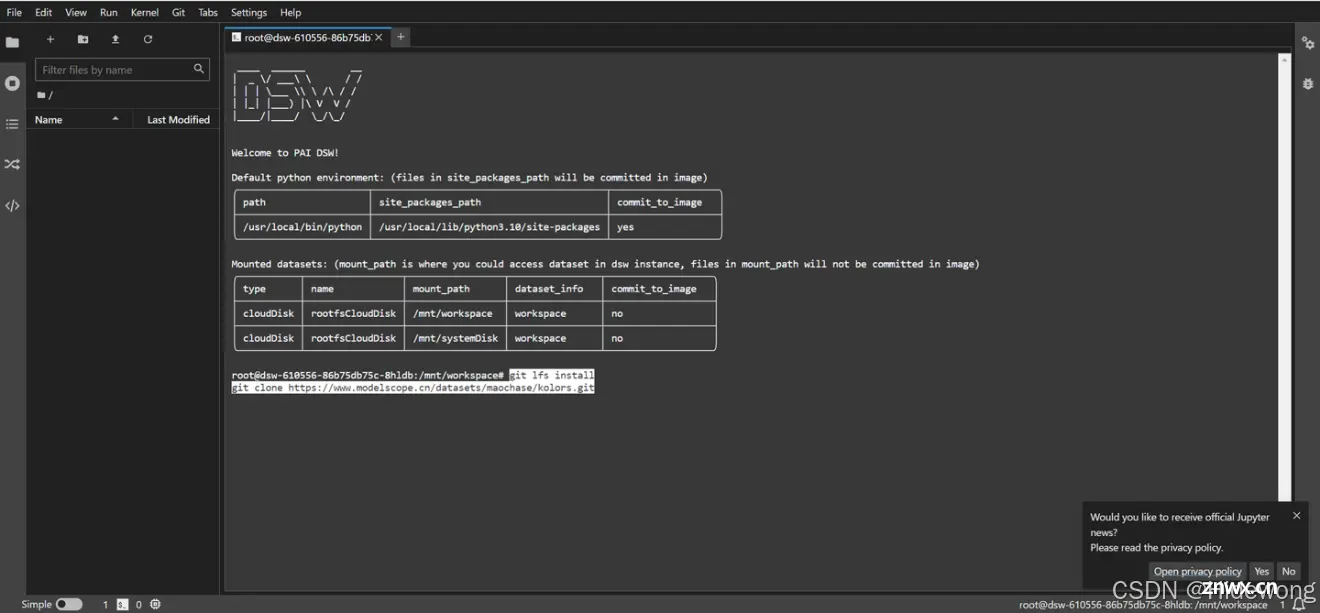
复制如下代码并按Enter
<code>git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors.git
2.2 进入Baseline
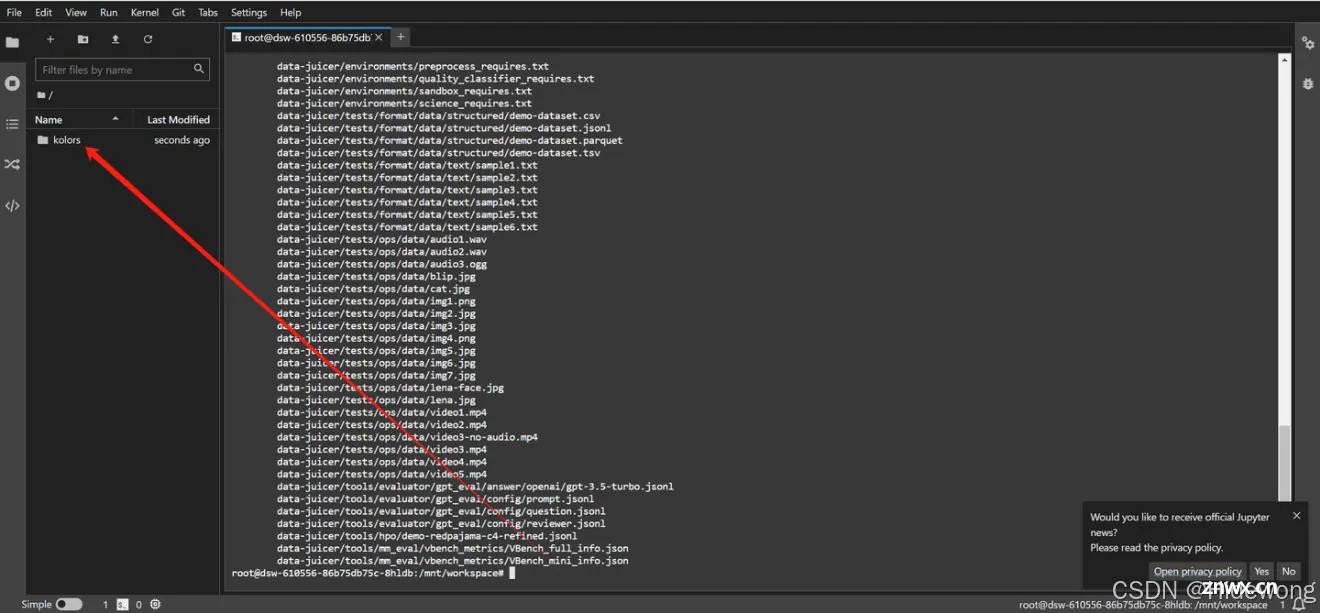
双击进入文件夹
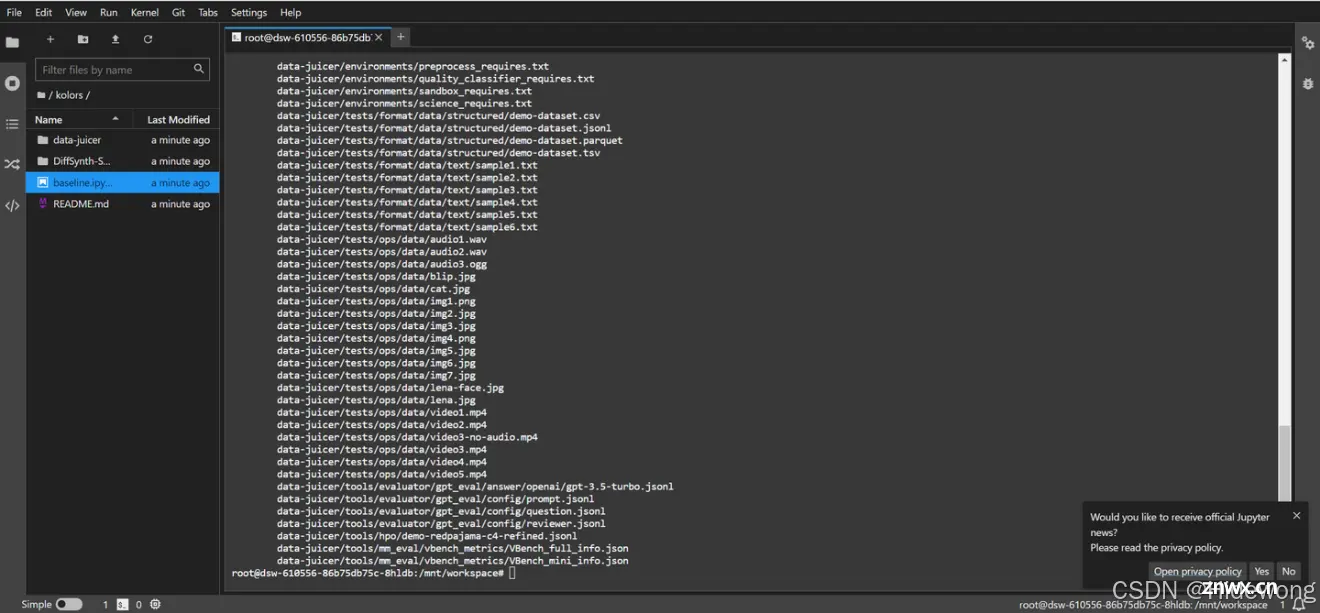
双击该文件
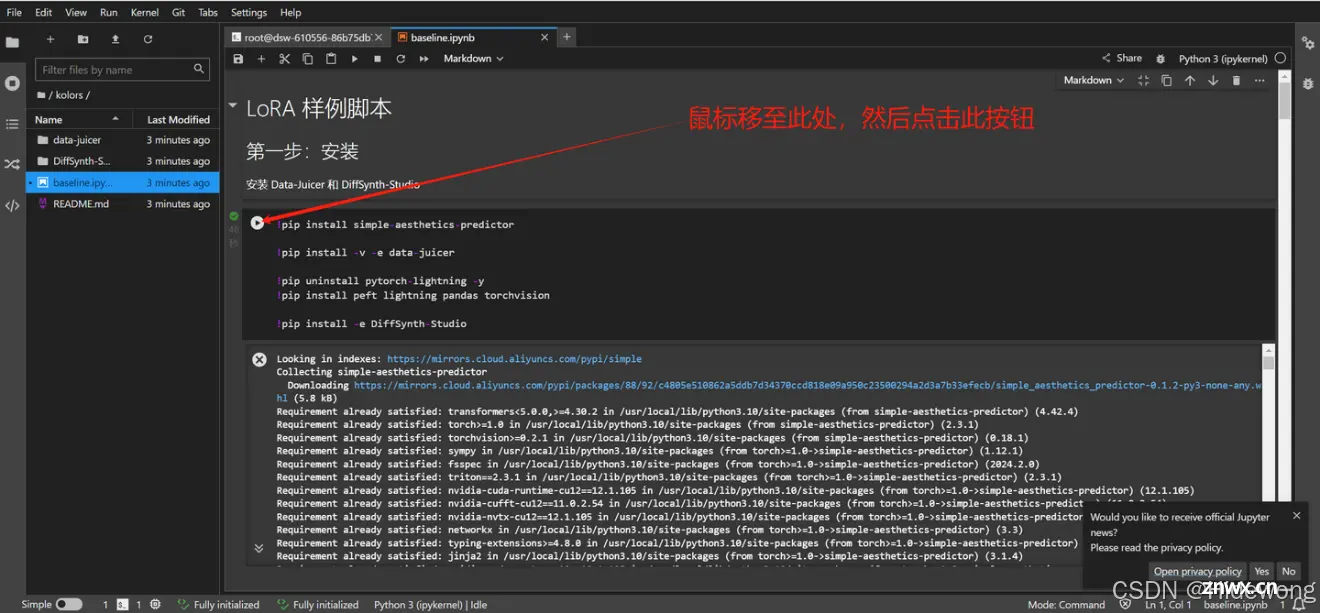
2.3 准备工作
在参加AI文生图比赛的过程中,安装 Data-Juicer 和 DiffSynth-Studio 是准备工作的关键步骤。这两个工具分别负责数据处理和模型训练,确保你能够顺利地从原始数据到生成最终的图像。
Data-Juicer 是一个专门用于数据处理和转换的工具。它的主要功能是简化数据的提取、转换和加载过程。
使用 Data-Juicer 来整理和转换数据,使数据适合用于训练。这一步骤确保你的数据能够被正确读取和处理,提高模型训练的效果。
DiffSynth-Studio 是一个用于高效微调和训练大模型的工具。它提供了优化的训练环境和功能,帮助你在基础模型上进行微调。
使用 DiffSynth-Studio 来微调和训练你的LoRA模型。它提供的高效训练环境和功能帮助你在基础模型的基础上进行优化,使其能够生成各种风格的图片。
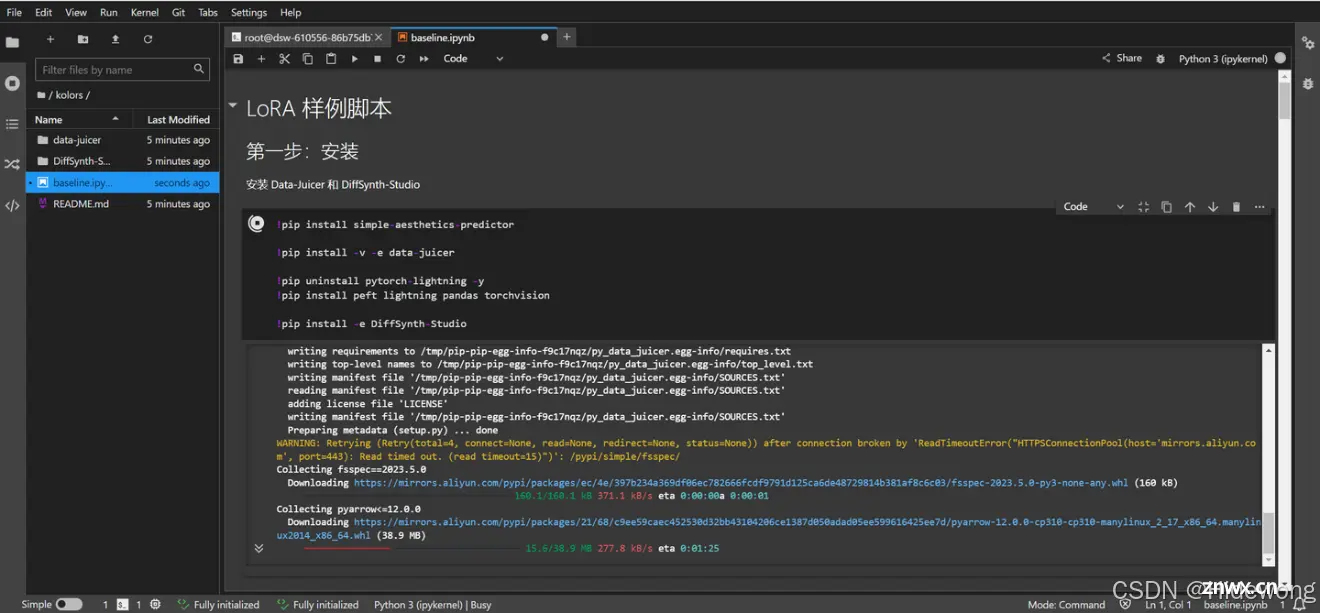
等待10分钟
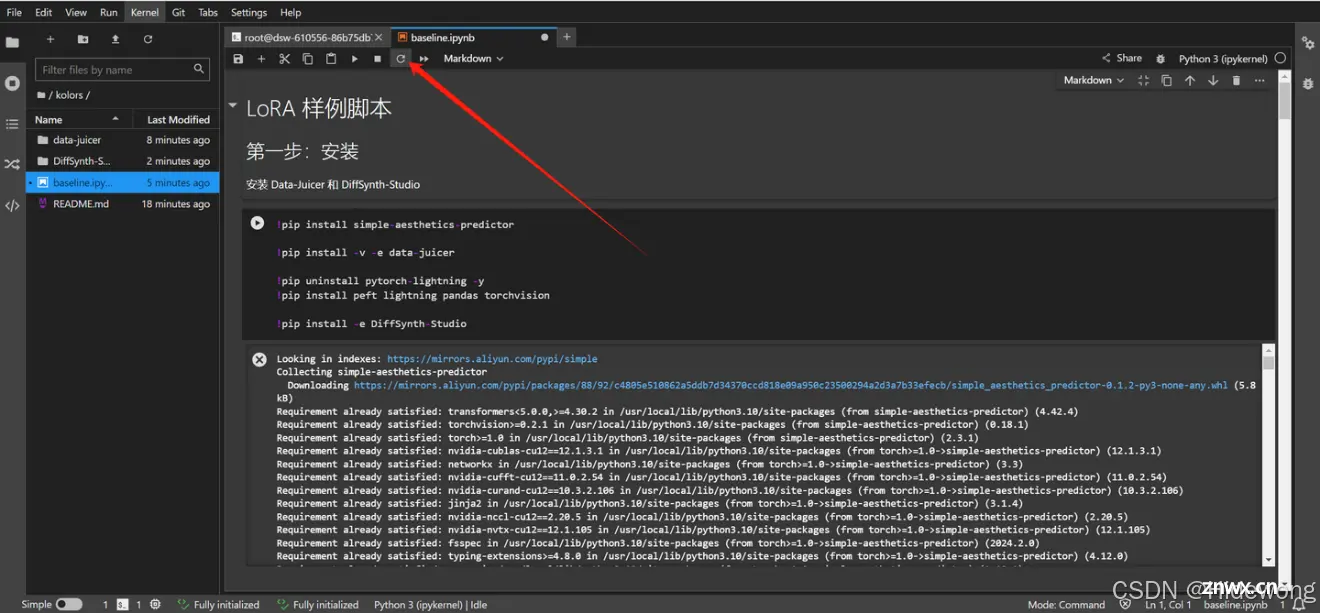
点击此按钮重启Kernel,腾出内存空间
2.4 运行剩余Baseline
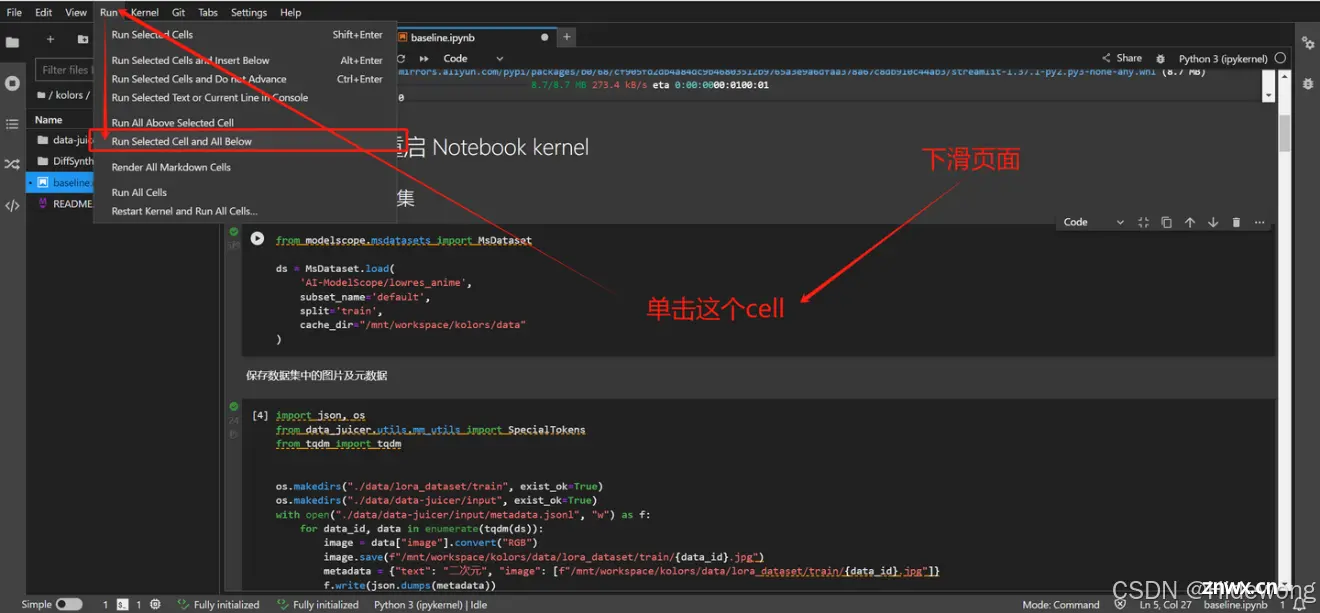
静静等待半个小时...
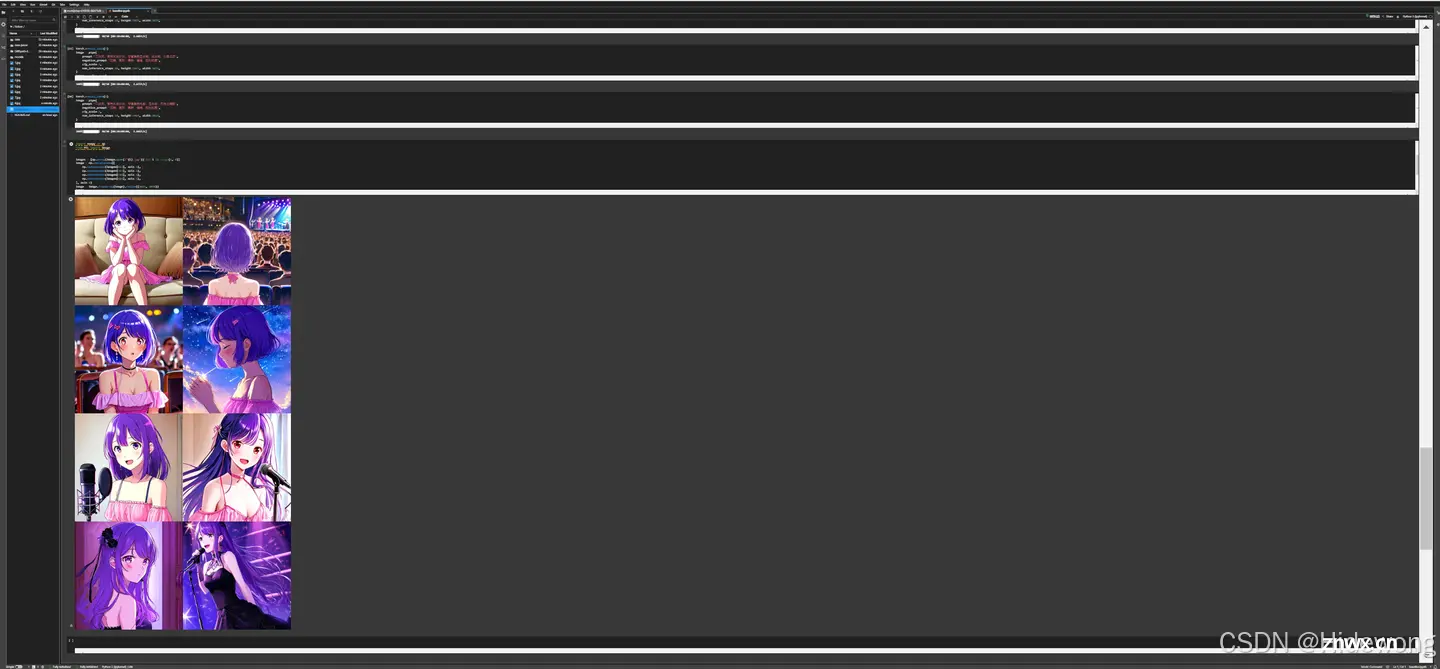
大功告成!
还差一点点...
第三步 提交结果
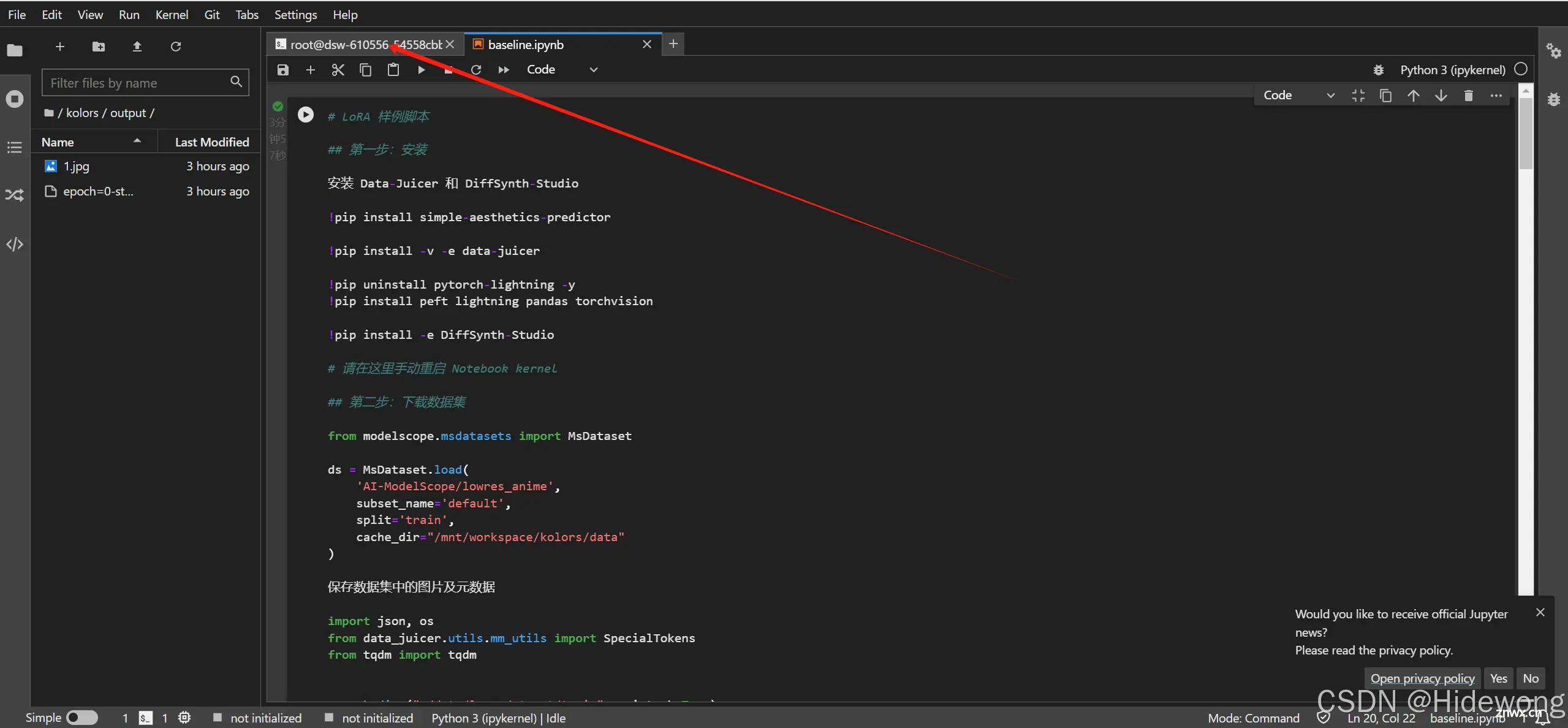
回到Terminal
复制以下代码到Terminal并按Enter
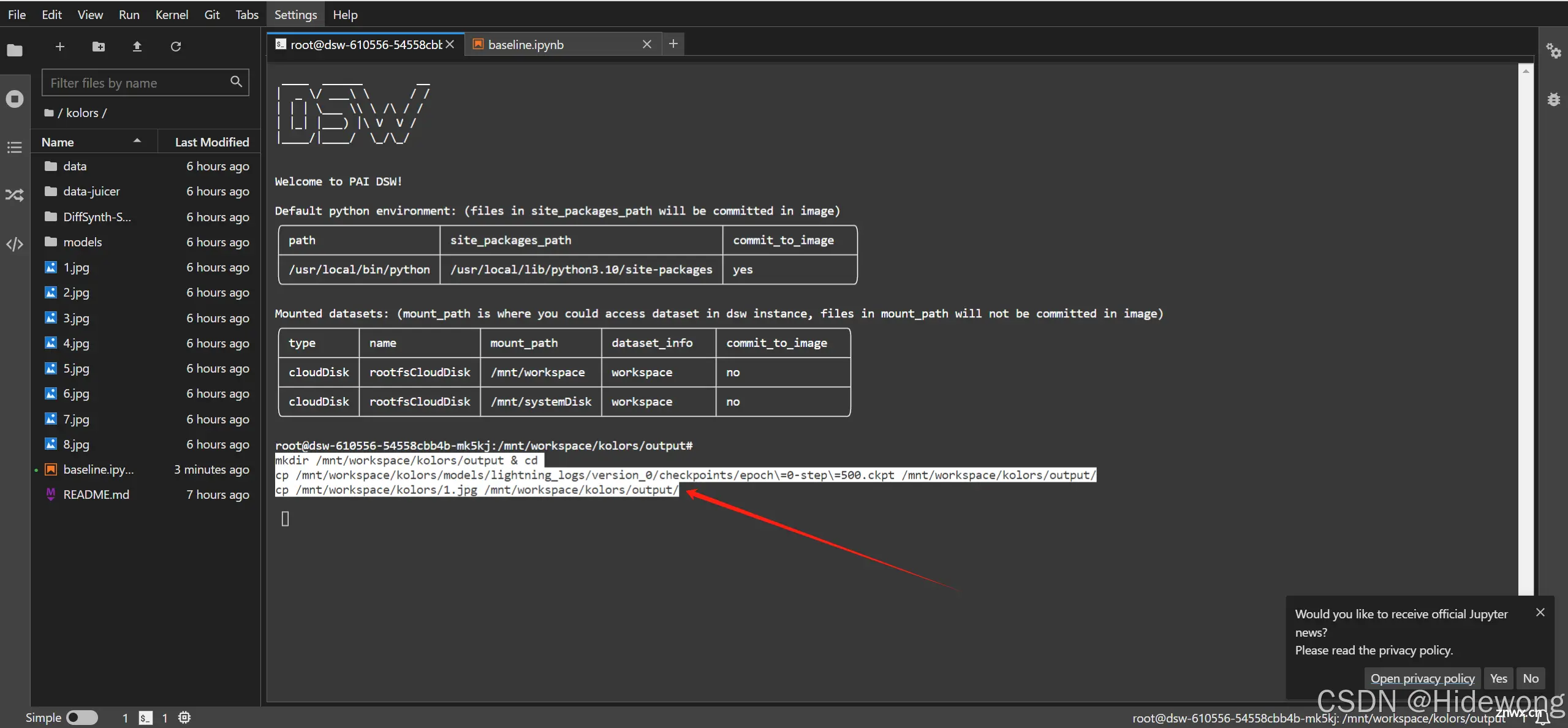
<code>mkdir /mnt/workspace/kolors/output & cd
cp /mnt/workspace/kolors/models/lightning_logs/version_0/checkpoints/epoch\=0-step\=500.ckpt /mnt/workspace/kolors/output/
cp /mnt/workspace/kolors/1.jpg /mnt/workspace/kolors/output/
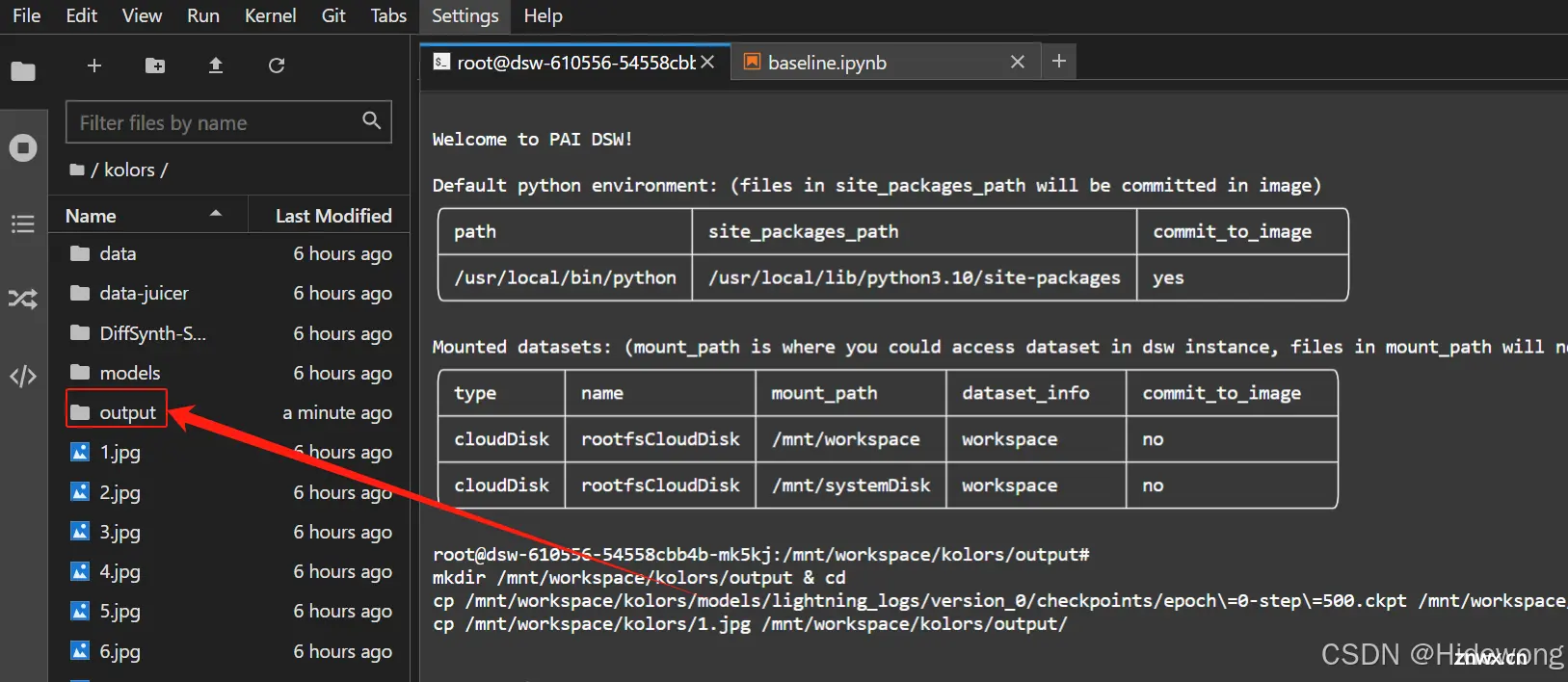
双击output文件夹
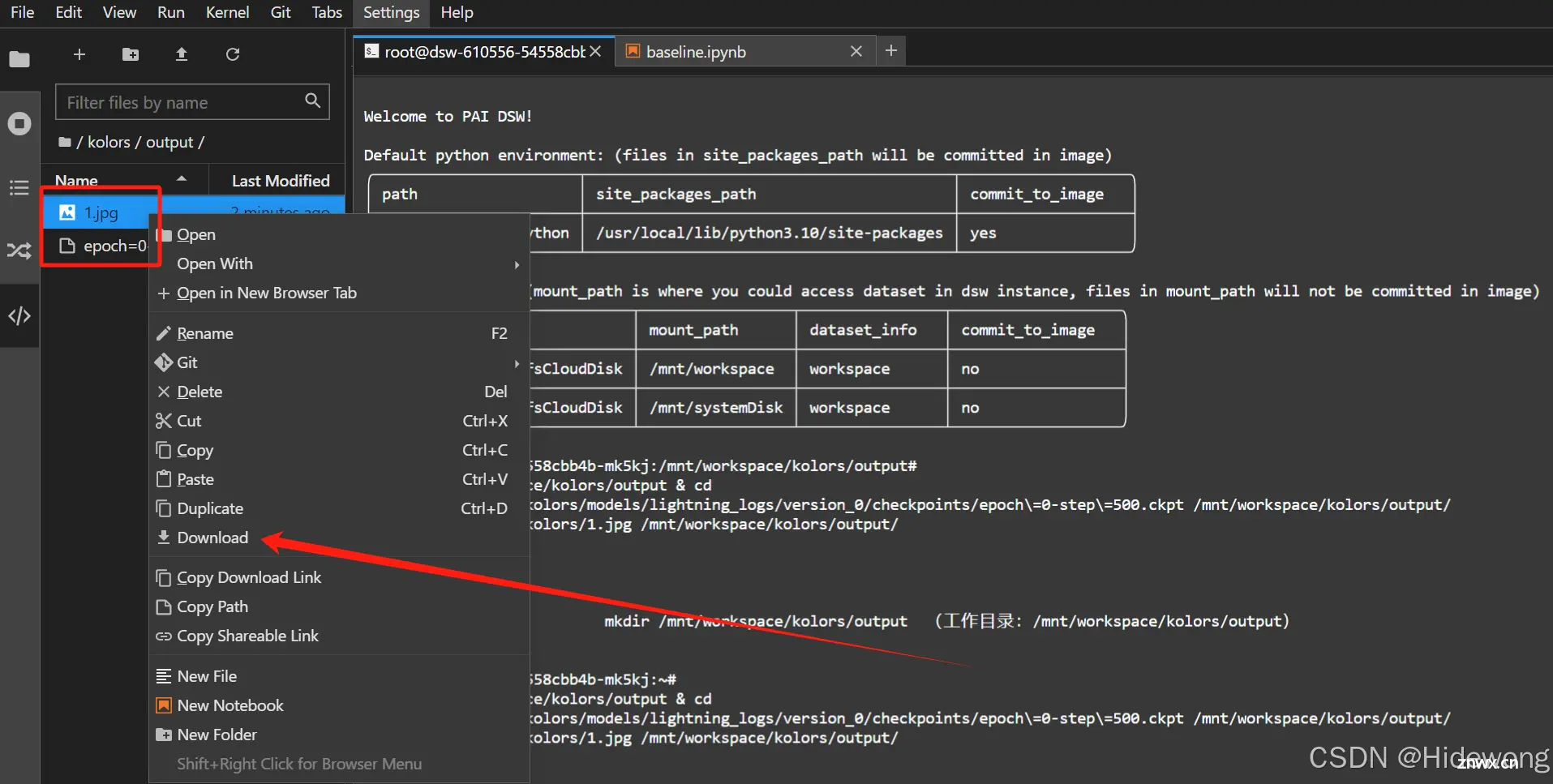
分别保存output文件夹下的两个文件
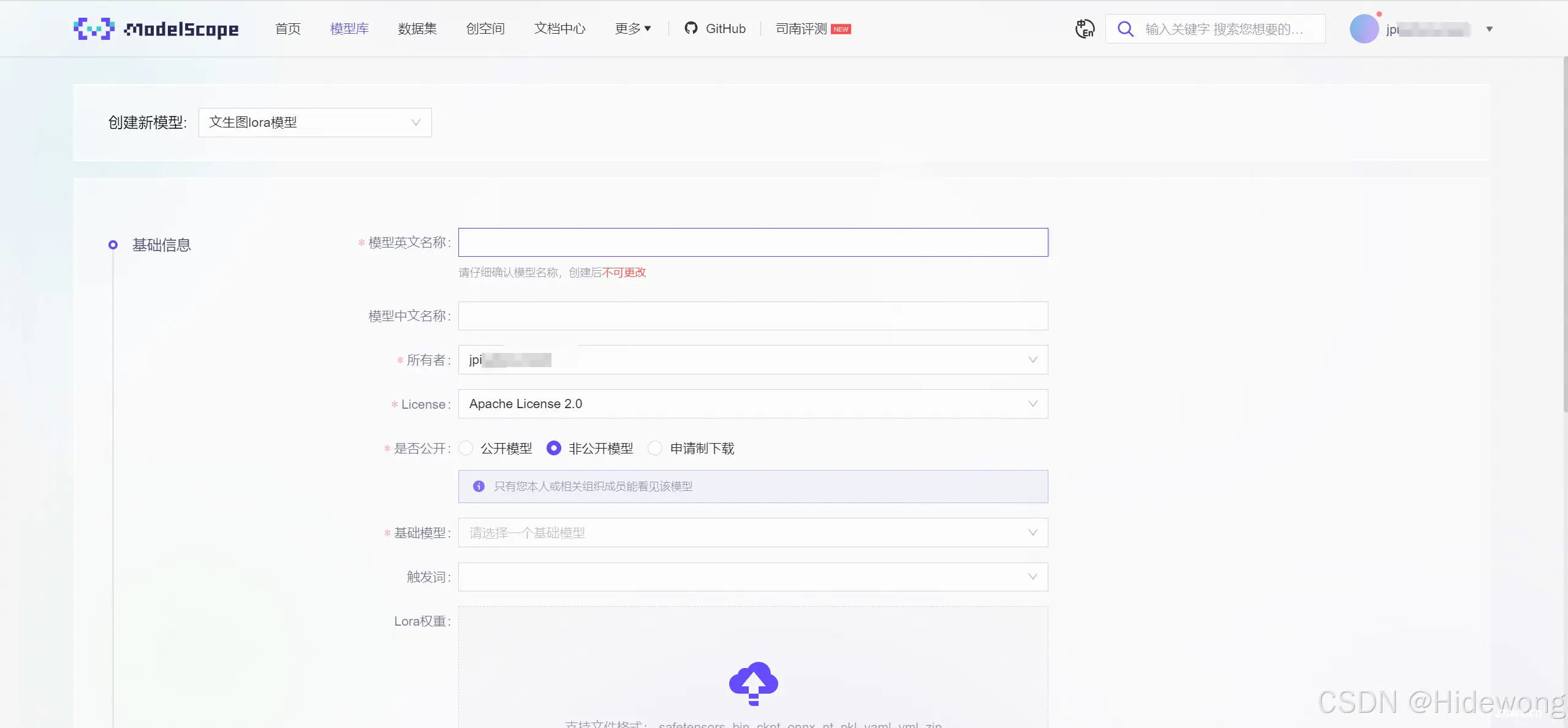
标题
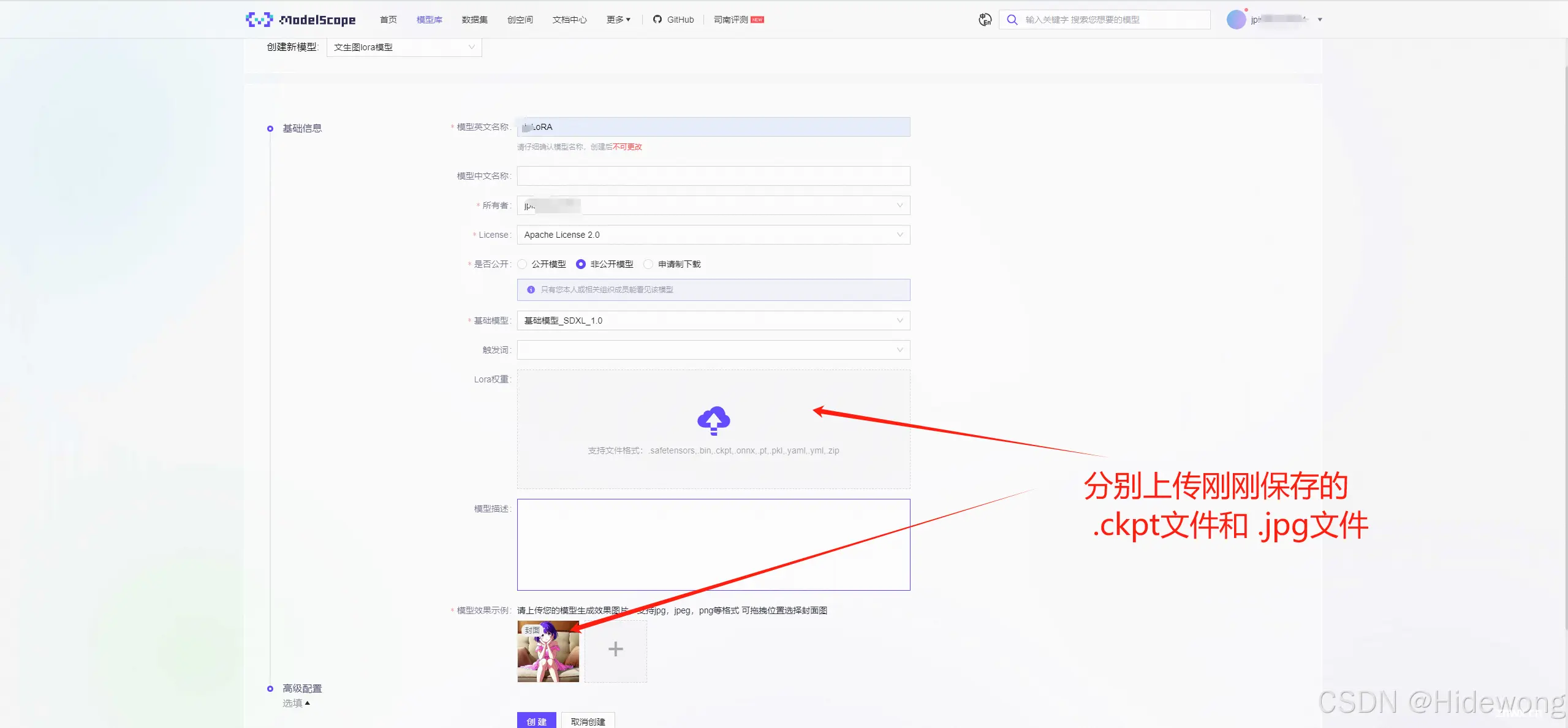
填写内容,上传文件,点击“创建”
代码的具体解析待续..
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。